はじめに
こんにちは、ひよこです。ところで皆さんは行列はお好きでしょうか。昔は高校数学で学んだ行列ですが、今はカリキュラム変更で大学になって初めて触れる方も多いようです。ところがこの行列、ニューラルネットワークや LLM との関連が非常に深い存在です。行列を知らないと深層学習や LLM の理論的な論文を理解するのは難しくなります。また、ある程度行列を知っている方でも、行列分解が出てくると少し尻込みしてしまうこともあるかもしれません。
そこで今回は、論文読みサポート企画として初心者でも行列分解の概要をつかめるよう、できるだけ優しくまとめてみたいと思います。
🐣 Matrix の訳が行列ってどうしてもしっくりこないんですよね
行列本当の初歩の初歩
ここでは、行列自体が「怪しい」「忘れた」という方のために、基礎を簡単に振り返ります。
そもそも行列って何?
まず、整数や実数など、一つだけで意味を持つ値を スカラー と呼びます。そのスカラーを 2 個セットにした表現が ベクトル です。たとえば ((x,y)) などが典型です。そして、このベクトルを複数並べて格子状にしたものが 行列 (matrix) です。ベクトルが線状に並んだ数字の集合なら、行列は縦横に並んだ数字の表と言えます。特に、縦と横の要素数が同じものを 正方行列 と呼びます。
行列をさらに積み重ねると、より高次元の配列が得られます。これを テンソル と呼び、縦や横に並んでいる数の個数を 次元、方向が何個あるかを 階 で表します。実は、スカラーは 0 階テンソル、ベクトルは 1 階テンソル、行列は 2 階テンソルと考えることができます。
なんのために使う?
行列は、ベクトルや他の行列に「作用」して新しいベクトルや行列を生成します。たとえば、ニューラルネットワークでは、入力ベクトルに重み行列を掛けて新たな特徴ベクトルを作り出します。深層学習は、入力ベクトルと行列をうまく掛けて、識別や生成に役立つ表現を得る仕組みとも言えます。
行列式
行列式は、正方行列が「どれだけ空間を伸び縮みさせるか[^1]」を示す尺度です。たとえば、2 次元の正方行列で行列式が 2 なら、その行列は単位正方形を面積 2 の平行四辺形に変形します。行列式が 0 の場合は、空間が「押しつぶされて」しまい、元の次元を保てません。以下の固有値や固有ベクトルなどと同様に、行列式は行列の本質的な性質を知るうえで重要な手がかりとなります。
🐣 この変換に平行移動が加わるとアフィン変換ですね 🧁
🐣note:2次行列における行列式の幾何学的意味
例 1: 単位行列
行列:
A =
\begin{pmatrix} 1 & 0 \\
0 & 1
\end{pmatrix}
行列式: $\det(A) = (1)(1) - (0)(0) = 1$
解釈: 単位行列は空間に何の変化も与えません。単位正方形の面積がそのまま保たれることを意味します。
例 2: 拡大する行列
行列:
B =
\begin{pmatrix}
2 & 0 \\
0 & 2
\end{pmatrix}
行列式:$\det(B) = (2)(2) - (0)(0) = 4$
解釈: 単位正方形が2倍に拡大され、面積が1から4に変わります。
例 3: せん断する行列
行列:
C = \begin{pmatrix}
1 & 1 \\
0 & 1
\end{pmatrix}
行列式:$\det(C) = (1)(1) - (1)(0) = 1$
解釈: 単位正方形を平行四辺形に変形しますが、面積は変化しません(行列式が1)。
例 4: 押しつぶす行列
行列:
D = \begin{pmatrix}
1 & 1 \\
1 & 1
\end{pmatrix}
行列式:$\det(D) = (1)(1) - (1)(1) = 0$
解釈: 単位正方形が線分に押しつぶされ、面積が0になります。このような行列は逆行列を持ちません。
例 5: 回転行列
行列:
E = \begin{pmatrix}
