01.はじめに
隠れエンジニアのひよっこです。仕事はザ・事務職なので、プログラミングは一切使いません。
ただ勤務先にメディア事業があるため、「AIを開発すれば使えるのでは」と考えました。そして今年3月にPythonの学習を始めました。
実はこれまでも、何度もPythonの本を読んでは途中で挫折していました。具体的な目的がないと、独学はまず無理でした。大変な割に成果が見えず、全くモチベーションが保てませんでした。そもそも頭に入ってきません。
そこで「今度こそ」との思いから、今回は意を決してオンラインスクール「アイデミー」さんでAI開発コースを6ヶ月コースで受講することに。最終的に、AIが、記事の見出し候補を自動でつけるアプリを作りました。この記事はその成果をまとめたものです。なんせ初心者なので、間違い等が多々ある可能性があります。疑問点などはぜひお寄せ下さい。
02.概要
この記事は以下の人に役立つと思います。
1.これからPythonを学ぶ人…Pythonの学習が、どんなAIに結びつくかが具体的に分かる
2.メディア関連の人…メディアの運営にどうAIを活用するかの参考に
3.AIを試したい人…無料、短期間で独自AIアプリの作成方法が分かる
また、私の挑戦内容は以下の通りです。
1.ライブドアのニュースコーパスで、GPT-2をファインチューニング
2.ジャンルと記事を入力すると、記事に沿った見出しを提案するプログラムを作成
3.Streamlitを使い、プログラムをWebアプリとしてネット上で利用可能に
以降、取り組んだ内容を具体的に解説します。
1.ライブドアのニュースコーパスで、GPT-2をファインチューニング
「GPT-2」は、最近爆発的に普及しているChat GPTに代表される、人間に近い流暢な会話が可能なAI「大規模言語モデル」(Large Language Model)です。人間が話すのと同じ自然言語を使って、様々な処理を高いレベルで行うことができます。
今回使ったGPT-2は、Chat GPTを開発したOpen AIが2019年に公開したモデルで、同社の最新モデルGPT-4から3世代前にあたります。性能はGPT-4には及びませんが、十分に流暢な日本語を扱うことができます。メモリー使用量が少なく、初心者が気軽に挑戦しやすいのも特徴です。また、無料で使える上、利用者が独自にカスタマイズ可能なオープンソースである点も大きなメリットです。なおこの記事では、Chat GPT自体は扱いません。
ここからは具体的な作り方を説明します。
まず初めに、ライブドアニュースで10年以上前に掲載された7000本以上の記事をまとめたフリーのデータセット「ニュースコーパス」を使い、記事(問題データ)と、実際につけられた見出し(正解データ)のペアでGPT-2を訓練(ファインチューニング)します。「本文がこの内容なら、この見出しをつけるのが正解」と記憶させるわけです。
2.ジャンルと記事を入力すると、記事をふまえた見出しを20個提案するプログラムを作成
新聞などの見出しを考える際、政治や経済、スポーツなどジャンルによって扱う記事や見出しがだいぶ変わります。「ライブドア ニュースコーパス」でも、9つのジャンルがあり、実際に文面、見出しとも個性があります。そこで、見出しをつけてほしい記事のジャンルを指定し、本文を入力すると、それに合わせた見出し案を出すようにプログラムを作ります。
見出し案はとりあえず20個にしていますが、増減は自由自在です。また見出し内容も、記事に厳密にしたり、オリジナリティあふれるようにしたりと、自作プログラムなので色々と変更できます。
3.Streamlitを使い、プログラムをWebアプリとしてネット上で利用可能に
見出しを自動でつけるプログラムを開発しても、自分以外も使えないと意味がありません。Webアプリとして公開する方法は色々ありますが、今回はstreamlitというサービスを使いました。これは複雑なプログラムや設定が不要で、簡単にWebアプリを公開できるものです。一般消費者向けのサービスでは向きませんが、例えば社内でのデモやプレゼンテーションなど、プロトタイプを公開するのに最適です。
次からは具体的な制作に入ります。
03.環境構築
まずPythonを使える環境を整備します。初心者には、Googleのアカウントがあればすぐに使えるGoogle Colaboratoryが最適です。自分のパソコンにPythonをインストールすることもできますが、バージョン問題などもあり、結構手間がかかります。機械学習に必須の高性能GPUも、無料利用できます。そのまま使うと毎回データが削除され、初期化されてしまうのが難点ですが、データをGoogleドライブに保存すれば大丈夫です。
04.目標
Google Colaboratoryが使えるようになったら、早速コードを書きます。が、最初は当然ですが「何をどうやって書けば?」となると思います。
まずは「何をしたいか」という目標をはっきりさせ、そのためにどんなライブラリを使うかを検索して調べるのが一番大事です。そもそも、そこが難しいのですが。
正直言って、私のような初心者がちょっとPythonを勉強した所で、簡単にはプログラミングはできませんでした。アイデミーさんで、「Python基礎」は4周くらい受けていますが、未だにマスターできていません。
Pythonには絶対の正解はありません。ゴールが達成できればよく、その過程は様々です。試行錯誤しかないのです。これがオンラインスクールで学んだ一番大きなポイントかもしれません。
05.写経
目的が決まれば、まずは先人のやったことを学び、コードを再現(写経)しましょう。
なぜ写経かと言うと、何もない状態からプログラミングするのはものすごく難しく、あっという間にプログラミングの樹海に迷い込んでしまうからです。特に仕事があり、本業でプログラミングを扱わない人にとっては、どれだけ時間があっても足りません。
私が今回のAIアプリを作る時に参考にしたのは、以下のブログです。まずは写経から始め、試行錯誤して改良することにしました。様々なプログラムを公開してくれている皆様に感謝!
