はじめに
2年前のAdvent Calendarで、GAE/Goのハマったところ(´・ω・`)という記事を書きました。
当時betaだったGAE/Goもその後めでたく正式リリースされ、最近では徐々に大きな会社や案件での採用事例も聞こえるようになってきました。数年前の状況を考えると涙がちょちょぎれる程感慨深いです(ToT)
2年前の記事ではGAEのGo SDKに特化したハマりポイントを紹介しましたが、今回はGAE(Google App Engine)自体のハマりポイントを書こうと思います。最近GAEを使い始めた人も多いかと思いますので参考になれば幸いです。
注:GAE runtime共通の話題を取り上げますが、コード例はGAE/Goで書きます
Datastore Index爆発でハマった(´・ω・`)
GAE Datastoreではカスタムインデックスを作ることで、通常では行えない条件の検索が可能になります。
例えば、FROM Hoge WHERE A="xx" AND B="yy" AND C > 999 ORDER BY C の様な条件は、カスタムインデックスなしではエラーになりますが、
- kind: Hoge
properties:
- name: A
- name: B
- name: C
というカスタムインデックスを作っておくと実行できる様になります。
ここで一つ罠があります。
Datastoreはコレクションプロパティというものがあり、配列の様な形のプロパティを持つことが出来ます。
コレクションプロパティに対してもカスタムインデックスを設定することが出来るのですが、例えば上記例のA,B,Cそれぞれが100件ずつのコレクションプロパティだった場合、1エンティティ保存に対して100x100x100=1,000,000個のインデックスが保存されることになります。これを俗にインデックス爆発と呼びます。
今年から料金体系が変わってインデックス保存に対して書き込み操作に課金がかからなくなりましたが、それでもストレージ料金や更新処理速度に悪影響が出ますのでご注意ください。
解決策
カスタムプロパティに複数のコレクションプロパティを設定するのは極力やめましょう。どうしても必要な場合は組み合わせ数を考慮しながら利用しましょう。
FYI: Index Limits
Datastore トランザクション競合でハマった(´・ω・`)
FYI: Transactions
GAE DatastoreにはEntity Groupという仕組みがあり、Keyに親子関係を作っておくことで、そのグループに属するKeyに対してトランザクション処理(Commit/Rollback)を行うことが出来ます(親子関係を持たない単一のKeyも1Entity Groupとして数えます)。
また、Cross Group Transactionを使うと、Entity Group25個まで1トランザクションに含めることが出来ます。
昔に比べると格段に強力になったトランザクション機能ですが、調子に乗って使いすぎると罠にハマります。
特にハマりやすいのがロック競合です。
同じEntity Groupに対して別々のトランザクションから同時に更新が走った場合、楽観的排他処理により後からcommitしたトランザクションがエラーになります。
頻繁に更新されるデータにEntity Groupを設定したり、Entity Groupをあまり巨大にしたりすると、ロック競合が起きやすくなります。
また、平時の更新頻度を考慮して適切にEntity Groupを適切に設定していたつもりでも、ある日夜間一括更新バッチを流したら競合が頻発した、という不具合も実際にありました。
解決策
- 基本的にEntity Group使わなくて済むのなら使わない
- 必要ならば、まずは更新頻度を考えてEntity Groupを設計する
- バッチ処理は極力Entity Group毎にまとめて更新する
- カウンタの実装にシャーディングを検討する
Datastoreトランザクション内のGetでハマった(´・ω・`)
トランザクション内でPutした値を同じKeyで再度Getしても、更新前の値を取得してしまいます!
err := datastore.RunInTransaction(ctx, func(ctx context.Context) error {
var hoge Hoge
if err := datastore.Get(ctx, key, &hoge); err != nil {
return err
}
log.Printf("before - %s\n", hoge.Value) // hoge
hoge.Value = "updated"
// Update!
