はじめに
Dataiku DSSをインストールし, いざ使おうと思ったときに一番最初に躓いたのはDataikuの説明がすべて英語であること. 頑張って英語を読んでチュートリアルを実施したので, その手順をまとめることにする.
実行環境はDataiku DSS 6.0.2
Dataiku Academy
Dataikuの説明書のようなものであるDataiku Academy. これを読めばDataiku DSSの使い方をほぼマスターできる(ただし英語).
Dataiku Academyでは実際に動かしながら使い方を学べるチュートリアルが用意されている. 今回はチュートリアルの基礎の基礎, Tutorial: Basicsのやり方をまとめる.
Tutorial: Basics
このチュートリアルでは, Haiku T-Shirtという架空のオンラインのTシャツショップのデータを使ってDataiku DSSの使い方を学んでいく.
今回はHaiku T-Shirtの注文履歴をDataiku DSSに読み込み, データを大まかに見てそこから発見したルールを適用して新しいデータセットを作成するという手順を学ぶ.
ちなみに上のURLにアクセスすればDataiku DSSの使い方を動画で見ることもできる.
以下のURLから今回使うデータ(orders.csv)をダウンロードしたらチュートリアルスタート.
https://downloads.dataiku.com/public/website-additional-assets/data/orders.csv
プロジェクトを作る
まず最初にDataiku DSSのプロジェクトを作成する. このプロジェクトの中でデータの加工や分析を行っていく. 今回はチュートリアル用のプロジェクトが用意されているのでそれを使って進めていく.
まずDataiku DSSにアクセスすると以下の画面になるはず.
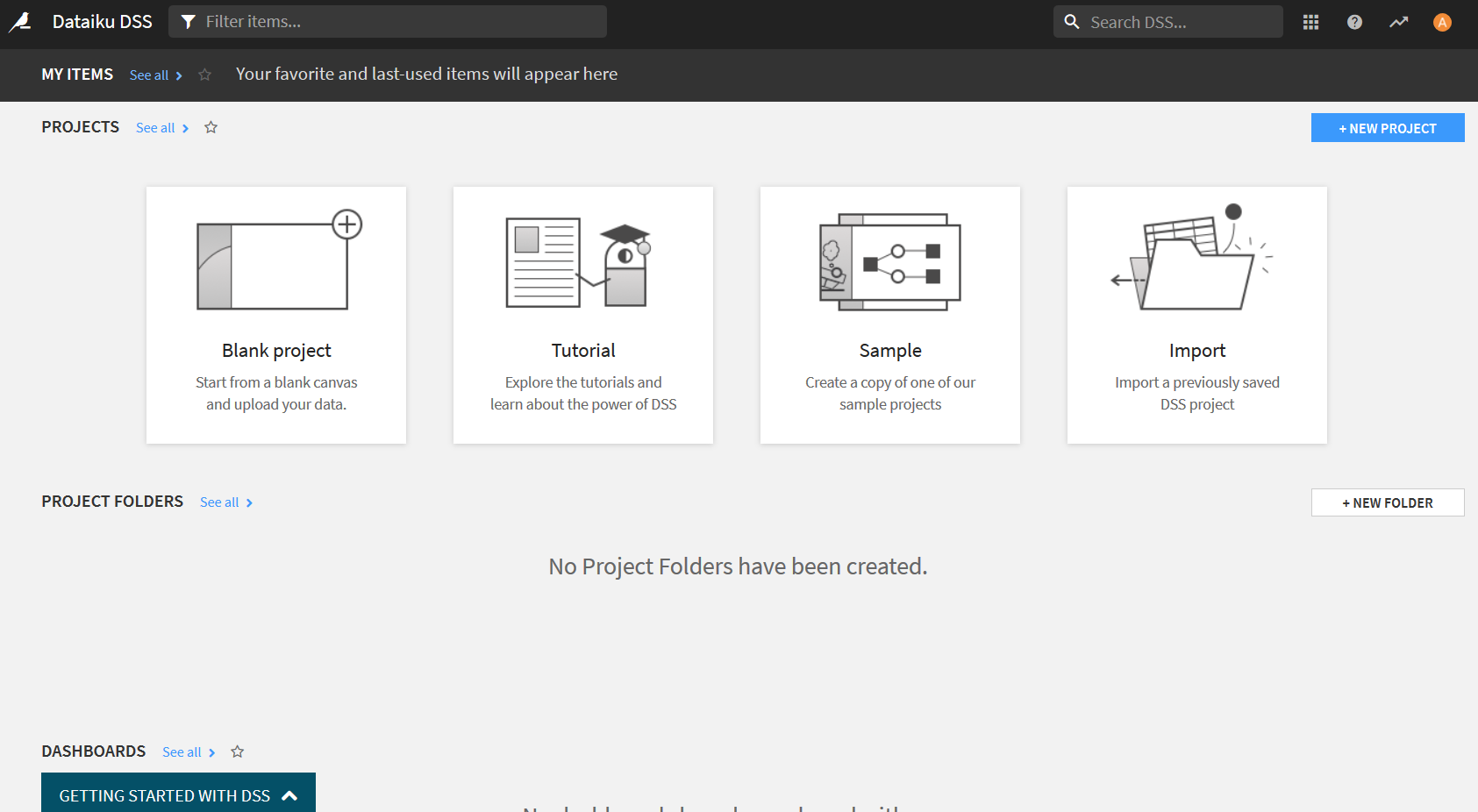
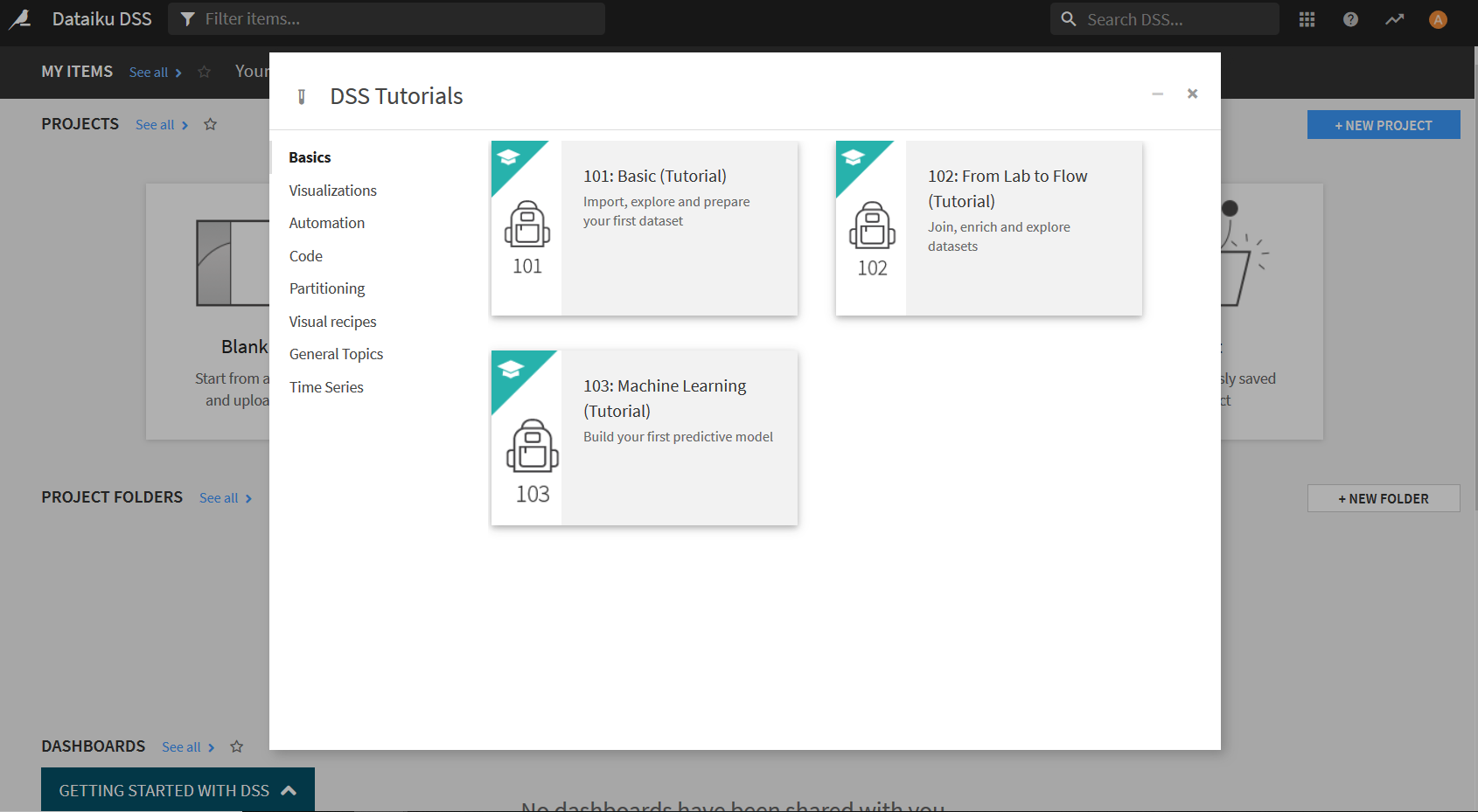
この"Tutorial"というのをクリックすると以下のような画面が表示されるので"101: Basic(Tutorial)"をクリック. 「Create "DKU_TUTORIAL_BASICS"」という画面が出てきたらOKを押す.
プロジェクトを作るとよく以下のような画面が出てくるが, 画面の説明をしてくれているだけなので閉じるか"GOT IT"をクリックすればよい.
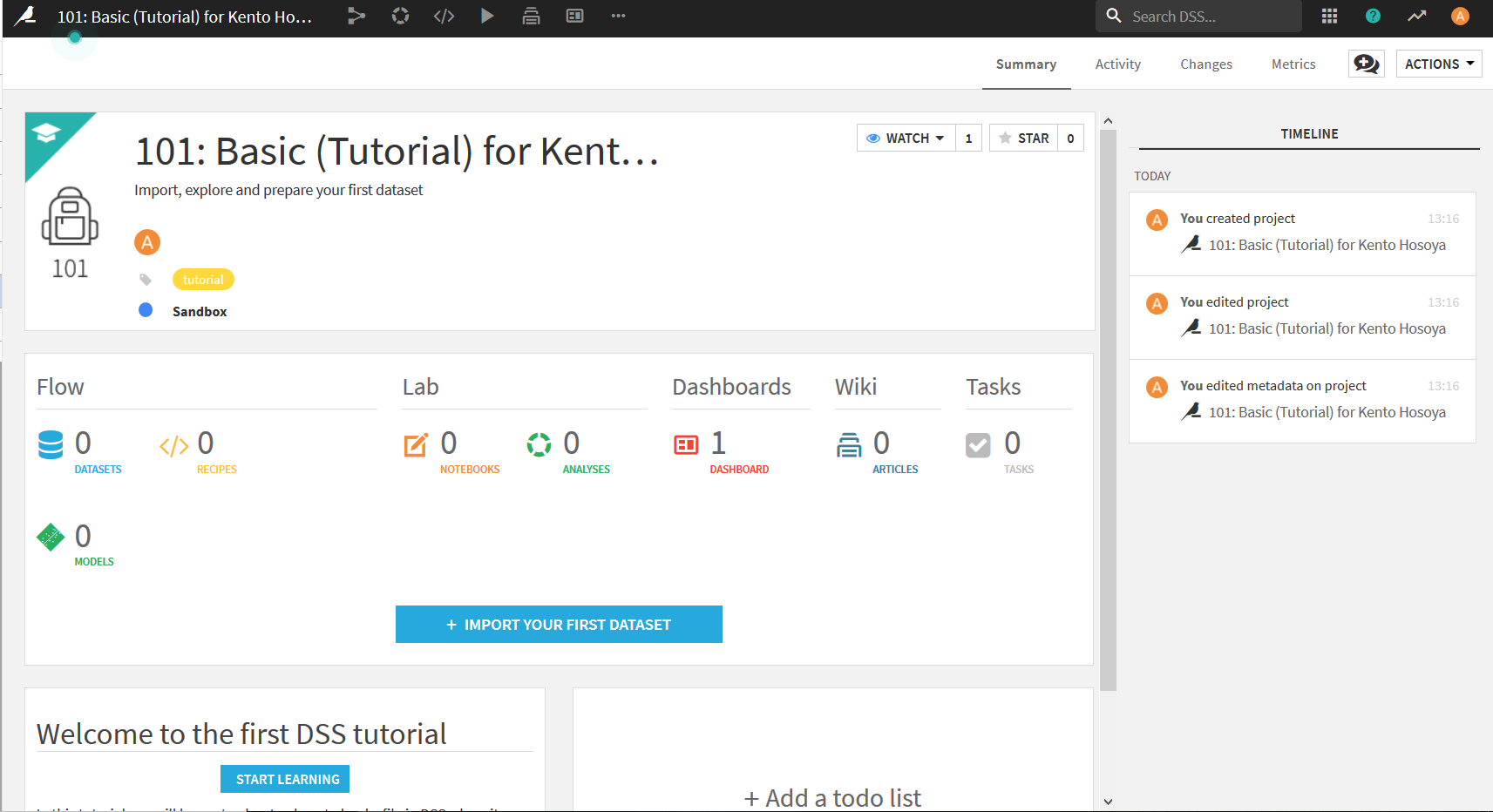
これでプロジェクトを作る工程は終了. 今回はTutorialのプロジェクトを使って進めるが, 自分のデータを読み込んで使いたいときは初めのページで"Blank project"を選べば良い.
データセットを作る(データの読み込み)
次に先ほどダウンロードしたデータセットをDataiku DSSにインポートする. 画面の中央くらいにある, "+ IMPORT YOUR FIRST DATASET"をクリック.
以下の画面になったら一番左上の"Upload your files"を選択.
"ADD A FILE"をクリックし, 先ほどダウンロードしたorders.csvを選択するか, orders.csvを真ん中のエリアにドラッグ&ドロップすることでファイルをDataiku DSS上にアップロードすることができる.
アップロードに成功すると以下のように画面の下部に"PREVIEW"というボタンが表示されるのでそれをクリック.
