はじめに
今まで、
- Kinesis Data Streams + AWS Lambda
- Amazon SQS+ AWS Lambdaのバックエンド、
- Amazon SNS + Amazon SQS + AWS Lambda
といったアーキテクチャをお客様のアプリケーションの中に組み込んできた中で、よくやっていたのが、Lambda Functions内で処理すべきデータか判断する、あるいは、判断を後に任せてとりあえず全部処理したり、不要なデータをスキップしたりしていました。これは、従量課金制のLambdaに対して、本来、処理対象ではないはずの不要なデータを投入し処理し、AWSサービス利用料、処理時間等に多少なりとも影響があったと思います。
当記事では、その課題の改善につながる、2021/11にリリースされたKinesis Data Streams, Amazon DynamoDB Streams, Amazon SQSをイベントソースとするLambda のEvent Filtering機能について、実際にSAMで環境を構築しデータを投入して実験し、その結果を整理したいと思います。
ここでの実験結果は私個人が興味で行っているものであり、所属する団体・組織を代表するものではありませんのであらかじめご了承ください。
サマリ
- EventBridgeのルール定義と同じ方法で条件を記載可能
- AWS CLI/SAMで定義可能
- イベントソースごとに不一致時の挙動がことなるため注意
Event Filtering機能とAWS サービス
Kinesis Data Streams, Amazon DynamoDB Streams, Amazon SQSをイベントソースとするLambda のEvent Filtering機能が出てきたときに、今まで、Event Filteringは他にどんな方法があったのかな?と考えてみました。冒頭で例に挙げた、SNS-SQSの場合は、SNSに対してSQSのSubscriptionを作成する際に、メッセージの属性と値の組み合わせを定義したFilter policiesを適用することで、メッセージのフィルタリングができ、キューに配信されないように制御できました。
それ以外のサービスとしては、Amazon EventBridgeも該当しますね。Amazon EventBridgeのイベントパターンもイベントをフィルタリングし、必要なイベントをターゲットに転送し、処理を行うことを支援します。
私は、この二つの機能が頭に浮かびあがりましたが、今回のAWS LambdaのEvent Filtering機能は、Event Bridgeのイベントパターンの定義形式と同じ形式するものであり、EventBridgeをご利用されている方(あるいは、その前身のCloudWatch Events)には、非常になじみやすいものかなと思います。
機能の特徴と利用時の注意点
さて、当機能の特徴を簡単に整理するとともに、私が個人的に注意すべきだなと思った点を整理します。
特徴
対象となるサービス
対象は、Event Source Mappingで定義されるサービスの中で、
- Kinesis Data Streams
- Amazon DynamoDB Streams
- Amazon SQS
が対象です。したがって、同期で呼ばれる場合や、非同期で呼ばれた場合、また、上記以外のAmazon Managed Streaming for Apache Kafkaは対象外です。
フィルタの定義と処理
上限
1つのイベントソースに対して最大5個まで、1つのフィルターには最大2048 文字まで定義できます。(2048文字については執筆時点では、こちらに記載がありました。) 前述した通り、Amazon EventBridgeのEvent Patternと同じ文法で定義できます。
イベントとフィルタ定義
各イベントソースからLambdaに届くイベントは例えば、各イベントソースとなるAWSサービスが付与するメタデータの部分と、イベントソースのアプリケーションプログラムがセットするデータで構成されます。フィルタ定義はこの両方に対して、フィルタルールを指定可能です。例えば、「Null」「空文字」「存在する・存在しない」から「一致する・前方一致」「数値データに対するXXX以上、XXX以下」や「AND/OR/NOT」も指定可能です。定義は、AWS CLIやSAMでも可能です。JSONでの定義は私は苦手なので、この後の検証では、SAMで検証します。
動き
イベントがAWS Lambdaに届くと、まず定義されたFilterに一致するか判断され、その後、「バッチ(Lambda 関数に渡すイベントまとまり)」を作りバッチ単位にLambda関数が起動されます。

図はこちらから引用
複数のフィルタを定義した場合、どれか1つのフィルタに対象レコードまたはメッセージが一致すれば、関数が起動されます。
これにより、不要なイベントが排除されて、Lambda関数は起動されず、Lambda関数のAWSサービス利用料の削減につながります。
一方、私が気になるのは、Kinesis Data Streamsの読み取りキャパシティです。このEvent Filterを利用することで、1つのStreamに対して特定のイベント用のLambdaを複数付け、それぞれが自分が処理したいデータだけをFilterで定義すると楽ちんだな~と考えたためです。これは、どういう動きになるのか、後で検証してみたいと思います。
なお、フィルターと不一致な場合の動きについては、後述の注意点で記載しますがイベントソースごとに異なるようです。
注意点
SQS利用時のメッセージフォーマットとフィルタ
SQS のメッセージのフォーマットは利用者が任意に決められます。例えば、BodyはPlain TextかもしれませんしJSONで構造化されているかもしれません。
This is Test Message. Timestamp is 2021-12-01T09:00:00
{
"message" : "This is Test Message"