if _, err := datastore.Put(ctx, key, &hoge); err != nil {
return err
}
// ここでGetし直しても更新後の値(Value="updated")は取得出来ない
if err := datastore.Get(ctx, key, &hoge); err != nil {
return err
}
log.Printf("after - %s\n", hoge.Value) // still hoge
return nil
}, nil)
解決策
そういう仕様です。覚えておきましょう(^^)
FYI: Isolation and consistency
そもそもトラザクション内で同じエンティティを繰り返しGetすること自体が無駄なAPI Callのはずです。ロジックを見直しましょう。
TaskQueueのリトライでハマった(´・ω・`)
TaskQueue(主にPUSH)はエラー終了すると無限にリトライします。
それにより、いつかは処理が完了することを担保します。
しかし、TaskQueue処理は気をつけて実装しないと罠にハマります。
例えば、TaskQueue処理内で自動生成IDでDatastore Entityを保存したとします。そのトランザクションCommit後に何らかのエラーが発生した場合、リトライの度に新しいEntityが保存され続けてしまいます。
解決策
TaskQueue内で新規にEntityを保存する場合は、IDを呼び出し側で生成し、パラメータで渡す様にしましょう。
上記の様な処理に限らず、TaskQueueの様なリトライ前提の処理を書く場合は、処理を冪等(何度実行しても結果が変わらない)に記述する必要があります。
Search APIのインデックス制限でハマった(´・ω・`)
GAEはSearch APIというテキスト検索APIを提供しています。Search APIを使うとDatastoreでは通常できない全文検索や、OR検索などを行うことができます。
Search APIはDatastoreのQueryを補完する使い方ができて非常に便利なものですが、Datastore Queryに比べて欠点もあります。
Datastoreのインデックスはお金さえ払えばほぼ無制限にデータを保存していくことが出来、Queryもインデックスを適切に設定・使用する限りはデータ量に関係なく高速に処理することが出来ます。
それに対してSearch APIはインデックスサイズに制限があります。インデックス毎の最大サイズが10GB、Googleにリクエストすると拡張可能の様ですが限度はあると思われます。
つまりデータがずっと増え続けるようなアプリケーションで使用していると、どこかで制限に達してAPIが失敗する様になります。
解決策
- cronで古いインデックスを削除するなどしてサイズ増加を抑制する
- 例えばユーザー毎に独立した情報などは、ユーザー毎に別のインデックスを作る(インデックスの管理が大変になるのであまり実用的ではないかも・・)
Search APIのソートでハマった(´・ω・`)
各ドキュメントはrankというフィールドを持っています。ソートを明示的に指定しない場合、検索結果はrank降順でソートされた状態で返されます。
rankは保存時に明示的に設定もできますか、省略した場合はドキュメント保存時間(2011/1/1からの秒数)が設定されます。
つまり意識しない場合ドキュメントの新しい順にソートされるのですが、以前バッチ処理でインデックスの再構築を行った際うっかり新しいデータから順にループしてインデックス再構築した為にrankの順序がごっそり反転されてしまい、以降検索結果が全て逆順になってしまった事故がありました。
解決策
- rankにはデフォルト値を設定するのではなく、元データの登録日時などを明示的に設定する
- rankはおそらく32bit integer(GAE/Go SDKではなぜかint64だが)なので、日時を指定する場合はデフォルト仕様に習って特定日時からの秒数を設定するとよい1