m__kさんの記事は私にとってコンパスのような存在でした(というか基本はほぼ写経)。基本的な構造はほとんど同じで、あとは実用化できるように精度を上げていく予定です。
npakaさんは、新しいLLMなどを積極的に試して発信しており、私のようなAI初学者には「神」のごとき存在です。
つくもちさんも、技術的な解説が非常に分かりやすく、Chat GPTに使われている自然言語処理を一から学びたいなら、非常に勉強になります。
streamlitについては、様々なページを見ましたが、一番最初に見たAidemy Tech Blogを紹介しておきます。これは写経するだけで、本当に簡単なWebアプリが作れます。
06.ニュースコーパスの加工
まずはGoogle Colaboratoryのデータを保存できるよう、Google driveをマウントします。
from google.colab import drive
drive.mount('/content/drive')
次に、ファインチューニングに必要な、ライブドアのニュースコーパスをダウンロードし、展開します。
!wget https://www.rondhuit.com/download/ldcc-20140209.tar.gz
!tar zxvf ldcc-20140209.tar.gz
googleドライブの直下にtextフォルダが作成され、中にニュースのジャンル別に9個のディレクトリが含まれています。各ディレクトリ中に一つ一つの記事がテキストファイルで保存されており、記事は合計7367本です。

ネット上では割と簡単に「ニュースコーパスを使いましょう」と書いてあることが多いのですが、初心者にはかなり難しかったです。その中では、このYUTAROさんのブログは非常に分かりやすいです。
そしてYUTAROさんの続きのページに従って、ファインチューニングに使えるようにデータを加工します。
import pandas as pd
import pathlib
#pandasで列名を指定します。順にカテゴリー、url、時間、見出し、本文です。
df = pd.DataFrame(columns=["category", "url", "time", "title", "text"])
#pathlibでデータを取り出します。
for file_path in pathlib.Path("./text").glob("**/*.txt"):
f_path = pathlib.Path(file_path)
file_name = f_path.name
category_name = f_path.parent.name
# 記事以外の特殊ファイルはスキップします。
if file_name in ["CHANGES.txt", "README.txt", "LICENSE.txt"]:
continue
with open(file_path, "r") as f:
text_all = f.read()
text_lines = text_all.split("\n")
url, time, title, *article = text_lines
article = "\n".join(article)
df.loc[file_name] = [category_name, url, time, title, article]
# インデックスに使用していたファイル名を列の1つにします。
df.reset_index(inplace=True)
df.rename(columns={"index": "filename"}, inplace=True)
# ファイルに保存します。
df.to_csv("drive/MyDrive/Colab Notebooks/livedoor_news_corpus.csv", encoding="utf-8_sig", index=None)
Google Colaboratoryを使ったプログラムは、ファイルの保存先が相対パスで書かれていることが多いのですが、写経してもなぜか失敗が頻発しました。そこで、フォルダ構造を完全に入れる絶対パスにすると、うまく行くようになりました。今回は「livedoor_news_corpus.csv」というファイル名で保存されています。
07.トレーニングデータの作成
ライブドアのニュースコーパスは無事ダウンロードできましたが、この形では使えません。そこで次は、GPT-2を使ってトレーニングできるようにデータを処理し、ファインチューニングに進みます。
この部分は、冒頭で紹介したm_kさんの、ほぼ写経です。トレーニングデータの作成まで一気に載せました。中身についてはコメントを参考にして下さい。実行前に、Googled driveで「Colab Notebooks」フォルダの下に、「GPT-2」フォルダを作っておく必要があります。
ファインチューニングまでに必要なライブラリは以下の通りです。
# ファインチューニングの実行
# ソースコードから直接transformersをインストール
!pip install git+https://github.com/huggingface/transformers
# rinna/japanese-gpt2-mediumのtokenizerはsentencepieceなのでsentencepieceもインストールする必要があります。
!pip install sentencepiece
!pip install datasets
!git clone https://github.com/huggingface/transformers
# run_clm.pyを使います
!ls ./transformers/examples/pytorch/language-modeling/
# README.md run_clm_no_trainer.py run_mlm_no_trainer.py run_plm.py
# requirements.txt run_clm.py run_mlm.py
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt2-medium")
