YOLOv4
YOLOv4: Optimal Speed and Accuracy of Object Detection
- Date: 2020-04-26
- Speaker: Hiroshi Nishigami
- Links:
はじめに
- yolov3 の著者 pjreddie (Joseph Redmon) が出した論文ではない
- pjreddie は CV の研究から引退。
- この論文 yolov4 の first author は、 darknet を fork して開発を続けていた人。
おさらい
-
YOLO とは
- You only look once (YOLO): it looks for the image/frame only once and able to detect all the objects in the image/frame
- リアルタイム物体検出 (object detection) システム
- 昨今の、object detection のスタンダードな手法
-
darknet とは
- C で書かれたオープンソースのニューラルネットワークのフレームワーク
- 構築済み (学習済み) の yolo series が利用できる
概要
- 最先端のテクニック・手法を (ある程度の仮説を立てながら) 総当たりで実験し、良いものを採用するための実験を行った (for single GPU)
- 性能が良かった組み合わせを採用して、YOLOv4 として提案
- 既存の高速(高FPS)のアルゴリズムの中で、最も精度が良い手法
- YOLOv3 よりも精度が高く、EfficientDet よりも速い
様々な最先端の手法が紹介されており、その手法の性能への評価を行っている。
手法の名前が色々出てくるが、CNN に馴染みのない人には辛い。
しかし、この論文に出てくる手法(名前)を参考に、各個人でそれぞれの参考文献をたどって抑えていけば、
最近の CNN 精度改善の Review ぽいので、おおよその最新手法を把握できそう。

AP: mean average precision (mAP)
検証内容
- Influence of different features on Classifier training
- Influence of different features on Detector training
- Influence of different backbones and pretrained weightings on Detector training
- Influence of different mini-batch size on Detector training
手法探索とチューニング
- モデルアーキテクチャ
- backbone: 画像の特徴抽出の役割
- neck: backboneから受けた特徴マップをよしなに操作して、よりよい特徴量を生み出す
- head: クラス分類やbbox(物体を囲む四角形)の位置を予測する
- Bag of freebies
