以前、このような記事を書きました。
このときは、オンプレTomcat 8+MySQL 5.5環境からAWS EC2上のTomcat8+Aurora(MySQL互換)クラスタへの移行ということで、コネクションプールにDBCP2を使いましたが、色々問題があって調整が大変でした。
今回は、これをHikariCP(2.7.6)に置き換えて、どう変わるか試してみます。
Apache DBCP2接続での問題点
一言でいえば**「とにかく遅い」**です。
特に、「プールからコネクションを取得(借用)する処理が遅い」です。
そのため、
- Auroraフェイルオーバー時の再接続に時間が掛かる
- フェイルオーバー後のWriterインスタンスへの再接続ができるようにするために異常コネクションの除去(Eviction)に関する設定が必要になるが、これが動作上のオーバーヘッドとなり更に処理全体が遅くなる
- 負荷が高い状態では、プールのコネクション数を増加させる必要がある場面(いくつかの遅いSQLがプール内のコネクションを長時間占有してしまっている状態、など)で処理が詰まってしまい、コネクション数が増えてくれない
というような状況になりやすいです。
HikariCPとは
高速・シンプル・高信頼性(という売り文句の)コネクションプールです。
紹介ページにMavenでの組み込み方が例示されています。
※例示されているバージョンが古い可能性がありますので、GitHubにあるREADME.mdを確認してください。
Hibernateとの組み合わせで使われている方も多いと思いますので、細かい説明は省略します。
DBCP2から置き換えてテスト
とあるWebアプリケーション(Tomcat 8で動作)で、JNDI DataSource Factoryを使い、Driver-based形式で組み込んでみます。
置き換え前(DBCP2)
<Context reloadable="true" crossContext="true">
<Resource
name="jdbc/【コネクションプール名】"
auth="Container"
type="javax.sql.DataSource"
driverClassName="com.mysql.jdbc.Driver"
factory="org.apache.commons.dbcp.BasicDataSourceFactory"
url="jdbc:mysql://【クラスタエンドポイント】/【DB名】?useUnicode=true&characterEncoding=utf8&connectTimeout=10000&socketTimeout=180000&alwaysSendSetIsolation=false&cacheServerConfiguration=true&elideSetAutoCommits=true&useLocalSessionState=true"
username="【接続ユーザ名】"
password="【接続パスワード】"
maxTotal="300"
maxIdle="150"
minIdle="10"
initialSize="10"
testOnBorrow="true"
validationQuery="select concheck.validation()"
validationQueryTimeout="10"
timeBetweenEvictionRunsMillis="60000"
maxWait="10000" />
</Context>
置き換え後(HikariCP)
<Context reloadable="true" crossContext="true">
<Resource
name="jdbc/【コネクションプール名】"
auth="Container"
type="javax.sql.DataSource"
driverClassName="com.mysql.jdbc.Driver"
factory="com.zaxxer.hikari.HikariJNDIFactory"
jdbcUrl="jdbc:mysql://【クラスタエンドポイント】/【DB名】?useUnicode=true&characterEncoding=utf8&connectTimeout=10000&socketTimeout=180000&alwaysSendSetIsolation=false&cacheServerConfiguration=true&elideSetAutoCommits=true&useLocalSessionState=true"