tokenizer.do_lower_case = True # due to some bug of tokenizer config loading
model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt2-medium")
import pandas as pd
import os
from tqdm import tqdm
!pip install -qqq evaluate
import evaluate
!pip install transformers[torch]
今回のGPT-2はrinnna社の「japanese-gpt2-medium」というモデルで、ホームページでは、「70ギガバイトの日本語テキストを約1カ月の長期間にわたってトレーニングしました」と紹介されています。
先ほどの06.ニュースコーパスの加工で作ったcsvファイルを基に、GPT-2に訓練データを読み込ませる形に成形します。
import os
from tqdm import tqdm
#csvファイルを読み込み、偏りがないようにランダムに並び替える。
livedoor_df = pd.read_csv('drive/MyDrive/Colab Notebooks/livedoor_news_corpus.csv')
livedoor_df = livedoor_df.sample(frac=1)
display(livedoor_df.sample(5))
# 学習データの保存先とファイル名「gpt2_train_data.txt」を指定する。
with open('drive/MyDrive/Colab Notebooks/GPT-2/gpt2_train_data.txt', 'w') as output_file:
for row in tqdm(livedoor_df.itertuples(), total=livedoor_df.shape[0]):
category = row.category
title = row.title
body = row.text
tokens = tokenizer.tokenize(body)[:256]
body = "".join(tokens).replace('▁', '')
text = '<s>' + category + '[SEP]' + body + '[SEP]' + title + '</s>'
output_file.write(text + '\n')
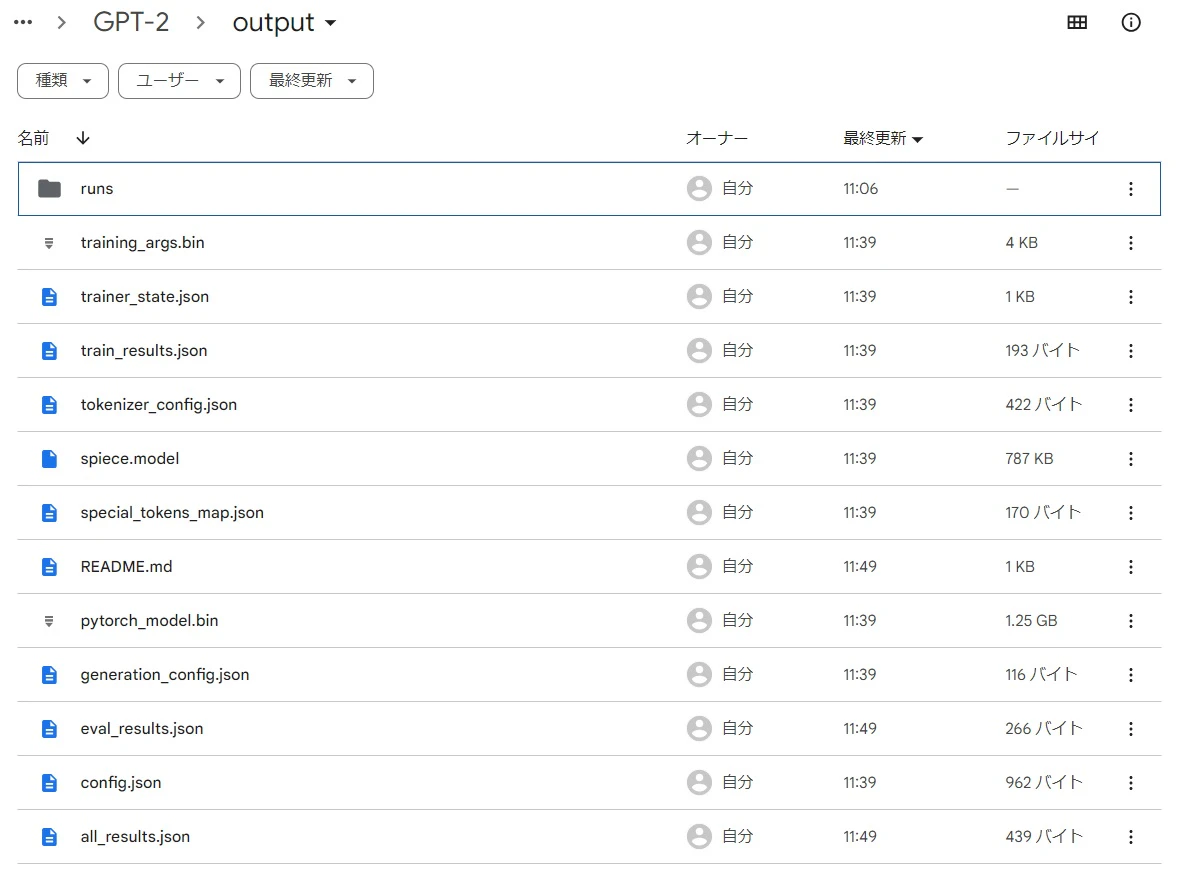
詳細な説明はm_kさんの記事を読んで理解してもらいたいのですが、下の画像が「gpt2_train_data.txt」の一部です。「it-life-hack」がジャンル、[SEP]以降が本文、最後の[SEP]以降が見出しになります。このような形式で一つ一つ保存された7000本以上の記事が、一つのテキストファイルにまとめられています。

08.ファインチューニング
次はGPT-2に学習させるファインチューニングをします。精度を上げるためには、トレーニング回数を増やすべきですが、Google Colabの無料枠内では1回が限界です(無理をするとすぐにメモリ不足で止まり、「課金しませんか?」と表示されます)。環境によりますが、1時間近くかかる事が多いです。
Google Colabでは放置しておくと「使っていない」とみなされて強制終了されるため、時々はマウスを動かすなどして止めないように見守る必要があります。
# ファインチューニングの実行
# ソースコードから直接transformersをインストール
!pip install git+https://github.com/huggingface/transformers
# rinna/japanese-gpt2-mediumのtokenizerはsentencepieceなのでsentencepieceもインストールする必要があります。
!pip install sentencepiece
!pip install datasets
!git clone https://github.com/huggingface/transformers
# run_clm.pyを使います
!ls ./transformers/examples/pytorch/language-modeling/
# README.md run_clm_no_trainer.py run_mlm_no_trainer.py run_plm.py
# requirements.txt run_clm.py run_mlm.py
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt2-medium")
tokenizer.do_lower_case = True # due to some bug of tokenizer config loading
model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt2-medium")
import pandas as pd
import os
from tqdm import tqdm
!pip install -qqq evaluate
import evaluate
!pip install transformers[torch]
!python ./transformers/examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path=rinna/japanese-gpt2-medium \
