はじめに
機械学習では、モデルの学習に使用するコードだけでなくデータセット、前処理で生成された生成物、モデルなどもセットで管理する必要があり実験管理が難しいという問題があります。適切な実験管理は、実験段階で動いていたコードを本番環境に持っていき同様の予測結果を再現するのにも重要になります。
機械学習の実験管理ではMLflowなどが有名ですが、ClearML(前の名前: Allegro Trains)という実験管理ツールを見つけたので、この記事ではClearMLの簡単に使い方について説明させていただきます。
ClearML: https://github.com/allegroai/clearml (Apache-2.0 License)
公式ドキュメント: https://allegro.ai/clearml/docs/index.html#
実験管理の考え方については、以下の記事も非常に参考になります。
実験管理について考える Re:ゼロから始めるML生活
要約
ClearMLは機械学習の実験管理、MLOpsの機能を提供しているツールです。機械学習のライフサイクルの中で開発、バージョントラッキングに関連した時間がかかる・エラーが起きやすいタスクをサポートしてくれます。
ClearMLには、大きく分けて3つの以下の機能があります。
-
実験管理
- 環境と学習結果を含めた自動的な実験管理
-
MLOps
- 自動化、パイプライン化、ML/DLジョブのオーケストレーション
-
データ管理
- オブジェクトストレージ(S3/GS/Azure/NAS)でのデータ管理&バージョン管理
この記事では、3つの機能のうち主に実験管理の使い方について説明させていただきます。
また、ClearMLのアーキテクチャについても最後に簡単に説明しています。
ClearMLを使用してみて、実験管理として以下の情報が管理可能と確認しています。
- コードバージョン
- 学習に使用したコードのCommit ID, ライブラリのバージョンをログとして取得
- データバージョン
- 出力された中間生成物,モデルの管理する機能あり
- ハイパーパラメータ
- Pythonのargparseのパラメータを自動的にログとして取得
- メトリクス
- 一般的なloss, accuracy, confusion matrixなど取得可能
- 環境
- 学習に使用したマシンの学習ディレクトリ場所をログとして取得
動作確認環境
- Ubuntu 18.04
- Python 3.7
- ClearML 0.17.2
新バージョンのClearMLでは、この記事の通りに動作しない可能性がありますのでご注意ください。
無料のClearMLホストサービスをセットアップする
この記事では、無料の外部にホストされているClearMLのサーバを使用します。セットアップ方法は以下のドキュメントに従っています。
