グラフのスペクトル疎化(Spectral Sparsification) はスペクトルグラフ理論に関するトピックで 2004 年の [10] の論文に端を発し, 今に至るまでこの 15 年間界隈でとても注目されています.
本記事ではその概念を説明するとともに, なかでもブレイクスルーとなった 2008 年の [9] で紹介されたアルゴリズムについてざっくりと解説したいと思います.
想定される読者
大学基礎課程の線形代数の知識がある方であれば概要はつかめると思います. 基本的なグラフ理論の知識があるとより理解がしやすいです.
準備
本記事では, 簡単のため 連結な重みなし無向グラフ についてのみ考えます. 連結性, 重みの有無は本質的に重要ではありません.
グラフ $G=(V, E)$, 頂点数, 辺数 $n = |V|$, $m = |E|$ のように表すとします.
次にグラフの 点枝接続行列 と ラプラシアン行列 について説明します(すでに知っている方は飛ばしていただいてかまいません).
グラフの点枝接続行列 $\mathbf{B} \in \mathbb{R}^{m\times n}$ は以下の図のように定義されます.

各辺を適当に向き付けて対応する要素を $1, -1$ とします.
つぎにラプラシアン行列 $\mathbf{L} = \mathbf{B}^\top \mathbf{B}$ は以下のようになります($\mathbf{B}$ の向き付けによらず 一意 に定まります).

対角成分は 各頂点の次数, 非対角成分は -(隣接行列) と見ることもできます.
重要な事実として, グラフのラプラシアン行列の 固有値 はその特徴を よく記述する ことが知られています. こちらについては都合により省かせて頂きます.
※ 詳しくは例えば Connectivity, Spectral Clustering, Cheeger Inequality, Mixing Time などのキーワードで調べてみると面白い知見が得られると思います.
スペクトル疎化の定義とその応用
スペクトル疎化とは一言で言うと 密なグラフをその特徴を保ったまま重要な辺だけを残した疎なグラフに変形すること です.

変形してできた疎なグラフをもとのグラフの spectral sparsifier と呼び, そのような変形を グラフのスペクトル疎化(spectral sparsification) と呼びます. (以降 spectral sparsification と書きます.)
厳密に "グラフ $H$ がグラフ $G$ の $\epsilon$ - spectral sparsifier である" とは $H$ が以下の条件を満たし, かつその辺数が小さい $\left( m = \mathrm{o}\left(n^2\right) \right)$ と定義することにします.
(1-\epsilon) \mathbf{L}_G \preceq \mathbf{L}_H \preceq (1+\epsilon) \mathbf{L}_G
ここで, $\mathbf{L}_G, \mathbf{L}_H$ はそれぞれグラフ $G, H$ のラプラシアン行列を表し, 関係 $\preceq$ は "$\mathbf{A} \preceq \mathbf{B} \Leftrightarrow \mathbf{B}-\mathbf{A}$ が半正定値行列" と定義することとします.
上の定義と Courant-Fischer の定理からすべての $i$ について, $\mathbf{L}_H$ の $i$ 番目に大きい固有値が $\mathbf{L}_G$ の $i$ 番目に大きい固有値の $(1 \pm \epsilon)$ 以内に入っていることが言え, グラフ $H$ はグラフ $G$ の特徴をよく保存することを保証しています.
応用例および関連する分野
グラフのラプラシアン行列を直接扱うような スペクトルクラスタリング などの機械学習アルゴリズム全般に応用が考えられます. また一度 spectral sparsifier を構築すれば疎化の恩恵として計算時間の高速化も可能になり, 繰り返し同種の問題を解くような場合(交差検定 など)との相性が良いです[3].
本記事ではラプラシアン行列についてのみ述べていますが, これを 半正定値行列に 拡張しても同様の疎化を考えることができます. そのため 線形回帰 $|| \mathbf{A}\mathbf{x} - \mathbf{b} ||_2$ でのデータ行列 $\mathbf{A}$ から重要なデータのみを残すような疎化にも直接応用することが可能です.
次に spectral sparsifier を構築する上での肝となる 各辺の重要度の指標 について説明します.
実効抵抗との関係性
結論から述べると, spectral sparsifier を構築する上でその辺を残すべきか否かを決める重要度の値は $i$ 番目の辺について $\mathbf{b}_i^\top \mathbf{L}_G^+ \mathbf{b}_i$ と定めるとうまくいきます.