--train_file=/content/drive/MyDrive/ColabNotebooks/GPT-2/gpt2_train_data.txt \
--validation_file=/content/drive/MyDrive/ColabNotebooks/GPT-2/gpt2_train_data.txt \
--do_train \
--do_eval \
--num_train_epochs=1 \
--save_steps=5000 \
--save_total_limit=3 \
--per_device_train_batch_size=1 \
--per_device_eval_batch_size=1 \
--output_dir=drive/MyDrive/ColabNotebooks/GPT-2/output/ \
--use_fast_tokenizer=False
コードの大部分は##07.トレーニングデータの作成##と重複しますが、別々にプログラムを動かす場合を想定して、あえて再掲しています。連続して実行する場合は、重複部分は冒頭に#をつけて実行しなくても構いません。
***** train metrics *****
epoch = 1.0
train_loss = 2.9793
train_runtime = 0:33:10.77
train_samples = 1979
train_samples_per_second = 0.994
train_steps_per_second = 0.994
08/12/2023 02:39:21 - INFO - __main__ - *** Evaluate ***
[INFO|trainer.py:3103] 2023-08-12 02:39:21,136 >> ***** Running Evaluation *****
[INFO|trainer.py:3105] 2023-08-12 02:39:21,136 >> Num examples = 1979
[INFO|trainer.py:3108] 2023-08-12 02:39:21,136 >> Batch size = 1
100% 1979/1979 [10:01<00:00, 3.29it/s]
***** eval metrics *****
epoch = 1.0
eval_accuracy = 0.4847
eval_loss = 2.6284
eval_runtime = 0:10:02.13
eval_samples = 1979
eval_samples_per_second = 3.287
eval_steps_per_second = 3.287
perplexity = 13.8517
[INFO|modelcard.py:452] 2023-08-12 02:49:23,554 >> Dropping the following result as it does not have all the necessary fields:
{'task': {'name': 'Causal Language Modeling', 'type': 'text-generation'}, 'metrics': [{'name': 'Accuracy', 'type': 'accuracy', 'value': 0.4847403108988465}]}
終了すると経過時間や評価などが表示されます。トレーニング自体(train_runtime)に33分、検証(aval_runtime)に10分を要しました。
今回はoutputフォルダにファインチューニング済モデルが作成されました。本体のpytorch_model.binを含め、全体で1Gbyte超あります。ファインチューニングをすることで、素のバージョンでなく、この学習済みモデルを読み込んで使えるようになる訳です。
09.見出しを生成する(1)
いよいよ準備が終わりました。記事に合う見出しをつけられるか、実際に確認します。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt2-medium")
tokenizer.do_lower_case = True
model = AutoModelForCausalLM.from_pretrained("drive/MyDrive/Colab/GPT-2/output/")
model.to(device)
model.eval()
def generate_news_title(category, body, num_gen=10):
input_text = '<s>'+category+'[SEP]'+body+'[SEP]'
input_ids = tokenizer.encode(input_text, return_tensors='pt').to(device)
out = model.generate(input_ids, do_sample=True, top_p=0.95, top_k=40,
num_return_sequences=num_gen, max_length=256, bad_words_ids=[[1], [5]])
print('='*5,'本文', '='*5)
print(body)
print('-'*5, '生成タイトル', '-'*5)
for sent in tokenizer.batch_decode(out):
sent = sent.split('[SEP]</s>')[1]
sent = sent.replace('</s>', '')
print(sent)
category = 'sports-watch'
body = '''
ああああ
'''
generate_news_title(category, body)
下部にある「category」に、見出しをつけたいカテゴリーを指定し、現在は「あああ」と書いてある部分に記事本文を貼り付けます。
