2019.07.24 原則はカーディナリティの高いものから貼っていく を追記しました。
2019.07.24 実際のMySQLはB+tree構造を採用している を追記しました。
はじめに
@hk206です。
最近になって初めてインデックスなるものを使い始めました。
これによってレコード検索が爆速になります。MAJIDE。
今まではしょぼい数のレコードのテーブルしか触ったことがありませんでしたが、
数百万、数千万のレコードを色々いじる機会がありまして......
処理速度やばない?ってふと気になり、インデックスを使用してみました。
インデックスとはなんぞやってところからB-tree構造まで、広ーーーく浅く調べたのでまとめてみました。
知ってるよーって方も復習になればいいかなと。
インデックスとは
インデックスは特定のカラムの、あるレコードをすばやく見つけるために使用されるものです。検索が爆速になります。
本を読む時、章ごとに付箋みたいなのを貼っておくと目的のページにたどり着くのが早いのと同じです。(貼らない人は、目次とか索引とかイメージしてもらえれば)
インデックスがないとMySQLは関連するレコードを見つけるために、先頭行から始めてテーブル全体を読みとらないといけなくなります。(フルテーブルスキャン)
広辞苑くらいぶっっっ厚い本に索引がなかったり、あいうえお順になっていなかったりしたら...地獄ですよね...。
インデックスの貼り方
検索をかけるカラムにインデックスを貼るだけ。ほんと簡単なのでやらないのは損。
参照コマンド(自分が貼ったインデックスがわかります。機能しているとは限りません。)
SHOW INDEX FROM テーブル名;
作成コマンド
ALTER TABLE テーブル名 ADD INDEX インデックス名(カラム名);
削除コマンド
ALTER TABLE テーブル名 DROP INDEX インデックス名;
インデックスの効果
今回はあるテーブルのcategoryカラムにインデックスを貼ってみました。
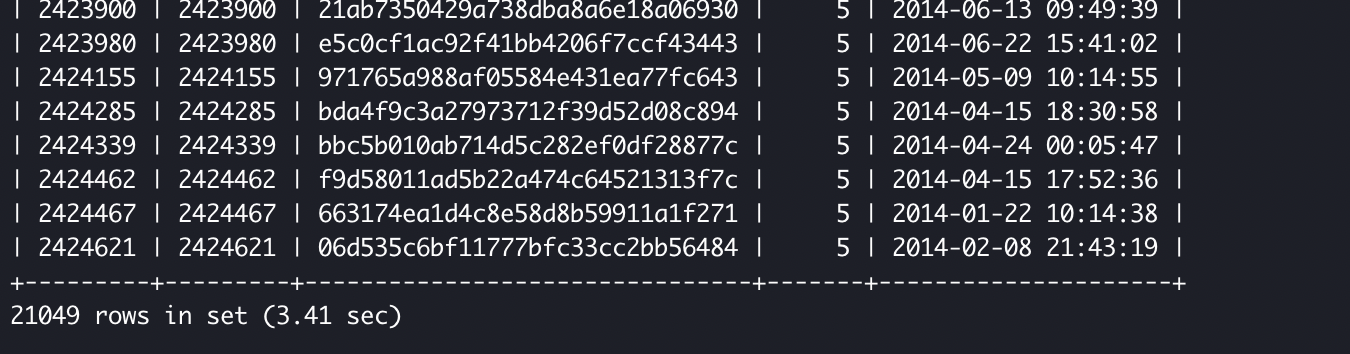
以下は250万弱のレコードのうち、カテゴリーナンバーが'5'である約2万レコードを抽出した時の例です。
インデックスがない場合
インデックスを貼った場合