"timestamp" : "2021-12-01T09:00:00"
}
上記のようにメッセージのフォーマットは任意ですが、その形式により挙動が変わります。なお、後述のKinesis Data Streams/DynamoDB Streamsの場合は、JSONデータであることが前提となっており、SQSと異なります。
SQSの挙動の詳細はこちらに定義されていますが、一部簡単に表現するとこのような形です。
| Message Format | データ(body)に対するフィルタ定義 | 挙動 |
|---|---|---|
| Plain Text | Plain Text | 条件に基づいて評価 |
| Plain Text | JSON | Drop |
| JSON | Plain Text | Drop |
Kinesis Data Streams/DynamoDB Streams利用時のメッセージフォーマットとフィルタ
SQSの場合は前述した通り、JSONもPlain Textも対応しましたが、それとは異なり、Kinesis Data Streams/DynamoDB Streamsのデータプロパティは(Kinesis の場合はdata,DynamoDB Streamsの場合はdynamodb) JSONとなります。
詳細はこちらに記載がありますが、一部抜粋すると以下のような形ですね。
| Message Format | データ(body)に対するフィルタ定義 | 挙動 |
|---|---|---|
| Valid JSON | Valid JSON | 条件に基づいて評価 |
| Valid JSON | Non JSON | Filter定義時に例外が発生 |
| Non-JSON | Valid JSON | Drop |
| Non-JSON | Non JSON | Filter定義時に例外が発生 |
フィルターと不一致だったイベントに対する挙動
SQSの場合も、Kinesis Data Streamsの場合もDropという表現が登場しました。また、そもそも、適切に評価されて、不一致と判定されたデータがどう言う動きになるのかが重要です。
| 観点 | Kinesis/DDB | SQS |
|---|---|---|
| 不一致の場合 | 対象レコードは処理されたとみなされスキップして次に進む | メッセージがキューから削除される |
| Dropの挙動 | 先に進む | メッセージが削除される |
イベントソースごとに異なるイベントデータ
前述した通り、例えば、Kinesis Data Streamsの場合は、ユーザーがPut Recordしたデータは、"data"属性内にセットされますが、Amazon SQSでSendMessageしたデータは、"Body"内に格納されます。イベントソースにってフィルタを書く際には当然メタデータも変わってきますので注意してください。
バッチウィンドウとバッチサイズ
バッチに入るデータは、Filterで一致したデータのみとなります。仮にバッチウィンドウを今までは30秒、バッチサイズを100件としていた場合、Filter定義を追加したことで、バッチサイズがバッチウィンドウ内に満たされず、実質、時間でトリガーするようなケースが発生するかもしれません。早急に処理したい場合は、それでよいですが、ある程度まとめて処理したい場合、バッチウィンドウを今までより伸ばすことで影響を小さくする可能性があります。
文字列 vs 文字列による比較
Lambdaは、フィルタを処理する際、「文字列」で比較するため、300と300.0の用に数値的に同じ値となるものでも、異なる値として判断します。
試してみたいこと
今回は、Kinesis Data StreamsとSQSをイベントソースにして以下を試したいと考えます。
1.基本動作確認として、Dropはどんな動きになるか目視したい(願望)
対象:SQS/Kinesis
内容:不一致なデータはどう処理されるのか確認する。
2.Kinesis Data Streamsで消費されるキャパシティユニット
対象:Kinesis
内容:Batchに入らない場合でもキャパシティユニットが消費されるか。10000件入れたけど、1件も一致しない場合もキャパシティユニットは消費されるか
3.条件に一致するけどエラーが繰り返された場合の動き対象:Kinesis
内容:バッチ内でエラーが繰り返されたら、バッチはどうなるのか。Destinationsに不一致メッセージは移動するのか
環境構築
はい、それでは、ここからは色々試していくためにまずは環境準備ということで、今回は、まっさらなCloud9を用意しました。
手順は以下の記事を参照してみてください。
ということで、検証環境のAWS CLIとSAMのバージョンは以下で試しました。
$ sam --version;aws --version
SAM CLI, version 1.36.0
aws-cli/2.4.3 Python/3.8.8 Linux/4.14.252-195.483.amzn2.x86_64 exe/x86_64.amzn.2 prompt/off
そして、SAM initを実行しました。
sam init
$ sam init --name sam-lambda-eventfiltering --app-template hello-world --runtime python3.9 --architecture x86_64 -p Zip
Cloning from https://github.com/aws/aws-sam-cli-app-templates
-----------------------
Generating application:
-----------------------
Name: sam-lambda-eventfiltering
Runtime: python3.9
Architectures: x86_64
Dependency Manager: pip
Application Template: hello-world
Output Directory: .