\cos\theta & -\sin\theta \\
\sin\theta & \cos\theta
\end{pmatrix}
行列式:$\det(E) = (\cos\theta)(\cos\theta) - (-\sin\theta)(\sin\theta) = \cos^2\theta + \sin^2\theta = 1$
解釈: 回転行列は単位正方形を回転させますが、面積はそのまま保たれます(行列式が1)。
逆行列
ある行列に別の行列をかけて単位行列(対角に1が並び他が 0 の行列)になるとき、その行列を「逆行列」と呼びます。ちょうど実数における逆数みたいなものですね。逆行列が存在する行列は「正則行列」と呼ばれ、行列式が 0 でない正方行列がこれにあたります。逆に、行列式が 0 の場合は逆行列は存在しません。これは 0 の逆数がないことに相当します。
固有値と固有ベクトル
一般に、ベクトルに行列を掛けると向きも大きさも変わります。しかし、行列によっては「この方向のベクトルなら、向きは変わらない」という特別なベクトルが存在します。これを 固有ベクトル と呼び、そのときの長さの倍率が 固有値 です。固有ベクトルと固有値は、行列の本質的な特徴を示す重要な手がかりで、ニューラルネットワークや次元削減(PCA など)の場面で重宝されます。
🐣 人を知るときも、ブレない「軸」が何かを知るのは大切ですよね
行列の掛け算
「行列の掛け算」と聞くと、「行と列を掛けて足す」という操作を思い出す方が多いでしょう。ただし、深層学習ではいくつか異なる積が使われます。
- 行列積: 最も一般的な掛け算。行列 $A$ と $B$ の行列積 $C$ は、$C_{ij} = \sum_k A_{ik}B_{kj}$ で計算します。ニューラルネットワークの基本処理です。$AB$ と書かれていればまずこの行列積のことです。
- アダマール積: $C_{ij}=A_{ij}B_{ij}$ のように対応する要素同士を直接掛け合わせます。「行列の掛け算」といわれて最初に思い浮かぶ方法ですね。CNN の畳み込み演算の途中でフィルターを画像に作用させるときに登場します。
- 直積(テンソル積): ベクトルや行列を使って、より高次元の行列やテンソルを作る方法です。$\vec{u}\otimes\vec{v}$ は要素 $u_i v_j$ で構成され、高次元データ解析や量子力学で用いられます。
この他にもさまざまな行列の積がありますが、ここでは代表的な 3 種類を挙げておきます。「積は一種類ではない」ことだけでも覚えておいてください。
名前付きの行列
初心者向けに、特殊な名前がついた行列を簡単に紹介します(詳細な数式は割愛します)。
- 上三角行列・下三角行列: ある方向より上または下側がすべて 0 になっている行列です。計算が簡単になるため、分解でよく登場します。
- 直交行列: 「回転」のような変換を表し、転置を取ると逆行列になる特殊な行列です。
- 交代行列: 転置するとマイナスが付くような行列で、物理や幾何で特別な意味を持ちます。
🐣 行列の要素が複素数になるとユニタリー行列やエルミート行列なんかに進化します
行列分解いろいろ:基礎から応用まで
行列分解は、連立方程式解法、数値解析、機械学習、そして LLM(大規模言語モデル) におけるモデル内部計算の効率化まで、多岐にわたる応用分野で用いられています。ここでは、正方行列に特化した手法から、非正方行列にも対応可能な手法まで、代表的な分解手法をご紹介します。まずは行と列の数が等しい正方行列に関する分解を紹介します。
LU 分解
行列を「下」と「上」にきれいに分解する、解法の定番です。
LU 分解は、正方行列 $A$ を下三角行列 $L$ と上三角行列 $U$ に分解します。
$A x = b$ を
- $L y = b$(前進代入)
- $U x = y$(後退代入)
で解くことで、計算が効率化されます。
- 何に使う?:科学技術計算や物理シミュレーションでの連立方程式高速解法、LLM 内部での行列演算処理最適化。