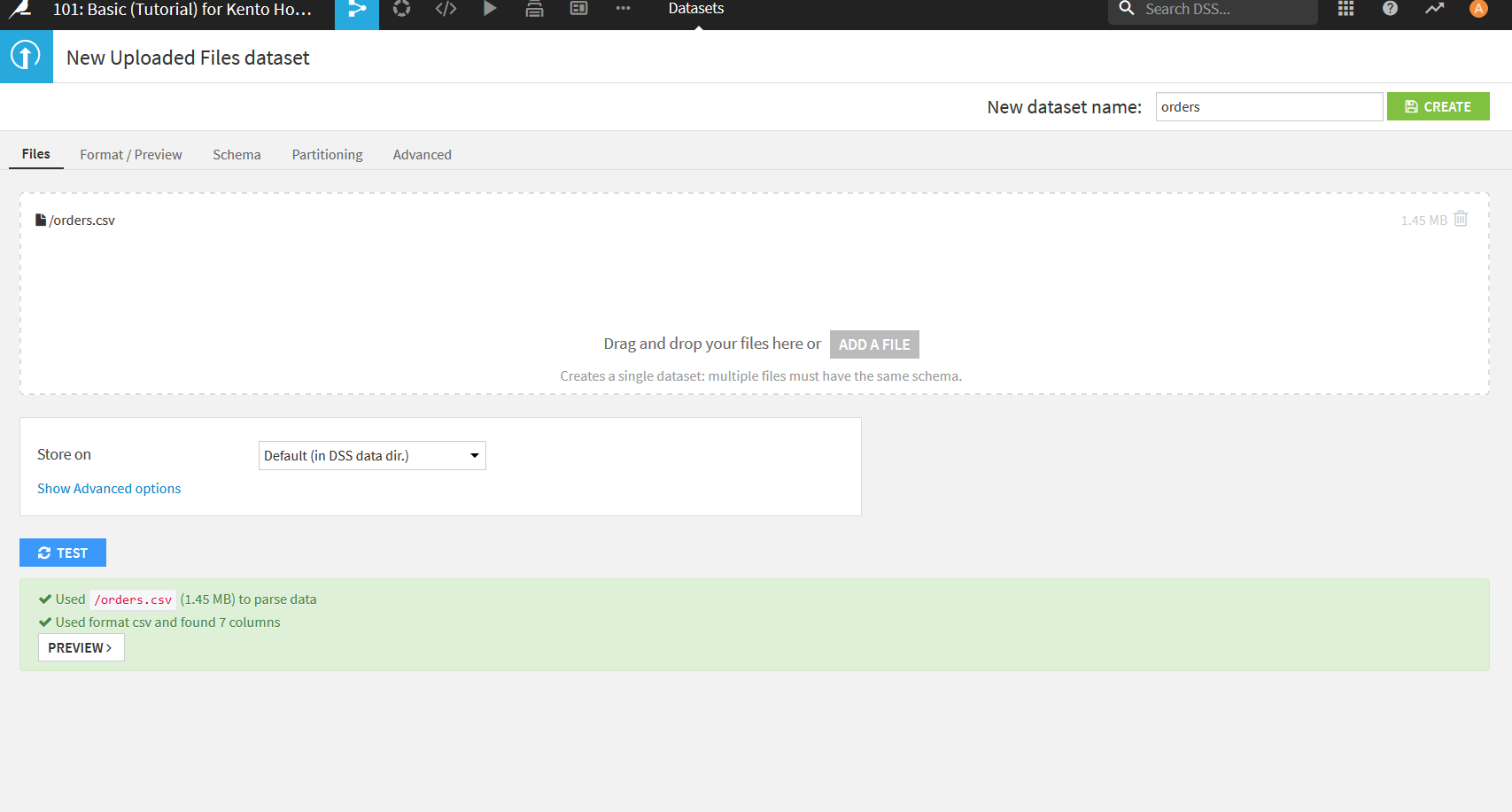
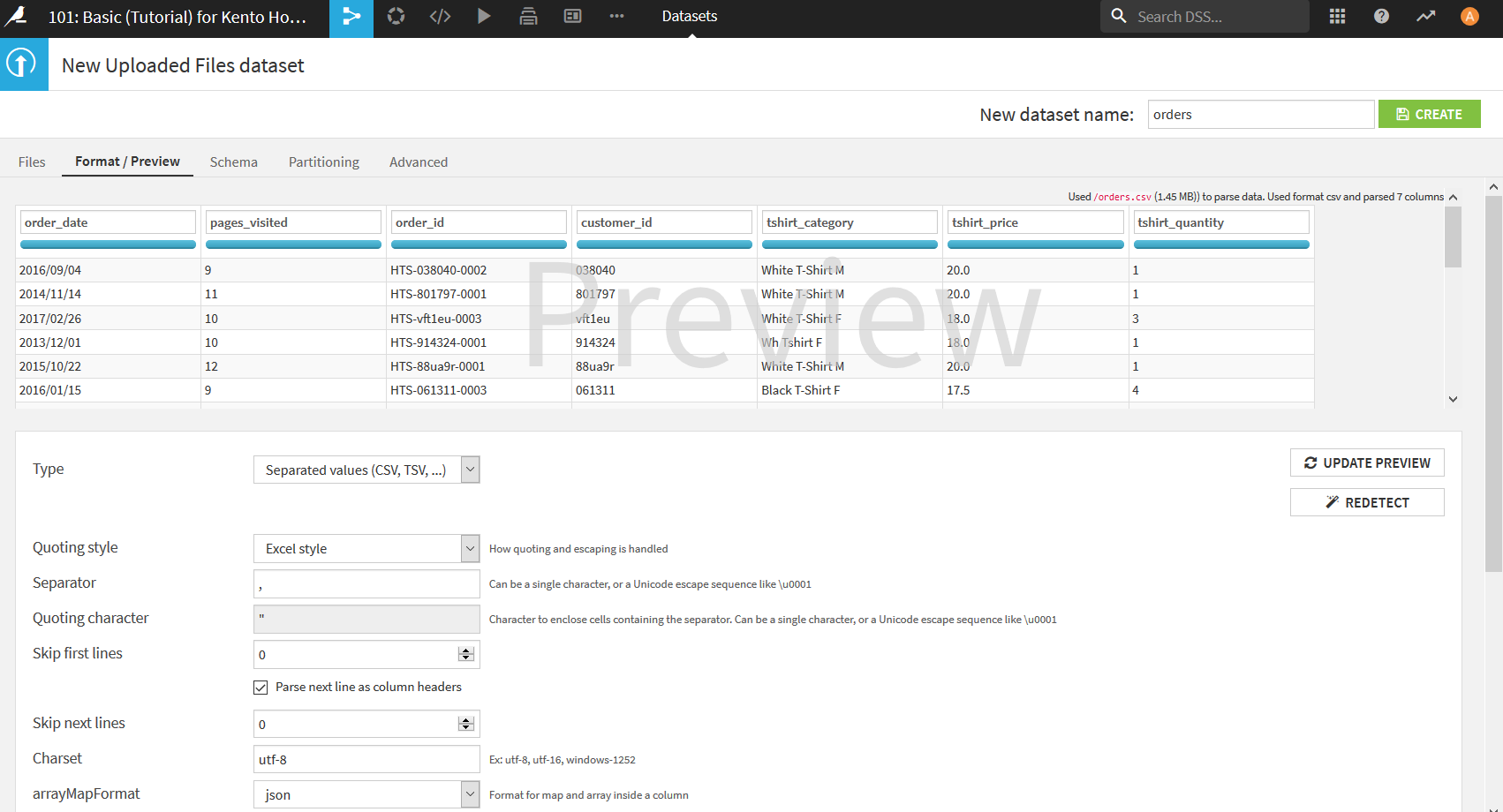
Dataiku DSSは自動でCSVファイルを認識して表形式のデータにしてくれる. その際どのような表になるかをこの画面で確認する. 万が一自動で識別された結果が想定と違った場合には, ここで設定を変更し直すことができる. 特に日本語のデータを扱う場合は文字コードの設定などを行うことが多い. 今回は特に直すことはないのでデフォルトの状態でよい.
データの確認が終わったら, 右上の「New dataset name: 」というところでDataiku DSS上で扱う際のデータセットの名前を付ける. 今回はファイル名でもある「orders」で問題ないのでここもデフォルトのまま右上の"CREATE"をクリック, あるいは__Ctrl+S__を押す. これでデータセットの作成は完了.
データの調査(Exploreページの説明)
データセットの作成が完了すると以下の画面になる. このページはExploreページといい, 作成したデータセットを確認することができる. この画面からデータの調査を行っていく.
サンプリング
ここはチュートリアルではあまり関係ないので読み飛ばしてもOK.
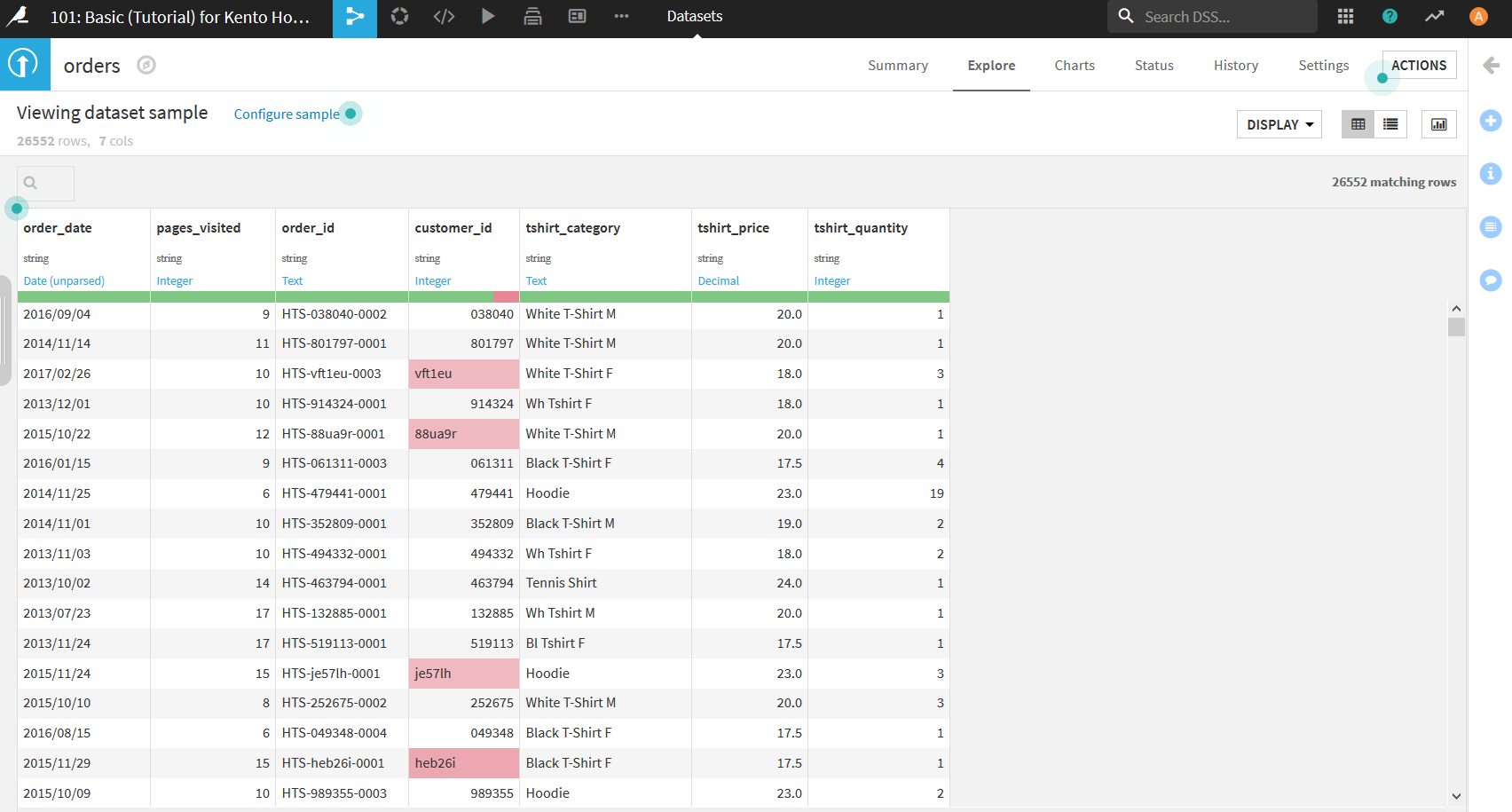
現在表示されているデータは実は読み込んだデータをすべて表示しているのではなく, データをサンプリング(一部を抽出)した状態で表示されている. これは, データが巨大であった場合にすべてを表示しているとPCのメモリを圧迫してしまうという問題に対応するための機能である.
デフォルトでは単純にデータの上から10000件を表示している. これだと表示は早いがデータが偏ってしまっている可能性もあるため, それが嫌な場合は設定を変更する必要がある.
まず, 少しわかりにくいが画面左側にパネルを開くためのボタンが存在する(以下の画像参照).
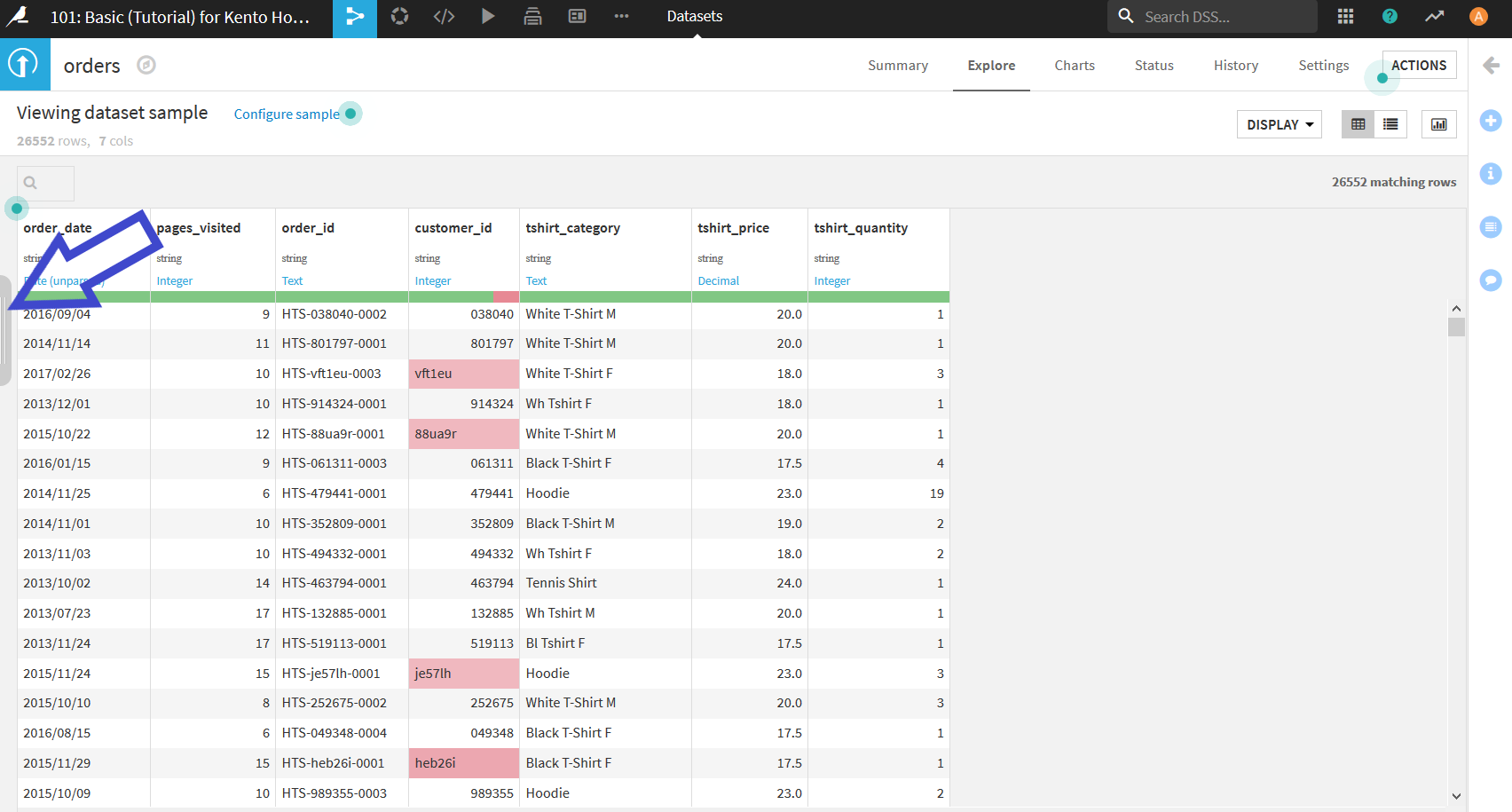
すると以下のようにデータセットのサンプリング方法を設定する画面が表示される. 設定項目は上から
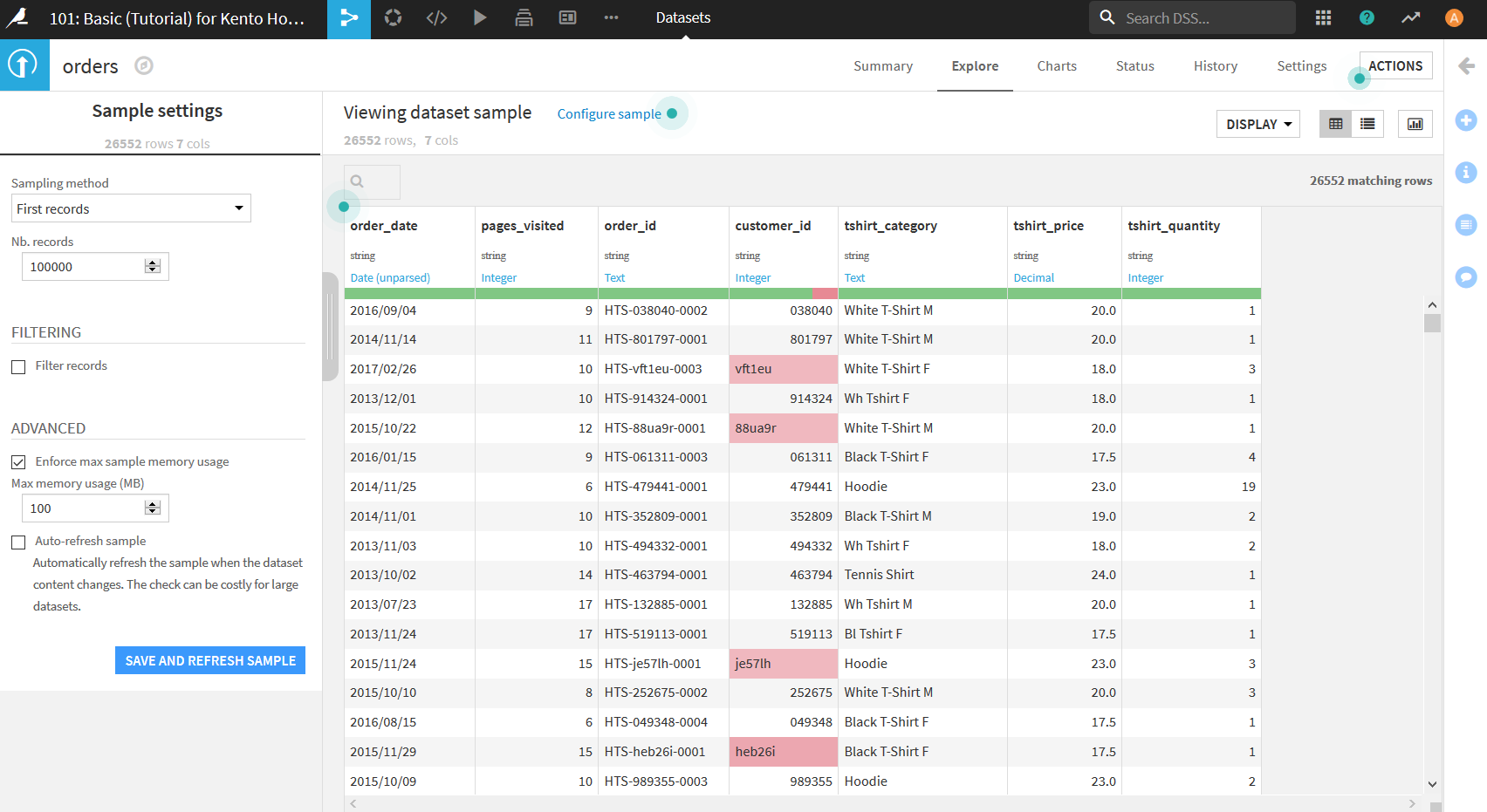
- Sampling method $\cdots$
サンプリングの方法を設定. 上から順に, 下から順に,ランダムになど. ランダムの場合にはその方法も指定できる. - Nb. records $\cdots$
データを何件表示させるかを設定. - Filter records $\cdots$
チェックをつけると, 表示させるデータのルールを自分で設定できる. - Enforce max sample memory usage $\cdots$
チェックをつけると, データセットを表示させる際に使う最大メモリを設定できる. 設定したメモリを上回るデータセットは表示できなくなる. - Auto-refresh sample $\cdots$
チェックをつけると, データセットを変更するたびに自動で変更を適用してくれる. データセットが大きいと毎回処理が行われてしまい, 動作が重くなる.
