はじめに
botプログラムによる機械的・連続的な入力を防ぐ目的で開発されたCAPTCHAという技術があります。人間にしか解けないような問題を解かせて、botの入力を排除するような仕組みの総称です。
CAPTCHAは誕生当初こそ有用な技術でしたが、いまや並のCAPTCHAではbotを防げない時代になりつつあります1。プログラム技術、特に機械学習の技術が発達した結果、テキスト認識については人間よりも機械の方が賢くなってしまったためです。
一方で、機械学習の知識がない普通のエンジニアからすると、CAPTCHAを破るプログラムを一から書けといわれても途方に暮れてしまいます。筆者もそんな一人ですが、機械学習APIを使えば機械学習の知識が無くてもCAPTCHAが破れるのではないか?と考えて試してみました。本稿ではその成果を紹介します。
CAPTCHAとは
すでに紹介したとおり、CAPTCHAは人間と機械を区別する技術です。アカウント作成の自動化やパスワードリスト攻撃など、botがビジネス上の脅威になるような場合に利用されます。
CAPTCHAという名前でピンと来ない人でも、Webサイトの会員登録ページやログインページなどで次のようなものを見たことがあるのではないでしょうか。これがCAPTCHAです。

このCAPTCHAは画像中のテキストを認識してASCII文字列を入力させるものです。最近では与えられた画像から自動車だけを選ぶなどのテキスト認識以外のCAPTCHAも増えてきましたが、初期のCAPTCHAはすべてテキスト認識でした。
CAPTCHAの歴史は古く、世界初のCAPTCHAは1997年にAltaVista2で開発されました。当時のAltaVistaは検索対象のURLを登録するフォームを持っていたのですが、SPAM botからの大量登録を受けており、これに対抗するためのものでした。
CAPTCHA誕生当初から画像中のテキストを機械的に読み取られる危険性については検討されていたようで、AltaVistaではOCR3のマニュアルに書いてあった認識精度を改善する方法を逆手に取り、次のような画像を作ればOCR対策になると考えました。
- 複数のフォントを混在させる
- 背景が均一でない
- 文字を歪ませたり回転させたりする
当時のOCRプログラムは出版物の読み取りを前提としており、出版物ではありえない条件のテキスト認識は困難だったと考えられます。実際、初期のCAPTCHAはbotプログラムの大半を除去できていたようです。
CAPTCHA破りの正攻法
CAPTCHAのテキスト認識は2000年頃の技術では困難でしたが、2019年現在の機械学習の専門家にとって難しい問題ではありません。機械学習の知識がある人がCAPTCHA破りで最高の精度を出そうと考えた場合、次のような手順でモデル構築をすることになります。
- 教師データの元となるCAPTCHA画像を大量に集める(おそらく数百から数千)
- 必要に応じて画像のノイズ除去など前処理を行う
- 1文字ごとに画像を切り出し、文字ごとにラベル付けを行う
- 必要に応じてデータの水増し(data argumentation)を行う
- 「学習」:モデル構築を行う。大量のGPU計算が必要。
- 「評価」:精度を評価する。イマイチだったら1または2からやり直し。
つまり、教師データの収集・作成を人力で行い、一定以上の計算リソースを投入して、画像処理の知識も駆使すれば確実に破れる、ということになります。とはいえ、教師データを作るコストとチューニングのコストは専門家でもタダにはなりません。専門家が取り組むにしても、人の時間とGPU時間とそれぞれ一定のコストがかかるというわけです。
手軽にCAPTCHAを破りたい!