- 対象とする行列:基本的には正方行列対象
- 難易度:初級~中級
🐣 0 が多いから計算がしやすいって感じですね
大学一年生のとき手で計算したのが思い出されます。
🐣note:こんな感じの見た目
\begin{bmatrix}
2 & 3 & 1 \\
4 & 7 & 7 \\
6 & 18 & 22
\end{bmatrix}
=
\begin{bmatrix}
1 & 0 & 0 \\
2 & 1 & 0 \\
3 & 9 & 1
\end{bmatrix}
\cdot
\begin{bmatrix}
2 & 3 & 1 \\
0 & 1 & 5 \\
0 & 0 & 4
\end{bmatrix}
LDLT 分解
対称性をうまく利用した「かしこい」分解です。
LDLT 分解は、対称な正方行列 $A$ に対して
$$
A = L D L^T
$$
と分解する手法です。$D$ は対角行列、$L$ は下三角行列で、対称性を活用し、LU分解に比べて数値的な安定性が得られる場合があります。
- 何のために?:対称行列を効率的かつ安定的に分解
- 何に使う?:物理シミュレーションや最適化問題での対称行列解法、LLM トレーニング時の共分散行列への適用
- 対象とする行列:対称な正方行列に限定
- 難易度:中程度
🐣note:こんな感じの見た目
\begin{bmatrix}
6 & 3 & 4 \\
3 & 5 & 2 \\
4 & 2 & 7
\end{bmatrix}
=
\begin{bmatrix}
1 & 0 & 0 \\
0.5 & 1 & 0 \\
0.666\ldots & 0 & 1
\end{bmatrix}
\cdot
\begin{bmatrix}
6 & 0 & 0 \\
0 & 3.5 & 0 \\
0 & 0 & 4.333\ldots
\end{bmatrix}
\cdot
\begin{bmatrix}
1 & 0.5 & 0.666\ldots \\
0 & 1 & 0 \\
0 & 0 & 1
\end{bmatrix}
固有値分解
固有値は行列の「個性」を示す一番基本的な能力値です。
固有値分解では、正方行列 $A$ を
$$
A = P \Lambda P^{-1}
$$
とし、$\Lambda$ に固有値、$P$ に固有ベクトルを並べます。行列の安定性や特性を把握するうえで不可欠な手法です。
- 何に使う?:システム安定性解析、スペクトル解析、LLM の行列特性解析
- 対象とする行列:正方行列対象
- 難易度:中級~上級
🐣note:こんな感じの見た目
\begin{bmatrix}
6 & 2 & 1 \\
2 & 3 & 1 \\
1 & 1 & 1
\end{bmatrix}
=
\begin{bmatrix}
1 & -1 & 1 \\
1 & 2 & -1 \\
1 & 0 & 1
\end{bmatrix}
\cdot
\begin{bmatrix}
6 & 0 & 0 \\
0 & 3 & 0 \\
0 & 0 & 1
\end{bmatrix}
\cdot
\begin{bmatrix}
1 & -1 & 1 \\
1 & 2 & -1 \\
1 & 0 & 1
\end{bmatrix}^{-1}
\text{固有値 } \lambda = 6: \text{ 固有ベクトルは }
v_1 =
\begin{bmatrix}
1 \\
1 \\
1
\end{bmatrix}
\text{固有値 } \lambda = 3: \text{ 固有ベクトルは }
v_2 =
\begin{bmatrix}
-1 \\
2 \\
0
\end{bmatrix}
\text{固有値 } \lambda = 1: \text{ 固有ベクトルは }
v_3 =
\begin{bmatrix}
1 \\
-1 \\
1
\end{bmatrix}
補足: 対角化可能性
