インテル® FPGA Advent Calendar 2020 - 3日目の記事です。
12/3 18 時頃 : 速度が出ない問題を修正し、約 600 ns での応答生成が見られる波形と約 7 Gbps 負荷を掛けた時の波形のデータを追加しました。
12/4 : インテル社の OS サポートページがアップデートされたようですので、それに対応して追記しました。
概要
- 10G SFP+ ポートのついた FPGA 開発キット(インテル® Cyclone® 10 GX FPGA 開発キット) を使い、ping コマンドに応答する専用アーキテクチャのサーバを作成しました。
- パイプライン化による 10G クラスの高速処理と、カットスルー方式の処理による約 600 ナノ秒での応答パケット生成を、インテル HLS コンパイラー を用い、回路合成用の特徴を持った C 言語を用いて記述しました。
- パケット処理を HLS コンパイラで記述する時のヒントとなりそうなアプローチを、当 ping 応答回路のコードを交えて解説します。
- 当開発キットをお持ちの方にお試しいただけるよう、コード一式を https://github.com/homelith/c10gx_icmp_server に公開しました。(但し、コードはサンプルであり、動作は保証されません。使用することで起こった事象について私は責任を負いません。)
1. 製作物
外観

図1 : 実験機材群を接続した外観写真
10G NIC を装着した試験用 PC (写真左)と Cyclone 10 GX 開発キット(写真右)の間を 10Gbase-SR SFP+ 2 つと 2m のパッチコードを用いて接続しました。開発キットの FPGA には固定の MAC アドレス及び IPv4 アドレス を割り当て、MAC アドレスの解決に用いる ARP 発信・応答回路と、ping (ICMP) パケットの応答回路を組み込みました。試験用 PC の SFP+ ポートに同一サブネットの IP を割り当て、開発キットの IP 宛に ping コマンドを実行することで、開発キットに ping パケットが送信され、応答が帰ってきます。
動作概要
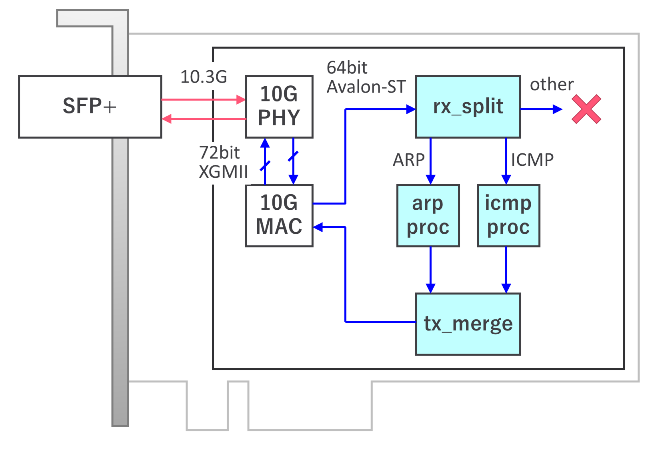
図2 : おおまかな機能ブロック図
使用した開発キットは インテル® Cyclone® 10 GX FPGA 開発キット です。搭載されている Cyclone 10 GX は上位の Arria 10 シリーズの小規模版といった使い勝手で、ライセンス不要で開発することができるものです。(無償で使用できるチップ群をカバーする Quartus Prime ライトではなくプロ・エディションを使うのですが、Cyclone 10 GX はライセンス不要となります)
開発キットに装着された SFP+ ケージと FPGA チップの間は 10.3125 Gbps の高速差動信号で接続されており、このままでは数百 MHz オーダで駆動するユーザロジック回路から直接読み書きすることができません。そこで、Cyclone 10 GX に内蔵された Transceiver PHY を IP Core から呼び出し、72bit 幅 156 MHz XGMII 信号の送受信ポートに変換します。(参考:Intel® Cyclone® 10 GX TransceiverPHY User Guide)
XGMII 信号はイーサネットパケットが存在する区間も、通信路がアイドル状態になっている区間も、全てを含んだ連続的な信号形式です。このままでは取り扱いにくいので、XGMII に対応した Ethernet MAC 回路を用いてイーサネットパケット部分のデータのみを取り出します。Ethernet MAC 回路には Intel 社が提供する LL Ethernet 10G MAC IP コア を用いたり、オープンソースの Ethernet MAC IP コアを組み込むこともできます。今回は簡便のため、LL Ethernet 10G MAC IP コアを使用しました。(製品に組み込んだりする場合は別途有償ライセンスが必要ですが、ライセンスが無くても評価モードとして試用できます。但し、flash 焼き込み用バイナリへの変換ができない、一定時間で動作停止する、などの制約があります。)
ここからが今回のコアとなる設計部分です。まず、取り出されたイーサネットパケットを一旦 rx_split モジュールに通し、ARP パケット、IPv4 ICMP パケット、それ以外を処理する回路に振り分けます。ARP、ICMP 以外のパケットは今回の処理に関係ないので、この時点で全て破棄します。
arp_proc は ARP パケットの処理モジュールで、開発キットに割り当てられた IP の MAC アドレスを問い合わせるパケットが到着したら、開発キット割り当ての MAC アドレスを書き込み、問い合わせフラグを応答フラグに書き換えて返送します。(参考:@IT MACアドレスを解決するARPプロトコル)
icmp_proc は ping 応答パケットの生成モジュールで、入力が ICMP echo request パケットであれば、ICMP echo reply パケットに書き換えて返送します。(参考 : ネットワークエンジニアとして - TCP/IP - ICMP とは)
ポイントは、ARP query パケットと ARP reply パケット、ICMP echo request パケットと ICMP echo reply パケットが同じ長さで、フィールドの値を書き換えただけの違いしかないことです。そのため、パケットの到着をトリガに新しいパケットを生成するのではなく、来たパケットを書き換えて送り返すシンプルな構成となっています。
arp_proc もしくは icmp_proc モジュールから返送されたパケットは tx_merge モジュールに通され、パケット同士が混じりあわないように1つの出力レーンにまとめられます。バス形式によりますが、今回は 64bit x 156MHz の avalon-ST データバスでの転送で処理が記述されており、8byte づつ複数回の転送によってパケット1つが送信されるため、このような工夫が必要です。
tx_merge から出力されたパケットは入力の逆順で XGMII 形式、10.3G 10GBase-R 形式に変換されていき、最終的に SFP+ モジュールから光信号として出力されて試験用 PC に帰っていきます。
動作例
試験用 PC (192.168.2.1) から Cyclone 10 GX 開発キット (192.168.2.100) に ping を打って測定したところ、平均 69 マイクロ秒での応答が得られました。(以下はコマンド結果)
(※ IP は例示のため変更しております)
$ ping 192.168.2.100
PING 192.168.2.100 (192.168.2.100) 56(84) bytes of data.