データの型と意味
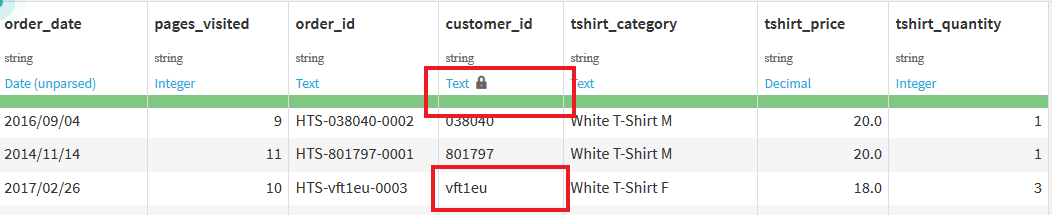
表のそれぞれの列には, その列の名前とデータの型が表示されている. 黒色の文字で表示されている型は, 読み込んだ元データの型を示している. 今回はCSVファイルであるためすべてstring型になっている. 青色の文字で表示されているのは, Dataiku DSSが自動で認識した意味である. IntegerやText, Decimalの他にも, DateやIP addresses, email, US statesというのも存在している. 残念ながら日本の地名は認識してもらえない.
ところで, 現在データの中に背景が赤くなっているセルがいくつかあるだろう. これは, Dataiku DSSが認識したデータの意味と異なるデータが入っている場合にこのような表示になる. また, データの意味(青文字)のすぐ下にある緑や赤のバーは, その列のデータにどれだけ認識と違うデータが含まれているかを表している. 今回のデータには存在しないが, もしデータが入力されていないセルがあった場合は灰色で表現される.

このデータでは, _customer_id_列をIntegerと認識したのに, 「vft1eu」のようにテキストのデータが入っているので, そのようなセルが赤く表示されている. しかし, 今回においては_customer_id_にテキストが入っているのも間違いではないため, 自分でデータの意味を選択する必要がある. 青文字の部分をクリックすると以下のようにデータの意味を選択できる画面が表示されるので, この中から"Text"を選択する.
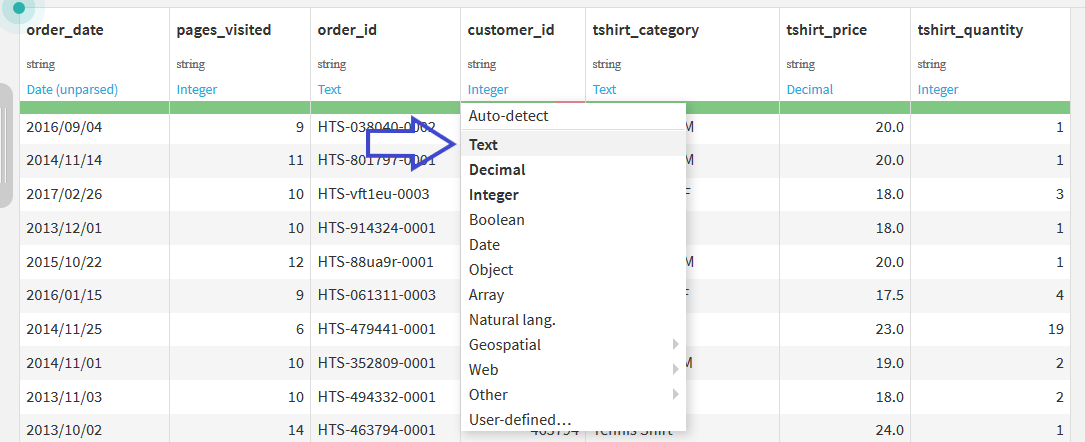
すると, 以下のように意味がTextで固定され, セルは通常の色に, バーはすべて緑になる.
可視化(Charts)
Dataiku DSSではデータの可視化機能(Charts)も備わっている. 画面右上辺り(青矢印)の"Charts"をクリックすることで, 以下のような画面になる. 画面左側に表示されている各データ項目をドラッグ&ドロップするだけでデータの可視化が可能.
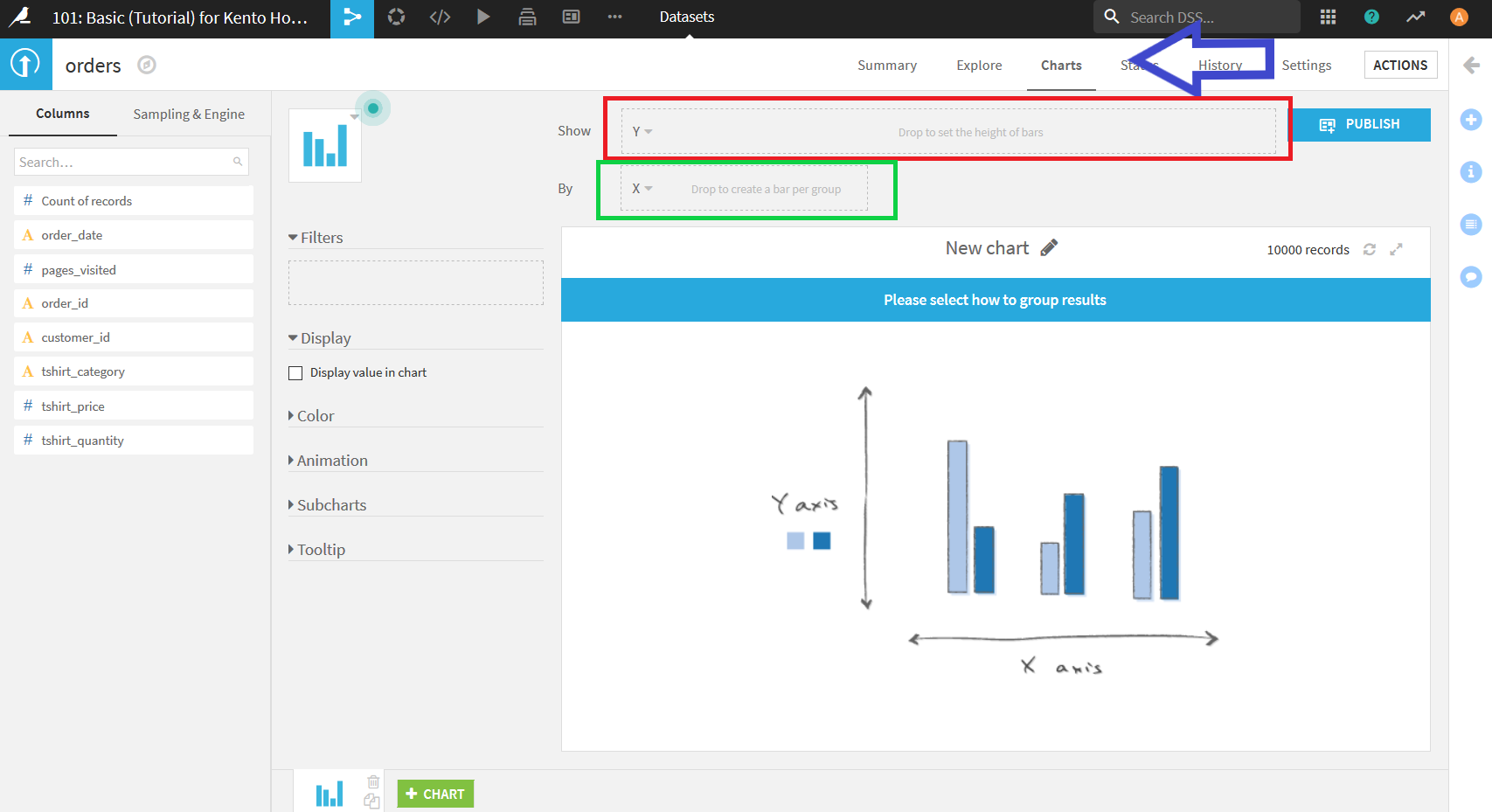
今回は, Tシャツのタイプごとに注文されている数について可視化を行う.
画面左側のデータの列名リストの中から"tshirt_category"をXエリア(上画像緑枠)にドラッグ&ドロップ. 次に, リストから"Count of record"をYエリア(上画像赤枠)にドラッグ&ドロップ. すると以下の画像のようになる. ここでCount of recordという項目はデータに存在する列名ではなく, X軸に選択したデータの数を数える際に用いるCharts用の項目である.
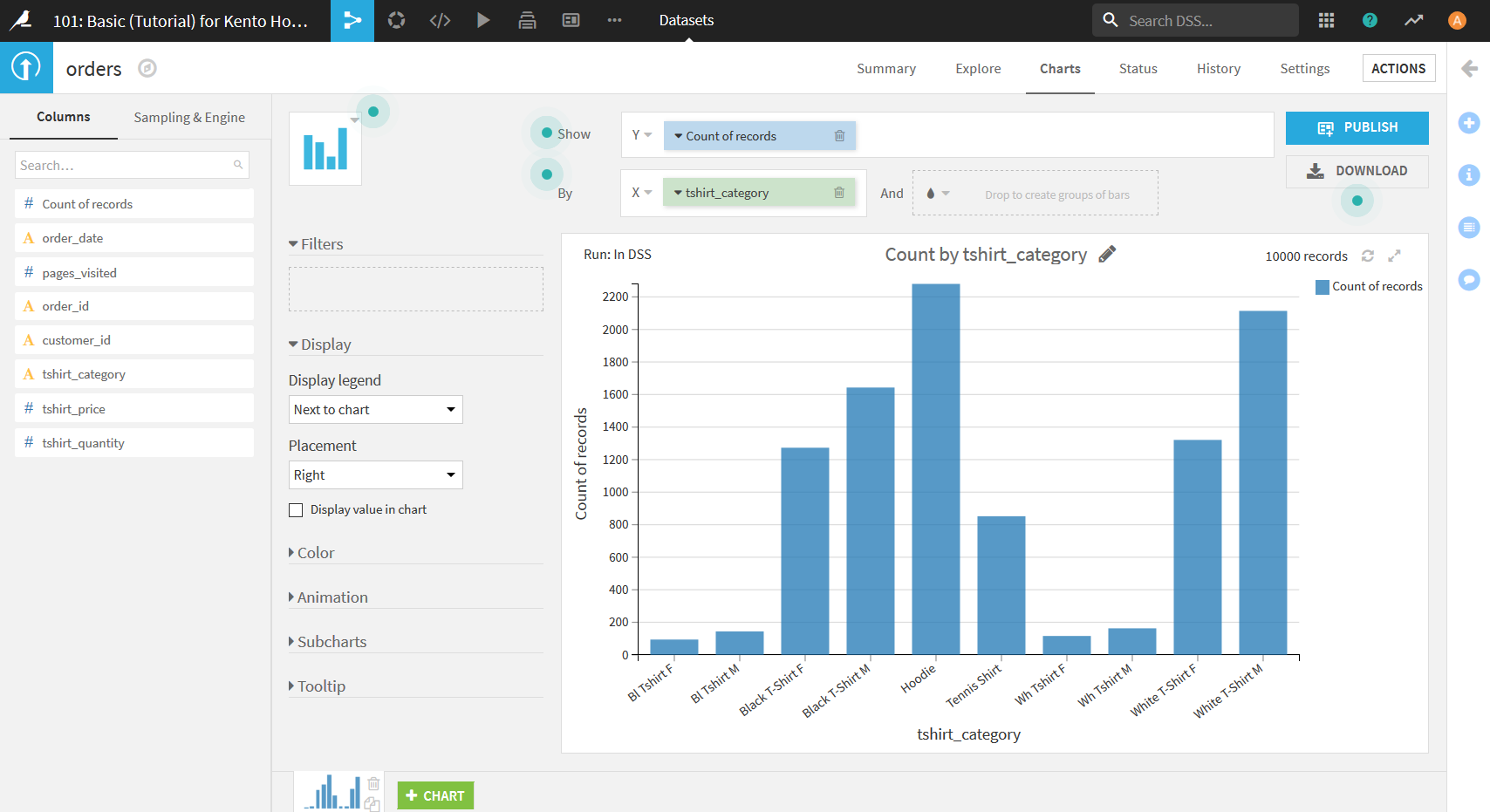
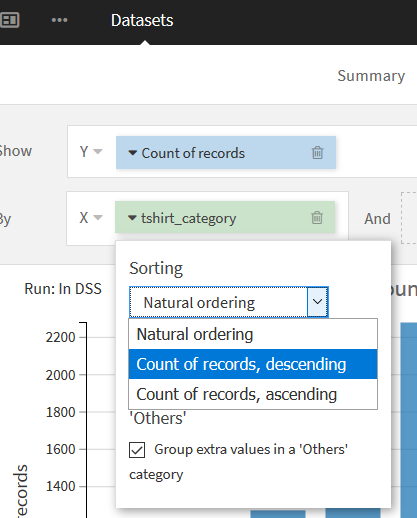
このままだとX軸の順番がアルファベット順になっているので, もし降順(昇順)に変更したい場合はXエリアの"tshirt_category"横の▼を押し, 「Sorting」の"Count of records, descending"("Count of records, ascending")を選択することで変更可能.
可視化した結果を見てみると, tshirt_categoryの値が統一されていないということがわかる. 例えば, 「Black」が「Bl」となっていたり, 「White」が「Wh」となっていたりなど. 次からはこれらの統一がされていない値についての対応を行っていく.
Visual Recipeを用いたデータの整形
ここでは, Dataiku DSSの重要な機能である, Visual Recipeを使用する.
Visual Recipeはデータの整形や加工を行うための機能で, 様々なことを行うことができる. Excelでいうと関数のようなものである. Dataiku DSSのVisual Recipeでは, データの整形の過程を記録することができるため, 後にデータを確認した際どのようなことを行ったかの確認をすることができる.
表記の統一
右上の"ACTIONS"ボタンをクリックし, 表示された項目の中から"Prepare"を選択する.
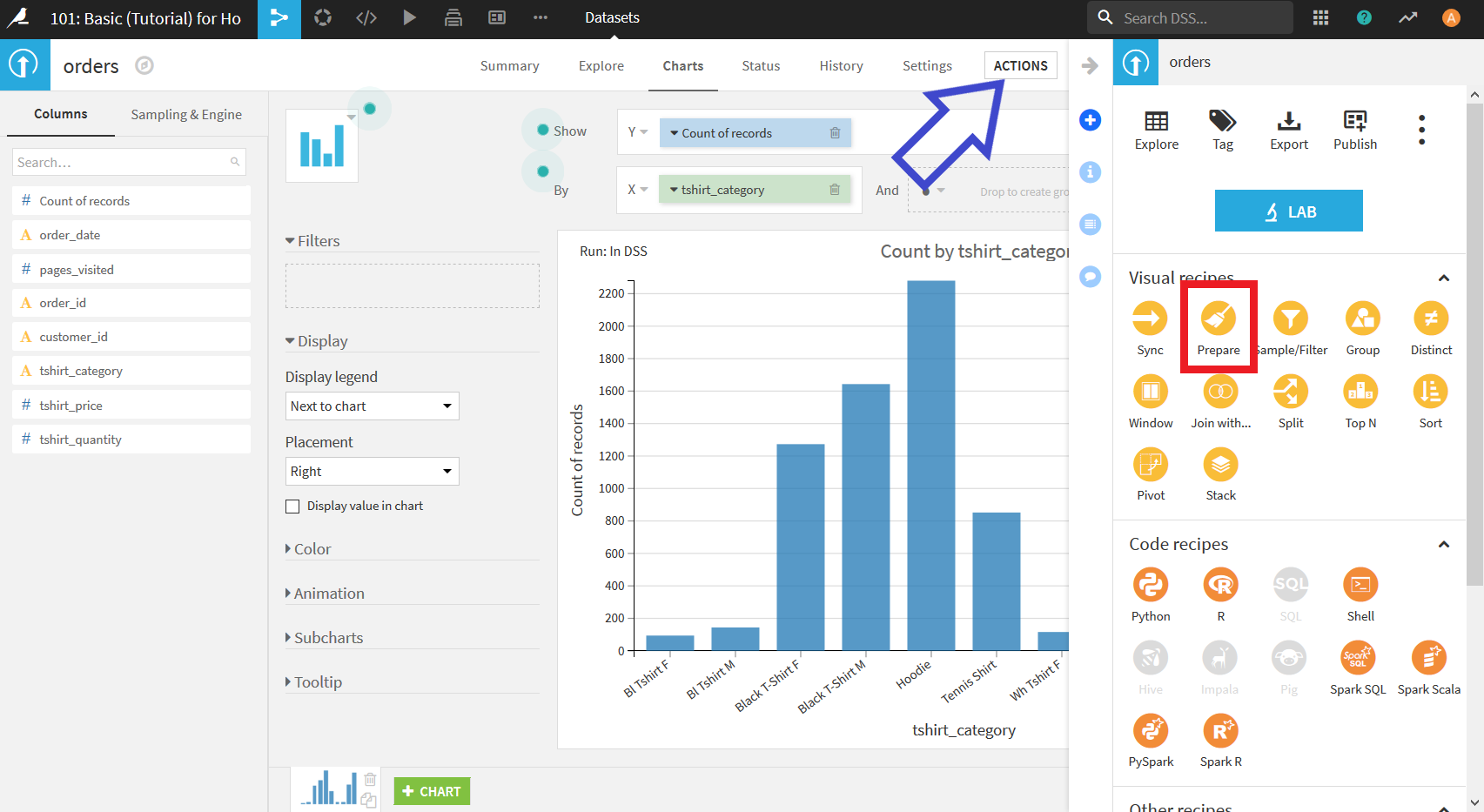
すると以下のような画面が表示される. この画面では整形を行いたいデータセットの選択(Input dataset)と整形後出力するデータセット(Output dataset)の名前の入力を行う.
