AWS の RDS / Aurora には、各インスタンスの負荷状況を可視化するパフォーマンスインサイトという機能があります。
マネジメントコンソールを使うとパフォーマンスインサイトの情報がグラフ化されるので見やすくて便利ですね。ただし、
- 追加費用なく保管できる期間が 30 日
- 追加費用を払えば 2 年間
- 画面上の表示期間を長くすればするほど、待機イベント・SQL(文)など細部の情報が欠落しやすくなる
- 詳しくはこちらのスライドを参照してください
といった注意点もあります。
パフォーマンスインサイトを DB チューニングに使う
DB まわりのチューニングというと、大きく分けて
- DB の設定や構成をチューニング
- SQL(文)をチューニング
が考えられますが、ここでは後者を考えます。
どのような処理が性能上のネックになっているのかを知るには待機イベントの分析も良いのですが、実際に SQL(文)をチューニングするときは**よく実行される SQL(文)・処理に時間がかかる SQL(文)**を優先して、効率的な実行計画が採用されるように調整するほうが一般的だと思います。
そこで、今回はパフォーマンスインサイトの情報のうち、トークン化(正規化)された SQL(文)トップ 10 を分単位で抽出して S3 バケットに転記する Lambda 関数を作ってみました。
2021/05/30 追記:
待機イベント内訳も転記する方法を別記事として追加しました。
S3 転記用 Lambda 関数の内容
以下のとおりです。GitHub にも置いてあります。
コード(Python 3.8)
import boto3
from datetime import date, datetime, timedelta
import os
db_id = os.environ["DB_ID"]
s3_bucket = os.environ["S3_BUCKET"]
def lambda_handler(event, context):
# 1時間前の時刻を取得(UTC)→対象時間のPerformance InsightsからS3へ
lasthour = (datetime.today() + timedelta(hours = -1)).replace(minute=0, second=0, microsecond=0)
print("Export: " + (lasthour + timedelta(hours = 9)).strftime('%Y/%m/%d %H:00-%H:59'))
# 1分ごとに上位最大10件の正規化SQLを取得してS3へ転記
for minute in range(60):
# Performance Insightsからデータを取得
pi_client = boto3.client("pi")
starttime = lasthour + timedelta(minutes = minute)
response = pi_client.describe_dimension_keys(
ServiceType="RDS",
Identifier=db_id,
StartTime=starttime,
EndTime=starttime + timedelta(minutes = 1),
Metric="db.load.avg",
PeriodInSeconds=60,
GroupBy={
"Group": "db.sql_tokenized",
"Dimensions": [
"db.sql_tokenized.statement"
],
"Limit": 10
}
)
if len(response["Keys"]):
# 対象となる時刻(分単位)のデータがあればS3へ転記(プレフィクスの時刻はJST)
s3_prefix = db_id + "/" + (starttime + timedelta(hours = 9)).strftime('%Y/%m/%d/%Y%m%d%H%M') + "_" + db_id + ".tsv"
exporttime = starttime.strftime('%Y-%m-%dT%H:%M:%SZ')
body_data = "start_time\tsql_tokenized\ttotal\n"
# すべてのKeysから正規化SQLと合計値を抽出
for item in response["Keys"]:
sqltk = item["Dimensions"]["db.sql_tokenized.statement"]
total = item["Total"]
body_data += exporttime + "\t" + sqltk + "\t" + str(total) + "\n"
# S3へ
s3_client = boto3.client("s3")
s3_client.put_object(
Bucket=s3_bucket,
Key=s3_prefix,
Body=body_data
)
return "Completed."