64 bytes from 192.168.2.100: icmp_seq=1 ttl=64 time=0.092 ms
64 bytes from 192.168.2.100: icmp_seq=2 ttl=64 time=0.058 ms
64 bytes from 192.168.2.100: icmp_seq=3 ttl=64 time=0.074 ms
64 bytes from 192.168.2.100: icmp_seq=4 ttl=64 time=0.092 ms
64 bytes from 192.168.2.100: icmp_seq=5 ttl=64 time=0.058 ms
64 bytes from 192.168.2.100: icmp_seq=6 ttl=64 time=0.062 ms
64 bytes from 192.168.2.100: icmp_seq=7 ttl=64 time=0.059 ms
64 bytes from 192.168.2.100: icmp_seq=8 ttl=64 time=0.087 ms
64 bytes from 192.168.2.100: icmp_seq=9 ttl=64 time=0.058 ms
64 bytes from 192.168.2.100: icmp_seq=10 ttl=64 time=0.059 ms
^C
--- 192.168.2.100 ping statistics ---
10 packets transmitted, 10 received, 0% packet loss, time 9198ms
rtt min/avg/max/mdev = 0.058/0.069/0.092/0.018 ms
なお、実験用 PC の 10G NIC 第2ポートを linux netns で分離し、第1ポート(192.168.2.1)から第2ポート(192.168.2.101)に対して ping 測定したところ、平均 152 マイクロ秒でした。(以下はコマンド結果)
$ ping 192.168.2.101
PING 192.168.2.101 (192.168.2.101) 56(84) bytes of data.
64 bytes from 192.168.2.101: icmp_seq=1 ttl=64 time=0.216 ms
64 bytes from 192.168.2.101: icmp_seq=2 ttl=64 time=0.174 ms
64 bytes from 192.168.2.101: icmp_seq=3 ttl=64 time=0.101 ms
64 bytes from 192.168.2.101: icmp_seq=4 ttl=64 time=0.176 ms
64 bytes from 192.168.2.101: icmp_seq=5 ttl=64 time=0.096 ms
64 bytes from 192.168.2.101: icmp_seq=6 ttl=64 time=0.096 ms
64 bytes from 192.168.2.101: icmp_seq=7 ttl=64 time=0.148 ms
64 bytes from 192.168.2.101: icmp_seq=8 ttl=64 time=0.172 ms
64 bytes from 192.168.2.101: icmp_seq=9 ttl=64 time=0.172 ms
64 bytes from 192.168.2.101: icmp_seq=10 ttl=64 time=0.176 ms
^C
--- 192.168.2.101 ping statistics ---
10 packets transmitted, 10 received, 0% packet loss, time 9217ms
rtt min/avg/max/mdev = 0.096/0.152/0.216/0.041 ms
通信路に寄与する部品が多いためざっくりとした見積もりですが、PC 用の NIC と Linux による応答に比べて、総合で 80 マイクロ秒程度のレイテンシ削減ができたといえるでしょう。
動作時の処理回路の波形と遅延・性能評価
SignalTap II ロジック・アナライザ を用い、処理パイプラインの主要部の動作波形を取得してみました。
