Deep Learningをやってみたいものの、Caffeだと、何か「書いている」気分もせずに悶々としていたところ、chainerが登場したので試してみることに。
なにはともあれ、かねてよりやりたかった、アニメ顔認識をやってみます。
本当は顔検出器+顔によるキャラ分類とかをやってみたいのですが、まずは顔とそれ以外を分類することを目指します。
ちなみに、アニメの顔認識というと、OpenCV+カスケードによる検出器があったりして、かなりいい感じに認識してくれます。
しかし、
- 原則、正面からの顔以外はうまく認識できない
- 斜めに少し傾いていても、検出されない
といった問題があるので、なんとか検出精度を向上させたいところです。
Step1: テスト画像準備
他のタスクにも使うことを考えて、自分で準備することにしました。所要時間20hぐらい。ぽよ~ん。
方針
- OpenCVとlbpcascade_animefaceを使って、アニメのフレームから顔を切り出し。
- そこから誤認識された画像をのぞいて、正解集合に入れる。
- 再びOpenCVを使って、顔が認識されなかったフレームを抽出。
- 3.の画像から、実際は顔が写っているものを探して、対象の顔を切り出し、正解集合に追加。
- 残りは顔が映っていないフレームから、ランダムにcropして、不正解集合に追加。
- それぞれの画像を90度、180度、270度回転させて、データを4倍に増やす。
- Networkの設計上、入力サイズをそろえる必要があったため、64x64に変換。
トレーニングセット
- 110,525枚(顔データ34,355枚、その他画像76,170枚)
- AngelBeats!、キルミー・ベイベー、ごちうさ・・など
- 適当に絵柄が異なりそうなものを選択、したつもり。
バリデーションセット
- 8,525枚(顔データ3,045枚、その他画像5,480枚)
- きんモザ
トレーニングセットとバリデーションセットの内訳の比率が揃ってないのは、嫌な感じですが、とりあえず先に進みます。
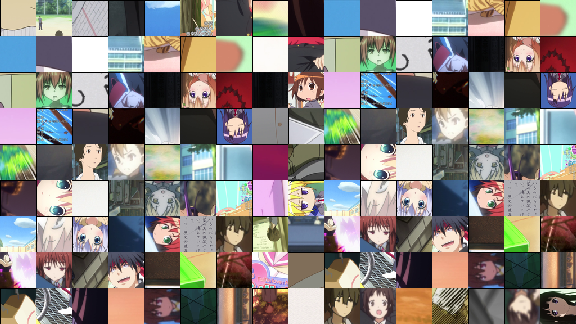
画像サンプル
- 顔画像

- 全体
Step2: 学習器作成
CNN
import chainer
import chainer.functions as F
class FrgNet64(chainer.FunctionSet):
insize = 64
def __init__(self):
super(FrgNet64, self).__init__(
conv1 = F.Convolution2D(3, 96, 5, pad=2),
bn1 = F.BatchNormalization(96),
conv2 = F.Convolution2D(96, 128, 5, pad=2),
bn2 = F.BatchNormalization(128),
conv3 = F.Convolution2D(128, 256, 3, pad=1),
conv4 = F.Convolution2D(256, 384, 3, pad=1),
fc5 = F.Linear(18816, 2048),
fc6 = F.Linear(2048, 2),
)
def forward_but_one(self, x_data, train=True):
x = chainer.Variable(x_data, volatile=not train)
h = F.max_pooling_2d(F.relu(self.bn1(self.conv1(x))), 5, stride=2)
h = F.max_pooling_2d(F.relu(self.bn2(self.conv2(h))), 5, stride=2)
h = F.max_pooling_2d(F.relu(self.conv3(h)), 3, stride=2)
h = F.leaky_relu(self.conv4(h), slope=0.2)
h = F.dropout(F.leaky_relu(self.fc5(h), slope=0.2), train=train)
return self.fc6(h)
def calc_confidence(self, x_data):
h = self.forward_but_one(x_data, train=False)
return F.softmax(h)
def forward(self, x_data, y_data, train=True):
""" You must subtract the mean value from the data before. """
y = chainer.Variable(y_data, volatile=not train)
h = self.forward_but_one(x_data, train=train)
return F.softmax_cross_entropy(h, y), F.accuracy(h, y)
※全結合層を3層にすると、精度が多少上がったりもしたのですが、処理速度が結構落ちたので、採用しませんでした。
学習用コード
import numpy as np
import time
import six
from util import loader
from chainer import cuda, optimizers
class NetSet:
def __init__(self, meanpath, model, gpu=-1):
self.mean = loader.load_mean(meanpath)
self.model = model
self.gpu = gpu
self.insize = model.insize
if gpu >= 0:
cuda.init(gpu)
self.model.to_gpu()
def calc_max_label(self, prob_arr):
h, w = prob_arr.shape
labels = [0] * h
for i in six.moves.range(0, h):
label = prob_arr[i].argmax()
labels[i] = (label, prob_arr[i][label])
return labels
def forward_data_seq(self, dataset, batchsize):
sum_loss = 0
