この記事は、NTTテクノクロス Advent Calendar 2021 の8日目です。
こんにちは、NTTテクノクロスの堀江です。普段はAWSやAzure上でのシステム設計・構築や調査検証系の案件を担当しています。
はじめに
本記事では、AWSが公式に公開している分散負荷テストソリューションの使い方に関するノウハウ、およびそれを使用してAWS上で負荷試験を実施する際の注意点を述べていきます。
※「分散負荷テスト(Distributed Load Testing)」だと長いので、以降は「dlt」と呼称します。
今年、とある案件でAWS上でのWEBアプリケーション(WEB層にALB、アプリ層にEC2のASGという一般的な構成)の性能試験を実施する機会があり、アプリケーションにリクエスト負荷を掛ける為のソリューションとして、dltを使用してみました。全体的に非常に便利なソリューションでしたが、思い通りの試験シナリオと性能を実現するために詰まったり試行錯誤したりした点もありました。本記事では、それらを踏まえたdltの使い方に関するノウハウと、AWS上で性能試験を実施する上での注意点を述べていきます。
本記事で扱うdltは、2021年9月30日にリリースされたv2.00の仕様に準拠しています。
AWSの分散負荷テストソリューションとは
dltの特徴は大きく以下の3点です。
- 負荷を発生させるためのクライアントをサーバレスな構成で管理可能
- GUIのテスト管理コンソール上から試験を作成/実行/確認することが可能
- Jmeterのスクリプトを使用して、テストの挙動やロギング設定をカスタマイズ可能
dltの全体的なアーキテクチャーは下図の通りです。事前の作業も特に不要で、全てのリソースを、公式が提供しているCloudFormationテンプレート一枚でデプロイ可能です。
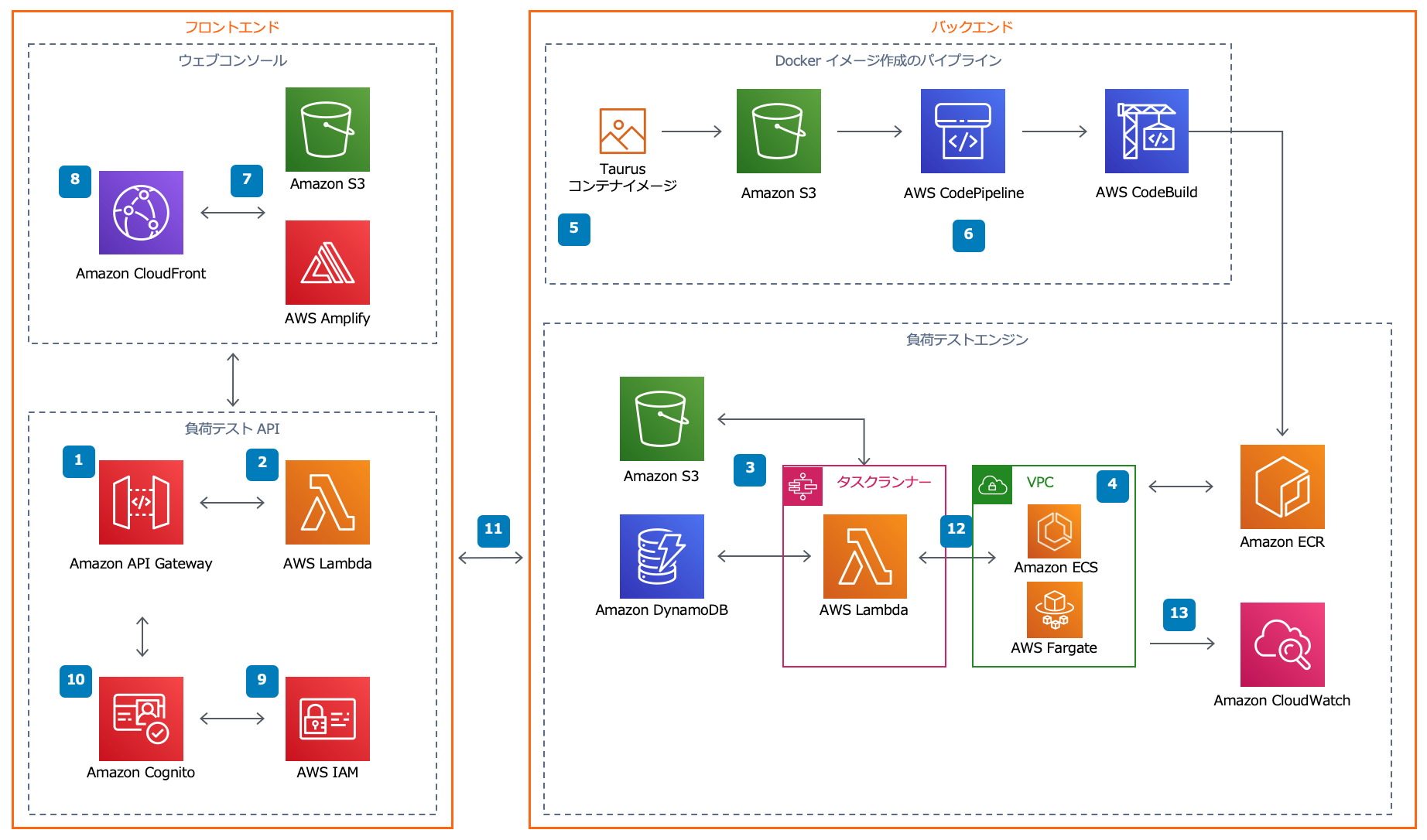
画像は公式サイトから拝借
https://aws.amazon.com/jp/solutions/implementations/distributed-load-testing-on-aws/