ここで $\mathbf{b}_i^\top$ は $\mathbf{B}_G$ の $i$ 番目の行ベクトル, $\mathbf{L}_G^+$ は $\mathbf{L}_G$ の Moore-Penrose 擬似逆行列とします.
...と言われてもさっぱりイメージが湧かないと思いますのでイメージをつかむためにここでグラフの辺を抵抗値 1 の抵抗とみた電気回路を考えたいと思います.
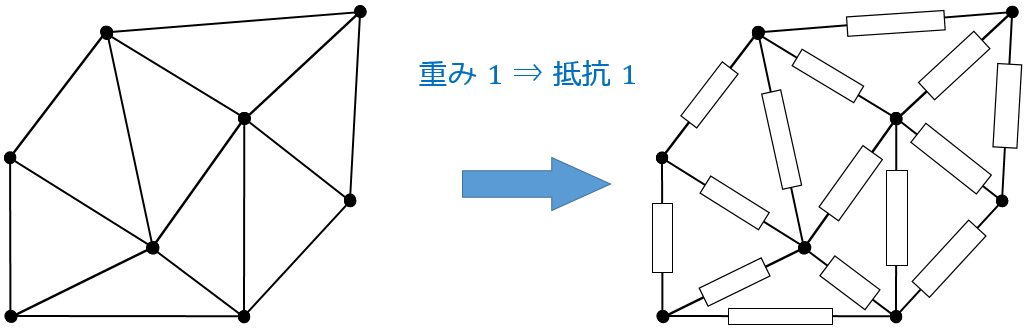
このとき先ほどの各辺の重要度の値がその間の 実効抵抗 の値と等しいことが知られています.
ここで頂点 $a, b$ 間の 実効抵抗 $\left( \mathbf{R}_{\left(a,b\right)}\right)$ とは "$a$ から $b$ に電荷を $1$ 流したときに生じる $a, b$ 間の電位差" のことを言い, $a, b$ 間の電気回路を1つの抵抗とみたときの抵抗値に等しいです.

実際に実効抵抗が重要度の値に等しいことを理解するために 1 つ例を見てみましょう.
(注) $\mathbf{b}_i^\top \mathbf{L}_G^+ \mathbf{b}_i$ (重要度の値) は $0$ から $1$ の間の値をとり, $i$ についての総和をとると $n-1$ になります.
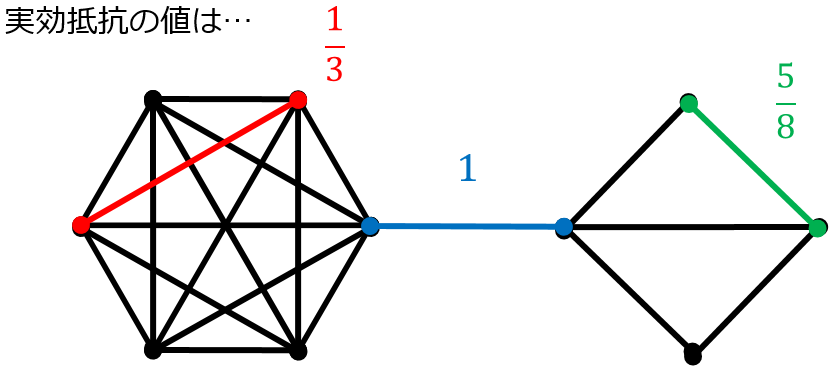
青の辺は取る取らない(残す残さない)でグラフの連結性が変化することからも分かるようにグラフの特徴を保つ上で 欠かせない 辺です. これは実効抵抗が最大値の $1$ をとることと合致しています.
赤の辺は取らなくても全体の構造に そこまで影響はでない だろうという感じがしますが実効抵抗の値はその直感と合致していることが分かります.
次にいよいよこの "重要度の指標" を用いて spectral sparsifier を構築するアルゴリズムについて説明したいと思います.
アルゴリズム
この章では任意のグラフ $G$ に対して時間計算量 $\mathrm{O} \left( m \log^2 n \right)$ で, 辺数 $\mathrm{O} \left( n \log n / \epsilon^2 \right)$ の $\epsilon$ - spectral sparsifier を高い確率 $(1 - 1 / \mathrm{poly}(n))$ で返すアルゴリズムについて説明します.
