はじめに
みなさん、こんにちは、M&Aクラウドの尾村です。以前、LangCheckを紹介する記事を書きました。今回は、同じようなツールですが、tensorboardのようなUI付きで確認できるArthur Benchを試してみたので紹介したいと思います。Arthur Benchは、アメリカのスタートアップArthur.ai社が開発しているLLM評価ツールです。Arthur社はArthur Benchの周辺ツールであるArthur ShieldやArthur Scopeをクラウドで提供することで利益を得ているようです。今回は、公式ドキュメントを参考に私の環境で試してみたのでその結果をお伝えします。
環境設定
公式にあるようにinstallしていきます。私は仮想環境上で試したいので、以下のコマンドで、benchenvという仮想環境を作成し、アクティブにしました。
python3 -m venv benchenv
source benchenv/bin/activate
このあとは、公式にあるようにインストールします。
pip install 'arthur-bench[server]'
UIを立ち上げるbenchコマンドは、環境変数BENCH_FILE_DIR配下のファイルを見に行くため、bench_runsフォルダーを作成します。
mkdir bench_runs
export BENCH_FILE_DIR="./bench_runs"
この状態で一度、benchコマンドが有効化試してみてください。
bench
正しく立ち上がり、下記のような画面ができればOKです。
テストスイートの作成
bench_runs以下に適当なファイルを作成し、以下のようにテストスイートを作成しましょう。
今回は、exact_match.pyという名前にしました。
from arthur_bench.run.testsuite import TestSuite
suite = TestSuite(
'bench_quickstart',
'exact_match',
input_text_list=["What year was FDR elected?", "What is the opposite of down?"],
reference_output_list=["1932", "up"]
)
run = suite.run('quickstart_run', candidate_output_list=["1932", "up is the opposite of down"])
print(run)
pythonコマンドで、実行しましょう。
python3 bench_runs/exact_match.py
bench_quickstartというディレクトリが作成されています。
この状態で、もう一度、UIを読み込んでみましょう。