Next application steps can be found in the README file at ./sam-lambda-eventfiltering/README.md
Commands you can use next
=========================
[*] Create pipeline: cd sam-lambda-eventfiltering && sam pipeline init --bootstrap
[*] Test Function in the Cloud: sam sync --stack-name {stack-name} --watch
treeをyumで導入して実行すると現在こんな感じでディレクトリが構成されています。
フォルダ構造
$ tree
.
├── events
│ └── event.json
├── hello_world
│ ├── app.py
│ ├── __init__.py
│ └── requirements.txt
├── __init__.py
├── README.md
├── template.yaml
└── tests
├── __init__.py
├── integration
│ ├── __init__.py
│ └── test_api_gateway.py
├── requirements.txt
└── unit
├── __init__.py
└── test_handler.py
5 directories, 13 files
こんな状態ではありますが、さっき実行したsam initの最後の部分に Commands you can use next が表示されてます。ここで紹介されているコマンドは、sam pipeline と言いましてCICD Pipelineを簡単に準備してくれる今年出た機能です。こちらは、コンテナ Lambda の CI/CD パイプラインを SAM Pipeline で作ろう !を参照してみてください。
さて、ローカルにアプリケーションを構築できる状態になったので、まずは、SQS/Kinesis Data StreamsとLambda関数を作りたいと思います。今回はこのテンプレートで構成しました。
SAMテンプレート
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: >
sam-lambda-eventfiltering
Globals:
Function:
Timeout: 20
Resources:
#### Message Producer Kinesis
KinesisClientFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: KinesisClient/
Handler: app.lambda_handler
Runtime: python3.9
Architectures:
- x86_64
Environment:
Variables:
STREAM_NAME: !Ref Stream
Policies:
- Version: '2012-10-17'
Statement:
- Effect: Allow
Action: kinesis:PutRecord
Resource:
- !GetAtt Stream.Arn
#### Message Producer SQS
SQSClientFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: SQSClient/
Handler: app.lambda_handler
Runtime: python3.9
Architectures:
- x86_64
Environment:
Variables:
QUEUE_URL: !Ref Queue
Policies:
- Version: '2012-10-17'
Statement:
- Effect: Allow
Action: sqs:SendMessage
Resource:
- !GetAtt Queue.Arn
#### Consumer Function SQS -
SQSFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: hello_world/
Handler: app.lambda_handler
Runtime: python3.9
Architectures:
- x86_64
Events:
SQSEvent:
Type: SQS
Properties:
Queue: !GetAtt Queue.Arn
BatchSize: 10
MaximumBatchingWindowInSeconds: 10
Enabled: True
FilterCriteria:
Filters:
- Pattern: '{"body": {"PRIORITY": [ { "numeric": [ "=", 101 ] } ]}}'
#### Event Source SQS
Queue:
Type: AWS::SQS::Queue
Properties:
RedrivePolicy:
deadLetterTargetArn: !GetAtt DeadLetterQueue.Arn
maxReceiveCount: 3
DeadLetterQueue:
Type: AWS::SQS::Queue
#### Consumer Function Kinesis
KinesisDataStreamsFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: KinesisFunction/
Handler: app.lambda_handler