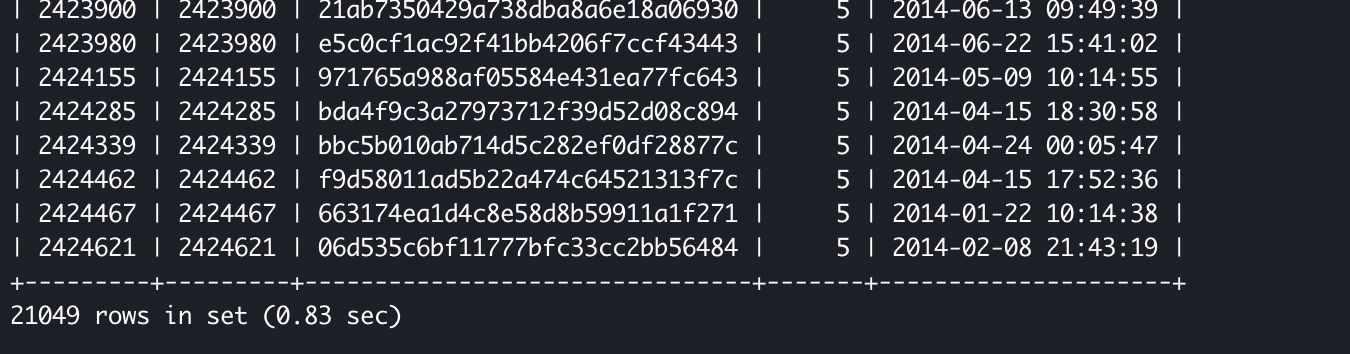
以上から分かるようにかかる時間が全然違います。
念のため、本当にインデックスが効いているかどうかをEXPLAINってやつを使って確認しましょ。
クエリのパフォーマンスを見るEXPLAIN
インデックスが効いているかどうかを実際に知るには、EXPLAINをクエリの頭につけて実行し確認する方法があります。
以下のコマンドで、どうぞ。
EXPLAIN SELECT カラム名1, カラム名2... FROM テーブル名 WHERE 条件...;
コマンドを実行すると以下のような結果に。(見づらいけど)
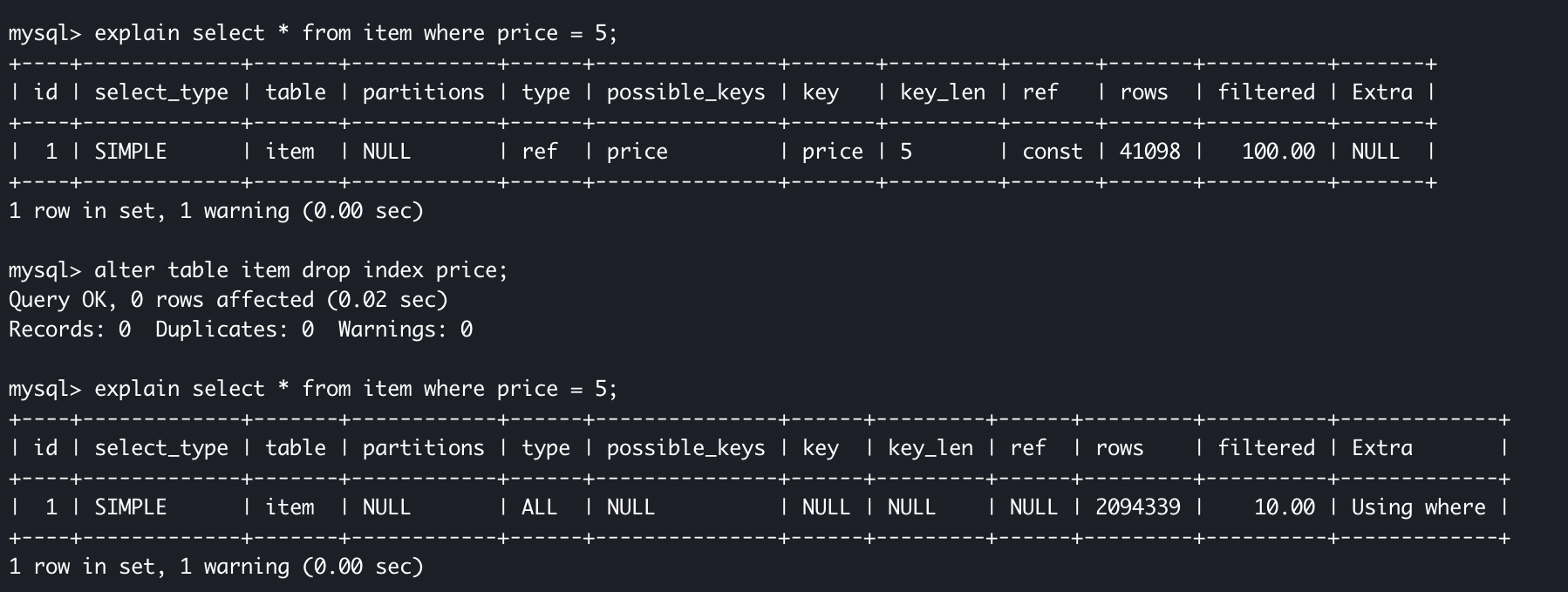
これは、データベースからレコードを引っ張ってきているわけではなくクエリ実行時のパフォーマンスを表しています。
1回目の実行結果はインデックスが効いている場合、2回目の実行結果はインデックスが効いていない場合です。
色々読み方が難しいので、ここではインデックス実行時に見るべきところだけを説明します。
type
レコードへのアクセス方法。ここがrefとなっている場合は、constではないインデックスを使って等価検索を行いアクセスしたことを表しているとのこと。とりあえずこれならOK。
ALLって書いてある場合は、フルテーブルスキャンしていることを表し、インデックスが全く使用されていないことを示すため注意が必要です。
possible_keys
貼られる可能性のあるインデックスを示す。ここではpriceのみとなっているが、複数つけた場合は複数表示される。例えばcategory, priceとあったら、カテゴリー順のインデックスと、値段順のインデックスどっちでも使える状態だよってことです。実際に使用されているわけではありません。
key
実際に使用されているインデックス。ここに希望のインデックスがあるかどうか確認します。もちろんpossible_keysの中から選ばれます。ここでは、使われたインデックスがpriceであることがわかります。
rows
そのテーブルから参照される行数の大まかな見積もり。これがインデックスを貼った時に減っていればインデックスが効いていることになります。
だいたいこの辺の項目を見ておけばインデックスが効いているかがわかります。