Search APIのソートでハマったその2(´・ω・`)
実はSearch APIで、rank以外に対してソートする場合制限があります。
ソートオプションのLIMIT(デフォルト1,000、MAX10,000)を超える結果を返す場合に順序が保証されません。
具体的には、Search APIはまずrank降順でデータを照会していき、hit数がLIMITに達するとそこで検索をストップし、指定されたソートを行います。
つまり、指定したソートでは本来上位にhitするはずのデータが、rankが低いと検索結果に現れない可能性があります。
解決策
- rank以外のソートをする場合はhit数がソートLIMITを超えない様に設計する
- ソートに利用したい値をrankに入れておき、rankでソートする。ただし、rank32はbit integerのため使用できるデータは限られる。また、rankの重複が多いと検索パフォーマンスに悪影響を及ぼすので要注意
- 例えば直近のデータが重要で古いデータを無視してよいユースケースであれば、rankに登録時刻(デフォルト)が設定されていれば、直近LIMIT件数内でソートがかかるので要件を満たせるかもしれません
Edge Cacheの有効期限でハマった(´・ω・`)
GAEはCache-Controlヘッダつけてレスポンス返すとGoogleのキャッシュサーバーにキャッシュが乗ります。
FYI: GCP エッジキャッシュ by @sinmetal
エッジキャッシュはとても強力ですが明示的に削除する方法がない為、うっかり単位を間違えてmax-ageを遥か未来に設定してしまったりすると、キャッシュが残ったまま変更できなくなってしまいます。
URLにクエリ文字列くっつけてキャッシュ無効化出来るリソースだったらよいですが、例えば/とか/index.htmlとかのレスポンスで間違って設定してしまうと大惨事ですね(´・ω・`)
解決策
気をつけましょう・・・としか言えない。。
GAE/Javaのspin-up遅くてハマった(´・ω・`)
最後は、runtime共通ではなくGAE/Javaの話になりますが・・
GAEは(設定によってある程度は変えられますが)基本的にリクエストがくると自動的にサーバーが起動します。これをspin-upと言います。
皆さんご存知の通りGAE/Javaは特にspin-upが遅いです。四天王(Go,Python,PHP,Java)の中でも最弱です。
↓だいぶ前の計測ですが、今もそれほど変わっていないと推測
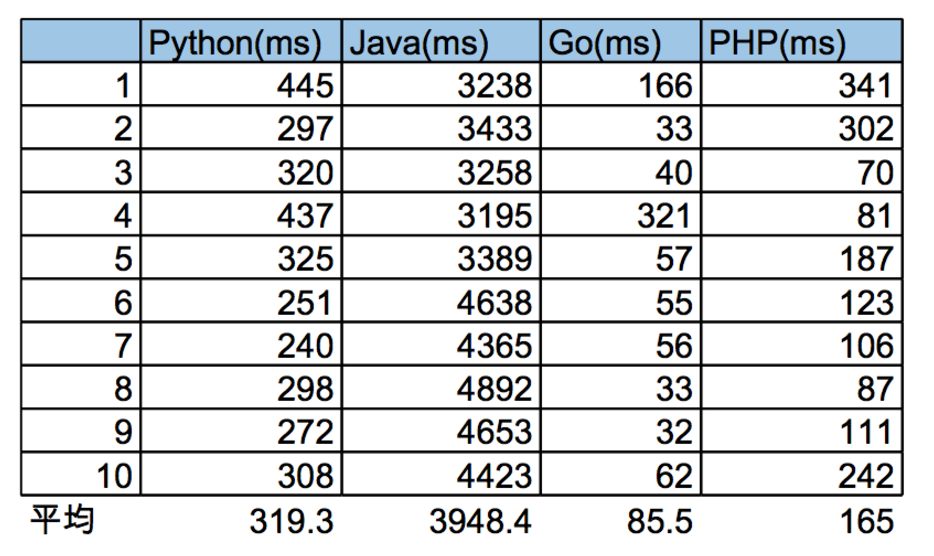
Javaが遅い主な理由はサーバー起動時のクラスロードにかかる時間です。特にMVC系のフレームワークやDIコンテナなどによってはアプリに必要なクラスを初回起動時に全てロードする仕組みになっていることが多いので、非常に時間がかかります。
以前かなり大きなアプリをGAE/Java & Springで書いているプロジェクトを見たことがありますが、そこでは最終的にspin-upに数十分かかる様になってしまい、Springのコードを全てSlim3で書き直していました。
解決策
GAE/Go使いましょう!\(^o^)/
GoじゃなくてもJava以外だったら何でもよいです。大分マシになるはず。。
どうしてもJavaを使いたいのであれば、slim3の様なリクエストごとに必要なクラスのみをロードするフレームワークを使いましょう。但しslim3は最近メンテされていない様なので使用は自己責任で。。
終わりに
GAE最近始めた方の中には、制限だらけで大変だなぁ、と思われている方もいらっしゃるかと思います。
ですが、殆どの制限はちゃんとした理論や理由に基づく制限で、その制限を乗り越えた先には圧倒的なScalabiltyとAvailabilityが待ってます!
\(^o^)/
来年もGAE、もっともっと盛り上がるといいな!
-
一応オーバーフローのタイミングは意識する様にしましょう。1900/1/1からの秒数にすると2038年に死にます(^^) ↩