Runtime: python3.9
Architectures:
- x86_64
Events:
KinesisEvent:
Type: Kinesis
Properties:
Stream: !GetAtt Stream.Arn
StartingPosition: TRIM_HORIZON
BatchSize: 100
MaximumBatchingWindowInSeconds: 100
MaximumRetryAttempts: 2
DestinationConfig:
OnFailure:
Destination: !GetAtt KinesisDestinationQueue.Arn
Enabled: True
FilterCriteria:
Filters:
- Pattern: '{"data": {"PRIORITY": [ { "numeric": [ ">", 100 ] } ]}}'
Policies:
- Version: '2012-10-17'
Statement:
- Effect: Allow
Action: sqs:SendMessage
Resource:
- !GetAtt KinesisDestinationQueue.Arn
-
KinesisDestinationQueue:
Type: AWS::SQS::Queue
#### Event Source Kinesis
Stream:
Type: AWS::Kinesis::Stream
Properties:
Name: LambdaEventFileringStream
RetentionPeriodHours: 24
ShardCount: 1
さて、上記のテンプレートで注目すべきは、Consumerとして実装したKinesis/SQS用の関数のEvents句です。それぞれ、SQS/Kinesisを指定していますが、以下のような条件式が定義されています。t同じメッセージをKinesisとSQSに投入していますが、データプロパティを示す属性が異なります。(dataとbody)
FilterCriteria:
Filters:
- Pattern: '{"data": {"PRIORITY": [ { "numeric": [ "<", 100 ] } ]}}'
FilterCriteria:
Filters:
- Pattern: '{"body": {"PRIORITY": [ { "numeric": [ "<", 100 ] } ]}}'
ちなみに、メッセージのProducerの関数でPutするメッセージは以下のような形です。つまり、上記条件式は、PRIORITYが100未満だったらバッチに加わることになります。各値はrandomで生成しています。
{
"EVENT_TIME": "2021-12-01T12:24:55.045103",
"ID": "ID-923760",
"PRICE": 87907,
"PRIORITY": 99
}
実験結果
1.基本動作確認として、Dropはどんな動きになるか目視したい(願望)
対象:SQS/Kinesis
内容:不一致なデータはどう処理されるのか確認する。
予想:スキップ?
期待:条件に一致するものは処理、しないものは放置。
方法:SQSの標準キュー/Kinesis Data Streamsのストリームに前述の形式のメッセージで、PRIORITYを1~10になるデータを数百件件投入。
適用するフィルタ条件式はこちら。
FilterCriteria:
Filters:
- Pattern: '{"data": {"PRIORITY": [ { "numeric": [ "=", 1 ] } ]}}'
結果:SQSとKinesisで動きが違う。
| 項目 | SQS | Kinesis |
|---|---|---|
| データの扱い | PRIPRITY=1のデータのみ処理された | PRIPRITY=1のデータのみ処理された |
| 不一致データの扱い | キューからメッセージを削除された | 該当のレコードをスキップして次に進んだ。もちろん、再利用、別プロセスによる処理も可能 |
| 推測 | DeleteMessageがされた | 全レコードGetRecordsでレコードが読み取られて進んだ |
| 考察 | 不一致データを一切処理しなくてよいなら、利用してもよい | 必要なデータだけを処理できて便利。 |
SQSの場合、メッセージが削除されてしまうので本当に不要なメッセージなのであれば、この機能が有効活用できますね。ただ、不要なメッセージは事前に送らないのがベストだなとは思います。また、SNS-SQS連携しているのであれば、冒頭に書いたSNSのSubscriptionのFilterを定義することで、そもそもSQSに入らないためそこで処理したいですね。注意点として、SNS のFilter Policyは、メッセージの属性に対して指定することができるという点で、今回のFilterとはFilteringする対象が異なる点は要注意です。
ということで、私が次に気になるのは、Kinesis!!!
Kinesis のバックエンドでレコードの内容に応じて、異なる複数の処理に分岐するような場合、今回のFilterが使えるんじゃないか?という点ですが、その際に気になるのが、キャパシティユニット。きっと、消費されるんだろうな~ということで動きを次の検証で確認したいと思います。(正式に消費されるかされないかは、AWSサポート等にご確認いただければ・・)
2.Kinesis Data Streamsで消費されるキャパシティユニット
対象:Kinesis
内容:Batchに入らない場合でもキャパシティユニットが消費されるか。数万件入れたけど、1件もフィルタ条件に一致しない場合もキャパシティユニットは消費される?
