どうもです。
つい先日後輩と銭湯に行く約束をしたものの、「すいません、女の子といて終電逃しました…」と断られ、怒りの余り作業が進み記事が完成しました。
ということで前回記事、Pytorchで日経平均の予測~幕間~で紹介した
Using Deep Learning Neural Networks and Candlestick Chart Representation to Predict Stock Market
についてのデータセットの作成、コーディング、学習を行ったので備忘録として残しておきます。
データセット作成
こちらで使われるデータセットはチャートのようなものですがちょっと特殊な画像です。(詳しくは論文をどうぞ!!)
論文を参考にして作成したものは
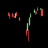
このように48×48で上下が赤と緑によって表現されている画像になります。
以下にコードを紹介します。
# !/usr/bin/env python3
# -*- coding: utf-8 -*-
import csv
import glob
import pandas as pd
import numpy as np
import sys
import matplotlib.pyplot as plt
import datetime
import openpyxl
# ローソク足描写
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
path = "/content/drive/My Drive/Colab/pytorch_pre/"
sys.path.append("/content/drive/My Drive/Colab/pytorch_pre")
import mpl_finance
ライブラリ関係のインポートです。google colaboratoryを使用しているためpathなどはドライブのファイルをおいている場所を表しています。
おそらく珍しいのはmpl_financeだと思います。これはgit hubからダウンロードすることが出来ます。ローソク足を描写するために使える便利なやつです。
mlp_finance
future_num = 1
fname = path + "data/nikkei_heikin_x3.csv"
flist = glob.glob(fname)
for file in flist:
dt = pd.read_csv(file, header=0, encoding="utf-8_sig", index_col='Datetime')
dt = dt.sort_values('Datetime')
print(dt)
future_price = dt.iloc[future_num:-18]['終値'].values
curr_price = dt.iloc[:-18-future_num]['終値'].values
# future_num日後との比較した価格を正解ラベルとして扱う
y_data_tmp = future_price / curr_price
# 正解ラベル用のlistを用意
y_data = np.zeros_like(y_data_tmp)
y_data_nam = np.zeros(len(y_data_tmp)+1, dtype=object)
Y_data = np.zeros((len(y_data_tmp)+1, 2), dtype=object)
Y_columns = ["label","ImageName"]
# 予測するfuture_num日後が上昇なら正解
for i in range(len(y_data_tmp)):
Y_data[i,0] = 0
if y_data_tmp[i] >= 1.0:
y_data[i] = 1
Y_data[i,0] = 1
count = 0
for i in y_data:
if i == 1:
count += 1
print(count)
for i in range(1,len(y_data_tmp)+1):
y_data_nam[i] = "{:04}.png".format(i-1)
Y_data[i,1] = y_data_nam[i]
Y_data[0,0] = "label"
Y_data[0,1] = "ImageName"
dn = pd.DataFrame(Y_data)
dn.columns = Y_columns
np.savetxt(path+"debug/y_data.csv", dn, delimiter=",", fmt='%s') # csvファイルに書き込
この辺でラベル付けに関することをしていきます。読み込んで来たデータを整理して当日の価格が前日よりも高い場合1、低い場合は0で二値分類していきます。
あとあと画像名からラベルを呼び出せるようにするためにcsvにファイルネーム(imagename)とラベルを同じ行に並べてテーブルのようにしておきます。
img_create = 1
if img_create == 1:
seq_len = 20
df = pd.read_csv(fname, parse_dates=True, index_col=0)
df = df.sort_values('Datetime')
df = df.rename(columns={'始値':'Open','高値':'High','安値':'Low','終値':'Close','出来高':'Volume'})
df.fillna(0)
plt.style.use('dark_background')
df.reset_index(inplace=True)
df['Datetime'] = df['Datetime'].map(mdates.date2num)
for i in range(0, len(df)):
c = df.iloc[i:i + int(seq_len) - 1, :]
if len(c) == int(seq_len-1):
# Date,Open,High,Low,Adj Close,Volume
ohlc = zip(c['Datetime'], c['Open'], c['High'],
c['Low'], c['Close'], c['Volume'])
my_dpi = 96
fig = plt.figure(figsize=(48 / my_dpi, 48 / my_dpi), dpi=my_dpi)
ax1 = plt.subplot2grid((1, 1), (0, 0))
# candlestick2_ohlc(ax1, c['Open'],c['High'],c['Low'],c['Close'], width=0.4, colorup='#77d879', colordown='#db3f3f')
mpl_finance.candlestick_ohlc(ax1, ohlc, width=0.4,
colorup='#77d879', colordown='#db3f3f')
ax1.grid(False)
ax1.set_xticklabels([])
ax1.set_yticklabels([])
ax1.xaxis.set_visible(False)
ax1.yaxis.set_visible(False)
ax1.axis('off')
# pngfile = 'datasets/{}_{}_{}.png'.format(
# i, seq_len, fname[11:-4])
pngfile = 'datasets/{:04}.png'.format(i)
fig.savefig(path+pngfile, pad_inches=0, transparent=False)
plt.close(fig)
print("Converting olhc to candlestik finished.")