https://allegro.ai/clearml/docs/docs/getting_started/getting_started_clearml_hosted_service.html
独自のClearMLサーバーをオンプレミスやAWS,GCPに立てるのも可能みたいですので、セキュリティなどの要件がある方は、以下のドキュメント手順で設定することができます。
https://allegro.ai/clearml/docs/rst/deploying_clearml/index.html
- 以下のサイトでsign upしてアカウントを登録します。
- アカウントはGoogleアカウント,Bitbucket,Githubのいずれかで登録可能のようです。
-
氏名や、Email,興味関心などを入力して、「SIGN UP」をクリックしてアカウントを登録します。
-
以下のコマンドを実行して、clearmlをインストールします。
pip install clearml
- 以下のコマンドを実行して、ClearMLのセットアップウィザードを起動します。
clearml-init
- アカウントの資格情報を作成してくださいとのメッセージが表示されるので、資格情報を取得する。無料のホストサービスのweb画面で右上のユーザアカウント>Profileをクリックします
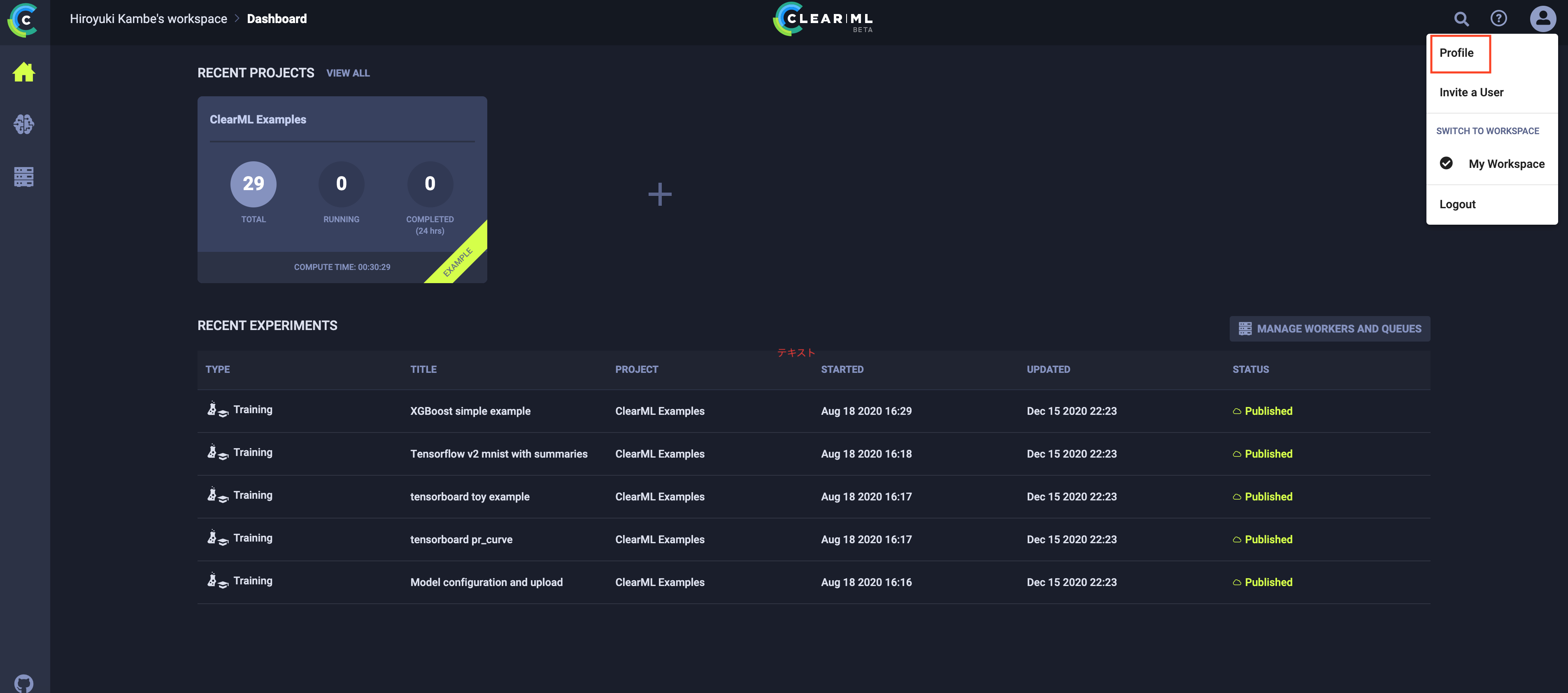
- Create new credentials > Copy to clipboardをクリックします。
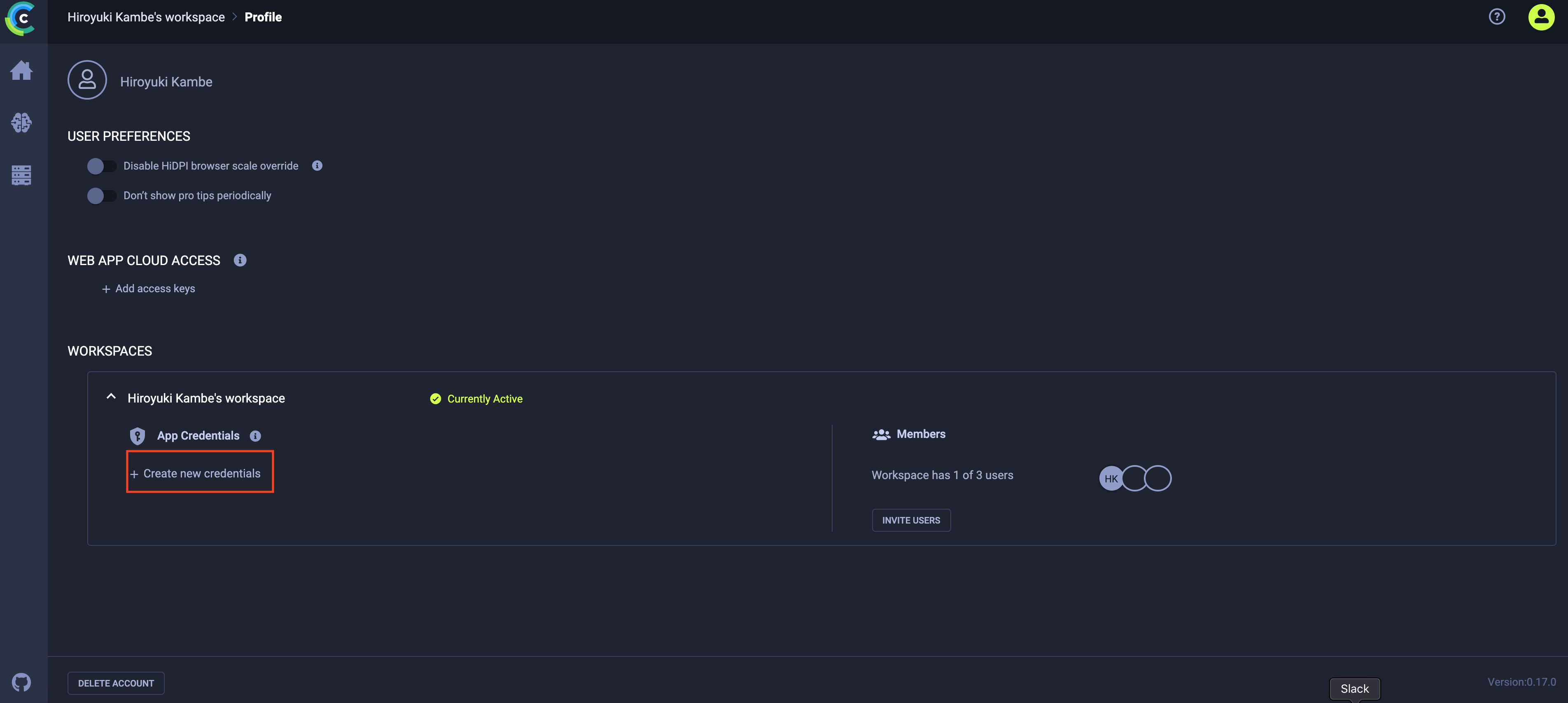
- ターミナルでコピーした資格情報をペーストすると、以下のように資格情報が検出されたメッセージが表示されます。
Detected credentials key="********************" secret="*******"
- web serverのURLを指定します。今回はデフォルトでEnterを押します。
WEB Host configured to: [https://app.community.clear.ml]
- 続いてAPI serverのURLを指定します。これもデフォルトのままでEnterを押します。
API Host configured to: [https://api.community.clear.ml]
- これで以下のようなメッセージが表示されるので、セットアップは完了です。
CLEARML Hosts configuration:
Web App: https://app.community.clear.ml
API: https://api.community.clear.ml
File Store: https://files.community.clear.ml
Verifying credentials ...