といってもアルゴリズム自体はシンプルで, 以下の操作を $q = \Theta \left(n \log n / \epsilon^2 \right)$ 回繰り返すだけです.
(操作)
グラフ $G$ に含まれる各辺 $e$ をその重要度に比例する確率 $p_e = \mathbf{b}_e^\top \mathbf{L}^+ \mathbf{b}_e / (n-1)$ でランダムにサンプリングし, グラフ $H$ に重み $1 / qp_e$ の辺 $e$ を加える.
こうしてできたグラフ $H$ は高い確率でもとのグラフ $G$ の $\epsilon$ - spectral sparsifier となります.
(注) $n-1$ は確率の和を $1$ にするための factor で, また同じ辺が 2 度以上サンプルされた場合は新たな辺を加えずその重みをすでに存在するものに足しあげることとします.
アルゴリズムの詳しい話
少し専門的な話になるので, この章はスキップしていただいて問題ありません.
Q. なぜ $\mathrm{O} \left( n \log n / \epsilon^2 \right)$ 回?
A. それだけ繰り返すと高い確率で, 得られるグラフ $H$ のラプラシアン行列 $\mathbf{L}_H$ が $\mathbf{L}_G$ の $(1 \pm \epsilon)$ 倍以内に入ることが知られているからです[11].
毎ターン、 $n$ 種類のクーポンのうち 1 つが等確率で得られるときに $n \log n$ 回くらいのターン数を繰り返すと高確率で各種類少なくとも 1 つ以上のクーポンを手に入れられるという クーポンコレクター問題 のイメージに近いです.
Q. 時間計算量 $\mathrm{O} \left( m \log^2 n \right)$ と言っているけどそんな計算時間では $\mathbf{b}_e^\top \mathbf{L}_G^+ \mathbf{b}_e$ の計算ができないのでは?
A. 実を言うと, この部分がこの論文のすごいところです.
ここには、
(i) 本当は各辺の重要度の値 $\mathbf{b}_e^\top \mathbf{L}^+ \mathbf{b}_e$ は exact に求める必要はなく定数近似さえ求まれば十分[5].
(ii) また $\mathbf{b}_e^\top \mathbf{L}^+ \mathbf{b}_e$ は $e=(a,b)$ としたとき, ある $m$ 次元ベクトル $v_a, v_b$ 間の Euclid 距離に対応している(これは式変形で分かる).
(iii) 上記の $n$ 個の $m$ 次元ベクトル $v_i (i \in V)$ のすべてのペアについてその間の Euclid 距離を良く保存するような $\Theta \left(\log n \right)$ 次元空間への線形射影 $\Pi$ が存在する(以下で述べる).
(iv) 最後に、 射影後の空間における $n$ 個のベクトル $\Pi v_i$ を求めるためには実は広義優対角行列を係数行列とする連立方程式解けば良いことが分かる. そのような連立方程式の近似解は高速に求めることができる[6].
といった 非自明要素 が詰まっています(今までざっくりと簡単に説明していたツケがここに回ってきた感じです).
(iii) の部分は Johnson-Lindenstrauss Lemma に基づく手法を用いていて他の論文でもよく見かける有名な手法なので明日使える定理として以下にステートメントを記しておきます.
Database-friendly Random Projections [Achlioptas 2001]
$n$ 個の $d$ 次元ベクトルを $v_1, \ldots, v_n \in \mathbb{R}^d$、 精度ファクターを $0 < \epsilon < 1$ とする. 各要素 $\pm 1 / \sqrt{k}$ のどちらかを一様ランダムに取ってできた $k \times d$ 行列を $Q$ とする. ただし $k \ge 24 \log n / \epsilon^2$ とする.
このとき $1 - 1 / n$ 以上の確率で、すべての添字の組 $(i, j)$ について以下の不等式が成り立つ.(1-\epsilon) \| v_i - v_j \|^2_2 \le \| Qv_i - Qv_j \|^2_2 \le (1 + \epsilon) \| v_i - v_j \|^2_2
Euclid ノルムをよく保つような $\Theta \left( \log n \right)$ 次元への線形変換が存在するのはかなり驚きです. ただ残念なことに任意の $L_p$ ノルム $\left( p \in [1, \infty] \setminus { 2 } \right)$ についてそのような線形射影が存在しないことも分かっています.
話が逸れましたが、その他の部分については何のことかよく分からないと思いますのでより詳しく気になる方は元論文をあたってください.