下記のような画面に変わります。
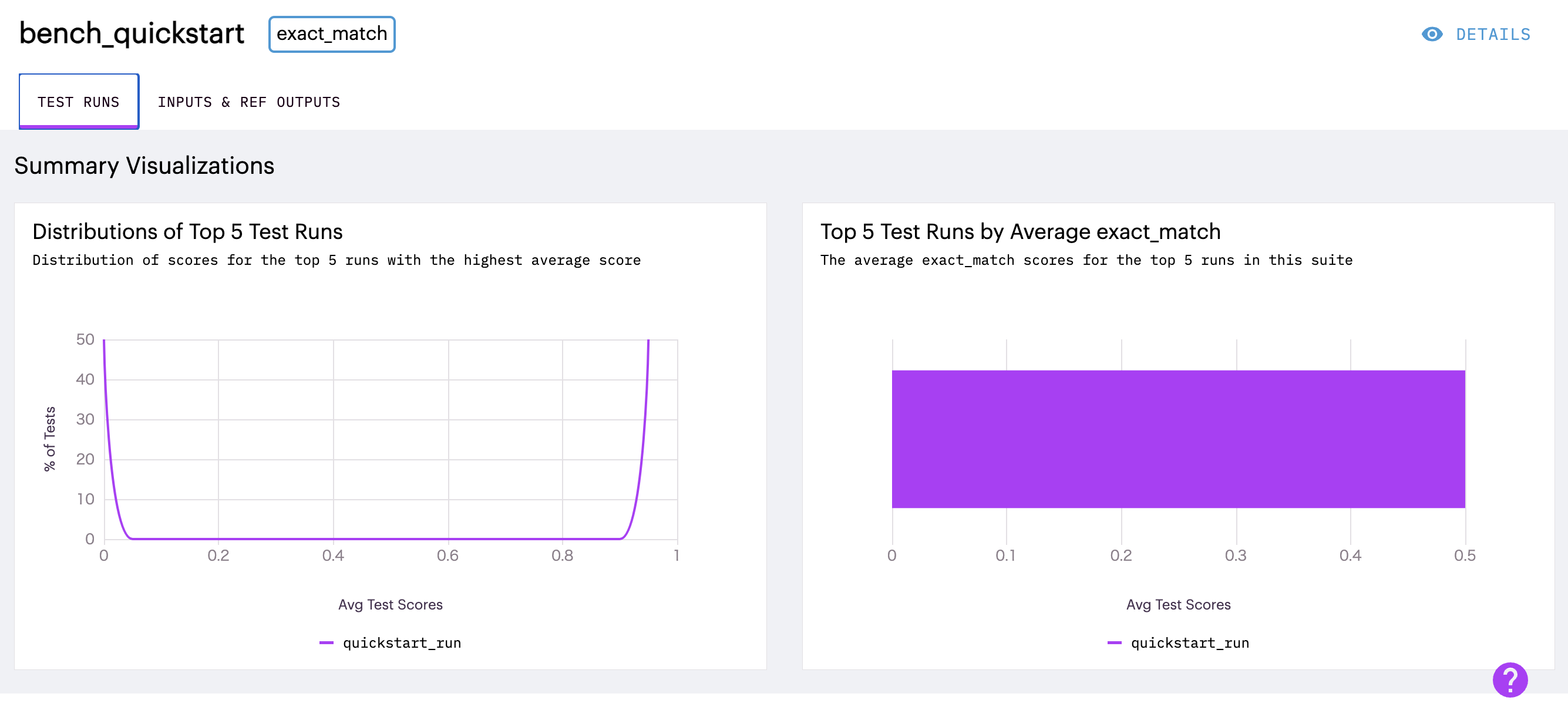
bench_quickstartを開いてみると以下のようにスコアの可視化がUIで確認可能です。
英語ですが、みやすくていいですね。
スコア
Arthur Benchでは、下記のような内容でスコアリングが可能です。
プロンプトベースは、他のopenAIチャットモデルを、embeddingsは何かしらの言語モデルを利用して評価しています。各スコアリングを行うために必要なものとしてinput/reference output/condidate output/contextの4つがあります。
| スコア | タスクの種類 | タイプ |
|---|---|---|
| BERTスコア | なんでも | embeddings |
| 完全一致 | なんでも | 辞書ベース |
| ハルシネーション | なんでも | プロンプトベース |
| 思慮深い言葉遣い | なんでも | embeddings |
| ユニットテスト | pythonコード生成 | コード評価 |
| QAの正確さ | 質疑応答 | プロンプトベース |
| リーダビリティ | なんでも | 辞書ベース |
| 特異性 | なんでも | 辞書ベース |
| 要約の品質 | 要約 | プロンプトベース |
| 単語カウント | なんでも | 辞書ベース |
テストスイートの作成
テストスイートの作成の方法は4つあります。今回は、1Listとpandasファイルを試してみます。
- List[str]
- pandas DataFrame
- csvファイル
- HuggingFace dataset
Listでのデータセットの作成
GPT-4で生成した回答をリファレンスとしてGPT3.5で生成した回答を評価します。評価するものにもよりますが、LLMが外国語に対応していると下記のように問題なく日本語でも使えます。注意点として、test runの名前はbench_llm_quickstartは一度作成すると上書きしてくれるわけではないので、別名にしたり(実行時間等を入れるとユニークにできると思います。)、削除したりする必要があります。
import os
import openai
from langchain.chat_models import ChatOpenAI
from arthur_bench.run.testsuite import TestSuite
os.environ['OPENAI_API_KEY'] = 'XXX'
gpt35 = ChatOpenAI()
gpt4 = ChatOpenAI()
inputs = ["明治維新が起こったのは何年ですか", "右の反対は?"]