Credentials verified!
New configuration stored in /home/<username>/clearml.conf
CLEARML setup completed successfully.
Reporting Tutorialをやってみる
- ClearMLにTutorialのコードがありますので、リポジトリをcloneしてきます。
cd ~
git clone https://github.com/allegroai/clearml.git
cd ~/clearml/examples/frameworks/pytorch
pip install -r requirements.txt
pip install pandas scikit-learn
-
pytorch_mnist.pyというReporting Tutorial用のスクリプトがありますので、これをコピーしてファイル名を変更します。
cp pytorch_mnist.py pytorch_mnist_tutorial.py
model checkpointsが保存されるディレクトリを設定する
- model checkpointsが出力されるoutputディレクトリは
Task.initのoutput_uriを指定してあげると設定できます。- 以下の箇所を変更します。
task = Task.init(project_name='examples', task_name='pytorch mnist train')
- 以下のように変更すると、
./clearmlにcheckpointsが保存されます。
model_snapshots_path = './clearml'
if not os.path.exists(model_snapshots_path):
os.makedirs(model_snapshots_path)
task = Task.init(project_name='examples',
task_name='extending automagical ClearML example',
output_uri=model_snapshots_path)
- スクリプトを実行するとClearMLは以下のようなディレクトリ構造を作成します。
+ - <output destination name>
| +-- <project name>
| +-- <task name>.<Task Id>
| +-- models
| +-- artifacts
Loggerの設定をする
ClearMLは自動ロギング機能に加えて、明示的にプロット、ログテキスト、テーブルなどのreportingが機能があるようです。
https://allegro.ai/clearml/docs/docs/tutorials/tutorial_explicit_reporting.html#step-2-logger-class-reporting-methods
- loggerは以下のようにTaskから取得することができます。
logger = task.get_logger
or
logger = Logger.current_logger()
- 以下のようにスカラーのメトリクスをロギングする場合は、
Logger.report_scalarメソッドを使用します。
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
Logger.current_logger().report_scalar(
"train", "loss", iteration=(epoch * len(train_loader) + batch_idx), value=loss.item())
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
- また、スカラー値以外のhistgram, confusion_matrixといったメトリクスも以下のような形で実装することができます。
def test(args, model, device, test_loader, epoch):
save_test_loss = []
save_correct = []
preds = []
targets = []
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
preds.append(pred.cpu().detach().numpy())
targets.append(target.cpu().detach().numpy())
save_test_loss.append(test_loss)
save_correct.append(correct)
test_loss /= len(test_loader.dataset)
Logger.current_logger().report_scalar(
"test", "loss", iteration=epoch, value=test_loss)
Logger.current_logger().report_scalar(
"test", "accuracy", iteration=epoch, value=(correct / len(test_loader.dataset)))
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
preds = np.concatenate(preds)
targets = np.concatenate(targets)
matrix = confusion_matrix(targets, preds) # use confusion matrix of scikit-learn
Logger.current_logger().report_confusion_matrix(title='Confusion matrix example',
series='Test loss / correct', matrix=matrix, iteration=1,
xaxis='correct', yaxis='pred', yaxis_reversed=True)
Logger.current_logger().report_histogram(title='Histogram example', series='correct',
iteration=1, values=save_correct, xaxis='Test', yaxis='Correct')
- また、
Logger.report_textを使うことで、level引数に応じたテキストメッセージを表示することができます。
Logger.current_logger().report_text('The default output destination for model snapshots and artifacts is: {}'.format(model_snapshots_path ), level=logging.DEBUG)
生成物を登録する
ClearMLはスクリプトを実行した際の生成物を登録することで、ClearML Serverにアップロードすることもできます。生成物が変化した場合、ClearML Serverでその変化のログを取るようになっています。しかし、2020/12/29時点ではPandasのDataFrameのみサポートしているとのことです。
https://allegro.ai/clearml/docs/docs/tutorials/tutorial_explicit_reporting.html#step-3-registering-artifacts
- 生成物を登録するには以下のように
testメソッドに以下のようなコードを追加します。
# Create the Pandas DataFrame
test_loss_correct = {
'test lost': save_test_loss,
'correct': save_correct
}
df = pd.DataFrame(test_loss_correct, columns=['test lost','correct'])
# Register the test loss and correct as a Pandas DataFrame artifact
Task.current_task().register_artifact('Test_Loss_Correct', df, metadata={'metadata string': 'apple',
'metadata int': 100, 'metadata dict': {'dict string': 'pear', 'dict int': 200}})
