はじめに
自然言語処理のWord2Vecについて調べてみました。
その中でも、特に、HR領域の単語で学習されたモデルを使ってみました。
Word2Vecについて
自然言語処理の一つであり、単語をベクトル化して次元を圧縮する手法です。
ベクトル化することで、以下のような単語同士の演算が可能になります。
「king」-「man」+「woman」=「Queen」
さらに、ベクトル化したデータを次のディープニューラルネットワークの入出力データに利用することで、分類や認識、予測を行うことができます。
Word2Vecのアルゴリズム
Word2Vecは教師あり学習であり、2層(隠れ層と出力層)から成るニューラルネットワークです。

学習アルゴリズムにはCBoWとSkip-gramの2種類があり、CBoWは前後の単語から対象単語を予測するアルゴリズムです。
一方で、Skip-gramは対象単語からその周辺単語を予測するアルゴリズムです。
一般にSkip-gramの方が精度が高い(らしい)ので、今回はSkip-gramについて紹介します。
学習データには、一般に対象単語とその周辺5単語を取ります。
例えば、次のような14個の単語から成るテキストがあるとします。
(実際には、何百万の単語から成るテキストを使用する。)
「I usually go to the library near Shiniizuka station on the Fukuhoku Yutaka line .」
「I」を入力データとすると学習データは、(I,usually)、(I,go)、(I,to)、(I,the)、(I,library)になります。
学習データはone-hotベクトルに変換し、下図のようなニューラルネットワークに学習させます。
(one-hotベクトルについては、こちらをご覧ください。)
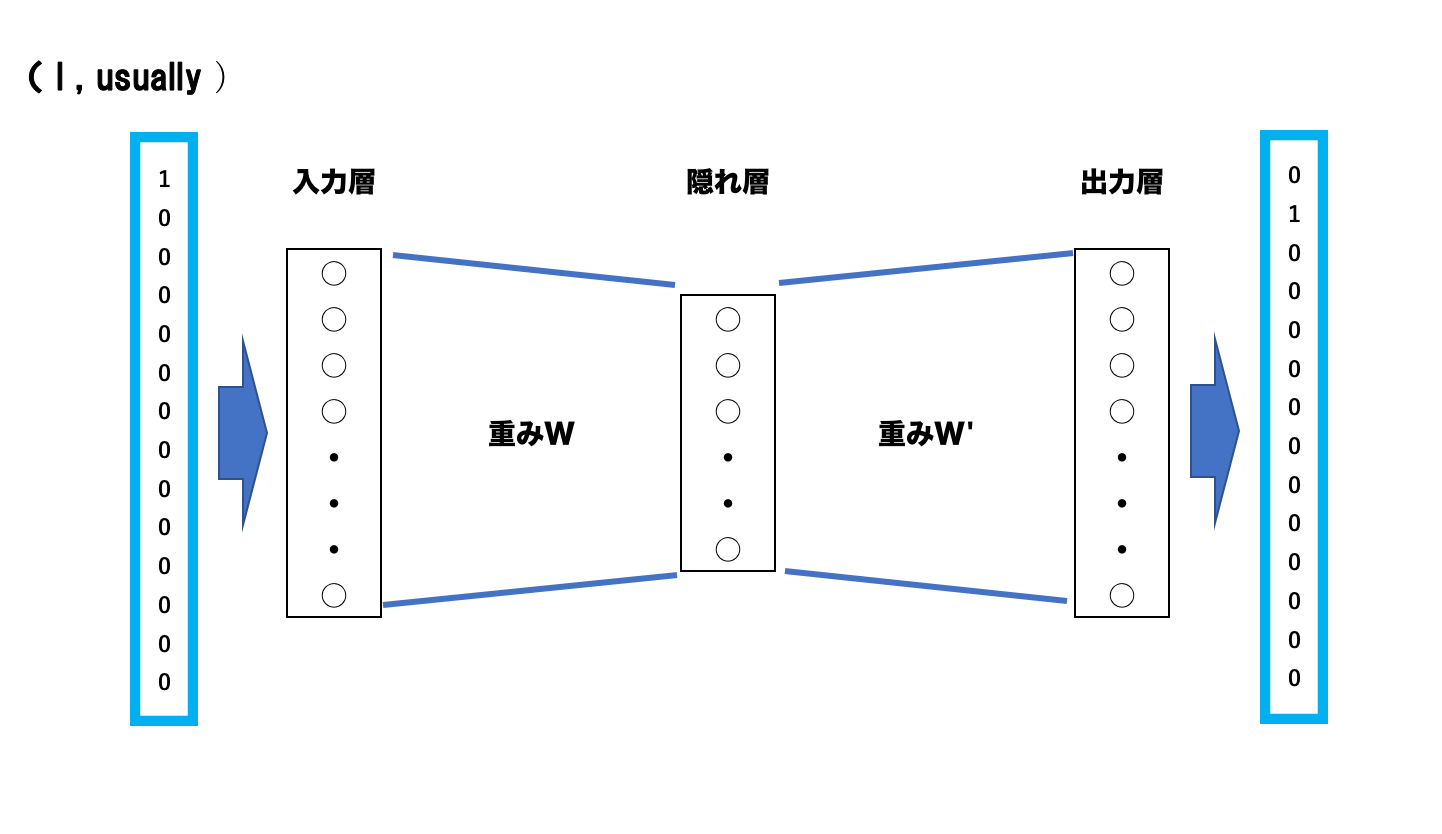
上図の場合は、「I」を入力すると「usually」が出力されるように学習させた場合です。
実際にWord2Vecを用いる際は、入力層を数万次元のベクトル、入力層から隠れ層への重み行列を数万×数百の次元に設定することが多いです。
つまり、次元を数万から数百に圧縮するということです。
このように学習させることで、入力層から隠れ層への重み行列Wを得ることができます。