sum_accuracy = 0
for i in range(0, len(dataset), batchsize):
mini_dataset = dataset[i:i+batchsize]
x_batch, y_batch = self.create_minibatch(mini_dataset)
loss, acc = self.forward_minibatch(x_batch, y_batch)
loss_data = loss.data
acc_data = acc.data
if self.gpu >= 0:
loss_data = cuda.to_cpu(loss_data)
acc_data = cuda.to_cpu(acc_data)
sum_loss += float(loss_data) * len(mini_dataset)
sum_accuracy += float(acc_data) * len(mini_dataset)
return sum_loss, sum_accuracy
def forward_minibatch(self, x_batch, y_batch, train=False):
if self.gpu >= 0:
x_batch = cuda.to_gpu(x_batch)
y_batch = cuda.to_gpu(y_batch)
return self.model.forward(x_batch, y_batch, train=False)
def create_minibatch(self, dataset):
minibatch = np.ndarray(
(len(dataset), 3, self.insize, self.insize), dtype=np.float32)
minibatch_label = np.ndarray((len(dataset),), dtype=np.int32)
for idx, tuple in enumerate(dataset):
path, label = tuple
minibatch[idx] = loader.load_image(path, self.mean, False)
minibatch_label[idx] = label
return minibatch, minibatch_label
def create_minibatch_random(self, dataset, batchsize):
if dataset is None or len(dataset) == 0:
return self.create_minibatch([])
rs = np.random.random_integers(0, high=len(dataset) - 1, size=(batchsize,))
minidataset = []
for idx in rs:
minidataset.append(dataset[idx])
return self.create_minibatch(minidataset)
import numpy as np
import sys
import time
import six
import six.moves.cPickle as pickle
from util import loader, visualizer
from chainer import cuda, optimizers
from network.manager import NetSet
class Trainer(NetSet):
""" Network utility class """
def __init__(self, trainlist, validlist, meanpath, model,
optimizer, weight_decay=0.0001, gpu=-1):
super(Trainer, self).__init__(meanpath, model, gpu)
self.trainset = loader.load_image_list(trainlist)
self.validset = loader.load_image_list(validlist)
self.optimizer = optimizer
self.wd_rate = weight_decay
if gpu >= 0:
cuda.init(gpu)
self.model.to_gpu()
optimizer.setup(model.collect_parameters())
def train_random(self, batchsize, lr_decay=0.1, valid_interval=500,
model_interval=10, log_interval=100, max_epoch=100):
epoch_iter = 0
if batchsize > 0:
epoch_iter = len(self.trainset) // batchsize + 1
begin_at = time.time()
for epoch in six.moves.range(1, max_epoch + 1):
print('epoch {} starts.'.format(epoch))
train_duration = 0
sum_loss = 0
sum_accuracy = 0
N = batchsize * log_interval
for iter in six.moves.range(1, epoch_iter):
iter_begin_at = time.time()
x_batch, y_batch = self.create_minibatch_random(self.trainset, batchsize)
loss, acc = self.forward_minibatch(x_batch, y_batch)
train_duration += time.time() - iter_begin_at
if epoch == 1 and iter == 1:
visualizer.save_model_graph(loss, 'graph.dot')
visualizer.save_model_graph(loss, 'graph.split.dot', remove_split=True)
print('model graph is generated.')
