これは MySQL Advent Calendar 2023 の 20 日目の記事です。
昨日(19 日)は tom--bo さんでした。
以前、GA 前の Aurora MySQL で Redshift との Zero-ETL 統合を試しました が、re:Invent 2023 期間中に RDS for MySQL との zero-ETL 統合もプレビュー公開されましたので、同じように試してみました。
この記事は 2023/12/13 現在の情報をもとに構成しています。
Zero-ETL 統合についておさらい
ざっくりいうと 細かい ETL の設定なしにデータウェアハウスや分析基盤などにデータを流す機能 です。
以前の記事での説明は以下のとおりです。
Aurora などのリレーショナルデータベース上のデータは、通常 ETL(Extract(抽出)/ Transform(変換)/ Load(ロード)の略)の流れを経て Redshift などのデータウェアハウスや分析基盤への流し込みを行います。
Aurora と Redshift のゼロ ETL 統合は、 この部分の構築・設定を簡素化し、ほぼリアルタイムでデータの流し込み(複製)を可能にする機能 です。
結果として、Redshift を使用した分析や機械学習がほぼリアルタイムで実行できます。
今回は Aurora ではなく RDS for MySQL で試します。
Aurora PostgreSQL も同時にプレビュー公開されています(オハイオリージョン限定)。
手順
ほぼ Aurora MySQL のときと同じですが、不可解なエラーで設定が詰まることはありませんでした。
ただし、試用中に一つだけ大きな問題が発生しました(後述)。
1. DB パラメータグループ作成
ユーザーガイドの指示どおりに設定します。
binlog_format=ROWbinlog_row_image=fullbinlog_checksum=NONE
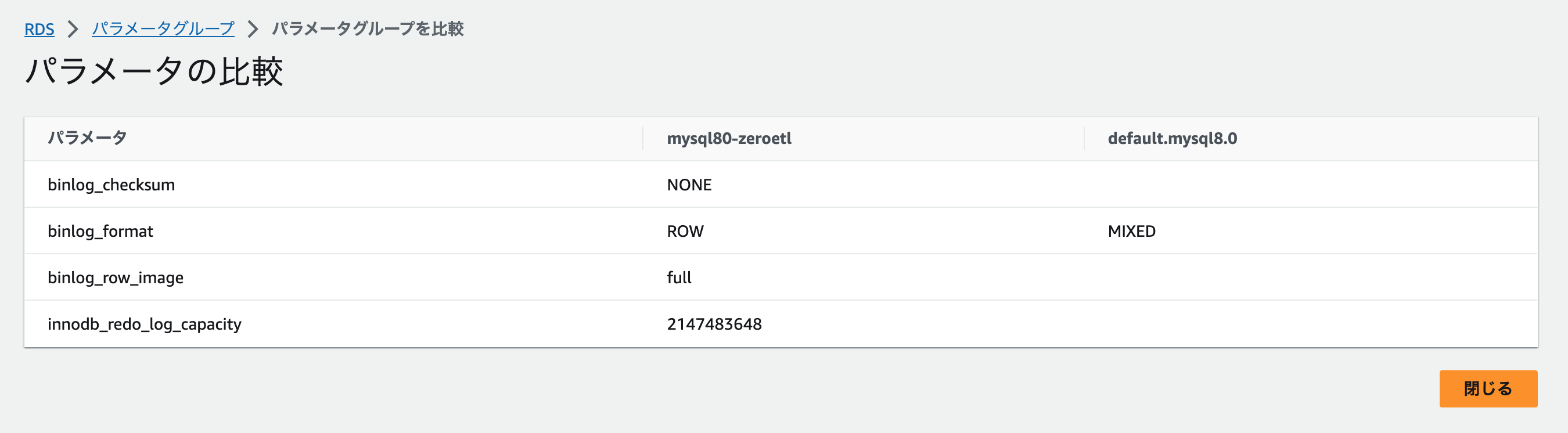
innodb_redo_log_capacityはデフォルト値のまま未変更です。
2. ソース DB(RDS for MySQL)作成
RDS for MySQL 8.0.28 以降の DB インスタンスを作成します。
- MySQL Community Edition
- エンジンバージョン : 8.0.35
- テンプレート : 開発 / テスト用(単一のインスタンス)
- DB インスタンス識別子 : 任意(今回は初期値
database-1のまま作成) - AWS Secrets Manager でマスター認証情報を管理しない
- DB インスタンスクラス : 今回は db.t4.small を選択
- ストレージ : 今回は gp3 20GiB(最低容量)
- コンピューティングリソース : EC2 コンピューティングリソースに接続しない
