はじめに
LLMのシステム構築の際に、LLM-as-a-Judgeをやることになり、下記論文をよんでみました。
https://arxiv.org/pdf/2411.15594
概要
正確で一貫性のある評価は、多くの分野における意思決定にとって不可欠ですが、本質的な主観性、ばらつき、規模といった要因により、依然として困難な課題です。大規模言語モデル(LLM)は、多様な領域で目覚ましい成功を収めており、「LLM-as-a-Judge」という概念が登場しました。これは、複雑なタスクの評価者としてLLMを利用するというものです。LLMは、多様なデータ型を処理し、スケーラブルで柔軟な評価を提供できるため、従来の専門家主導の評価に代わる魅力的な選択肢となります。しかし、LLM-as-a-Judgeシステムの信頼性を確保することは、慎重な設計と標準化が必要となる重要な課題です。本論文は、LLM-as-a-Judgeに関する包括的な調査を提供し、その正式な定義とユースケースの詳細な分類を示します。その上で、中心的な問いである「信頼性の高いLLM-as-a-Judgeシステムをどのように構築できるのか?」に焦点を当てます。一貫性の向上、バイアスの軽減、多様な評価シナリオへの適応など、信頼性を高めるための戦略を探ります。さらに、LLM-as-a-Judgeシステムの信頼性を評価するための方法論を提案し、この目的のために設計された新しいベンチマークによって裏付けます。LLM-as-a-Judgeシステムの開発と実際の展開を促進するために、実際の応用、課題、および将来の方向性についても議論します。本調査は、この急速に進化している分野の研究者や実務家にとって、基礎となる参考文献として役立つでしょう。関連リソースは、https://awesome-llm-as-a-judge.github.io/ でアクセスできます。
1. はじめに
判断力とは、個別のものを普遍的なものに包含されるものとして考える能力である。それは、規則の下に包摂する能力、つまり、あるものが与えられた規則に該当するかどうかを区別する能力を含む。——カント、『判断力批判』(カント、1790年)、序論IV、5:179;『純粋理性批判』(カント、1781年)、A132/B171。
近年、大規模言語モデル(LLM)は、技術分野から人文科学、社会科学に至るまで、数多くの分野で目覚ましい成功を収めています。その成功に基づき、LLMを評価者として利用するという概念、一般に「LLM-as-a-Judge」(Zheng et al., 2023b)と呼ばれるものが大きな注目を集めています。これは、LLMに与えられた規則の範囲内に何かが該当するかどうかを判断させるというものです(カント、1790年、1781年)。この関心の高まりは、LLMが人間のような推論や思考プロセスを模倣する能力に由来しており、従来は人間の専門家に委ねられていた役割を引き受けながら、増大する評価要求に対応するために容易に拡張できる費用対効果の高いソリューションを提供します。たとえば、LLM-as-a-Judgeを学術的な査読プロセス¹に採用することで、専門家レベルの判断を維持しながら、投稿数の急速な増加に対応することができます。
LLMの時代以前は、包括的かつスケーラブルな評価のバランスをとることが長年の課題でした。一方、専門家による評価(Shi et al., 2024; Gao et al., 2023b)のような一般的に使用される主観的な方法は、全体的な推論とニュアンスに富んだ文脈理解を統合しており、包括性の面でゴールドスタンダードとなっています。しかし、これらのアプローチは高価であり、拡張が難しく、一貫性に欠ける可能性があります。他方、自動メトリクスのような客観的な評価方法は、優れたスケーラビリティと一貫性を提供します。たとえば、BLEU(Papineni et al., 2002)やROUGE(Lin, 2004)などのツールは、人間の介入なしに、機械生成された翻訳や要約をリファレンステキストと迅速に比較できます。しかし、これらのメトリクスは、表面的な語彙の重複に大きく依存しているため、より深いニュアンスを捉えることができず、ストーリー生成や説明文などのタスクでは性能が低下することがよくあります(Schluter, 2017)。この長年のジレンマに対する解決策として、「LLM-as-a-Judge」は、上記の2つの評価方法の長所を組み合わせ、自動化された手法のスケーラビリティと、専門家の判断に見られるニュアンスに富んだ文脈に敏感な推論を融合させるという有望なアイデアとして登場しました(Zheng et al., 2023b; Wang et al., 2023d; Zhu et al., 2023a; Li et al., 2023b; Chen et al., 2024e)。さらに、LLMは、適切なプロンプト学習またはファインチューニングの下で、マルチモーダル入力(Chen et al., 2024d)を処理できるほど柔軟になる可能性があります(Khattak et al., 2023)。これらの利点は、LLM-as-a-Judgeアプローチが、複雑でオープンエンドな評価問題を解決するための、斬新で広く適用可能なパラダイムとして機能する可能性を示唆しています。
LLM-as-a-Judgeは、専門家による人間による評価や従来の自動メトリクスと比較して、スケーラブルで適応可能な評価フレームワークとして大きな可能性を秘めていますが(Wang et al., 2024b)、その採用は2つの主要な課題によって妨げられています。最初の課題は、LLM-as-a-Judgeの研究における正式な定義の欠如、断片的な理解、およびカジュアルな使用慣行を反映した、体系的なレビューが存在しないことです。これらのギャップにより、研究者や実務家がLLM-as-a-Judgeを完全に理解し、効果的に適用することが困難になっています。これに基づいて、2番目の課題は、信頼性に関する継続的な懸念に対処することです(Yu et al., 2024b)。なぜなら、単にLLM-as-a-Judgeを採用するだけでは、正確で確立された基準に沿った評価が保証されるわけではないからです。これらの課題は、LLM-as-a-Judgeによって生成された出力のより深い評価だけでなく、「信頼できるLLM-as-a-Judgeシステムを構築するにはどうすればよいか?」という重要な調査を必要としています。
これらの課題に対処するために、本稿では、LLM-as-a-Judgeに関する研究の体系的なレビューを提供し、信頼できるLLM-as-a-Judgeシステムを構築するための戦略を検討しながら、この分野の包括的な概要を提供します。まず、「LLM-as-a-Judgeとは何か?」という基本的な質問に答え、正式な定義と非公式な定義の両方を通じてLLM-as-a-Judgeを定義することから始めます。次に、「LLM-as-a-Judgeをどのように使用するか?」を探求し、既存の方法とアプローチを分類します。これに続いて、「信頼できるLLM-as-a-Judgeシステムを構築するにはどうすればよいか?」という重要な質問に対処するために、次の2つのコアな側面を検討します。(1)LLM-as-a-Judgeシステムの信頼性を高めるための戦略、および(2)これらのシステムの信頼性を評価するための方法論。最初の側面については、LLM-as-a-Judgeのパフォーマンスを最適化するための主要な戦略をレビューします。2番目の側面については、LLM-as-a-Judgeシステムを評価するために使用されるメトリクス、データセット、および方法論を調べ、潜在的なバイアスの発生源とその軽減方法を強調します。これに基づいて、LLM-as-a-Judgeシステムを評価するために特別に設計された、新しいベンチマークを紹介します。さらに、実用的なアプリケーションシナリオを探求し、各コンテキストに固有の課題を特定します。最後に、信頼性、スケーラビリティ、および適用性を向上させるための重要な領域を強調しながら、将来の研究の方向性について議論します。
この調査の残りの部分は、図1のように構成されています。第2節では、LLM-as-a-Judge分野の概要(その定義や既存の方法の分類など)を提供します。特定のシナリオでLLMをJudgeとして実装するための簡単なガイドについては、クイックプラクティス(2.5)で回答を見つけることができます。LLM-as-a-Judgeシステムの信頼性を高め、評価するための戦略は、それぞれ第3節、第4節、および第5節で議論されています。特に、第6節では、LLM-as-a-Judgeとo1のような推論強化の相乗効果について議論します。ここでは、動的なフィードバックを使用して推論パスを最適化し、モデルが複雑な問題を解決する能力を大幅に向上させます。第7節では、実用的なアプリケーションを探求し、第8節と第9節では、課題に対処し、将来の研究の方向性を概説します。最後に、第10節で結論を示します。

LLM-as-a-Judge (LLMを評価者として)
-
LLM-as-a-Judgeとは? [セクション2]
- 非公式な定義
- 公式な定義
-
LLM-as-a-Judgeの使い方? [セクション2]
- In-Context Learning (文脈学習)
- モデル選択
- 後処理
- 評価パイプライン
- 簡単な実践
-
LLM-as-a-Judgeを改善するには? [セクション3]
- プロンプトの改善 (ICLに基づく)
- LLMの能力の向上 (モデルに基づく)
- 最終結果の改善 (後処理に基づく)
-
LLM-as-a-Judgeを評価するには? [セクション4, 5]
- 基本的な指標
- バイアス
- 敵対的頑健性
- メタ評価
- ベンチマーク
-
LLM-as-a-Judgeとo1のような推論の強化 [セクション6]
- 機械学習
-
応用 [セクション7]
- 金融
- 法律
- AI4Sci
- その他の特定の分野
- その他
-
課題 [セクション8]
- 信頼性
- 頑健性
- 強力なバックボーンモデル
-
今後の研究 [セクション9]
- より信頼性の高いLLM-as-a-Judge
- データアノテーションのためのLLM-as-a-Judge
- MLLM-as-a-Judge (マルチモーダルLLMを評価者として)
- より多くのLLM-as-a-Judgeベンチマーク
- LLM最適化のためのLLM-as-a-Judge
2. 背景と手法
LLMが人間の推論を模倣し、特定の入力を事前に定義されたルールに基づいて評価する能力は、「LLM-as-a-Judge(審判としてのLLM)」への道を開きました。LLMのスケーラビリティ、適応性、費用対効果は、従来人間が行っていた評価タスクの増加に対応するのに適しています。これらの能力は、多様な評価シナリオや目的に応じてLLMを柔軟に活用するための鍵となります。LLM-as-a-Judgeの導入は急速に進んでいます。当初、LLMの主な焦点は言語生成と理解でした。人間のフィードバックからの強化学習(RLHF)(Ouyang et al., 2022a)のようなトレーニングパラダイムの進歩により、LLMは人間の価値観や推論プロセスにさらに適合するようになりました。この適合性により、LLMは生成タスクから評価タスクへと移行することができました。LLM-as-a-Judgeの中核とは、LLMを用いて、事前に定義されたルール、基準、または好みに基づいて、対象物、行動、または決定を評価することを指します。これには、以下のような幅広い役割が含まれます:採点者(Trung et al., 2024; Dong et al., 2023)、評価者/査定者(Li et al., 2024b; Zhang et al., 2024d)、批評家(Ke et al., 2024; Xiong et al., 2024; Putta et al., 2024)、検証者(Ling et al., 2024; Shinn et al., 2023; Wang et al., 2024e)、試験官(Bai et al., 2023a)、報酬/ランキングモデル(Yang et al., 2024b; Sun et al., 2023a; Luo et al., 2023a; Yuan et al., 2023)など。
現在、LLM-as-a-Judgeを評価タスクに効果的に使用する方法の定義は、概して非公式または曖昧であり、明確かつ形式的な表現に欠けています。したがって、まずLLM-as-Evaluator(評価者としてのLLM)の形式的な定義を以下のように示します:
ℰ
←
𝒫ℒℒℳ
(x⊕𝒞)
- ℰ: LLM-as-a-Judgeプロセス全体から期待される形で得られる最終的な評価。スコア、選択肢、ラベル、文などがあります。
- 𝒫ℒℒℳ: 対応するLLMによって定義される確率関数であり、生成は自己回帰的なプロセスです。
- x: 評価されるのを待っている、利用可能なあらゆる種類の入力データ(テキスト、画像、ビデオ)。
- 𝒞: 入力xのコンテキスト。プロンプトテンプレートや対話履歴情報と組み合わせられることが多いです。
- ⊕: 入力xとコンテキスト𝒞を組み合わせる結合演算子であり、この操作はコンテキストに応じて、先頭、中間、または末尾に配置されるなど、変化する可能性があります。
LLM-as-a-Judgeの定式化は、LLMが自己回帰的な生成モデルの一種であり、コンテキストに基づいて後続のコンテンツを生成し、そこからターゲットとなる評価を得ることを反映しています。これは、入力設計、モデル選択とトレーニング、出力後処理など、LLMを評価タスクにどのように活用するかを示しています。LLM-as-a-Judgeの実装の基本的なアプローチは、定式化に従って、インコンテキスト学習、モデル選択、後処理手法、評価パイプラインに分類できます。これらのアプローチは図2にまとめられています。このパイプラインに従うことで、評価のための基本的なLLM-as-a-Judgeを構築できます。簡単な実践ガイドはセクション2.5で提供されています。

LLMをジャッジとして使用する評価パイプライン
目的: データ、モデル、エージェントを採点/評価/批評/検証/調査/ランク付けするため
入力:
- テキスト
- 画像
- ビデオ
1. インコンテキスト学習
-
スコア:
- 回答を1から10で採点し、10が最高点とする。
-
Yes/No:
- この回答は事実に基づいているか?