予想:消費される。
期待:消費されないなら、めちゃスゴイ。
方法:Kinesis Data Streamsのストリームに前述の形式のメッセージを数万件投入。
投入後にEventSource Mappingを一斉に有効化し、CloudWatch Metricsでメトリクスの推移を確認する。なお、ConsumerのLambda関数を(界王拳)10倍にして読取スロットリングが起きるかメトリクスで確認する。
EventSource Mappingの有効化は以下の Enabled: TrueをFalseなら無効、Trueなら有効で切り替えが可能。
KinesisDataStreamsFunction:
Type: AWS::Serverless::Function
Properties:
# (省略)
Events:
KinesisEvent:
Type: Kinesis
Properties:
# (省略)
Enabled: True
FilterCriteria:
Filters:
- Pattern: '{"data": {"PRIORITY": [ { "numeric": [ "<", 0 ] } ]}}'
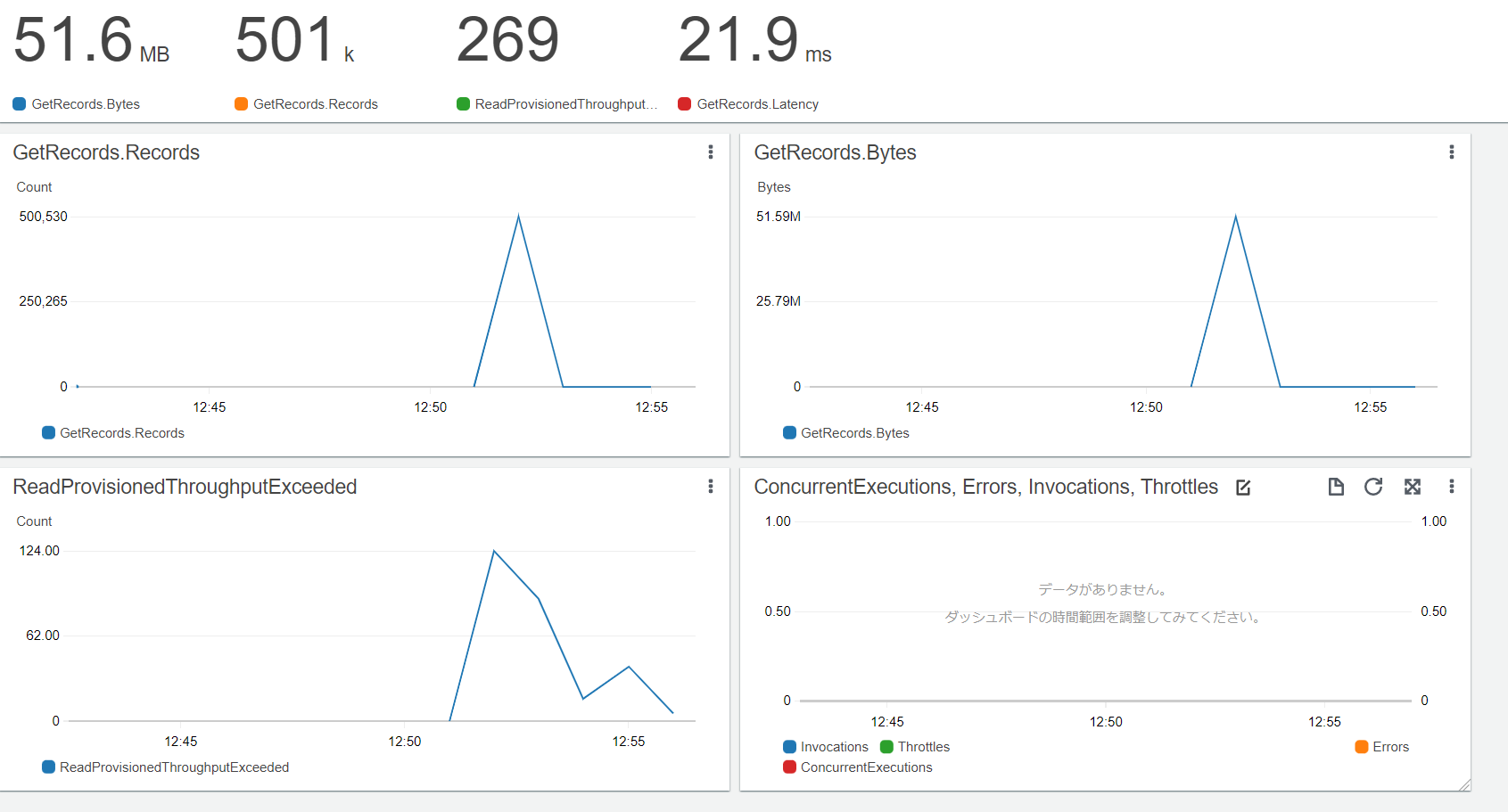
結果:Kinesisの読み取りでスロットリング起きたよ(想定通り。Lambdaがフィルタで判定するために読み取るからね)。Lambdaは1件も起動されてないよ(想定通り:条件に一致するメッセージは1件もないため)。画面の右下がLambdaのメトリクス。1件も起動されてないので何も出てこない。画像上部には、5分間で読み取ったデータ量も表示されており、ばっちり読み込まれてますね。ちなみに、読み込まれてることが確認できればスロットリングを起こす必要はないのですが、あえて起こしてみました。趣味です。
3.条件に一致するけどエラーが繰り返された場合の動き
対象:Kinesis
内容:バッチ内でエラーが繰り返されたら、バッチはどうなるのか。Destinationsに不一致メッセージは移動するのか
