[ML論文輪読] Tiny Video Networks
~精度を保ったまま映像認識を軽量化する~
紹介する論文
タイトル:Tiny Video Networks
著者:AJ Piergiovanni, Anelia Angelova, Michael S. Ryoo
所属:Robotics at Google
発行日:15 Oct 2019
掲載元:arxiv [1910.06961] Tiny Video Networks
概要
- 映像認識は挑戦的な課題である
- これまでに提案されている方法では計算コストが非常に高かった
- 一番早いアルゴリズムでも、1つの断片的な映像に、GPUを使って0.5秒以上はかかっていた
- 著者らは映像認識をするための新しいモデル学習手法を考えた(Tiny Video Networksと呼ぶ)
- その手法によって、自動で非常に効率的なモデルを作成することができる
- 例えば、1つのビデオを1GPUで10ミリ秒で推論が可能になる
背景
- Video understanding: 映像認識
映像認識は、コンピュータビジョンの応用(e.g., automated cideo tagging, activity recognition, robot perception)における重要な問題。
例えば、以下の映像から、「バント」をしているという行動を認識させる。

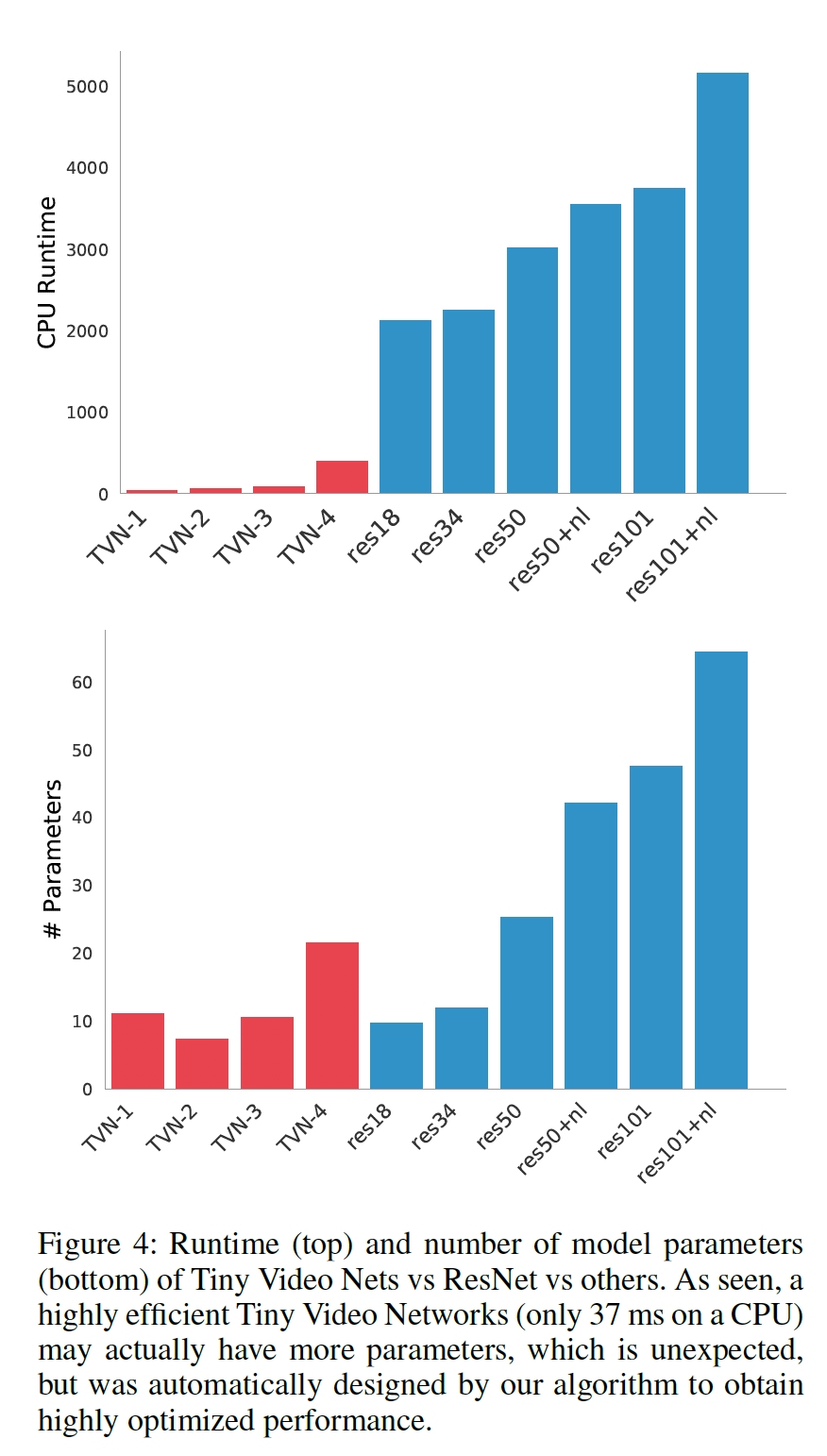
TVN (Tiny Video Networks) とresnetの実行速度比較
まずは結果から
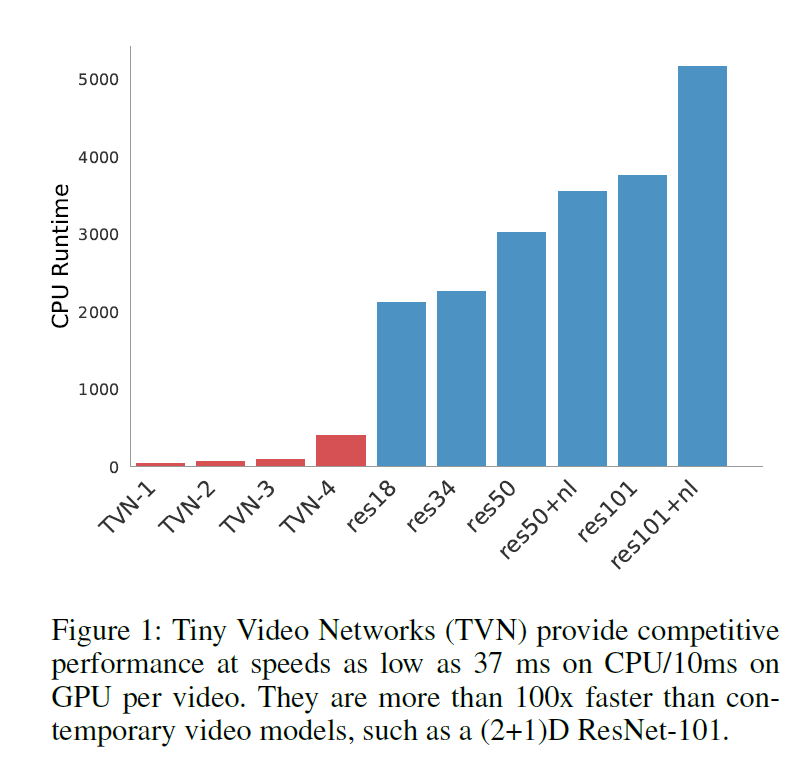
- TVN-1 から TVN-4 は、ネットワークの大きさやパラメータの数が違う
- いずれのTVNも、どのresnetモデルよりも推論処理が速い
CPU Runtime vs Accuracy
TVN は実行時間が短く、精度は従来の大きなモデルと遜色ないレベル。
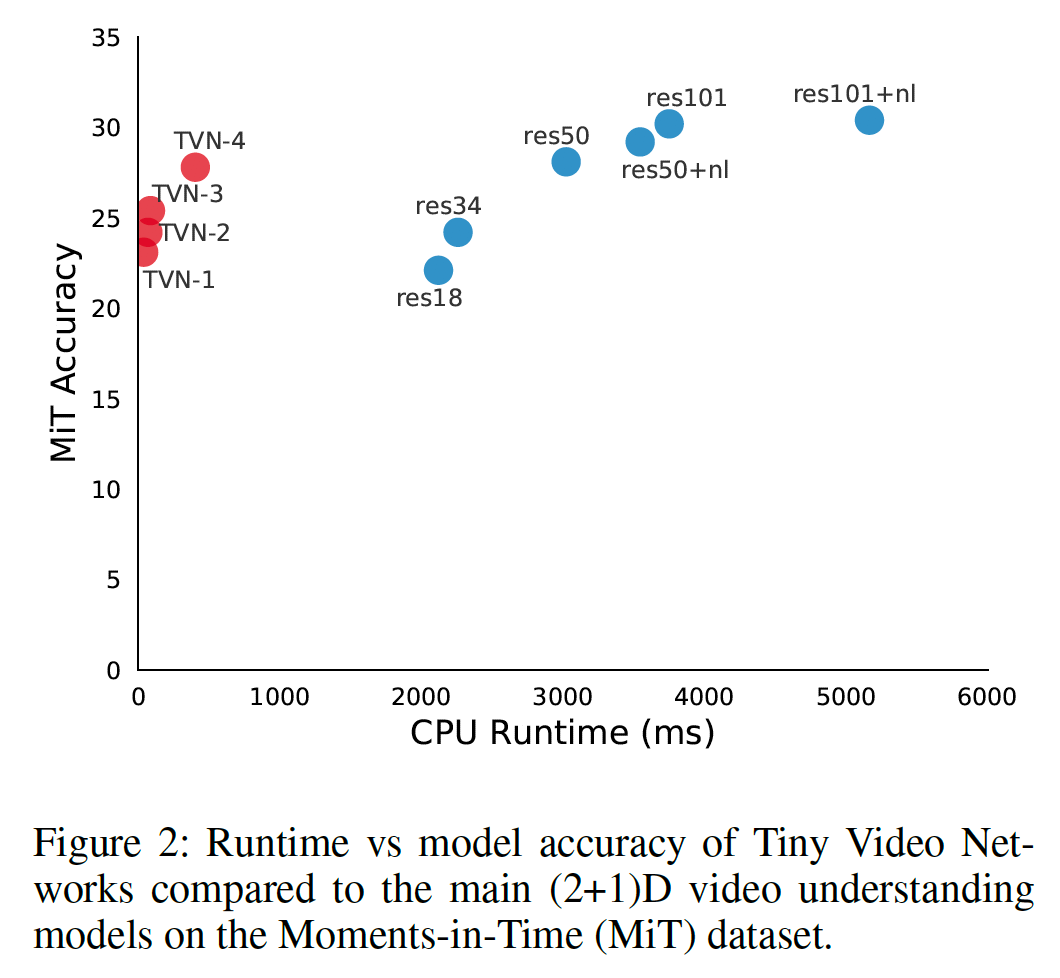
