データベースの論理設計で概念データモデルを作成する際、共通の属性を持つエンティティをスーパータイプ/サブタイプとして表現しますが、これをテーブルに実装する際に、いくつかのパターンがありますので、概要をまとめてみました。
なお、ネットゲームなどの世界では、スーパータイプ/サブタイプをテーブルに実装するための高度なノウハウがあるようですが、そこまで深いところには触れません。あくまでも概要です。
また、コメントでOracleなどが持つ機能の情報を寄せていただきましたが、RDBMS固有の機能についても(あまり)触れていません。
スーパータイプ/サブタイプ
スーパークラス/サブクラスと同様、汎化と特化の関係を表すものです。
スーパータイプは、共通の属性を持ち、主キーも共通している複数のエンティティから、共通の属性を抜き出したものです(=汎化)。
サブタイプは、スーパータイプの属性を除いた、各エンティティの差分にあたるものです(=特化)。
例えば、ある会社の従業員を表すエンティティがあるとします。
その会社では、「正社員」と「パート・アルバイト」に分けて従業員を管理しており、
- 正社員(従業員コード, 氏名, 入社年月日, 等級, 月給)
- パートアルバイト(従業員コード, 氏名, 入社年月日, 時給)
※主キーを太字で示しています。
というような属性を持つとします。
この場合、
- スーパータイプ:従業員(従業員コード, 氏名, 入社年月日, 従業員区分)
- サブタイプ:正社員(従業員コード, 等級, 月給)
- サブタイプ:パートアルバイト(従業員コード, 時給)
と定義することができます。
排他的サブタイプと共存的サブタイプ
サブタイプの種類を区別する切り口はいくつかありますが、テーブルへの実装で考慮が必要なものとして、排他的サブタイプと共存的サブタイプがあります。
排他的サブタイプは、インスタンス(個々のデータ)が特定の1種類のサブタイプにしか属することができないものです。
以下、図ではXがスーパータイプ、A・Bがサブタイプ、点(ドット)がインスタンスを表します。
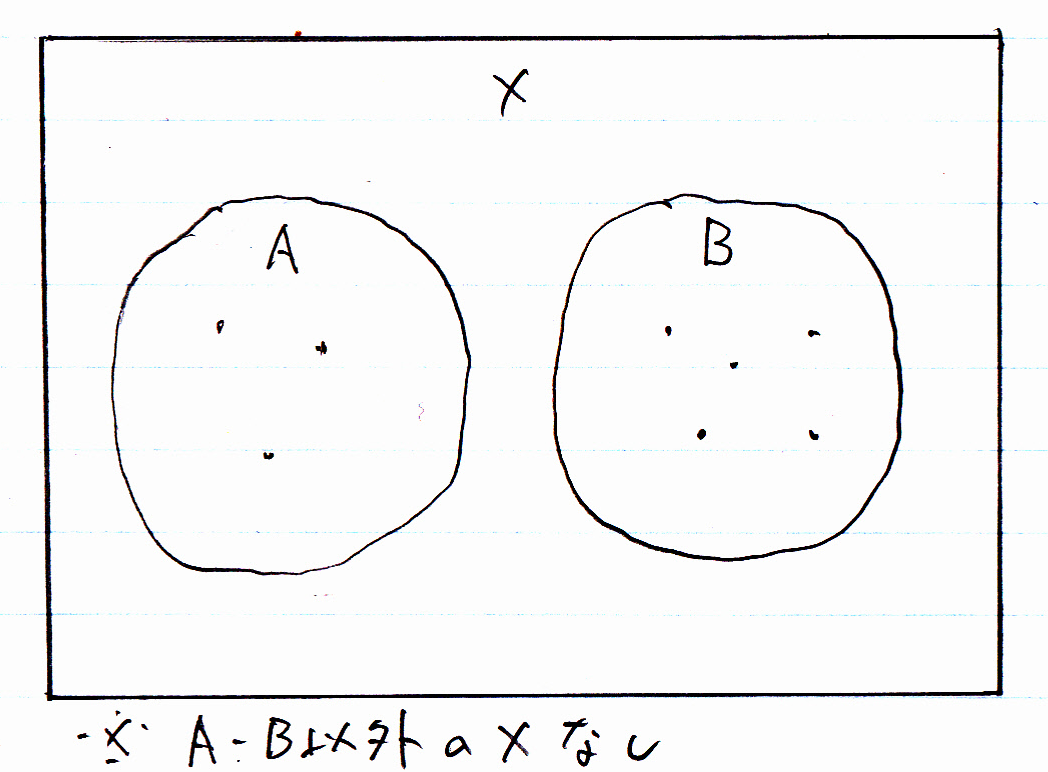
