ご注意
本ドキュメントは 2019/12 時点の状況での検証結果をまとめています。
コメントに頂きましたが 2020/9 に CloudSQL がレプリ元をFQDNで指定可能となった (ref) ようで、Aurora -> CloudSQL へ MySQL レプリケーションができるようになった可能性がありますのでご注意ください。
はじめに
ZOZOテクノロジーズでSREチームに所属している@hkameです
普段はZOZOTOWNのオンプレ基盤を運用しております
ZOZOTOWNはレガシーなシステムから徐々にパブリッククラウドへのリプレイスを実施していまして
そのプロジェクトに関わりながら、日々クラウドやk8s・CICDのスキルを吸収している人です
マルチクラウドでサービスを構築するための検証として
Aurora->CloudSQLの2サービスのみで、MySQLのレプリケーションができるか
を試したのでそちらを記事にします
レプリ要件
Aurora
https://aws.amazon.com/jp/rds/aurora/
AWSのフルマネージド型RDSで、saasと言われるサービスです
DBエンジンはMySQL, PostgreSQLが選択できます
外部へレプリするためには下記が求められます
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/AuroraMySQL.Replication.MySQL.html
- レプリ先のMySQLバージョン5.5以降
- InnoDBストレージエンジンを使用しているテーブルであること
CloudSQL
https://cloud.google.com/sql/?hl=ja
GCP版のフルマネージド型RDS saasです
DBエンジンはMySQL, PostgreSQL、さらにSQLServerが選択できます
外部からレプリを受けるためには、レプリ元データベースサーバに下記が求められます
https://cloud.google.com/sql/docs/mysql/replication/replication-from-external?hl=ja#server-requirements
ポイントは下記になります
- バイナリログが行ベースのロギングであること
- GTID が有効にされていて、GTID 整合性が強制されること
- MySQL ユーザー アカウントに REPLICATION_SLAVE 権限が割り当てられていて、どこからの接続でも受け入れるように構成していること(ホスト = %)
- IPv4 アドレスと TCP ポートに外部からアクセスできること
こちらの要件からAuroraはGTIDを設定する必要があり、IPv4でアクセスできる必要が出てきます
※GTID(グローバルトランザクション識別子)
個々のトランザクションに対してつけられた世界でユニークなIDのこと
それがバイナリログに記載されることで、マスターポジションを指定しないレプリケーションができる
https://dev.mysql.com/doc/refman/5.6/ja/replication-gtids-concepts.html
Aurora->CloudSQLへレプリしてみる
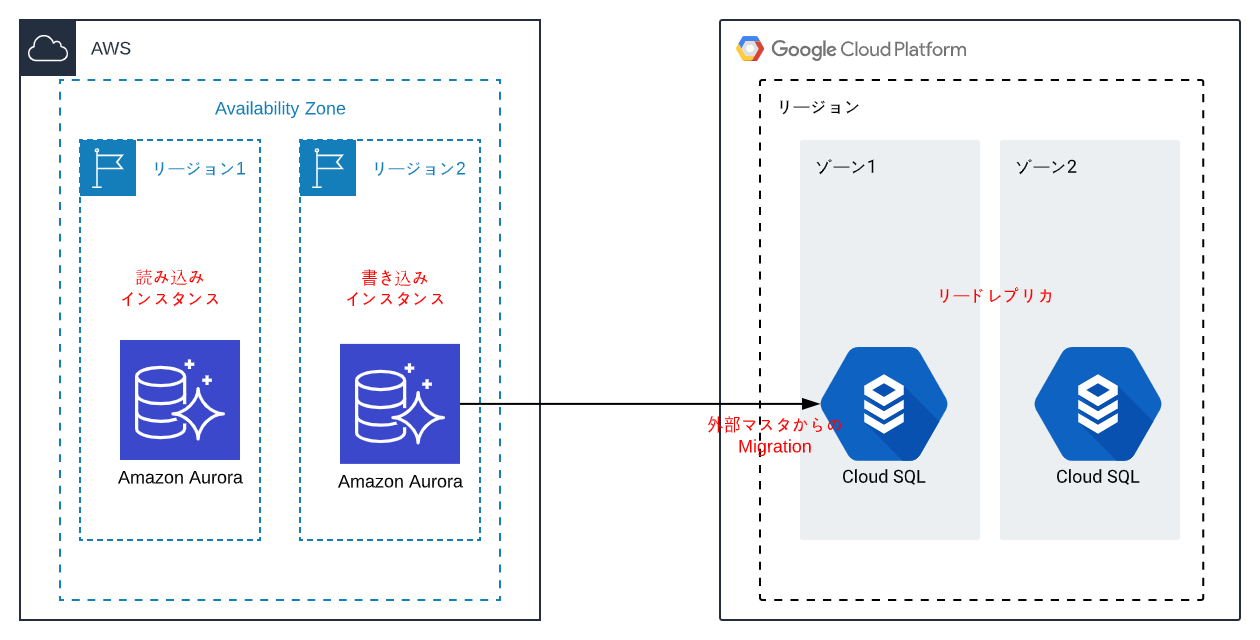
イメージ図
このようなものを作りました
Auroraはマルチリージョンで作成し、書き込みインスタンスからCloudSQLへレプリ
レプリカはマルチゾーンで複数作成
手順
前提
- 検証できるAWS・GCP環境、アカウント、権限