- 学習上の工夫
- Bag of specials
- 少ないコスト(推論時間や計算リソース)で大きな精度向上ができるもの
著者は、これらを BoF, BoS と命名し、区別して議論しているが、一般的に使われる用語ではないと思われる。
物体検出器のアーキテクチャ
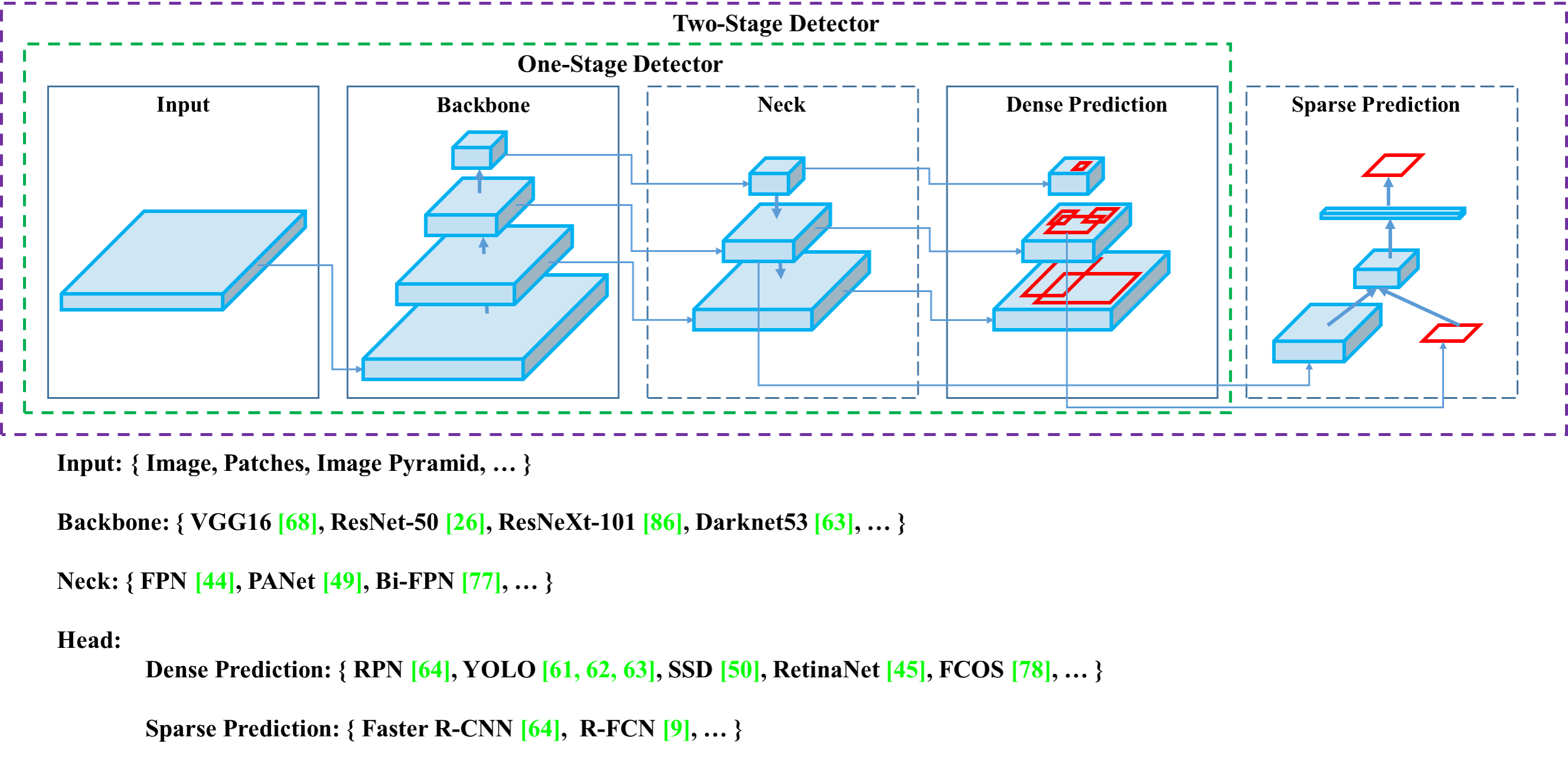
- backbone: 画像の特徴抽出の役割
- neck: backboneから受けた特徴マップをよしなに操作して、よりよい特徴量を生み出す
- head: クラス分類やbbox(物体を囲む四角形)の位置を予測する
- 1-stage: 直接的に予測を行う
- YOLO系列やSSD
- 速度重視
- 2-stage: 候補領域を出してから予測を行う
- R-CNN系列
- 精度重視
- 今回は、1-stage のみに focus する
- 1-stage: 直接的に予測を行う
ネットワークアーキテクチャ
Backbone: CSPDarknet53
Neck: SPP、PAN
Head: YOLOv3
Backbone: CSPDarknet53
-
CSPNet
- 精度をあまり落とさずに、計算コストを省略するための手法
- CSPNet で提案される機構を Darknet53 (YOLOv3で使われているbackbone) に導入
Neck: FPN、PANet
-
FPN (Feature Pyramid Network), Bi-FPN
- YOLOv3 は FPN を Neck として採用し、異なるスケールの特徴を backbone から抽出している
- 複数サイズの window でプーリングして特徴量を作り
、受容野を広げることができる
- PAN (Path Aggregation Network for Instance Segmentation)
Head
- bounding box (bbox) の分類タスクを担うネットワーク
- output の例として、 bounding box の (x, y, h, w) と k 個のクラスの確率 + 1 (バッググランドの確率)
- YOLO は anchor-based な検出器で、anchor ごとに head network が適用される
- Single Shot Detector (SSD) や RetinaNet も anchor-based な検出器である
Bag of freebies
推論コストを上げず、学習手法と学習コストのみ変更させ、精度を改善する手法
- bbox の regression loss
- IoU-loss
- GIoU-loss
- CIoU-loss
- データオーグメンテーション
- CutOut
- CutMix
- Mosaic data augmentation
- Self-Adversarial Training
- 正則化
- DropOut, DropConnect and DropBlock
- 正規化
- CmBN (cross mini-batch normalization) (後述)