- ネットワークタイプ : 今回は IPv4
- VPC / DB サブネットグループ : 任意
- パブリックアクセス : なし
- VPC セキュリティグループ : 作業用の EC2 や Zero-ETL 統合先の Redshift に接続できるように設定したものを選択
- データベース認証 : 今回は「パスワード認証」のまま
- DB パラメータグループ : 1. で設定したものを指定
- 自動バックアップを有効化
- バックアップ保持期間 : 最低 1 日間
- 暗号化 : 今回はデフォルトのキーで有効化
3. ターゲット Redshift データウェアハウスを作成(Redshift Serverless プレビュー版ワークグループ)
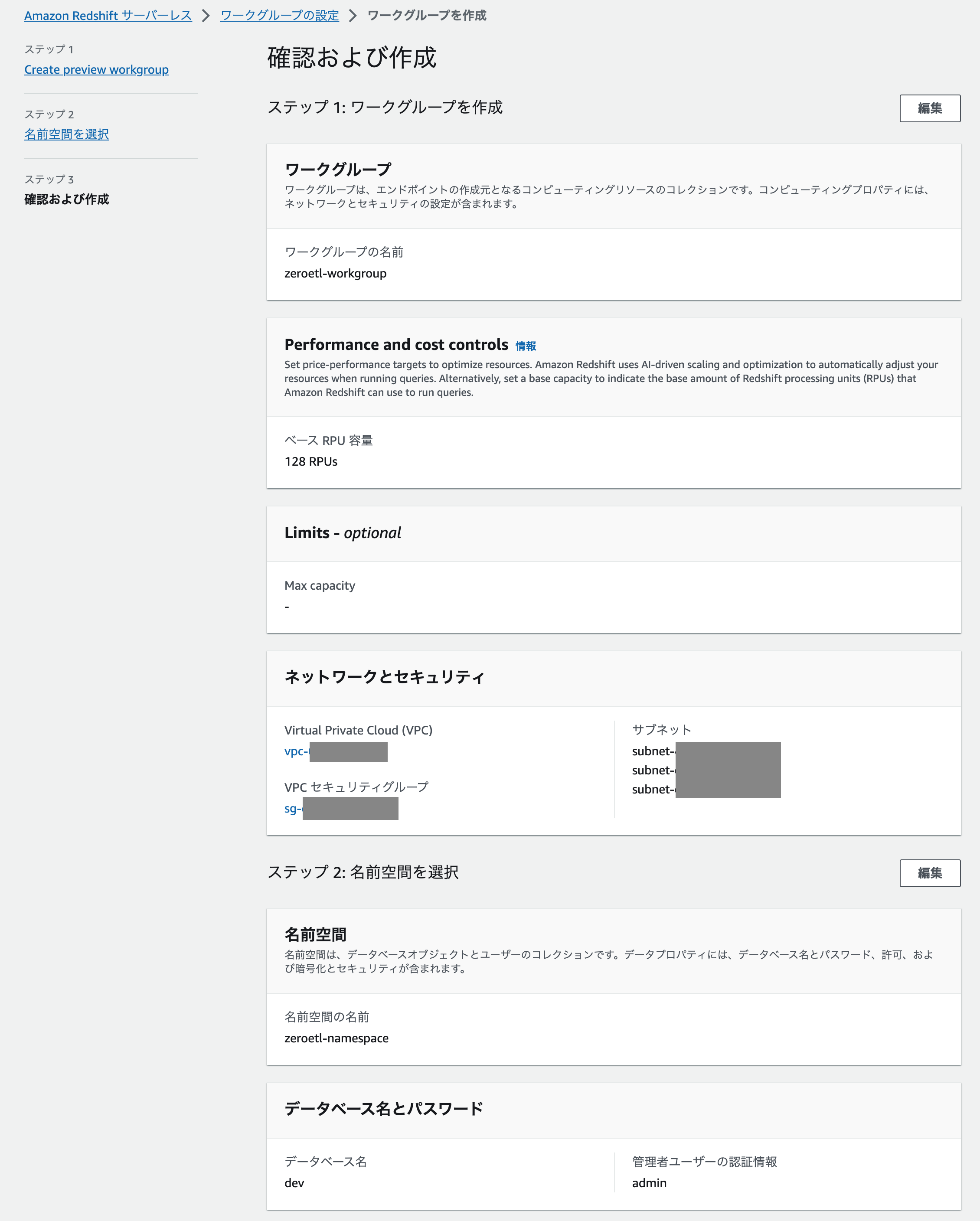
Aurora MySQL のときと同様に画面右上の「Create preview workgroup」から Redshift Serverless のプレビュー版を作成します。
- ワークグループ名 : 任意(今回は
zeroetl-workgroup) - Performance and cost controls : ベース RPU 容量を選択(容量は 128)
- ネットワークとセキュリティ : RDS インスタンスに接続可能な VPC・セキュリティグループ・サブネットを指定