- 登録された生成物は、Pythonコードから以下のように参照することができ、後の処理に活用にできます。
# Once the artifact is registered, we can get it and work with it. Here, we sample it.
sample = Task.current_task().get_registered_artifacts()['Test_Loss_Correct'].sample(frac=0.5,
replace=True, random_state=1)
生成物をアップロードする
Task.upload_artifactメソッドを使用することで、ClearMLにスクリプトで生成した生成物をアップロードすることができます。しかし、こちらのアップロードは上の登録と異なり、変更は追跡されないようになっています。
- 以下のコードを
testメソッドに記載して、Prediction結果をアップロードします。
# Upload test loss as an artifact. Here, the artifact is numpy array
Task.current_task().upload_artifact('Predictions', artifact_object=np.array(save_test_loss),
metadata={'metadata string': 'banana', 'metadata integer': 300,
'metadata dictionary': {'dict string': 'orange', 'dict int': 400}})
Reportingスクリプトを実行する
- 以下のコマンドでスクリプトを実行します。実行するとClearMLのログやモデル学習のロスなどのログが表示されます。
python3 pytorch_mnist_tutorial.py
- 今回の場合ですと以下のようにモデルが保存されます。
ls clearml/examples/extending\ automagical\ ClearML\ example.13e46b70da274fa085e772ed700df028/models/
mnist_cnn.pt test.pt training.pt
Web画面での学習結果の確認
- web画面で学習結果を確認することできます。
Task.initの引数でproject_name='examples'を渡しているので、web画面のexamplesのprojectをクリックします。
-
Task.initの引数でtask_name='extending automagical ClearML example'なので、extending automagical ClearML exampleと表示されているもので、学習に対応しているものをクリックします。