設定など
- タイムアウトは 2 ~ 3 分程度に

- トリガーで 1 時間ごとの実行を指定(毎時 5 ~ 10 分頃に実行)

- ロールは Lambda の一般的な権限に、S3 バケットアップロード権限+パフォーマンスインサイトフル権限+(必要に応じて KMS ユーザー権限)を追加

{
"Effect": "Allow",
"Action": "s3:*",
"Resource": [
"【転送先S3バケットのARN】",
"【転送先S3バケットのARN】/*"
]
},
{
"Effect": "Allow",
"Action": "pi:*",
"Resource": "arn:aws:pi:*:*:metrics/rds/*"
},
{
"Effect": "Allow",
"Action": [
"kms:Encrypt",
"kms:Decrypt",
"kms:ReEncrypt*",
"kms:GenerateDataKey*",
"kms:DescribeKey"
],
"Resource": "【Performance Insightsの暗号化用KMSのARN(※)】"
}
(※)転送先S3バケットの暗号化用KMSが別にあれば配列で定義
- 環境変数では RDS / Aurora インスタンスの ID(
DB-ID)と転記先の S3 バケット名(S3_BUCKET)を指定

補足
現状では、トークン化(正規化)された SQL トップ 10 を、1 分(60 秒)単位で、
-
start_time: 時刻 -
sql_tokenized: トークン化(正規化)された SQL(文) -
total: 同 SQL(文)の平均負荷
の 3 項目だけ転記していますが、コードを調整することで、秒単位での集計結果やカウンターメトリクス値、待機イベント・SQL(トップ 10)別待機イベントなどを転記することも可能です。
- Performance Insights API によるデータの取得(AWS ドキュメント)