-
フロントエンド
- Amplifyによって管理コンソールアプリケーション(静的サイト)がデプロイされます。
- コンソール上から、負荷テストAPIを介してテストの作成・実行を行うことができます。
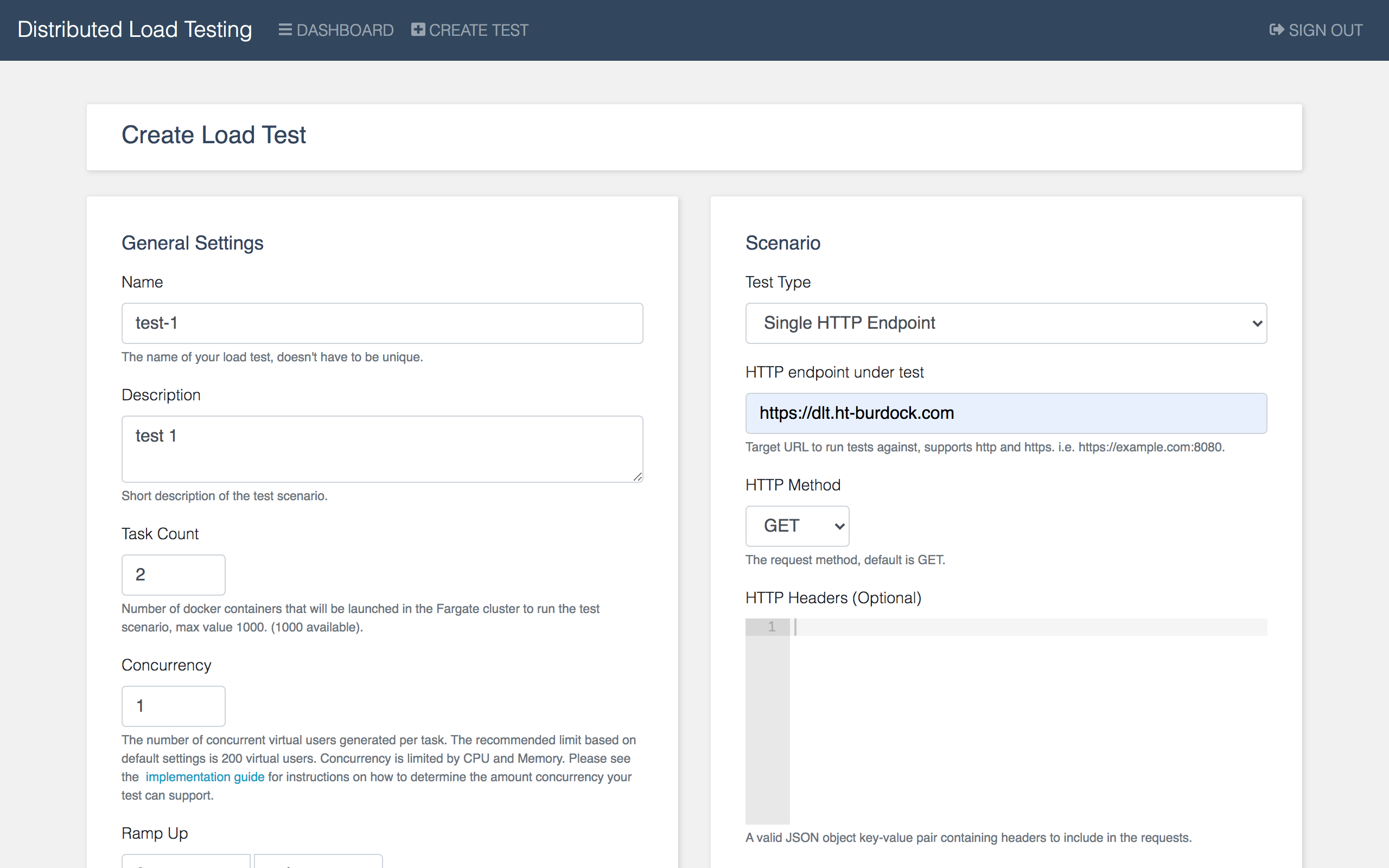
- コンソールへのログインおよびAPIの使用はCognitoによる認証で守られています。
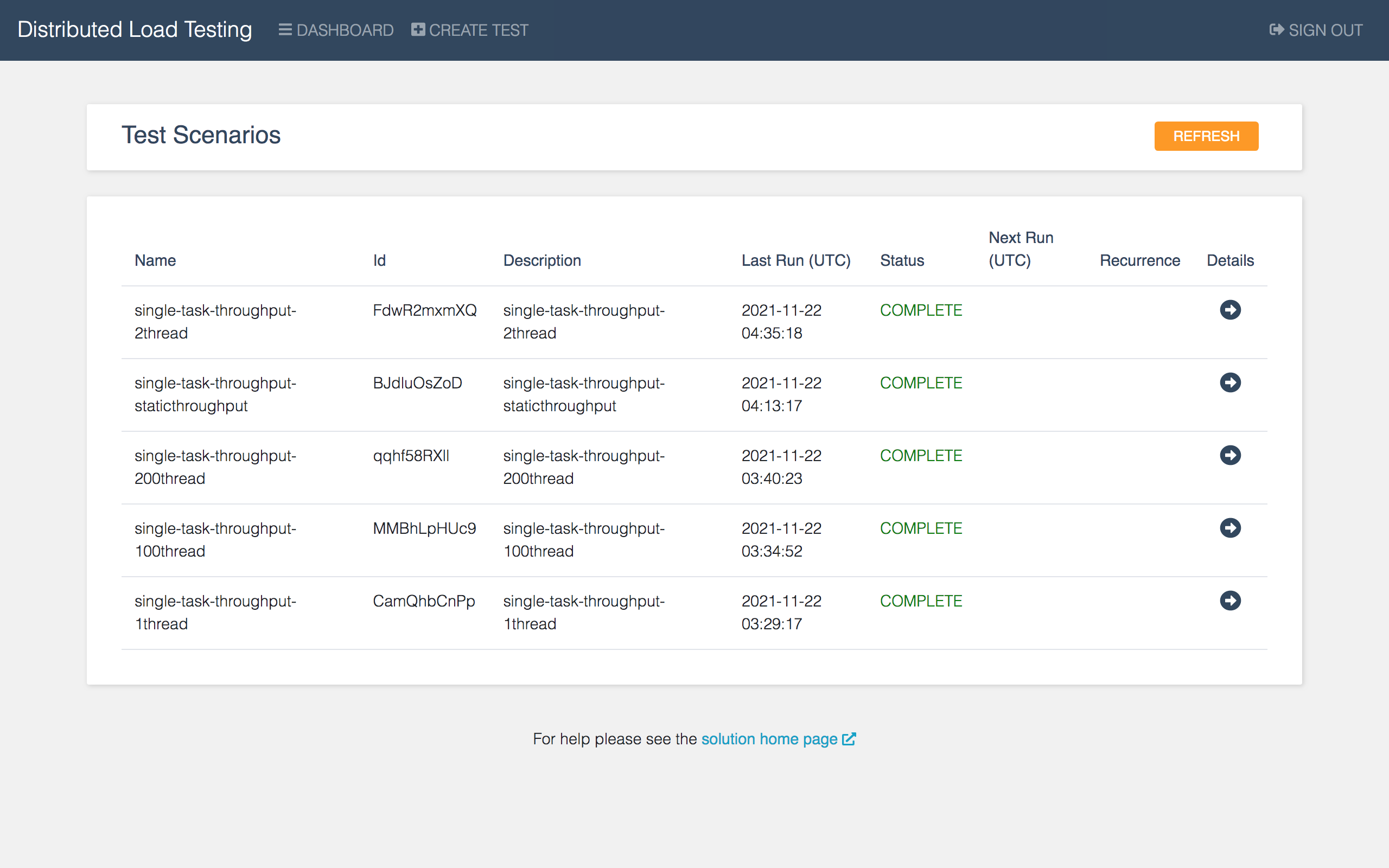
- テストが完了すると、下図のようにグラフィカルかつ直感的な結果を確認することが可能です。

- Amplifyによって管理コンソールアプリケーション(静的サイト)がデプロイされます。
-
バックエンド
- テストの実行がリクエストされると、指定した数・設定のECS Fargateのタスクが負荷クライアントとして起動されます。
- 自分のアカウントでは、デフォルトで最大50までタスクを起動することが可能でした(デフォルトの上限数はアカウント毎に異なっている可能性あり)。後述するように上限緩和申請を行えば最大1000まで増加可能なようです。また、各タスクごとにさらに並行数を設定することが可能です。(推奨されている最大数は200)
- 最大数百タスクの起動・停止に関するオーケストレーションはStep FunctionsとLambdaが担当してくれます。
dltを使用することで、金銭的・作業的コストを抑えつつ、アプリケーションに対して手軽に大規模な性能試験を実施することができます。
dltを使用した負荷試験実施時の注意点
上記の通り、非常に便利なdltですが、AWS上で実際に負荷試験を行う際にはいくつか注意すべき点、事前に確認しておくべき点がありました。(何点かはdltと無関係ですが、)具体的には以下の通りです。
- AWSのテストポリシーを照会すること
- AWSのサービスクォータを確認すること
- 負荷テストツールの性能を把握すること
- ネットワークの経路には注意すること
- ALBの性能を把握しておくこと
AWSのテストポリシーを照会すること