- その他
- Optimal hyper parameters
- Cosine annealing scheduler
- Class label smoothing
Data augmentation
- 明るさ、彩度、コントラスト、ノイズを変更したり、画像の回転、トリミングなどの幾何学的歪みを導入する
- モデルの汎化性能を上げることができる
- 例えば、CutOut や Random Erase はランダムに画像の領域をマスクして適当な値で埋める
Random Erase

正則化
- overf-itting を防ぐ
loss
- 伝統的なものは平均二乗誤差 (MSE: Mean Squared error)
- IoU loss: 予測された bbox と ground truth の bbox の面積を考慮
- GIoU loss: 面積だけでなく、bbox の形と回転を考慮
- CIoU loss: 中心間の距離とアスペクト比を考慮
- YOLOv4 では CIoU loss が使われている (他の手法より、収束が速く、精度が良かったため)
Bag of specials
推論コストを少しだけ上げて、物体検知の精度を大幅に上げる手法
- Improving receptive field
- SPP (Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition), ASPP and RFB
- YOLOv4 は SPP を採用
- Attention modules for CNNs
- channel wise attention: Squeeze-and-Excitation (SE)
- spatial-wise attention, like Spatial Attention Module (SAM)
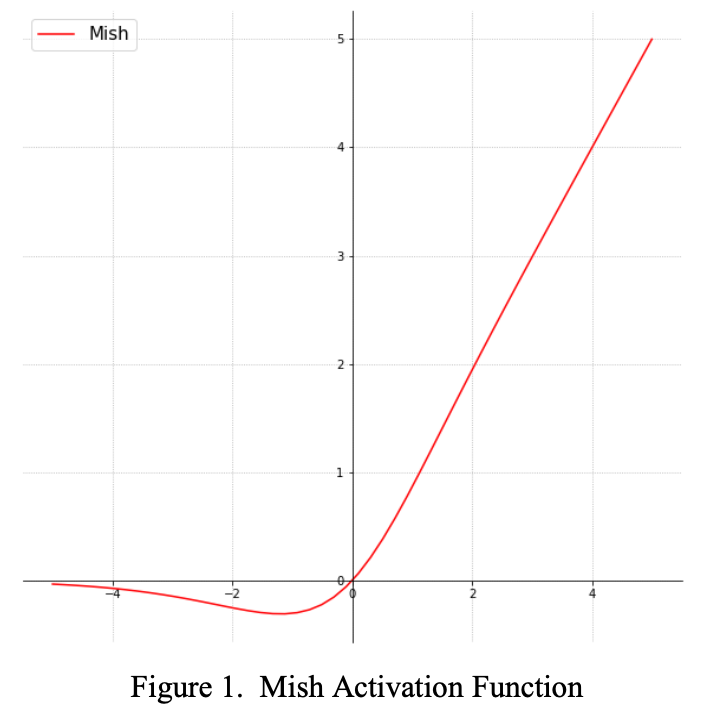
- 活性化関数
- Mish acrivation, LReLU, PReLU and ReLU6
attention modules for CNNs
- channel wise attention: Squeeze-and-Excitation (SE)
- 10% 推論時間が伸びる (on GPU)
- spatial-wise attention, like Spatial Attention Module (SAM)
- SAM は SE ほど推論コストの悪化は多くはないらしい
- YOLOv4 は SAM を採用(修正あり)
Activation
-
Mish
- Squeeze Excite Network with Mish (on CIFAR-100 dataset) resulted in an increase in Top-1 test accuracy by 0.494% and 1.671% as compared to the same network with Swish and ReLU respectively.