図 3 は Linux の ping コマンドを標準設定で発行し、取得した波形です。
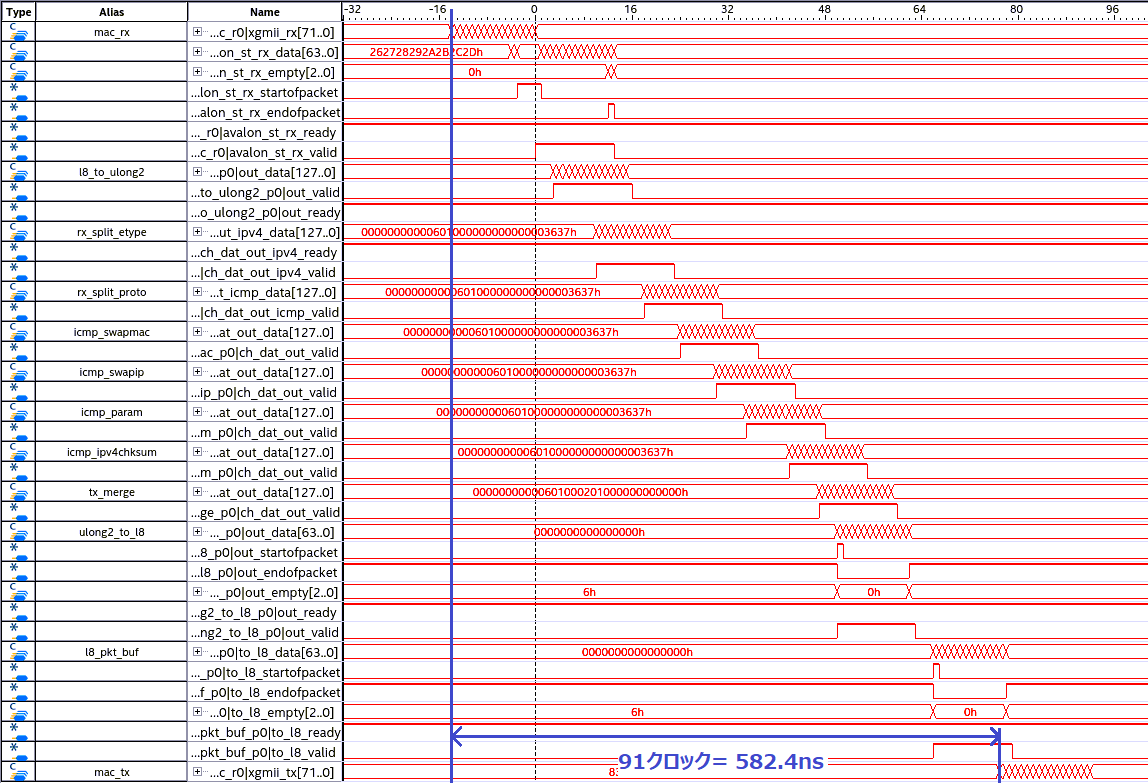
図3 : 1 ping パケットの動作波形
PHY RX 回路から XGMII 形式でデータが出始めてから、PHY TX 回路にパケットの最初のデータを投げ返すまでを 91 クロックの 582.4ns で達成することができました。なお、別途筆者の環境である SFP 10Gbase-SR モジュールを測定し、10G PHY + 10Gbase-SR モジュールの片道伝搬遅延として 80ns ~ 90ns の測定値を得ています。よって、開発キットに ICMP パケットが光入力されてから出始めるまでは 750ns 程度と見積もることができます。これは測定用 PC から見た ping コマンドの結果平均 69 マイクロ秒に対して相当に小さい値となることから、前項での測定においては ping コマンドのレイテンシはそのほとんどが PC 用 NIC、Linux のネットワークスタック内などで発生したものと推定できます。
次に、ping コマンドを pcap ファイルに記録し、tcpreplay で大量に再生成して送り付けてみました。送信性能を上げるため、ping のペイロード部を可能な限り大きくし、1514 bytes のイーサネットフレームになるようにして送信しています。その結果を図 7 に示します。
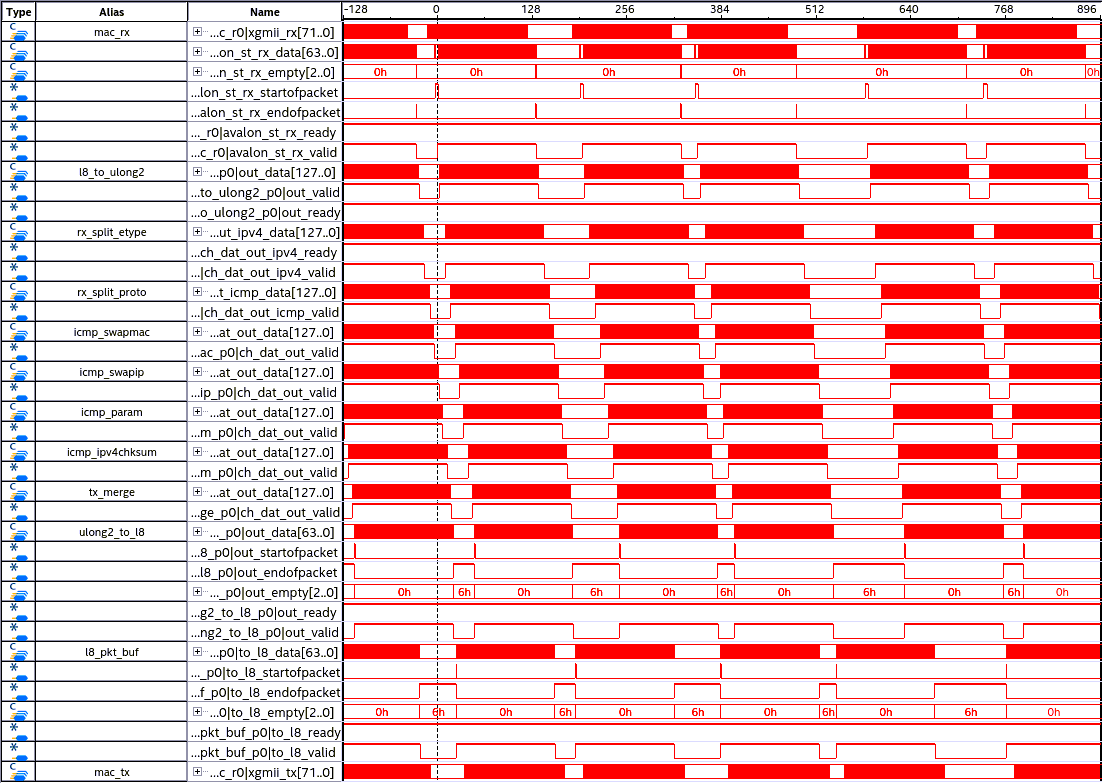
パイプラインの 60% ~ 80% 程度が埋め尽くされているものの、応答が正常に行われていることが分かります。この時、測定用 PC 側では平均 7192 Mbps での送信が記録されていました。
今回は測定機材の性能の都合これ以上の試験は行えませんが、10G クラスの応答性能を持っているとみて相違ないでしょう。
2. パイプライン&カットスルー方式の ping 応答回路の検討
ICMP echo request パケットを書き換えて ICMP echo reply を作り出す処理を例に、高速動作と低遅延での応答を実現する設計の概要を説明します。
主に、パイプライン処理 の考え方と、カットスルー交換方式 の考え方を複合させたものを用います。
図 5 に対象とする ICMP echo request パケットの例を示します。この例ではパケット長は FCS を除いて 74 bytes です。
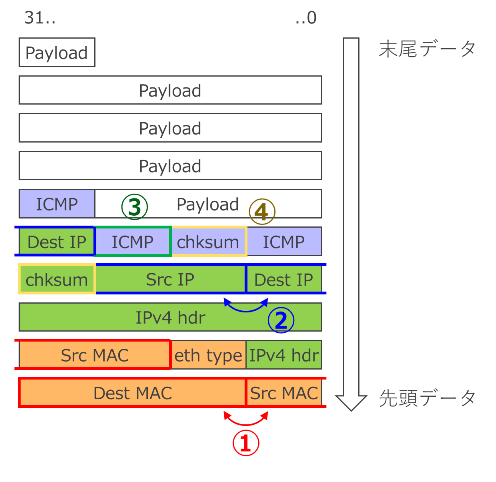
図 5 : ICMP echo request パケット例(下側、左側が先頭)
ICMP echo reply パケットに書き換えるにあたってやるべきことは主に
① Destination MAC address と Source MAC address を入れ替える
② Source IP と Destination IP を入れ替える
③ ICMP ヘッダ先頭 1 バイトのタイプフィールドを、ICMP echo request (0x08) から ICMP echo reply (0x00) に入れ替える
④ パケットの中身を書き換えたことに合わせ、ICMP チェックサムと IPv4 チェックサムを再計算し更新する
の 4 つです。
データは図 6 のようにクロックサイクルごとに次々と到着します。
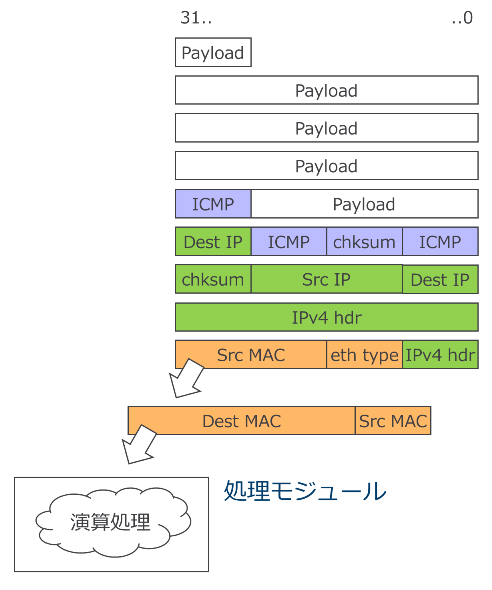
図 6 : パケットが毎サイクル到着するイメージ
これを「毎クロックサイクルデータが到着してもさばききれるように」、かつ「パケット全てをメモリに蓄えることなく、処理可能になり次第速やかに」処理していきます。
一つ目の作業、「Destination MAC address と Source MAC address を入れ替える」処理に絞って見て行きましょう。Dest MAC と Src MAC のフィールドは 8 byte 区切りのデータ列では先頭データと2番目のデータに跨って存在します。そこで、MAC アドレス入れ替えモジュールはその内部に、8byte データを FIFO (First In First Out) 形式で蓄える 3 つのレジスタ(遅延スロットと呼びます)を持つこととします。MAC アドレス入れ替えモジュールはパケットが到着したら順に遅延スロット #1 に格納し、同時に遅延スロット #1 のデータを #2 に、#2 のデータを #3 に押し出します。2つ目のデータまでが格納された時点を図 7 に示します。