AWS上のリソースに対してネットワーク負荷テストを実行する際に、ユーザが遵守すべきポリシーが公式に定められています。
負荷試験時に想定されるネットワークのトラフィック量がこのポリシーに違反していないかを事前に確認し、必要があれば事前にAWSに相談する必要があります。
AWSのサービスクォータを確認すること
例えばEC2インスタンスをバックエンドサーバとして使用しているアプリケーションに対してdltを使用して負荷試験を行う場合、事前に最低でも以下のサービスクォータの値を確認し、必要であれば早めに上限緩和申請を行っておくのが良いでしょう。
-
「Running On-Demand All Standard (A, C, D, H, I, M, R, T, Z) instances」といった、vCPU数に関するクォータ
- 自分が使用していた環境では、このクォータの設定値が36vCPUしかなく、(かつ他のアプリケーションとの共用環境であったため、)いざ試験を行おうとしても必要な台数のバックエンドサーバを起動することができませんでした。(上限緩和申請が通るまで数時間試験が停滞)
-
Fargate On-Demand resource count
- 自分が使用していた環境では、このクォータの設定値が50でした。しかしそれでは計画していた量の負荷を発生させることができず、上限緩和申請が必要となりました。(上限緩和申請が通るまで数日間試験が停滞)
- 特にハマったのは、Service Quotasのダッシュボード上では「適用されたクォータ値」が100となっていたのに、実際には50までしかタスクを作成できない点でした。AWSではService Quotasのダッシュボード上に表示される「適用されたクォータ値」と実際に適用されているクォータ値が乖離していることが偶にあるので、しっかり事前に動確までしておく必要がありました。
負荷テストツールの性能を把握すること
負荷試験の結果が芳しくない場合、それがアプリケーション(サーバ)側の問題なのか、テストツール(クライアント)側の問題なのか、もしくはそれ以外(ネットワークやロードバランサ)の問題なのかの切り分けができていることが重要です。dltに関しても、1Fargateタスク(クライアント)あたりの負荷性能の限界を事前に把握しておくことが大事です。