-
ペア:
- どちらの回答がより人間らしいか?
-
多肢選択:
- 事実に基づいている回答を以下から選択してください。
2. モデル選択
-
汎用LLM
-
クローズドソース LLM:
- 例:Gemini
-
オープンソースLLM:
- 例:Llama, Falcon, MPT, ...
-
クローズドソース LLM:
-
ファインチューンされたLLM
- 指示、評価データ、評価
3. ポストプロセス
-
特殊なトークン
- スコアは4です。
- 回答1が良いです。
- 選択肢1, 3, 4, 6にはエラーが含まれています。
-
ロジット
- 確率 = Π(ti ∈ "Yes") P(ti | t<i)
-
選択された文
- サブ質問:ジュリーは今日何ページ読みましたか?
4. 評価
-
数値:
- 例:4
-
オプション:
- 回答1 / 修正が必要です。
-
確率:
- 例:0.3284
-
選択肢:
- 例:A,B,C,D; 1,3,4,6
2.1 インコンテキスト学習
LLMを評価者として適用するには、通常、インコンテキスト学習の手法を用いて評価タスクを定義します。これは、モデルの推論と判断を導くための指示と例を提供することです。このプロセスは、プロンプトと入力の設計という2つの重要な側面を含みます。入力の設計においては、評価する変数の種類(テキスト、画像、ビデオなど)、入力の方法(個別、ペア、バッチなど)、入力の位置(最初、中間、最後など)を考慮することが重要です。プロンプトの設計に関しては、図2に示すように、4つの異なる方法を採用できます。その4つの方法とは、スコアの生成、正誤問題の解答、ペアワイズ比較の実施、多肢選択問題の選択です。詳細については、以下のセクションで説明します。

図3. ICLにおけるスコア生成方法の図解
1-3
1-5
リカート尺度
試験官としてのLM
1-5
リカート尺度
G-Eval
G-Eval
加重合計スコア: 2.59
1-10
JudgeLM
離散スコア
連続スコア
スコアで判断する
0-1
ChartMimic
0-100
LLaVA-Critic
応答を〜の範囲で採点する
2.1.1. スコアの生成
評価を対応するスコアで表現することは、非常に直感的です。しかし、より慎重な検討を要するのは、評価に使用するスコアの性質と範囲です。スコアは離散的であり、1-3、1-5 (Jones et al., 2024)、または 1-10 (Zhu et al., 2023a; Li et al., 2023b) などの一般的な範囲を持つことができます。あるいは、0 から 1 または 0 から 100 (Xiong et al., 2024) の範囲の連続的なスコアとすることもできます。最も単純なスコアリング方法は、コンテキストを通して、スコアの範囲とスコアリングの主要な基準を設定することです。例えば、「応答の役立ちやすさ、関連性、正確性、詳細度を評価してください。各アシスタントは 1 から 10 のスケールで総合的なスコアを受け取ります。スコアが高いほど、全体的なパフォーマンスが優れていることを示します」(Zhu et al., 2023a)。もう少し複雑な方法としては、より詳細なスコアリング基準を提供することが挙げられます。より複雑なスコアリング状況としては、Figure 4 に示されているように、絶対的な評価尺度としてリッカート尺度スコアリング関数を使用する Language-Model-as-an-Examiner (Bai et al., 2023a) などがあります。評価者は、正確性、一貫性、事実性、包括性など、事前に定義された側面について、与えられた応答にスコアを割り当てます。これらの側面はそれぞれ 1 から 3 のスケールで評価され、最悪から最良までを表します。評価者は、前の 4 つの側面に割り当てられたスコアに基づいて、1 から 5 の範囲で全体的なスコアを提供することも求められます。このスコアは、回答の全体的な品質の指標として機能します。
2.1.2. Yes/No問題の解決
Yes/No問題は、与えられたステートメントの正確性のみに焦点を当て、判断を必要とします。このタイプの問題は単純かつ直接的で、追加の比較や選択肢はなく、yesまたはno、trueまたはfalseの2つの固定された回答のみを提供します。
このタイプの評価は、中間プロセスで頻繁に利用され、フィードバックループの条件を作り出します。たとえば、Reflexion (Shinn et al., 2023)に見られるように、自己最適化サイクルを促進します。Reflexionは、将来の試行に役立つ貴重なフィードバックを提供するために、口頭での自己反省を生成します。バイナリの成功ステータス(成功/失敗)のような、乏しい報酬シグナルを持つシナリオでは、自己反省モデルは現在の軌跡と永続的なメモリを使用して、ニュアンスのある具体的なフィードバックを生成します。同様に、自己改善の文脈 (Tian et al., 2024)では、Yes/No問題を使用して、"修正が必要" や "修正は不要" のようなカスタムフレーズを評価し、次のサイクルへの移行を容易にすることができます。さらに、これらの評価は、知識の正確性をテストしたり、ステートメントが確立された事実に沿っているかどうかを評価したりするのによく使用されます (Sun et al., 2023d)。例えば、”質問と、関連する検索されたナレッジグラフトリプル(エンティティ、関係、エンティティ)が与えられた場合、これらのトリプルとあなたの知識で質問に答えるのに十分であるかどうかを尋ねられます(YesまたはNo)。” 図5に、詳細で具体的な例が示されています。
2.1.3. ペアワイズ比較の実施
ペアワイズ比較とは、2つの選択肢を比較し、どちらが優れているか、または特定の基準により合致しているかを選択することであり、図6に示されています。これは、「はい」または「いいえ」の判断ではなく、2つの選択肢の間で意思決定を行うことを伴います。比較は、主観的または客観的な基準に基づいて行われる可能性があります。この評価は相対評価です。ペアワイズ比較は、複数の選択肢をランキング付けしたり、優先順位を付けたりするためにしばしば使用されます。これは、ペア間でいくつかの比較を行い、より良い選択肢を特定したり、階層を確立したりするためです。
ペアワイズ比較は、さまざまな分野に大きな影響を与えてきた確立された手法です(Qin et al., 2024a)。(Liu et al., 2024b)が指摘しているように、LLMと人間の評価は、スコアベースの評価と比較して、ペアワイズ比較の文脈においてより一致しています。多くの研究が、ペアワイズ比較評価が位置的一貫性の点で他の評価方法よりも優れていることを示しています(Zheng et al., 2023c; Liusie et al., 2024)。さらに、ペアワイズ比較は、高度なランキングアルゴリズム(Qin et al., 2024a; Liu et al., 2024b)やデータフィルタリング(Yuan et al., 2023)を使用して、リストワイズ比較など、より複雑な関係ベースの評価フレームワークに拡張できます。ペアワイズ比較評価では、LLM-as-a-Judgeは、当面の質問に最も良く答える応答を選択するように促されます。引き分けの可能性に対応するために、いくつかのオプションモードが導入されています。Two-Optionモードでは、審査員は与えられた2つの選択肢からより良い応答を選択する必要があります。Three-Optionモードでは、追加の選択肢が導入され、どちらの応答も好ましくない場合に引き分けを示すことができます。評価は通常、ペアワイズ比較を通じて、応答に対する勝ち、引き分け、または負けの結果を決定し(Wang et al., 2023d)、各応答の勝ちラウンド数をカウントすることを伴います。Four-Optionモードは選択肢をさらに拡張し、審査員は応答を「両方良い引き分け」または「両方悪い引き分け」として分類することができます。
2.1.4. 複数選択肢の選択
複数選択肢の選択とは、いくつかの選択肢の中から選ぶ形式であり、一対比較で相対的な選択肢を選ぶものでも、イエス/ノーで判断するものでもありません。評価者は、最も適切または正しい選択肢を選ぶ必要があります。この方法は、正誤問題よりも幅広い回答を可能にし、より深い理解や好みを評価できます。例は図7に示されています。ただし、この種のプロンプト設計は、最初の3つよりも一般的ではありません。
2.2. モデル選択
2.2.1. 一般的なLLM
LLMを審査員として用いた自動評価を実現する効果的なアプローチの一つは、人間の評価者の代わりに、GPT-4 (OpenAI, 2023a) のような高度な言語モデルを活用することです (Zheng et al., 2023c)。例えば、Li et al. (2023c) は805問の質問からなるテストセットを作成し、GPT-4を用いて text-davinci-003 と比較することで性能を評価しました。さらに、Zheng et al. (2023c) は、8つの一般的な分野にわたる80の多ラウンドテスト問題を設計し、GPT-4を用いてモデルの応答を自動的にスコアリングしました。GPT-4に基づく評価者の精度は、プロの人間評価者と比較して高いことが示されており、評価において優れた一貫性と安定性を示しています。ただし、使用する一般的なLLMが、指示に従う能力や推論能力に制限がある場合、LLMを審査員として用いる手法の効果は著しく影響を受ける可能性があります。
2.2.2. ファインチューニングされたLLM
しかしながら、評価のために外部APIに依存することは、プライバシー漏洩に関する懸念を引き起こす可能性があり、APIモデルの不透明性は評価の再現性にも課題を投げかけます。したがって、その後の研究では、ペアワイズ比較や採点などの手法を強調し、評価に特化した言語モデルを洗練することを推奨しています。例えば、PandaLM (Wang et al., 2023d) は、Alpacaの指示とGPT-3.5のアノテーションに基づいてデータを構築し、LLaMA-7B (Touvron et al., 2023a) を評価モデルとしてファインチューニングします。JudgeLM (Zhu et al., 2023a) は、多様な指示セットとGPT-4のアノテーションからデータを構築し、Vicuna (Touvron et al., 2023b) をスケーラブルな評価モデルとしてファインチューニングします。Auto-J (Li et al., 2023b) は、複数のシナリオに基づいて評価データを構築し、評価と批判的な意見の両方を提供できる生成型評価モデルを訓練します。Prometheus (Kim et al., 2023) は、数千もの評価基準を定義し、GPT-4に基づいてフィードバックデータセットを構築し、きめ細かい評価モデルをファインチューニングします。
審査モデルをファインチューニングする典型的なプロセスは、図14に示すように、主に3つのステップで構成されます。ステップ1: データ収集。訓練データは通常、指示、評価対象、評価の3つの要素で構成されます。指示は通常、指示データセットから取得され、評価はGPT-4または人間のアノテーションから得られます。ステップ2: プロンプト設計。プロンプトテンプレートの構造は、評価スキームに基づいて変化する可能性があり、これはすでに§2.1で詳細に説明されています。ステップ3: モデルのファインチューニング。設計されたプロンプトと収集されたデータを用いて、評価モデルのファインチューニングプロセスは通常、指示ファインチューニングパラダイム (Ouyang et al., 2022b) に準拠します。モデルは指示と1つ以上の応答を受け取り、評価結果と場合によっては説明を含む出力を生成します。
ファインチューニング後、評価モデルはターゲットオブジェクトを評価するために使用できます。これらのファインチューニングされたモデルは、自己設計のテストセットで優れたパフォーマンスを示すことが多いですが、評価能力にはいくつかの制限があることが特定されており、これについてはセクション4.2で詳細に説明します。現在のプロンプトとファインチューニングデータセットの設計は、しばしば汎化能力の低い評価LLMをもたらし、GPT-4のような強力なLLMとの比較を困難にしています。
2.3.後処理手法
