はじめに
画像認識において、識別器がどこを注目して認識したかを可視化することは重要です。
CNNでは、損失関数の勾配をバックプロパゲーションで入力画像まで伝搬し、その絶対値の強度を可視化する方法が提案されていますが、ノイズが多いという問題がありました。
SmoothGradでは、入力画像にガウシアンノイズを与え、複数の勾配を平均するだけで、きれいな可視化でできるという、とても簡単な方法です。

平均化される様子
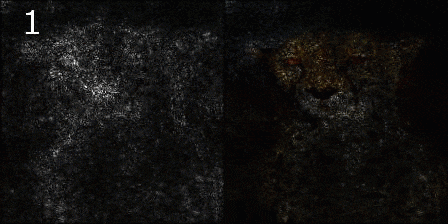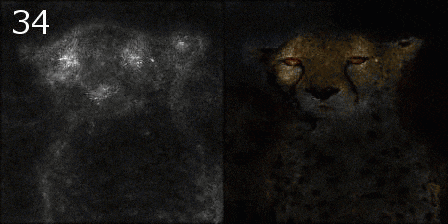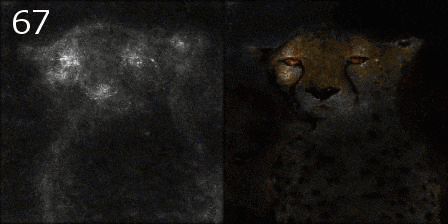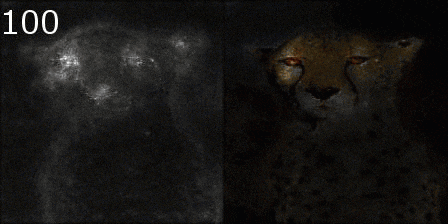
Smooth Grad

Vanilla Grad(従来手法)
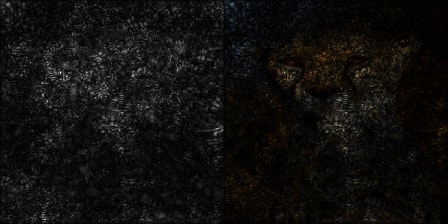
TensorFlowのコードや論文は下記からダウンロードできるようです。
https://tensorflow.github.io/saliency/
Chainer v2の勉強を兼ねて、SmoothGradを実装してみました。
モデルには、学習済みのVGG16モデルを使っています。
環境は、
Windows7 64bit
Python 3.5.2 |Anaconda 4.2.0 (64-bit)
chainerのversionは'2.0.0'です。
GPUには対応していません。
実装
import
import chainer
import chainer.functions as F
from chainer.variable import Variable
from chainer.links import VGG16Layers
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
config
テストモードで行いますが、バックプロパゲーションは行う必要があるので、
chainer.configを以下のように設定します。
chainer.config.train=False
chainer.config.enable_backprop=True
VGG16モデルのロード
VGG16モデルをロードします。
モデルは500MB程度あるので、事前にダウンロードされていない場合は、それなりに時間がかかります。
model = VGG16Layers()
画像の読み込みと前処理
VGGは画像サイズが224x224なのでリサイズしておきます。
image = Image.open("cheetah.png")
image = image.resize((224,224))
パラメータ
サンプリング数とノイズレベルを設定します。
サンプリング数は100、ノイズレベルは20%としています。
sampleSize = 100
noiseLevel = 0.2 # 20%
sigma = noiseLevel*255.0
勾配計算
使用メモリの関係上、今回は一枚ずつ行うことにします。
まず、VGG16ではチャネルの並びがBGRなので変換し、平均値を引きます。
次に画像のノイズを加えながら、順伝搬、ロスを計算し、逆伝搬することで勾配を計算します。
求めた勾配は、リストに追加しておきます。
gradList = []
for _ in range(sampleSize):
x = np.asarray(image, dtype=np.float32)
# RGB to BGR
x = x[:,:,::-1]
# 平均を引く
x -= np.array([103.939, 116.779, 123.68], dtype=np.float32)
x = x.transpose((2, 0, 1))
x = x[np.newaxis]
# ノイズを追加
x += sigma*np.random.randn(x.shape[0],x.shape[1],x.shape[2],x.shape[3])
x = Variable(np.asarray(x))
# FPして最終層を取り出す
y = model(x, layers=['prob'])['prob']
# 予測が最大のラベルでBP
t = np.zeros((x.data.shape[0]),dtype=np.int32)
t[:] = np.argmax(y.data)
t = Variable(np.asarray(t))
loss = F.softmax_cross_entropy(y,t)
loss.backward()
# 勾配をリストに追加
grad = np.copy(x.grad)
gradList.append(grad)
# 勾配をクリア
model.cleargrads()
可視化
勾配の各チャネルの絶対値の最大値を取り、画像に対して平均を取ります。
G = np.array(gradList)
M = np.mean(np.max(np.abs(G),axis=2),axis=0)
M = np.squeeze(M)
plt.imshow(M,"gray")
plt.show()

結果
平均する枚数を増やしながら、元画像とマップを画素ごとにかけて可視化してみました。
1サンプル
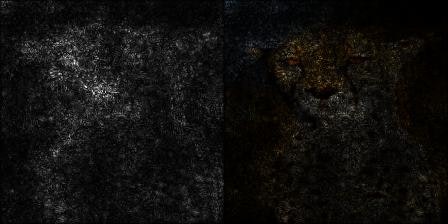
2サンプル

3サンプル

10サンプル

20サンプル

30サンプル

50サンプル

75サンプル

100サンプル
ノイズを与えずに、一枚のサンプルから可視化すると以下のようにノイズが多く見られます。