こちらの記事は2024/12/09時点の内容となります。
はじめに
プレビュー段階ではありますが、Azure OpenAI ServiceのGPT-4o Realtime Audioが使用できるようになりました。
GPT-4oモデルの一種であり、音声での対話が低遅延で行えるモデルです。
これまでは、音声入力した内容を文字起こしする → 生成AIに回答させる → 回答を音声化する という手順を踏む必要があったのですが、このタイムラグが軽減されることになるため、音声を使って生成AIとやりとりするプロダクトには欠かせない存在になりそうです。
やりたいこと
aoai-realtime-audio-sdk のPythonサンプルコードをvenvではなくdocker環境で動かすことが目標です。
README.mdを見てみると、venvを使った環境構築手順が紹介されています。
私が関わっている案件ではdockerを使った開発がメインであるため、dockerで動かせるように調整してみたいと思います。
やらないこと
公式の手順で構築したものとの完全な比較は行いません。
最低限、AOAIの gpt-4o-realtime-preview モデルとやり取りし、結果が返ってくるところまでを目指します。
また、この記事は 2024/12/09時点 の内容であり、積極的に更新は行わない方針ですのでご了承ください。
(前提)docker環境について
今回構築する環境は、python3.11 + FastAPI が動作するdocker環境を想定しています。
具体的な内容は下記を参考にしてください。
⚠️ 抜粋して記載しているため、このまま実行しても動作しませんのでご了承ください。
ディレクトリ構成
.
├── docker_images/
│ └── app/
│ └── Dockerfile
├── src/
│ ├── bff/ # サーバサイドのルート
│ │ ├── api/
│ │ │ └── api_v1/
│ │ │ ├── endpoints/
│ │ │ │ └── sample.py # APIの処理を記述
│ │ │ └── api.py # APIのルーティング処理を記述
│ │ ├── core/
│ │ │ └── config.py # サーバサイドの基本設定・定数の管理
│ │ ├── public/ # フロントエンドのビルド結果が格納される
│ │ ├── schemas/ # APIのリクエスト・レスポンスの型定義
│ │ ├── services/ # APIが呼び出すビジネスロジックを記述
│ │ ├── utils/ # Azureサービスの操作・汎用的な処理など
│ │ ├── main.py # サーバサイドで最初に呼び出される
│ │ └── requirements.txt
│ └── frontend/ # フロントエンドのルート
│ (※)フロントエンドのコードは今回の本題から逸れるため割愛
├── .env # 環境変数を格納するファイル(gitignoreすること!)
├── compose.yml
└── Makefile
主要ファイル
ARG DISTROLESS_VER
FROM python:3.11-slim AS builder
WORKDIR /app/src
COPY src/bff/ ./
RUN set -x \
&& apt update -y \
&& apt upgrade -y \
&& \
: "package install" \
&& pip --no-cache-dir install --upgrade pip \
&& mv requirements.txt ../ \
&& cd .. \
&& pip install --no-cache-dir --target py-packages -r requirements.txt \
&& \
: "権限を変更" \
&& chown -R 1000:1000 /app
FROM gcr.io/distroless/python3:${DISTROLESS_VER}
WORKDIR /app/src
COPY --from=builder /app ../
ENV PYTHONPATH=/app/py-packages
EXPOSE 8000
CMD ["/app/py-packages/bin/uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
from api.api_v1.endpoints import sample
from fastapi import APIRouter
api_router = APIRouter()
api_router.include_router(sample.router, prefix="", tags=["sample"])
from pydantic_settings import BaseSettings
class Settings(BaseSettings):
API_V1_STR: str = "/api/v1"
class Config:
case_sensitive = True
settings = Settings()
from api.api_v1.api import api_router
from fastapi import FastAPI
from core.config import settings
app = FastAPI()
app.include_router(api_router, prefix=settings.API_V1_STR)
app.mount("/", StaticFiles(directory="public", html=True), name="static")
fastapi==0.115.*
uvicorn==0.32.*
pydantic-settings==2.6.*
services:
app:
build:
context: .
dockerfile: ./docker_images/app/Dockerfile
args:
DISTROLESS_VER: "debug-nonroot"
container_name: "sample-app"
volumes:
- ./src/bff:/app/src:cached
command: "/app/py-packages/bin/uvicorn main:app --host 0.0.0.0 --port 8000 --reload"
ports:
- 8000:8000
tty: true
env_file:
- .env
aoai-realtime-audio-sdkから必要なものを移植する
ようやく本題です。
aoai-realtime-audio-sdk のPythonサンプルコードのうち、/python/samples/client_sample.py を動かすことを考えます。
1. client_sample.pyを移植
今回のディレクトリ構成の場合、API内で実行するビジネスロジックは src/bff/services/ へ置くという決まりにしているので、ここに /python/samples/client_sample.py の内容をそのまま移植します。
...
├── src/
│ ├── bff/
│ │ └── services/
│ │ └── client_sample.py # client_sample.pyをそのまま移植
...