- AuroraのMySQLエンジンクラスタが作成されている
CloudSQLへインターネット越しにレプリするのでパブリックアクセス許可 - 検証用のデータベース・テーブルが作成されている
- 下記ができる作業用の環境
- mysqlコマンドで作成したAuroraクラスタの書き込みエンドポイントに接続
- gcloud、gsutilコマンドでGCPへ接続
Auroraの準備
クラスタのパラメータグループを変更
パラメータグループでクラスタのMySQLパラメータを変更できます
下記を変更します
-
binlog_formatをROWに設定
Aurora内のクラスタはバイナリログでなく、同一ストレージを参照することでレプリが実現されます
それもありバイナリログはデフォルト無効なので、ROWに設定し行ベースでのbinlogを有効にします -
gtid-modeをONに設定
GTIDはデフォルトOFFなので、ONに設定することで有効になります -
enforce_gtid_consistencyをONに設定
GTID整合性を強制します
変更後、クラスタの再起動をします
バイナリログの保持期間を設定する
バイナリログの保持期間を1週間に設定します
短いと、レプリ設定が完了する前にバイナリログが削除されてしまう可能性があるためです
Auroraの書き込みエンドポイントに、rootユーザでMySQLログインし下記を実行します
変更
CALL mysql.rds_set_configuration('binlog retention hours', 168);
確認
CALL mysql.rds_show_configuration;
レプリ用ユーザを作成する
作成
CREATE USER '[レプリ用ユーザ名]'@'%' IDENTIFIED BY '[パスワード]';
GRANT REPLICATION SLAVE ON *.* TO '[レプリ用ユーザ名]'@'%';
確認
SHOW GRANTS FOR '[レプリ用ユーザ名]'@'%';
CloudSQLの準備
CloudStorageでバケット作成
CloudSQLレプリカはAuroraのmysqldumpデータをインポートします
その際、GCPのクラウドストレージであるCloudStorageにデータを設置しておく必要があるため
バケットを作成しておきます
レプリケーション設定
AuroraのMySQLdumpを取得
mysqldump -u admin -p -h [Aurora書き込みエンドポイント] -P3306 \
--databases [データベース] \
--single-transaction \
--order-by-primary | gzip > dump.sql.gz
GTIDを利用した環境ではデータベースを指定した部分dump時に下記の警告がでます
データ自体は取得できていて、今回の検証では無視して進めてOKです
Warning: A partial dump from a server that has GTIDs will by default include the GTIDs of all transactions, even those that changed suppressed parts of the database. If you don't want to restore GTIDs, pass --set-gtid-purged=OFF. To make a complete dump, pass --all-databases --triggers --routines --events.