def generate_news_title(category, body, num_gen=10):
input_text = '<s>'+category+'[SEP]'+body+'[SEP]'
input_ids = tokenizer.encode(input_text, return_tensors='pt').to(device)
out = model.generate(input_ids, do_sample=True, top_p=0.95, top_k=40,
num_return_sequences=num_gen, max_length=256, bad_words_ids=[[1], [5]])
ちなみに上の部分がGPT-2の設定項目です。パラメーターの内容は諸説ありますが、簡単に説明すると以下の通りです。
num_gen…生成する見出しの数。この設定なら10個を出力。
top_p…回答のランダム性を決める。0~1で、数字が大きいほどランダムになる。
top_k…回答のトップ何位までに来る単語に絞るかの設定。
max_length…生成される最大トークン。日本語だと大体1文字1トークンなので、最大256文字
「何かおもしろい記事はないか」と思って探していたところ、ちょうど読売新聞にAI絵画コンテストが中止になったという記事が出ていました。
記事の2段落目までを抜粋したのが以下の文です。
武蔵野美術大学(東京)などが、6~7月に作品を募集した画像生成AIによる絵画のコンテストを取りやめていたことがわかった。主催者側は、特定の画像生成AIアプリの使用を応募の条件としたが、アプリの機能に関する説明を誤った上、SNSで著作権侵害を懸念する声が上がり、受賞者が批判される恐れがあると判断したという。
コンテストは、同大と教育ベンチャー「スタディプラス」(同)、ネットサービス会社「カヤック」(神奈川)が主催した「武蔵野AI美術大学 AI絵画アワード」。東京の企業が提供する画像生成AIアプリの使用を応募の条件とし、初めて開催した。一般の人を対象に、6月22日~7月5日に募集して、400点以上の応募があった。
そして読売新聞オンラインの見出し=正解が
武蔵美のAI絵画コンテスト、「著作権侵害」批判で急きょ中止…400点以上の応募
です。AIはこれにどこまで近づけられるでしょうか。今回は幅広い案を示すため、候補を20にしてみました。ジャンルはあえて特定しない「topic-news」です。
----- 生成タイトル -----
武蔵野美術大学と教育ベンチャー「スタディプラス」が、画像生成アプリのコンテスト中止を発表【ニュース】
武蔵野美術大学が、絵画のコンテストを復活させる
oogle、「oop!」のページをデザインを一新!写真投稿もできる
、写真投稿サイトuploadookを刷新!画像投稿の審査方法などを変更し、使いやすくなる
武蔵野美術大学が「スタディプラス」を廃止
、 で画像生成ソフトの使用を応募の条件に
で著作権侵害...画像作成ツールのと審査員で大論争
は、応募を取りやめた理由を「アプリの不正使用などがあった」と説明
写真にデジタルで文字を吹き込んだらこうなる? 写真から文字を吹き出す3技術
artists&creators2012【ol.14】
が画像投稿アプリ「oogle lay」をリニューアル!絵が描ける人と描けない人が出ちゃう?
amuka arts
(武蔵野美術大学)がデザインした絵画展・絵画コンテスト「武蔵野美術大学 絵画アワード」が中止
審査の結果、応募作品の使用が取りやめに
「武蔵野美術大学 絵画アワード」の審査に批判殺到
武蔵野美術大学が、画像処理による絵画コンテストを取りやめ
審査を辞退していた画像生成を再び開催
画像制作で賞金狙う? 武蔵野美術大学「武蔵野美術大学 絵画 アワード」の応募中止
「武蔵野美術大学 絵画アワード」が廃止
う~ん、微妙(笑)。16本目の「武蔵野美術大学が、画像処理による絵画コンテストを取りやめ」が一番近いですが、人間ならまず入れる「AI」というキーワードがありません。「武蔵野美術大学」「AI」「絵画コンテスト」「中止」がほしい要素でしたが…。
まだまだ学習が足りませんね。無関係の企業を中傷する、あまりに問題がありそうな見出しは自粛しました。見事にハルシネーション(=幻覚。LLMによくある、聞いてもいないことをあたかも当然のように答える現象)が出ています。
10.見出しを生成する(2)
もう一つ、ジャンルを「peachy」に変更してみます。peachyはライブドアによると、「毎日をハッピーに生きる女性のためのニュースサイト」だそうです。
見出し案は以下の通り。
は審査を厳しくしたというニュースもありましたが... 武蔵野美術大学 絵画アワード|気になる記事をチェック!
文科省が「芸術の振興を図る」と発表
(講談社)「 」フォトコンテストを中止
次ページへ 次の投稿: 【終了しました】“女子が選ぶ“好きなアニメ”ランキング”発表
宮崎駿監督の最新作『風立ちぬ』公開記念! 無料イラスト展「宮崎駿を描いてみよう!」開催
! ! ! ! ! 女子美術大学 絵画コンクールを中止
ay y ay ay ay! 武蔵野美術大学の画像合成がグランプリ受賞
! ookay!(7月号)特集:芸術性を高めるために、デザイナーが教えるべきこと
次へ 前の記事: 【終了しました】人気の&Cレザーアイテムが最大50%オフ!【10/23まで!】
が画像投稿・販売プラットフォーム「picta」で画像販売、販売価格を50〜60%オフの495円に
、応募したアプリ「photo」をに送付
で著作権侵害を懸念
大は応募を取り下げ、画像生成アプリの使用を応募の条件とした
次の記事> 『lack&hite/ブラック&ホワイト』<1>運命を操る男 2012年8月10日
ページ1〜6「武蔵野大学」「武蔵野美術大学」などの表記揺れ
Cの意図
を使わない画像処理で絵画を描け!
artport ouchy!〜2012年度公募【終了しました】
で著作権侵害 絵を描いたのは学生か
やっぱり微妙…。なぜに宮崎駿監督?!