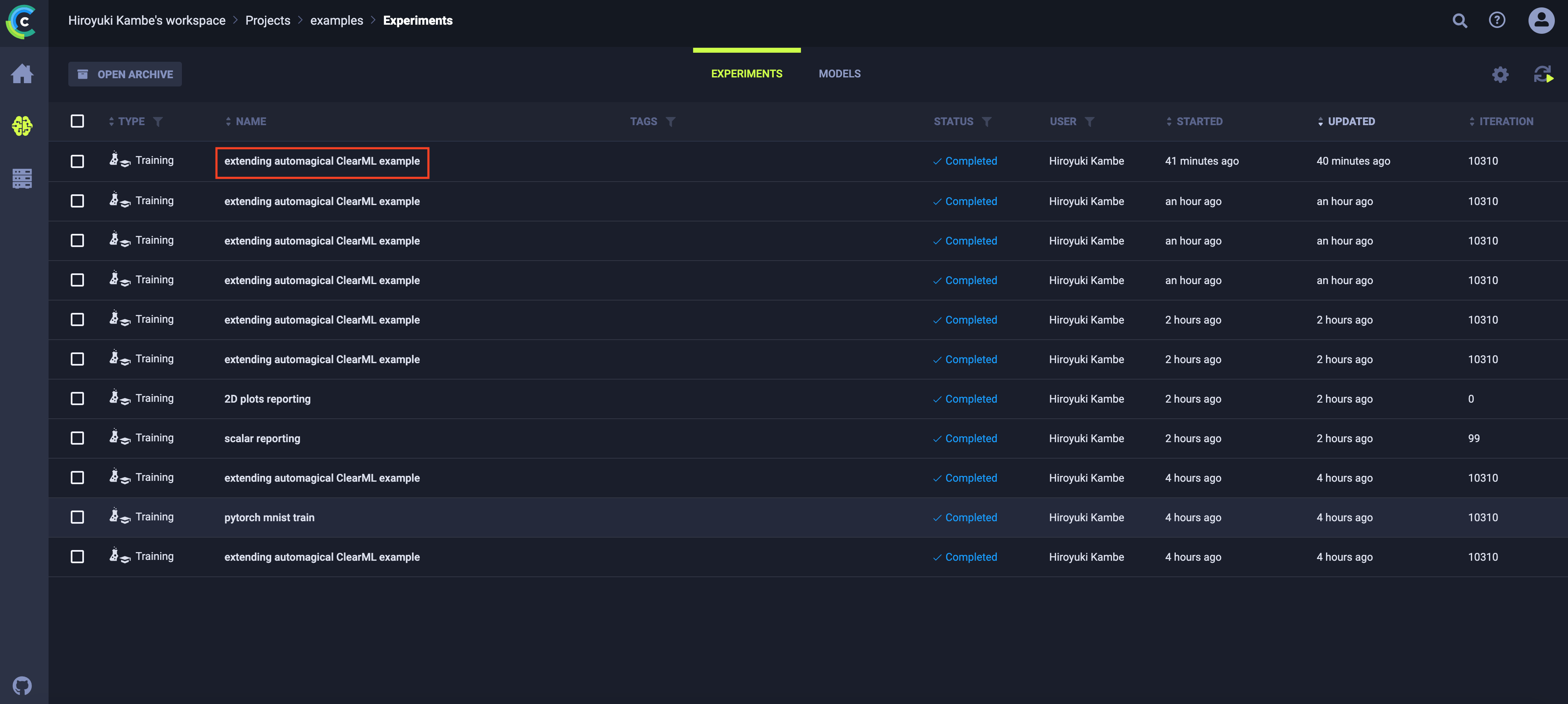
- EXPERIMENTSのEXECUTIONでは、学習の際実行したソースコードの情報などが確認できます。実行したスクリプトのファイル名や、COMMIT IDのログが取られているので実験を再現できるようになっています。
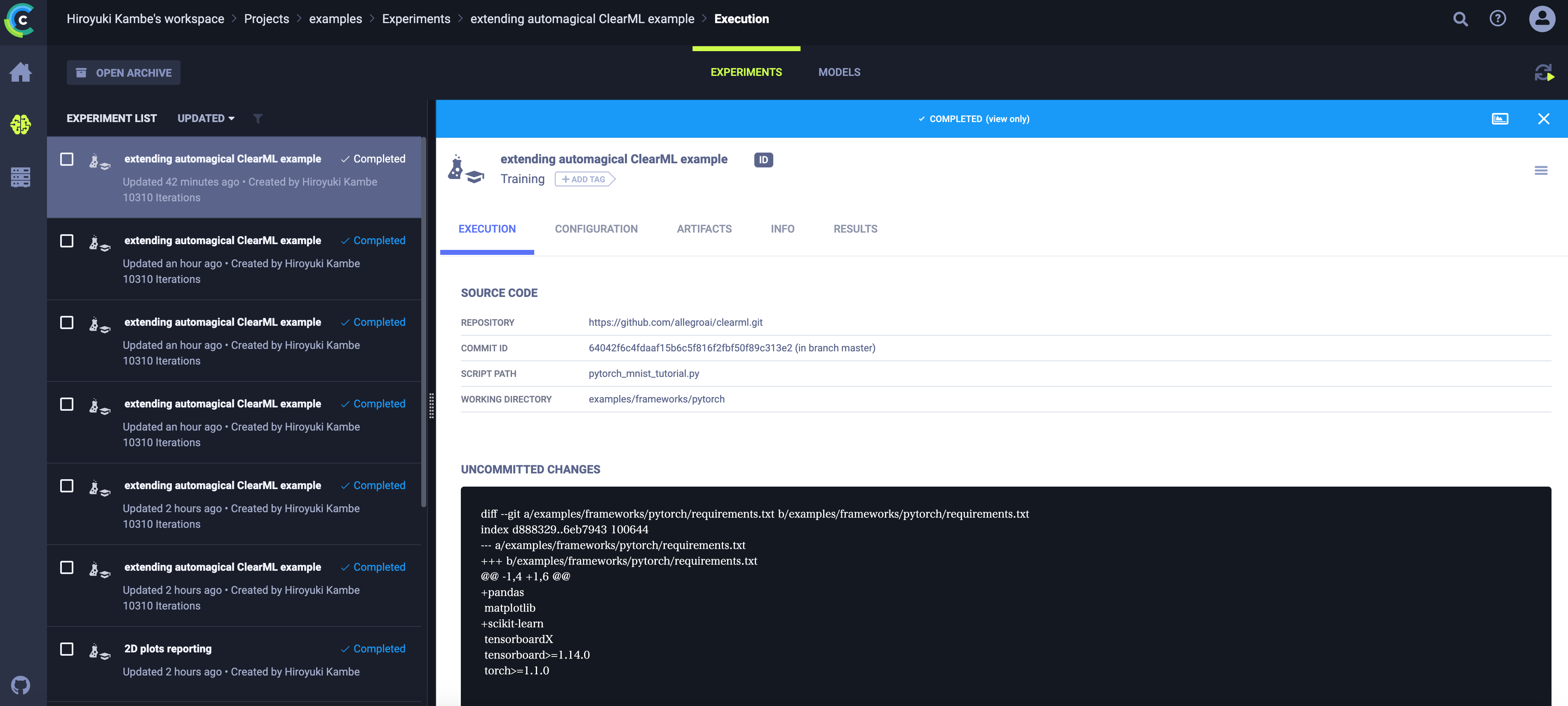
- CONFIGURATIONでは、学習の際のハイパーパラメータのログが確認できます。ハイパーパラメータに対して独自のログに関するコードを追加する必要がないのでこれも便利だなぁと思いました。
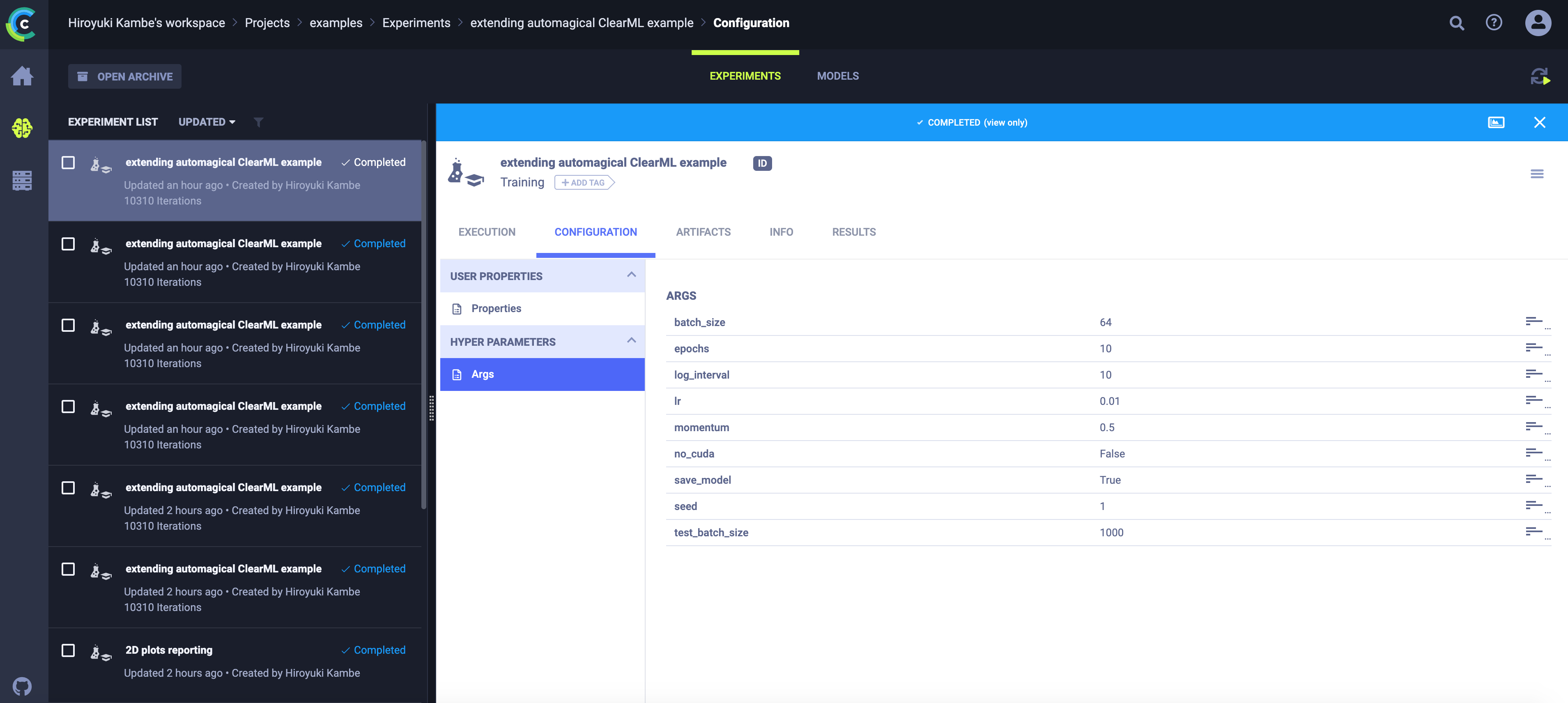
- ARTIFACTSでは、出力されたモデルの情報や、生成物に関する情報を確認できます。
- RESULTSでは、スカラー値やプロットに関するログを確認できます。学習時のロス変化や精度変化のプロットは以下になります。
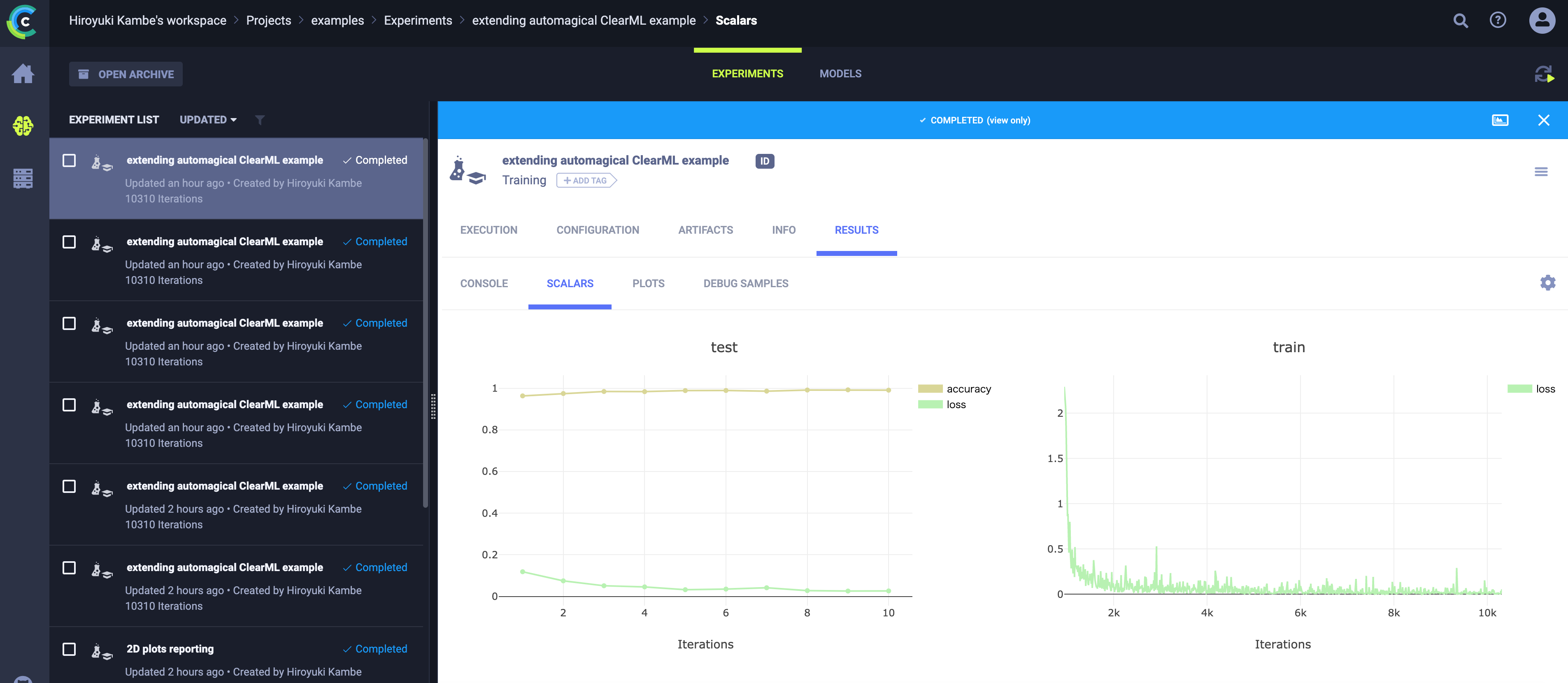
- また、混合行列のプロットは以下のようになります。
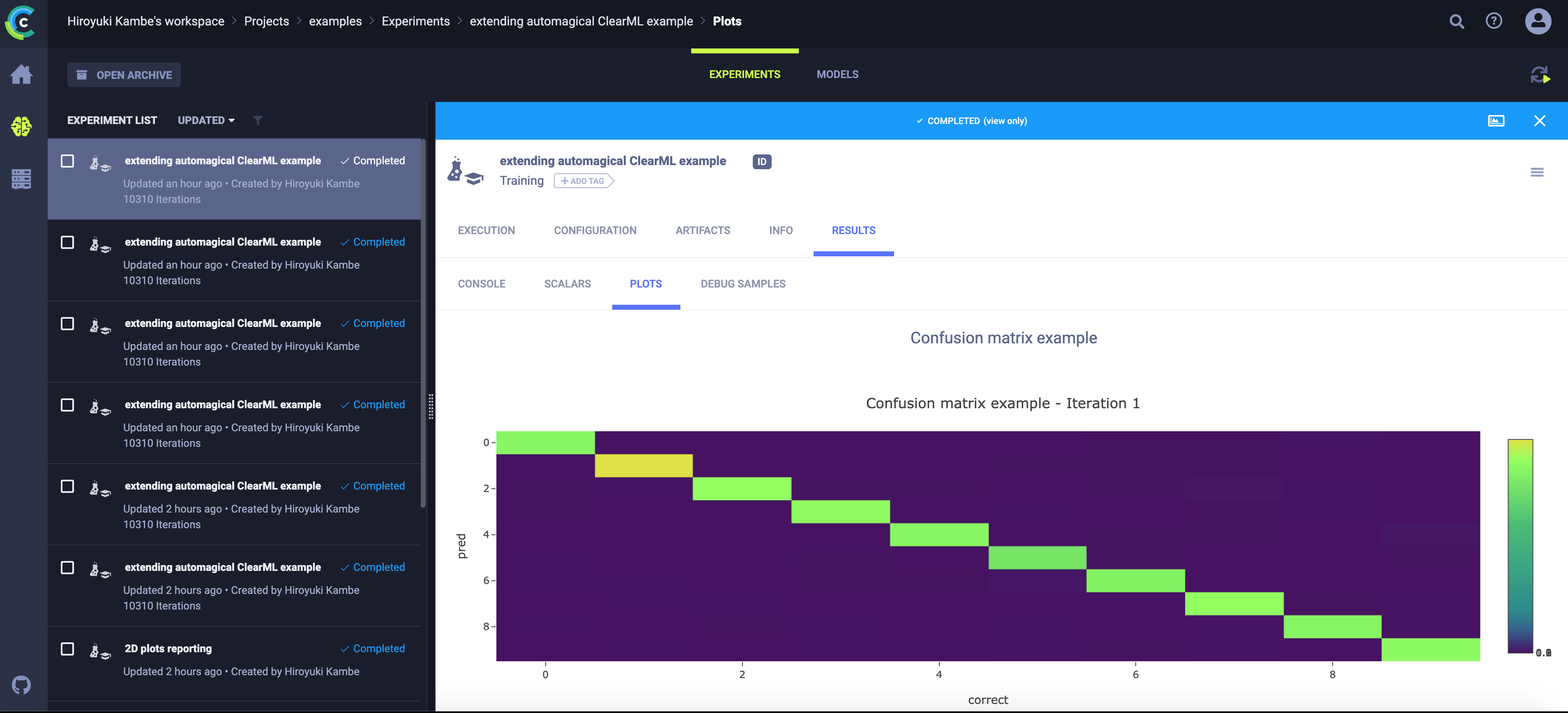
これで、メトリクスや生成物のログをとるReportingのTutorialは以上になります。
ClearMLのアーキテクチャ