後処理は、正確な評価を提供するために、LLM-as-a-Judgeによって生成された確率分布を洗練します。評価形式は、我々のIn-Context Learningのデザインと整合している必要があります。加えて、後処理は、In-Context Learningフレームワークと密接に関連し、一貫して適用される、抽出された評価の信頼性を高めるための手順を含むことがあります。後処理の主な方法は3つあり、特定のトークンの抽出、出力ロジットの正規化、および高いリターンを持つ文の選択です。
これらの方法について詳しく説明します。ただし、客観的な質問を評価する際には、それぞれの方法に大きな制限があることに注意することが重要です。例えば、テキスト応答評価(Yu et al., 2024b)において、LLMの応答からキーとなる解答トークンを正確に抽出できない場合、誤った評価結果につながる可能性があります。後処理におけるこれらの課題は、初期のICL段階で使用されたプロンプト設計と、選択されたモデルの指示に従う能力に深く関連しています。
2.3.1.特定のトークンの抽出
In-context Learning(セクション2.1)で示したように、評価対象がスコア、特定の選択肢の選択、またはYes/Noでの応答といった形式をとる場合、確率分布の反復中に生成された応答から対応するトークンを抽出するために、ルールマッチを適用することが一般的に使用されます。Yes/Noは、判断を含むカスタムステートメントを含む広範な定義であることに注意する価値があります。カスタムフレーズ(Tian et al., 2024)における評価のためのYes/No質問(例:"修正が必要。" と "修正は不要。")や、Yes/No質問(例:"上記の回答はさらに修正する必要がありますか?")を考えてみましょう。入力サンプルをテンプレートに通すと、"修正が必要。"、"結論:修正が必要。"、または "はい"のような出力が得られる可能性があります。この応答形式のばらつきを一貫して解析することは困難です。応答に応じた適切な後処理が必要となります。設計したプロンプトと入力コンテンツ、および評価に使用されるバックボーンモデルのために、ルールを用いて特定のトークンを抽出するには、セクション2.2で議論したように、より高い要件が必要になります。In-context learningでは、応答の出力形式が明確に示されていない場合、さまざまな評価表現が存在する可能性があります。これは図2で見ることができます。例えば、"応答1の方が良い"と"より良い応答は応答1である"は、同じ選択を伝えていますが、形式が異なるため、ルールの認識が困難になります。単純な解決策としては、"最後の文は’より良い応答は’で始まるべきである"といった明確な指示を提供するか、few-shot戦略を用いることが挙げられます。また、指示に従う能力が不十分な汎用モデルでは、指示に従ってターゲットの評価形式や内容を生成できない可能性があり、その結果、ルールに従って抽出される後処理が期待どおりにスムーズに進まないことがあります。
2.3.2.制約付きデコーディング
制約付きデコーディングは、JSONのような形式で、事前に定義されたスキーマに従ってトークン生成を制限することにより、大規模言語モデル(LLM)からの構造化された出力を強制する手法です。このアプローチでは、有限状態マシン(FSM)を使用して、各デコードステップで有効な次のトークンを計算し、モデルの出力確率分布を効果的にマスキングして、目的のスキーマへの準拠を保証します。この方法は構文的に有効な出力を保証しますが、いくつかの課題があります。モデルの学習された分布を歪め、出力品質を低下させる可能性があり、大規模なエンジニアリング実装作業が必要であり、推論時に計算オーバーヘッドが発生します。
最近の研究では、これらの課題に対処するためにさまざまな解決策が提案されています。(Beurer-Kellner et al., 2024)は、制約を強制しながら自然なトークン化を維持するデコードアルゴリズムであるDOMINOを紹介しています。彼らのシステムは、事前計算と投機的デコードを通じてオーバーヘッドを最小限に抑え、制約のないデコードよりも高速なパフォーマンスを達成することもあります。(Dong et al., 2024b)は、トークンを事前チェック可能なものと実行時検証が必要なものに分離することにより、文法制約付き生成を高速化するXGrammarを開発しました。文法エンジンをLLM推論と共同設計することにより、既存のアプローチよりも最大100倍の高速化を実現します。(Zheng et al., 2024b)は、ドメイン固有言語と最適化されたランタイムを組み合わせたSGLangを発表しています。彼らのシステムは、効率的なKVキャッシュの再利用と、より高速なデコードのための圧縮された有限状態マシンを備えており、プログラミングモデルとランタイムの思慮深い共同設計が制約付きデコードのオーバーヘッドを最小限に抑えることができることを示しています。
2.3.3. 出力ロジットの正規化
Yes/No設定の中間ステップにおいてLLMを評価者として使用する場合、出力ロジットを正規化して、0から1の間の連続した小数形式で評価値を得ることがよくあります。これはエージェント手法やプロンプトに基づいた最適化手法でも非常に一般的です (Hao et al., 2023a; Zhuang et al., 2023; Wang et al., 2024e)。例えば、ℳEvaluatorの1回のフォワードパスにおける自己整合性と自己反省スコア (Wang et al., 2024e) は、プロンプト [(x⊕𝒞),"Yes"] を構築し、前のトークンを条件とした各トークンの確率 P(ti|t<i) を取得することで実質的に得られます。自己回帰的特徴を利用して、関連するトークンの確率を集計し、自己整合性スコア ρSelf-consistency と自己反省スコア ρSelf-reflection を計算します。最終スコアは ρj=ρSC,j⋅ρSR,j で算出されます。
(x⊕𝒞)⏞ρSC"Yes"⏞ρSR→⇒{ρSC=∏ti∈αP(ti|t<i)⋅∏ti∈βP(ti|t<i)ρSR=∏ti∈"Yes"P(ti|t<i)
さらに、自己評価 (Hao et al., 2023a) も、LLMを評価者として使用する際にこの方法でよく行われます。 LLMに「この推論ステップは正しいか?」と質問し、次の単語が「Yes」になる確率に基づいて報酬を与えることは有用です。
2.3.4. 文の選択
特定のトークンを選択して出力ロジットを正規化することに加えて、LLMを評価者として抽出されるコンテンツは、文または段落である場合もあります。図2に示すように、推論タスクのエージェント (Hao et al., 2023a) は、LLMを評価者として使用し、最も有望な推論ステップ(アクション、サブ質問)を反復的に考慮することで、推論ツリーを構築します。

図8:LLMを裁判官として使用する評価パイプラインの4つの典型的なシナリオ
- モデル向け
- データ向け
- LLMを裁判官として
- エージェント向け
- 推論/思考向け
2.4 評価パイプライン
3つのプロセスを完了した後、最終的な評価値 ℰ を得ます。入力から出力まで、これらのステップはまとめて、図2に示すLLM-as-a-Judge評価パイプラインを形成します。このパイプラインは、図14に示すように、モデルに対するLLM-as-a-Judge、データに対するLLM-as-a-Judge、エージェントに対するLLM-as-a-Judge、および推論/思考に対するLLM-as-a-Judgeという、4つのシナリオで一般的に適用されます。
2.4.1. モデルに対するLLM-as-a-Judge
LLMを評価する最良の方法が人間の判断であることは広く知られていますが、人間のアノテーションを収集するには、コストがかかり、時間がかかり、手間がかかります(Ouyang et al., 2022b; Zheng et al., 2023d)。LLMを評価するための自動化された代替手段として、強力なLLM(通常はクローズドソースのもの、例えばGPT-4、Claude、ChatGPT)を使用することが自然な選択肢となっています(Zhou et al., 2023a)。適切なプロンプト設計により、評価の質と人間の判断との一致は有望です(Dubois et al., 2023; Zheng et al., 2023d; Zhang et al., 2023c; Wang et al., 2023b)。しかし、特に大規模データでモデルの検証が頻繁に必要な場合、これらのプロプライエタリなモデルのAPIを呼び出す際のコストの問題は依然として存在します。さらに、クローズドソースのLLM-as-a-Judgeは、APIの背後にあるモデルが変更される可能性があるため、再現性が低くなります。いくつかの最近の研究では、オープンソースの代替手段を試み始めています。SelFee(Ye et al., 2023)は、ChatGPTから生成、フィードバック、修正された生成を収集し、LLaMAモデルをファインチューンして批判モデルを構築します。Shepherd(Wang et al., 2023c)は、オンラインコミュニティからのフィードバックと人間のアノテーションのデータを使用して、単一応答に対する批判を出力できるモデルをトレーニングします。PandaLM(Wang et al., 2023d)は、LLM Instruction Tuning Optimizationのためにペアワイズ比較を行うモデルをトレーニングし、Zheng et al.(2023d)は、よりコスト効率の高いプロキシとしてオープンソースモデルの可能性を調査するために、20Kのペアワイズ比較データセットでVicuna(Touvron et al., 2023b)をファインチューンします。
図9. モデルに対するLLM(大規模言語モデル)を裁判官として用いるシナリオの図解
2.4.2. データに対する LLM を Judge として活用
データアノテーションとは一般的に、未加工データに機械学習モデルの有効性を向上させるために使用できる関連情報をラベル付けまたは生成することを指します。しかし、このプロセスは労働集約的であり、コストもかかります。LLM の登場は、LLM を Judge として活用することで、複雑なデータアノテーションプロセスを自動化する前例のない機会をもたらします。LLM を Judge として評価する必要があるデータのほとんどは、モデルによって生成されたデータ、または大規模にクローリングされたデータです。言語モデルはまず、人間による指示への適合方法を模倣するために、教師ありファインチューニングを実施します (Wang et al., 2023a; Taori et al., 2023)。その後、人間の好みに言語モデルを適合させるために、強化学習の手法が検討されてきました (Ouyang et al., 2022; Ramamurthy et al., 2023)。最も成功している方法は、人間のフィードバックに基づいて報酬モデルをトレーニングし、PPO (Schulman et al., 2017) を使用して言語生成のポリシーモデルを取得する RLHF フレームワーク (Ouyang et al., 2022) を適用することです。しかし、実際には、PPO トレーニングパラダイムはコーディングとハイパーパラメータチューニングが複雑であり、トレーニングが難しい 4 つのモデルが必要です。これにより、人間の好みに言語モデルを適合させるための、よりシンプルで直接的な方法を模索する動機が生まれます。これには、さまざまな応答が人間の好みに適合しているかどうかを LLM を Judge として使用して評価する方法が含まれます。たとえば、(Yuan et al., 2023b; Dong et al., 2023) は、より適切に人間の好みに適合させるために、汎用 LLM (ChatGPT) を使用しています。Aplaca プロンプト (Taori et al., 2023) は、さまざまなモデルが応答を生成するためのサンプリングクエリとして使用されます。そして、これらのデータは LLM を Judge として評価され、新しい言語モデルをトレーニングするための人間の好みスコア(報酬スコア)が得られます。他の研究では、教師ありファインチューニング (SFT) モデル自体を評価者として使用することを試みています。例えば、事後的に修正されたプロンプト (Zhang et al., 2023a; Liu et al., 2023d) や原則に基づいた自己適合 (Sun et al., 2023b) など、SFT 用により適切に適合したデータセットを生成します。