CloudStorageにdumpを設置
gsutil cp dump.sql.gz gs://[バケット名]/.
CloudSQLのレプリカを作成
GCPのコンソール画面のMIGRATE DATA 機能で
Auroraの書き込みエンドポイントをソースにレプリカを作成します
ここでひと工夫必要になりました
CloudSQLの外部からレプリケーションを受けるための、レプリ元サーバの要件
- IPv4 アドレスと TCP ポートに外部からアクセスできること
レプリ元をIPv4でしか指定できなかったのです!
AuroraはIPv4のエンドポイントを提供していません
仕方ないので、暫定的に書き込みエンドポイントをAWS外部から名前解決した際に確認できる
Auroraインスタンスの実態であるEC2インスタンスのIPv4アドレスを使用します
確認方法は下記になります
dig [書き込みエンドポイント] +noall +answer
結果例
[書き込みエンドポイント] 5 IN CNAME [書き込みインスタンスのエンドポイント]
[書き込みインスタンスのエンドポイント] 5 IN CNAME [EC2インスタンスのエンドポイント]
[EC2インスタンスのエンドポイント] 86400 IN A xx.xx.xx.xx
AuroraでCloudSQLレプリカからの通信許可
レプリカを作成すると、送信IPアドレスが払い出されます
Auroraのセキュリティグループのインバウンドルールで
送信IPアドレスからの3306通信を許可します
レプリ完了をまつ
レプリカのステータスアイコンがロード中から
緑のチェックに変わるとレプリ完了です
SHOW SLAVE STATUS¥Gで確認すると
このような状態でレプリケーションがされていました
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
slaveIO、SQLどちらも正常
Seconds_Behind_Master: 0
スナップショットから最新バイナリログまで追いついている
Replicate_Wild_Ignore_Table: mysql.%
mysqlデータベース以外がレプリケーション対象
また、レプリカインスタンスはread_onlyがONでした
複数のレプリカを作成する
1つ目はコンソール画面から作成する必要があるのですが
2つ目以降はgcloudコマンドでのみ作成ができます
gcloud beta sql instances create [レプリカインスタンス名] \
--master-instance-name=[外部プライマリインスタンス名] \
--master-username=[レプリユーザ名] --prompt-for-master-password \
--master-dump-file-path=gs://[バケット名]/[dumpファイル名] \
--tier=[インスタンススペック/例:db-n1-highmem-2] --storage-size=[DISKサイズ/例:10G]
同様に、AuroraでCloudSQLレプリカからの通信許可をしレプリ完了を待ちます
完了
以上でAurora->CloudSQLへレプリケーションができました
検証は成功なの?
レプリケーションをすることはできましたが
今回の構成ではAuroraの書き込みインスタンスがフェイルオーバーなどで変更した場合
レプリケーションが止まってしまうため、失敗です
レプリ元をIPv4で指定せざるを得ないため
フェイルオーバーでレプリ元が降格したレプリカを指定する状態になってしまい
Slave_IO_Running: No
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Binary log is not open'
とレプリが止まってしまいました
各クラウドのエンジニアにも確認しましたが
- AuroraがIPv4のエンドポイントを提供
- CloudSQLがレプリ元をFQDNで指定可能
現在はどちらもサービス提供はしていないとのことで
どちらかが可能になれば2サービスのみで
Aurora->CloudSQLができるのではないかと思っております!
最後に
まだまだ知識不足で、文言など間違いあったらすいません
マルチクラウドでシステム構築したい!
という方がどのくらいいるのか疑問ではありますが、少しでも興味を持って頂けたら幸いです