summary
タイトルは煽りです。ごめんなさい。
結論:
- 次の5通りの方法があるが、並び替え後の列名に新しい列名(既存の列名に含まれない)ケースでのエラーを明示的にするため
df[new_col]が無難(タイプ量も少ない観点もプラス)。 - 速度の違いは微々たるものだが、少しでもパフォーマンス要求される場合は
df.loc[:, new_col]が速い。
new_cols = [...]
df[new_cols]
df.filter(new_cols, axis=1)
df.reindex(columns=new_cols)
df.reindex(new_cols, axis=1)
df.loc[:, new_cols]
これは何
Pandas での列の並べ替え方法は複数ある。それらのどれを使えばよいのか調査した。
速度の観点
- 概ね
reindex<filter<.loc[:, ...]<[の順で時間がかかる-
filterは内部でreindexを 呼んでいる -
[->__getitem__->self._take_with_is_copy(pandas.core.generic.py) ->self.takeで 必ずコピーを返す(pandas 1.0 以上) -
.locはclass _LocationIndexer->__getitem_->_getitem_tuple->_getitem_tuple_same_dim->_getitem_axis->self.obj.iloc[tuple(indexer)]と呼び出す method が多い
-
- 列x行の数(以下要素数)に比例して処理時間がかかり、同じ要素数の場合は行数が多い方が処理時間が長い
patterns = {
1: lambda: df[cols_new],
2: lambda: df.filter(cols_new, axis=1),
3: lambda: df.reindex(columns=cols_new),
4: lambda: df.reindex(cols_new, axis=1),
5: lambda: df.loc[:, cols_new],
}
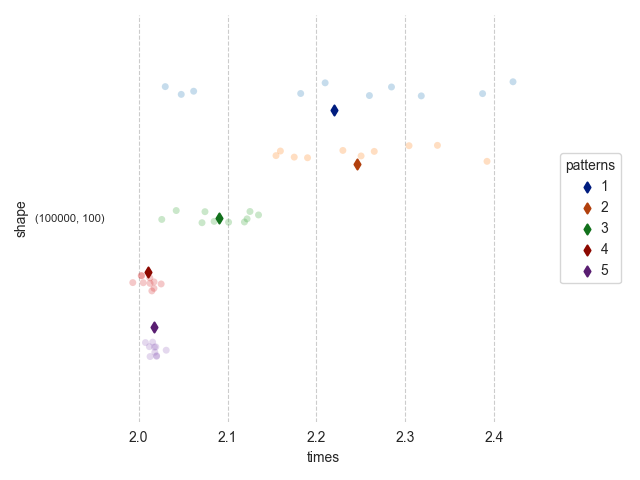
以下の図は DataFrame の各 shape に対する上記5パターンの対応を timeit.repeat(repeat=10, number=100) にて計測した結果である。
python code
import numpy as np
import pandas as pd
import timeit
import seaborn as sns
import matplotlib.pyplot as plt
def make_df(row_num, col_num, seed=1) -> pd.DataFrame:
rng = np.random.default_rng(seed=seed)
return pd.DataFrame({f"x{i}": rng.random(row_num) for i in range(col_num)})
rows = [1_000, 10_000, 100_000, 1_000_000, 10_000_000]
cols = [10, 100]
# limit max shape because (10_000_000, 100) overflows on my machine
dfs = [make_df(r, c) for r in rows for c in cols if r * c <= 1e8]
def reorder_columns(df, repeat=10, n=100, seed=1) -> dict[int, list[float]]:
rng = np.random.default_rng(seed=seed)
col_names = [f"x{i}" for i in range(df.shape[1])]
cols_new = rng.permutation(col_names) # reorder
patterns = {
1: lambda: df[cols_new],
2: lambda: df.filter(cols_new, axis=1),
3: lambda: df.reindex(columns=cols_new),
4: lambda: df.reindex(cols_new, axis=1),
5: lambda: df.loc[:, cols_new],
}
out = {k: timeit.repeat(v, repeat=repeat, number=n) for k, v in patterns.items()}
return out
results = {df.shape:reorder_columns(df) for df in dfs}
results_df = pd.concat([
pd.DataFrame({"shape": str(k), "row": k[0], "col": k[1], "pattern": k2, "times": v2})
for k,v in results.items()
for k2, v2 in v.items()
])
def draw(df: pd.DataFrame, filename: str, show=False) -> None:
plt.clf()
# sns.set_theme(style="whitegrid")
sns.set_style("whitegrid", {'grid.linestyle': '--'})
f, ax = plt.subplots()
sns.despine(bottom=True, left=True)
# Show each observation with a scatterplot
sns.stripplot(x="times", y="shape", hue="pattern",
data=df, dodge=True, alpha=.25, zorder=1)
# Show the conditional means
sns.pointplot(x="times", y="shape", hue="pattern",
data=df, dodge=.532, join=False, palette="dark",
markers="d", scale=.75, ci=None)
# Improve the legend
handles, labels = ax.get_legend_handles_labels()
pos = len(df['pattern'].unique())
ax.legend(handles[pos:], labels[pos:], title="patterns",
handletextpad=0, columnspacing=1,
bbox_to_anchor=(1.05, 0.5),
loc="center left", ncol=1, frameon=True)
# y label
ax.set_yticklabels(ax.get_yticklabels(), fontdict={'fontsize' : 8})
f.tight_layout()
plt.savefig(f"20210501-python-columns/{filename}")
if show:
f.show()
draw(results_df.loc[lambda df_: df_['row'] * df_['col'] <= 1e5], "shape_<=1e5.png")
draw(results_df.loc[lambda df_: df_['row'] * df_['col'] == 1e6], "shape_1e6.png")
draw(results_df.loc[lambda df_: df_['row'] * df_['col'] == 1e7], "shape_1e7.png")
draw(results_df.loc[lambda df_: df_['row'] * df_['col'] == 1e8], "shape_1e8.png")
draw(results_df.loc[lambda df_: df_['shape'] == '(1000000, 10)'], "shape_1e6x1e1.png")
draw(results_df.loc[lambda df_: df_['shape'] == '(100000, 100)'], "shape_1e5x1e2.png")
draw(results_df.loc[lambda df_: df_['shape'] == '(10000000, 10)'], "shape_1e7x1e1.png")
draw(results_df.loc[lambda df_: df_['shape'] == '(1000000, 100)'], "shape_1e6x1e2.png")





列名エラーの観点
既存の列名に含まれない列名を指定した時の挙動
-
[(__getitem__) はエラー -
filterは存在する列のみ抽出 -
reindexは存在する列のみならず、存在しない列は値をNaNで作成 -
.locはエラー
df = pd.DataFrame({'x': [0, 2, 3], 'y': list('abc')})
cols_new = ['x', 'z'] # z is not included in df.columns
df[cols_new]
# KeyError: "['z'] not in index"
df.filter(cols_new)
# x
# 0 0
# 1 2
# 2 3
df.reindex(columns=cols_new)
# x z
# 0 0 NaN
# 1 2 NaN
# 2 3 NaN
df.reindex(cols_new, axis=1)
# x z
# 0 0 NaN
# 1 2 NaN
# 2 3 NaN
df.loc[:, cols_new]
# KeyError: "Passing list-likes to .loc or [] with any missing labels is no longer supported. The following labels were missing: Index(['z'], dtype='object'). See https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#deprecate-loc-reindex-listlike"
動作環境
$ python -V
Python 3.9.4
$ python -c 'import pandas as pd; print(pd.__version__)'
1.2.4
以上。
こういう深掘りが好きな方、ぜひ justInCase へ遊びに来てみてください。