さらに、ドメイン固有のモデルトレーニングデータの不足は一般的な現象です。アノテーション付きの高品質なデータを取得するために、LLM を Judge として使用してドメインデータを生成および評価することも非常に一般的です。WizardMath (Luo et al., 2023) は、その Instruction Reward Model (IRM) を評価者として使用し、進化する指示の品質を次の 3 つの側面から判断することを目指しています。i) 定義、ii) 精度、iii) 整合性。IRM のランキングリストトレーニングデータを作成するために、各指示に対して、ChatGPT と Wizard-E を使用してそれぞれ 2〜4 個の進化した指示を生成します。次に、Wizard-E を利用して、これらの 4〜8 個の指示の品質をランク付けします。
ただし、データアノテーションのために LLM を Judge として使用することだけに頼ると、特にアノテーション付きデータの価値がモデルパフォーマンスの急速な向上とともに低下するため、課題が生じます。この問題に対処するために、Self-Taught Evaluator (Wang et al., 2024b) のようなアプローチは、人間のアノテーションの必要性を排除することで、有望な代替手段を提供します。この方法は、ラベルのない指示から始めて、モデルから対照的な出力を生成する合成トレーニングデータを利用します。これらの出力は、LLM を Judge としてトレーニングして、推論トレースと最終的な判断を生成するために使用されます。反復ごとに、評価者は洗練された予測から学習することによって改善され、継続的な自己強化のサイクルが作成されます。この反復的なアプローチは、アノテーションの関連性を維持するだけでなく、評価者が進化するモデルとともに進化することも保証します。
マルチモーダルデータの評価に関する最近の研究は、マルチモーダル大規模言語モデル (MLLM) における視覚言語のミスマッチに対処することに焦点を当てています。これにより、しばしば幻覚、つまり視覚的または文脈的な証拠と矛盾する出力が発生します (Li et al., 2023a; Wang et al., 2023e; Cui et al., 2023)。人間のフィードバックからの強化学習 (RLHF) や、事実を強化した RLHF などの手法が、構造化されたグラウンドトゥルースデータと画像キャプションを組み込むことによってモデルの適合性を改善し、幻覚検出を強化するために採用されています (Sun et al., 2023a)。MLLM-as-a-Judge (Chen et al., 2024b) などのベンチマークは、スコアリング、ペア比較、バッチランキングなどのタスクを使用してこれらのモデルを評価し、人間の好みとの適合性の制限を明らかにします。永続的な問題には、バイアス (例:位置、冗長性) や幻覚が含まれており、GPT-4V のような高度なモデルでさえ課題が見られます。ペア比較タスクは人間の判断とより適切に一致しますが、スコアリングとバッチランキングには、信頼できるデプロイメントのために大幅な改善が必要です。これらの調査結果は、MLLM の評価と適合性を改善するための革新的なフレームワークとデータセットの必要性を強調しています。
2.4.3. エージェントに対する LLM-as-a-Judge
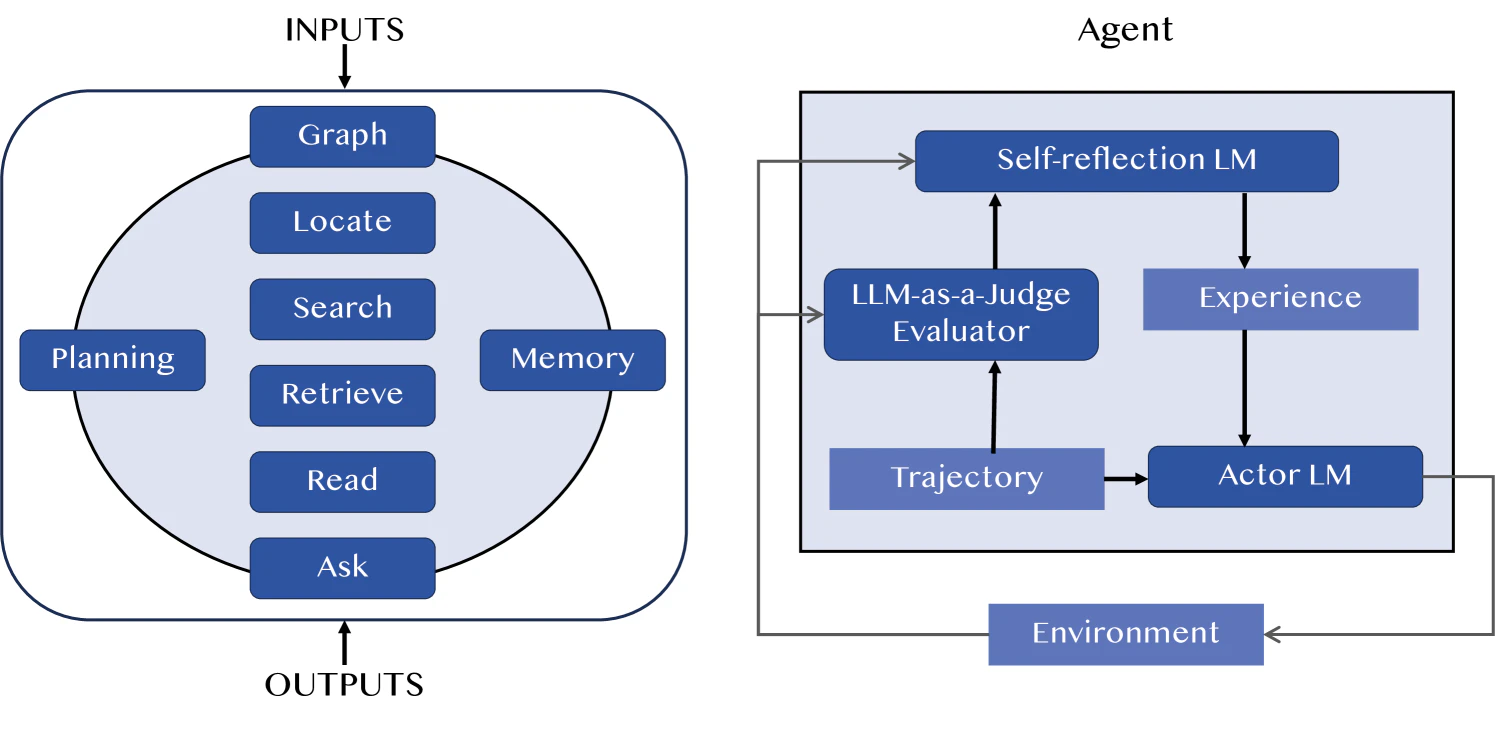
図10. LLM-as-a-Judgeは、エージェントにおいて2つの一般的な形式で登場します。左の図は、評価者として機能する完全なエージェントを設計するAgent-as-a-Judgeです。右の図は、エージェントのプロセスにおいてLLM-as-a-Judgeを使用することを示しています。
エージェントにLLM-as-a-Judgeを適用するには、2つの方法があります。1つは、インテリジェントエージェントのプロセス全体を評価する方法(Zhuge et al., 2024)で、もう1つは、エージェントフレームワークプロセス内の特定の段階で評価する方法(Hao et al., 2023; Shinn et al., 2023)です。どちらのアプローチも、図10で簡単に説明されています。LLMをエージェントの頭脳として使用することにより、エージェントシステム(Zhuge et al., 2024)は人間のように評価でき、人間の関与の必要性を減らし、徹底性と労力の間のトレードオフを解消します。さらに、エージェント(Shinn et al., 2023)は言語を通じて環境と対話し、LLMを通じてアクションに関するフィードバックを受け取り、次のアクションの意思決定を行うことができます。
2.4.4. 推論/思考に対する LLM-as-a-Judge
推論(Huang and Chang, 2023)は、結論を導き出すために論理、議論、証拠を適用する認知プロセスとして定義され、意思決定、問題解決、批判的分析などの知的タスクの中心となります。推論は本質的に判断よりも要求が厳しく多面的ですが、論理的な一貫性を確保し、中間ステップを洗練し、結果の明確さを実現するためには、多くの場合、判断に依存します。この意味において、LLM-as-a-Judgeは、LLMの推論能力を強化するための不可欠なツールとなります。
推論または思考を強化する際のLLM-as-a-Judgeの役割は、学習時間の拡大(Gao et al., 2023c; Trung et al., 2024)とテスト時間の拡大(Snell et al., 2024)という2つのフレームワークを通じて理解できます。学習フェーズでは、LLM-as-a-Judgeは、強化学習パラダイム内で頻繁に動作し、データまたはプロセスの報酬モデルまたは評価者として機能します。これにより、ステップごとの検証(Lightman et al., 2023)、Direct Preference Optimization(DPO)(Rafailov et al., 2024)、自己洗練(Yuan et al., 2024)などのメカニズムを通じて、高品質の推論データセットを作成できます。最近では、高度な推論および思考能力を示すように強化学習でトレーニングされたいくつかのLLM、例えばo12、DeepSeek-R13、gemini-thinking4、およびQVQ5が注目を集めています。テスト時間のフレームワークでは、LLM-as-a-Judgeは、最良の推論パスを評価および選択するために重要です。たとえば、複数の推論出力が生成される「Best-of-N」生成シナリオでは、評価者は最も正確で一貫性のある応答を決定します。トレーニングフェーズとテストフェーズの両方におけるこの二重の役割は、推論システムを強化する上でのLLM-as-a-Judgeの不可欠な性質を示しています。
2.5.

図11. クイックプラクティスのフローチャート
LLM-as-a-Judgeのデザインを効果的に適用するためには、さまざまなシナリオにおいて、テストサイクルの中でより効果的な構成を見つけることをお勧めします。LLM-as-a-Judgeの活用が成功するかどうかは、タスクの複雑さ、プロンプトのデザイン、モデルの選択、後処理の方法など、実装の詳細に大きく依存します。図11に示すように、LLM-as-a-Judgeのクイックプラクティスのプロセスは、主に4つの段階で構成されています。まず、思考段階では、何を評価する必要があるのかを決定し、典型的な人間の評価アプローチを理解し、信頼できる評価の例を特定することで、評価目標を定義します。次に、プロンプトのデザイン(2.1項で詳述)では、言葉遣いとフォーマットの両方が重要になります。最も効率的で一般的に効果的なアプローチは、スコアリングの次元を指定し、より良い評価のために相対比較を強調し、LLMを導くための効果的な例を作成することです。3番目の段階、モデルの選択(2.2項)では、信頼性の高い評価を確実にするために、強力な推論能力と指示追従能力を備えた大規模モデルを選択することに焦点を当てます。最後に、評価プロセスを標準化することで、出力が構造化されるようにします(2.3項)。これは、\boxed、数値スコア、またはバイナリ応答(例:「はい」または「いいえ」)などの特定の形式を使用することで実現できます。プロセス全体には、ケースを用いた反復テストと、再テストによる改善が含まれており、それによって信頼性が向上します。開発中は、モデルやプロンプトを比較し、継続的な改善を確認することが不可欠です。
3. LLM を評価者として活用するための改善戦略
LLM を直接評価タスク (スコアリング、選択、ペアワイズ比較、ランキングなど) に使用する場合、LLM 固有のバイアス (長さバイアス、位置バイアス、具体性バイアスなど[111]) が評価結果を損なう可能性があります。これらの固有のバイアスを軽減し、LLM の全体的な評価パフォーマンスを向上させることは、LLM を評価者として適用する上で重要な課題です。
このセクションでは、LLM を評価者として活用する際の評価パフォーマンスを向上させるための 3 つの改善戦略を紹介します。それは、評価プロンプトの設計戦略 (インコンテキスト学習ベース)、LLM の評価能力の向上戦略 (モデルベース)、および最終的な評価結果の最適化戦略 (後処理ベース) です。
図 12 に示すように、私たちの分類は、セクション 2 で定義した LLM を評価者とする形式的な定義に基づいており、プロセスにおける 3 つの重要な段階 (コンテキスト C、LLM 自体の能力 PL LM、および最終結果 E を得るための後処理 ←) をターゲットとすることで、評価の有効性を高めることに焦点を当てています。
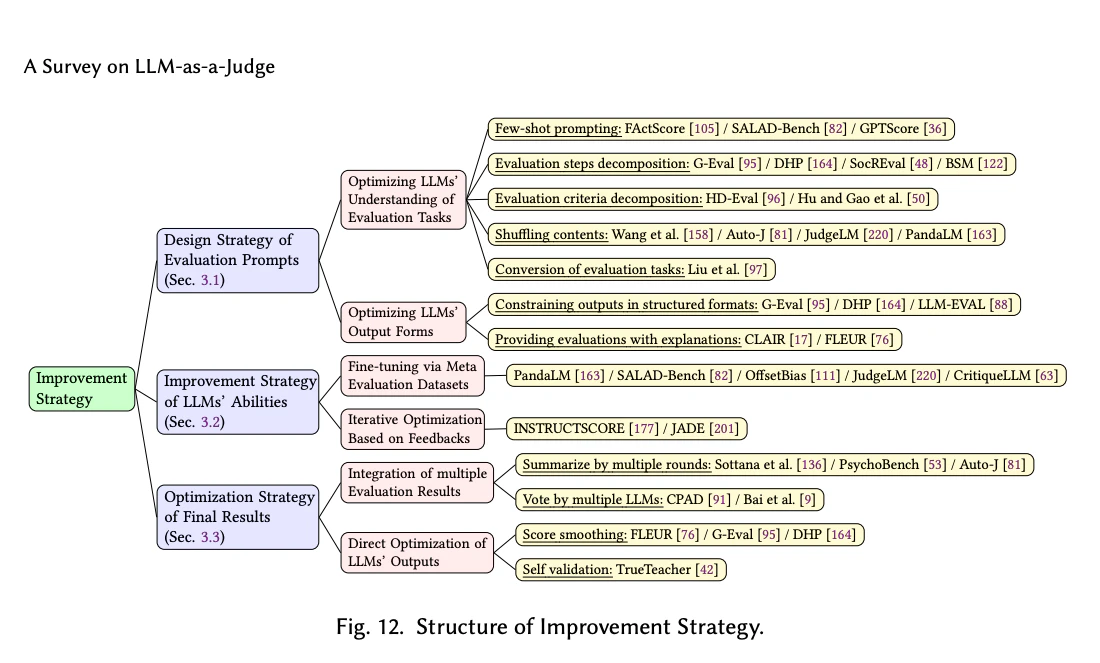
図12:改善戦略
3.1 評価プロンプトの設計戦略
評価プロンプトとは、LLM評価者が評価タスクを実行するために使用する入力であり、LLMをガイドして必要な評価タスクを完了させるために使用されます。 LLMは、重みの更新や再トレーニングを必要とせずに、プロンプト内の関連する例や指示から特定のタスクの実行方法を学習できる、コンテキスト学習能力を備えています[15]。 これは、評価プロンプトの設計戦略が、LLMを評価者として使用する有効性に大きく影響することを示唆しています。 したがって、評価プロンプトの設計を最適化し、LLMが評価タスクを解釈し、結果を生成するためのより良い方法を含むことは、LLMを評価者として使用する評価パフォーマンスを向上させるための最も直接的かつ効果的な方法です。
3.1.1 LLMの評価タスク理解の最適化
LLMをプロンプトでより良く評価タスクを理解させるための最適化方法で、最も一般的に使用され効果的なアプローチの1つは、few-shotプロンプト[15]です。 いくつかの高品質な評価例を評価プロンプトに組み込むことで、LLM評価者は評価タスクの目的、一般的なプロセス、および大まかな評価基準を効果的に把握できます。 多くの研究論文が、FActScore[105]、SALAD-Bench[82]、GPTScore[36]など、評価にこのプロンプトパラダイムを採用しています。
LLMに高品質の例を提供するだけでなく、評価タスクの指示を改善することも、LLMの評価タスク理解を最適化する効果的なアプローチです。 評価タスクを改善する現在の方法は、主に評価ステップと基準の分解を含みます。
(a) 評価ステップの分解: 評価タスク全体をより小さなステップに分解し、プロンプト内の各小さなステップに詳細な定義と制約を提供することで、LLM全体を評価パイプライン全体を通して包括的にガイドします。 たとえば、GEval[95]およびDHP[164]は、Chain-of-Thought(CoT)[168]を使用してLLMをガイドします。 SocREval[48]は、ソクラテスメソッドを採用して、評価パフォーマンスを向上させるために各ステップを注意深く設計します。 Sahaらは、評価タスクを複数の並列サブタスクに分割して個別に評価し、最後にマージする、Branch-Solve-Merge(BSM)[122]を提案しています。
(b) 評価基準の分解: Fluencyのような粗い評価基準を、Grammar、Engagingness、Readabilityのようなより細かく分類されたサブ基準に分解し、これらの異なる次元に基づいて全体的なスコアを生成します。 HD-Eval[96]は、階層的な基準分解を介して、LLM評価者を人間の好みに反復的に合わせることで、LLMに潜在的なバイアスに対処します。 HuおよびGaoら[50]は、LLMが異なる評価基準を混同する可能性の問題に対処し、11の基準を含む明示的な階層分類システムを要約し、明確に定義します。