すべての行列が対角化できるわけではなく、その場合は固有値分解はできません。対角化できない行列に対しては、上位種であり任意の正方行列に対して適用可能なジョルダンの標準形とジョルダン分解を使うことになります。
コレスキー分解
正定値対称行列を下三角行列へと「綺麗に因数分解」する分解法です。
コレスキー分解では,正定値対称行列 $A$ を
$$A = L L^T$$
と分解します。ここで $L$ は対角要素が正の下三角行列です。
この分解によって $A x = b$ を
- $L y = b$(前進代入)
- $L^T x = y$(後退代入)
で解けるため,正定値行列を扱う最適化問題や巨大システムの解法を効率化できます。LLM のトレーニングや最適化問題の裏で計算コストを抑えるために適用されることもあります。
- 何に使う?:正定値行列を用いた連立方程式解法の高速化、最適化問題での内部計算
- 対象とする行列:正定値対称行列
- 難易度:中級
🐣note:こんな感じの見た目
\begin{bmatrix}
4 & 2 \\
2 & 2
\end{bmatrix}
=
\begin{bmatrix}
2 & 0 \\[6pt]
1 & 1
\end{bmatrix}
\cdot
\begin{bmatrix}
2 & 1 \\[6pt]
0 & 1
\end{bmatrix}^T
ここからは正方行列でなくても利用できる分解手法を紹介します。ニューラルネットワークの各層間での重み行列は、それぞれの層に含まれるノード数が一致していない場合、正方行列にはなりません。このような非正方行列にも適用可能な手法は、特に深層学習と非常に相性が良いといえます。
QR 分解
回転 ($Q$) と拡大縮小 ($R$) で行列を「整える」、幾何的センスあふれる分解です。
QR 分解では、任意の行列 $A$ (正方・非正方問わず) を直交行列 $Q$ と上三角行列 $R$ に分解します。
$A x \approx b$ の最小二乗解を求める際、$A = Q R$ とすることで、$R x = Q^T b$ と簡略化でき、過剰決定系を解きやすくなります。
- 何に使う?:データフィッティング(最小二乗解)、LLM での次元削減や特徴抽出一部工程
- 対象とする行列:任意の行列
- 難易度:中級
🐣note:こんな感じの見た目
\begin{bmatrix}
1 & 2 \\
2 & 3 \\
4 & 5
\end{bmatrix}
=
\begin{bmatrix}
\frac{1}{\sqrt{21}} & -\frac{2}{\sqrt{78}} \\
\frac{2}{\sqrt{21}} & \frac{5}{\sqrt{78}} \\
\frac{4}{\sqrt{21}} & -\frac{7}{\sqrt{78}}
\end{bmatrix}
\cdot
\begin{bmatrix}
\sqrt{21} & \frac{28}{\sqrt{21}} \\
0 & \frac{\sqrt{78}}{21}
\end{bmatrix}
特異値分解 (SVD)
任意形状の行列を「バラして」本質的な特異値で情報を切り分ける、万能ツールです。
SVD (Singular Value Decomposition) は、任意の行列 $A$ を
$$
A = U \Sigma V^T
$$
と分解し、$U$、$V$ は直交行列、$\Sigma$ は特異値を並べた対角行列です。特異値は行列の情報重要度を示し、次元削減やデータ圧縮に最適です。
- 何に使う?:次元削減(PCA の基盤)、画像圧縮、LLM の文脈表現圧縮
- 対象とする行列:任意の行列
- 難易度:中級~上級
🐣note:こんな感じの見た目
\begin{bmatrix}
1 & 2 \\
3 & 4
\end{bmatrix}
=
\begin{bmatrix}
\frac{1}{\sqrt{10}} & -\frac{3}{\sqrt{10}} \\