さて、私のように機械学習分野の専門知識もなく、よいGPUも持っていない人間がCAPTCHA破りに取り組む方法はあるのでしょうか。
ひとつは既存のOCRソフトウェアを使うことです。定評のあるOCRソフトウェアとしてTesseract OCRというOSSがあります。実際に試したわけではないのでCAPTCHA破りに使えるかはわかりませんが、状況次第では有力な選択肢になるはずです。
さらにお手軽な方法として、機械学習APIを利用する手があります。クラウド事業者の多くがテキスト認識APIを提供しており4、いずれも安価に利用することができます。また、環境構築のコストがほぼゼロなのもAPIのよいところでしょう。
こうしたAPIではCAPTCHAを破るような使い方は想定していないはずですから、過度の期待はできません。とはいえ、多少精度が低くても手軽にCAPTCHA破りができることがわかれば、それはそれで価値があるはずです。そのような考えから、今回Cloud Vision APIを使ったCAPTCHA破りに挑戦してみました。
Cloud Vision APIとは
Cloud Vision APIはGoogle Cloud Platform (GCP)上で提供されている画像分析APIで、画像のカテゴリ分類、テキスト認識など複数の機能をもつAPIです。
このAPIはGCPにアカウントがある人なら誰でも利用できます。また、デモ利用であればアカウント無しで試すこともできます。Cloud Vision APIのページがデモページになっているので、興味のある読者の方は試してみてください5。
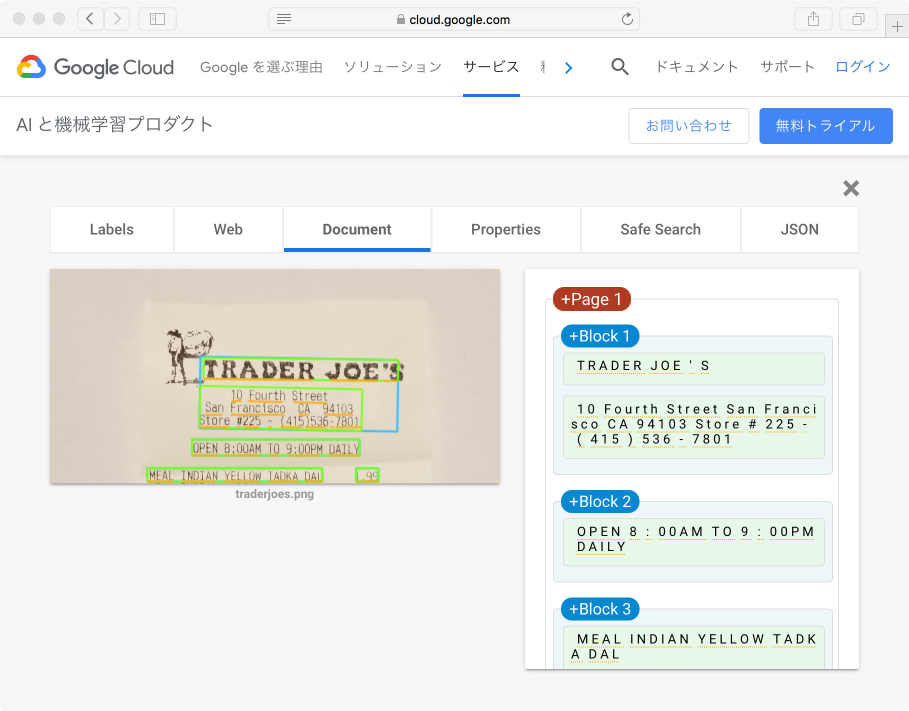
気になる利用料金ですが、1000API呼び出しあたり1.5ドルです。CAPTCHAのように短いテキストに対して使うには若干高く思えますが、本来は書籍1ページをスキャンしてテキスト化するような用途で使うものですから、むしろ破格と言ってよいでしょう。
API単体でCAPTCHAは破れるか
CAPTCHA破りをするには対象となるCAPTCHAが必要です。今回は次の6サイトについてCAPTCHA画像を20個ずつ集めました。
| 画像例 | |
|---|---|
| サイトA |  |
| サイトB |  |
| サイトC |  |
| サイトD | 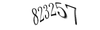 |
| サイトE | 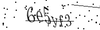 |
| サイトF |  |
これら6サイトについてVision APIでテキスト認識を試したところ、次のような結果になりました。
| 正解率 | |
|---|---|
| サイトA | 100% |
| サイトB | 55% |
| サイトC | 55% |
| サイトD | 95% |
| サイトE | 0% |
| サイトF | 10% |
サイトAとサイトDについては正解率が100%近い結果になりました。サイトAはパッと見で簡単そうなので納得ですが、サイトDは一見難しそうに見えるので意外な結果です。両サイトとも数字しか出現しないので、その分簡単なのかもしれません。
サイトBとサイトCは約50%の正解率になりました。機械学習の専門家ならもっと精度を上げられそうですが、CAPTCHA破りとしては十分な精度です。というのも、CAPTCHAを使った入力フォームでは通常リトライができるので、1回の正解率が50%なら5回以下で突破できる確率は96.8%ということになるからです。
サイトEとサイトFについてはほぼ0%で、実用的とは言いがたい結果になりました。この2サイトについてはもう少し深追いしてみましょう。
ノイズ除去で認識精度を上げる
一般に、機械学習では入力データのノイズ除去や正規化といった前処理も重要になってきます。特に今回はOCR機能を利用しているので、元画像をOCR向きの画像に加工することで精度改善ができそうです。
先ほどの実験で精度が出なかったサイトE・サイトFの画像に共通することとして、文字だけでなくドットや直線などのノイズが加えられているという特徴があります。このノイズを除去できれば正解率が上がるかもしれません。