- PI(Boto3 Docs)
また、このコードでは Glue を介して Athena で分析することを意図して .tsv 形式で出力するようにしていますが、もちろん .csv 形式や JSON 形式のまま出力することも可能です(JSON 形式で出力するときは、日付を文字列に変換する必要がある点に注意)。
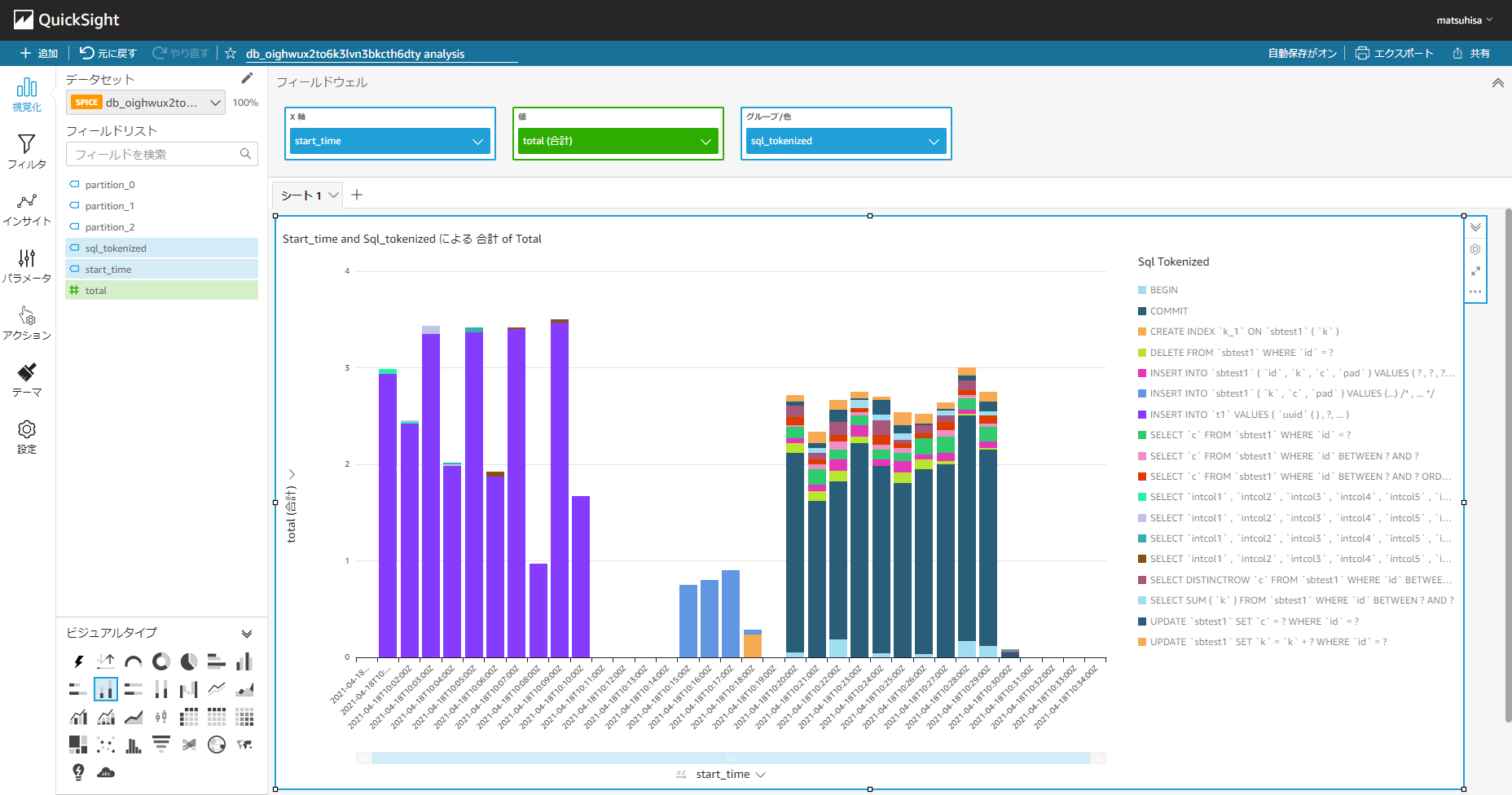
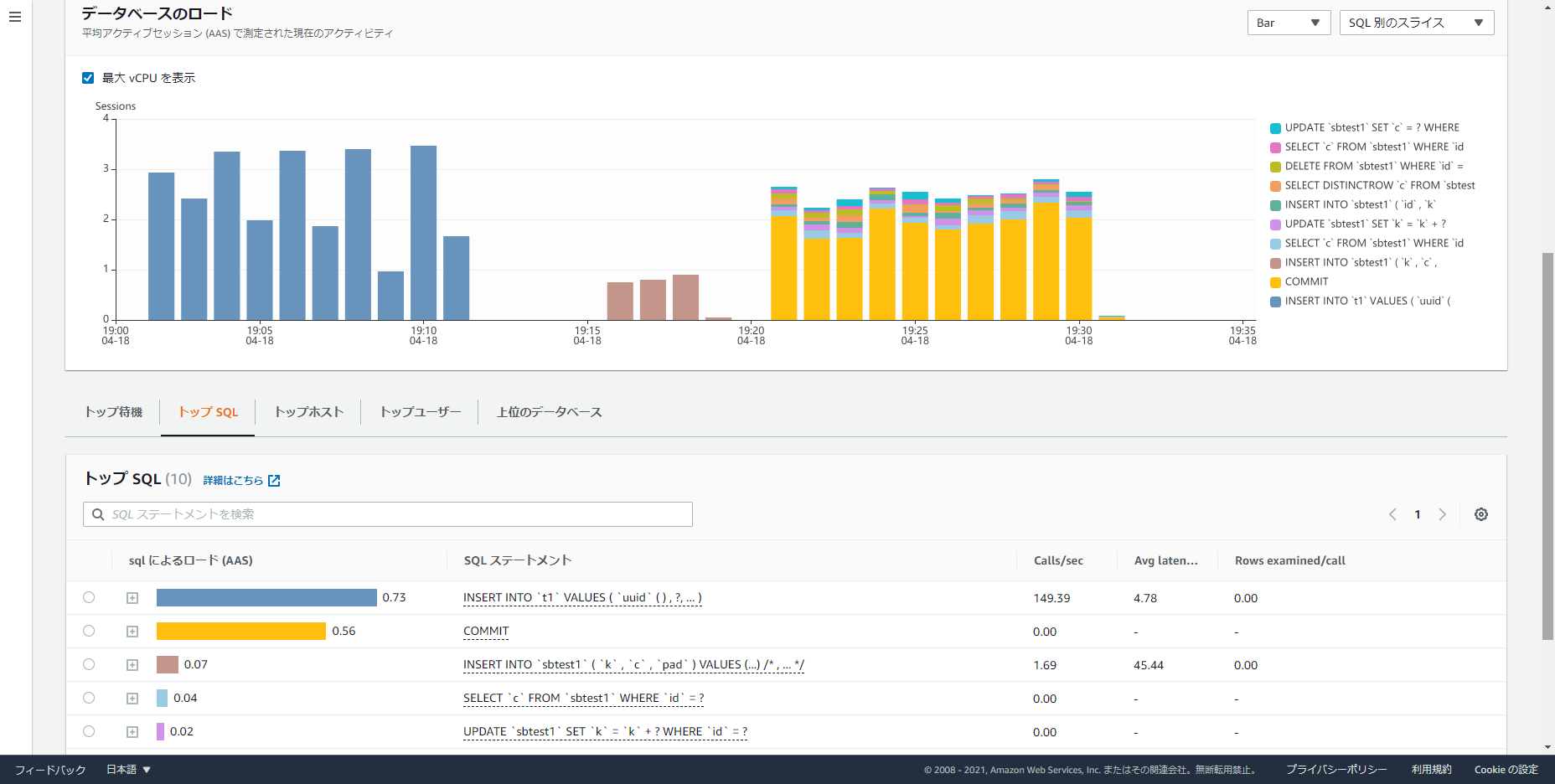
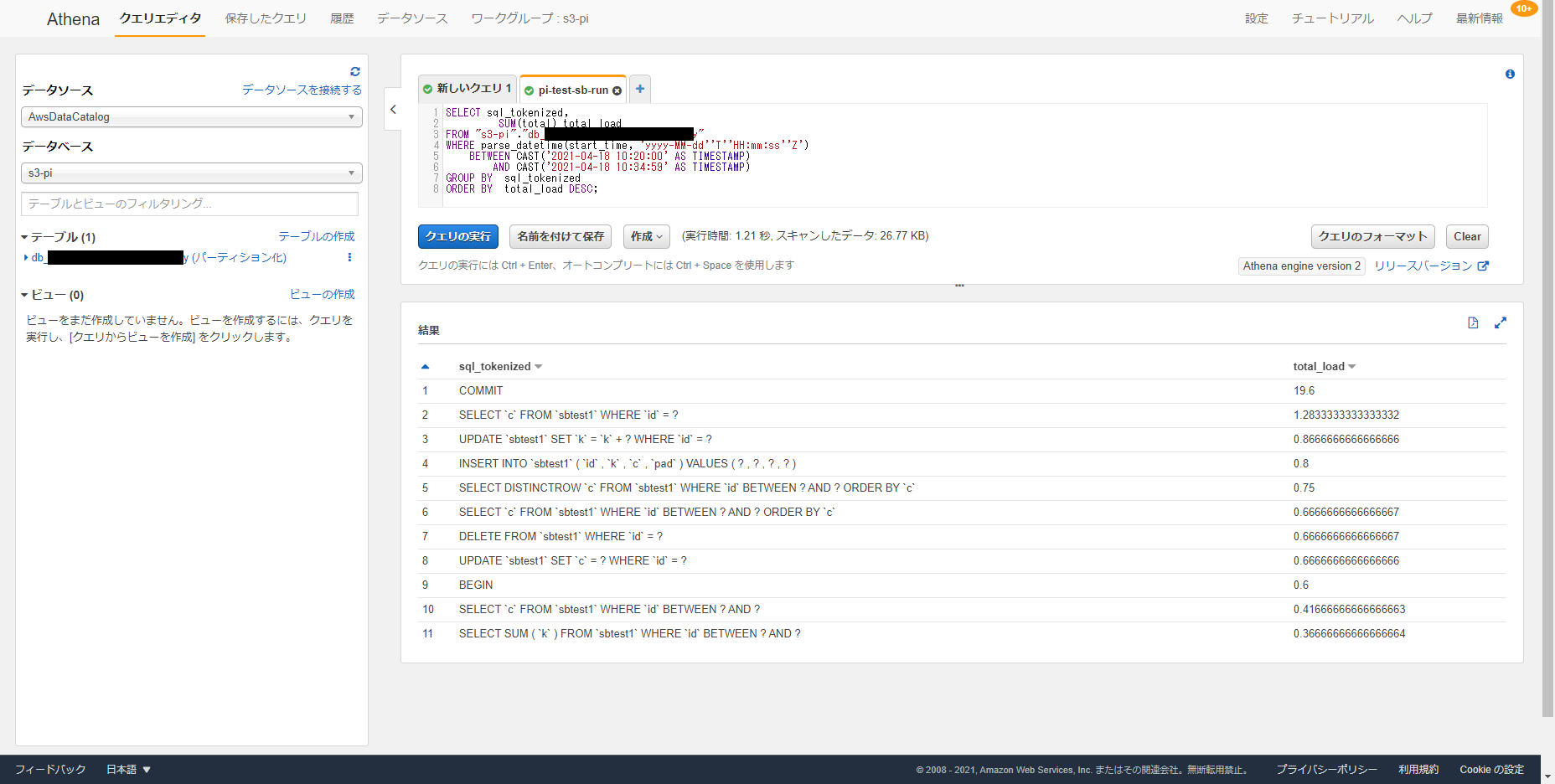
おまけ:Athena や QuickSight での表示例
データはいずれも Aurora MySQL 2 系でmysqlslap・sysbench(ベンチマークツール)を使用したときのもの
- パフォーマンスインサイト(元のグラフ画面・SQL 別のスライス)
- Athena
- QuickSight