\frac{3}{\sqrt{10}} & \frac{1}{\sqrt{10}}
\end{bmatrix}
\cdot
\begin{bmatrix}
5 & 0 \\
0 & 1
\end{bmatrix}
\cdot
\begin{bmatrix}
\frac{2}{\sqrt{5}} & -\frac{1}{\sqrt{5}} \\
\frac{1}{\sqrt{5}} & \frac{2}{\sqrt{5}}
\end{bmatrix}^T
補足: 固有値と特異値
実数値対称行列なら固有値の絶対値=特異値になるなどお互いに深い関係にある概念です。ただし、一般の正方行列の場合、固有値と特異値は関係はしているもののもう少し複雑です。また、固有値は複素数になることもありますが、特異値は必ず非負の実数となるという違いがあります。
🐣レコメンドでも用いられているね。
一般化逆行列
最後に分解ではありませんが、非正方行列でも行列式が 0 でも無理やり逆行列っぽいものを定義できる 一般化逆行列 (Moore-Penrose 逆行列) を紹介します。
答えがスッキリ決まらないときに頼れる調整役的な存在です。解が存在しない場合や無数にある場合に、最も妥当な解を与えることができ、特に SVD を用いた計算法が有名です。
- 何に使う?:LLM の最適化で非正則な勾配行列処理、機械学習での冗長特徴量削減
- 対象とする行列:任意の行列
- 難易度:中級
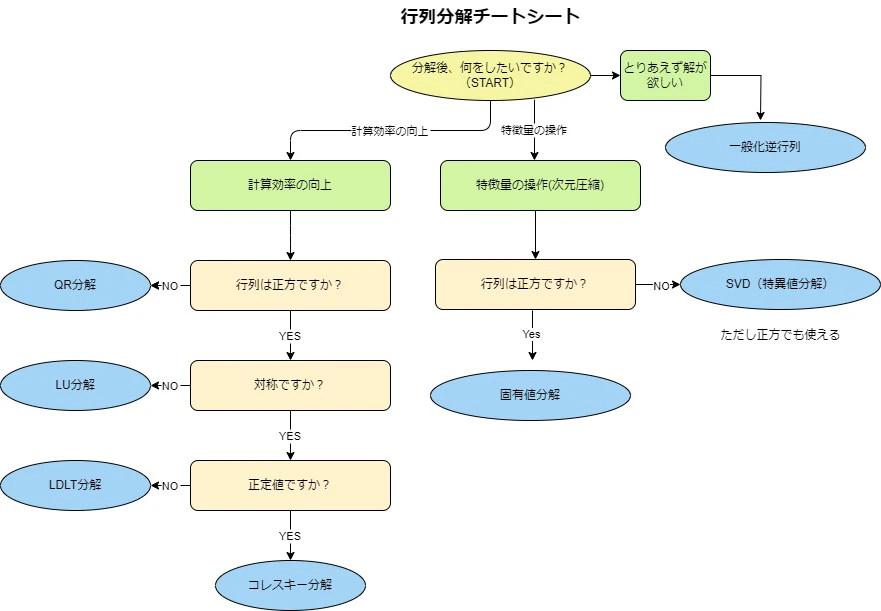
結局、分解後何をするの?
行列分解はあくまで「手段」であり、分解後に何をしたいかによって利用シナリオが変わります。ここでは、分解結果を用いた主な使い方を簡潔に 3 つに分類して示します。
計算効率の向上
行列分解は,巨大な行列演算の高速化や,反復的な線形代数計算の効率改善に使われます。
例えば LU 分解を用いた方程式系の反復解法や,QR 分解による安定した最小二乗近似は,計算コストを抑える意義が大きい分野です。
特徴量の操作
分解により得た固有値や特異値を基に,次元削減や特徴抽出を実施します。
PCA(主成分分析)や SVD による次元削減は代表例で,膨大な変数を持つデータから本質的な情報軸を抽出する際に有効です。
その他
分解を通じてノイズ除去,特徴強調,適度な正則化などを実施できる場合があります。
非正則な行列への一般化逆行列適用や,非負値行列分解(NMF)を用いたパーツベース表現は,視覚情報処理やクラスタリングなどで多用されます。
ライブラリ内での使用例
以下では、実際に PyTorch や scikit-learn で行列分解が用いられる部分の一例を示します。参考文献として公式ドキュメントへのリンクも記します。
1. 固有値分解
PyTorch の torch.linalg.eig は行列の固有値分解を行う関数です。
(参照: PyTorch公式ドキュメント)
import torch
# ランダムな正方行列を生成
A = torch.randn(3, 3)
# 固有値分解の実行
w, v = torch.linalg.eig(A)
# w に固有値, v に固有ベクトルが列方向に格納される
# A = v @ torch.diag(w) @ v⁻¹ として表現できる(A が対角化可能な場合)
上記のように w と v に分解することで,行列 A の固有特性を解析することができます。
2. PyTorch における SVD の使用例
PyTorch の torch.linalg.svd は特異値分解を行う関数です。
(参照: PyTorch公式ドキュメント)
import torch
# ランダムな行列を生成
A = torch.randn(5, 3)
# SVD の実行
U, S, Vh = torch.linalg.svd(A)