baseline_outputs = [gpt4.predict(x) for x in inputs]
candidate_outputs = [gpt35.predict(x) for x in inputs]
suite = TestSuite(
"bench_llm_quickstart",
"exact_match",
input_text_list=inputs,
reference_output_list=baseline_outputs
)
suite.run('quickstart_llm_run', candidate_output_list=candidate_outputs)
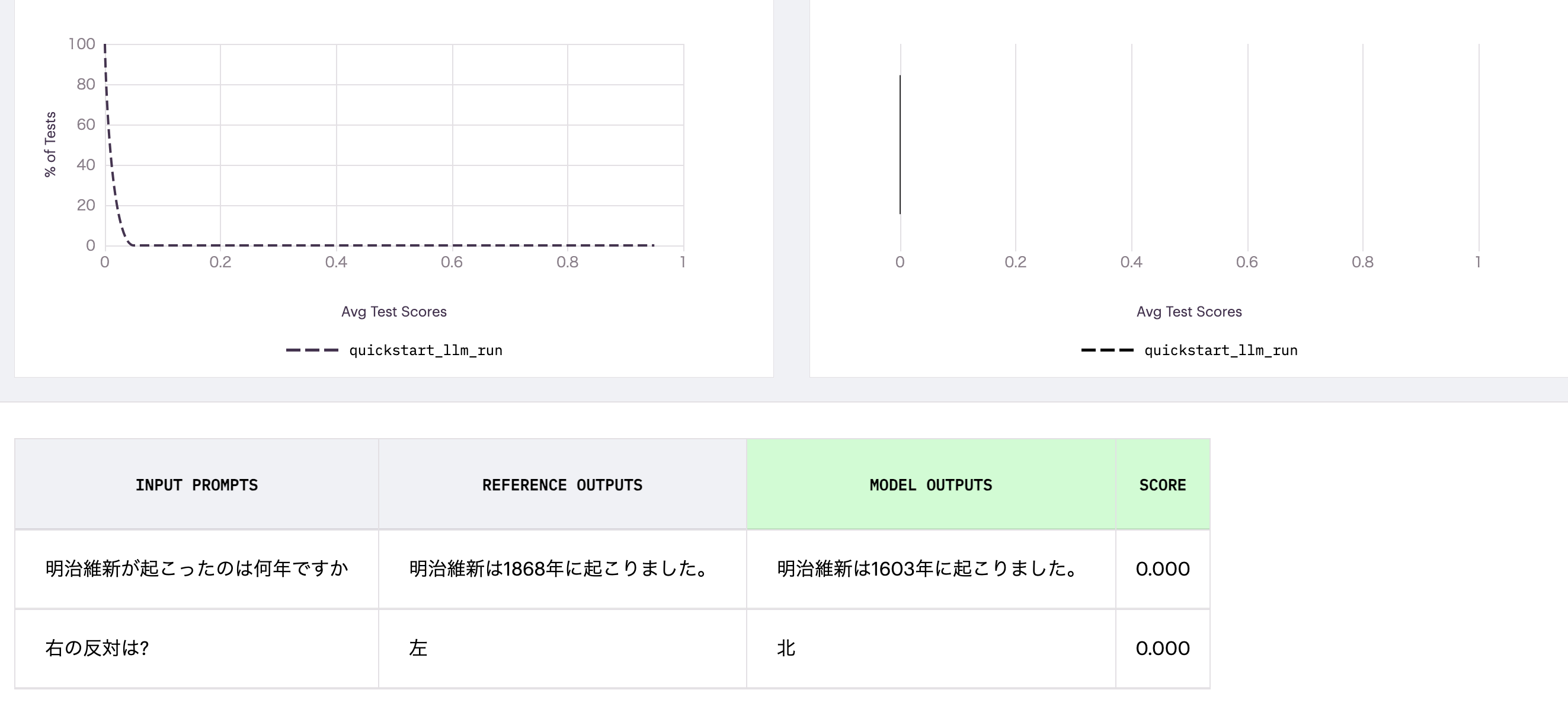
簡単な質問なので、GPT3.5でも正確に答えています。model outputsが評価されたアウトプットです。ただし、完全一致だと流石に流石に正確に一致するのは難しいですね。
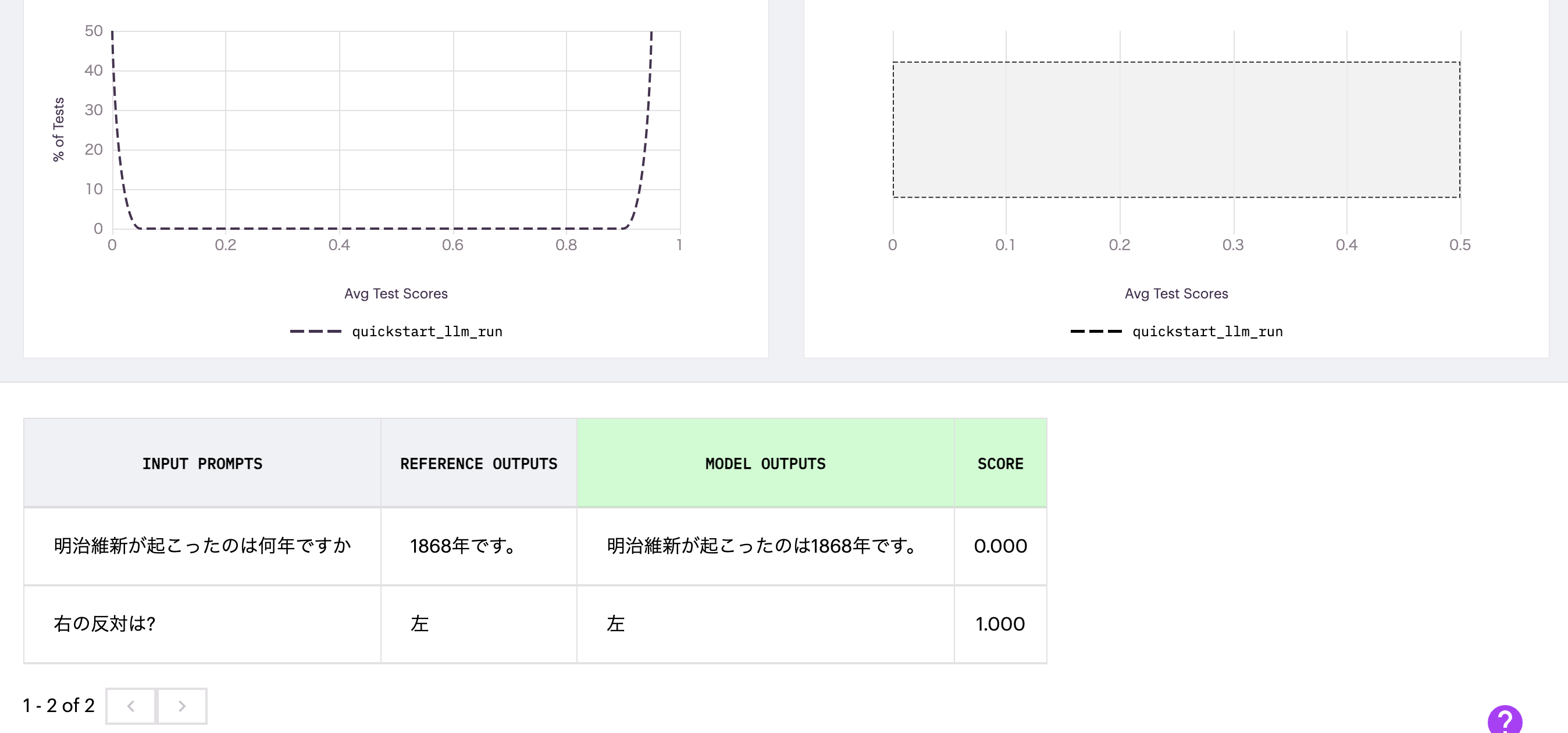
手動で、全く見当違いの結果を入れると下記のように0点と評価します。
Pandasデータフレーム
Listの代わりに下記のように、pandasのデータフレームでデータを入力することが可能です。列名を指定することで、その列を評価してくれます。PoCの段階では、データセットを加工するのにpandasでやる人は便利ですね。
from arthur_bench.run.testsuite import TestSuite