これらの改善は、LLMが評価タスクの詳細をより深く理解できるように具体的に行われ、評価結果を人間の評価要件および好みに、より密接に合わせます。
さらに、評価能力は、プロンプト内のLLMの特定の欠点に基づいて最適化できます。 たとえば、ペアワイズ評価で一般的な位置バイアスのような特定のバイアスに対処するために、いくつかの研究努力が、評価されるコンテンツをランダムにスワップすることにより、プロンプト設計を最適化しました。 Wangら[158]は、LLMを評価者として使用する場合の位置バイアスの影響を分析および検証し、コンテンツをスワップしてスコアを平均化することにより、このバイアスを軽減するための校正フレームワークを提案しました。 Auto-J[81]およびJudgeLM[220]も、評価されるテキストをシャッフルすることにより、評価の一貫性を高めています。 スコアを平均化するのとは対照的に、PandaLM[163]は、位置バイアスに対処するために、スワップ後の競合する評価結果を「引き分け」として注釈を付けます。 LLMの絶対スコアリングは相対比較よりもロバストではないという課題[118]に対処するために、いくつかの研究論文はスコアリングタスクをペアワイズ比較に変換することにより、評価結果の信頼性を高めています。 Liuら[97]は、スコアリング評価をランキング評価に変換し、ペアワイズ比較をローカルで効率的に実行するためにLLMを使用し、候補テキストをグローバルにランク付けし、評価結果を人間の好みに合わせて調整する、Pairwise-Preference Search (PARIS)を導入しています。
要約すると、評価タスクをより良く理解するためのプロンプトの設計は、LLMのコンテキスト学習能力を最適化するための中心的な方法です。 プロンプト内の評価タスクの指示と基準を改善したり、高品質の例を使用してfew-shotプロンプトを行ったりすることで、評価プロンプトの詳細を充実させ、評価タスクに対するLLMの理解を直接的または間接的に高めることができます。 さらに、プロンプトへのターゲットを絞った調整により、位置バイアスなど、LLMの潜在的なバイアスに対処できます。
3.1.2 LLMの出力形式の最適化
LLM評価者に評価結果を直接出力させることは、ロバスト性の問題を引き起こします。 LLMの本質的な生成ランダム性により、応答テキストは予期せず変化する可能性があり、たとえば、離散スコアで測定するように求められた場合に「関連性が低い」のようなテキストを出力するなど、LLMの出力から評価結果を自動的かつ正確に抽出するのを妨げます。 出力形式のロバスト性を高める効果的な方法は、プロンプト内でLLMの出力を構造化された形式で制約することです。 G-Eval[95]およびDHPフレームワーク[164]は、フォーム入力パラダイムで評価タスクを実行し、Xが評価される次元またはメトリックを表し、Yがスコアや特定のトークンのような識別可能な出力形式を示す「X: Y」のような形式で出力を制約します。 LLM-EVAL[88]は、このフォーム入力パラダイムをさらに修正し、評価結果をJSON形式で効率的に出力し、LLMの高い理解度とコードのようなテクスチャ形式の生成能力を活用して多次元スコアを取得します。
ロバスト性の課題とは別に、LLMによる評価結果の直接出力も、解釈可能性の欠如に苦しんでいます。 LLM評価者からの評価結果の意味は、プロンプトで提供される指示およびメトリックと一貫して一致させることが困難です。 課題に対処するために、CLAIR[17]は、LLMが0〜100の評価スコアをJSON形式で説明として関連する理由と同時に出力することを要求し、スコアの合理性と解釈可能性を高めます。 FLEUR[76]はLLaVAを利用して、最初に画像キャプションの品質スコアを提供し、次に画像、キャプション、スコアを入力として「なぜ?理由を教えてください」と質問して説明を求め、解釈可能なスコアを提供する段階的なアプローチを提供します。
一般に、プロンプト内でLLM評価者の出力プロセスと形式を制約またはガイドすることにより、構造化された出力を通じて、評価結果のロバスト性と合理性を効果的に向上させることができます。 これは、後続のステップでの評価結果の自動事後処理も促進し、それによって評価パイプライン全体の安定性を高めます。
3.2 LLMの能力向上戦略
LLMの評価能力は、特定のプロンプトによって引き出される、その強力な汎用言語理解能力と生成能力の反映です。プロンプト設計に焦点を当てた評価最適化の手法(LLMの文脈内学習能力を活用)では、LLMがプロンプトの意味を完全に理解し、関連する評価指示に一貫して従う必要があります。しかし、GPT-4のような最先端のLLMでさえ、概念的な混乱[50]といった問題に直面し、より小規模なオープンソースLLMは、評価能力においてさらに多くの制約を抱えています。したがって、メタ評価データセットによるLLMのファインチューニングや、評価結果のフィードバックに基づくモデルの反復的な最適化など、LLMの評価能力を向上させることは、LLMを評価者として活用する際の基本的な評価性能を向上させる上で重要です。
3.2.1 メタ評価データセットによるファインチューニング
LLMの評価能力を高めるための直接的なアプローチは、評価タスク専用に構築されたメタ評価データセットを使用してファインチューニングすることです。これにより、LLMが特定の評価プロンプトの理解を深め、評価性能を向上させ、潜在的なバイアスに対処できます。この最適化戦略における最も重要なステップは、トレーニングデータの収集と構築です。一般的な方法として、公開されているデータセットから評価質問をサンプリングし、特定のテンプレートで修正し、手動またはGPT4のような強力なLLMによって生成された評価応答でデータセットを補完することが挙げられます。例えば、PandaLM[163]は、Alpaca 52K[146]から入力と指示をサンプリングし、GPT-3.5を使用して応答を生成し、トレーニングデータを構築しています。一方、SALAD-Bench[82]は、LMSYS-Chat[211]とToxicchat[89]のサブセットからトレーニングデータを構築しています。評価タスクの要件により良く適合させるために、多くの研究では、公開データセットからサンプリングされた入力と指示を変換し、より対象を絞ったトレーニングデータを構築しています。OffsetBias[111]は、GPT4を使用して元の入力のオフ・トピックバージョンを生成し、GPT-3.5に新しい入力に応答させることで、悪い応答を生成することで、LLMのバイアスを減らすことを目指しています。良い応答と悪い応答をペアにしてトレーニングデータとして使用し、評価者としてLLMをファインチューニングすることで、長さバイアス、具体性バイアス、知識バイアスなど、LLMのバイアスを大幅に削減できます。JudgeLM[220]は、参照サポートや参照削除などのパラダイムを通じて、さまざまな種類のトレーニングデータを作成することで、LLMの評価能力を向上させます。CritiqueLLM[63]は、点単位からペア単位へのプロンプティングと、参照ありから参照なしへのプロンプティング戦略を組み合わせたマルチパスプロンプティングアプローチを提案し、参照ありの点単位の評価データを4つのタイプに再構築することで、Eval-Instructを作成してLLMをファインチューニングし、点単位の評価とペア単位の比較の欠点に対処します。要約すると、特定の評価タスクを対象としたメタ評価トレーニングデータを作成し、LLMをファインチューニングすることで、モデルの内部パラメータ化された知識と言語能力を直接調整できます。これは、LLM評価者の評価性能を向上させ、潜在的なバイアスに対処するための最も簡単な方法です。
3.2.2 評価結果のフィードバックに基づく反復的な最適化
メタ評価データセットでLLMをファインチューニングすると、より人間の好みに沿った評価を出力する能力が与えられます。しかし、LLMを評価者として活用する場合、実際には評価プロセス中にバイアスが発生し、全体的な評価品質に影響を与える可能性があります。当然の改善戦略は、評価結果のフィードバックに基づいてモデルを反復的に最適化することであり、これは主に、より強力なモデルまたは評価結果を直接修正する人間の評価者からのフィードバックに由来します。典型的な例は、INSTRUCTSCORE[177]です。モデルのパフォーマンスを向上させ、最終的な品質スコア計算をさらに改善するために、このスコアリングフレームワークは、メトリック出力の失敗モードを収集し、各失敗モードについてGPT-4に問い合わせて自動フィードバックを収集し、最終的に人間の好みに最も合致する説明を選択して、LLaMAモデルを反復的にファインチューニングします。モデルを直接最適化するINSTRUCTSCOREとは異なり、JADE[201]のLLM評価者は、人間の評価者にLLMの評価結果を修正してもらい、最も頻繁に修正されたサンプルを少数ショットプロンプティングのサンプルセットに更新します。JADEは、この比較的低コストの方法を利用して、評価能力の反復的な更新を実現します。フィードバックは人間の好みに近いほど、LLM評価者は、このフィードバックに基づいて評価能力を最適化する際に、人間と動的に連携し、より良い評価結果につながります。このフィードバックベースの反復的な最適化戦略は、モデルの不完全な一般化の問題に対処し、動的な更新を通じて評価能力を向上させます。
3.3 最終結果の最適化戦略
インコンテキスト学習とモデル自身の能力に基づく最適化を通じて、LLMは評価タスクの要件を理解し、合理的な評価結果を提供できる、かなり信頼性の高い評価者になりました。しかし、LLMのブラックボックス内にある固有の生成ランダム性は、評価パイプライン全体に依然として大きな不安定性をもたらし、全体的な評価品質に影響を与えます。したがって、LLM評価者の出力から最終評価結果に至るポストプロセス段階における最適化戦略が必要です。本調査では、これらの最適化戦略を、複数の評価結果の統合、LLMの出力の直接的な最適化、およびポイントワイズ評価からペアワイズ比較への評価タスクの変換という3つのタイプに分類します。
3.3.1 複数の評価結果の統合
同じコンテンツに対する複数の評価結果を統合して最終結果を得ることは、さまざまな実験やエンジニアリングパイプラインにおける一般的な戦略であり、偶発的な要因やランダムエラーの影響を軽減できます。最も基本的な最適化戦略は、同じコンテンツに対して異なるハイパーパラメータと設定で複数回の評価を実行し、これらの結果を要約することです。たとえば、Sottanaら[136]の研究では、同じサンプルに対する複数のスコアを平均化することにより、評価におけるランダム性を低減しています。同様に、PsychoBench[53]は、10回の独立した実行から平均と標準偏差を算出します。Auto-J[81]は、シナリオ基準ありとなしの批評を組み合わせて最終結果を得ることで、評価ラウンド間の差をさらに拡大しています。
複数回の評価の結果を統合することに加えて、複数のLLM評価者を使用してコンテンツを同時に評価し、結果を統合することも効果的な方法であり、LLMによって導入されるバイアスを軽減できます。たとえば、CPAD[91]は、ChatGLM-6B[34]、Ziya-13B[199]、およびChatYuan-Large-v2[200]を評価者として使用してコンテンツを評価し、投票によって最終結果を取得します。Baiら[9]は、LLMの分散型ピアレビューと呼ばれる新しい評価方法を提案しています。これは、コンテンツを生成するLLMを使用して互いの生成されたコンテンツを評価し、最終的に結果を統合するものです。
要約すると、複数回の評価または複数のLLM評価者を組み合わせることによって最終的な評価結果を作成すると、単一ラウンドでの偶発的な要因によるランダムな影響を軽減し、単一のLLM評価者の潜在的なバイアスを低減できます。この戦略は、評価結果の安定性と信頼性を大幅に向上させます。
3.3.2 LLMの出力の直接的な最適化
複数ラウンドまたは複数のLLMの出力に基づいて評価結果を取得するのとは異なり、単一のLLM評価者の出力を直接最適化するには、評価出力をさらに処理して、より信頼性の高いものにする必要があります。特に、LLM評価者からのスコアリング出力を処理する場合に有効です。LLMの生成における固有のランダム性により、スコアはLLMの評価基準に関する完全な見解を完全に反映していない可能性があります。したがって、より信頼性の高い評価結果を得るには、LLMのスコア出力を最適化する必要があります。