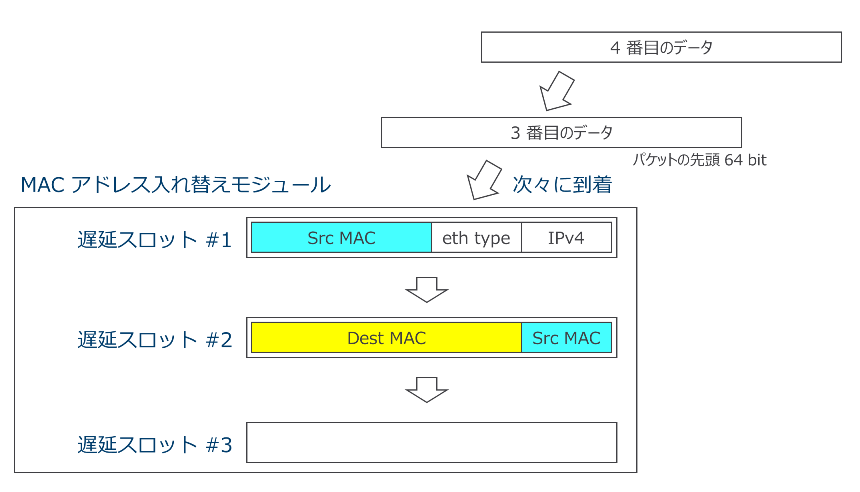
図 7 : 遅延スロットの 2 つ目までが埋まった状態
MAC アドレス入れ替えモジュールは遅延スロット #1、#2 がパケットの先頭 2 データで埋まっていることを条件に、図 8 のように遅延スロット #1、#2 のアドレス部分を入れ替えながら #2、#3 に移し替える動作を行います。勿論この間、同時に次のデータを遅延スロット #1 に受け入れます。
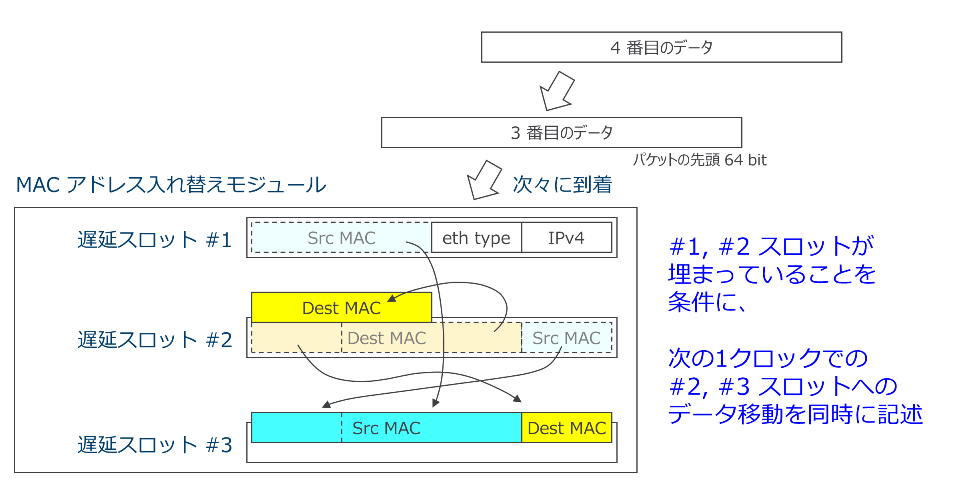
図 8 : 遅延スロットの 3 つ目を埋める時の入れ替え動作
この動作の条件に当てはまらない時は、入れ替え動作は行わず、遅延スロットの #1 に常に新しいデータを受け入れ、#2、#3、出力ポートの順に押し出し続けます。このようにすることで、常にデータを受け入れ可能なパイプライン処理と、先頭から2データまでが到着次第即座に送出を開始するカットスルー方式の両方を満たした処理構造が構築できます。
3. パケット処理を高位合成用記述に落とし込むときのテクニック
これを解説したい理由
2章の「毎サイクル動作&必要データが集まり次第処理開始」の処理構造はとてもデジタル回路化に向いていると言えます。先ほど遅延スロットを構成する「レジスタ」を例に上げて説明した通り、全てのレジスタとレジスタの間で「各クロック毎に何をすればいいか」が明確なためです。よって、レジスタ転送レベル(RTL)の記述ができる HDL (ハードウェア記述言語)でこれを記述し、論理合成・配置配線ツールを使い FPGA にコンフィグできる回路に変換することができます。
しかし、RTL 記述での作業量は莫大です。特にこのようなパケット処理のパイプラインでは、モジュールが一時的に新しいデータの受付ができなくなった時に、入力側につながっている前段のモジュールにデータ送出の停止を指示するバックプレッシャ信号(例えば、ready 信号が 0 の間はデータの受け入れを停止するなどのロジック)の制御が複雑となる傾向があるように思います。
そこで是非活用したいのが、 C 言語などからの記述から HDL を生成することでより簡単な回路設計の記述を可能にしてくれる、高位合成ツールです。しかし、現在入手できる高位合成ツールでの記述ノウハウやサンプルコードは「ユーザは『画像データなどを一旦メモリに蓄積したのち、for ループでデータ列に対して繰り返し処理を行う』記述を行い、高位合成コンパイラが『for ループを並列回路に展開することで、ソフトウェアによる逐次動作に比べて圧倒的な高速性を実現する』 HDL を出力する」といった目的のものが多く、パケット処理向けの活用にはハードルがまだ高いのではないかと私は考えています。
そこで、私が今回 ICMP 応答回路を書いた時のアプローチ、記述のワンポイントテクニックを下記にコードを交えて解説します。
筆者の感覚で「記述しやすい」「高クロックで動作させやすい」と感じたアプローチを上げておりますので、記述の正確性の検証等ができているものではありません。あくまで参考程度にお考え下さい。
今回使用したツールは開発キットの Cyclone 10 GX チップに対応する、インテル HLS コンパイラー・プロ・エディションです。詳しい使用法はリファレンスマニュアルを参照いただくのが良いでしょう。スタンダード版とプロ版は対応する FPGA デバイスによって変える必要があるのでご注意下さい。
おことわり:Avalon-ST パケットモード信号の取り扱い
LL Ethernet 10G MAC IP コアが入出力に用いる Avalon-ST 形式のポートはパケットモードが有効になっており、64bit データの他に、パケットの先頭を示す startofpacket、末尾を示す endofpacket、末尾データのうち無効長を示す 3 bit の empty 信号が含まれます。インテル HLS コンパイラーで高位合成モジュールを C 言語の関数のように書く時、Avalon-ST 入出力に相当する引数には ihc::usesPackets を指定することで対応できます。