ここは論文とほぼ同じです。出来高表示は出来ていません。出来たら教えてください。
論文と同じ形の数値データではないので形を合わせています。自分が使用したデータです。
renameすることで形を合わせます。これでデータセットの画像が完成します。
学習
学習を行うモデルはResNetを使用します。論文では独自のモデル構造を使用してSOTAを記録していましたが、ResNetでも十分な結果が得られていたのでこちらを使用します。
class MyDataSet(Dataset):
def __init__(self, csv_path, root_dir):
self.train_df = pd.read_csv(csv_path)
self.root_dir = root_dir
self.images = os.listdir(self.root_dir)
self.transform = transforms.Compose([transforms.ToTensor()])
self.y_columns = ["label","ImageName"]
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
# 画像読み込み
# print(self.images)
image_name = self.images[idx]
image = Image.open(os.path.join(self.root_dir, image_name) )
image = image.convert('RGB') # PyTorch 0.4以降
# label (0 or 1)
self.train_df.columns = self.y_columns
label = self.train_df.query('ImageName=="'+image_name+'"')['label'].iloc[0]
return self.transform(image), int(label)
def conv3x3(in_channels, out_channels, stride=1, groups=1, dilation=1):
return nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=True,
dilation=dilation)
def conv1x1(in_channels, out_channels, stride=1):
return nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=True)
class BasicBlock(nn.Module):
# Implementation of Basic Building Block
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(in_channels, out_channels, stride)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(out_channels, out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
def forward(self, x):
identity_x = x # hold input for shortcut connection
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity_x = self.downsample(x)
out += identity_x # shortcut connection
return self.relu(out)
class ResidualLayer(nn.Module):
def __init__(self, num_blocks, in_channels, out_channels, block=BasicBlock):
super(ResidualLayer, self).__init__()
downsample = None
if in_channels != out_channels:
downsample = nn.Sequential(
conv1x1(in_channels, out_channels),
nn.BatchNorm2d(out_channels)
)
self.first_block = block(in_channels, out_channels, downsample=downsample)
self.blocks = nn.ModuleList(block(out_channels, out_channels) for _ in range(num_blocks))
def forward(self, x):
out = self.first_block(x)
for block in self.blocks:
out = block(out)
return out
class ResNet18(nn.Module):
def __init__(self, num_classes):
super(ResNet18, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = ResidualLayer(2, in_channels=64, out_channels=64)
self.layer2 = ResidualLayer(2, in_channels=64, out_channels=128)
self.layer3 = ResidualLayer(
2, in_channels=128, out_channels=256)
self.layer4 = ResidualLayer(
2, in_channels=256, out_channels=512)
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512, num_classes)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.maxpool(out)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.avg_pool(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
class Trainer:
def __init__(self, model, optimizer, criterion):
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.model = model.to(self.device)
self.optimizer = optimizer
self.criterion = criterion
def epoch_train(self, train_loader):
self.model.train()
epoch_loss = 0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(train_loader):
inputs = inputs.to(self.device)
targets = targets.to(self.device).long()
self.optimizer.zero_grad()
outputs = self.model(inputs)
loss = self.criterion(outputs, targets)
loss.backward()
self.optimizer.step()
epoch_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += predicted.eq(targets.data).cpu().sum().item()
epoch_loss /= len(train_loader)
acc = 100 * correct / total
return epoch_loss, acc
def epoch_valid(self, valid_loader):
self.model.eval()
epoch_loss = 0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(valid_loader):
inputs = inputs.to(self.device)
targets = targets.to(self.device).long()
outputs = self.model(inputs)
loss = self.criterion(outputs, targets)
epoch_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += predicted.eq(targets.data).cpu().sum().item()
epoch_loss /= len(valid_loader)
acc = 100 * correct / total
return epoch_loss, acc
@property
def params(self):
return self.model.state_dict()
ResNetの定義、データセットの読み込みなどをしています。MyDataSetでラベルとファイルネームを読み込んでラベル付けをしています。
if __name__ == '__main__':
model = ResNet18(2)
epoch_n = 100
optimizer = optim.Adam(model.parameters(),
lr=0.001,
weight_decay=1e-4)
criterion = nn.CrossEntropyLoss()
trainer = Trainer(model, optimizer, criterion)
transform = transforms.Compose([
transforms.Resize((50, 50)),
transforms.ToTensor(),
])
tmp_data = MyDataSet(path+'debug/y_data.csv', path+'datasets/')
dtrain, dtest = train_test_split(tmp_data, test_size=0.2)#出力が4つないとだめ??