Moments-in-Time (MiT) は、データセットの名前
作成されたネットワークの一例
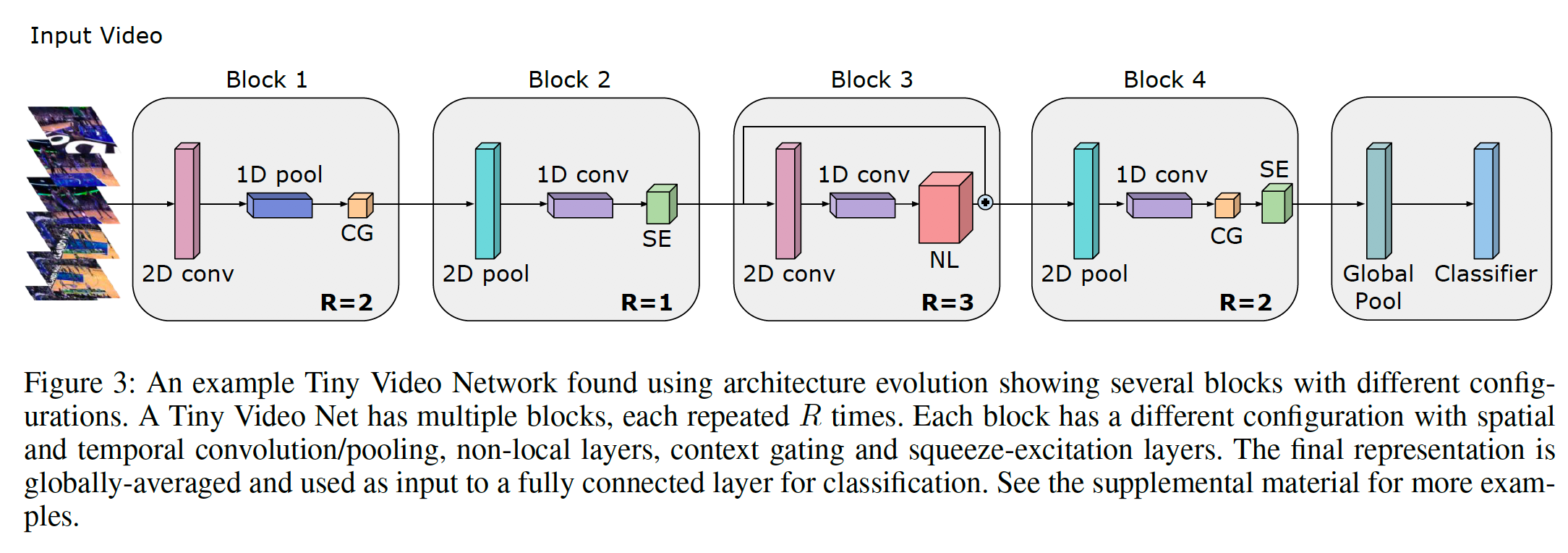
CG: context gating
SE: squeeze-excitation
NL: non-local
他の例に関しては、論文のAppendixに記載。
探索したいもの
- 空間的な解像度(イメージサイズ)と時間的な解像度(フレーム数)の最適な比率
- どのように or どこで 空間的・時間的な情報を削減することができるか
- 限られた実行時間内で、どんな構成のネットワークが最高のパフォーマンスを出すか
- ネットワークは、どれぐらい深く or 広くあるべきか
TVN models
- TVN-1
- CPU 50ms 以内で実行できる制限をかけた場合の最速モデル
- It runs at 37ms and was evolved on Momentsin-Time.