import pandas as pd
df = pd.DataFrame({
"my_input": ["What year was FDR elected?", "What is the opposite of down?"],
"baseline_output": ["1932", "up"],
"gpt35_output": ["1932", "up is the opposite of down"]
})
test_suite = TestSuite(
"suite_from_df_custom",
"exact_match",
reference_data=df,
input_column="my_input",
reference_column="baseline_output"
)
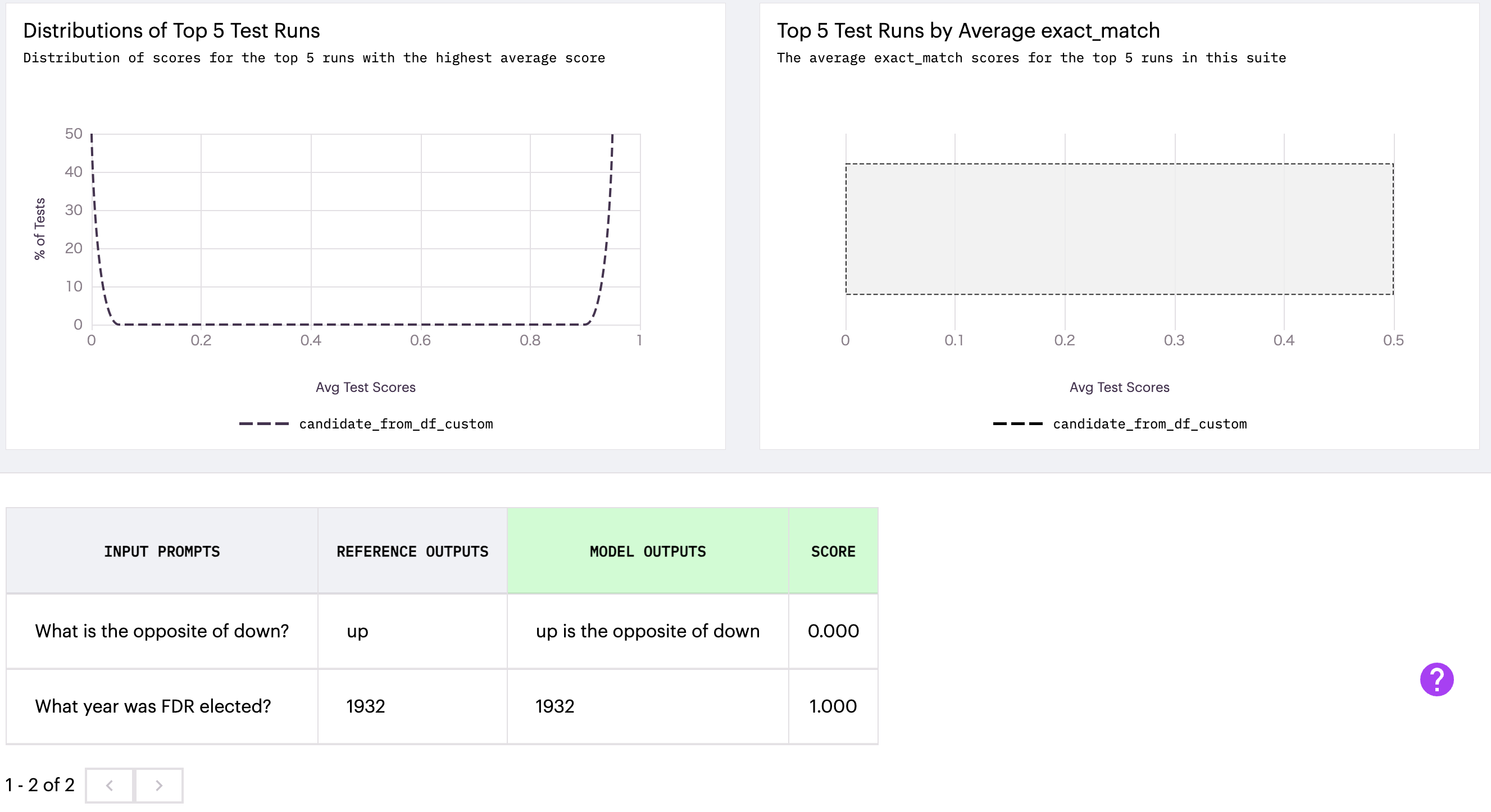
test_suite.run(
"candidate_from_df_custom",
candidate_data=df,
candidate_column="gpt35_output"
)
プロンプトの比較
プロンプトの比較を行ってみました。公式のドキュメントをそのままコピーしてきました。評価基準はBERT scoreです。
import os
import pandas as pd
from datasets import load_dataset
from arthur_bench.run.testsuite import TestSuite