ただし、topic-newsと全く見出しが変わったことは一目で分かります。学習データに影響されすぎて、入力した記事をうまく理解できていないようです。まだAIには早すぎましたか。とまあ、実用レベルにはほど遠いですが、一応記事に基づく見出しをつけることができています。
11.StreamlitでWebアプリにする(1)
とりあえず見出し作成AIはできたので、今度は自分外の人も使えるようにWebアプリにします。冒頭で紹介したStreamlitで作ります。
このサンプルでは風船を飛ばすアプリなので、このプログラムを参考に、自分の見出し生成プログラムを移植します。その結果がこちら。
#streamlitメインの処理を/content/app.pyに保存
#%%writefile app.py以降の記述を変えれば色々とstreamlitを試せる
%%writefile app.py
import streamlit as st
import time
import torch
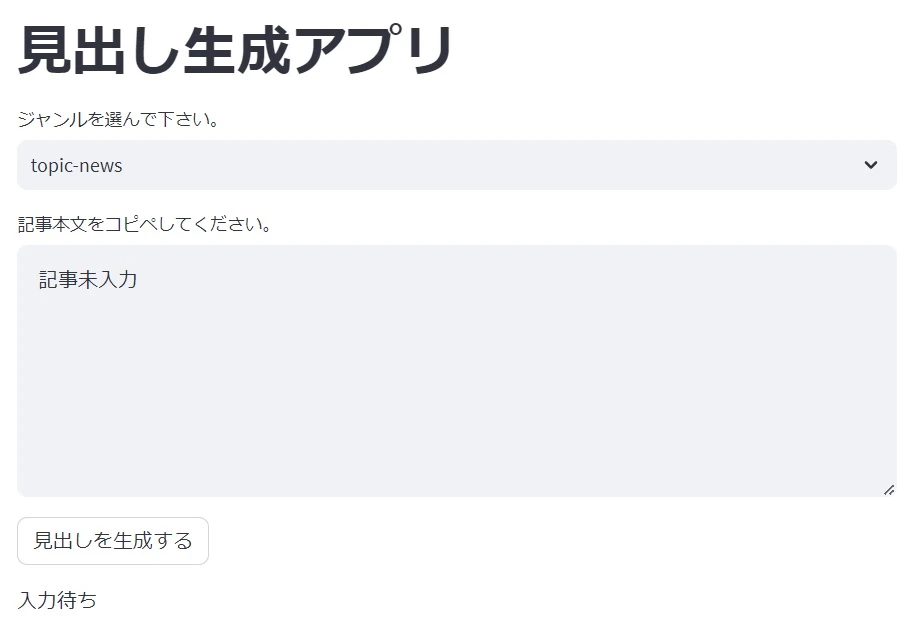
st.title("見出し生成アプリ")
def main():
category_list = st.selectbox('ジャンルを選んで下さい。',('topic-news', 'dokujo-tsushin','it-life-hack','kaden-channel',
'livedoor-homme','movie-enter','peachy','smax','sports-watch'))
text = st.text_area(
label="記事本文をコピペしてください。",
value="記事未入力",
height=200
)
if st.button('見出しを生成する'):
# 最後の試行で上のボタンがクリックされた
st.write('入力済み')
st.write('入力記事: ', text)
from transformers import AutoModelForCausalLM, AutoTokenizer
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt2-medium")
tokenizer.do_lower_case = True
model = AutoModelForCausalLM.from_pretrained("drive/MyDrive/Colab Notebooks/GPT-2/output3/")
model.to(device)
model.eval()
def generate_news_title(category, body, num_gen=10):
input_text = '<s>'+category+'[SEP]'+body+'[SEP]'
input_ids = tokenizer.encode(input_text, return_tensors='pt').to(device)
out = model.generate(input_ids, do_sample=True, top_p=0.95, top_k=40,
num_return_sequences=num_gen, max_length=256, bad_words_ids=[[1], [5]])
st.write('-'*5, '生成タイトル', '-'*5)
for sent in tokenizer.batch_decode(out):
sent = sent.split('[SEP]</s>')[1]
sent = sent.replace('</s>', '')
st.write(sent)
category = 'category_list'
body = f'''
{text}
'''
generate_news_title(category, body)
else:
st.write('入力待ち')
if __name__ == '__main__':