タスクあたりの負荷性能(ここでは1秒間に可能なリクエスト数とします)を左右する要因は以下の2点です。
- タスク内の並行数
- タスクに割り当てられるvCPU数
タスクの並行数は、テスト作成時に1~200の値で自由に設定することが可能です。
タスクに割り当てられるvCPU数は、デフォルトで2048となっています。この設定値はパラメータ化されていませんが、以下のようにCloudFormationテンプレートを修正することで、上限一杯(4096)までスケールアップ可能です。
# ... 省略
DLTEcsDLTTaskDefinition6BFC2400:
Type: AWS::ECS::TaskDefinition
Properties:
ContainerDefinitions:
- Essential: true
Image: public.ecr.aws/aws-solutions/distributed-load-testing-on-aws-load-tester:v2.0.0
LogConfiguration:
LogDriver: awslogs
Options:
awslogs-group:
Ref: DLTEcsDLTCloudWatchLogsGroupFE9EC144
awslogs-stream-prefix: load-testing
awslogs-region:
Ref: AWS::Region
# Memory: 4096
Memory: 8192
Name:
Fn::Join:
- ""
- - Ref: AWS::StackName
- -load-tester
# Cpu: "2048"
Cpu: "4096"
ExecutionRoleArn:
Fn::GetAtt:
- DLTEcsDLTTaskExecutionRoleDE668717
- Arn
# Memory: "4096"
Memory: "8192"
NetworkMode: awsvpc
RequiresCompatibilities:
- FARGATE
TaskRoleArn:
Fn::GetAtt:
- DLTEcsDLTTaskExecutionRoleDE668717
- Arn
# ... 省略
自分が試しに測定してみた限り、並行数とvCPU数ごとのタスクの負荷性能の目安はおおよそ以下の通りに想定しておくと良さそうです。
| vCPU数\並行数 | 1 | 100 | 200 |
|---|---|---|---|
| 2048 | 50req/s | 150req/s | 150req/s |
| 4096 | 100req/s | 300req/s | 300req/s |
| ※t2.mediumインスタンス4台(nginxのウェルカムページをレスポンスするだけ)をターゲットに持つALBに対する負荷結果を基にしています。 |
上記より、例えば並行数100、vCPU数2048で負荷を掛けているのにアプリケーションが毎秒100リクエスト程度しか捌けていない場合は、アプリケーション側にボトルネックがある可能性が高いです。
一方で、秒間1000リクエストの負荷をかけたいような場合には、並行数100、vCPU数2048のタスクを最低10個は用意する必要がありそうです。
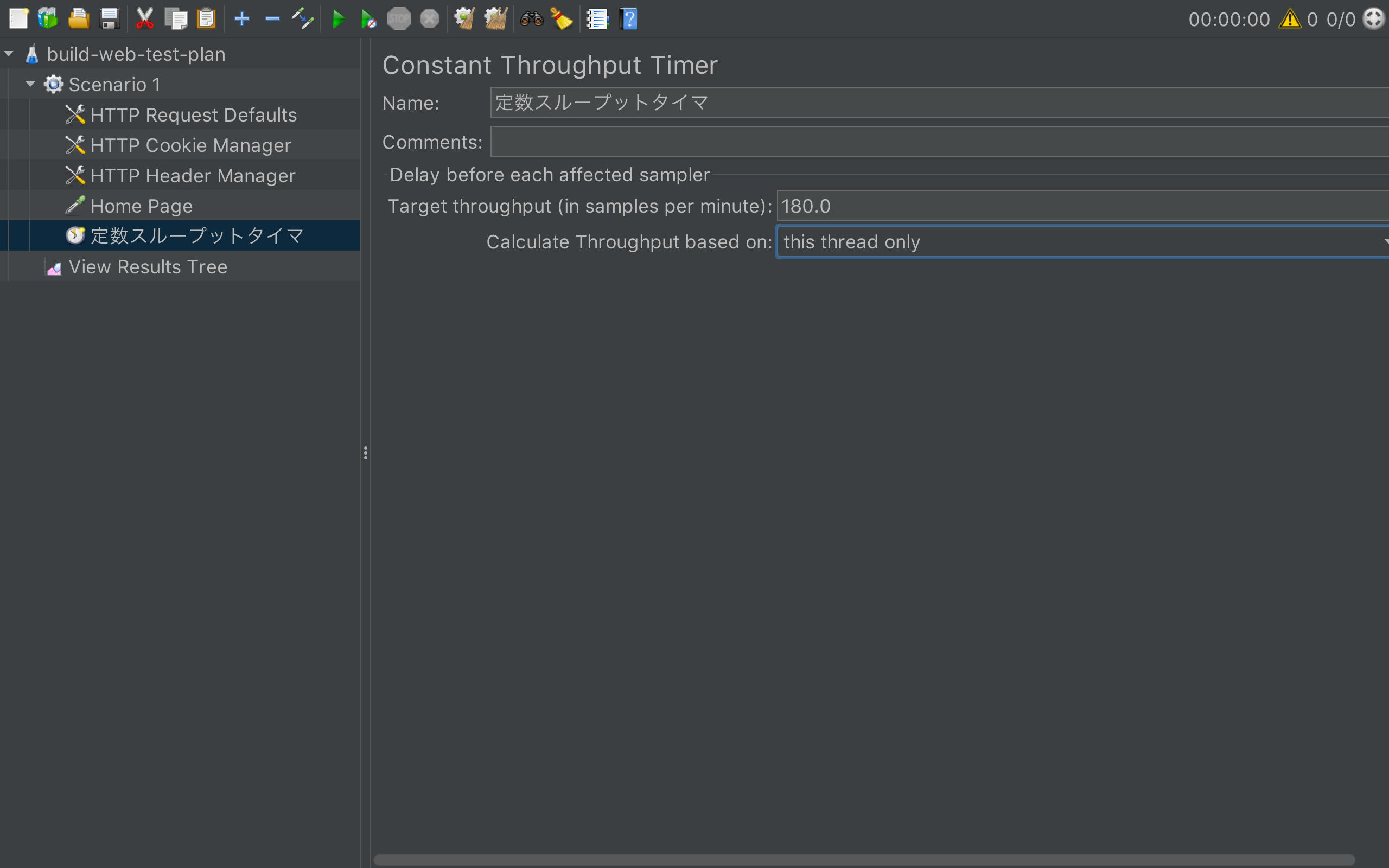
(補足)dltで秒間リクエスト数を特定の値に固定する方法
上記の性能目安から、例えば並行数100、vCPU数2048のタスクを5つ作成すれば、アプリケーションに掛かる負荷は概ね毎秒750リクエスト前後になりそうです。しかし、もっと正確に毎秒リクエスト数を固定したいような場合には、Jmeterのシナリオファイルを使用する必要があります。
Jmeterのシナリオには、ConstantThroughputTimerという設定項目があり、クライアントごとの毎分あたりのリクエスト数をコントロールしてくれます。
最終的に実現される秒間リクエスト数は、(ConstantThroughputTimerの設定値 / 60s) * タスク数 * タスクあたりの並行数となります。
