CLIP: Connecting Text and Images
2021年1月5日にOpenaiが提案した、web上に豊富にある画像とテキストのペアのみの学習で、ImageNetやその関連データセットで高い精度での分類を可能にしたCLIPです。この文章は以下のブログを要約したものであり、図などはすべてここからの引用です。
参考:公式ブログ
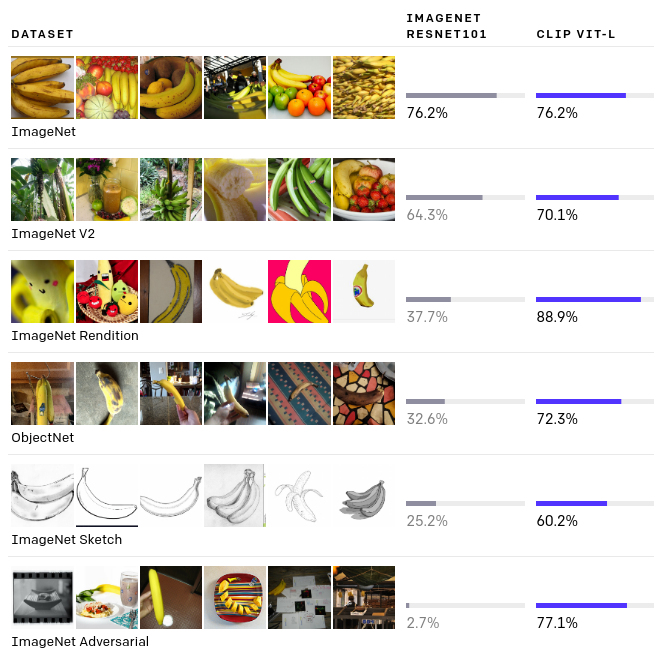
近年の深層学習の発展は目覚ましいものがありますが、その精度は学習したデータセットでしか発揮されない、という課題があります。
以下の図において、IMAGENETRESNET101ではImageNetをResNetで学習しそのままほかのデータセットを含んで評価した精度を、CLIP VIT-Lでは今回提案された、ネット上からの画像とテキストのみで学習し、同じデータセットで精度評価した結果が示されています。IMAGENETRESNET101の列が示すように、学習したデータセットでは精度は高いものの、そうではない画像では精度が低いことが示されています。
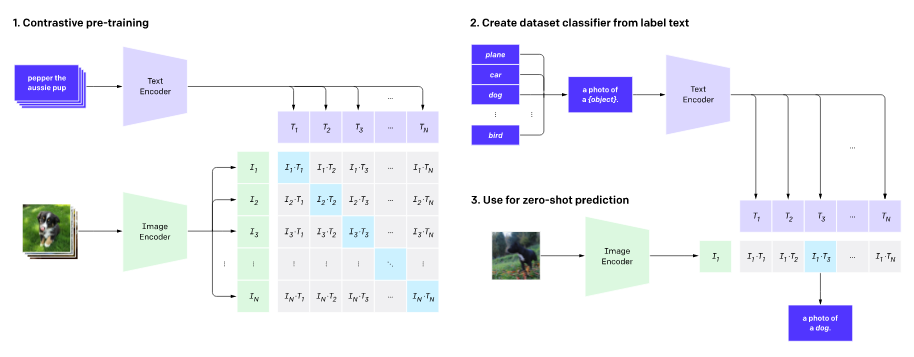
この課題を解決するために提案されたCLIPではNeural Language visedなモデルを提案しています。まず、ネット上から画像とテキストのペアを大量に取ってきます。(下の図の例だと犬の画像と"pepper the aussie pup")次に画像とテキストをそれぞれエンコードします。実装をみるとImage encoderにはVisual Transformerが、Text encoderにはTransformerが使われていました。このエンコードされた画像とテキストはバッチ間で内積がとられます。$T_i$がエンコードされた$i$番目のバッチ、$I_i$がエンコードされた$i$番目のバッチを表し、$dot(T_i,I_j)$がすべての$i,j$について計算されます。そして対応するバッチとの内積の値が高くなるようにCrossEntropyLossがかけられます。数式で表すと以下のようになります。ここで$I@(T.t)$はエンコードされた画像IとテキストTの転置の行列積を、Bはバッチサイズを表します。
$$loss=loss_i+loss_j$$
$$loss_i=CrossEntropyLoss(I@(T.t),range(B),dim=0)$$
$$loss_j=CrossEntropyLoss(I@(T.t),range(B),dim=1)$$
以下ではInferenceについて説明します。上記のようにして学習されたモデルを用いて、"a phase of a {object}"をモデルのtext_encoderに入力します。objectにはcatやdogなどの推測したいクラス群が入ります。そして画像をエンコードし、エンコードされたテキストとの内積をとることで、どのクラスが一番近いかを得ます。
このようにして、様々なデータセットで評価した結果が始めに示した図です。繰り返しではありますが、このCLIP VIT-Lではwebから取得した画像とテキストのみで学習を行っており、データセットのtrainsetは全く使っていません。かなりの一般性をもって高い精度で分類できていることがわかります。
一方で課題もあります。画像内の物体の個数を数えたり、花の種類の分別など、抽象的または細かいデスクではほぼあってずっぽうな結果だったそうです。またMNISTでの精度は88%であり、人間の99.75%を大きく下回っています。CLIPは言葉使いや言い回しに敏感な可能性があり、入力には試行錯誤が必要であるとも述べられています。
以下は感想です。課題はありますが、Neural Language drivenという新しい学習スキームを用いて、zero-shotで多くのデータセットでここまでの精度が出せたことは凄いことだと思います。学習データづくりに苦労する日々の終焉も意外と早いのかもしれません。