- TVN-2
- CPU 100ms 以内、12,000,000個以内のパラメータ数
- It runs at 65ms and was evolved on MLB-YouTube.
- TVN-3
- CPU 100ms 以内、パラメータ数は無制限
- It runs at 85 ms and was evolved on Charades.
- TVN-4
- CPU 1,200ms 以内、30,000,000個以内のパラメータ数
- a max computation cost roughly comparable to I3D
- It runs at 402ms on CPU and is evolved on Moments-in-Time.
ネットワーク探索の方法
一定の実行時間・パラメータの数の制限下で, F(accuracy)を最大化するネットワークコンフィギュレーションを探す。
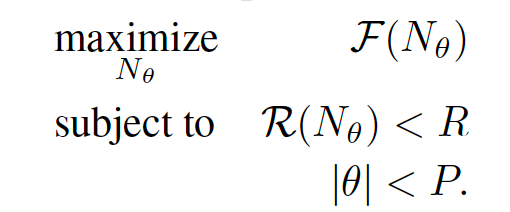
F: the fitness function, in our case, it measures the accuracy
of the trained model on the validation set of a dataset
N: the network configuration
theta: the learnable parameters of the network
(|theta|: the number of parameters in the network)
P: a hyperparameter controlling th e maximum size of the
network
R(N_small_theta): the runtime of the network on a device, given the network N with its weight values theta
R: the maximum desired computational runtime
Evolutinary Method
おおざっぱにいえば(細かい数とかは正確ではないので論文を参照)、
- 手元にあるランダムに生成されたモデル(例えば200個)の中で最適なものを決定する
- その現状最適なモデルからランダムに変異をいれて、さらに複数のサンプルを生成する
- ここで変異と言っているのは元のモデルの構造の一部をランダムに改変すること
- それらのサンプルから最適なモデルを選び出しさらに上記の手順を繰り返す
↓
- 著者らは、上記の手順を1000回の繰り返しを行なった。
- その各ラウンドでモデル(200個)は、それぞれ10,000エポックで学習される。
- 平均の学習時間は1.5時間
- 平行で学習させることで1日以内で全ジョブが終わったらしい
Hardware
- Intel Xeon CPU
- 2.9GHz
- NVIDIA TESLA V100 TENSOR CORE GPU
- 16 or 32 GB Memory,
- 640 Tensor Cores
offers the performance of up to 100 CPUs in a single GPU
Tesla V100 Data Center GPU | NVIDIA
Tensor Cores in NVIDIA Volta Architecture | NVIDIA
探索空間
- ネットワークは 2 から 10 個の複数のブロックから構成される
- これらは探索プロセスの中で最適なものが選択される
- 最終ブロックは、global average pooling, a dropout layer, and a fully connected layer which outputs
the number of classes required for classification - In each block, the algorithm can select from a number of layers: spatial convolution, temporal
convolution, non-local layers (Wang et al. 2018), contextgating layers (Xie et al. 2018), and squeeze-and-excitation layers (Hu et al. 2018) - For each layer, a number of parameters can be selected.
- each block is repeated 1 to 8 times and can have a skip/residual connection
- we also include the input size as part of the search space: spatial resolution (32 x 32 to 320 x 320), number of frames to sample (1 to 128) and frame rate (1fps to 25fps).
小話
- Since we are working with videos, exploring all of these potential architectures leads to a very large search space.
- Each block has ~2^34 possible configurations.
- When including the input resolution and up to 8 blocks in the network, the search space has a size of ~2^45 or about ~10^13.
- Thus, without automated search (e.g., if we do a brute-force grid search or random search), finding good architectures in this space is extremely difficult, especially when adding constraints such as runtime or maximum number of parameters.
- In fact, in our experiments, we did observe that many of the architectures in this space give nearly random performance,i.e., have poor classification results, or diverge during training, or exhibit other unstable behaviors.