main()
12.StreamlitでWebアプリにする(2)
Streamlitの中身について解説します。
st.title("見出し生成アプリ")
ここが、アプリのタイトル部分です。
def main():
category_list = st.selectbox('ジャンルを選んで下さい。',('topic-news', 'dokujo-tsushin','it-life-hack','kaden-channel',
'livedoor-homme','movie-enter','peachy','smax','sports-watch'))
ここで記事のジャンルを指定します。
text = st.text_area(
label="記事本文をコピペしてください。",
value="記事未入力",
height=200
)
ここが、記事を入力するテキストボックスです。何も入力されていない状態では、valueの部分(ここでは「記事未入力」)がデフォルトで入っています。
if st.button('見出しを生成する'):
# 最後の試行で上のボタンがクリックされた
st.write('入力済み')
st.write('入力記事: ', text)
ifで「見出しを生成する」ボタンを押した場合の動作を指定します。「入力済み」と表示され、入力(コピペ)された記事本文が表示されます。
from transformers import AutoModelForCausalLM, AutoTokenizer
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt2-medium")
tokenizer.do_lower_case = True
model = AutoModelForCausalLM.from_pretrained("drive/MyDrive/Colab Notebooks/GPT-2/output3/")
model.to(device)
model.eval()
def generate_news_title(category, body, num_gen=10):
input_text = '<s>'+category+'[SEP]'+body+'[SEP]'
input_ids = tokenizer.encode(input_text, return_tensors='pt').to(device)
out = model.generate(input_ids, do_sample=True, top_p=0.95, top_k=40,
num_return_sequences=num_gen, max_length=256, bad_words_ids=[[1], [5]])
「見出しを生成する」ボタンを押したことで、ファインチューニング済のGPT-2モデルを呼び出し、入力されたテキストを解釈し、設定条件に従って見出しを考えます。先ほどの解説通り、num_gen=10が見出し案の数です。
st.write('-'*5, '生成タイトル', '-'*5)
for sent in tokenizer.batch_decode(out):
sent = sent.split('[SEP]</s>')[1]
sent = sent.replace('</s>', '')
st.write(sent)
category = 'category_list'
body = f'''
{text}
'''
generate_news_title(category, body)
コピペされた記事本文{text}をGPT-2に受け渡し、指定したジャンルに基づいて回答を示します。「生成タイトル」の下に、候補を10個表示します。
else:
st.write('入力待ち')
if __name__ == '__main__':
main()