インデックスってなんで早くなるの?
早くなるからただ使っているっていうのは、なんだか気持ち悪いので色々仕組みを調べてみました。
インデックスを貼ると、検索用に最適化されたデータベースが生成されるそうで、それを参照することで処理するレコード数を効率的に減らしているらしいです。
検索用のデータベースってなんぞやってのを理解するためには、データ構造のひとつでMySQLが採用しているB+tree構造(びーぷらすつりーこうぞう)について理解する必要があります。
ですが、やや複雑ですのでよりシンプルなB-tree構造について先に説明します。
B-tree構造
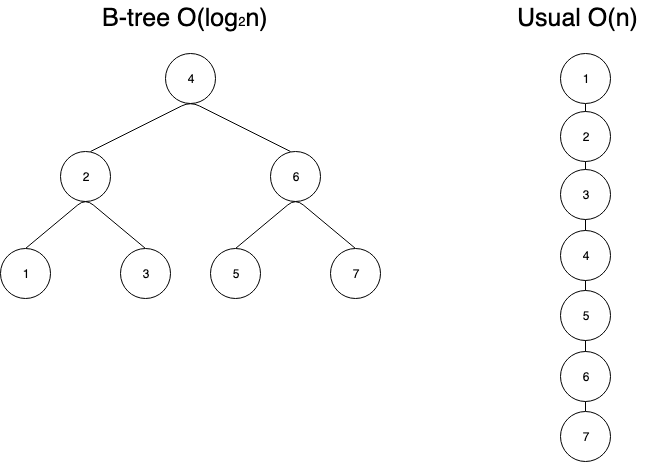
一種のデータ構造のことで、下図のとおり二分探索しやすいように値を大小で振り分けたデータ構造のことを言います。MySQLでインデックスを貼る時に生成されるデータベースはこの構造になっています。
上図右側
インデックスを貼ってない普通のデータ構造です。先頭から順に計算していくため、ある一つのデータを抽出するためには最大7回の計算をしなければならないことになりますね。
上図左側
対してB-treeは、ターゲットが中央値より大きいか小さいかで分岐させ、それを繰り返す二分探索をするため計算は最大3回で済みます。
このデータ構造の仕組みにより、検索を高速化できます。
この**O(n)**ってやつのOはOrderで計算量を表します、()内のnはレコード数になります。インデックスを使うことで計算量は対数関数的に減っていきますよって感覚がわかりますね。テーブルが大きくなれば受ける恩恵は大きいってことです。
カテゴリー検索例
簡単な例を作ってみた。
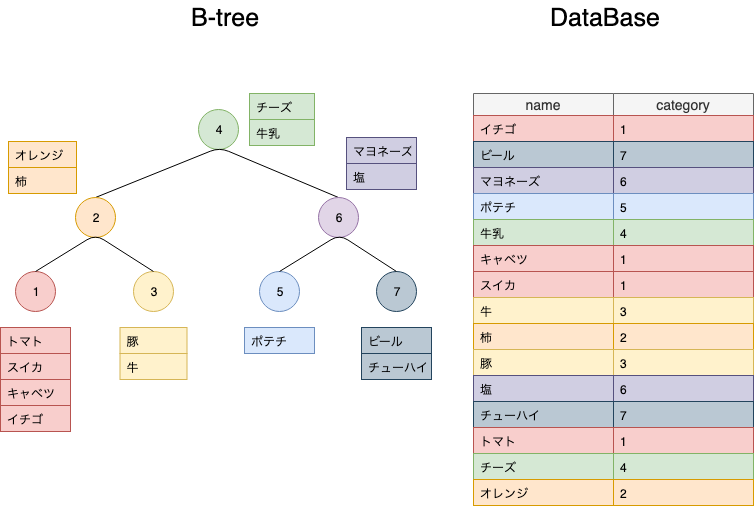
インデックスが貼られた時、検索時に使用するデータを新たに生成します。それが上図右側のB-tree構造のデータです。
検索をかけた時には、検索用のB-tree構造のインデックスデータにアクセスし、該当するレコードだけを引っ張り出します。
例えば、category'2'を抽出したい時、普通であれば全レコード総数と等しい15回の計算を行わなければなりません。しかしインデックスを貼った場合には、2回の計算で済むため効率的に目的のレコードを参照できることがわかります。