- 名前空間 : 新しい名前空間を作成(今回は
zeroetl-namespace) - 許可 : 「デフォルトを設定」から新規に作成(ロールがアクセスする S3 バケットに「任意の S3 バケット」を指定)
- 作成したロールを選択(チェック)して関連付け
- ログはひととおりチェックを入れて出力対象に
作成したらユーザーガイドの Enable case sensitivity on the data warehouse のとおりに CloudShell から大文字・小文字の識別を有効化します。
aws redshift-serverless update-workgroup \
--workgroup-name zeroetl-workgroup \
--config-parameters parameterKey=enable_case_sensitive_identifier,parameterValue=true
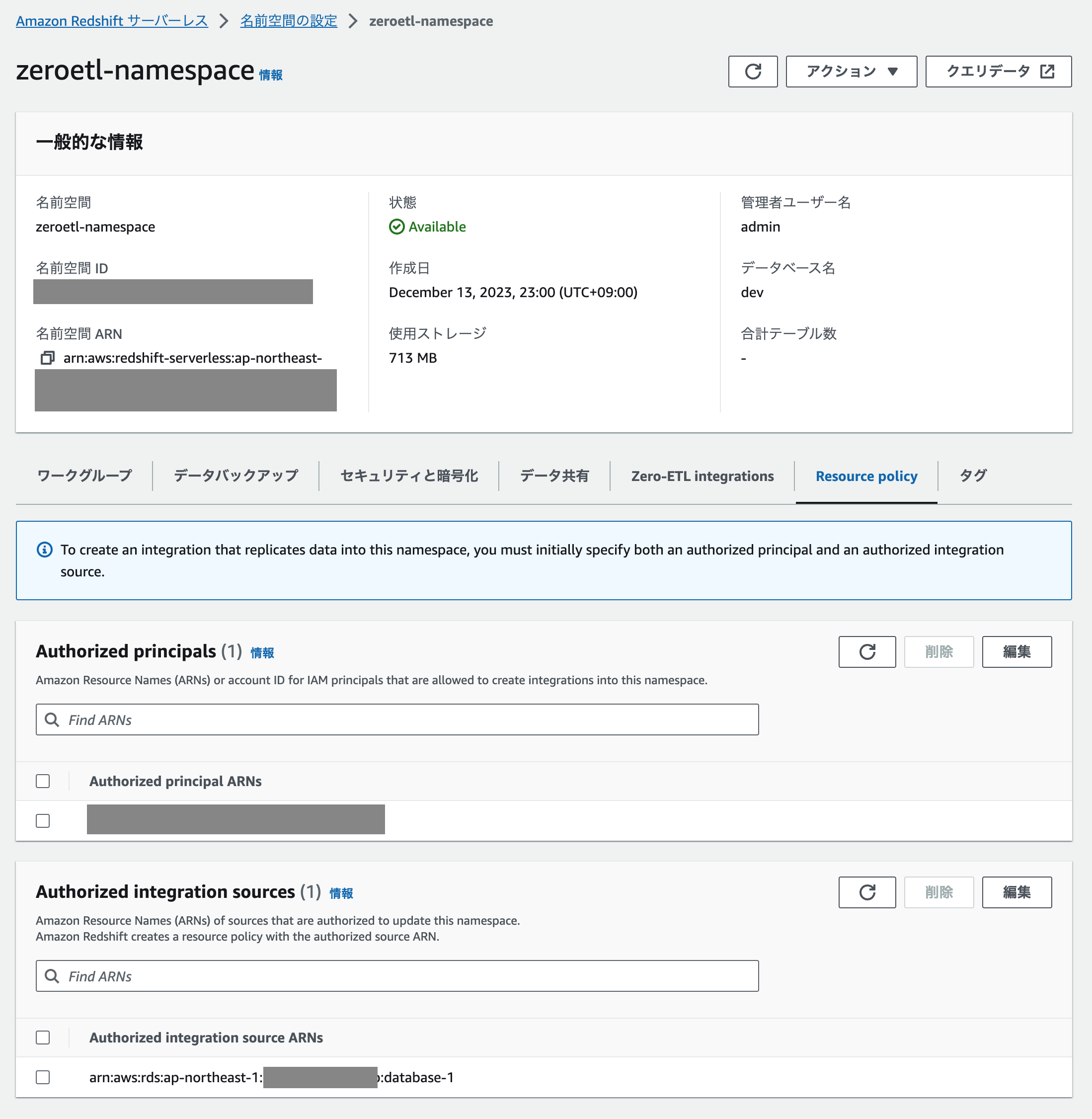
そして名前空間の Authorized principals と Authorized integration sources を設定します(それぞれ右上の「Add…」ボタンから)。
- Authorized principals : アカウント ID を指定
- Authorized integration sources : ソース DB の ARN を指定