os.environ['OPENAI_API_KEY'] = 'XXX'
billsum = load_dataset("billsum")
billsum_df = pd.DataFrame(billsum["ca_test"]).sample(10, random_state=278487)
example_bill = billsum["test"][6]["text"]
example_bill_summary = billsum["test"][6]["summary"]
from langchain.chat_models import ChatOpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
gpt35 = ChatOpenAI(temperature=0.0, max_tokens=100)
prompt0_template= PromptTemplate(
input_variables=["text"],
template="""
Text: {text}
Summary:
"""
)
prompt1_template = PromptTemplate(
input_variables=["text", "example_bill", "example_bill_summary"],
template="""
You are an expert summarizer of legal text. A good summary
captures the most important information in the text and doesnt focus too much on small details.
Make sure to use your expert legal knowledge in summarizing.
===
Text: {example_bill}
Summary: {example_bill_summary}
===
Text: {text}
Summary:
"""
)
prompt0_chain = LLMChain(llm=gpt35, prompt=prompt0_template)
prompt1_chain = LLMChain(llm=gpt35, prompt=prompt1_template)
# generate summaries with truncated text
prompt0_summaries = [prompt0_chain.run(bill[:3000]) for bill in billsum_df.text]
prompt1_summaries = [
prompt1_chain({"text" : bill[:3000], "example_bill" : example_bill, "example_bill_summary" : example_bill_summary})["text"]
for bill in billsum_df.text
]
my_suite = TestSuite(