今回はデフォルトで入力されている状態のままでよいので, このまま右下の"CREATE RECIPE"をクリックする.
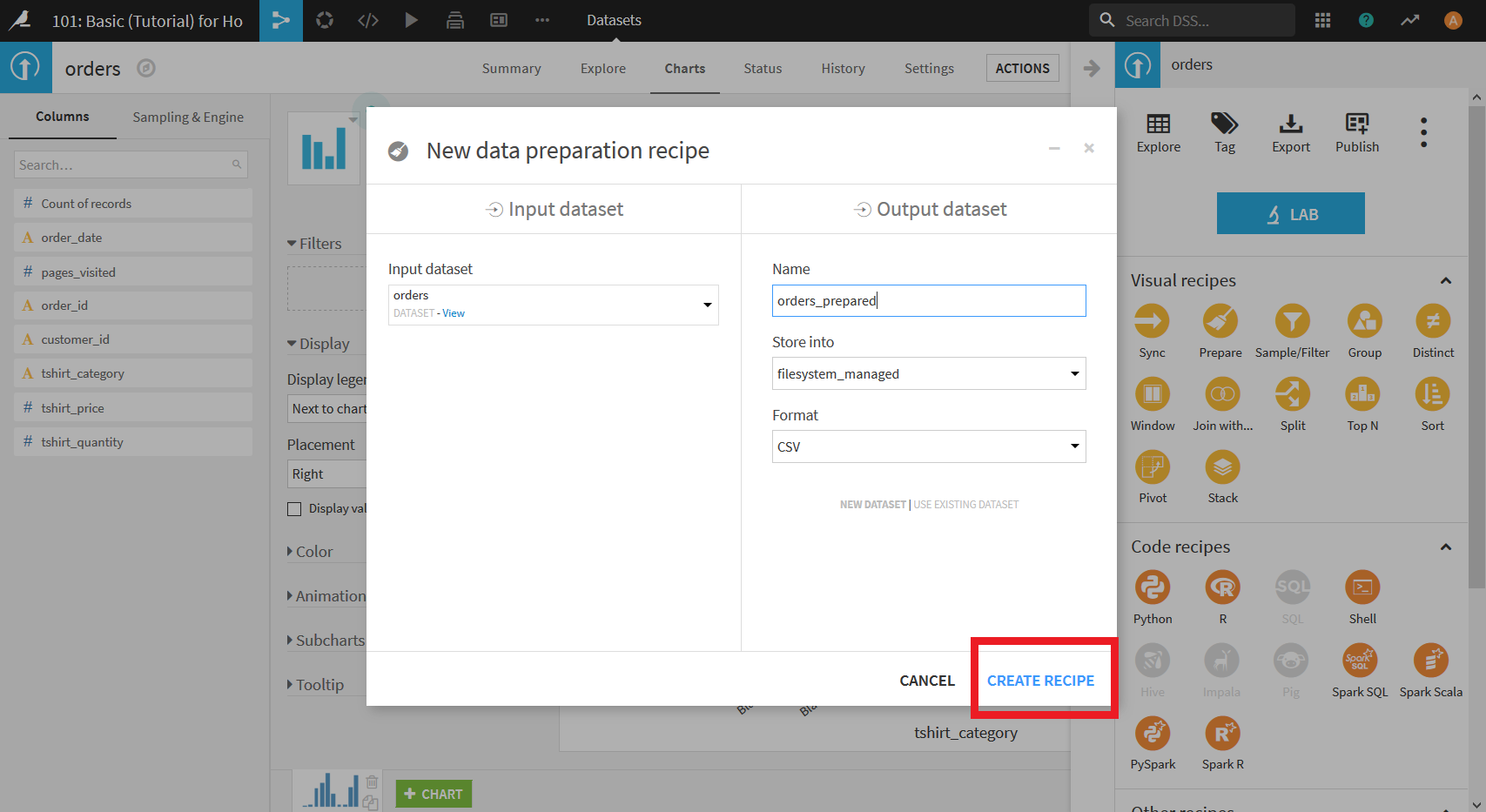
すると, 以下のような画面になる. これがデータ整形を行うための画面である.
まず行いたいのは, _tshirt_category_のデータの表記の統一である. そのために, 列名"tshirt_category"をクリックする.
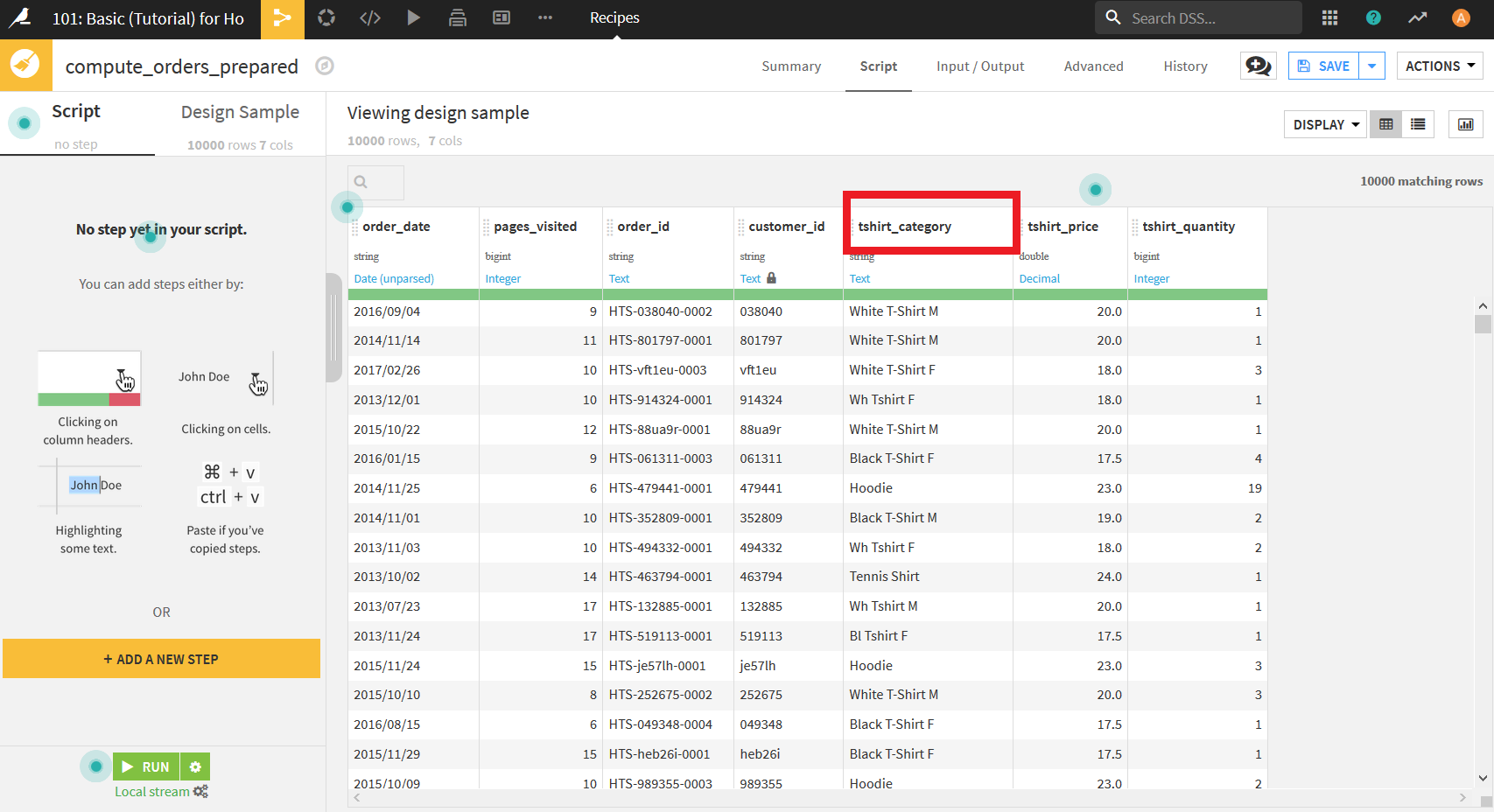
そして表示されたメニューから"Analyze..."を選択する.
すると以下の画面が表示される. この画面では選択した列に関する情報が表示されている.
まず, 「White T-shirt M」と「Wh Tshirt M」に関する表記のというつを行う. 表示されているデータの中から, 「White T-shirt M」と「Wh Tshirt M」にチェックを入れる.
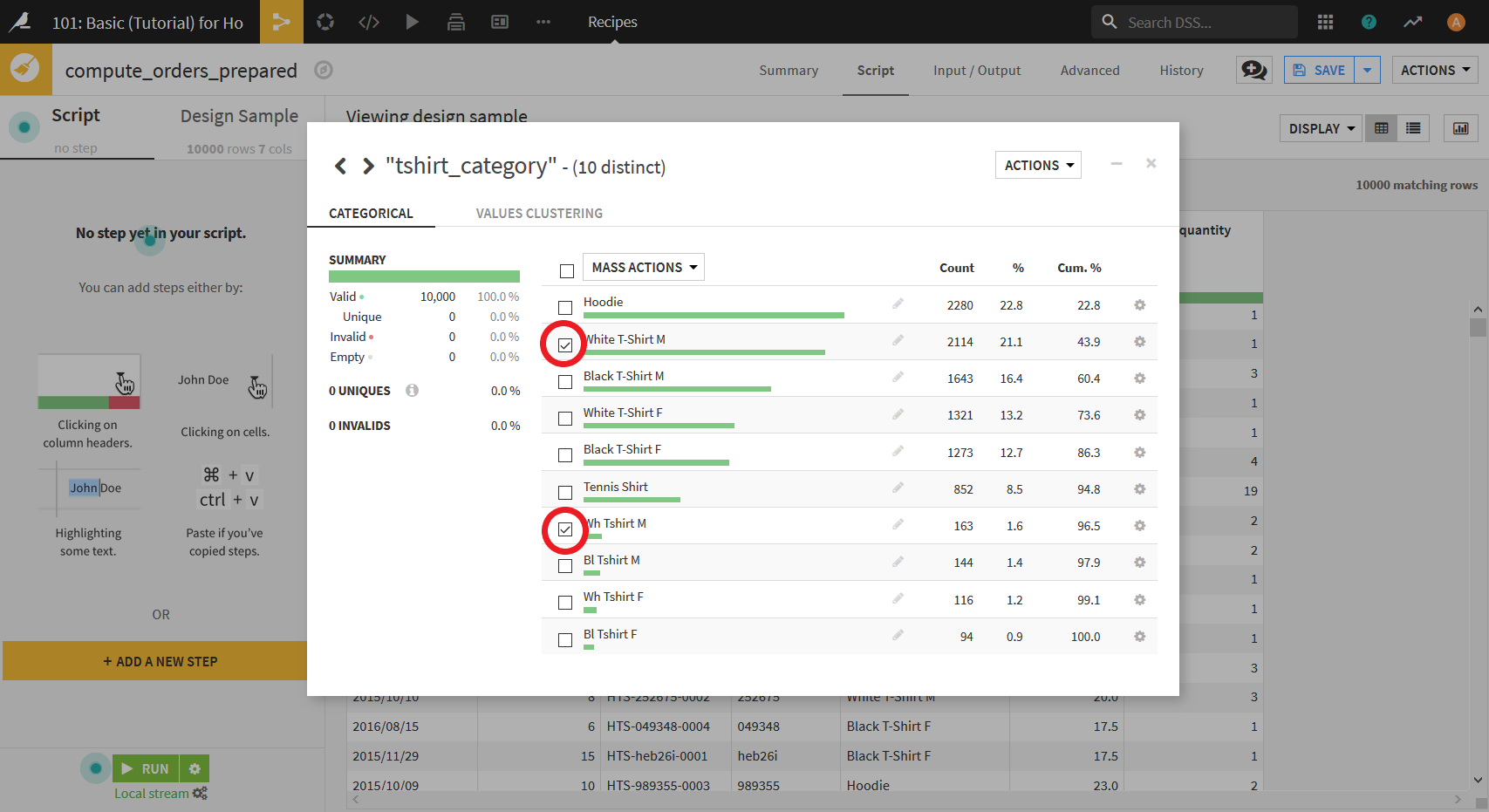
その後, "MASS ACTIONS"ボタンをクリックし, 表示されたメニューの中から"Merge selected"を選択する.
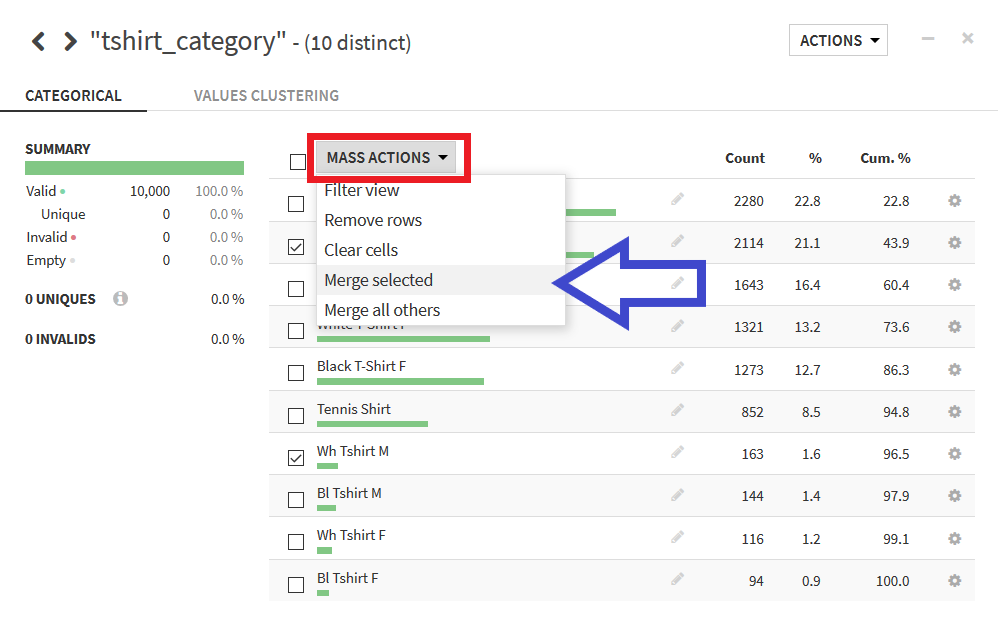
そして, 表示された"MERGE"ボタンをクリックすると, 表記の統一が完了する. この際, 左のテキストボックスで統一する際の値を指定できルが, 今回はデフォルトのままでよい.
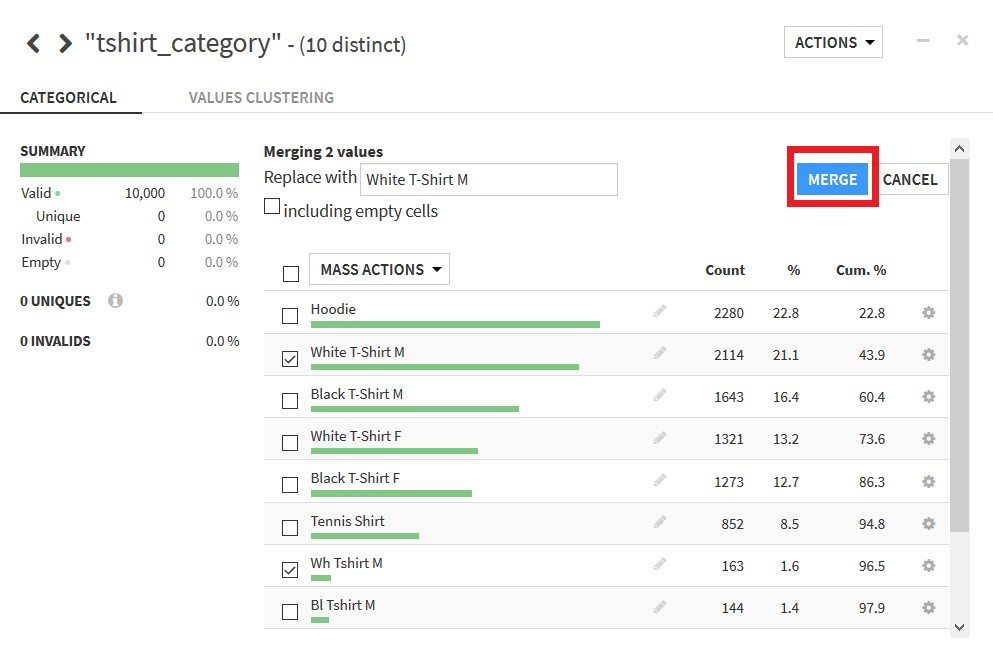
これと同様の操作を「Black T-Shirt M」と「Bl Tshirt M」, 「White T-Shirt F」と「Wh Tshirt F」, 「Black T-Shirt F」と「Bl Tshirt F」に行うと最終的に以下のようにデータの種類が5つに統一される.
