結論(2023年6月時点)
M1 Mac使ってる人は何も考えずにconda(defaultsかconda-forge)で環境を作るだけでよい。
Notebookの学習をレジュームしたいならこつこつstoreしよう。
Scikit-learnを速くするにはn_jobsを設定しよう。
結論に至るまとめ
試した環境でのベンチマーク結果(秒なので短いほどよい)
(n_jobs設定前)
conda-default 1484
conda-default-libblas インストール不可
conda-default-np_veclib 1450
conda-forge 1435
conda-forge-nice 1450
conda-forge-highpower 1447
conda-forge-libblas 1448
kaggle-no_acc 1952
kaggle-gpu-p100 2424
kaggle-gpu-t4-2 2488
colab-free 1941
hp-conda-forge 1929
(n_jobs設定後)
conda-default 472
kaggle-no_acc 1410
きっかけ その1(長い前置き)
みなさんこんにちは。
私は日曜プログラマなんですが、最近機械学習の勉強を始めました。
"Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow"
(scikit-learn、Keras、TensorFlowによる実践機械学習)
https://www.oreilly.com/library/view/hands-on-machine-learning/9781098125967/?_gl=1*n601rm*_ga*MTU5NTYxMDMwNC4xNjg4MTI1OTU4*_ga_092EL089CH*MTY4ODEyNTk1Ny4xLjEuMTY4ODEyNTk2OS40OC4wLjA.
https://www.amazon.co.jp/gp/product/B0BHCFNY9Q
を読んで勉強しています。
最近のPythonの本はJupyterのNotebookとしてサンプルコードが提供されているものが多いのでとても便利ですね。この本でもChapter毎にNotebookが提供されていて、自由にダウンロードして、自分で実行しながら、そして自分なりの試行錯誤を加えながら学ぶことができます。
ただコードの実行が遅いのには参りました。M1 Max(10コア64Gbメモリ)を使っているのですが、あるChapterのNotebookを上から下まで実行するまでに20分ほどかかってしまいます。一気に一つのChapterを読み切ることができず、何度かにわけて読むので、読書を再開する度にNotebookを再実行していると、勉強を始めるまでにかかる時間が馬鹿になりません。
storeのマジックコマンドで変数を保存するという手もあるのですが、所詮はサンプルコードなので、作業状態を保存するために手間をかけたくなく。
そこでなんとかコードの実行速度自体を速くできないかと工夫した結果(その結果改善できなかったという結果)がノートです。他の方が同じことに時間を使わないで済むように(又は僕が見つけられなかったソリューションをより早く見つけられるきっかけになれるように)、メモを残しておきます。
!追記 別の解決案のメモを書きました。
https://qiita.com/homunet/items/eb32c668e993ae47c239
きっかけ その2
Notebookを上からしたまで実行してみると、PCがそれほど熱くならないし、ファンも回りません。このMacでゲームをすると結構ファンが回って熱くなるのに。ということはまだまだM1をの潜在能力は発揮し切れていないのではないかと。
そこでGoogle先生に聞いてみると以下の記事を見つけて、試して見る価値があるかもと思った次第です。
https://developer.apple.com/forums/thread/695963
使ったコード
https://github.com/ageron/handson-ml3
の中の
03_classification.ipynb
です。
このChapterはPyTorchとかTensorflowとかは無しで、Scikit-Learnのみで学習・予測をしています。
ポイントとしてはPyTorchやTensorFlowみたいにGPUアクセラレーションが効かないので、素のCPU環境の勝負になるという所です(誤解があったら指摘お願いします)。
単純に上から下まで実行する秒数を計測しています。
環境
-
conda-default 1484
何も考えずにcondaのdefaultsチャンネルからscikit-learnをインストールしただけ$ conda install -y pandas jupyter matplotlib jupyterlab nltk scikit-learn $ pip install urlextract -
conda-default-libblas インストール不可
以下の何人かが結果をレポートしている手法です。
https://developer.apple.com/forums/thread/695963$ conda install numpy "libblas=*=*accelerate"これはconda installが完結せず、計測できませんでした。
-
conda-default-np_veclib 1450
以下のアドレスで「速かったぜ」と紹介されている方法です。
https://gist.github.com/MarkDana/a9481b8134cf38a556cf23e1e815dafb
紹介されているソースからコンパイルする方法はnumpyが2系列なって実行時にエラーになったので、下記のコマンドでインストールしています。$ pip install --no-binary :all: --no-use-pep517 numpy -
conda-forge 1435
conda-forgeには各arch用のバイナリが上がっているというのをどこかで見かけて試してみました。$ conda config --remove channels defaults誤差の範疇ですが、これが最速。
-
conda-forge-nice 1450
それでも誤差しかないので、jupyter labを起動する際にniceでプロセス優先度を最高にした状態です。 -
conda-forge-highpower 1447
やっぱり誤差なので、Macのシステム環境設定中のBatteryでHigh Powerにした状態です。 -
conda-forge-libblas 1448
2.と同じ以下の方法でnympyをインストールする方法です。$ conda install numpy "libblas=*=*accelerate" -
kaggle-no_acc 1952
クラウドの速度はどうなんだろうと思ってkaggleで試してみました。
これはアクセラレーション無しの結果です。 -
kaggle-gpu-p100 2424
kaggleでGPU P100でアクセラレーションした結果です。
選択時にコア数が減ると告知されますが、その通りパフォーマンスが低下しました。