2. 環境変数を追加
client_sample.py の with_azure_openai メソッドで、下記の環境変数が呼ばれています。
endpoint = get_env_var("AZURE_OPENAI_ENDPOINT")
key = get_env_var("AZURE_OPENAI_API_KEY")
deployment = get_env_var("AZURE_OPENAI_DEPLOYMENT")
これらに相当する値を .env ファイルに追加しておきます。
⚠️ このファイルはgitignoreするなどして適切に管理するようにしてください。
3. rtclientを移植
さて、client_sample.py の内容を眺めると、下記のようなimportがあります。
from rtclient import (
InputAudioTranscription,
RTAudioContent,
RTClient,
RTFunctionCallItem,
RTInputAudioItem,
RTMessageItem,
RTResponse,
ServerVAD,
)
どうやら /python/rtclient の内容をimportしているようです。
必要そうなので、このディレクトリも丸ごと移植します。
...
├── src/
│ ├── bff/
│ │ └── rtclient/ # 丸ごと移植
...
4. requirements.txtを移植
追加でライブラリが必要になりそうな予感がするので /python/samples/requirements.txt を確認してみたところ、下記の4つのライブラリが含まれていました。
python-dotenv
soundfile
numpy
scipy
環境変数の展開は compose.yml でまとめて行いたいので、python-dotenv は今回追加しないでおきます。
fastapi==0.115.*
uvicorn==0.32.*
pydantic-settings==2.6.*
soundfile
numpy
scipy
5. APIの追加
パッと移植できるところは移植してしまったので、とりあえずAPIが実行できるように下記のコードを追加します。
from fastapi import (APIRouter, File, Form, UploadFile)
from fastapi.responses import JSONResponse
from services.client_sample import with_azure_openai
router = APIRouter()
@router.post("/process_audio/")
async def process_audio(audio_file: UploadFile = File(...), out_dir: str = Form(...)):
temp_file_path = f"/tmp/{audio_file.filename}"
with open(temp_file_path, "wb") as temp_file:
temp_file.write(await audio_file.read())
if not os.path.exists(out_dir):
os.makedirs(out_dir)
try:
await with_azure_openai(temp_file_path, out_dir)
except Exception as e:
return JSONResponse(status_code=500, content={"message": str(e)})
return {"message": "Processing completed successfully"}
6. 環境立ち上げ & エラー解消
docker compose up --build コマンドでdocker環境を立ち上げます。