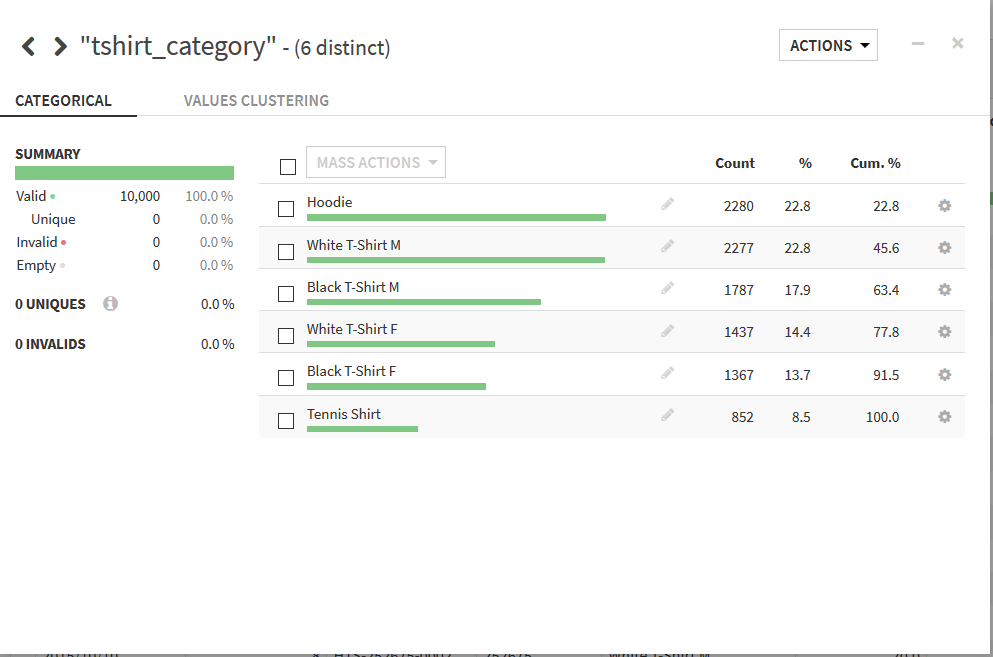
Analyze画面を閉じると, 画面が以下のように変化している.
今回行った処理がscriptとして画面左側に表示され, そのscriptによって変更が行われたセルの背景が青色になっている.
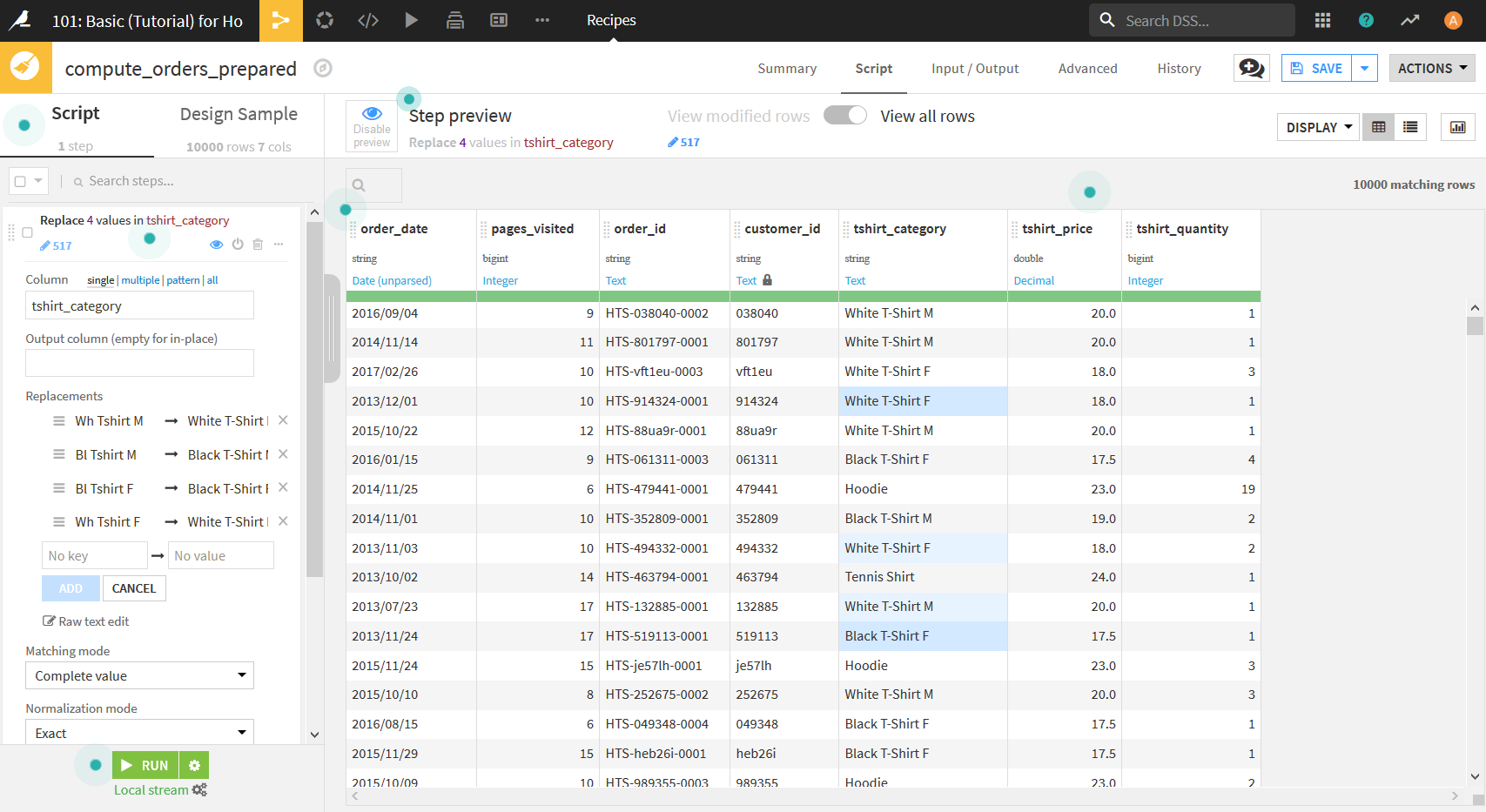
さらなるデータ加工
他のデータ加工についても, いくつか実行していく.
次に実行するのは日付の認識である. Dataiku DSSは日付のフォーマットを選択するとその通りの日付として認識し, 記述方法を変更することができる.
"order_date"をクリックし, 表示されたメニューから"Parse date..."を選択.
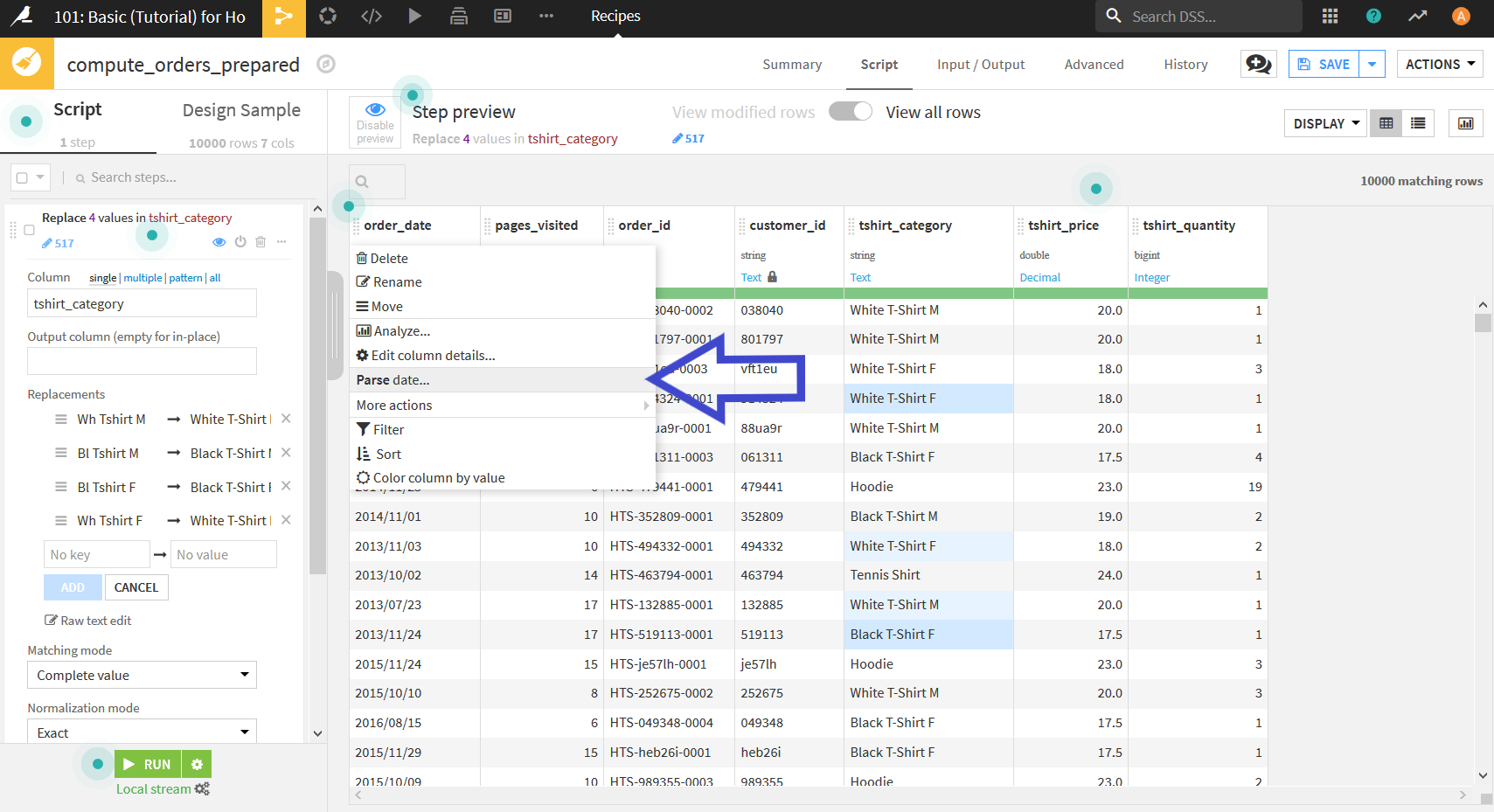
表示された以下のダイアログにおいて, データに適した日付のフォーマットを選択する.
今回は「年/月/日」となっているので"yyyy/MM/dd"を選択し, 右下のOKを押す.
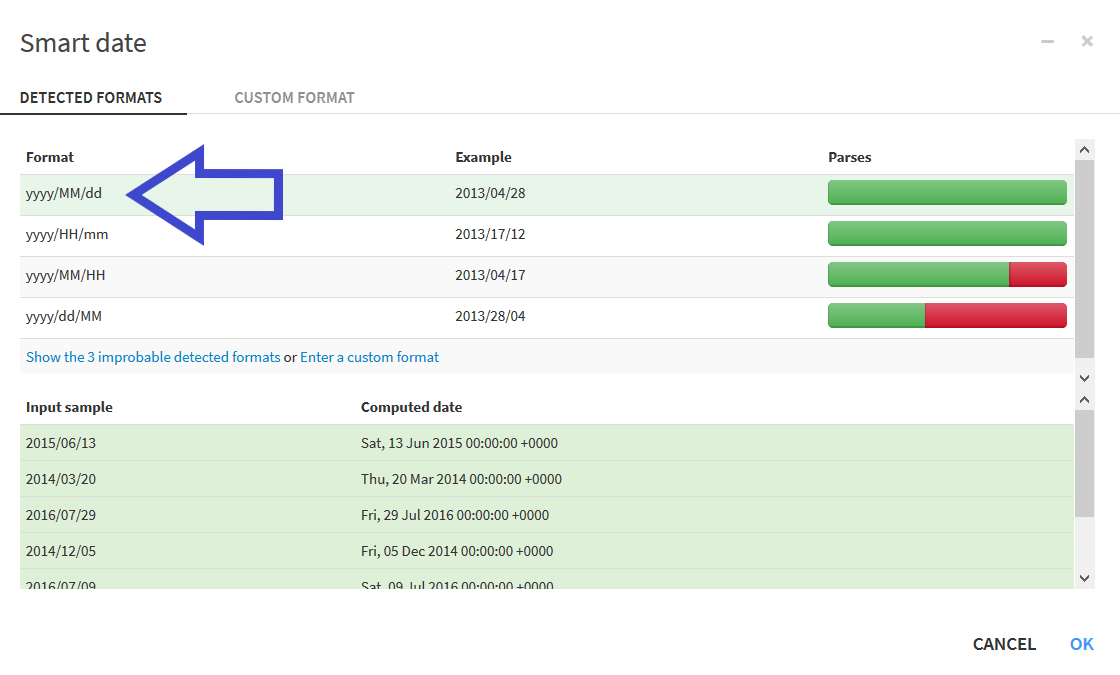
すると, _order_date_の隣に_order_date_parsed_という列が追加される. しかし, 今回は日付を表す列は一つでいいので, 日付の認識後の列を新しく追加するのではなく, もともとあった列に上書きするという出力にする. そのためには, 左側に表示されているscriptの「Output column」というテキストボックスに入力されているものを削除するだけでよい.
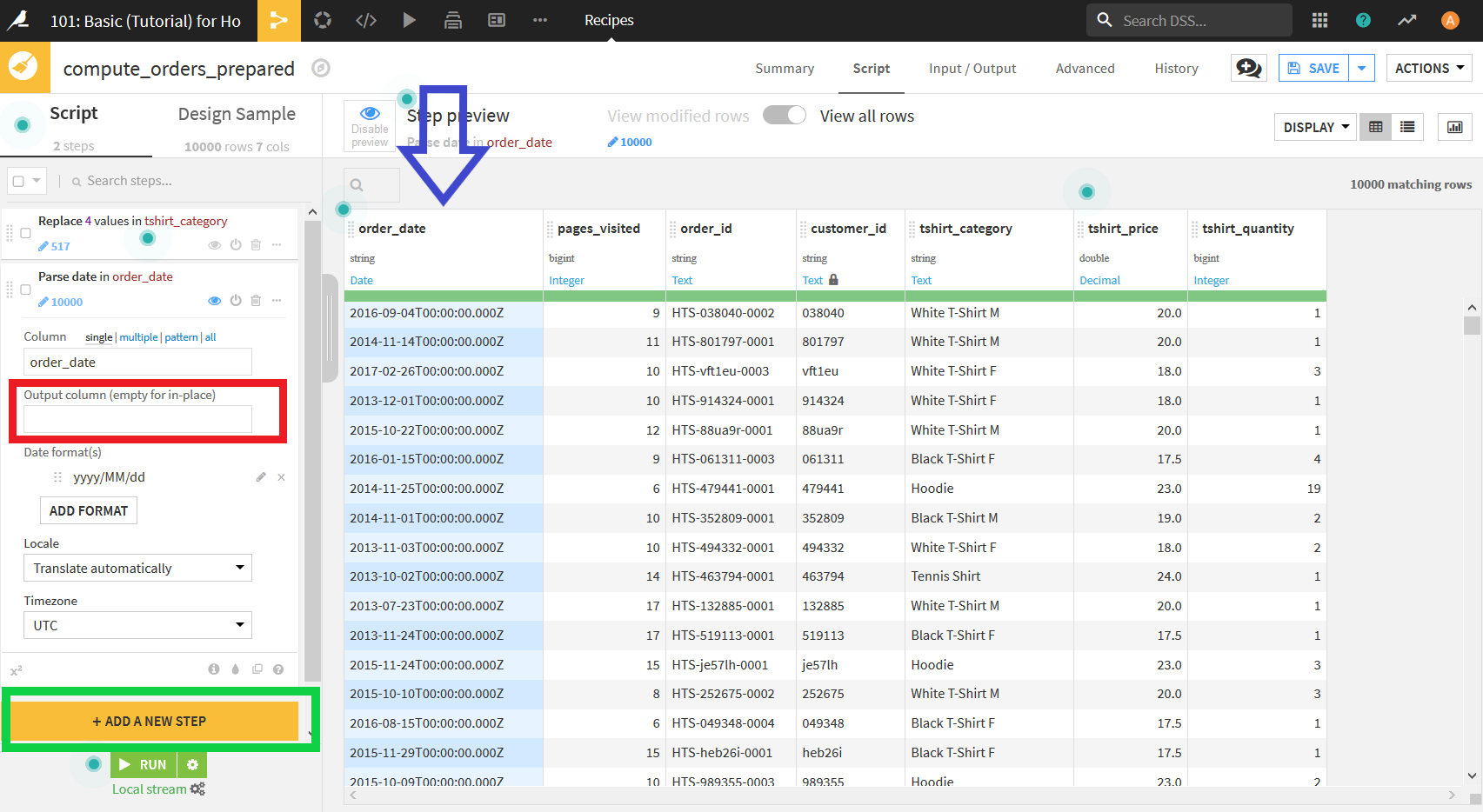
これで日付の認識は終了.