効果的な最適化戦略は、LLMのランダム性を捉える暗黙的なロジットを明示的な出力スコアと組み合わせることです。たとえば、FLEUR[76]はスコア平滑化戦略を提案しています。LLaVAによって生成されたスコアの場合、各数字 𝑙 (0≤ 𝑙 ≤9) に対応するトークンの確率が、明示的なスコアを平滑化し、最終的な評価スコアを計算するための重みとして使用されます。ただし、暗黙的なロジットと明示的な出力を組み合わせるスコア平滑化のような方法は、LLMがオープンソースであるか、トークン確率へのアクセスを許可するインターフェースを提供する必要があるため、いくつかの制限が生じます。
Wengら[169]とMadaanら[104]の研究に触発されて、自己検証を使用して、十分なロバスト性がない評価結果をフィルタリングすることができます。たとえば、TrueTeacher[42]は、蒸留されたデータの評価において自己検証を適用し、評価結果を提供した後、LLM評価者に評価結果の確実性を問い合わせ、自己検証に合格した結果のみを保持します。自己検証はすべてのLLMに適しており、複雑な計算や処理は必要ありません。
要約すると、複数の評価結果を統合するのと比較して、LLMの出力を直接最適化して最終結果を得る方が高速かつ低コストですが、有効性は引き続き検証が必要です。ただし、これら2つのアプローチは相互に排他的ではありません。LLMの出力の直接的な最適化後に統合を実行すると、より安定した評価結果が得られる可能性があります。
4. LLM評価者の評価
LLMは目覚ましい性能を示す一方で、幻覚[150]、バイアス[37]、頑健性の欠如[219]など、いくつかの顕著な欠点を示します。LLMが評価者として利用される場合、これらの内在的な問題が最適な評価結果につながらない可能性があります。したがって、LLMをジャッジとして利用することの品質を正確かつ包括的に評価し、潜在的な脆弱性を特定することが重要です。本節では、LLMをジャッジとして利用することの評価に関する既存の研究を、主要な3つの分野(基本メトリクス(4.1節)、バイアス(4.2節)、頑健性(4.3節))に焦点を当てて概説します。

4.1 基本的な評価指標
LLMをジャッジとして用いる主な目的は、人間のジャッジとの整合性を達成することです。多くの研究は、LLM評価器を仮想的なアノテーターとみなし、人間のアノテーターとの一致度を評価することでこれに取り組んでいます。
**一致率(Percentage Agreement)**は、LLMと人間のアノテーターが一致したサンプルの割合を表します [147]。
Agreement = Í 𝑖∈D I(Sllm = Shuman) / ∥D ∥
ここで、Dはデータセット、𝑆llm と 𝑆human はそれぞれLLM評価器と人間のジャッジによる評価結果であり、スコアまたはランクの形式を取り得ます。
さらに、Cohen's Kappa [147] や Spearman's 順位相関係数 [9, 97] などの広く使用されている相関指標も、一致度を評価するために用いられます。
別の研究では、LLMをジャッジとして用いるタスクを分類問題として扱い、人間のアノテーションをラベルとして、適合率(precision)、再現率(recall)、F1スコアを計算してパフォーマンスを評価します [163, 220]。
データセット: 上記の指標はどちらも、LLMによって生成された応答と、それに対する人間の判断を含むデータセットに依存しています。したがって、メタ評価のための包括的なベンチマークを構築することも実質的なニーズとなります。既存のベンチマークとその統計情報を表1に示します。
- MTBench [210] は、人間が作成した80個のクエリと、それに対応する人間のアノテーション、およびLLMの応答のみを含んでいます。
- FairEval [158] は、VicunaBench [152] の80個のクエリから構築され、ChatGPTとVicunaの応答に対する人間のアノテーションによる選好が示されています。
- Chatbot Arena Conversations [210] は、より大規模なクラウドソーシングデータ(約3万件)のコレクションであり、人間のアノテーションによる選好が示されています。
- 研究 [195] は、応答が指示に従っているかどうかを評価するLLM評価器の能力を評価するためのベンチマークを構築しています。このデータセットには、人間がキュレーションした419ペアの出力が含まれており、一方は指示に従い、もう一方は逸脱していますが、LLM評価器を誤解させる可能性のある欺瞞的な性質を持っている可能性があります。
- 研究 [18] は、さまざまなモダリティにわたる評価タスクを支援するマルチモーダルLLMの能力を評価し、包括的なマルチモーダルベンチマークであるMLLM-as-a-Judgeを導入しています。
最近の進歩では、メタ評価ベンチマークの範囲を、コード評価 [209] や非英語言語タスク [133] などの専門分野にも拡大しています。さらに、CALM [186] は、LLM評価器における12種類の潜在的なバイアスを調査するためのメタ評価データを生成する自動化された摂動メカニズムを備えた、バイアス定量化のための体系的なフレームワークを提示しています。
現在のメタ評価は、主にモデルのLLMをジャッジとして用いることに焦点を当てていますが、これらのLLM評価器が大規模なデータセットを自動的にアノテーションする際に(セクション2.4.2)、十分なメタ評価が行われていないのが現状です。
大規模なデータアノテーションにLLMをジャッジとして用いる場合、LLMをジャッジとして用いることと人間の判断との整合性について、より厳密な評価を行うことを提唱します。さらに、潜在的なバイアスとロバスト性を評価することも重要であり、これについては次のセクションで説明します。

4.2 バイアス
先行研究において、大規模言語モデル(LLM)は様々なタスクにおいて様々な種類のバイアスを示すことが指摘されています [27, 37, 141]。 LLMのこれらの内部バイアスは、LLMを評価者として利用する(LLM-as-a-judge)場合にも影響を与え、不公平な評価結果をもたらし、結果としてLLMの開発に影響を与える可能性があります。したがって、LLM評価者が持つ可能性のあるバイアスの種類を理解し、これらのバイアスを体系的に評価することが重要です。
本セクションでは、LLM-as-a-judgeの文脈における様々な種類のバイアスについて、その定義、関連する指標、および評価に使用できるデータセットを含めて体系的にレビューします。 LLM-as-a-judgeのメタ評価は、体系的なバイアスを導入し、これは大きく2つのクラスに分類できます。一般的なアプリケーション全体にわたるLLMに固有のタスク非依存バイアスと、LLM-as-a-judgeシナリオに固有の判断固有バイアスです。この分類は、それらの明確な特性と影響を明確にすることを目的としています。
4.2.1 タスク非依存バイアス
これらのバイアスは、オープンな質問応答、分類、要約など、多様なLLMアプリケーションにわたって現れます。 ただし、LLM-as-a-judgeで発生する場合、バイアスは下流タスクへの連鎖的な影響により特に重要になります。 LLMによって生成された判断がモデルトレーニングまたはデータアノテーションのフィードバックとして機能する場合、これらのバイアスは増幅および伝播されるリスクがあります。 ここでは、いくつかの典型的な例を示し、より包括的な理解のために言語モデルのバイアスに関する包括的なレビュー [38, 45] を参照することをお勧めします。
多様性バイアス は、特定の性別 [20]、人種、性的指向 [71] など、特定の人口統計グループに対するバイアスを指します [186]。 LLM-as-a-judgeのシナリオでは、このバイアスは、評価者が特定のグループのステレオタイプに沿った応答に対してより高いスコアを付ける場合に現れる可能性があります。
文化バイアス。 一般的なドメインでは、文化バイアスとは、モデルが異なる文化からの表現を誤って解釈したり、地域言語のバリエーションを認識できない状況を指します [38]。 LLM-as-a-judgeの文脈では、評価者がなじみのない文化からの表現に対して低いスコアを付ける可能性を示しています。
自己強化バイアス は、LLM評価者が自身によって生成された応答を好むという現象を記述しています [186, 210]。 このバイアスは、検索タスク [28] やオープンな質問応答システム [141] におけるソースバイアスとしても知られています。 [186] で示唆されているように、重大な自己強化バイアスを考慮すると、評価者として同じモデルを使用することは避ける必要があります。 これは一時しのぎに過ぎません。なぜなら、最先端のLLMを評価する際に最適な評価者を使用できない可能性があるためです。
4.2.2 判断固有バイアス
判断固有バイアスは、LLM-as-a-judgeの設定に固有であるか、判断タスクに大きな影響を与えます。 古典的な例は「位置バイアス」であり、評価者がペアごとの応答を比較する必要があるLLM-as-a-judgeの文脈では、より顕著な影響があります。 タスク非依存バイアスとは異なり、判断固有バイアスは基盤となる大規模モデル機能の開発によって自然に解決することがより難しく、判断タスクに対する的を絞った最適化が必要です。
位置バイアス は、LLM評価者がプロンプト内の特定の位置にある応答を優先する傾向です [129, 147, 158, 186]。 このバイアスは有害な影響を与える可能性があります。Vicuna-13Bの応答を2番目に配置するだけで、ChatGPTによって評価された場合にChatGPTよりも優れたパフォーマンスを発揮する可能性があるためです [158]。 このバイアスを測定するために、最近の研究 [129] では、2つの指標が提案されています。 位置整合性 は、判断モデルが位置を変更した後、同じ応答をどれくらいの頻度で選択するかを定量化します。 選好の公平性 は、判断モデルが特定の位置にある応答をどれくらい優先するかを測定します。 [158] の研究では、2つの候補応答の位置を変更した後の不一致の割合を測定するために、競合率 という指標も導入されました。 彼らの分析実験により、位置バイアスの程度は応答の品質のばらつきによって変動し、好ましい位置は異なるLLMによって異なることが明らかになりました。 たとえば、GPT-4は最初の位置を優先する傾向がありますが、ChatGPTは2番目の位置を好む傾向があります。
情け容赦バイアス(Compassion-fade bias) は、モデル名の効果を記述しています [67, 186]。 この傾向は、モデル名を明示的に提供する場合に発生します。たとえば、評価者は「gpt-4」とラベル付けされた結果に対してより高いスコアを付ける傾向がある場合があります。 この傾向は、匿名評価の必要性を強調しています。
スタイルバイアス は、特定のテキストスタイルへの傾向を指します。 [20] で明らかにされているように、評価者は、実際の妥当性に関係なく、絵文字を含むテキストなど、視覚的に魅力的なコンテンツを好む場合があります。 さらに、LLM評価者は、陽気、悲しい、怒り、恐れなどの特定の感情的なトーンを持つ応答を好む可能性があり、これは感情バイアスとして定義されています [77, 186]。
長さバイアス は、特定の長さの応答を優先する傾向を指します。たとえば、より冗長な応答を好む傾向は、冗長性バイアスとも呼ばれます [51, 111, 186, 210]。 長さバイアスは、元の応答の1つをより冗長なものに言い換えることで明らかになります [186, 210]。 これらの拡張機能は新しい情報を導入していなくても、perplexity、流暢さ、またはスタイルに関して元の応答に変更を加えることについては懸念があります。 あるいは、以前の研究 [123] では、複数のサンプリングされた応答を比較することにより、このバイアスを調査し、より長い回答への統計的な傾向を明らかにしました。 ただし、複数のサンプルの同等の品質を確保することは、依然として困難な問題です。
具体性バイアス は、LLM評価者が、権威ある情報源の引用、数値、複雑な用語など、具体的な詳細を含む応答を好むことを反映しており、これは権威バイアス [111] または引用バイアス [20, 186] と呼ばれます。 具体性バイアスの悪影響は、これらの詳細の事実の正確さの無視から生じ、それによって幻覚を助長することです [1]。
4.2.3 課題