しかし、HLS コンパイラの過去バージョン(例えば、17.1 スタンダード版)ではこの機能はサポートされておりませんでした。よって、筆者が書いた HLS モジュールはデータ型を 128bit に拡張し、128bit に下記構造体をマッピングすることによって実現しています。これによって過去バージョンの HLS コンパイラでも動作できる見込みが高いですが、パディングを行っているため回路面積が増大するなど、デメリット発生の可能性があります。
typedef struct L8_AVALON_ST_PKT_tag{
UINT64 data;
UINT8 sop;
UINT8 eop;
UINT8 empty;
UINT8 padding_no_use[5];
} L8_AVALON_ST_PKT;
このマッピングは HLS ではなく RTL で記述したモジュールによって行われています。
サンプルコード内の HLS モジュール群パイプラインの前後に接続された u8_to_ulong2 モジュール(avalon-ST 64bit packet-mode -> 128bit struct)及び ulong2_to_l8 モジュール(128bit struct -> avalon-ST 64bit packet-mode)がその役割を担っています。
現行バージョンではプロ版、スタンダード版ともに ihc::usesPackets がサポートされているようなので、今後記述のアップデートを行いたい所です。
12/4 追記:スタンダード版は 19.1 を最後にサポートが終了しています。今後はプロ版を使用していくように切り替える必要がありそうです。
小さな処理構造に分ける
2 章では ICMP echo reply の生成のために書き換える処理を 4 つに分けて記載しましたが、これらを最初から 1 モジュールで記載することはお勧めできません。まずはできるだけ細かく操作を分けて、単機能を行うフィルタモジュールを作り、それらを直列接続することでパイプラインを構成することをお勧めします。
直列処理をした場合、最初のデータ到着から応答パケット生成開始までのレイテンシはその分加算されていきますが、正しい記述を行えば毎サイクルデータ受付の能力(今回は 10Gbps での処理能力)は失われません。
1モジュール内で複数の処理を行えるようにした場合レイテンシを削減していける可能性がありますが、正しい動作が取れなくなる可能性や、動作周波数が下がり必要な速度を満たせなくなる可能性が上がっていきます。
今回の設計の場合、最大動作周波数が 156.25 MHz を下回ってしまうと、10G イーサネットと協調して動作することができなくなります。
一旦直列設計で動作を取ったあと、動作周波数や正しい動作を維持しながら同モジュール化できる処理を探していくことが得策と思われます。
関数の底からデータが湧き上がるように書く
当プロジェクトの ICMP 応答パイプラインの一つ、icmp_proc_param 関数(合成後はモジュールとして取り扱う)を例にとって説明します。当モジュールは「ICMP ヘッダ先頭 1 バイトのタイプフィールドを、ICMP echo request (0x08) から ICMP echo reply (0x00) に入れ替える」機能と、「パケットの中身を書き換えたことに合わせ、ICMP チェックサムを更新する」機能を持ちます。
2章で解説した MAC アドレスフィールド交換と違って遅延スロットは2個で、ICMP パケットを 8byte 単位に分割した時 5 番目にくる ICMP ヘッダを発見したら、遅延スロット #1 から #2 に移動するときに echo request フラグを echo reply フラグで置き換え、チェックサム部に計算済みのチェックサムを上書きするというものです。
ソースコードの対応箇所は https://github.com/homelith/c10gx_icmp_server/blob/main/src/icmp_proc/icmp_proc.cpp#L239 です。
#include "hls_component_param"
component void icmp_proc_param(
L8_AVALON_ST_PKT_RX_BUF8 &ch_dat_in,
L8_AVALON_ST_PKT_TX &ch_dat_out
){
static L8_AVALON_ST_PKT stage1;
static L8_AVALON_ST_PKT stage0;
static UINT8 stage1_idx;
static UINT8 stage0_idx;
static bool stage1_en = false;