- 参考: Activation Functions の比較
Additional improvements
- Mosaic, a new data augmentation method
- Self-Adversarial Training (SAT)
- Genetic algorithmを使ったハイパーパラメータのチューニング
- modified SAM, modified PAN, and Cross mini-Batch Normalization (CmBN)
Mosaic と SAT は著者らによって新しく提案された Data Augmentation の手法
Mosaic
4 つの画像を混ぜる

SAT: Self-Adversarial Training (SAT)
- 1度、network weights の代わりには元々の画像を更新 (self-adversarial attack)
- 2度目、この修正された画像に対して通常の学習を行う
Modified SAM
spatial-wise から pointwise attention へ修正

Modified PAN
PAN (Path Aggregation Network for Instance Segmentation)
addition から concatenation に変更

Cross mini-Batch Normalization (CmBN)
Cross-Iteration Batch Normalization (CBN) (2020/02/13 on arXiv) をベースにして、改良を加えた

-
CBN (Cross-Iteration Batch Normalization)
- batch size が小さいときは、Batch Normalization の有効性が低いことが知られている
- CBN では複数の iteration の examples を結合することで有効性を上げる
- CmBN は、1つの batch に含まれる全ての mini-batches のみを結合して normalize する
検証結果
Influence of different features on Classifier training
- data augmentation
- bilateral blurring, MixUp, CutMix and Mosaic
- activations
- Leaky-ReLU (as default), Swish, and Mish

- Mish (A Self Regularized Non-Monotonic Neural Activation Function) は、昨年発表された連続な活性化関数 (2019年10月)


CutMix, Mosaic, Label Smoothing, Mish の効果が大きい
Influence of different features on Detector training
-
Loss algorithms for bounded box regression
- GIoU, CIoU, DIoU, MSE
-
単純な bbox の MSE 誤差よりも、IoU ベースの損失関数 (CIoU-loss: Nov 2019) の方が良い
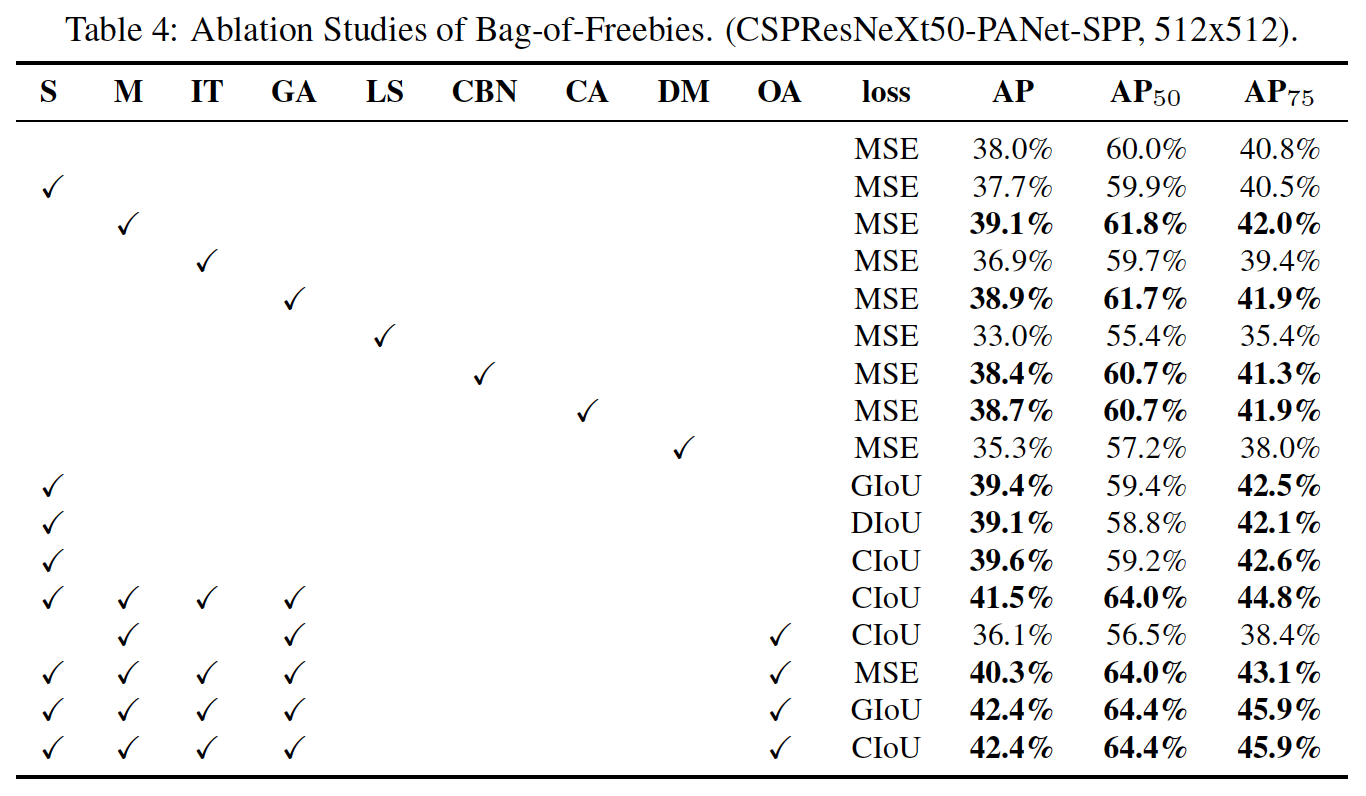
最終的に採用された手法
YOLOv4 アーキテクチャ
- Backbone: CSPDarknet53