予想:移動しない。移動するのは、フィルタ条件に一致して繰り返し処理されたメッセージのみ
方法:Kinesis Data Streamsのストリームに前述の形式のメッセージを投入。ConsumerのLambdaで常にErrorになるように対応。Filterにマッチしたレコード以外のレコードが DLQDestinationに移動しているか確認
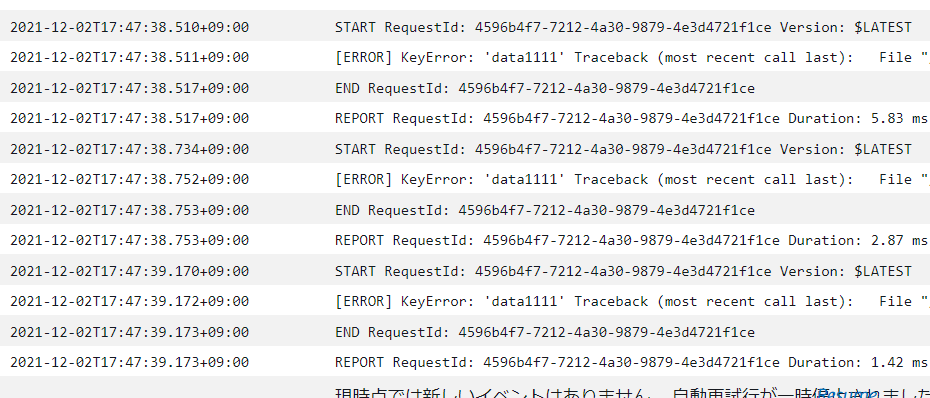
結果: フィルタ条件にマッチしたデータでLambdaがエラーと応答したデータのみ。
今回は、Filterの条件と一致するメッセージを1件、不一致のメッセージを10件投入して動作確認しました。
まず、ログデータ。メッセージの投入。12/02 17:17:41秒前後に投入しています。
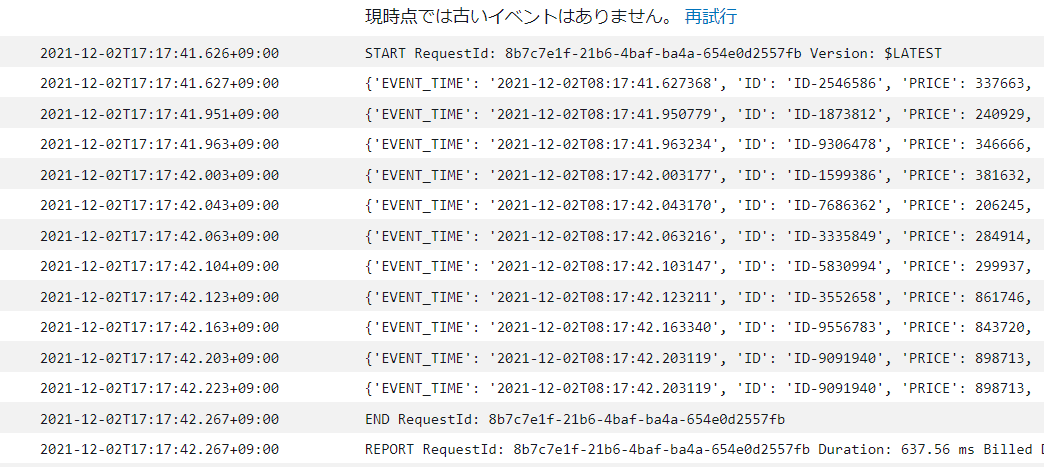
Concumer側のLambdaが動きました。。
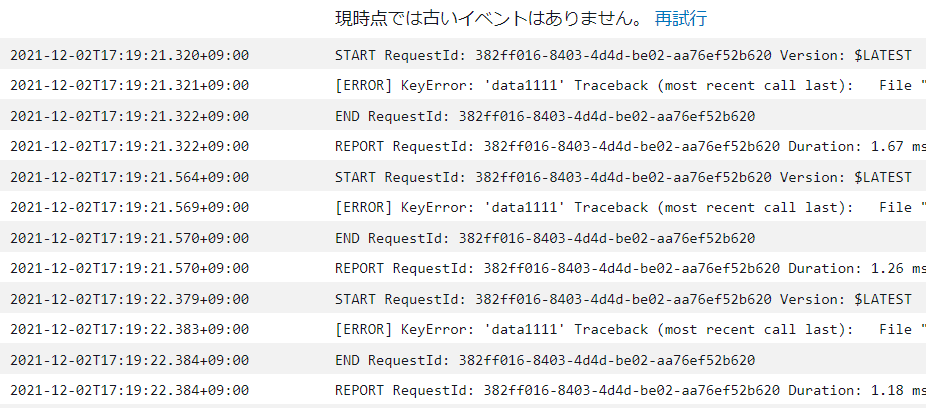
STARTを3回しています。が3回とも[ERROR]で終わってます。存在しないデータにアクセスしているためですね。
ここで、なぜ3回なのかというと、以下の設定をEventの定義にしていたため、初回動いた後、2回リトライをしたわけです。そして、2回リトライした後は、Dead Letter Queue に移動しています。
MaximumRetryAttempts: 2
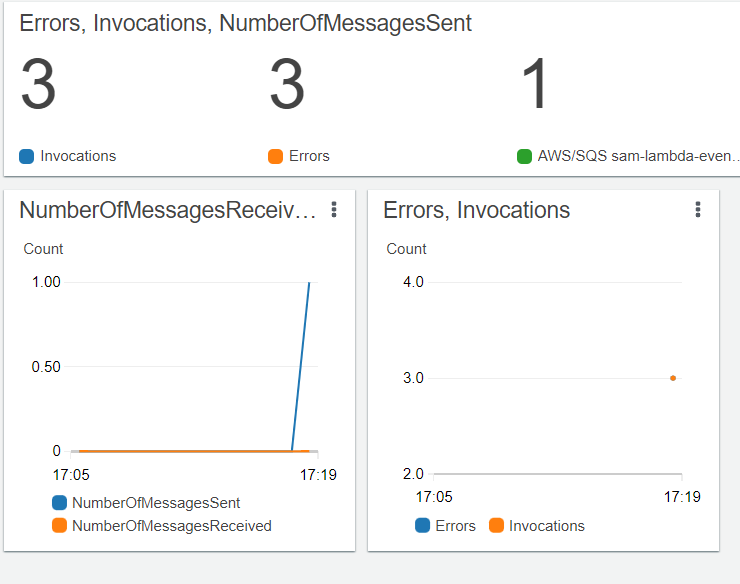
ちゃんとキューには、1件だけメッセージがあります。
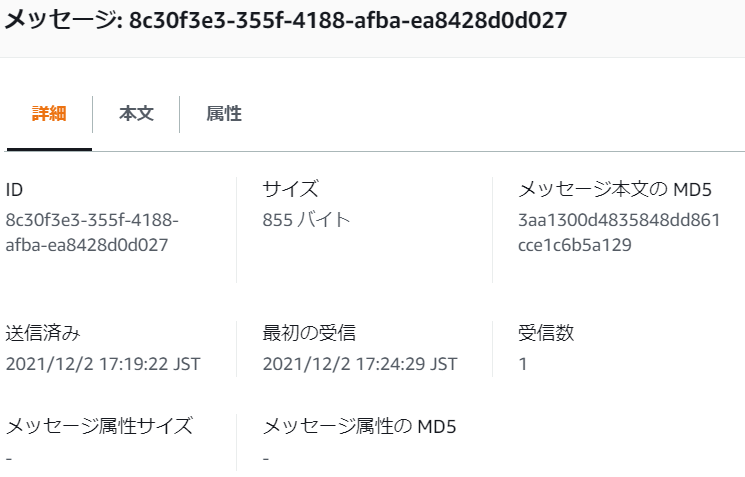
{"requestContext":{
"requestId":"382ff016-8403-4d4d-be02-aa76ef52b620",