# A = U @ torch.diag(S) @ Vh と分解される
# U, Vh は直交行列,S は特異値を集めた対角成分を持つ
上記のように,U, S, Vh に分解することで行列 A の性質を解析したり,特徴量の圧縮などを行う際に活用できます。
3. PyTorch における QR 分解の使用例
PyTorch の torch.linalg.qr を用いると,行列を直交行列 Q と上三角行列 R に分解できます。
(参照: PyTorch公式ドキュメント)
import torch
A = torch.randn(4, 3)
# QR分解
Q, R = torch.linalg.qr(A)
# A = Q @ R と表せる
# Qは直交行列,Rは上三角行列
この分解は最小二乗近似や,重み行列の再正規化など,数値線形代数上のさまざまな場面で用いられます。
4. scikit-learn における PCA (SVDを内部で使用)
scikit-learn の PCA (主成分分析) は,内部的に SVD を用いてデータ行列を特異値分解しています。この手法によりデータ次元を削減し,説明変数の主要な軸を抽出します。
(参照: scikit-learn公式ドキュメント:PCA)
from sklearn.decomposition import PCA
import numpy as np
# データ行列 X (サンプル数n×特徴数d)
X = np.random.rand(100, 20)
# PCA の適用(デフォルトでSVDによる分解を内部的に実行)
pca = PCA(n_components=5)
X_reduced = pca.fit_transform(X)
# X_reduced は主要な特異値や固有ベクトルに基づく次元削減後の特徴量
PCA は特異値分解を通じて,データ内の分散が最大になる方向(固有ベクトルに相当)とその強さ(特異値に相当)を見つけ,低次元でのデータ再表現を実現します。
おまけ
虚数の基本的な性質として、$i^2 = -1$ がありますが、実は行列だと実数の範囲でも同じような性質が現れることがあります。
単位行列 $I$ は、次のように対角成分がすべて 1 で、他の成分が 0 の正方行列です。任意の行列 $X$ に対して $IX=XI=X$ が成立するため掛け算における 1 に相当する行列です。以下が 2 次の単位行列です。
I = \begin{pmatrix} 1 & 0 \\ 0 & 1 \end{pmatrix}
ここで、次の 2 次正方行列 $A$ とします。
A = \begin{pmatrix} 0 & -1 \\ 1 & 0 \end{pmatrix}
この行列 $A$ を二乗してみましょう:
A^2 = \begin{pmatrix} 0 & -1 \\ 1 & 0 \end{pmatrix} \begin{pmatrix} 0 & -1 \\ 1 & 0 \end{pmatrix}
行列の掛け算を実行すると、
A^2 = \begin{pmatrix} (0 \cdot 0 + -1 \cdot 1) & (0 \cdot -1 + -1 \cdot 0) \\ (1 \cdot 0 + 0 \cdot 1) & (1 \cdot -1 + 0 \cdot 0) \end{pmatrix}
= \begin{pmatrix} -1 & 0 \\ 0 & -1 \end{pmatrix}
この結果は、単位行列 $I$ の負の形 $-I$ です。したがって、この $A$ は $A^2 = -I$ を満たします。
このように行列の世界では、虚数的な存在がちゃんと実在しているのです。
🐣 行列って、虚数みたいな不思議な性質があるんだね!
おまけ 2
おわりに
今回は、LU 分解、QR 分解、特異値分解、固有値分解、そして一般化逆行列について、初心者向けに概要と目的、LLM との関連性に触れました。行列分解は、データ解析やモデル構築の基盤であり、行列を「分解」してみると、その背後に潜む構造が見えてきます。
ではまた次の記事でお会いしましょう。