Step Functions触り始めて2日目の人です。
今年の仕事も締まったということで、自分の勉強がてらStep Functionsを使ってみたくてやってみた話です。エラー処理だとかめちゃめちゃ度外視していますが、とりあえず動いたので…最初の一歩としてまあいいかなと…
最終的にやったこと
最終的に何をやったかというと、inputにタイトルの文言を送ると、
{
"input": "とあるエンジニアのアプリケーション開発の進捗状況"
}
Bedrockで簡単なストーリーを作って、そのストーリをもとにTitanとPollyで画像と音声を作って動画にするという感じです。Step Functionsはこんな感じ。
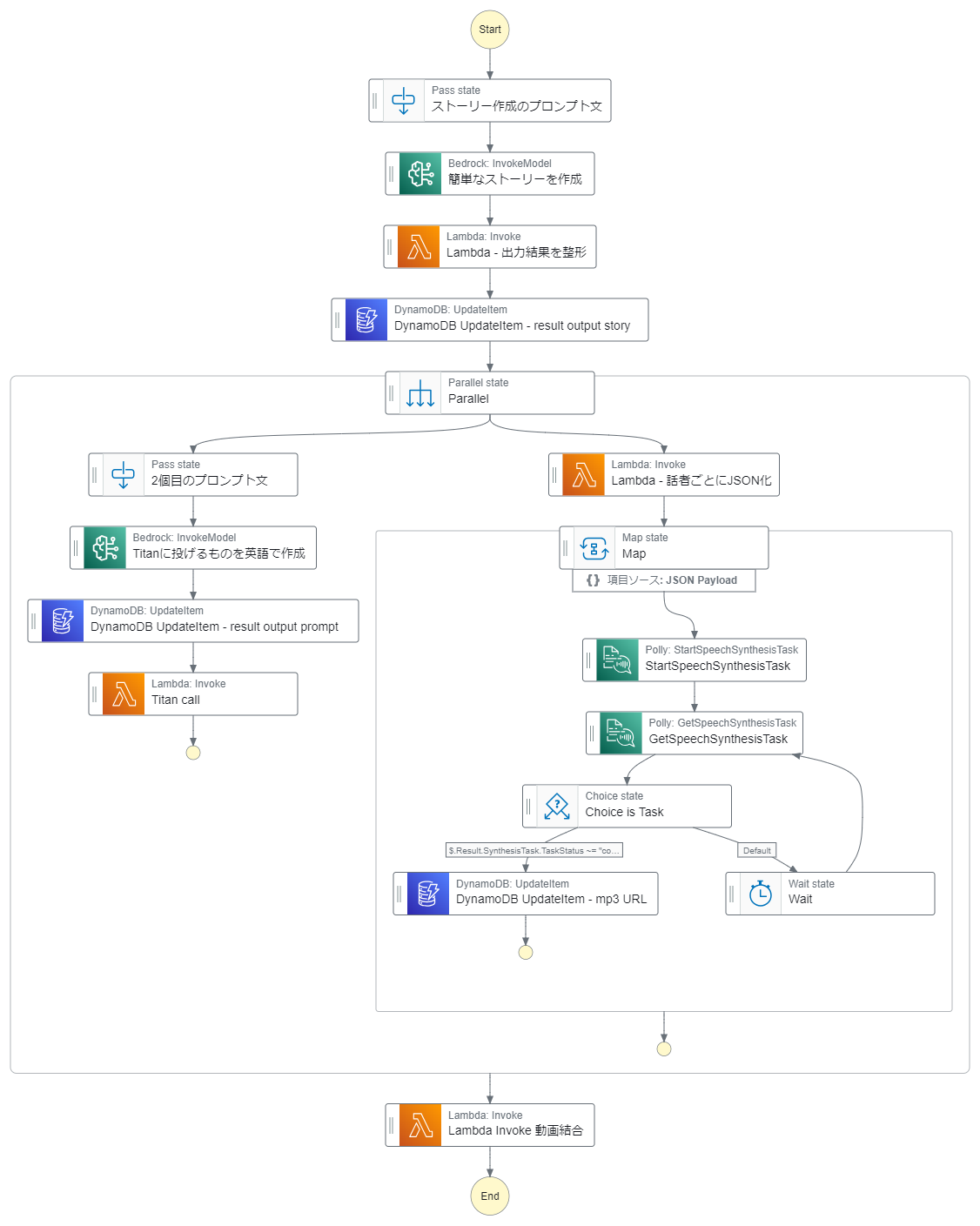
使ったサービス
・Step Functions
・Bedrock Claude v2
・Bedrock Titan Image Generator
・Lambda
・Polly
・DynamoDB
データの流れ
1.Bedrockでストーリーを作って整形する[Bedrcok -> Lambda]
inputでもらったタイトルに対して、「ストーリー作ってね。」とか「口語体でお願い。」「ストーリーは<text></text>で囲んでね。」とかを付与します。そのあとにBedrockに対して、投げ込んでます。
{
"result_one": " <text>\nA:「やあ、久しぶり!プログラミングの進捗どう?」\n\nB:「俺のアプリ開発は思ったよりも遅れてるよ。要件定義から始めたのに、まだ設計段階だ」\n\nA:「えー、そんなに遅れてるの?どうして?」\n\nB:「なんでもないんだけど、なかなか設計が煮詰まらない。アーキテクチャ設計で悩んでる最中」 \n\nA:「そうなんだ。確かにアーキテクチャの設計は大変だよね。俺も同じこと悩んだことある」\n\nB:「あー、助かる。アドバイスくれる?」\n\nA:「うん。まずは最小構成でプロトタイプ作って、動作確認しながら徐々にブラッシュアップしていくのがオススメだと思う。ぜひ試してみるといいよ」\n\nB:「なるほど、そうすることで設計ミスも減らせそうだ。アドバイスありがとう!」 \n\nA:「いいよ、頑張って!」\n</text>"
}
Bedrockから降りてきた文章をLambdaでタグの中身だけ抽出します。ここでtextタグの中身だけ抽出しているのは、「はい、簡単なストーリーを作成します。」とか「以上が、私の考えたストーリーです。問題ありませんでしょうか。」とか律儀に返してくることがあるので、それを取り除くためにやってます。
{
"result_one": "\nA:「やあ、久しぶり!プログラミングの進捗どう?」\n\nB:「俺のアプリ開発は思ったよりも遅れてるよ。要件定義から始めたのに、まだ設計段階だ」\n\nA:「えー、そんなに遅れてるの?どうして?」\n\nB:「なんでもないんだけど、なかなか設計が煮詰まらない。アーキテクチャ設計で悩んでる最中」 \n\nA:「そうなんだ。確かにアーキテクチャの設計は大変だよね。俺も同じこと悩んだことある」\n\nB:「あー、助かる。アドバイスくれる?」\n\nA:「うん。まずは最小構成でプロトタイプ作って、動作確認しながら徐々にブラッシュアップしていくのがオススメだと思う。ぜひ試してみるといいよ」\n\nB:「なるほど、そうすることで設計ミスも減らせそうだ。アドバイスありがとう!」 \n\nA:「いいよ、頑張って!」\n"
}
2-A. BedrockでTitanに投げ込む用のプロンプトを作って、Titanで画像を作成する[Bedrock→Lambda(Bedrock)]