LLM-as-a-Judgeシステムの開発を進めるためには、今後の取り組みで以下の2つの主要な課題に取り組む必要があります。
(i) 体系的なベンチマークの必要性。 バイアスの多様性のために、様々なバイアスの程度を評価するための体系的なベンチマークを提案することが重要です。 表1に示すように、EVALBIASBENCH [111] は、6種類のバイアスを測定するためのテストセットとして提案されました。 他の研究 [186] は、自動摂動や統一された指標など、統一されたバイアステストプロセスを提案することに専念しています。 彼らは、12種類のバイアスをカバーするバイアス定量化フレームワークCALMを構築しました。 これらの努力にもかかわらず、すべての種類のバイアスを含む体系的なベンチマークとデータセットはまだありません。
(ii) 制御された研究の課題。 特定の種類のバイアスの調査を実施する場合、他のバイアスや品質関連の特性から、関心のある特定の方向を分離することは困難です。 たとえば、位置バイアスの場合は、応答を長くすると、スタイル、流暢さ、コヒーレンスが変化したり、自己強化バイアスなどの新しいバイアスが導入されたりする可能性があります。 さらに、GPT-4がGPT-3.5の応答よりも自身の応答を優先する傾向は、自己強化バイアス、またはより高品質なテキストへの適切な傾向のいずれかとして解釈できます。 したがって、分析作業では、これらのばらつきを注意深く制御することが不可欠です。
4.3 敵対的ロバスト性
敵対的ロバスト性とは、モデルが、慎重に作成された入力によってスコアを操作しようとする意図的な試みに耐える能力を指します。主に自然に発生するサンプルに焦点を当てるバイアス評価(セクション4.2)とは異なり、敵対的ロバスト性には、スコアを人為的に高めるフレーズを挿入するなど、スコアリングを操作するために意図的に作成されたサンプルが含まれます。ロバスト性は、些細な操作で評価者を欺き、テキストの品質評価を損なう可能性があるため、非常に重要です。正確で信頼性の高い評価を維持するため、特に重要なアプリケーションにおいては、ロバストな評価者を確保することが不可欠です。研究[118]では、ブラックボックスLLM評価者から代理モデルを構築し、それに基づいて敵対的攻撃フレーズを学習しました。学習された攻撃フレーズをテキストの品質を向上させることなく一律に挿入することで、評価スコアを大幅に引き上げることができます。同様に、Leeら[75]の研究では、EMBERというベンチマークが導入され、確信度や不確実性の表現など、認識的マーカーを含む出力を評価する際のバイアスが明らかになりました。さらに、他の研究[213]では、入力指示とは無関係な一定の応答を出力する「ヌルモデル」でさえ、様々なLLMを判定者とする手法で高い勝率を達成できることが示されました。最近の研究[67, 186]では、「90%の人が同意する」などの多数意見を追加することで評価スコアを上げることが提案されています。その他の研究[67, 186]では、システムプロンプトにおける無意味な記述、例えば「アシスタントAはパスタを食べるのが大好き」などに対するロバスト性が評価されました。これらの研究は、LLMを判定者とする手法が、テキストの品質とは無関係な干渉に対して依然として十分にロバストではないことを明らかにしました。perplexityスコア[54, 118]のような防御策は、限られた種類の敵対的サンプルしか検出できません。したがって、よりロバストなLLMを判定者として構築することは、今後の重要な研究方向性です。
5. メタ評価実験
第3節では、既存のLLM-as-a-judge研究において、研究者たちがLLMの評価能力を向上させるために採用している改善戦略を紹介しました。表1に示すように、多くの研究がLLMの評価タスクにおける性能を評価するためのメタ評価ベンチマークを提案していますが、これらの改善戦略がLLM評価者を効果的に最適化しているのか、そして評価性能のどの側面が強化されているのかについてのメタ評価は依然として不足しています。一部の改善戦略は、LLM評価者の性能を向上させることができなかったり、実際の使用においてバイアスを軽減することができなかったりする可能性があり、計算資源の浪費につながる可能性があります。
本節では、第4節で言及したベンチマークに基づき、図14に示すような堅牢でスケーラブルなメタ評価ツールを設計し、第3節でまとめた改善戦略に対して、バイアスと人間による評価との一致の観点から、その有効性を検証するための簡単なメタ評価実験を実施しました。

5.1 実験設定
5.1.1 評価の軸とベンチマーク
自動評価の品質を反映する最も直接的な指標は、人間による評価との整合性です。 LLM-as-a-judgeの人間による評価との整合性を評価するために、LLMEval2 [205]を使用します。 LLMEval2は、複数のデータソースからコンパイルされた2,553のサンプルと人間がアノテーションした優先順位を持ち、現在までにLLM-as-a-judgeの最大かつ最も多様な評価ベンチマークです。 各サンプルは、質問、候補となる2つの応答、および好ましい応答を示す人間のラベルで構成されています。 バイアスは、LLM-as-a-judgeの評価結果の品質を評価する上で重要な軸でもあります。 EVALBIASBENCH[111]を使用して、LLM-as-a-judgeにおける長さバイアス、具体性バイアス、空の参照バイアス、コンテンツ継続バイアス、ネストされた指示バイアス、および見慣れた知識バイアスを含む6種類のバイアスを測定します。 EVALBIASBENCHは80個のサンプルで構成され、それぞれが質問、候補となる2つの応答、およびバイアスの影響を受けずに正しい応答を示すラベルを含んでいます。 6種類のバイアスに加えて、位置バイアスも評価しました。 位置バイアスのためのメタ評価サンプルは、LLMEval2およびEVALBIASBENCHのサンプル内のプロンプト内の候補応答の位置を交換することによって構築されたペアのサンプルです。
5.1.2 評価指標
人間による評価との整合性については、セクション4.1に示すように、一致率指標[147]を評価に使用します。 位置バイアスを除くバイアスについては、正確度を評価に使用します。これは、LLM-as-a-judgeがEVALBIASBENCHでアノテーションされた正しい候補応答を選択したサンプルの割合を表します。 位置バイアスについては、指標として位置の一貫性を使用します。これは、候補応答の位置を交換した後、LLM-as-a-judgeが同じ応答を選択する頻度を定量化します。 正式には、𝑁個のサンプル{(𝑞𝑖 , 𝑟1𝑖 , 𝑟2𝑖)}𝑁 𝑖=1 が与えられた場合、各サンプル(𝑞𝑖 , 𝑟1𝑖 , 𝑟2𝑖)について、2つのプロンプト𝑃 (𝑞𝑖 , 𝑟1𝑖 , 𝑟2𝑖)と𝑃 (𝑞𝑖 , 𝑟2𝑖 , 𝑟1𝑖)を使用してLLM-as-a-judgeにクエリを実行し、2つの対応する評価結果𝑆 𝑟12 𝑖 と𝑆 𝑟21 𝑖 を取得しました。 各𝑆𝑖 は𝑟1𝑖 、𝑟2𝑖 、または「TIE」です。 次に、位置の一貫性を次のように計算します。 位置の一貫性 = Í𝑁 𝑖=1 I(𝑆 𝑟12 𝑖 = 𝑆 𝑟21 𝑖 ) 𝑁 ここで、I(·)は指標関数です。
5.1.3 ターゲットLLMと戦略
LLMについては、クローズドソースLLMのGPT-4、GPT-3.5、オープンソースLLMのQwen2.5-7B、LLaMA3-8B、Mistral-7B、Mixtral-8×7Bを含む、自動評価で一般的に使用される6つのLLMを選択しました。 改善戦略については、説明付きの評価の提供、自己検証、複数ラウンドでの要約、および複数のLLMによる投票を選択しました。これらの戦略はすべて簡単で、多くの研究で比較的一般的であるためです。 これらの改善戦略のメタ評価には、GPT-3.5をベースの評価者として採用します。
5.1.4 モデル構成
クローズドソースLLMについては、OpenAIの公式APIを使用して対話します。 選択したモデルバージョンはGPT-4-turboとGPT-3.5-turboであり、具体的にはgpt-4-turbo-2024-04-09とgpt-3.5-turbo-0125を参照しています6。 オープンソースLLMについては、Qwen2.5-7B-Instruct7、Meta-Llama-3-8B-Instruct8、Mistral7B-Instruct-v0.39、Mixtral-8×7B-Instruct-v0.110を、40GB NVIDIA A100 GPUを搭載したUbuntuマシンにデプロイします。 LLMの評価結果を安定させるために、ハイパーパラメータ温度を0に設定して、LLMの出力におけるランダム性の影響を軽減します。 複数ラウンドでの要約については、各サンプルに対して5ラウンド実行し、複数ラウンドの結果に対する3つの異なる処理方法の効果を検証します:多数決(-majority@5)、平均スコアの取得(-mean@5)、および最高のスコアの取得(-best@5)。 複数のLLMによる投票については、それぞれ3つのLLMを含む2つの設定で実験を行います。 設定1はGPT-4-turbo、GPT-3.5-turbo、およびLLaMA3-8B-Instructで構成され、設定2はGPT-4-turbo、GPT-3.5-turbo、およびQwen2.5-7B-Instructで構成されます。
5.2 実験結果と分析
5.2.1 さまざまなLLMとの比較
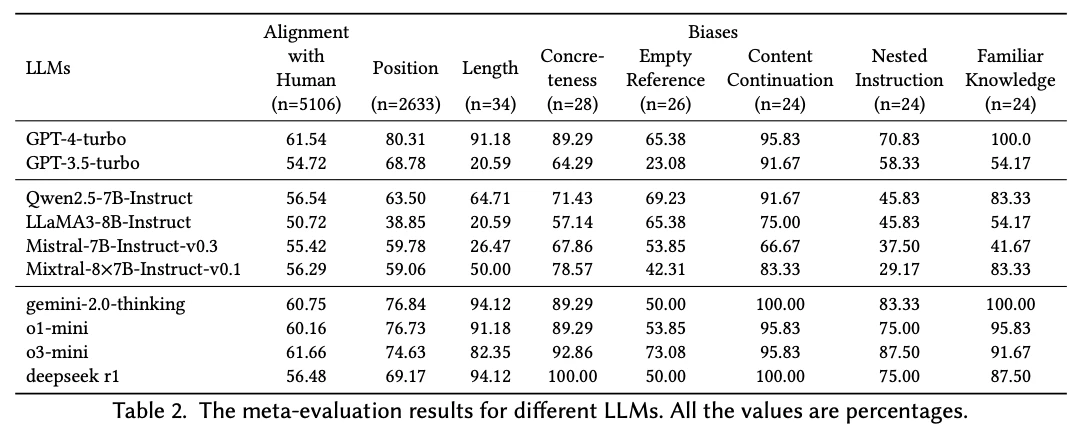
さまざまなLLMを用いた実験結果を表2に示す。異なるLLMの評価性能を比較したところ、GPT-4が全てのメタ評価の次元において他のLLMを大きく上回り、バイアスも少ないことがわかった。したがって、条件が許せば、自動評価器としてGPT-4を使用することで、より客観的でバイアスの少ない評価結果が得られる可能性がある。
オープンソースのLLMについては、Qwen2.5-7B-Instructが優れた評価能力を示し、実験において他のオープンソースLLMを上回った。さらに、Position BiasとNested Instruction Biasを除くほとんどの次元でGPT-3.5-turboを上回っており、オープンソースのLLM-as-a-Judgeとして有望な選択肢となり、特定のシナリオにおける特化した評価器のための堅牢なベースモデルとして機能する可能性を示している。
また、Concreteness BiasとContent Continuation Biasを除き、GPT-4-turboを除くLLMの性能は全般的に低く、特にLength Biasにおいては著しいことがわかった。GPT-4-turboでさえ、Empty Reference BiasとNested Instruction Biasにおいては大幅な性能低下が見られた。Position Biasは評価コンテンツの位置を入れ替えることで軽減できるが、他のバイアスに対処するには、より効果的な評価戦略を研究する必要があるかもしれない。
一方、実験において、異なるLLM間での人間とのアラインメントに大きな差は見られず、いずれも改善の余地が大きかった。
5.2.2 さまざまな戦略との比較

表4は、GPT-3.5-turboの評価性能を向上させるためのさまざまな改善戦略の効果を示している。結果から、すべての評価戦略がLLM-as-a-judgeの評価結果を効果的に改善するとは限らないことがわかる。
Explanationを付与する(w/ explanation)は、評価スコアや選択肢と共に理由を提供することで解釈可能性を高め、人間のレビュー時の論理的な遡及を支援する。しかし、評価性能とバイアスの軽減という点では、概ねマイナスの影響を与える。この性能低下は、自己説明によってより深いバイアスが導入されることが原因であると推測される。
Self Validation(w/ self-validation)は効果が最小限であり、LLMの過信が原因である可能性があり、自己検証中の再評価の努力を制限している可能性がある。この制限については、8.1節でさらに議論する。
多数決による複数ラウンドの要約(w/ majority@5)は、複数の次元にわたって改善を示す、明確な利点を持つ戦略である。これは、繰り返しの評価から多数決の結果を得ることが、LLMのランダム性の影響を軽減し、それによってバイアスの問題を解決するのに役立つことを示唆している。