sum_loss += float(cuda.to_cpu(loss.data)) * batchsize
sum_accuracy += float(cuda.to_cpu(acc.data)) * batchsize
if iter % log_interval == 0:
throughput = batchsize * iter / train_duration
print('training: iteration={:d}, mean loss={:.8f}, accuracy rate={:.6f}, learning rate={:f}, weight decay={:f}'
.format(iter + (epoch - 1) * epoch_iter, sum_loss / N, sum_accuracy / N, self.optimizer.lr, self.wd_rate))
print('epoch {}: passed time={}, throughput ({} images/sec)'
.format(epoch, train_duration, throughput))
sum_loss = 0
sum_accuracy = 0
if iter % valid_interval == 0:
N_test = len(self.validset)
valid_begin_at = time.time()
valid_sum_loss, valid_sum_accuracy = self.forward_data_seq(self.validset, batchsize, train=False)
valid_duration = time.time() - valid_begin_at
throughput = N_test / valid_duration
print('validation: iteration={:d}, mean loss={:.8f}, accuracy rate={:.6f}'
.format(iter + (epoch - 1) * epoch_iter, valid_sum_loss / N_test, valid_sum_accuracy / N_test))
print('validation time={}, throughput ({} images/sec)'
.format(valid_duration, throughput))
sys.stdout.flush()
self.optimizer.lr *= lr_decay
self.wd_rate *= lr_decay
if epoch % model_interval == 0:
print('saving model...(epoch {})'.format(epoch))
pickle.dump(self.model, open('model-' + str(epoch) + '.dump', 'wb'), -1)
print('train finished, total duration={} sec.'
.format(time.time() - begin_at))
pickle.dump(self.model, open('model.dump', 'wb'), -1)
def forward_data_seq(self, dataset, batchsize, train=True):
sum_loss = 0
sum_accuracy = 0
for i in range(0, len(dataset), batchsize):
mini_dataset = dataset[i:i+batchsize]
x_batch, y_batch = self.create_minibatch(mini_dataset)
loss, acc = self.forward_minibatch(x_batch, y_batch, train)
loss_data = loss.data
acc_data = acc.data
if self.gpu >= 0:
loss_data = cuda.to_cpu(loss_data)
acc_data = cuda.to_cpu(acc_data)
sum_loss += float(loss_data) * len(mini_dataset)
sum_accuracy += float(acc_data) * len(mini_dataset)
return sum_loss, sum_accuracy
def forward_minibatch(self, x_batch, y_batch, train=True):
if self.gpu >= 0:
x_batch = cuda.to_gpu(x_batch)
y_batch = cuda.to_gpu(y_batch)
if train:
self.optimizer.zero_grads()
loss, acc = self.model.forward(x_batch, y_batch, train)
if train:
loss.backward()
self.optimizer.weight_decay(self.wd_rate)
self.optimizer.update()
return loss, acc
import os
import numpy as np
import six.moves.cPickle as pickle
from PIL import Image
### functions to load files, such as model.dump, images, and mean file.
def unpickle(filepath):
return pickle.load(open(filepath, 'rb'))
def load_model(filepath):
""" load trained model.
If the model is trained on GPU, then you must initialize cuda-driver before.
"""
return unpickle(filepath)
def load_mean(filepath):
""" load mean file
"""
return unpickle(filepath)
def load_image_list(filepath):
""" load image-file list. Image-file list file consists of filepath and the label.
"""
tuples = []
for line in open(filepath):
pair = line.strip().split()
if len(pair) == 0:
continue
elif len(pair) > 2:
raise ValueError("list file format isn't correct: [filepath] [label]")
else:
tuples.append((pair[0], np.int32(pair[1])))
return tuples
def image2array(img):
return np.asarray(img).transpose(2, 0, 1).astype(np.float32)
def load_image(path, mean, flip=False):
image = image2array(Image.open(path))
image -= mean
if flip:
return image[:, :, ::-1]
else:
return image
main.pyはごちゃごちゃしているので、訓練部分だけ抜粋します。
### a function for training.
def train(trainlist, validlist, meanpath, modelname, batchsize, max_epoch=100, gpu=-1):
model = None
if modelname == "frg64":
model = FrgNet64()
elif modelname == "frg128":
model = FrgNet128()
optimizer = optimizers.MomentumSGD(lr=0.001, momentum=0.9)
trainer = batch.Trainer(trainlist, validlist, meanpath, model,
optimizer, 0.0001, gpu)
trainer.train_random(batchsize, lr_decay=0.97, valid_interval=1000,
model_interval=5, log_interval=20, max_epoch=max_epoch)
学習は基本的にGPUを使い、また、画像サイズが小さいこともあって、CPU側はマルチスレッド用に書いていないです。
Step3: 学習
パラメータ
| パラメータ | 設定値 | 備考 |
|---|---|---|
| learning rate | 0.001 | epochが1経過するごとに、0.97を掛ける |
| ミニバッチサイズ | 10 | |
| 重み減衰 | 0.0001 | epochが1経過するごとに、係数λに0.97を掛ける |
| momentum | 0.9 | chainerのデフォルト値 |
- learning rateは、誤差の変化が平坦になったら下げる、ということもやったものの、バリデーションセットに対する誤差がうまく収束しなかったので、やめました。
- ミニバッチサイズは、最初は100で試していたものの、トレーニングセットとバリデーションセットの誤差の乖離が大きかったので、小さくしています。
- 重み減衰の係数は、固定でも良かったのですが、いずれlearning rateと値が逆転するのが気になったため、順次減らすようにしています。
環境
| バージョンなど | |
|---|---|
| GPU | GeForce GTX TITAN X |
| Python | Python 3.4.3 |
結果
所要時間
全体で3時間弱かかり、訓練誤差がほぼ0になったため、epoch 30で終了しています。
画像の処理速度は、おおよそ
- 訓練中 560枚/sec
- バリデーション中 780枚/sec
でした。
誤差
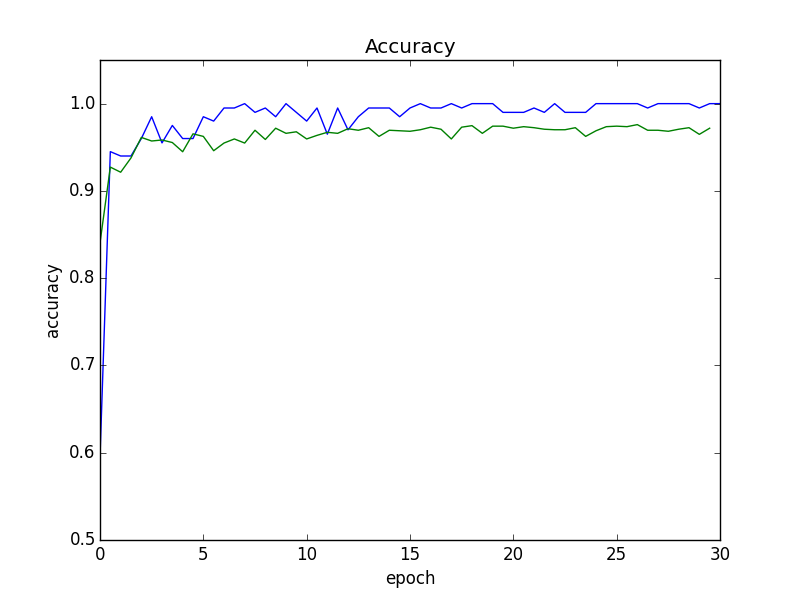
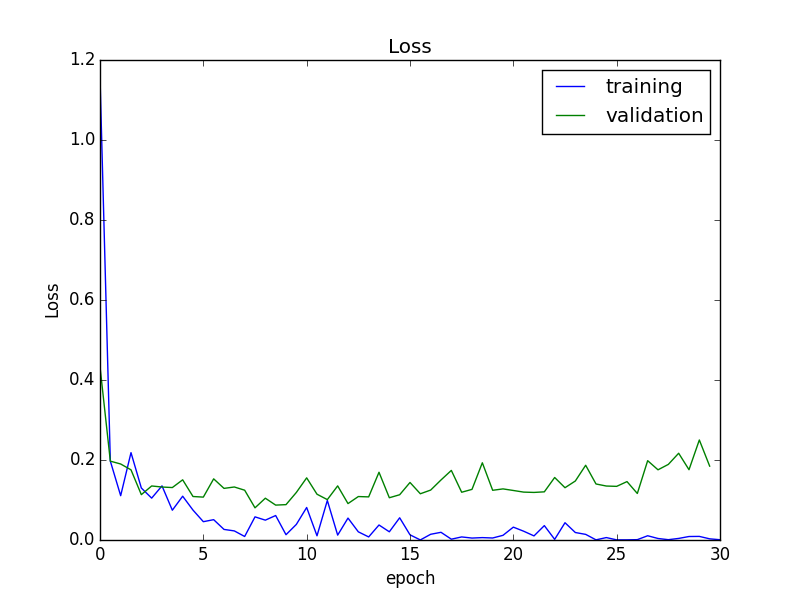
途中から、認識精度はほぼ収束している一方、バリデーションセットに対する誤差がやや増加しています。そのため、以降の実験では、誤差が最小だったepoch 15終了時のモデルを採用することにします。
このモデルは、バリデーションセットに対する認識精度が、95.5%でした。
以下に、失敗しているケースの例をあげておきます。
誤認識例
誤って顔と認識しているケース

一部テストデータの不良(ラベリングミス)っぽいです。。
顔を認識できていないケース

綺麗に顔を切り取れていないデータもありますが、わりと堂々と間違えてくれているような感じで、やや心配・・
Step4: 実データ投入
Sliding Windowで画像を切り出して、訓練済みNetworkに投入します。