補足
以上の例では7種類の値をもつカテゴリーカラムに対してインデックスを使用する場合を例にあげました。B-tree構造を簡潔にしたいがためにそのような例にしましたが、実際にこのような貼り方は好ましくありません。詳しくは" カーディナリティの高いものから貼っていく "に記載しています。
実際のMySQLはB+tree構造を採用している
名前が似ていてややこしいですがB+tree(びーぷらすつりー)について説明します。実は、MySQLはこっちの構造を採用しています。B-treeと似ているようで若干構造が異なります。
とはいっても先ほどのB-tree構造を理解してしまえば簡単です。以下はB-treeとB+treeの構造を比較したものです。
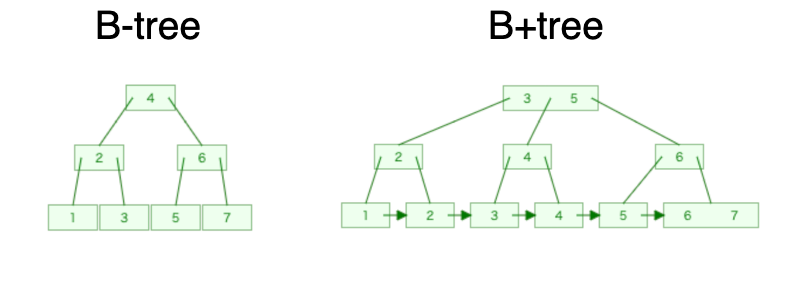
今までに説明したB-treeは一番下の段(リーフノード)だけではなく一段目(ルートノード)、二段目(子ノード)にもデータを持たせており、探索時、上流でヒットすればそれだけ早く計算が終了するという特徴があります。
それに対してB+treeでは、リーフノードに全ての情報を持たせており、かつそのそれぞれを繋げています。上流にはデータを持たせていません、あくまで計算して分岐させるだけです。
何が利点かというと、範囲検索に強いことです。例えば3〜5の検索をした時、3までたどり着けばそのまま横にずれて4と5の条件も拾っていけます。B-treeだと範囲検索時はいちいち上流から計算し直さなければなりません。これがB+treeの利点です。
インデックスを貼るときの注意点
インデックスをむやみに貼らない
じゃあインデックスとりあえず全部貼っておくか!!ってなりそうだけどそうはいきません。
B-treeを生成するデメリット
- データ容量を圧迫する
- データ挿入時、更新時に処理が重くなる
これらは検索用のデータを新たに生成する事による弊害です。
データを増やすことが容量を圧迫することになるのは容易に想像できますね。
また、データ挿入や更新時には他の全てのインデックス用データベースも更新しなければなりません。インデックスを1個しか使わなくていいものを10個貼ったのなら、9個分のデータベースを余計に更新することになります。このことにより処理が重くなります。