例えば下図のシナリオファイルでは毎分あたりのスループットを180にしているので、3並行のタスクを10個作成すれば、トータルでアプリケーションに掛かる秒間リクエスト数は(180 / 60) * 3 * 10 = 90となります。
ネットワークの経路には注意すること
dltのFargateタスク(クライアント)のリクエストを、Nat Gateway経由でアプリケーションにルーティングする際には負荷量が制限されることに注意しましょう。
そもそも自分の試験実施時にNat Gatewayを経由させたかった理由ですが、アプリケーション(のALB)にアクセス可能なIPアドレスをセキュリティグループで制限したかったためでした。通常であればdltはテストが実行されるたび、Fargateタスク毎ににその都度パブリックIPアドレスが払い出されるため、アプリケーションのALBのセキュリティグループを0.0.0.0/0でオープンにしておく必要がありました。そこでFargateタスクをプライベートサブネット上に起動させ、Nat Gatewayを経由してアプリケーションにリクエストするように修正すれば、Nat GatewayにアタッチされたElastic IPアドレス以外からのALBへのリクエストをセキュリティグループで制限することが出来ます。
上記の修正自体はそれほど難しくありません。具体的には、Nat Gatewayへのルーティングが設定された2つのプライベートサブネットを含むVPCを予め作成しておき、dltのスタック作成時に設定可能なパラメータExistingVPCId,ExistingSubnetA,ExistingSubnetBにそれぞれ値を設定すれば可能です。
しかし上述の設定を実施した上で大規模な負荷を掛けようとすると、以下に記載されているようなNAT Gateway側の性能限界に引っかかってしまいます。
NAT ゲートウェイは送信先別に最大 55,000 の同時接続をサポートできます。この制限は、単一の送信先に 1 秒あたり約 900 の接続 (1 分あたり約 55,000 の接続) を作成する場合にも適用されます。送信先 IP アドレス、送信先ポート、またはプロトコル (TCP/UDP/ICMP) が変更された場合は、追加の 55,000 の接続を作成できます。55,000 を超える接続の場合は、ポートの割り当てエラーによる接続エラーの可能性が高くなります。