- Neck: SPP , PAN
- Head: YOLOv3
Bag of Freebies (BoF) for backbone
(BoF: 学習時の手法)
- CutMix and Mosaic data augmentation
- DropBlock regularization
- Class label smoothing
Bag of Specials (BoS) for backbone
(BoS: 推論時のテクニック・追加モジュール)
- Mish activation
- Cross-stage partial connections (CSP)
- Multiinput weighted residual connections (MiWRC)
Bag of Freebies (BoF) for detector
- CIoU-loss
- CmBN
- DropBlock regularization
- Mosaic data augmentation
- Self-Adversarial Training
- Eliminate grid sensitivity
- Using multiple anchors for a single ground
truth - Cosine annealing scheduler
- Optimal hyperparameters (genetic algorithm)
- Random training shapes
Bag of Specials (BoS) for detector
- Mish activation
- SPP-block
- SAM-block
- PAN path-aggregation block
- DIoU-NMS
議論、課題など
- Detector の BoF を改善できる余地がある?
In the future we plan to expand significantly the content of Bag of Freebies (BoF) for the detector, which theoretically can address some problems and increase the detector accuracy, and sequentially check
- FPSが70~130程度あるが、V100の強めのマシンであることには注意が必要(既存のモデルに対するパフォーマンスがよいことには変わりない)
エッジ領域である、Jetson AGX XavierはFPSが割と小さく、TensorRTに変換及び量子化等の対応が必要
Jetson AGX Xavier上で32FPS程度
Ref: https://github.com/AlexeyAB/darknet/issues/5386#issuecomment-621169646)
ちなみに
- NVIDIA Tesla V100
先行研究と比べて何がすごい?(新規性について)
- アーキテクチャ・手法が object detection 性能に与える影響を調査した
- 既存の手法よりも良い手法を提案した (YOLOv4)
- YOLOv3 と同程度に速く、より高い精度
- EfficientDet より速く、同程度の精度
- 速度重視で物体認識モデルを考えるのであれば、選択の筆頭候補ということになる
参考資料
- yolov4 の日本語解説資料
- 英語解説記事
- yolov3 architecture: A Closer Look at YOLOv3