…汚い図ですみません。今、手がこんな状態ですので…。
「AかつB」のインスタンスはありません。
共存的サブタイプは、インスタンスが同時に複数のサブタイプに属することができるものです。
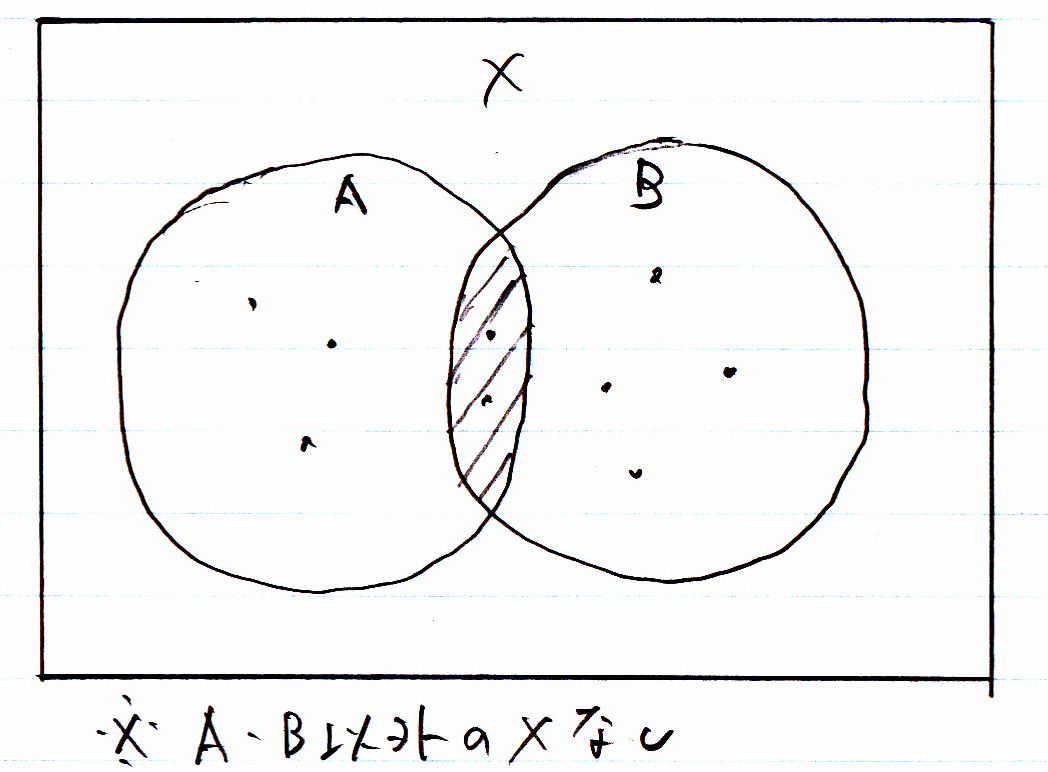
「AかつB」のインスタンスがあります。
先の従業員の例では、「正社員かつパート・アルバイト」の従業員は存在しないので、排他的サブタイプとなります。
別の例として、「実店舗での販売とネット販売を行う会社」があり、取扱商品として、
- 店舗販売のみを行う商品
- ネット販売のみを行う商品
- 店舗販売もネット販売も行う商品
があるとすると、この場合、取扱商品のインスタンスには、「店舗販売商品かつネット販売商品」が含まれますので、こちらは共存的サブタイプとなります。
不完全なサブタイプと包含関係
スーパータイプへの汎化を行った結果、「どのサブタイプにも属さないインスタンス」ができることがあります。このようなパターンを不完全なサブタイプと呼びます。
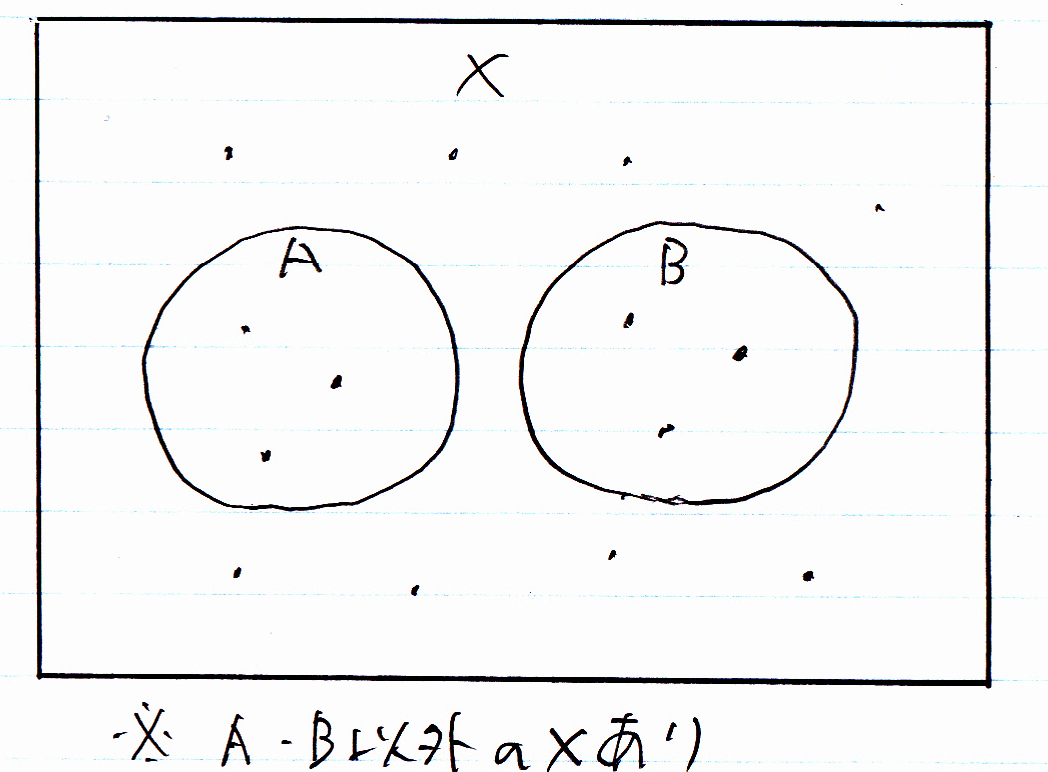
上の図では、サブタイプA・Bに属さないインスタンスがあります。
例えば、いわゆる「フリーミアム」のビジネスモデルで提供されているサービスがあって、「会員」として「有料会員」のみ特別な属性を持って管理している場合がこれにあたります。
また、**「サブタイプのサブタイプ」**という階層関係もあります。
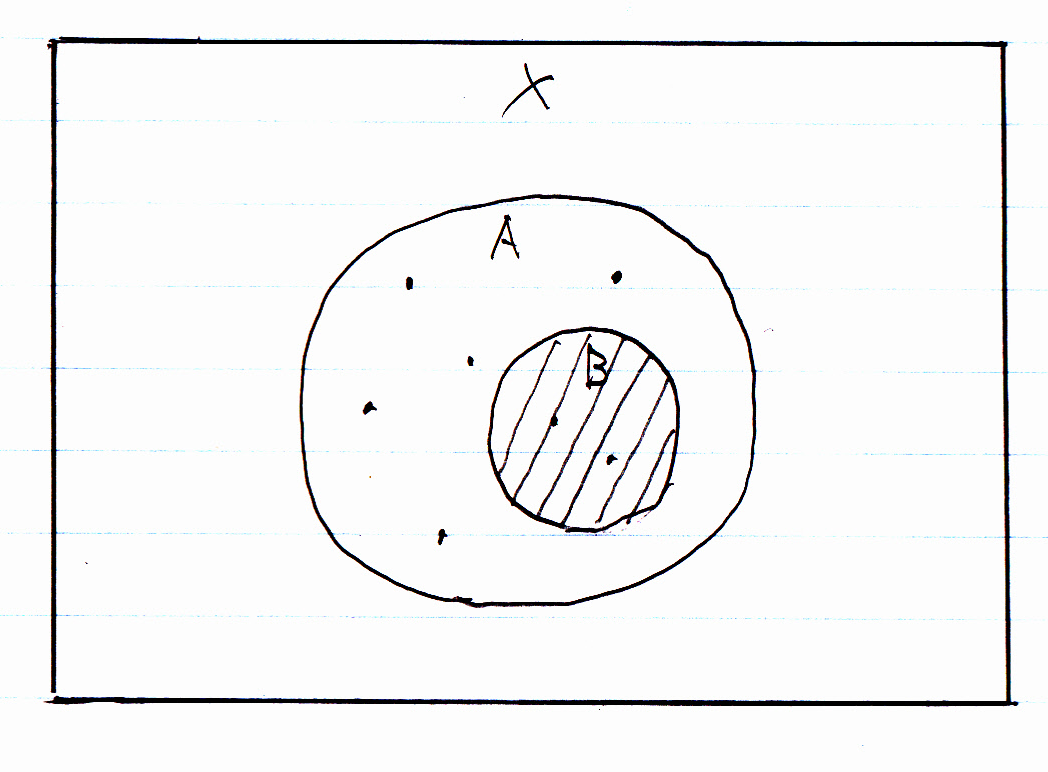
この図では、サブタイプBがサブタイプAに属しています。この場合、**「サブタイプAはサブタイプBを包含している」**ということになります。
先の従業員の例で、サブタイプ「正社員」に「総合職」と「一般職」というサブタイプが含まれる場合、**「サブタイプ正社員は、サブタイプ総合職・一般職を包含している」**といえます。
テーブルへの実装
テーブルへの実装を行う際に気を付ける点には、例えば以下のようなものがあります。