4. Zero-ETL 統合を作成
まずユーザーガイドのこちらの Sample policy を参考に IAM でポリシーを作成します。
そのポリシーを持つ IAM ロールを作成し、先ほどの名前空間の Authorized principals に追加します。
この工程(IAM ロール作成・追加)は不要かもしれません。
ユーザーガイドを参考に、DB インスタンスの「ゼロの ETL 統合」タブから Zero-ETL 統合を作成します。
- 統合名 : 任意(今回は
zeroetl) - ソースデータベース : 2. で作成した DB
- Data warehouses : 先ほど作成した名前空間(
zeroetl-namespace)- ここでポリシーの権限が足りない場合は↓のような警告が表示され、「Fix it for me」をチェックすると修正内容の確認が表示されます。
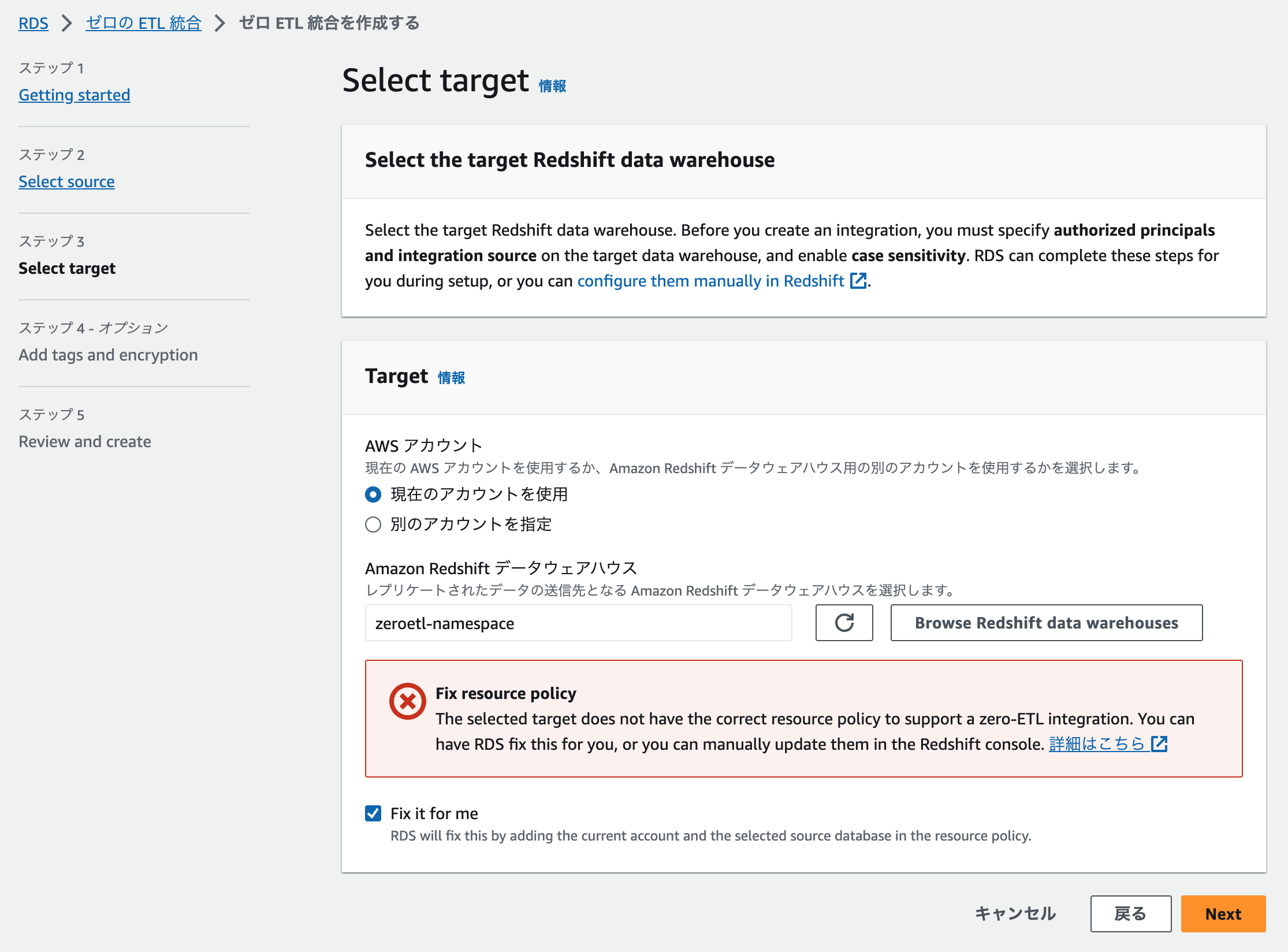
確認して作成します。
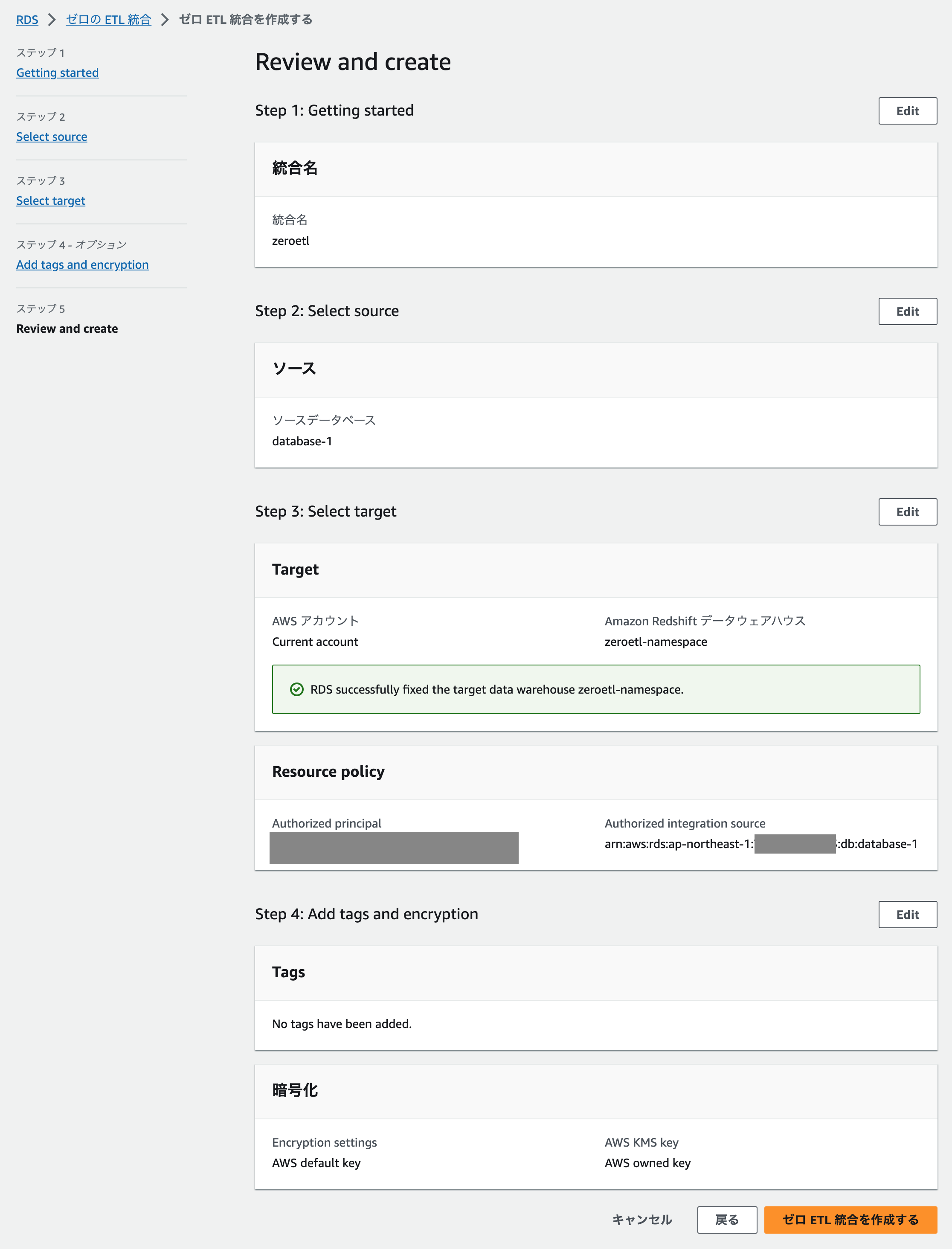
しばらく(初回は 30 分前後かそれ以上)待つと Zero-ETL 統合の Status が Active になります。
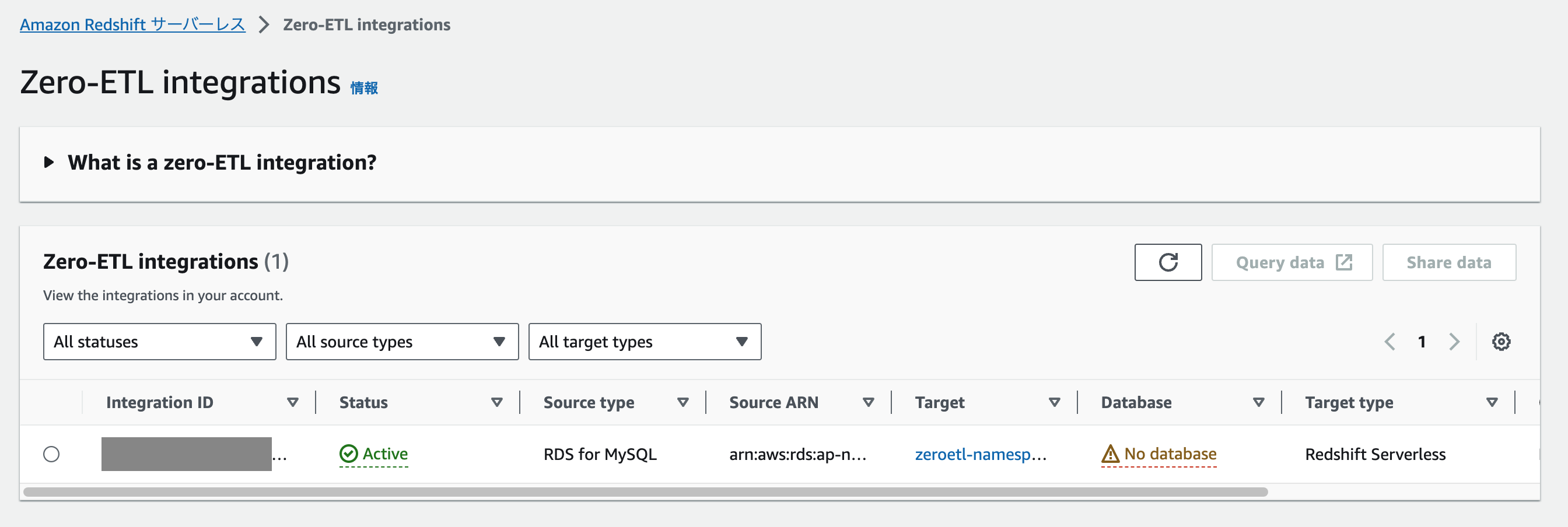