記事が入力され、「見出しを生成する」ボタンが押されるまでは「入力待ち」と表示されたままになります。そして最後が、プログラム全体を閉じる部分です。
13.StreamlitでWebアプリにする(3)
プログラム本体の「app.py」は完成しました。以下はより作りやすくするための追加プログラムで、絶対必要なわけではないそうです。ここはアイデミーさんの写経で。
#Google Colabのファイルブラウザを起動し、エディタでapp.pyを開く
#動作上は必須作業ではない
from google.colab import files
files.view("/content")
files.view("app.py")
#次のコード実行する際にprotobufのバージョン起因のエラーが出るので、それを直すおまじない
!pip install --upgrade protobuf
このコードを入れることで、下の画像のように、右側に「app.py」のプログラム、左側にフォルダの構造が表示されます。
次はいよいよ、Streamlitを起動し、対外的に使えるようにします。
#streamlitをlocaltunnelのトンネルで起動
#実行画面に出るyour url is:のurlに接続し、ブラウザの別タブに移動
#Click to Continueでstreamlitの動作を確認
#確認が終わったらこのセルの実行を停止する
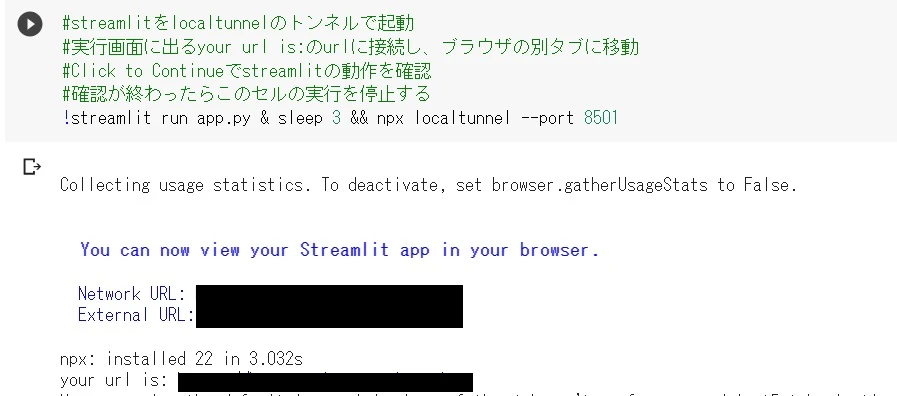
!streamlit run app.py & sleep 3 && npx localtunnel --port 8501
このプログラムを実行すると、画像のようにExternal URLなどが表示されます。your url is:の後ろのリンクをクリックします。
出てきた画面でExternal URL:の後ろのIPアドレスを入れます(「:8501」は不要です)。そして青い「Click to Submit」ボタンを押します。
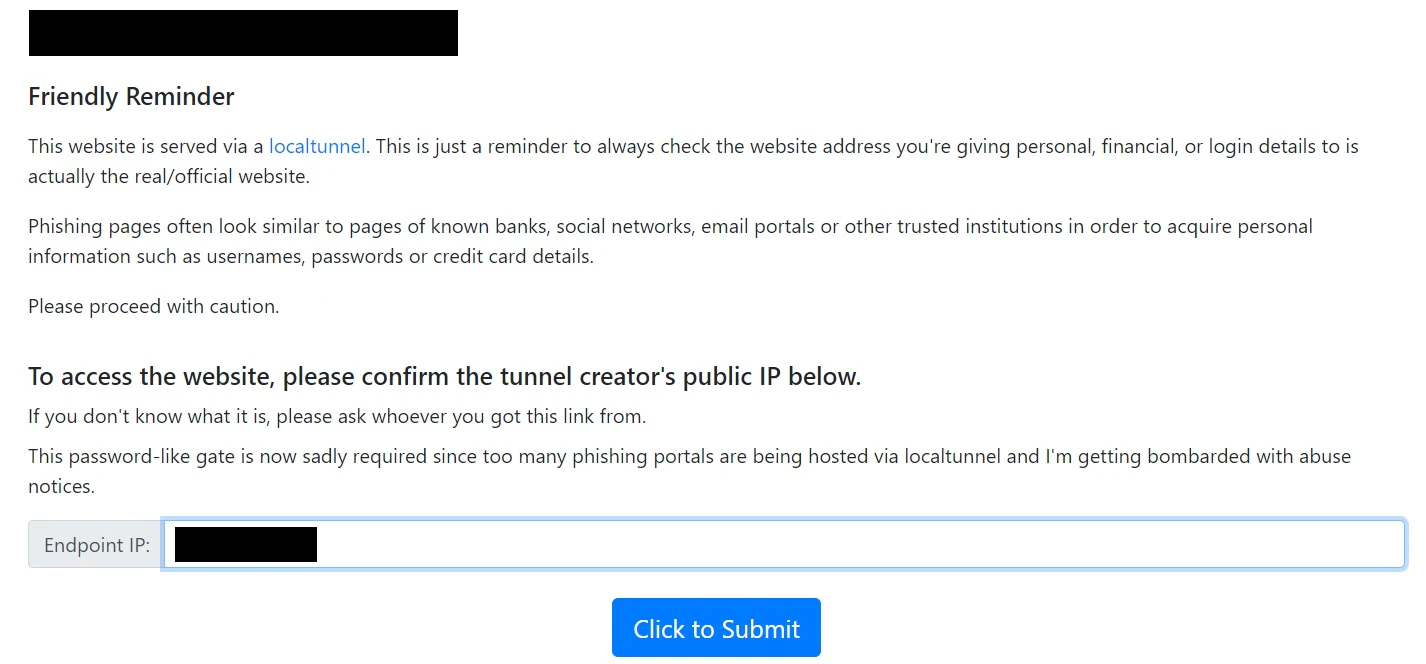
するとapp.pyで作ったプログラム本体の画面が表示されます。使い方はこれまでの説明通りです。
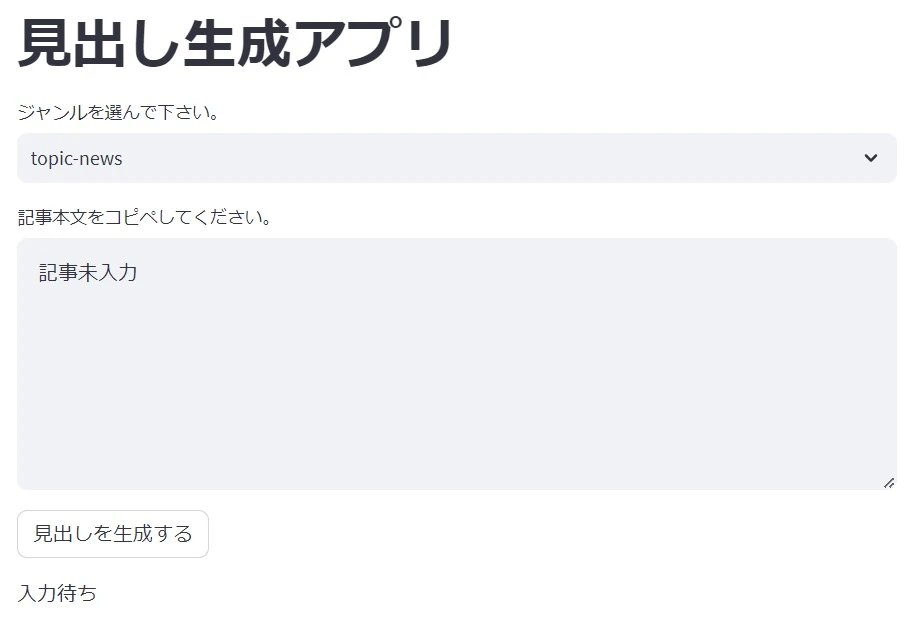
Streamlitはものすごく便利な反面、Google Colaboratoryで手動で動かしている間しかプログラムが使えません。常時公開したい場合は別の方法でWebアプリ化する必要があります。
14.おわりに
長文を読んでいただき、ありがとうございました。AIを使った見出し生成アプリは完成です。
しかし私自身、全く満足できる出来ではありませんし、実際に使ってもらうにはまだまだ越えるべきハードルがあると思っています。
1.トレーニングデータに実際の記事を使い、記事の件数も数万件単位に。
2.ファインチューニングの回数を増やし、生成される見出しの精度を上げる。
3.LLMのモデルをGPT-2ではなく、最新版に変更する。
4.お試し用のStreamlitではなく、常時使えるWebアプリに変更する。
1.は読んでの通りで、見出しは学習データの影響を大きく受けます。自社の記事を使ってトレーニングするべきでしょう。少なくとも数万件は必要だと思います。
2.も今回はGoogle Colaboratoryの無料枠内で抑えるため、トレーニングが1回しかできていません。本来なら3回はやりたい所です。
3.も無料で挑戦したためでしたが、最新ではないGPT-2を選んだのはメモリー使用量が少ないためです。最近はより高性能なオープンソースの日本語LLMも多数登場しており、これらも試してみたいところです。このあたりはnpakaさんが多数紹介しています。
4.モデルを最新版にした後は、Google Colaboratoryの稼働中しか使えないStreamlitではなく、Renderなどを使って常時公開できるWebアプリに改造しようと思います。
まだまだ実用にはほど遠いですが、今後もゴールへ向けて取り組んでいきたいと思います。