データセットの種類(4つ)

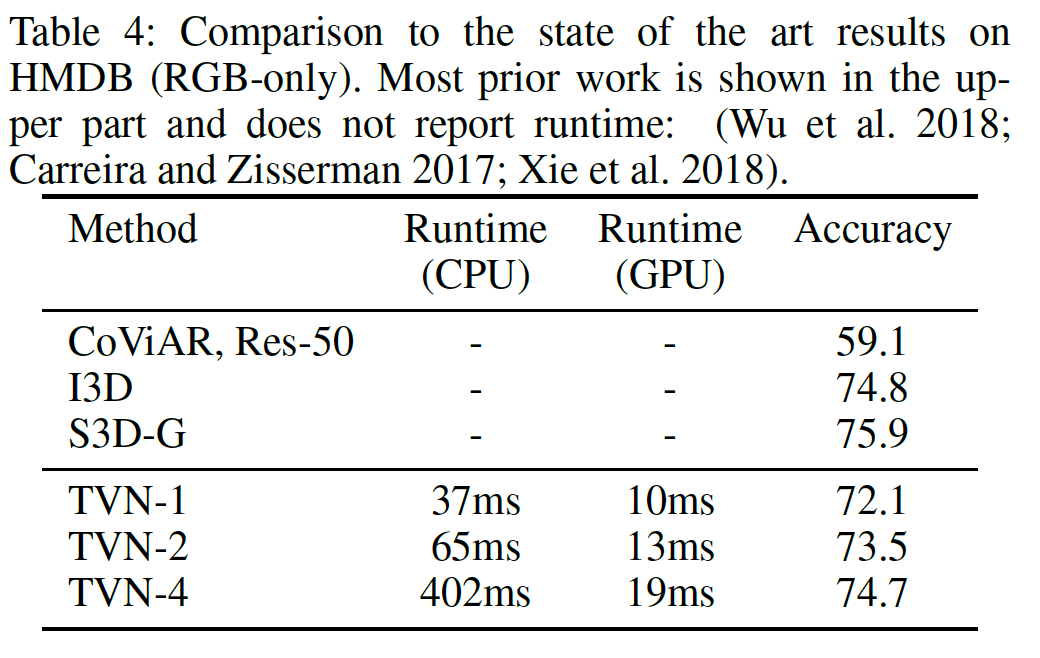
精度の比較(Moments-in-time)
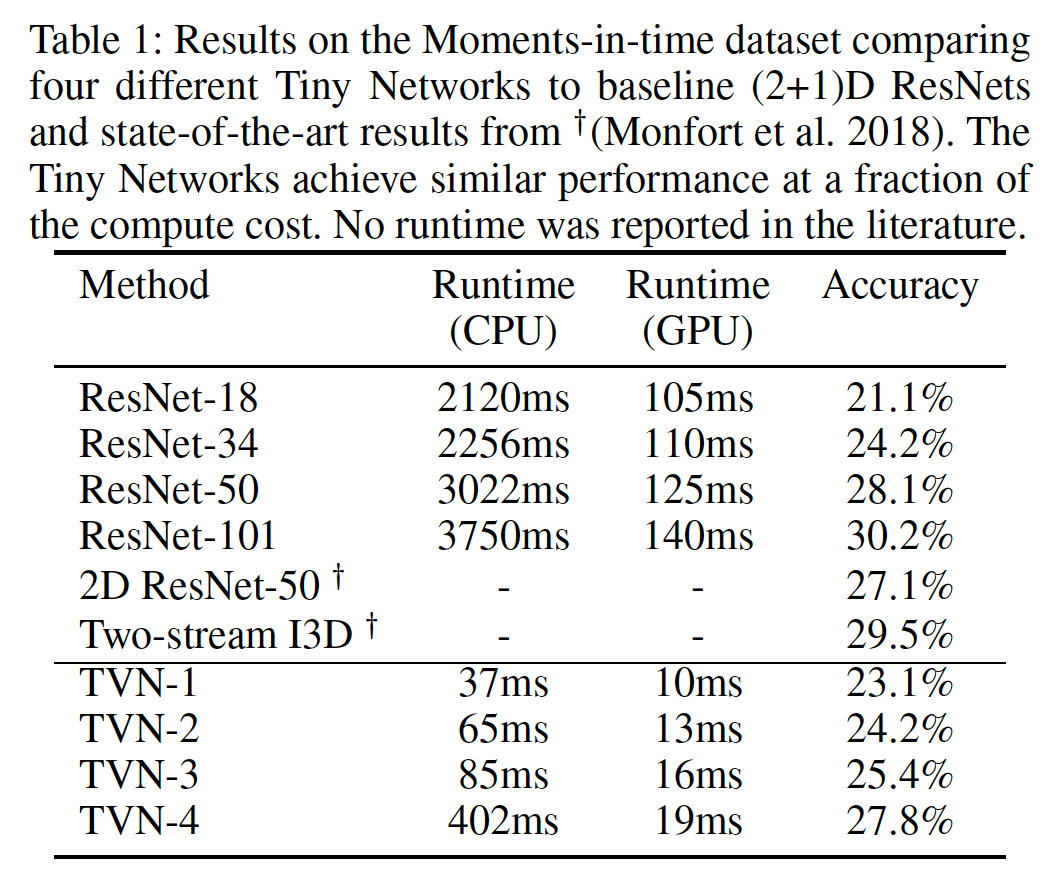
精度の比較(MLB-YouTube)
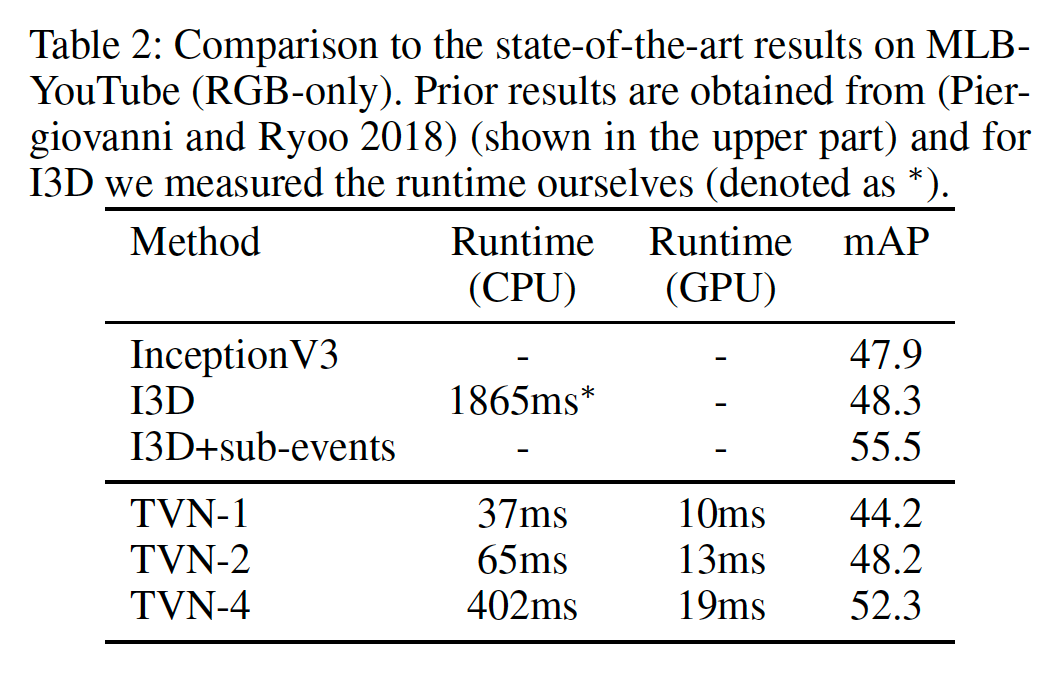
精度の比較(Charades)