static bool stage0_en = false;
static UINT8 idx_counter = 0;
// output stage
if (stage1_en) {
stage1_en = !( ch_dat_out.tryWrite(stage1) );
}
// stage1
if (! stage1_en & stage0_en) {
switch (stage0_idx) {
case 4 : {
UINT16 chksum = ~((UINT16)(stage0.data >> 16));
if (chksum < 0x0800) {
chksum --;
}
chksum = ~(chksum - 0x0800);
stage1.data = (stage0.data & 0xFFFF00FF0000FFFFULL)
| (((UINT64)chksum) << 16);
break;
}
default : {
stage1.data = stage0.data;
}
}
stage1.sop = stage0.sop;
stage1.eop = stage0.eop;
stage1.empty = stage0.empty;
stage1_idx = stage0_idx;
stage1_en = true;
stage0_en = false;
}
// stage0
if (! stage0_en) {
stage0 = ch_dat_in.tryRead(stage0_en);
if (stage0_en) {
stage0_idx = idx_counter;
idx_counter = stage0.eop ? (UINT8)0 : (UINT8)(idx_counter + 1);
}
}
return;
}
特徴として、この関数の中には for ループなどが含まれておらず、ループ展開を必要としません。厳密ではありませんが、「1 クロックごとに C 言語でのこの関数の呼び出し1回が行われる」イメージを持っていただくと理解しやすいかもしれません。マイコンなどで割り込みハンドラを用いた処理に習熟されている方は割り込みハンドラのようなものをイメージされてもいいかもしれません。この考え方を元に、毎クロック呼び出される関数で常に ch_dat_in ポートからデータ1つを読み出し、加工して ch_dat_out ポートに渡す処理を書いていきます。
HLS で Avalon-ST 型のポートの読み書きを行う場合は、データ到着 or 送出完了まで処理をブロックして停止する Read / Write 関数と、データがあるとき・即時送出可能な時だけ送受信を行い、そうでない場合は処理を行わない tryRead / tryWrite 関数があります。パケットなどの処理パイプラインにおいては、データ受信と送出は独立で常にデータ受け入れが可能なようにしたいため、tryRead / tryWrite 関数を使うことが多いでしょう。これは今回のコードでは、「送信ポートが現在ブロックされていてデータの送出待ち状態(tryWrite 関数が失敗してすぐに処理を戻す)になっていたとしても、遅延スロットに空きがある限りは新規データを遅延スロットに導入(tryRead)しておき、送信ポートが利用可能になり次第即座に次のデータの処理を開始する」ことを実現するために使用されています。
icmp_proc_param 関数には、stage1 (遅延スロット #2) の処理が関数の頭の方に、stage0 (遅延スロット #1) の処理が関数の終わりに配置されています。stage0 / stage1 はデータ格納用のレジスタで、該当レジスタにデータが存在するかのフラグを stage0_en / stage1_en で保持しています。
大まかに
・stage1 にデータがあるとき、出力ポートからの送出を試す。送出が成功したら、stage1_en を false にする。
・stage1 のデータが送出完了によって無くなり、かつ stage0 にデータがあれば、stage1 = stage0 として移し替える。移し替えが成功したら、stage0_en を false にする。
・移し替える時の特殊な条件として、パケット先頭から5番目のデータであるときのみ、stage0 のデータを加工(フラグ変更、chksum 埋込)して移し替える。