- データをできるだけ冗長に待たない(1 fact 1 place)
- 余分な列(NULL許可列)をできるだけ作らない
- 同一の「子テーブル」を持つ複数の「親テーブル」を作らない
- 個々のテーブルのサイズ(行数×行長)が大きくなりすぎないようにする
これらに気を付けつつ、テーブルへの実装パターンを考えます。
パターン1:スーパータイプのテーブルを作らず、全てを個別のテーブルに実装する
このパターンが適合するケース
- 排他的サブタイプであること
- 同一の子テーブルを持たないこと
- サブタイプ間の独立性が高く、複数のサブタイプを同一の処理で扱わないこと
説明
そもそも、汎化を行わず、スーパータイプのテーブルを作らないパターンです。
先の従業員の例では、
- 正社員(従業員コード, 氏名, 入社年月日, 等級, 月給)
- パートアルバイト(従業員コード, 氏名, 入社年月日, 時給)
をそのまま、個別のテーブルとして実装するパターンです。
アンチパターンのように見えますが、このデータを扱うシステムが、
- 正社員とアルバイトを完全に分けて扱う(同じ一覧に表示しない、集計処理が完全に独立している)
- 同一の子テーブルを持たない
のであれば、適合する可能性があります。
また、一見、同一の子テーブルを持つように見えても、**「属性が共通しているだけで、子テーブルのインスタンスを共通の処理でまとめて扱う必要がない」**のであれば、子テーブルも個別のテーブルに分けることで、このパターンに適合するかもしれません。
一方、共存的サブタイプの場合は、共通属性(スーパータイプ部分)を冗長に持たないといけなくなるため、このパターンには合いません。
また、「同一の子テーブルを持つ」場合、サブタイプ間で主キー値の重複が起こるとシステム障害の原因にもなるので、このパターンは避けます(実際に、身近でそのような障害を見たことがあります)。
パターン2:全てのサブタイプを同一テーブルに実装する
このパターンが適合するケース
- サブタイプ固有の属性が少ないこと(=サブタイプ間の差分が小さい)
- サブタイプ間の独立性が低く、同一の処理で複数のサブタイプを扱う場合が多いこと