次に学習で以下のような重みが得られたとし、入力データが「usually」であるとすると隠れ層の値は、

となり、重み行列の第2行がそのまま入ります。
つまり、重み行列の各行が入力単語それぞれのベクトルになります。
以上が簡単なSkip-gramのアルゴリズムです。
ベクトルの可視化
実際に(HR領域の単語で)学習済みのモデルを使って実装してみようと思います。
プログラムはPython3を使用しており、”こちら”にソースコードは載せています。
まずは、単語のベクトルを確認してみます。
下図は"Java"という単語を例にした場合です。
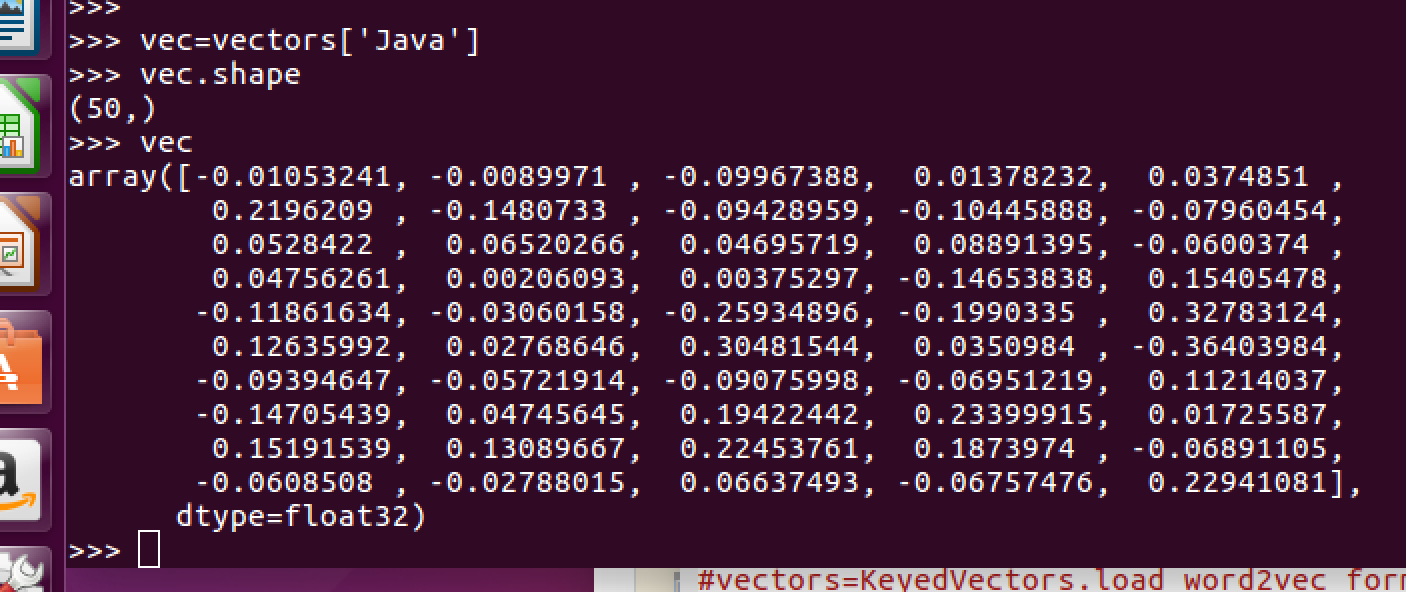
このモデルの場合、単語は50次元で表されているようです。
次に、"Java"と"機械"という単語について似ている順に10個見てみます。
ここでは、cos類似度を基に似ているかどうか判断しています。
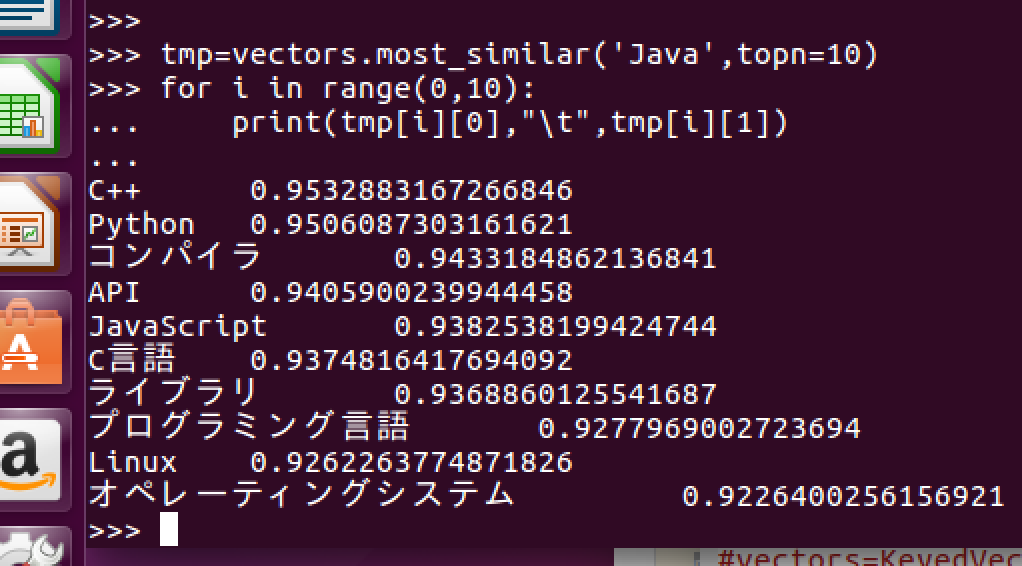
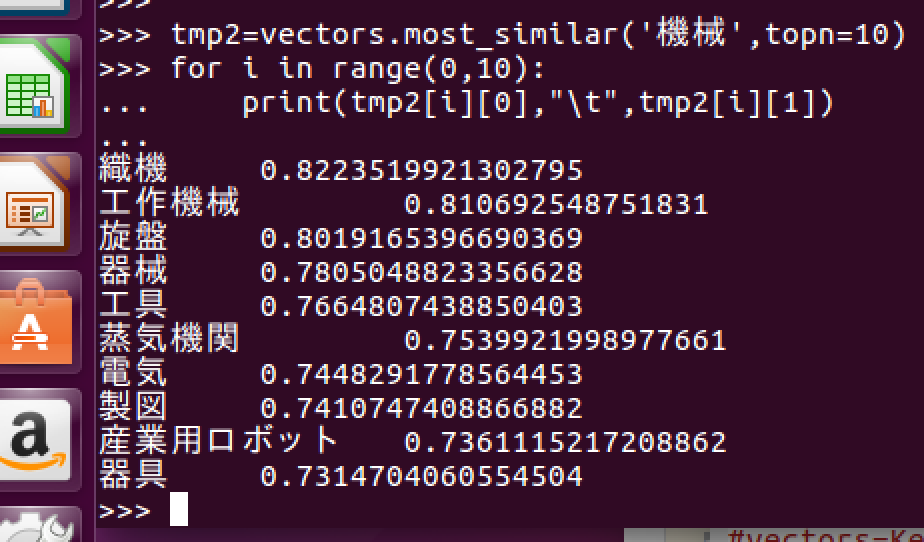
"Java"ではプログラミングに関係する単語、"機械"では工学系の単語が得られていることが確認できます。