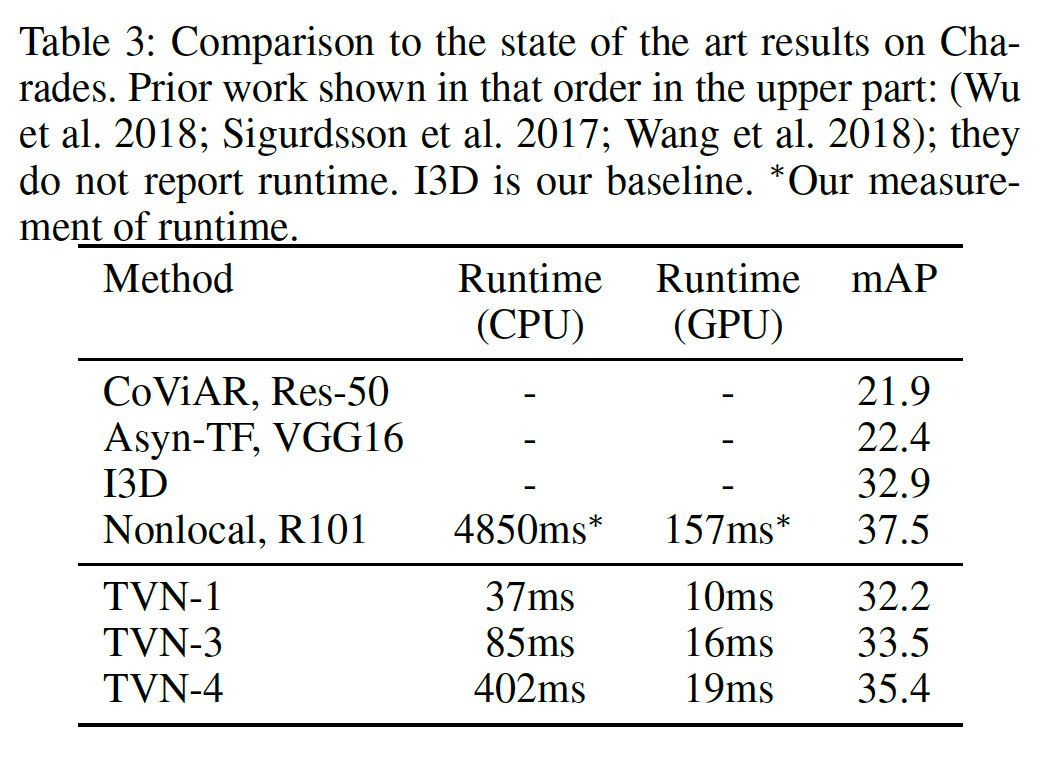
精度の比較(HMDB)
実行時間の比較
フレーム数による精度の変化 (Moments-in-timeの場合)
筆者らは、フレーム数を増やすと実行時間が長くなるが、精度はあまり改善しないと言っている。
(計算コストの割に合わない)

TVN-16 frames: a search requiring every network to have 16 frames as input.