ではどのようにインデックスを貼っていけば効率的なのでしょうか。
原則はカーディナリティが高いものに貼っていく
カーディナリティは多重度とか、選択度という意味があります。好みですが、選択度の方が理解しやすい気がします。
これはどういうことかというと、カラム内の値の種類が2種類しかない時、例えば男女で分ける場合には絞り込み度は50%となります。50%というのはカーディナリティがかなり低い部類に入ります。これはインデックスを貼ってもあまり効果が見込めません。
対して500万レコードの顧客情報に苗字カラムがあったとして、その種類が5千種類だとすると、インデックスを貼った場合の絞り込み度は0.02%になります。これはカーディナリティの高い状態であり、インデックス使用時の効果が高くなります。
ですので、原則インデックスはカーディナリティの高いものに貼っていくべきで、低いものに貼る場合にはしっかり効果を確認して判断する必要があります。(低いものでも効果が見込める場合があるため)
インデックスが適用されない場合もある
他にも、インデックスを貼ったはずなのに効いてないよーーーって時もあるので注意が必要です。
以下のような時にはインデックスは適用されません。
- LIKEが%で始まる場合
- DB全体を読んだ方が早いとMySQLが判断した場合(レコードが全体の30%を超える場合や、1000件未満の場合など)
- ORDER BYを使用している場合
他にも色々あるので調べてみてください!
とりあえず効いてるかはEXPLAINで必ず確認しておくといいと思います。
おわりに
インデックスとかB-treeデータ構造とか初心者なりに調べて偉そうに語ってみました。
何か指摘等ありましたらコメントお願いします![]()
参考
8.3.1 MySQL のインデックスの使用の仕組み
MySQLでインデックスを貼る時に読みたいページまとめ(初心者向け)
B-treeインデックス入門
「複業クラウド」について
弊社Another worksでは複業マッチングプラットフォーム「複業クラウド」を開発しています!
▼複業でスキルを活かしてみませんか?複業クラウドの登録はこちら!
https://talent.aw-anotherworks.com/?login_type=none