データウェアハウスのデータベースが作成されていないので、Zero-ETL 統合の画面から「Create database from integration」ボタンをクリックして作成します。
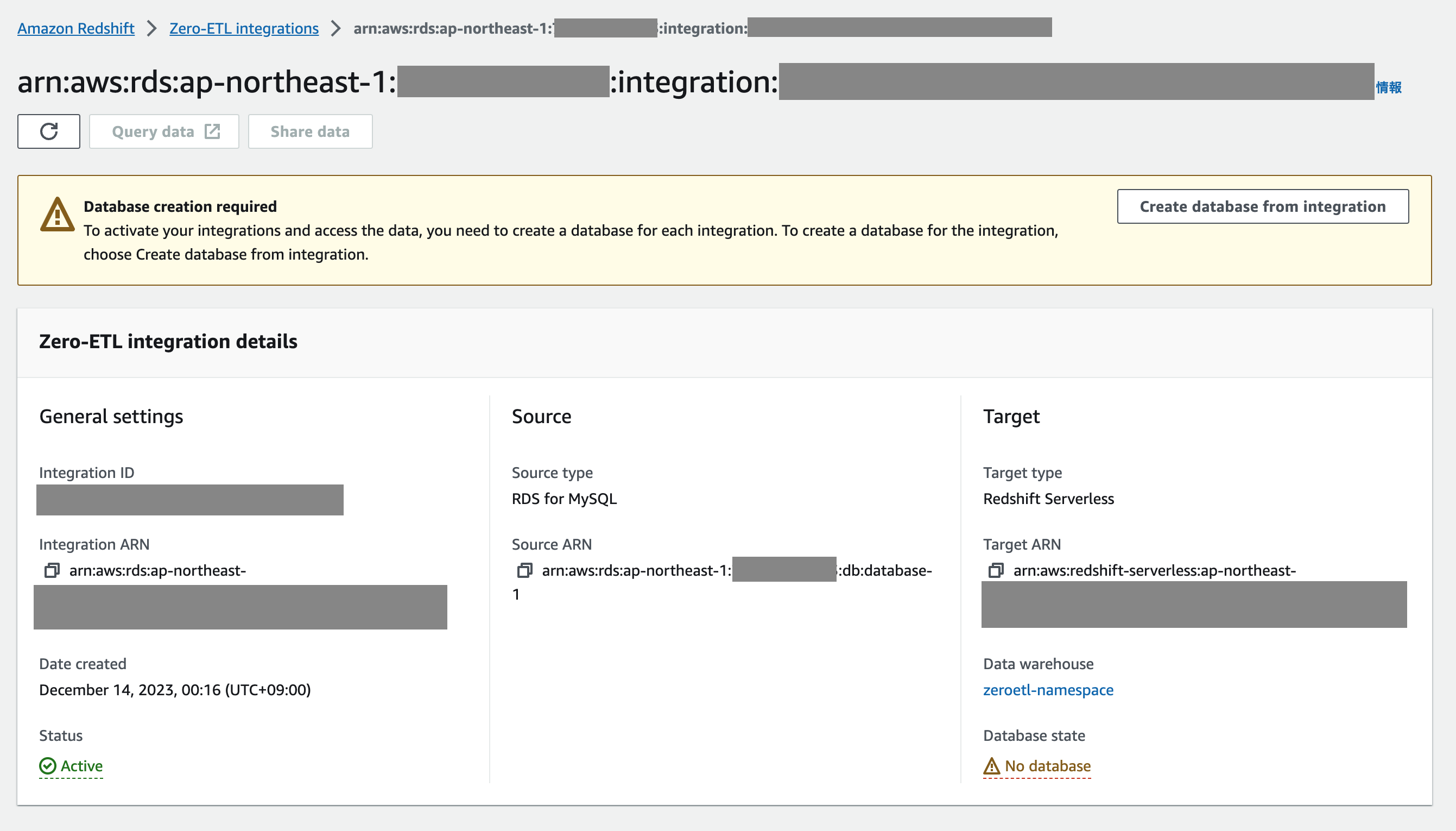
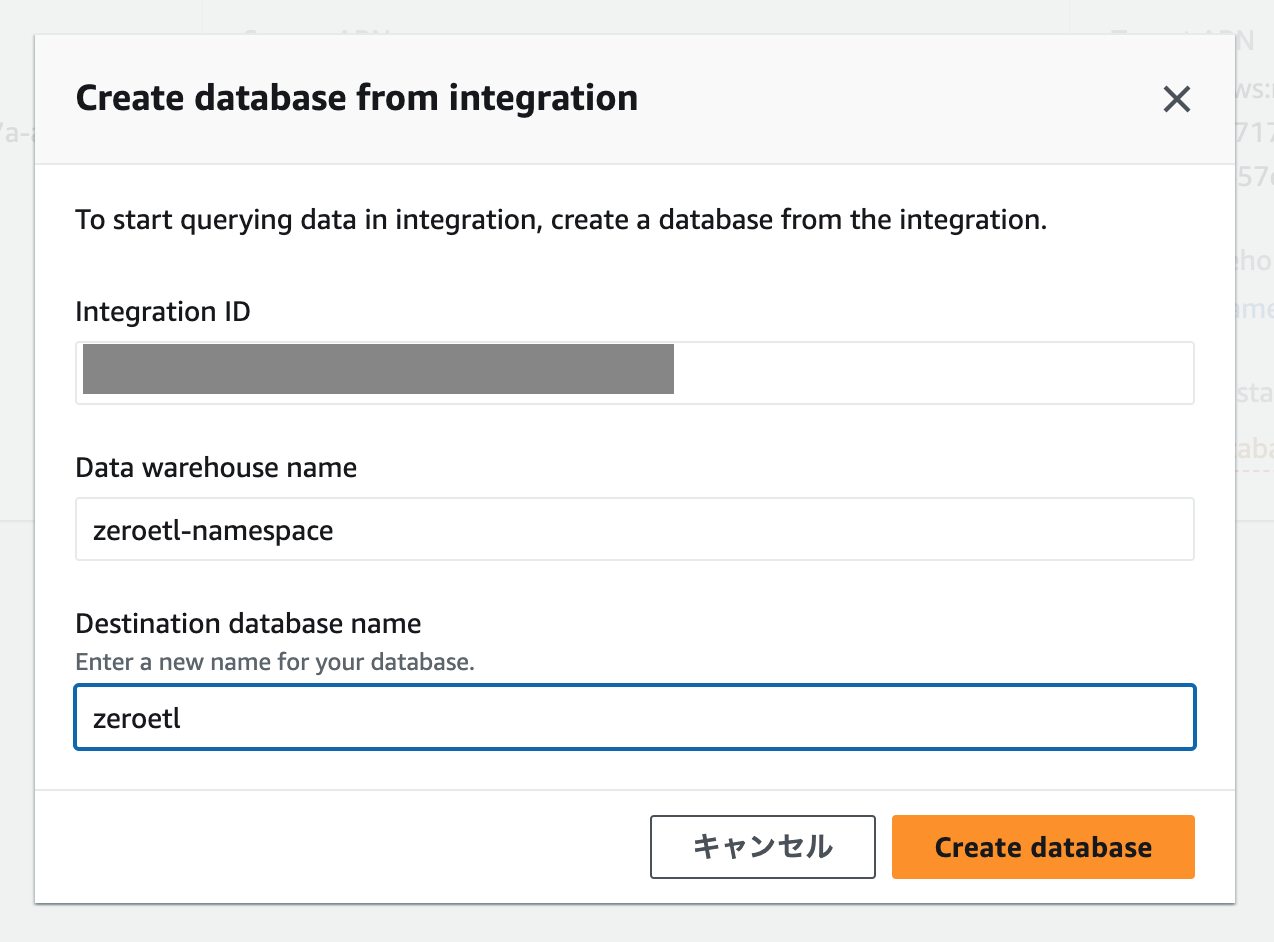
再びしばらく待つとデータウェアハウスのデータベースが作成されてデータがロードされます。
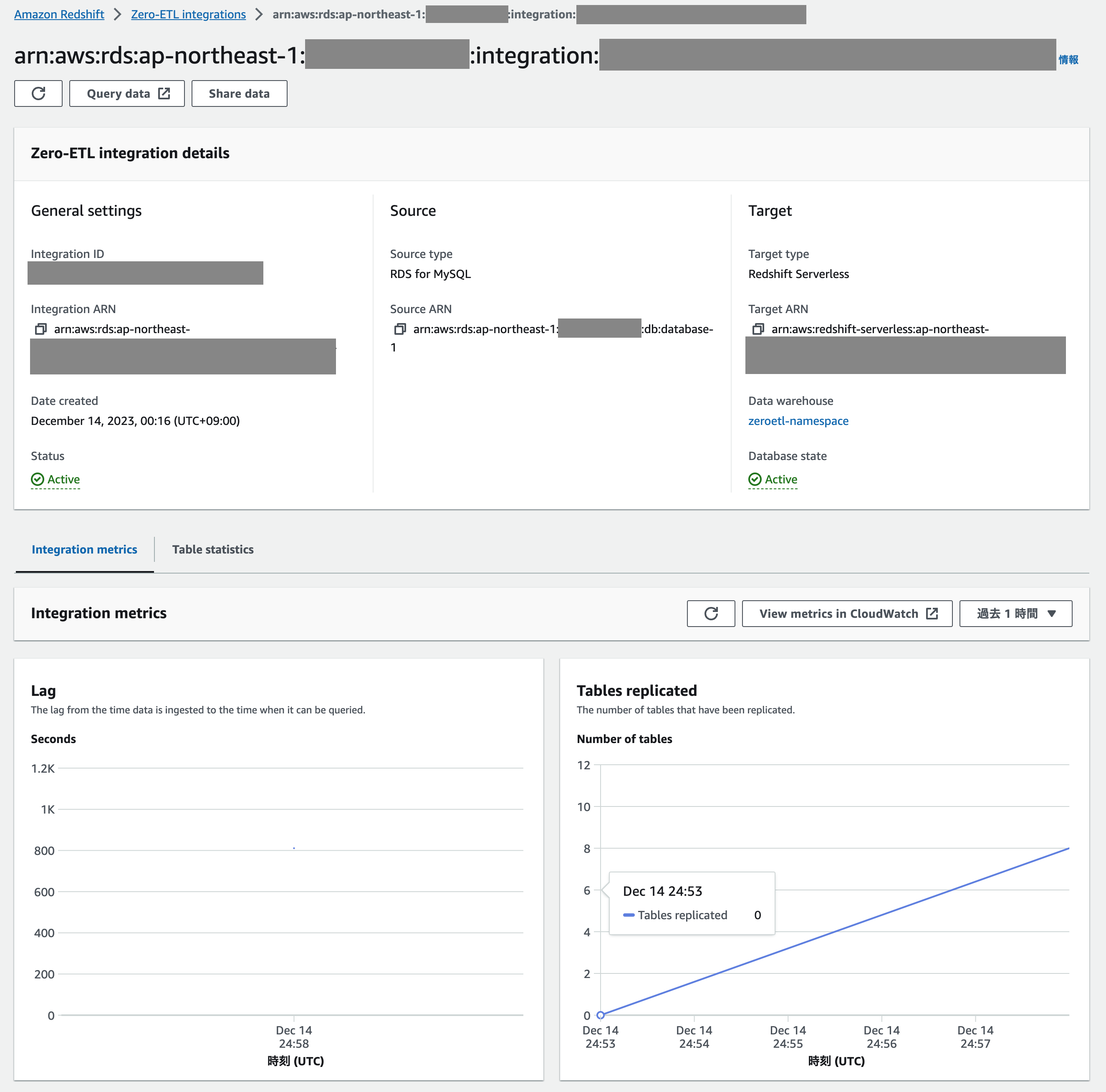
このあたりは Aurora MySQL の Zero-ETL プレビュー版の頃と比べて安定していますね。
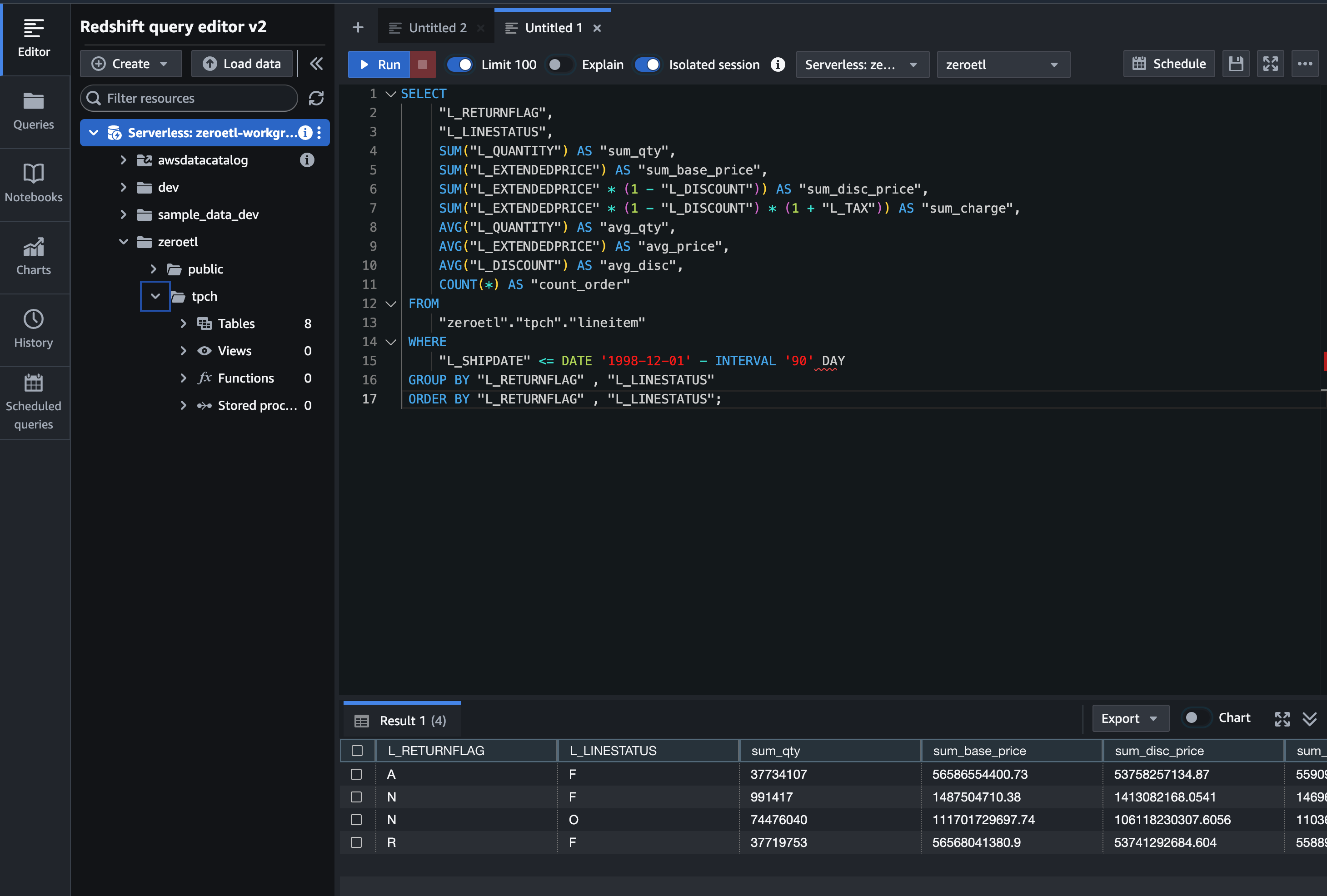
Redshift query editor v2 からクエリを実行すると結果が返ってきました。
注意点
私が実際に試したときには、以下のような不具合が発生しました。
- ソース DB を一時的に停止してその後再開すると、ソース DB での追加・更新・削除がターゲットのデータウェアハウスに一切反映されなくなる
ユーザーガイドの General limitations には、
- If you stop the source DB instance, the last few transactions might not be replicated to the target data warehouse until you resume the instance.