下記のようなエラーが出ました。
...
File "/app/src/services/interview.py", line 10, in <module>
from azure.core.credentials import AzureKeyCredential
ModuleNotFoundError: No module named 'azure'
調べてみると、azure-core というライブラリが必要なようです。
src/bff/requirements.txt に追加して再度docker環境を立ち上げると、次のエラーが出ました。
...
File "/app/src/rtclient/low_level_client.py", line 10, in <module>
from aiohttp import ClientSession, WSMsgType, WSServerHandshakeError
ModuleNotFoundError: No module named 'aiohttp'
aiohttp も追加して再度docker環境を立ち上げます。
二度あることは三度ある。またエラーが出ました。
...
RuntimeError: Form data requires "python-multipart" to be installed.
You can install "python-multipart" with:
pip install python-multipart
ご丁寧に python-multipart をインストールせよとのことなので、これもsrc/bff/requirements.txt に追加します。
ここまで対応すると、ようやくdocker環境が正常に起動しました!
最終的に src/bff/requirements.txt はこのような状態になりました。
それぞれ最新バージョンの指定を追加してあります。
fastapi==0.115.*
uvicorn==0.32.*
pydantic-settings==2.6.*
soundfile==0.12.1
numpy==2.1.3
scipy==1.14.1
azure-core==1.32.0
aiohttp==3.11.10
python-multipart==0.0.19
本来であれば公式の手順に従って .whl ファイルを展開すべきところを、無理やり強行突破したような感じです。
sdkに含まれる他の機能も試す場合は、更に必要なライブラリが出てくるかもしれません。
7. 実行
APIの実行はFastAPIの 自動ドキュメント生成 の機能を使って行います。
前段でdocker環境が起動していれば、http://localhost:8000/docs にアクセスすることでSwagger UIの画面が表示されます。
記事内のAPIパスと若干異なりますが、下記のようなイメージで無事に実行確認することができました👏
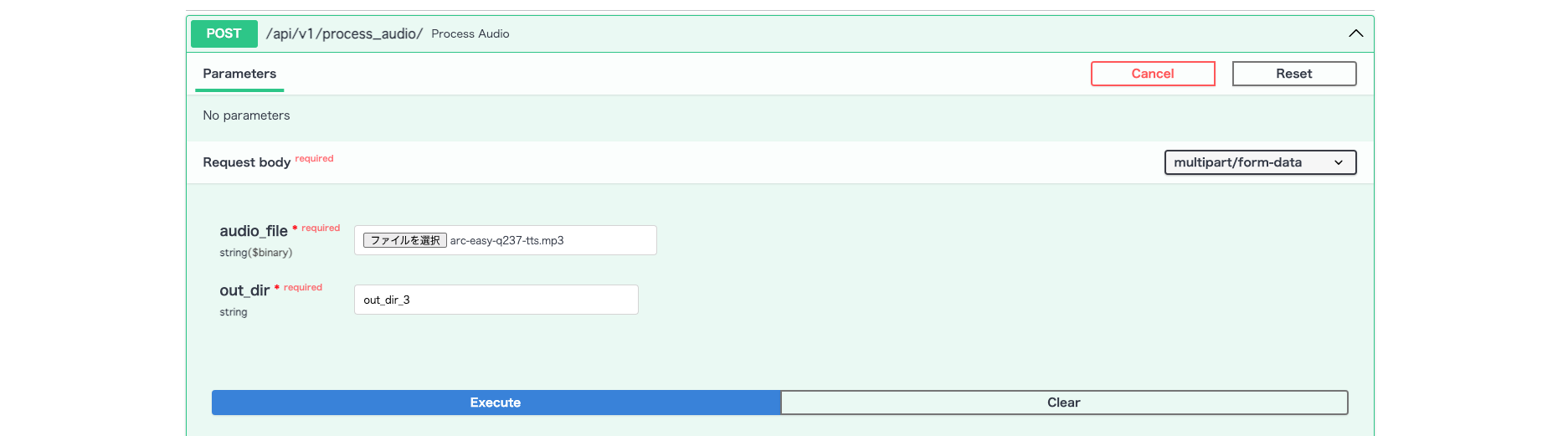
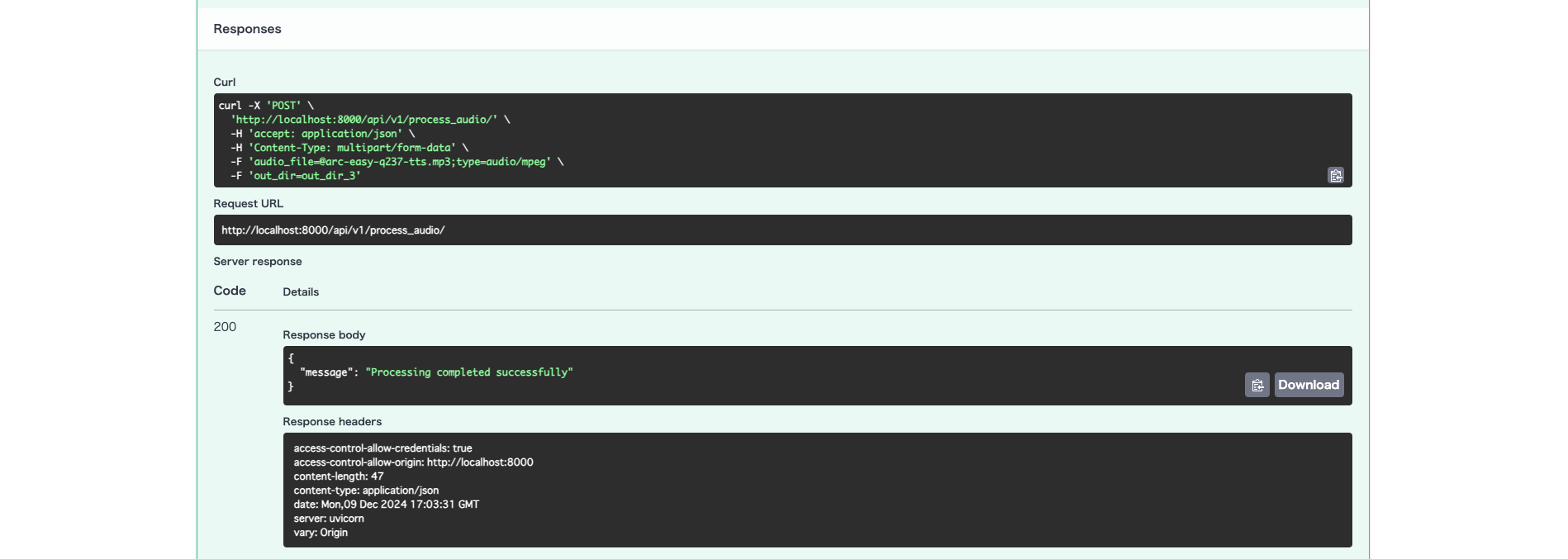
リクエストに使うファイルは、 aoai-realtime-audio-sdk/python/samples/input 内にあったファイルを拝借しました。
また、リクエストとして設定した out_dir 内には 結果ファイル(.wav と .txt の2種類)が出力されていました。
.wav の音声を文字起こしした内容が .txt に反映されているようです。
さいごに
とりあえず動かすところまでは確認できたので、今後はフロントエンドとの繋ぎこみやストリーミングに対応していきたいと思います。
API自体がプレビュー段階なので、今後SDKもより使いやすいものになっていくかな…?と期待しています。
参考文献
下記の記事を参考にさせていただきました!ありがとうございます。