・stage0 のデータが stage1 に移し替えられることによって無くなっていたら、入力ポートからのデータ吸い出しを試す。
の順序で処理が行われます。
stage1 の処理が関数の頭にあり、stage0 の処理が関数の末尾にあり、処理の流れとしては直感に反する順序と感じられるかもしれません。しかし、仮に stage0 から順に記述した場合を想像してみてください。関数の最初の時点では出力ポートからのデータ出力が今サイクルで成功するかどうか、stage0 から stage1 へのデータ移動が成功するかが分からない状態になります。また、HDL での記述では stage0 へのデータ取り込みと stage0 -> stage1 へのデータ移動を同時に行う記述は簡単ですが、C 言語は上の行から順に実行していくものとして解釈されるため、stage0 にデータを取り込んでしまった時点で今サイクルで stage1 がデータの移動元として考えている stage0 のデータは上書きされて消えてしまいます。出力ステージを先頭に置き、順に入力ステージに向かって記述していくことで、これらの依存関係を整理しすっきりと記述することができる仕組みです。
同じ変数に対して読み書きをする場合は先に「参照」してから、後に「代入」をするのが良いでしょう。この時、参照される値は前のクロックサイクルの終了時に確定しているので、参照結果を用いるロジックは代入の完了を待たずに動き始め、高速な動作をすることが期待できます。一方、代入の後に参照してしまうと、その動作は 1 サイクルの中で直列に実行しようとされてしまい、クリティカルパスが伸びる結果となりがちです。重たい演算を含むロジック(例えば乗算、ルックアップ等)はできるだけ前のクロックサイクルで準備されたデータだけで即座に動作開始できるように工夫すると良い結果が得られるようです。それら「重たいデータは関数の底から湧き上がる」ように書くことを意識してみてください。
4. サンプルコードの公開と、動作環境等に関する tips
サンプルコードについて
今回使用したコード一式を https://github.com/homelith/c10gx_icmp_server に公開しております。
動作を保証するものでなく、使用されたことで起こった事象に関して筆者は責任を負えないことをご理解の上ご利用いただけると幸いです。
当リポジトリは CLI のみでのビットストリーム生成が 1 コマンドで行えるように Makefile 群を整備してあります。
おおまかには
・Intel HLS コンパイラの駆動によって HLS モジュール IP コアを生成する
・qsys-generate の駆動によって HLS モジュール、RTL モジュール、Quartus のビルトイン IP コア群を含めた全システムの HDL を生成する
・Nios II EDS プロジェクトを復元し、BSP のコンパイル -> プログラムのコンパイル -> プログラムメモリ用の mif ファイルを生成する
・ハードウェア部の HDL、ソフトウェア部の mif を合わせて、quartus_sh で CLI モードでコンパイルフローを実施する
といった手順で行われています。
FPGA プロジェクト用のソースコードをコミットすると自動ビルド・検証が行われるような CI/CD の仕組みを作るのにも有効かもしれません。
対応 OS に関して
今回のプロジェクトで使用している Nios II EDS プロ 20.1 及び HLS コンパイラ プロ 20.1 は オペレーティング・システム・サポート 情報によれば Windows 10 と RHEL 6 のみのサポートとなっています。
タイムリーな事に、RHEL 6 (及びそれのコミュニティ版となる CentOS 6)については数日前の 2020 年 11 月 30 日を以て、Redhat 社との個別の契約がある場合を除いて製品のサポートが終了しました。例えばこれから開発を始める方に、CentOS 6 系などの使用をおすすめすることは正直できない状況です。計算資源が豊富なサーバ用 OS として大きな位置を占める Linux 環境での利用が便利になっていくよう、今後の対応 OS 拡充に期待したいところです。
12/4 追記:
今日 OS サポートページを見ると、20.3 版のサポート状況に更新されていました。
それによれば、Nios II EDS プロと HLS Compiler プロについては RHEL 8 ではサポートされず、代わりに SUSE Linux Enterprise 12 でサポートされるようになったようです。