- You can’t delete an integration if the source DB instance is stopped.
とだけ書いてあるので、ソース DB を停止してはいけない仕様ではないはずです。
このときは結局 Zero-ETL 統合を作り直しました。
また、Aurora MySQL の Zero-ETL 統合は GA になりましたが、制約のうち「列フィルタが使えない」点については GA でもそのままです。
- Zero-ETL integrations don’t currently support data filtering.
MySQL から Redshift へ変換できる列の型の範囲が限定されているため、例えばBLOB型の列を持つテーブルは Redshift にそのままデータ連携できません。
そのため、プロダクト利用しているデータベースのテーブルをそのまま Zero-ETL 統合で連携するには少し厳しいのではないか?と思います。
レプリケーションチャネルフィルタの利用も非推奨のようなので、対象テーブルの除外も自己責任になりますし。
- Zero-ETL integrations rely on MySQL binary logging (binlog) to capture ongoing data changes. We recommend that you do not use binlog-based data filtering, as it can cause data inconsistencies between the source and target databases.
おまけ
先日(12/18)の JAWS-UG 名古屋でも少し触れました。
Aurora MySQL で Redshift との Zero-ETL 統合を使うには enhanced binary log の設定が必須、Aurora PostgreSQL(プレビュー)でも enhanced logical replication という(初めて見た)設定が必須になっています。
いずれもコンピュート層を介さずストレージ層で Redshift にデータ転送ができるようです(enhanced logical replication については「IOPS の向上」以外に記述が見当たらないので推測ですが)。
一方で RDS for MySQL の場合は Optimized Writes などは必須ではなく、Zero-ETL 統合作成時と非作成時でパフォーマンスに差がなさそうだったので(いずれも binary log 生成のためのオーバーヘッドのみ発生?)、どこで binary log を読み取ってデータ転送をしているのかは不明です。
明日(21 日)は mita2 さんです。