そのような考えから、OpenCVを使ってノイズ除去プログラムを作成してみました。OpenCVといえば顔認識のライブラリだと考えている人も多いかもしれませんが、実際は画像処理全般のライブラリで、さまざまな画像処理関数が用意されています。
与えられた画像について、下記のようにノイズ除去を行ってみました6。
| 元画像 | ノイズ除去後 | |
|---|---|---|
| サイトE | 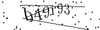 |
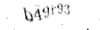 |
| サイトF |  |
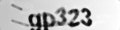 |
このノイズ除去済の画像に対してCloud Vision APIを使ってみたところ、次のように20%〜25%ほど精度が向上しました。
| 元画像 | ノイズ除去後 | |
|---|---|---|
| サイトE | 0% | 20% |
| サイトF | 10% | 35% |
まだ合格ラインと呼べる成績ではないですが、あと一歩で実用(?)になりそうです。
このように、元画像に対してノイズ除去を行うことで認識精度を改善できることがわかりました。問題に特化した前処理を行った上で汎用の機械学習APIを利用するような使い方は今後どんどん増えていくはずですから、その意味でも面白い結果が得られたように思います。
reCAPTCHAを使おう
本稿では攻撃者の視点からCAPTCHAの攻略について考えてきましたが、サイト運営者の視点ではCAPTCHAをどう考えるべきなのでしょうか。
まず言えることは、CAPTCHAを自作してはいけないということでしょう。本稿で示したとおり、いまや簡単なテキスト認識CAPTCHAであれば私のような門外漢でも容易に破れる状況であり、知識を持った攻撃者の前では大抵のCAPTCHAは無力です。現在でも有効なCAPTCHAを作れるのは一部の専門家だけと考えるべきでしょう。
では、botを防ぎたい場合に現実解はあるのでしょうか。
実は機械学習のプロでも破るのが難しいCAPTCHAをGoogle社が無料で提供しています。それがreCAPTCHA v2およびv3です。reCAPTCHA v2(下図)は画像を選ばせるタイプのCAPTCHAですが、機械学習方面の知見が盛り込まれており7、日々改良されています。また、v3はページ遷移に注目するCAPTCHAで、ページ遷移の情報だけを基に人間かどうかを判定するようです。アカウント大量作成botのようなものは人間の挙動とは随分違うはずですから、効果は大きそうですね。

まとめ
- Cloud Vision APIでCAPTCHAが破れた
- 単純なテキスト認識CAPTCHAなら正解率100%
- 元の画像を加工してOCRが得意そうな画像に書き換えると精度が上がった
- ノイズ除去は大事
- CAPTCHAを自作してはいけない
- 専門知識なしGPUなしでCAPTCHAが破れる時代
- reCAPTCHAを使うべき
-
後述しますが、reCAPTCHA v2およびv3であれば現在でもbot対策として有効です。 ↩
-
今は亡き検索エンジン。Google登場以前は最大手サービスのひとつでした。 ↩
-
Optical Character Reader。印刷された文章を読み取ってテキストファイルにする装置。かなり古くから製品が作られています。 ↩
-
たとえばAWSのAmazon Rekognition やAzureのComputer Vision API など。 ↩
-
デモ利用では言語のヒント情報を与えることができないので、APIを使った方が認識精度は上がります。 ↩
-
サイトEはメディアンフィルターを2回適用しました。また、サイトFについてはモルフォロジー変換を行っています。 ↩
-
機械学習モデルを騙すテクニック(Adversarial example)が使われていたり、機械学習モデルの成績が悪い画像をわざわざ混ぜ込んだりしている気配を感じます[要出典] ↩