次に行うデータの加工は, 注文ごとの合計金額の計算である.
今回用いているデータセットには, 注文されたTシャツの値段と(tshirt_price)そのTシャツを注文された数(tshirt_quantity)を示す列がある. しかし, その注文の合計金額を示す列がないためその列を追加する処理を行う.
まず, 画面左下の"+ ADD A NEW STEP"(上画像緑枠)をクリックする. 以下のようにProcesser(データ加工のプロセス)のリストが表示されるので, その中から"Formula"を選択する.
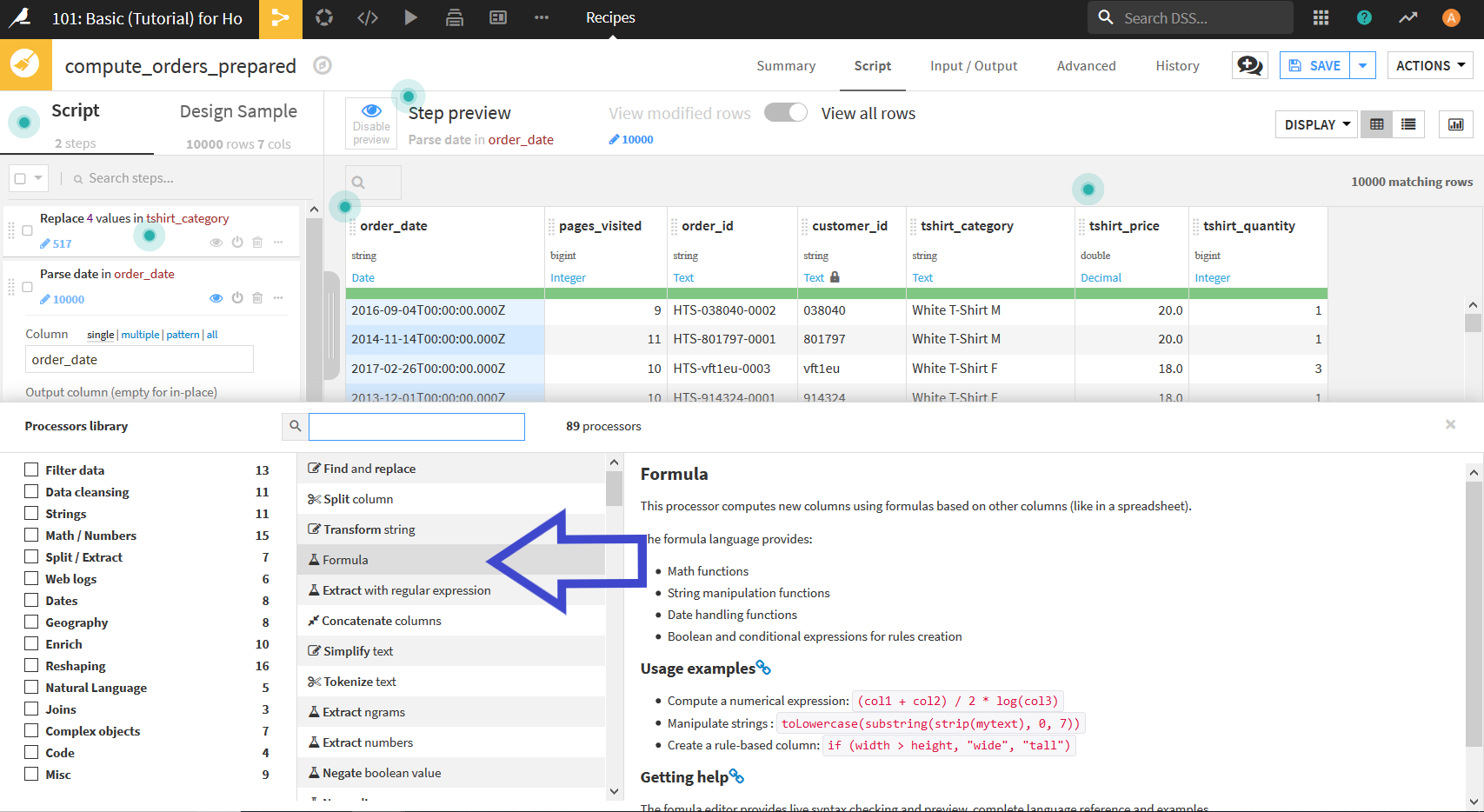
画面左側のscriptに新しくFormulaが追加されるので, そこを以下のように編集していく.
- 「Output column」に
totalと入力. - 「Expression」に
tshirt_price*tshirt_quantityと入力.
すると, 合計金額を示す列が追加される.

もうTシャツの値段と数の列は必要がないので_tshirt_price_と_tshirt_quantity_を削除する. それぞれ列名をクリックし, "Delete"を選択.
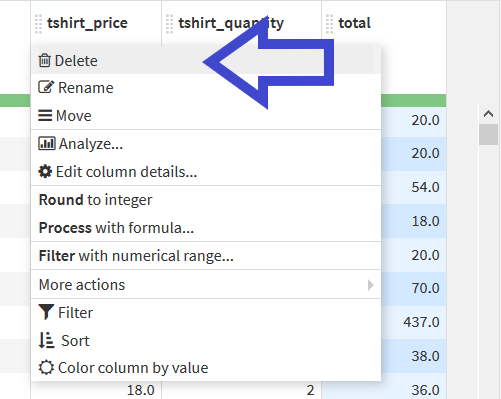
これでデータの整形は終了.
最後に行うのは, この整形した結果を実際にデータ全体に適用することである.
ここで, 現在データ整形を行っている際に表示されているデータが一部をサンプリングしたものであることを思い出してほしい. 今回行った変更を全体に適用させるために, もう1ステップ必要である.
まず, 左下にある"RUN"ボタンをクリックする.
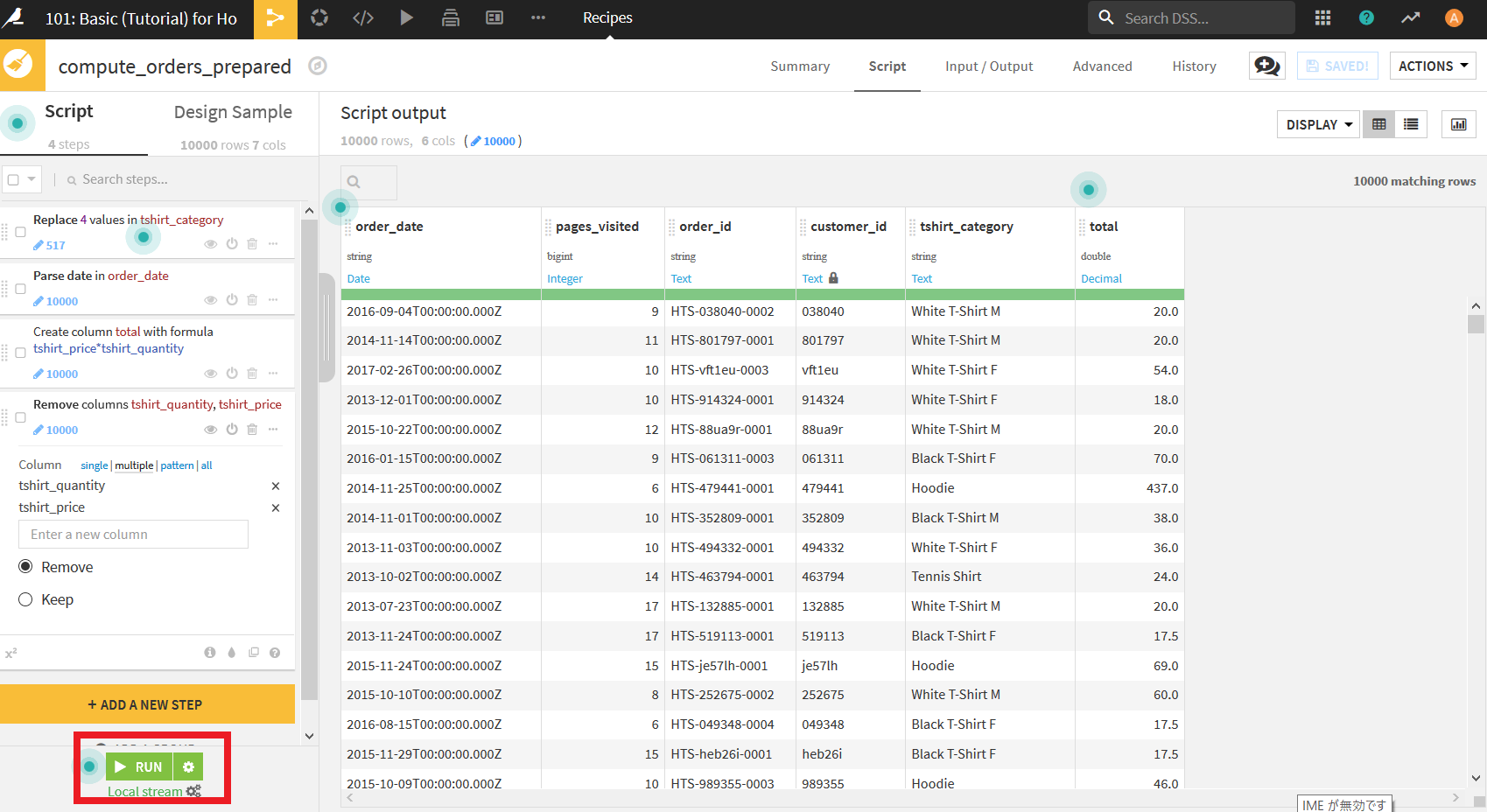
すると以下のようなダイアログが表示される. これは, 今回出力するデータセットが変更されていることが問題ないかを確認されている. 基本的にこのダイアログは無視してかまわないので, チェックもつけたまま"UPDATE SCHEMA"をクリックする.
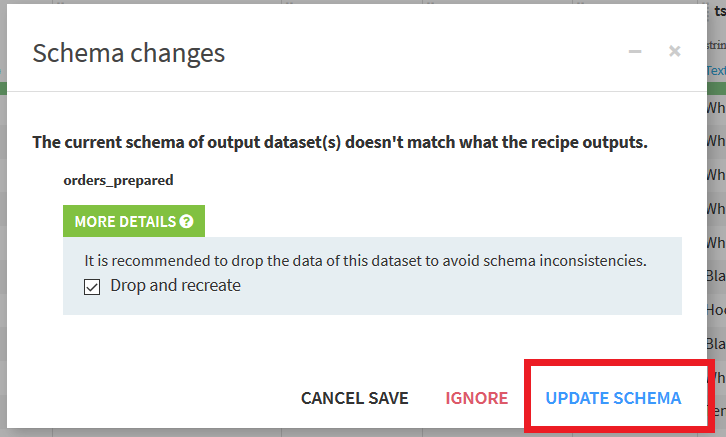
データセットに対して処理が実行され, それが成功すれば下に「Job suceeded」という画面が表示される. これで, 変更を適用した新たなデータセットの出力が完了である. "Explore dataset orders_prepared"をクリックすることで出力したデータセットを見ることができる.
出力したデータセットの確認
出力したデータセットでまず注目してほしいのは, データの型の部分である. 前に確認した時にはすべてstring型だったが, 出力されたデータセットではその列のデータを認識した通りの型に変換されている. 例えば_pages_visited_はbigint, total_はdoubleなど.
データを整形したり, 新たに列を追加したりしたので, それについての可視化も行っていく. 今回確認するのはどのTシャツの売り上げが一番高いのか. それをグラフで見るためにまたChartsを開く.
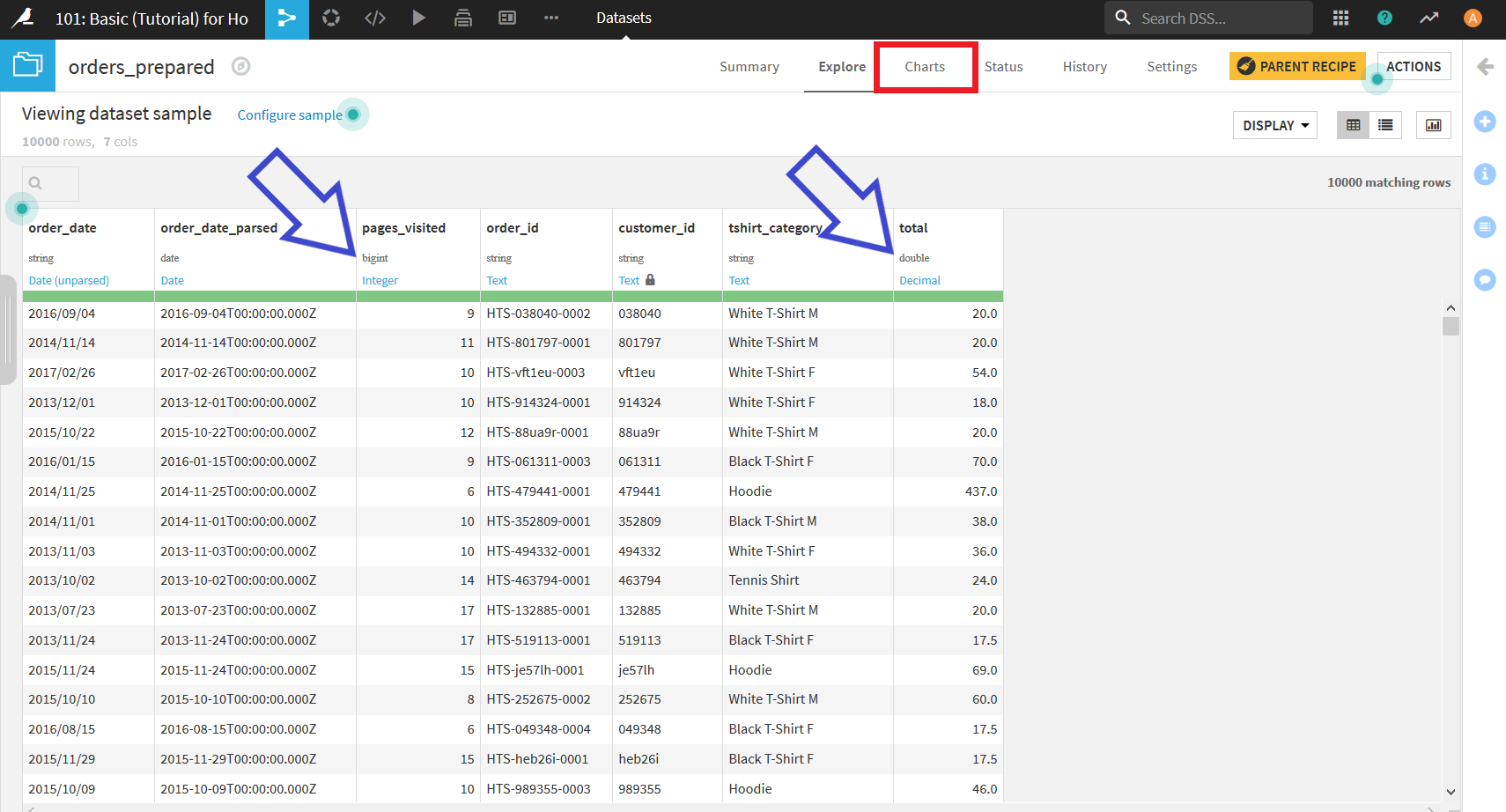
Xエリアに_tshirt_category, Yエリアに_total_をそれぞれドラッグ&ドロップをすることで, 以下のようなグラフを得ることができる.