受け取ったストーリーに、「生成AIに投げ込む用のプロンプトを英語でくれ」とか「Jsonでくれ」とか付け加えて、Bedrockに投げ込むと、
{
"result_two": " Here are the prompts in English to generate images for the above story:\n\n{\n\"prompts\":[\n\"Two Japanese male friends talking\",\n\"One friend asking the other about the progress on his programming project\", \n\"The other friend saying his app development is delayed from initial planning\",\n\"He is still at the design phase even though he started with requirements definition\", \n\"The first friend saying he understands it's hard, he also struggled with architecture design before\",\n\"The second friend asking for advice on architecture design\",\n\"The first friend advising to start with minimum prototype first and validate\", \n\"He suggests gradually enhancing the prototype based on testing\",\n\"The second friend agreeing it's a good idea to reduce design mistakes\",\n\"He thanks the first friend for the useful advice\",\n\"The first friend says no problem and cheers him on\"\n]\n}"
}
こんな感じで返ってくるので、あとはLambdaにつないで、プロンプト一個ずつTitanで画像を作成します。
#Json部分だけ抽出
input_string = event["result"]
json_start_index = input_string.find('{')
json_end_index = input_string.rfind('}') + 1
json_data = input_string[json_start_index:json_end_index]
data_dict = json.loads(json_data)
# promptsに対応する値を配列に格納
prompts_array = data_dict['prompts']
# インデックス番号を使ってTitan_requests()を呼び出す
for idx, prompt in enumerate(prompts_array):
formatted_idx = '{:02d}'.format(idx)
titan_requests(prompt, str(formatted_idx))
最初はStep FunctionsでBedrockのtitan-image-generator使えんじゃん!みたいに意気揚々とやってみたんですが、出力の結果がStep FunctionsのPayloadの上限を超えるっぽくて、エラーが出てしまって…なにか方法があるんですかね…