ただ、ここには Nios II EDS スタンダードも SUSE SLE 12 サポートの記載がありますが、Standard 版には 20.3 がなく、12/4 時点で 20.1.1 が最新です。20.1.1 で SUSE SLE 12 がサポートされるのかは調べる必要がありそうです。
Ubuntu 18.04 での動作について
公式にはサポートされておりませんが、Ubuntu 18.04.5 LTS で上記リポジトリの動作(特に、HLS コンパイラを使うときの co-sim)を取る方法がありましたので、参考に記載しておきます。自己責任の範囲にて、ご活用いただけますと幸いです。
- /etc/apt/source.list に xenial と trusty 追加, i386 対応, 4.4 系 gcc を導入します。
$ sudo dpkg --add-architecture i386
$ deb http://archive.ubuntu.com/ubuntu/ xenial main restricted universe multiverse
$ deb http://archive.ubuntu.com/ubuntu/ trusty main restricted universe multiverse
$ sudo apt install gcc-4.4 gcc-4.4-multilib g++-4.4 g++-7
$ sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 10 --slave /usr/bin/g++ g++ /usr/bin/g++-7
$ sudo apt install gcc-4.4 gcc-4.4-multilib g++-4.4 g++-7
- 32bit ライブラリや古めのライブラリ諸々を入れます。
$ sudo apt install libc6:i386 libx11-6:i386 libxext6:i386 libxft2:i386 libncurses5:i386 libncursesw5:i386 libpng12-0:i386 libpng12-0:amd64
- 19.1 以降 gcc は Quartus インストールに内蔵されるようになりましたが、modelsim 内でテストベンチをコンパイルしている箇所では OS の 32bit ライブラリに依存しているため、HDL co-sim が動きません。
- 恐らく centos では /usr/lib32 の下に libgcc.a などが配置されているものと推測しますが、それが無いため ubuntu では動かないものと思われます。
よって、/usr/lib32 に centOS ではあると思われるファイルを直接コピーして一時対処します。
(OS のアップデート時などに構造が崩れる可能性があるので、大事な環境には使用しないでください)
$ sudo cp -r /usr/lib32 /usr/lib32_bak
$ sudo cp -r /usr/lib/gcc/x86_64-linux-gnu/4.4/32/* /usr/lib32/
20.1 以降の情報はまだないようですが、過去のリリースにおいて公式サポートのない OS で動かすノウハウは
https://wiki.archlinux.jp/index.php/Altera_Design_Software
にも多く記載されています。
おわりに
FPGA でネットワークインタフェースを使用することが多く、新しいボードのネットワークポートの動作確認をするときの良いサンプルデザインがあればよいなと思ったことから、今回の記事を書くに至りました。
また、バッチ処理型の動作記述に良く使われるイメージのある高位合成記述をパケット処理に応用するテクニックについても、「手続き型で書くことを自ら放棄して、C 言語で RTL を記述している」ような書き方なので万人のお役に立つものではありません。しかし、RTL で書く時の構造が既に頭に浮かんでいるとき、RTL に比べて記述量を減らして楽ができると考えれば一定の利用価値があるのではと考え、解説を書いてみました。
これら日頃の取り組みをアウトプットできる機会を頂きました当カレンダー企画に感謝いたします。
これからも楽しんで FPGA 用のコード開発を続けて行こうと思います。