では最後に、これらの単語を2次元でプロットしてみます。
(10単語では2次元に落とし込む際に特徴量が足りないので、30単語ぐらい使用しました。)
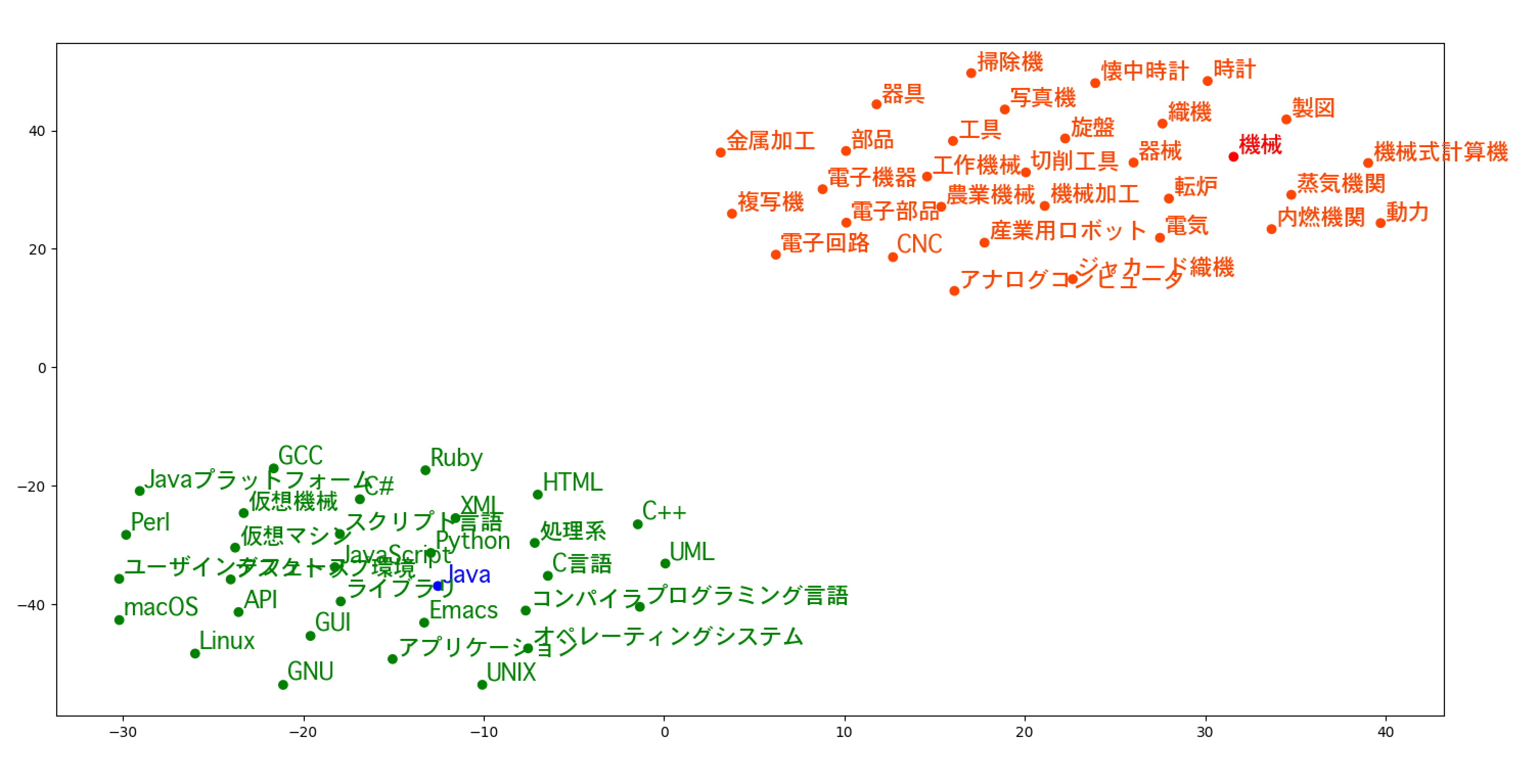
結果は、2つの単語に似た単語でグループ分けすることができました。
botの作成
Word2Vecを使って似たような単語を返す簡単なボットをつくってみました。
ソースコードは”こちら”に載せています。
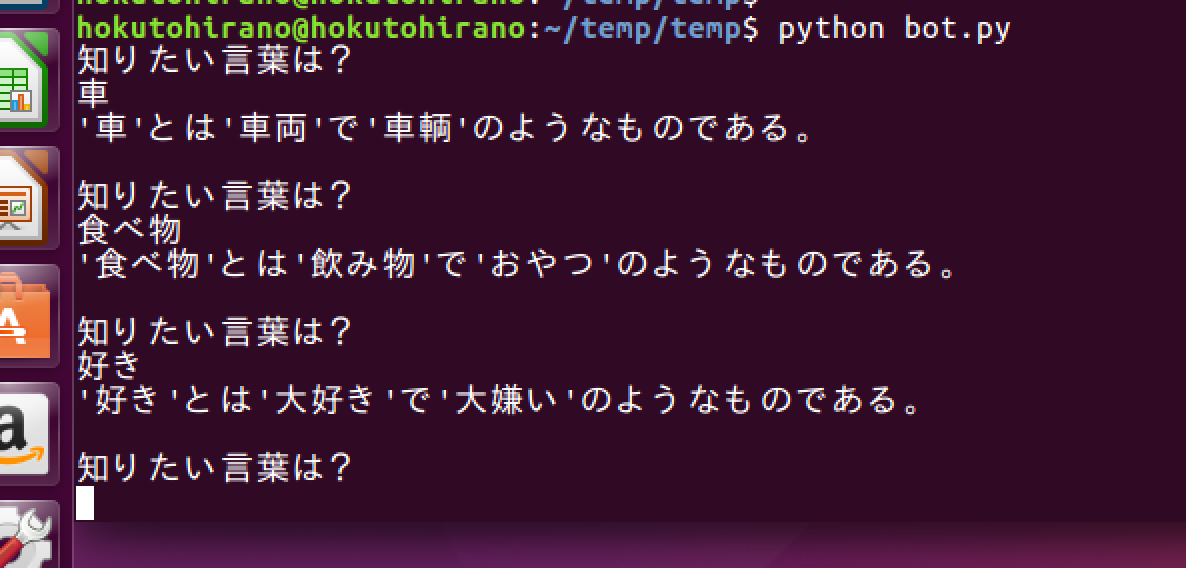
それなりに似たような言葉が帰ってきました。
しかし、最後の「好き」については少しヘンでした。
これは、学習時に「類似性」と「関連性」を区別して学習していないからです。
ここで、類似性とは「パソコン」と「コンピュータ」、関連性とは「パソコン」と「キーボード」といったような関係です。
「類似性」と「関連性」を区別できないことに関連して、対義語に弱いことがあります。
例えば、「私はあなたのことが好きです。」と「私はあなたのことが嫌いです。」では、学習データセットが同じになるからです。
課題点
Word2Vecは面白い技術ですが、以下のような課題点が挙げられます。
-
「類似性」と「関連性」を区別していない。
-
対義語に弱い。
-
学習していない単語のベクトルは得られない。
-
複数の意味をもつ単語に関して考慮していない。
応用例
-
レコメンドシステム
単語ベクトルの類似度を計算し、アイテムレコメンドの精度向上が可能。 -
機械翻訳
従来の確率的翻訳よりも翻訳精度が高い。 -
Q&A・チャットボット
従来の確率的翻訳では難しかった、固有名詞や数値表現(日付など)の抽出が可能。 -
文章のクラスタリング
トピックの抽出やニュースやエンタメといったジャンル分けが可能。 -
感情分析
Twitterなどの文章から感情分析が可能。
他にも、パターンが識別される可能性のある、遺伝子、コード、再生リスト、その他の文字列や記号列にも適用できる。
最後に
Word2Vecは、学習済みのモデルを使うことで簡単に試すことができました。
簡単なアルゴリズムですが、なかなか良さそうな結果が得られたと思います。
また、HR領域モデルの応用にも期待です。
他にも、Word2Vecの強化版であるfastTextというものがあるらしいので気になります。