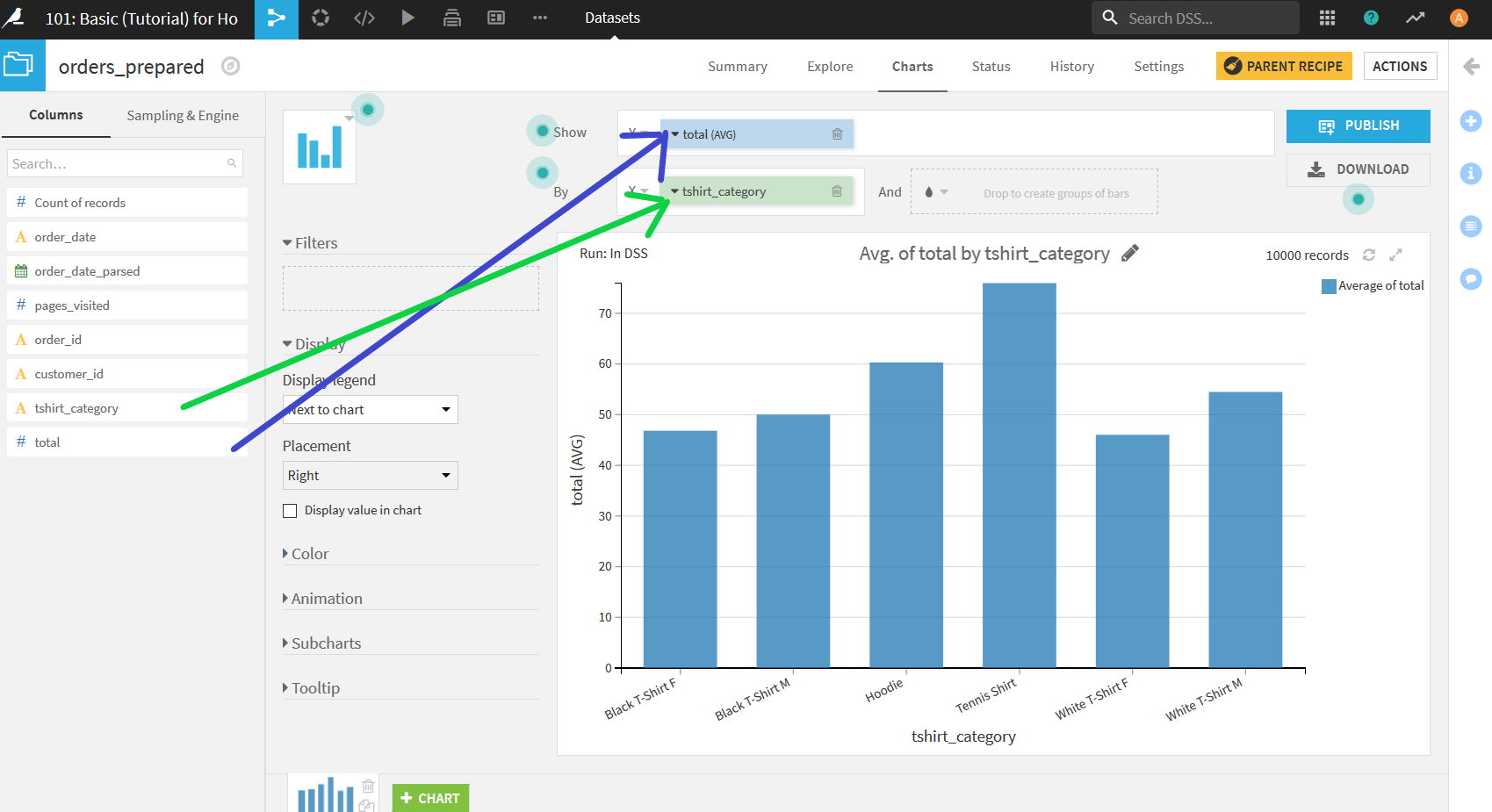
このグラフを一見するとTennis Shirtの売り上げが一番多いように見えるが, 実はこの段階ではTシャツの種類ごとに_total_の平均をとってしまっているため, 純粋な売り上げの比較になっていない. これをTシャツごとの売り上げ比較ができるように変更するには, Yエリアに置いた"total"をクリックしメニューを開く. その中の「Aggregate」のドロップダウンを開き, SUMを選択.
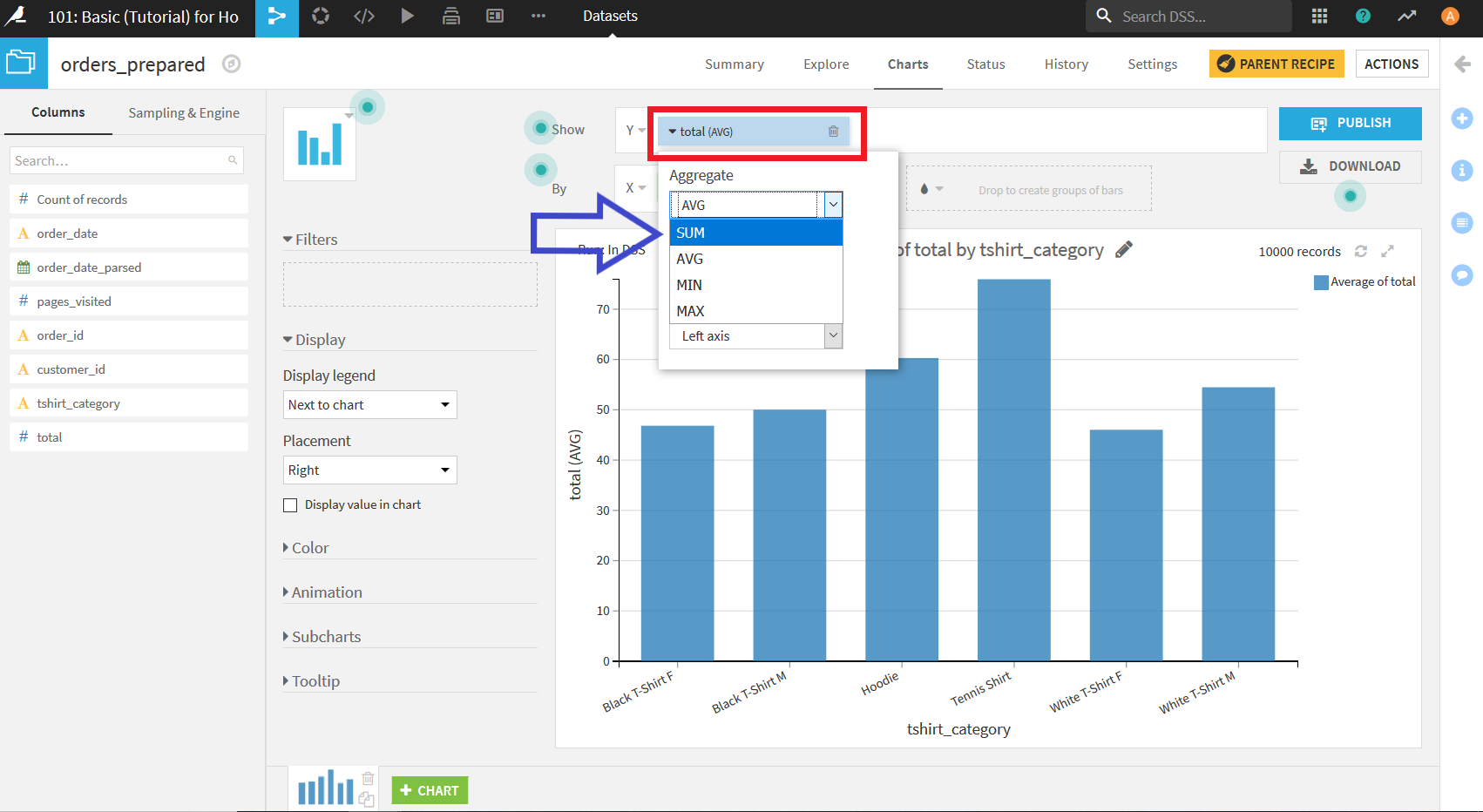
すると, グラフがTシャツの種類ごとの売り上げのグラフに変更される(この時, X軸の方も降順表示になっていない場合は変更しておくとグラフが見やすくなる).
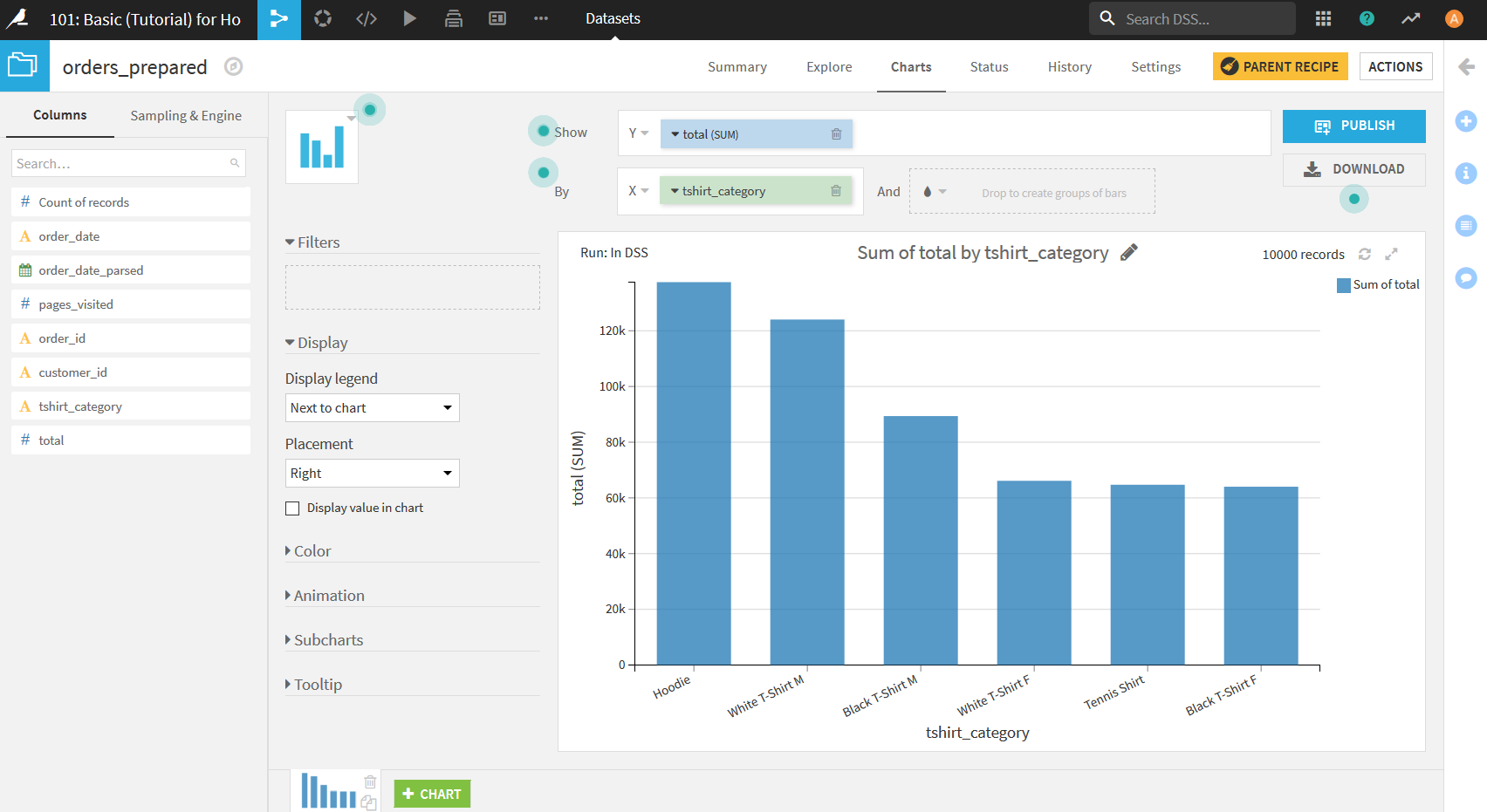
顧客ごとにグループ化
最終的にこのデータを用いて行いたいことはHaiku T-Shirtsの顧客について理解することである. このチュートリアルの最後に, 顧客ごとに過去の注文データをすべてまとめたデータを作成する.
画面右上の"ACTION"をクリックしてメニューを開き, "Group"を選択する.
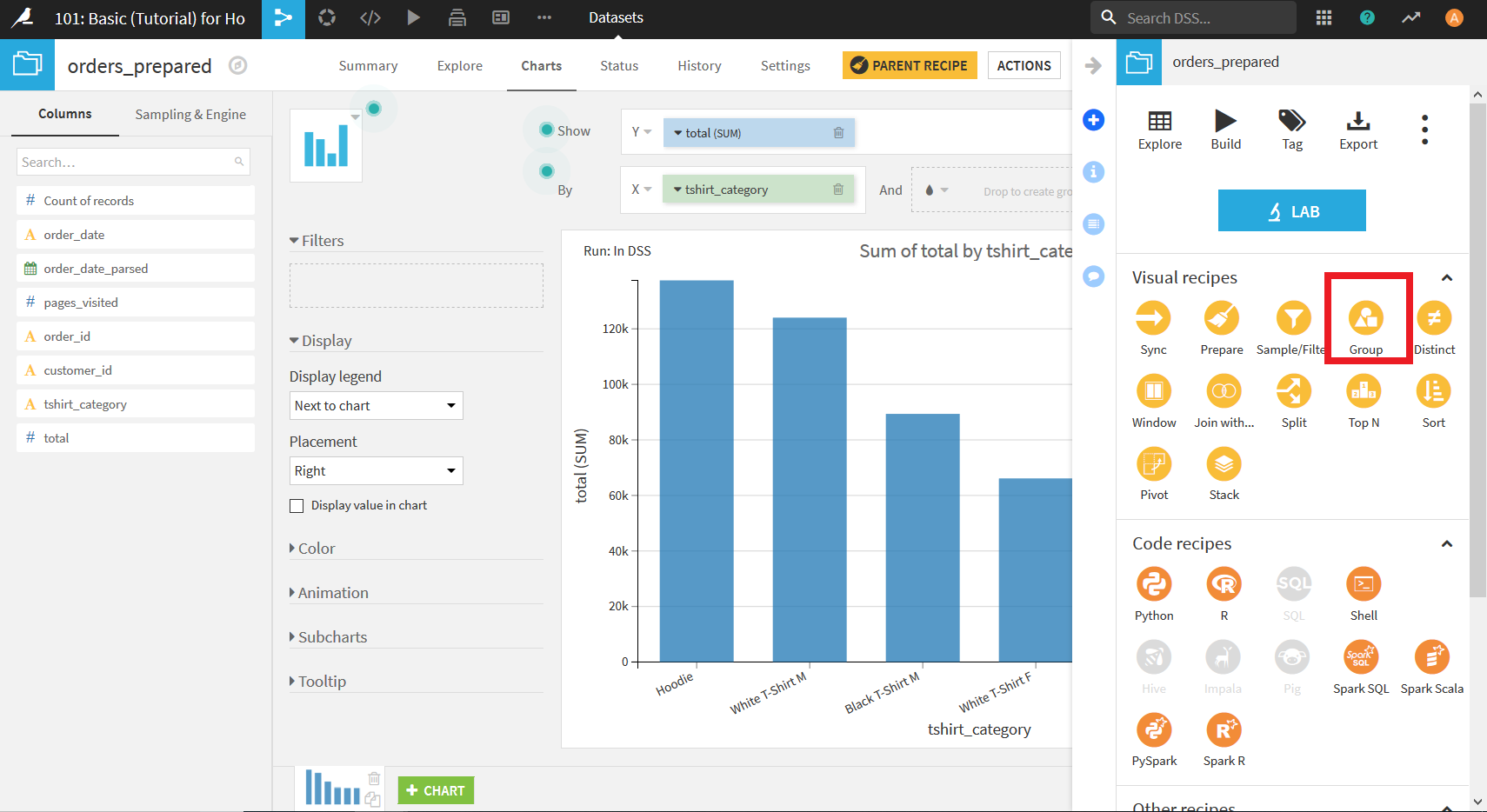
表示されたダイアログにおいて「Group By」のプルダウンから, "customer_id"を選択する.
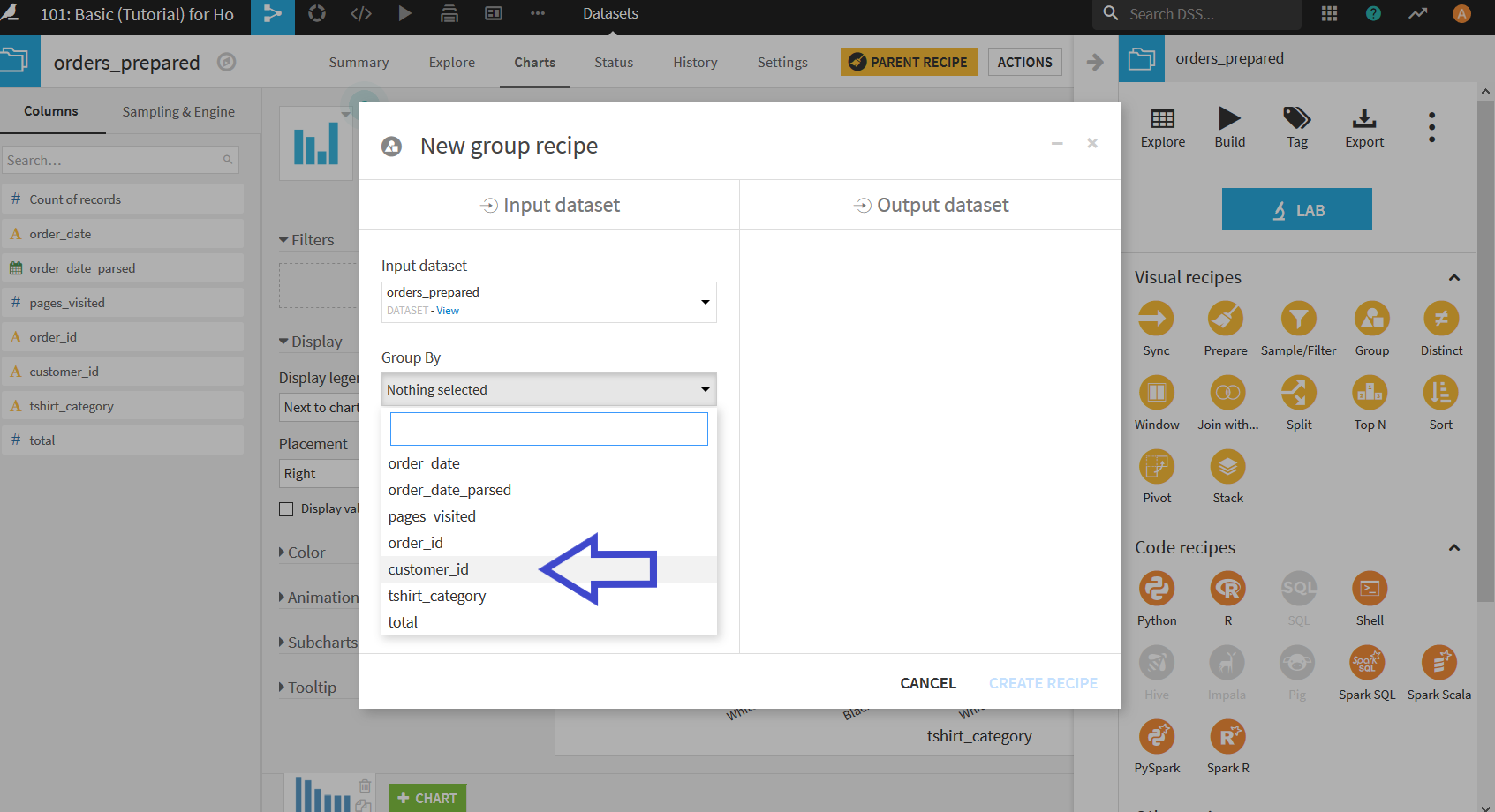
そして, 出力するデータセットの名前がデフォルトのままだと長すぎるため, 少し短く「orders_by_customer」に変更し, "CREATE RECIPE"をクリック.