前スライドに関する疑問
筆者らは本文で
We found that for some datasets (e.g., Moments-in-time and
HMDB), the network prefers to use very few frames (e.g.,
2 or 4 frames) to reduce the computation cost which is natural,
given that runtime is the only constraint. Further, on
these datasets, many activities are scene-based (e.g., swimming
and baseball appear very differently), so a single frame
is often enough to discriminate them well.
と言っているが、
We also found that searching
on different datasets produces models with different temporal
scales. For example, when searching on Moments-in-
Time, which has short 3 second videos, the model prefers
to use 2 or 4 frames at covering about 1 second of video.
However, when searching on Charades, which has long 30-
second videos, the model generally selects 8 frames covering
about 10 seconds of video or 24 frames covering 30 seconds
of video.
Similarly, on MLB-YouTube, the models cover about 6 to
8 frames of video, but only capture about 2 to 5 seconds,
reflecting the short duration of the videos but indicating that
temporal information is more important on this dataset than
Moments-in-Time.
とも言っている。
Moments-in-time が1フレームでも十分な精度がでるなら、フレーム数を増やしてもあまり精度が出ないのはあたりまえ。
なぜ、HMDBやMLB-youTubeで、これを検証しなかったか?
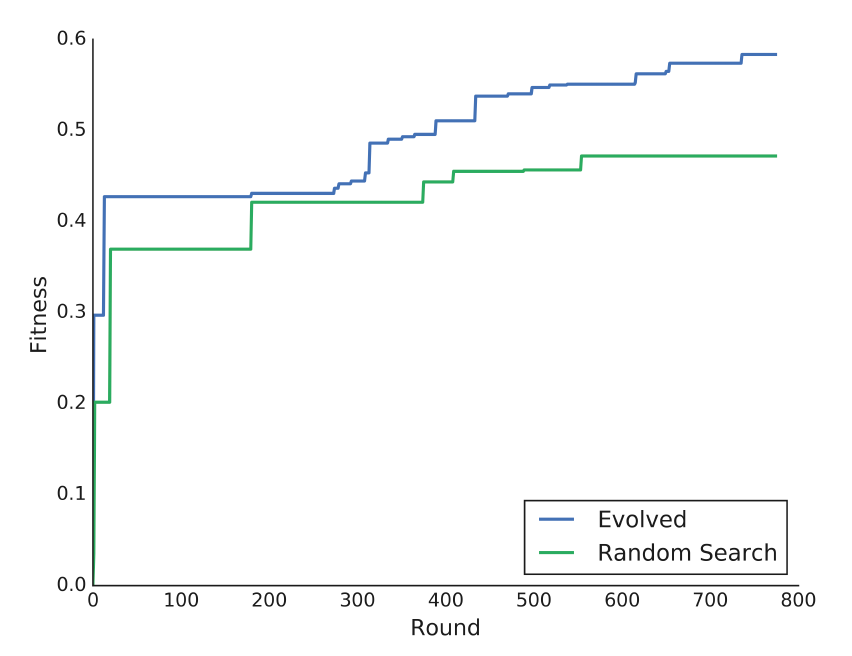
ランダムサーチとの比較
著者らの提案する手法(進化的アルゴリズム)の方が、効率的に最適なネットワークを見つけることができている。
モデルの精度をさらに改善するには
解像度とwidthを上げることで最大のパフォーマンスが得られる(著者談)。
depthよりもwidthの方が精度に寄与するということは、EfficientNetで報告されている傾向と一致している。
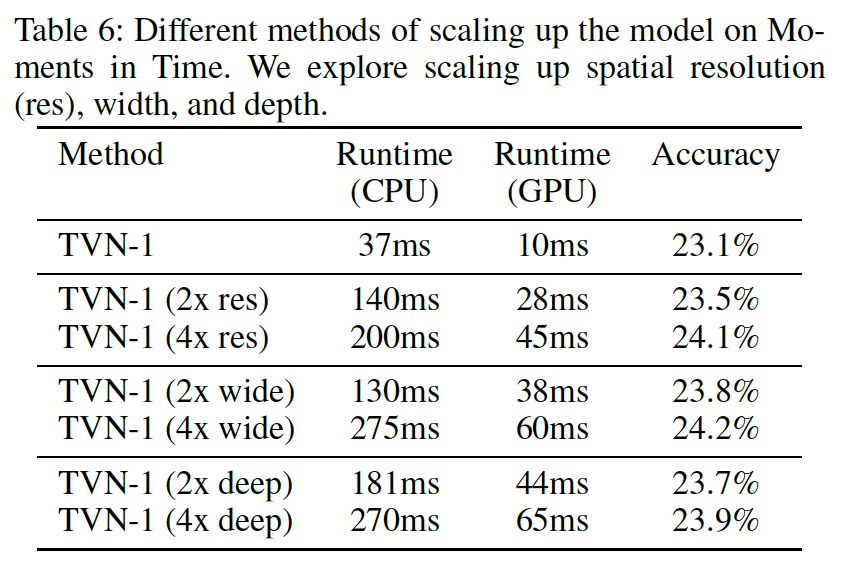
res: spatial resolution (size of images)
wide: the width (number of filters in each layer)
deep: the depth (number of times each block is repeated)
先行研究で提案されているパラメータスケーリングを用いた場合
他の文献を参考にして、入力イメージの解像度、width、depthをスケールアップしたモデル(TVN-1 EN)は、
他の巨大なモデルと比較して、ほぼ同程度の精度を効率的に達成することができている。
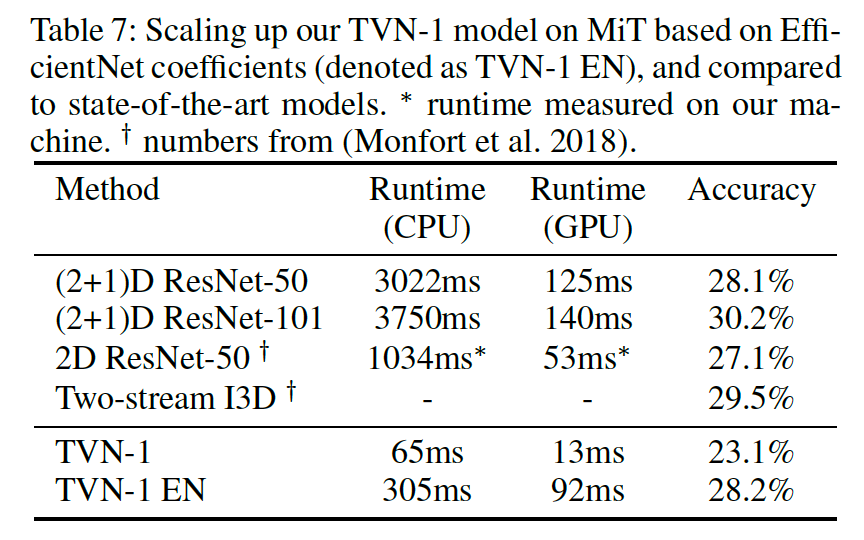
TVN-1 EN: Based on the findings of EfficientNet (Tan and Le 2019), we scaled up TVN-1 in all dimensions (input resolution, width and depth) based on their coefficients
まとめ
- 自動で、軽量なVideo Network Architectureを探索する新規の手法を提案した
- 高速で正確な認識を行うモデルを初めて発見した
- これらのモデルは4つのデータセットに対して良いパフォーマンスを発揮した
- 従来のモデルより100倍高速で、パラメータ数はより少ない
- したがってリアルタイムロボティクスやモバイルデバイスの上で動かすことができる
- チューニングをすることによってTVNは、最先端のモデルと同程度のパフォーマンスを発揮する(その際の実行時間は何倍も早い)
- TVNを改良することで、さらに精度の良い、より高速化されたネットワークの発見が期待される
所感
- Qiita のスライドモード、文字とか画像のサイズとか難しい。