ClearMLは以下のようなコンポーネントで構成されています。
- ClearML Python Package (clearml)
- 既存のスクリプトに数行のコードを追加することでClearMLに統合する
- ClearML Server (clearml-server)
- 実験、モデル、ワークフローのデータを保存する。また、Web UIによる実験管理や、再現性、チューニングのためのMLOpsの自動化の役割を持つ。
- ClearML Agent (clearml-agent)
- MLOpsオーケストレーション、実験、ワークフローに対して役割を持つ
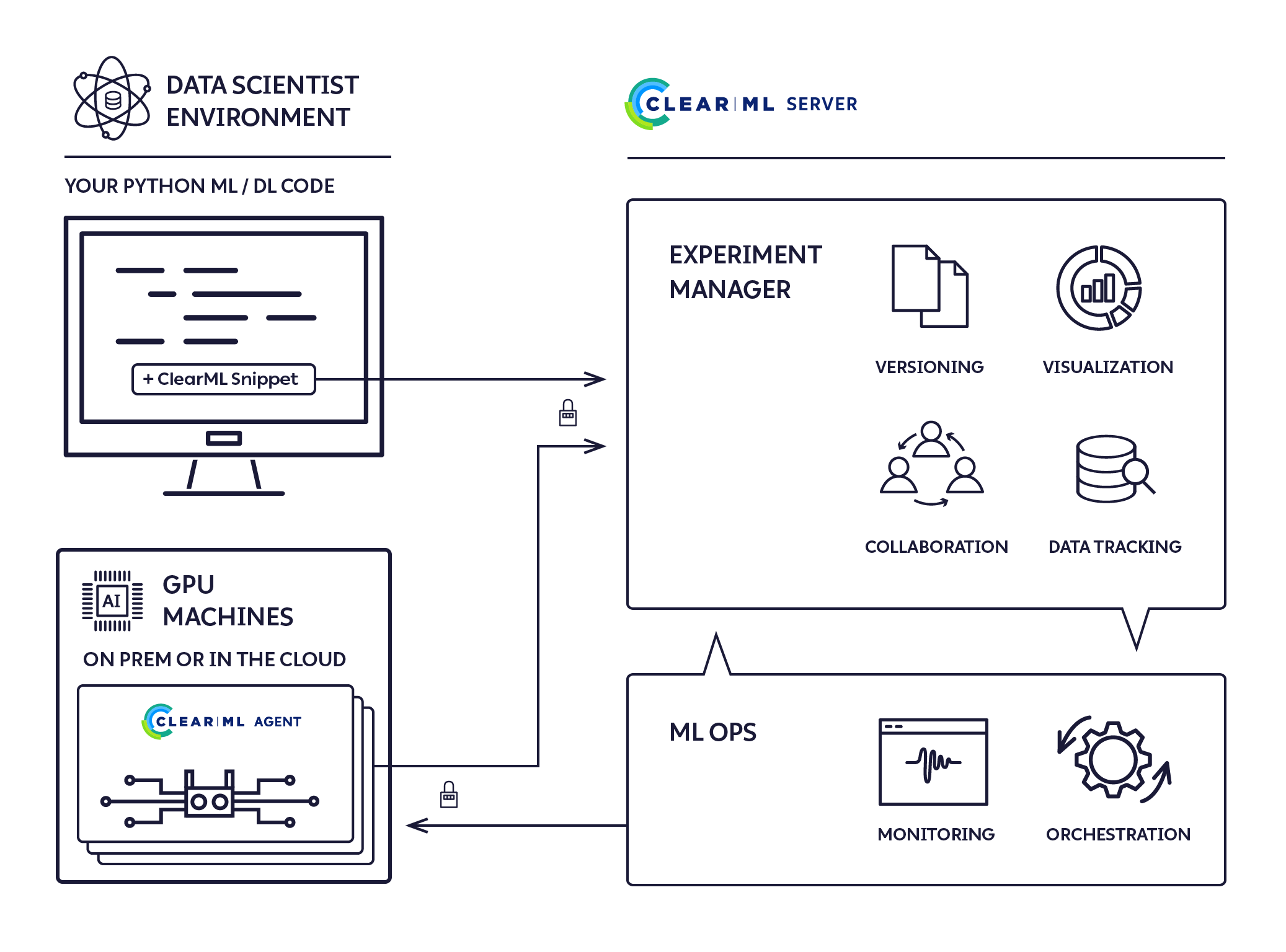
引用: https://allegro.ai/clearml/docs/rst/architecture/index.html
上図のClearML Serverは今回無料の外部ホストのものを使用しました。おさらいになりますが、ClearML Serverはオンプレミス環境で独自サーバを立てるのも可能ですし、AWS,GCPなどのクラウド上にサーバを立てて利用することも可能です。
また、上図の左のDATA SCIENTIST ENVIRONMENT環境とGPU MACHINES(オンプレ or クラウド)の両方で同じ数行のコードを追加するだけで使えるのも利点であるように思われます。
ClearMLを使用してみて感じた良さ
- pipインストールして、数行のコードを追加するだけで使える手軽さ
- 無料の外部ホストで使い始めが簡単
- 独自サーバを立てることで、オンプレミス、クラウドの両方で使える
- examplesのコードが充実している
- Pytorch, Pytorch-Lightning, Tensorflow, Keras, AutoKerasなど様々なフレームワークをサポートしている
- Web UIの見た目が綺麗
- MLOps的な機能、例えば反復的にハイパーパラメータチューニングする機能がある模様。
参考文献
- ClearML: https://github.com/allegroai/clearml (Apache-2.0 License)
- ClearML 公式ドキュメント: https://allegro.ai/clearml/docs/index.html#
- 実験管理について考える Re:ゼロから始めるML生活
免責事項
著者は本記事を掲載するにあたって、その内容、機能等について細心の注意を払っておりますが、内容が正確であるかどうか、安全なものであるか等について保証をするものではなく、何らの責任を負うものではありません。
本記事内容のご利用により、万一、ご利用者様に何らかの不都合や損害が発生したとしても、著者や著者の所属組織(日鉄ソリューションズ株式会社)は何らの責任を負うものではありません。