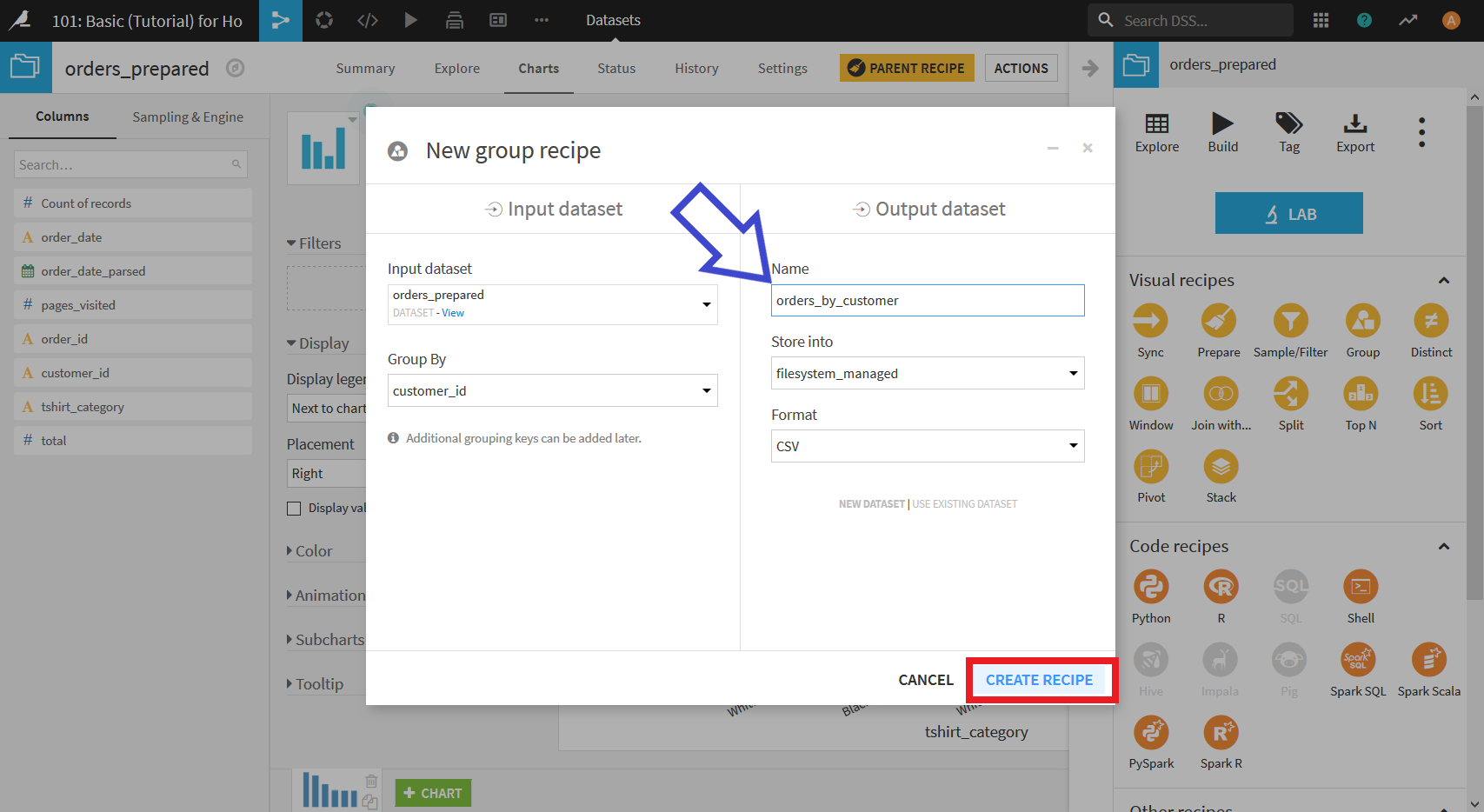
以下のような画面になるので,
- order_date: Min
- pages_visited: AVG
- total: Sum
をそれぞれクリックしチェックを入れる.
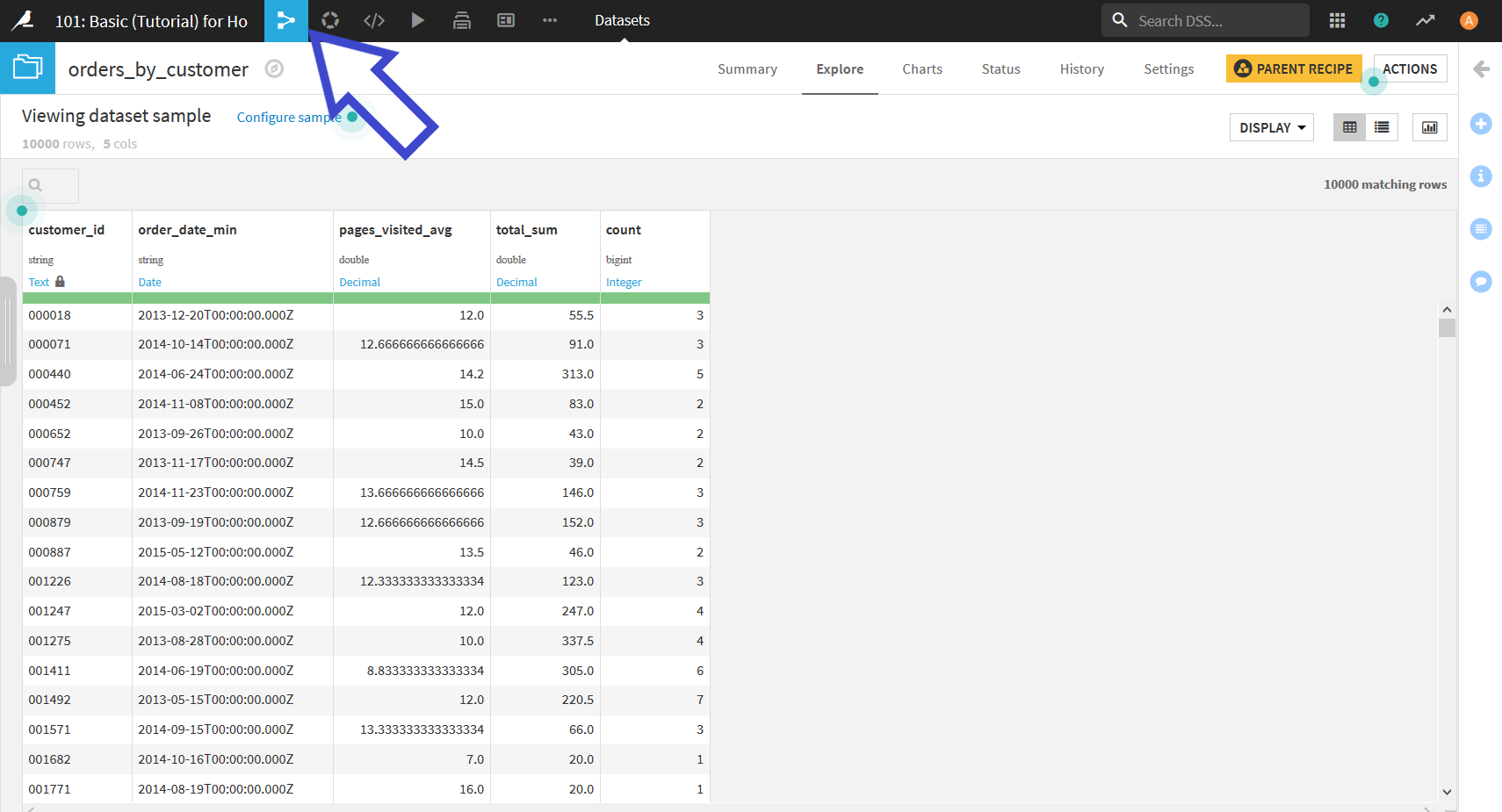
その後"RUN"ボタンを押すことで, 顧客ごとにグループ化したデータセットが出力される.
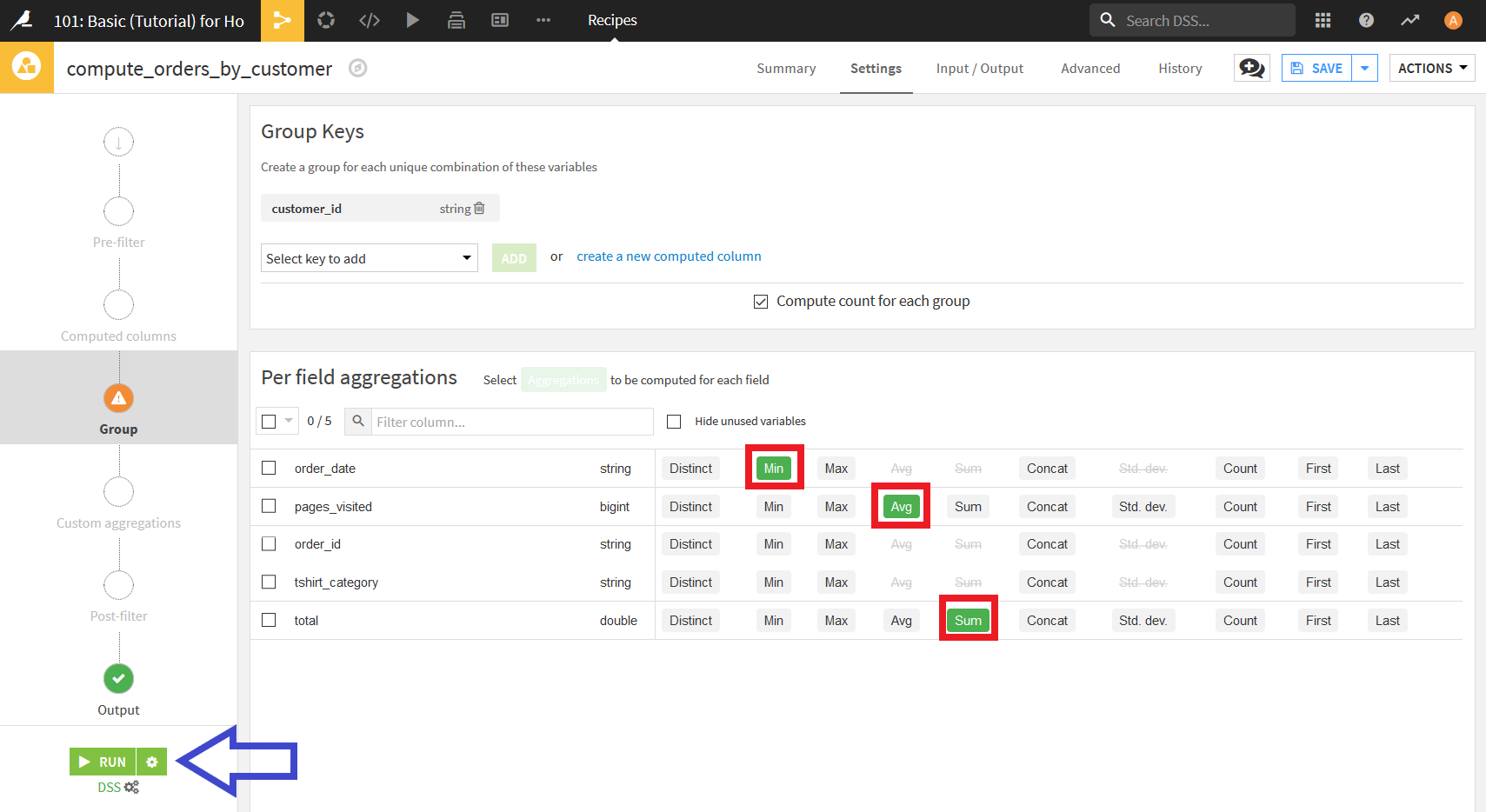
出力されたデータセットは以下のようになる.
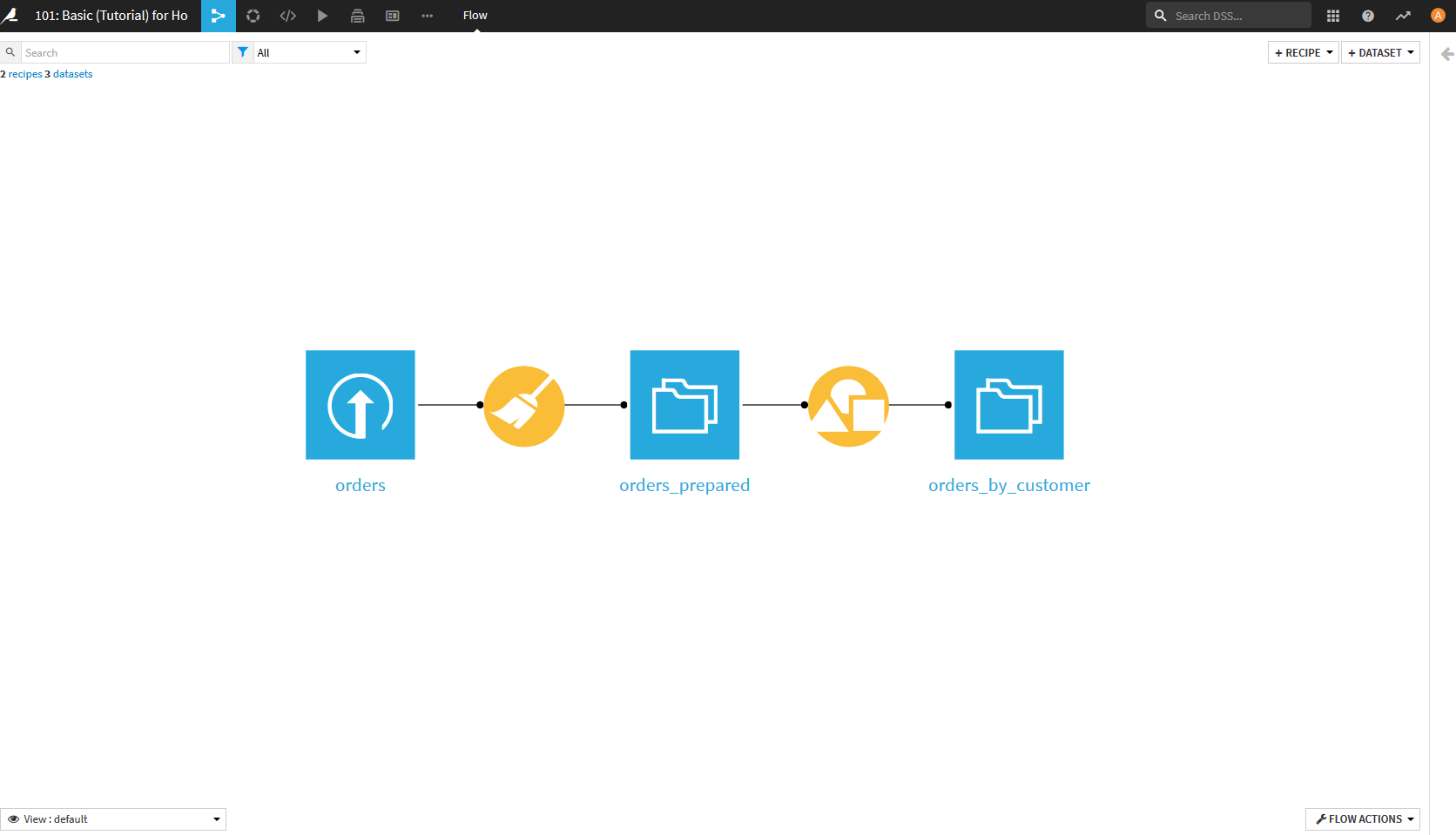
最後に, 左上のFLOWボタンをクリックして, 今までの処理を振り返る.
Prepare(箒マーク)でデータを加工し, Group(図形マーク)でデータをグループ化した流れがこのFLOW画面では見ることができる.
もし, 前の処理を確認したくなったらどんなことをやったか見ることができるし, やり直したくなったら前の処理を編集することで後の出力を変更することもできる.
以上でこのチュートリアルは終了.
次のチュートリアルは別の人がやってくれているのでそれを参考にしてもらうと良い.
Dataiku チュートリアルやりました(From Lab to Flow)
https://qiita.com/komugiko/items/fb547a83eb73f243441c