単純に切り出すと、かなりの枚数になるので、画像の幅を512まで縮小したうえで、
- アスペクト比 1:1
- (size, stride)は、(48, 16), (72, 24), (144, 48)の3パターン
で切り出し、訓練時と同じ64x64のサイズにresizeしました。(手元の画像では、全部で630通り)(2015/8/8 修正)
また、Networkに投入して、顔の候補となる領域を抽出できたら、IoU(Intersection over Union) >= 30%を基準に領域をふるいに掛けて、Networkの出力の値(確率)が最大のものを選択しています。(この値の絶対値に意味があるのかは分かりませんが)
顔以外の領域とのIoUは、特に考慮していません。
実験
OpenCV + lbpcascade_animefaceで試した結果と比較で載せています。
ただし、パラメータ次第で結果が変わりうるので、必ずしもフェアな比較ではないと思います。(上がCNNで、下がOpenCVで検出した画像)
平均実行時間はCNN(GPU)が約0.8秒、OpenCV(CPU)は約0.35秒でした。
まずは、OpenCVでも今回のCNNでも認識できた画像から。さすがにanimefaceは位置が正確に見えます。


©原悠衣・芳文社/きんいろモザイク製作委員会
次は、今回狙っていた、横顔がある画像。枠の位置は微妙ですが、OpenCVでとれていなかった横顔が、認識できています。ただし、アリスと忍のあいだに変な枠ができてしまっていますが。。


©原悠衣・芳文社/きんいろモザイク製作委員会
最後は、


©Koi・芳文社/ご注文は製作委員会ですか?
あー、ビンが、、やたらビンが検出されてます。。
もちろんOpenCVのほうは正確に検出していました。悲しい
総括
感覚としては、OpenCV版よりも、拾えるケースはぐっと増えた感じなのですが、同時に顔以外の箇所を顔と誤認識する率も上がってしまった印象でした。それをふまえて・・
うまくいったこと
- 訓練データの増殖
- 画像に回転を加えて、データを増殖させたところ、収束速度がぐっとあがっていました。やはりデータ量は大事なのかと実感。
- ミニバッチサイズの調整
- 1回に100枚食わせてパラメータ更新をしていた時は、訓練誤差は収束するものの、validationの誤差はすぐに頭打ちになっていました。が、10枚に減らしたところ、validationのaccuracyは2pt程度増加して、それなりに効果があった印象です。
改善点・反省など
-
検出器
- 検出は単純なSliding Windowなので、相当時間がかかります。そこを回避するために、切り出す画像のサイズを制限していますが、この場合、画面いっぱいの顔については、検出できません。。
- 今回は顔検出なので大きな問題にはなっていないと思いますが、アスペクト比も1対1で固定です。
- 最初から、位置のラベル付きデータを使うべきだった気もしています。
-
訓練データ
- やはり、絶対量がまだまだ少なかった感があります。
- 不正解データ(の質)が足りてなかったかもしれないです。顔が映っていない画像からランダムにcropしたのですが、物自体がほぼ写っていない画像や、物の境界が捉えられていない画像が多く入ってしまい、やはりデータとしては弱かったように思います。誤検出率が高いのは、その影響も少なくないかと。
次は・・
位置のラベルつきのデータで、検出器を作ってみたいかなと。今の方式だと仮に精度が出ても、速度が出ないので、SPP-netあたりも試してみたいです。
ソースコード
chainerのバージョンが変わって動かなくなったりしているので、修正したコードをGithubにアップしました。
https://github.com/homuler/pyon2-detector/