https://docs.aws.amazon.com/ja_jp/vpc/latest/userguide/vpc-nat-gateway.html#nat-gateway-basics
自分の場合は秒間10000リクエストの負荷を掛けようとしたものの、上記の制限に引っかかって期待通りのスループットが出ず、解析に丸一日を要しました。
少ないリクエストまでであれば問題はないかもしれませんが、大規模な負荷をアプリケーションに掛けたい場合は、Nat Gatewayは使用すべきではないでしょう。(自分の場合は、大規模負荷試験の際は一時的に0.0.0.0/0を許可する必要性を顧客に説いて納得してもらいました。)
ALBの性能を把握しておくこと
例えば、Elastic Load Balancingの特徴を紹介している以下の公式ページでは、下記の様にロードバランサーの高スループット性を説明しています。
Elastic Load Balancing は、トラフィックが増大した場合でも処理できるよう設計されており、1 秒間に数百万件ものリクエストでも負荷分散できます。また、突発的で不安定なトラフィックパターンにも対処できます。
この記述だけを読めば、ELB(ALB)は暖気申請などせずとも、突発的で大量の(毎秒数千~数万件の)リクエストも簡単に捌くことが可能で、負荷試験時のボトルネックにはなり得ないと判断出来るかも知れません。恥ずかしながら自分はそうでした。
しかし実際に(暖気申請無しで)ALBとそのバックエンドサーバ群に対して高負荷試験を実施してみると、事前の想像とは大分異なるALBの挙動を確認することが出来ました。
以下は、新規構築直後のALBに対してdltから秒間10000リクエスト相当(※)の負荷を60分間掛けた際にCloudWatchで記録された、ALBのRequestCountメトリクスの推移です。
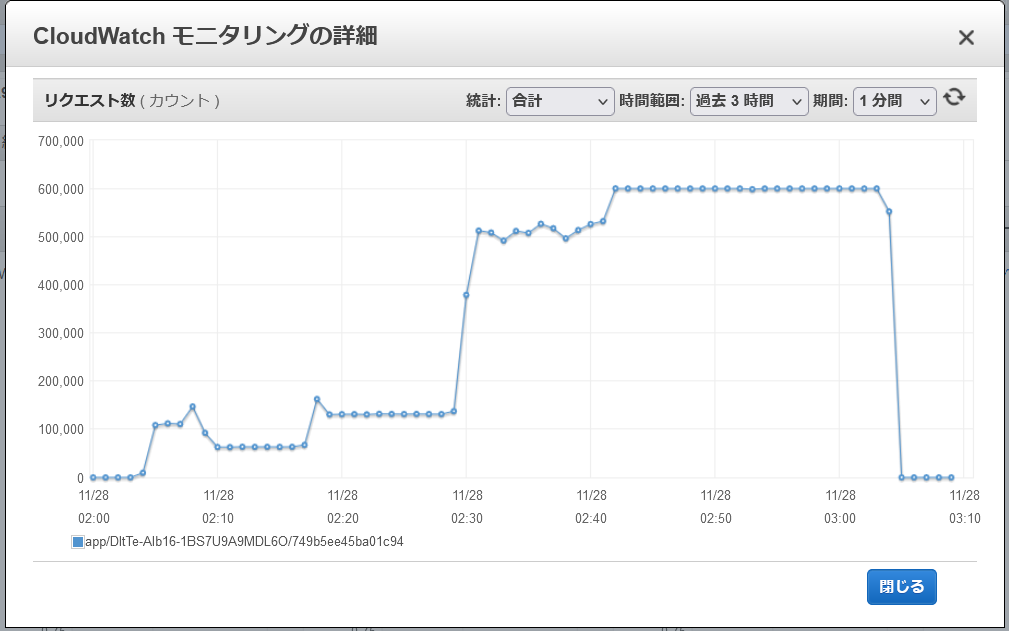