"functionArn":"arn:aws:lambda:ap-northeast-1:123456789012:function:sam-lambda-eventfiltering-KinesisDataStreamsFuncti-1Q3pbmbZ7OWW",
"condition":"RetryAttemptsExhausted",
"approximateInvokeCount":3
},
"responseContext":{
"statusCode":200,
"executedVersion":"$LATEST",
"functionError":"Unhandled"
},
"version":"1.0",
"timestamp":"2021-12-02T08:19:22.397Z",
"KinesisBatchInfo":{
"shardId":"shardId-000000000000",
"startSequenceNumber":"49624442129468525601182640052593233276102295172440653826",
"endSequenceNumber":"49624442129468525601182640052593233276102295172440653826",
"approximateArrivalOfFirstRecord":"2021-12-02T08:17:42.226Z",
"approximateArrivalOfLastRecord":"2021-12-02T08:17:42.226Z",
"batchSize":1,
"streamArn":"arn:aws:kinesis:ap-northeast-1:123456789012:stream/LambdaEventFileringStream"}}
上記のデータより、最初に到着したおよその時刻は、approximateArrivalOfFirstRecord":"2021-12-02T08:17:42.226Z"、つまり、Producerでメッセージを送信した時間であり、"timestamp":"2021-12-02T08:19:22.397Z"から初回のエラー発生後2回目を終えたこの時間に、DLQDestinationで指定したSQSのキューに自動で移動したと判断でき、特に違和感はないです。
さて、既にお気づきかもしれませんが、ProducerがキューにメッセージをPutしてから、Consumerが処理を開始するまでに、100秒の差があります。これは何か?それは、Eventに定義した2つの属性が関わっています。
BatchSize: 100
MaximumBatchingWindowInSeconds: 100
これは、以下の二つのOr条件として定義しているものです
- バッチのサイズが100になったら起動してね
- 100秒待ってもバッチがいっぱいにならなかったら起動してね。
今回は処理対象のメッセージが1件だったので、BatchSizeを満たすことができず、MaximumBatchingWindowInSecondsである100秒間、待っていました。
ということで、処理対象のメッセージが10件、BatchSizeも10だったら起動時間がどうなるのか最後に試したいと思います。
BatchSize: 10
MaximumBatchingWindowInSeconds: 10
MaximumRetryAttempts: 2
Producerが一致するデータを10件投入。(1件不一致)
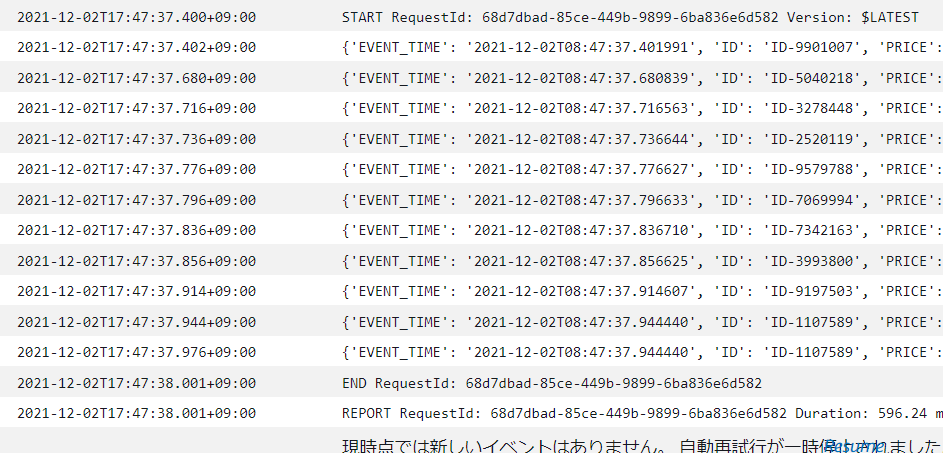
1秒後には、Consumerが起動
終わりに
Filtering機能、簡単に定義ができ、自身が処理すべきメッセージだけを処理することが可能です。とはいえ、EventSource側には、読み取りキャパシティユニットの消費やAPIコールが発生するわけですから、不要なメッセージを入れないに越したことはありませんが、Consumer側でフィルタリングが必要な場合には簡単に実装ができてとても良いなと思いました。