- テーブルのサイズ(行数×行長)が大きくなりすぎないこと
説明
テーブルをサブタイプで分けずに、共通属性(=スーパータイプ部分)もサブタイプ固有の属性も、全て1つのテーブルに実装するパターンです。
先の従業員の例でいうと、
- 従業員(従業員コード, 氏名, 入社年月日, 従業員区分, 等級, 月給 , 時給)
の形でテーブルに実装するパターンです。
このパターンでは、テーブル設計がシンプルになりますが、サブタイプ間の差分が大きい場合は無駄なNULL許可列が大量に作られることになりますし、テーブルサイズが大きくなると検索効率が低下します。
パターン3:スーパータイプを1つのテーブルに実装し、サブタイプを個別のテーブルに実装する
このパターンが適合するケース
- サブタイプ固有の属性が少なくないこと(=サブタイプ間の差分がそれなりにある)
- サブタイプ間の独立性がそこそこあるが、共通の処理も存在すること
説明
テーブルを、ほぼ論理設計通りに実装するパターンです。
先の従業員の例でいうと、
- 従業員(従業員コード, 氏名, 入社年月日, 従業員区分)
- 正社員(従業員コード, 等級, 月給)
- パートアルバイト(従業員コード, 時給)
の形でテーブルに実装するパターンです。
従業員テーブルが親テーブル、正社員テーブルとパートアルバイトテーブルが子テーブルの関係になります。
分かりづらいですが、正社員テーブルとパートアルバイトテーブルの「従業員コード」は、従業員テーブルの「従業員コード」に対する外部キーでもあります。
※実際には、RDBMSごとの特性に応じてテーブル実装することになるため、例えばMySQLなどでは、本来の主キーの代わりに連番(AUTO_INCREMENT)の代理キー(サロゲートキー)を使うことがよくあります。その場合、
- 従業員(従業員テーブルID, 従業員コード, 氏名, 入社年月日, 従業員区分)
- 正社員(正社員テーブルID, 従業員テーブルID, 等級, 月給)
- パートアルバイト(パートアルバイトテーブルID, 従業員テーブルID, 時給)
のようになったりします(斜体は外部キーを表します)。