"congressional_bills_to_reference",
"bertscore",
input_text_list=list(billsum_df.text),
reference_output_list=list(billsum_df.summary)
)
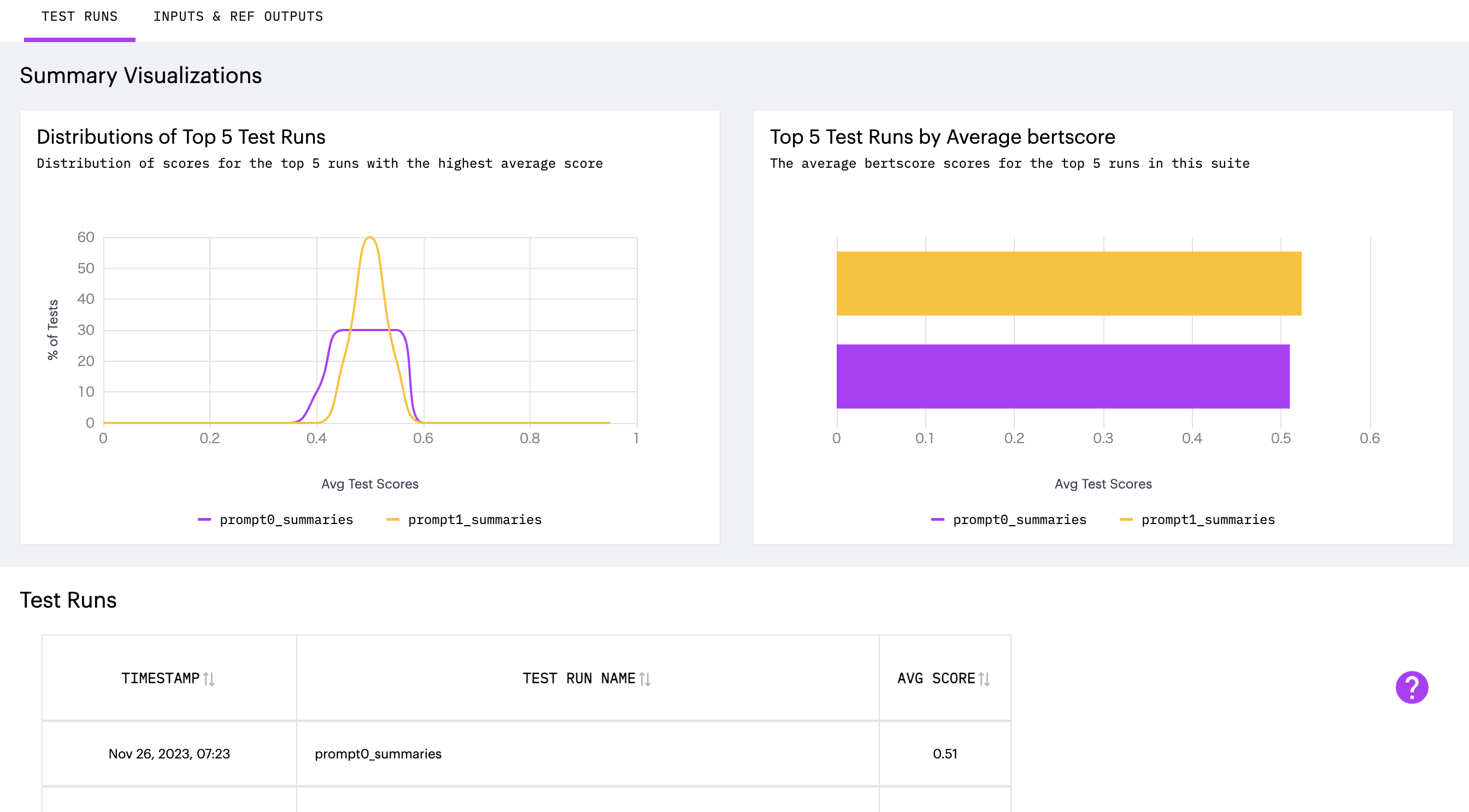
my_suite.run("prompt0_summaries", candidate_output_list=prompt0_summaries)
my_suite.run("prompt1_summaries", candidate_output_list=prompt1_summaries)
結果を確認すると、スコアの平均値は大きな差がありませんが、スコアの分散が収められており、品質の整ったテキストが生成されていそうです。
最後に、次に日本語でもやってみようかと思いましたが、BERT scoreはmicrosoftのdeberta-v3-baseを使っており、日本語に対応できているか判断がつかなかったため、今回は行いませんでした。ここら辺が日本語に対応できていけると使いやすくなって良さそうです。頑張れば、日本語への拡張といった開発やその他諸々もできるのがOSSのいいところですね。
最後に
今回は、Arthur Benchを使ってLLMの評価を試してみました。UIがついているので、結果を確認したりするのにやりやすく、また、データも保存されているのでLLMopsを行う上で有用なツールになっていくのではないかと思います。