※上のパートでいくつか [9] の論文より後に出た論文を参照していますが, これは後に分かった 計算量の改善 を意味しています.
最後にですが, ここで $m$ が $\epsilon^{-2}$ と比べて大きいということを仮定しているので, 時間計算量に $\epsilon$ が陽に出てきていません.
最近の話題
2019 年 2 月現在, 最近の話題として 3 つ論文を紹介します.
(I) Almost-linear-time algorithms for markov chains and new spectral primitives for directed graphs. (STOC '17) [4]
この分野を切り開いてきた研究者たち 7 人によって書かれた 有向グラフ について Spectral Sparsification を考えようという論文です.
ちなみに有向グラフのラプラシアン行列は非対称で, $\left( \mathbf{L}+\mathbf{L}^\top \right) /2$ という対称化を施しても半正定値とは限らないといったかなり性質の悪い行列です.
(II) An SDP-based algorithm for linear-sized spectral sparsification. (STOC '17) [7]
計算量を $\mathrm{o} \left(m^2\right)$ に保ったまま、疎化したあとのグラフの辺数を $\mathrm{O}(n / \epsilon^2)$ と本記事で述べたものよりも $\log n$ 小さい spectral sparsifier を構築するアルゴリズムを紹介した論文です.
ちなみに spectral sparsifier の辺数の lower bound は $\mathrm{O} \left( n / \epsilon^2 \right)$ であることが知られているので[2], このアルゴリズムは lower bound を達成する spectral sparsifier を高速に構築するものといえます.
(III) Spectral Sparsification of Hypergraphs. (SODA '19) [8]
東京大学の相馬さんとNIIの吉田さんによって書かれた ハイパーグラフ についての Spectral Sparsification を構築しようという論文です.
この論文では実際にハイパーグラフの Spectral Sparsification $\left( \text{辺数 } \mathrm{O}\left( n^3 \log n / \epsilon^2 \right) \right)$ を構築する多項式時間アルゴリズムを与えています.
参考文献
[1] D. Achlioptas: "Database-friendly random projections." In Proceedings of the 20th ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems (PODS). 2001.
[2] J. D. Batson, D. A. Spielman, and Nikhil Srivastava: "Twice-ramanujan sparsifiers." In Proceedings of the 41st Annual ACM Symposium on Theory of Computing (STOC). 2009.
[3] D. Calandriello, et al: "Improved large-scale graph learning through ridge spectral sparsification." International Conference on Machine Learning (ICML). 2018.
[4] M. B. Cohen, et al: "Almost-linear-time algorithms for markov chains and new spectral primitives for directed graphs." In Proceedings of the 49th Annual ACM-SIGACT Symposium on Theory of Computing (STOC). 2017.
[5] I. Koutis, A. Levin, and R. Peng: "Improved spectral sparsification and numerical algorithms for SDD matrices." In Proceedings of the 29th Symposium on Theoretical Aspects of Computer Science (STACS). 2012.
[6] I. Koutis, G. L. Miller, and R.Peng: "A nearly-m log n time solver for sdd linear systems." In Proceedings of IEEE 52nd Annual Symposium on Foundations of Computer Science (FOCS). 2011.
[7] J. R. Lee, M. Mendel, and A. Naor: "Metric structures in L1: dimension, snowflakes, and average distortion." European Journal of Combinatorics, 26.8, 1180--1190, 2005.
[8] Y. T. Lee and H. Sun: "An SDP-based algorithm for linear-sized spectral sparsification." In Proceedings of the 49th Annual ACM-SIGACT Symposium on Theory of Computing (STOC). 2017.
[9] T. Soma and Y. Yoshida: "Spectral Sparsification of Hypergraphs." In Proceedings of the 30th Annual ACM-SIAM Symposium on Discrete Algorithms (SODA). 2019.
[10] D. A. Spielman and N. Srivastava: “Graph sparsification by effective resistances.” In Proceedings of the 40th Annual ACM-SIGACT Symposium on Theory of Computing (STOC). 2008.
[11] D. A. Spielman and S. H. Teng: “Nearly-linear time algorithms for graph partitioning, graph sparsification, and solving linear systems.” In Proceedings of the 36th Annual ACM-SIGACT Symposium on Theory of Computing (STOC). 2004.
[12] J. A. Tropp: "User-friendly tail bounds for sums of random matrices." Foundations of Computational Mathematics, 12.4, 389--434, 2012.