-
kaggle-gpu-t4-2 2488
kaggleでGPU T4 x4でアクセラレーションした結果です。やはりパフォーマンスが低下しています。

-
colab-free 1941
kaggleもやっぱりそんなに速くないので、colabならどうだと試した結果です。 -
hp-conda-forge 1929
最後に自宅にあったちょい古ゲーミングノート(i7 8750H)での結果です。
所感
そんなわけでMac上で使う環境を工夫しても残念ながらパフォーマンスは改善できませんでした。この結果からすると、先述の記事のアップから今日までに、defaultsやconda-forgeにあるバイナリがM1用にある程度アップデートされたのでしょう。
ただGeekbench6のマルチコアのスコアあたりからすると、M1 Maxはi7 8750Hの2.3倍ぐらいのパフォーマンスが出るようなので、今後もう少し性能改善が期待できるかもしれません。
いずれにせよ、当面はこのMacのローカルで、変数をwhoで取ってstoreしながら学習を進めようと思います。
こうやったら速くなるとか、速くなるライブラリが出たとかがありましたら、お知らせいただけるとありがたいです。
自己解決的アップデート
その後何か解決方法がないかと色々試しているときに、以下のベンチマークコードを実行するとCPUが100%で回ってMacが熱くなることを発見
https://developer.apple.com/forums/thread/695963
import time
import numpy as np
np.random.seed(42)
a = np.random.uniform(size=(300, 300))
runtimes = 10
timecosts = []
for _ in range(runtimes):
s_time = time.time()
for i in range(100):
a += 1
np.linalg.svd(a)
timecosts.append(time.time() - s_time)
print(f'mean of {runtimes} runs: {np.mean(timecosts):.5f}s')
ここからpythonのコードによってコアを最大限使うものとそうでないものがあると推測して調べたところ、scikit-learnの多くのモデルにn_jobsという引数があることを発見。そこでサンプルコード中n_jobsを付けられるモデルにはn_jobsを付けてみた。
https://github.com/homunet/python/blob/main/03_classification-time-njob-1.ipynb
結果、472秒となりこれまで最速だった環境から3倍ほど高速化。
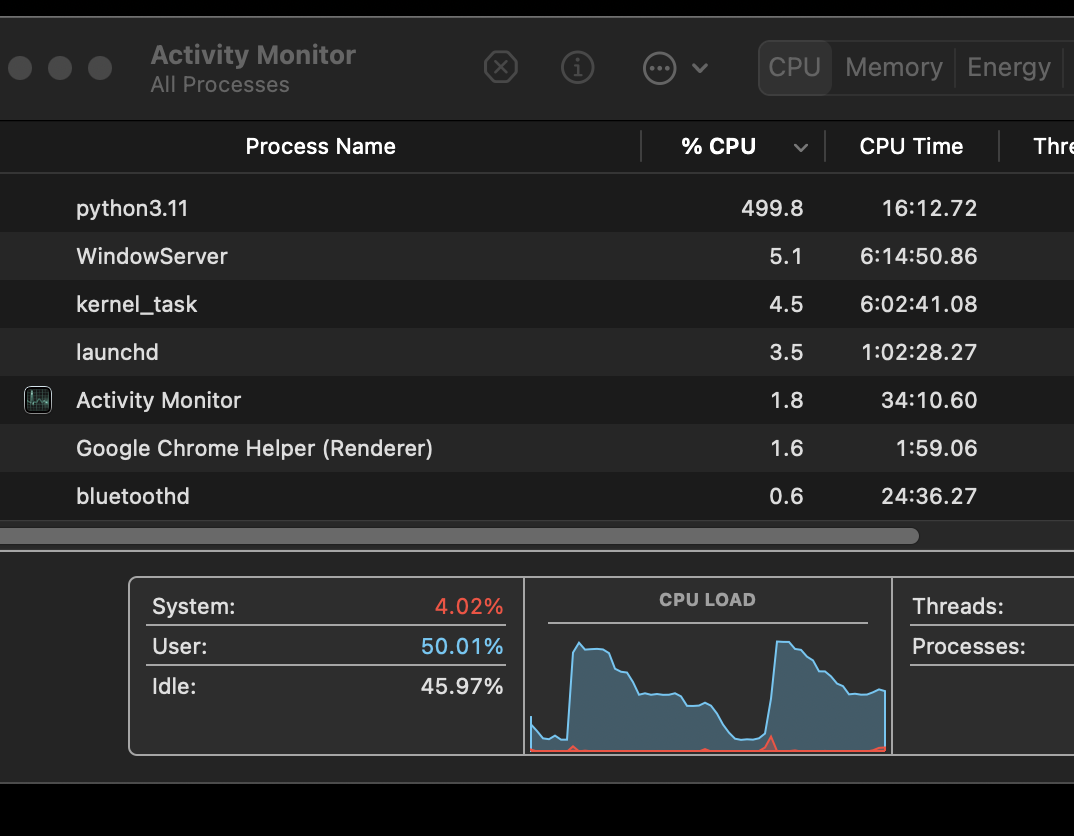
アクティビティモニタ上でも定期的にCPUがぶん回されているのを確認。
n_jobsを設定しない状態のCPU使用度とは全くパターンが異なりました。

kaggleでも試したところ、多少の改善効果を確認しました(1952秒→1410秒)。ただM1 Macのローカルの方が圧倒的に速い。
これならコーヒーを入れている間に終わるので許容範囲かな。