この例は、サブタイプ間の差分が小さいので現実的ではないですが、もっと差分が大きかったり、サブタイプ側にサイズの大きな属性があるときには、このパターンが適合します。
但し、SQLでデータを取り出す場合に、結合(JOIN)が多くなり、パフォーマンスに影響が出る可能性があります。もっとも、メモリキャッシュ/バッファ(MySQLでいうところのバッファプール)のサイズとの兼ね合いもあり、一概にはいえませんが。
なお、スーパータイプの属性を全て親テーブル側に定義するかどうかについては、検討の余地があります。
共通の処理で扱う属性は親テーブル側に残すべきですが、共通の処理では扱わず、サブタイプの個別処理で扱う属性は、子テーブル側に持って行ったほうが良いかもしれません。
先の従業員の例で、「等級」という属性が正社員だけではなく、パートアルバイトにも存在するとします。
もしこの「等級」が示す値の意味が、正社員の場合とパートアルバイトの場合で違うのであれば子テーブル側に実装するのが当然として、値の意味が共通しているとしても、正社員・パートアルバイト共通の処理では利用せず、全く別々の処理で利用するのであれば、子テーブル側に実装するのが良い可能性があります。
その他
サブタイプの数が非常に多くなることもあります(数十・数百~)。
その場合、全てのサブタイプを別々のテーブルに実装するのは現実的ではないため、例えば先に示した包含関係に合わせるなど、共通性の高いサブタイプごとにテーブルをまとめることになるでしょう。
また、テーブル定義を行う際には、外部キー制約、検査制約などを利用することも検討します。
アプリケーションに不具合がなく、入力値チェックが完全であれば、データの整合性も保てる、と思いがちですが、アプリケーションにはバグがつきもので、データが登録されてしまった後に不整合の有無と原因を調査するのは、登録される前にエラーが出てバグの原因を探すよりも大変です。
排他的サブタイプのチェックが漏れがちですが、検査制約(CHECK制約…MySQLにはありませんが)やトリガなどの機能で、データ登録時にチェックすることが可能です。