dataSource.implicitCachingEnabled="true"
dataSource.user="【接続ユーザ名】"
dataSource.password="【接続パスワード】"
minimumIdle="10"
maximumPoolSize="300"
connectionTimeout="10000"
idleTimeout="180000"
maxLifetime="180000"
connectionInitSql="select concheck.validation()"
validationTimeout="9800" />
</Context>
※フェイルオーバー対応のための確認クエリ(詳細は前述の記事を参照)は、connectionTestQuery が非推奨のため connectionInitSql に書いています。ここに書いても、エラーが返ってきた(=Readerインスタンスに読み書きモードで接続してしまった)場合にはコネクションを閉じて再接続してくれます。
比較
あるWebアプリケーションに対し、分間3,000リクエスト(750スレッド)をJMeterから45分間送信しました。
そして、Webアプリケーション内にいくつかある画面へのリクエストのうち、素(単独実行時)の処理時間が短/中/長の3種類を抜き出してみました。
※単位はミリ秒。なお、スレッド(ユーザ)ごとにデータ量のばらつきが大きいため、特に「長」の画面のSQLの処理時間は素の状態でもばらつきがあります(最長で8.5秒程度)。その他の条件は以下の通り。
- Webサーバは4台(EC2 r4.large/Amazon Linux 2017/09版/各AZに2台ずつ/Tomcat 8.0.47)
- Auroraはdb.r4.2xlargeをメインDBに2クラスタ/各クラスタWriter・Reader1台ずつ/Ver.1.16
- 結果はJMeterによる集計値(JMeterクライアントは2台)
- DBCP2の結果
| リクエスト(画面) | 平均値 | 中央値 | 90%値 | 最小値 | 最大値 |
|---|---|---|---|---|---|
| 短時間処理の画面 | 60 | 49 | 78 | 24 | 22,832 |
| 中程度の画面 | 234 | 177 | 332 | 86 | 21,607 |
| 長時間処理の画面 | 728 | 171 | 1,827 | 45 | 24,557 |
- HikariCPの結果
| リクエスト(画面) | 平均値 | 中央値 | 90%値 | 最小値 | 最大値 |
|---|---|---|---|---|---|
| 短時間処理の画面 | 46 | 45 | 57 | 22 | 347 |
| 中程度の画面 | 172 | 158 | 242 | 83 | 3,087 |
| 長時間処理の画面 | 676 | 146 | 1,703 | 41 | 9,524 |
全体的にHikariCPが速いですが、注目すべきは最大値です。
DBCP2の場合、短/中/長いずれも20秒台となっています。これは、SQLを並列で流すときにDBサーバ(Aurora)の処理が遅くなったからではなく、プールからコネクションを取得(借用)するのに(他のスレッドの処理に影響されて)待ち時間が発生していることを示しています。
一方、HikariCPの場合、この程度のリクエスト数であれば**「素のSQL処理時間+α」の範囲内**でレスポンスを返しています。
フェイルオーバー動作
DBCP2では、アプリケーションの動作負荷が高くなると、すぐにフェイルオーバー後の再接続が詰まってしまう状況になりがちでした。
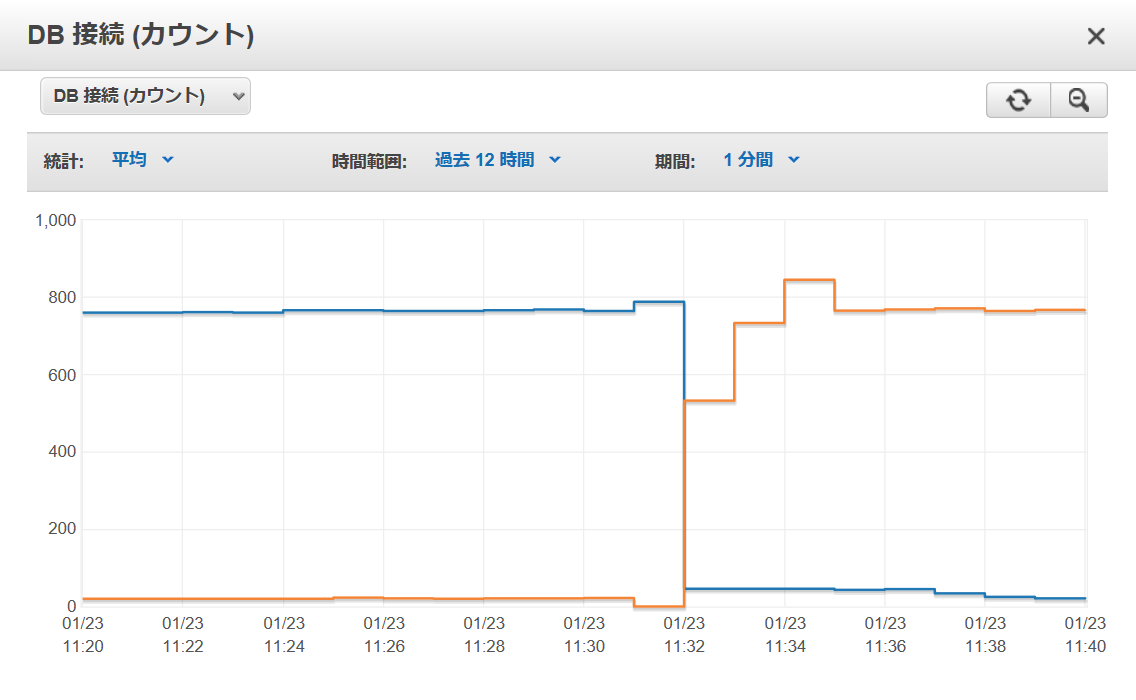
HikariCPで前述の負荷を掛けながらフェイルオーバーを実行したところ、下図の通り短時間に再接続が行われる状態になりました。
まとめ
負荷が低い状態ではそれほど差がわかりませんが、ある程度負荷が掛かるシステムの場合、コネクションプールによって性能が大きく変わり、それによって接続数のキャパシティ(スケール可能な範囲)やフェイルオーバー動作の安定性も大きく変わることがわかりました。
特に、オンプレからAWS環境に移行する場合やDBのみAuroraに移行する場合など、WebサーバやSQLを発行するクライアントからの通信遅延(レイテンシ)が大きくなることで**「以前はDBCP2で何の問題もなかったけれど、移行した途端に接続数がうまくスケールせずに詰まるようになった」**などの事象が発生しがちなので、移行の際には注意深く検証する必要があると思います。