今回は、Jsonの処理だとか諸々あったのでLambdaで解決しております。
def titan_requests(prompt,index):
body = json.dumps(
{
"taskType": "TEXT_IMAGE",
"textToImageParams": {
"text":prompt
},
"imageGenerationConfig": {
"numberOfImages": 1,
"quality": "standard",
"height": 512,
"width": 512,
"cfgScale": 8.0,
"seed": 0
}
})
response = bedrock_runtime.invoke_model(
body=body,
modelId="amazon.titan-image-generator-v1",
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response.get("body").read())
images = [Image.open(BytesIO(base64.b64decode(base64_image))) for base64_image in response_body.get("images")]
生成した画像をS3に保存します。
2-B. Amazon Pollyでストーリーの音声を作成する。[Lambda → Polly]
上位から受け取った結果を、Step Functionsのmapで回したいのでLambdaでJsonの形に整形します。
{
"result": [
{
"line_number": "01",
"comment": "やあ、久しぶり!プログラミングの進捗どう?",
"speaker": "Takumi"
},
{
"line_number": "02",
"comment": "俺のアプリ開発は思ったよりも遅れてるよ。要件定義から始めたのに、まだ設計段階だ",
"speaker": "Mizuki"
},
{
"line_number": "03",
"comment": "えー、そんなに遅れてるの?どうして?",
"speaker": "Takumi"
},
…略…
}
整形した結果をmapを使って、一つずつPollyに投げて音声を作成します。
{
"line_number": "01",
"comment": "やあ、久しぶり!プログラミングの進捗どう?",
"speaker": "Takumi"
}
{
"OutputFormat": "mp3",
"OutputS3BucketName": "hogehoge",
"OutputS3KeyPrefix.$": "States.Format('mp3/{}_',$.line_number)",
"Text.$": "$.comment",
"VoiceId.$": "$.speaker"
}
mapを使ってみたかったので無駄に男女で交互に読ませてます。
3. 画像と音声をLambdaで結合する
あとは、生成した画像と音声を一つずつ結合して、最後に全部をがっちゃんこしてます。
出力結果
ポリシーに引っかかる文章が来たら、怒られてエラーが出ることもあります。
エラーが出た時の文章:
「One reminds the other they should eat quickly since their lunch break is almost over」
基準がわからん。
問題なく動くと、こんな感じの変な動画ができます。
締め
Step Functionsめっちゃ楽しい。