# x_train, y_train, x_test, y_test = train_test_split(tmp_data)
train_loader = torch.utils.data.DataLoader(dtrain, batch_size=43, shuffle=True,
drop_last=True)
valid_loader = torch.utils.data.DataLoader(dtest, batch_size=43, shuffle=True,
drop_last=True)
best_acc = -1
for epoch in range(1, 1 + epoch_n):
train_loss, train_acc = trainer.epoch_train(train_loader)
valid_loss, valid_acc = trainer.epoch_valid(valid_loader)
if valid_acc > best_acc:
best_acc = valid_acc
best_params = trainer.params
print(f'EPOCH: {epoch} / {epoch_n}')
print(f'TRAIN LOSS: {train_loss:.3f}, TRAIN ACC: {train_acc:.3f}')
print(f'VALID LOSS: {valid_loss:.3f}, VALID ACC: {valid_acc:.3f}')
torch.save(best_params, path + 'models/resnet.pth')
学習を行う部分です。普通のResNetとほぼ変わらないと思います。
学習結果です。
EPOCH: 1 / 100
TRAIN LOSS: 0.700, TRAIN ACC: 62.114
VALID LOSS: 1.145, VALID ACC: 52.442
EPOCH: 2 / 100
TRAIN LOSS: 0.502, TRAIN ACC: 76.391
VALID LOSS: 0.476, VALID ACC: 78.023
EPOCH: 3 / 100
TRAIN LOSS: 0.426, TRAIN ACC: 81.248
VALID LOSS: 0.467, VALID ACC: 77.907
EPOCH: 4 / 100
TRAIN LOSS: 0.368, TRAIN ACC: 83.633
VALID LOSS: 0.357, VALID ACC: 85.000
EPOCH: 5 / 100
TRAIN LOSS: 0.324, TRAIN ACC: 86.488
VALID LOSS: 0.648, VALID ACC: 76.395
EPOCH: 6 / 100
TRAIN LOSS: 0.305, TRAIN ACC: 87.018
VALID LOSS: 0.365, VALID ACC: 84.884
EPOCH: 7 / 100
TRAIN LOSS: 0.277, TRAIN ACC: 88.284
VALID LOSS: 0.480, VALID ACC: 79.884
.
.
.
EPOCH: 92 / 100
TRAIN LOSS: 0.006, TRAIN ACC: 99.853
VALID LOSS: 0.874, VALID ACC: 85.349
EPOCH: 93 / 100
TRAIN LOSS: 0.025, TRAIN ACC: 99.058
VALID LOSS: 0.960, VALID ACC: 78.953
EPOCH: 94 / 100
TRAIN LOSS: 0.028, TRAIN ACC: 99.058
VALID LOSS: 0.992, VALID ACC: 85.698
EPOCH: 95 / 100
TRAIN LOSS: 0.021, TRAIN ACC: 99.264
VALID LOSS: 0.744, VALID ACC: 84.884
EPOCH: 96 / 100
TRAIN LOSS: 0.007, TRAIN ACC: 99.735
VALID LOSS: 1.000, VALID ACC: 85.349
EPOCH: 97 / 100
TRAIN LOSS: 0.008, TRAIN ACC: 99.735
VALID LOSS: 0.834, VALID ACC: 86.279
EPOCH: 98 / 100
TRAIN LOSS: 0.020, TRAIN ACC: 99.470
VALID LOSS: 0.739, VALID ACC: 85.930
EPOCH: 99 / 100
TRAIN LOSS: 0.005, TRAIN ACC: 99.853
VALID LOSS: 0.846, VALID ACC: 86.395
EPOCH: 100 / 100
TRAIN LOSS: 0.016, TRAIN ACC: 99.382
VALID LOSS: 1.104, VALID ACC: 83.953
trainデータでは100%、testデータでも87%を記録しました。前回のLSTMを使用して約60%を考えると遥かに精度が良くなっています。
結論考察
画像を使用することで上下を当てるだけならば、精度は向上しうることがあるというのがわかりました。実際に使って儲かるのかはわかりませんが…
ここまでは論文の後追い実験なのでここから、深層距離学習を取り入れて3%上昇の予想をして行こうかと思っています。
ちなみに約4300のデータで前日比で3%上昇しているのは70しかありませんでした。全体の5%となっていてかなり不均衡なデータセットといえるでしょう。
次回はこれをなんとかしたいと思います。