※JmeterシナリオのConstantThroughputTimerを120に設定し、(毎分120リクエスト / 60秒) * 50タスク * 100並行 = 毎秒10000リクエスト(= 毎分600000リクエスト)とした。
この結果から、ALBのスループットは約10分間隔で段階的にスケーリングされる、ということが言えそうです。(構築直後のALBが捌けるのは秒間2000リクエスト前後。秒間10000リクエストを捌けるようになるまでに約30~40分程度掛かる。)
なお、試しに上記の1時間後に再度同じALBに同じ負荷を掛けてみると、今度は最初から秒間10000リクエスト捌けているようでした。スケーリング状況は暫くの間(少なくとも1時間は)継続するようです。
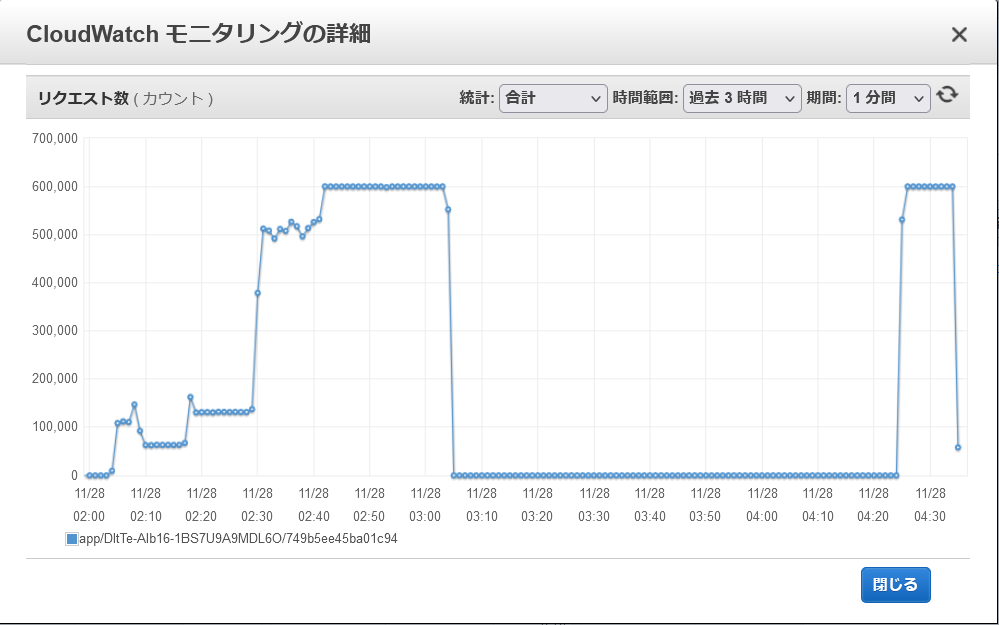
ALBのスループットのスケーリングに関する仕様は明らかにされていないので、この挙動の再現性や普遍性を保証することは出来ません。しかし実際にALBを使用して試験を行う際には(そして実際に本番運用する際には)この挙動のことを覚えておいて損は無いでしょう。
(補足)ALBの暖気申請について
(多くのAWS技術者は資格試験問題等を通してご存知かと思いますが、)ALBの暖気申請をAWSサポートに対して行うことで、上記のような段階的なスケーリングに時間を掛けず、いきなり高スループットを実現出来るとされています。
ただ、暖気申請に関しては公式の情報が殆ど存在しないのですよね。本当に利用可能なのか、個人的には都市伝説めいた存在に感じてしまいます。
まとめ
AWSではdltを使用することで、簡単に高負荷の性能試験を実施することが出来ます。一方で、dltやALBのようなマネージドサービスの性能限界や挙動を正しく把握していないと、期待通りの性能が得られなかったり、解析で思わぬドツボにはまってしまったりする可能性もあります。本記事で挙げた内容がそういったトラブルを回避する助けになればと思います。
明日のNTTテクノクロス Advent Calendar 2021は、 @thetakei さんによる、標準化活動に関する記事です。
お楽しみに!