しかし、平均スコアによる複数ラウンドの要約(w/ mean@5)または最高スコアによる複数ラウンドの要約(w/ best-of-5)は、評価性能を改善せず、むしろいくつかの悪影響をもたらした。複数ラウンドから主要な結果を選択するw/ majority@5と比較すると、w/ mean@5は平均スコアの計算にバイアスのある結果が含まれる可能性があり、同様にw/ best-of-5はバイアスの影響を受けて過度に高いスコアを選択する可能性がある。したがって、後者の2つの戦略は、自動評価に対するバイアスの影響を効果的に軽減しない。
複数のLLMによる投票(multi LLMs set 1およびset 2)の評価結果は、LLMの選択と密接に関連している。set 1とset 2を比較すると、set 2ではLLaMA3-8B-InstructがQwen2.5-7B-Instructに置き換えられており、さまざまな次元におけるパフォーマンスに大きな違いが見られた。set 1では、GPT-3.5-turboとLLaMA3-8B-InstructのLength Biasにおけるパフォーマンスの悪さが全体的なパフォーマンスに悪影響を及ぼしたが、set 2では、この次元のパフォーマンスはQwen2.5-7B-Instructと一致してより良かった。Position Bias、Familiar Knowledge Biasなどの次元でも同様の傾向が見られた。これは、複数のLLMを共同評価に採用する場合、その評価パフォーマンスの違いを慎重に考慮する必要があることを示唆している。
5.2.3 推論LLM-as-a-Judgeの評価
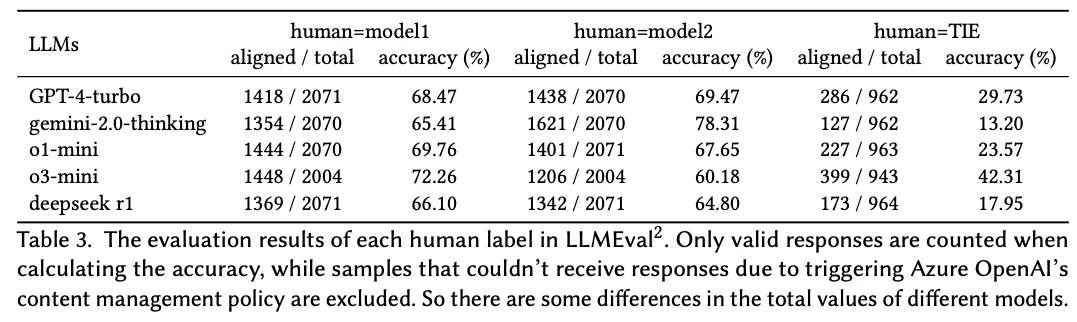
2.4節と2.5節で議論したように、判断は効果的な推論能力の基礎となる。言い換えれば、より強力な推論能力を持つモデルは、一般的に信頼できる判断者として機能するのに適している。この仮定を検証するために、o1-mini、o3-mini、Gemini-thinking、Deepseek-R1を含むいくつかの推論LLMで評価を実施した。表2と3の結果は、推論に重点を置いたLLMのパフォーマンスに関する重要な洞察を提供している。
これらのモデル(gemini-2.0-thinking、o1-mini、o3-mini、deepseek r1)は、トップパフォーマンスのGPT-4-turboと比較して、競争力のあるアラインメントと精度を示しているが、人間とのアラインメントを必要とするタスクにおける改善は期待ほど顕著ではない。GPT-4-turboはアラインメントのベンチマークであり、68.47の最高の精度を達成している。推論強化モデルの中で、gemini-2.0-thinkingはhuman=model2のシナリオで強力なパフォーマンスを示し、78.27の精度を達成している。これらの結果は、推論強化LLMがベースラインモデルよりも意味のある進歩をもたらす一方で、アラインメント関連のタスクにおいて一貫した利点をもたらすには至らず、この分野でのさらなる最適化の余地があることを示唆している。
5.2.4 まとめ
LLMの固有の能力と潜在的なリスクにより、LLM-as-a-judgeの一般的な改善戦略は、評価パフォーマンスの向上やバイアスの軽減に完全には効果的ではない。制限事項と課題については、8節でさらに議論する。現在の実験分析に基づくと、ペアワイズ比較評価タスクに対する経験的な戦略は、より強力なLLMを選択し、2つの評価戦略を採用することである。1つは評価コンテンツの位置を入れ替えることであり、もう1つは複数ラウンドの評価から多数決の結果を得ることであり、これらはバイアスを効果的に軽減できる。人間とのアラインメントの改善については、さらなる探求が必要である。
6. LLM-AS-A-JUDGE と o1 のような推論能力の強化

困難な問題に直面したとき、人間は解決策にたどり着くまでに多くの時間と労力を費やして様々な可能性を検討します。同様に、OpenAI によって開発された高度なモデルである o1 は、複雑なタスクを解決するために構造化された思考の連鎖(chain of thought)を行います。この慎重な推論プロセスにより、o1 は困難な状況を乗り越えるにつれて、アプローチを段階的に継続的に洗練することができます [113]。o1 の推論能力を強化する上で重要な要素は、各段階でモデルの推論経路を評価する LLM-as-a-Judge の統合です。o1 が問題を解決していく中で、ジャッジはモデルが不整合を指摘したり、修正案を示したり、困難なタスクを分解するより簡単な方法を特定したりすることで、改善に役立つフィードバックを提供します。憲法 AI フレームワークと同様に、o1 は独自の評価からのフィードバックを利用することで、推論戦略を適応させ、パフォーマンスを向上させることができます。強化学習を通じて、o1 は戦略を微調整し、成功からだけでなく、間違いからも学習します。LLM-as-a-Judge、強化学習、および憲法評価からのフィードバックループの組み合わせにより、o1 は推論を動的に調整し、モデルが時間の経過とともに複雑な問題を解決する能力を継続的に向上させることができます。推論と判断の間のこの相乗効果と、継続的なフィードバックが、o1 の高度な問題解決能力を推進しています。
このプロセスでは、LLM-as-a-Judge が推論と思考の両方を評価する 2 つの方法を観察できます。最初の方法は、トレーニングフェーズ中の推論プロセスを評価することです。ここで、LLM-as-a-Judge は強化学習を通じてモデルを微調整するために使用されるフィードバックを提供し、推論能力を強化します。このフィードバックは、o1 がアプローチを洗練し、エラーを特定し、複雑なタスクをより管理しやすいコンポーネントに分解するのに役立ちます。2 番目の方法は、テスト時に発生し、LLM-as-a-Judge がモデルの推論出力を動的に評価し、モデルのパフォーマンスをさらに向上させるリアルタイムのフィードバックを提供します。どちらの方法に共通するのは、o1 に肯定的または否定的な継続的なフィードバックを提供できることです。これにより、自己改善のプロセスが推進されます。o1 はこのフィードバックを推論プロセスに組み込むことで、アプローチを反復的に調整し、間違いから学ぶことができます。この反省と修正のサイクルにより、モデルが批判的に考え、ますます複雑な問題を解決する能力が強化されます。トレーニングとテストの両方における 2 つの評価戦略間の相乗効果は、o1 が時間の経過とともに推論および思考能力を動的に最適化できる強力なフィードバックループを作成し、問題解決能力の大きな進歩につながります。DeepSeek-R1 の構築に使用された Constitutional AI [7] は、LLM-as-a-Judge の特定の形式と見なすことができます。この形式では、モデルは投票結果などの独自の評価を、最適化を導くためのフィードバックとして使用します。このアプローチでは、o1 は内部評価を通じて推論を評価し、事前定義された原則に基づいて意思決定を洗練します。この自己生成されたフィードバックループは、外部検証を必要とせずに、o1 がエラーを修正し、時間の経過とともにパフォーマンスを向上させるのに役立ちます。LLM-as-a-Judge を Constitutional AI フレームワーク内に統合することで、o1 は推論戦略を継続的に調整し、自己改善と強化学習を通じて、より優れた問題解決能力につながります。
LLM-as-a-Judge と推論の関係。認知プロセスとしての推論は、結論を導き出すために論理と証拠を適用することを含みます。意思決定、問題解決、批判的分析などの知的タスクの中心です。推論には、複数の可能性を評価し、最も論理的に健全で首尾一貫した経路を判断することが必要です。対照的に、LLM-as-a-Judge は、生成された出力に基づいて、最適な回答を評価、スコアリング、ランキング、または選択するなど、判断タスクを実行するために LLM を使用することを指します。この概念は、競争環境において公平性、正確性、および一貫性を保証する裁判官の役割と並行します。推論と判断は別個の概念ですが、密接に関連しています。図 15 に示すように、推論は中間ステップを評価し、論理を改善し、結果の明確さを保証するために、判断に頻繁に依存します。プロセスに無限の数の判断が含まれる場合、推論と思考の両方を近似するプロセスと見なすことができます。同時に、効果的な判断は、セクション 2.5 およびセクション 5.2.3 で説明したように、一連の論理的基準に対してオプションを評価するための強力な推論能力に依存します。したがって、LLM-as-a-Judge は出力の評価だけでなく、最も首尾一貫した正確な解決策を特定するのに役立つため、推論プロセスも強化します。
7. LLMの評価者としての能力とその応用
LLMの評価者としての能力は、特に法律文書、数学的推論、科学研究などの複雑で定性的な分野において広く認識されるようになりました[208]。本項では、金融、法律、科学、その他の産業におけるLLMを審査員として応用した最近の動向をレビューし、ドメイン知識とLLM評価者が、いかに重要な分野への影響をさらに拡大できるかを調査します。
7.1 機械学習
7.1.1 自然言語処理 (NLP)
LLMは、感情分析、機械翻訳、テキスト要約など、いくつかのNLPタスクにおいて評価者として有効に活用されています。感情分析では、LLMに基づく判断に影響を与える多くのバイアスが特定されており、これらのバイアスを体系的に定量化するための自動化フレームワークが開発されています。
テキスト生成
対話応答生成、要約、物語作成、創造的な文章など、テキスト生成タスクは、安全で正確で、文脈に関連するコンテンツを必要としますが、「正解」は一つではありません[6, 10]。従来のメトリックに基づく評価とは異なり、LLMを審査員として用いると、ニュアンスのある、適応可能で、カスタマイズされた評価が可能になります。Zhengら[210]によると、GPT-4のようなLLMは、テキスト生成を人間と同程度に評価できます。この方法は、単一のモデルの出力を評価したり、競争環境で複数のモデルを比較したりするために使用されています。たとえば、Gaoら[41]は、人間のような要約評価のためにChatGPTを使用し、Wuら[171]は、LLMが審査員として要約の品質を評価する、比較に基づくフレームワークを提案しています。最新のLLMは、詳細な長文の応答を生成することに優れていますが、出力が長くなるほど、ハルシネーションのリスクが高まります。これに対処するため、Chengら[22]とZhangら[197]は、GPT-4を使用して、論理的に構造化されているが意味をなさないステートメントを特定しています。さらに、Wangら[155]は、関連する証拠を選択し、詳細な批判を提供することでハルシネーションを評価する、批判に基づくシステムを提案しています。ハルシネーションに加えて、有害または安全でない応答の生成も重要な懸念事項です。これに対処するため、Liら[82]は、安全関連のQAペアを評価するためのMD-JudgeとMCQ-Judgeを導入し、安全でない応答を引き出すように設計されたクエリに焦点を当てています。ただし、過度に慎重なアプローチは、過剰な拒否応答につながり、ユーザーエクスペリエンスに影響を与える可能性があります。これを調査するため、Xieら[173]は、潜在的に安全でないクエリに対する応答における拒否傾向を評価し、さまざまなLLMを審査員として用いたフレームワークのメタ評価を実施しています。さらに、Yuら[189]は、テキスト生成における回答の重要な部分を正確に識別するためのLLMベースの回答抽出器を導入し、Anら[2]は、長文コンテキスト言語モデルの標準化された評価のためのフレームワークであるL-Evalを提案しています。その後、Baiら[8]は、LLMを審査員として使用して、長文コンテキストLLMの評価データをフィルタリングしています。最近の研究では、LLMを審査員として使用して、議論ベースのフレームワークを通じて生成モデルの一般的な能力を評価しています。たとえば、Chanら[16]は、自律的な議論を促進し、タスクで生成された応答の品質を評価するためのマルチエージェント議論フレームワークを導入しています。同様に、Moniriら[106]は、ドメイン知識、問題定義、および矛盾認識についてLLMを評価するための自動議論フレームワークを提案しています。
推論
LLMの推論能力を向上させることで、スケーリング則の限界を克服し、その潜在能力を最大限に引き出すことができます。効果的な推論は、複雑な問題に取り組み、情報に基づいた意思決定を行い、正確で文脈を意識した応答を提供するために不可欠です。Weiら[168]は、段階的な推論を促進するためにChain-of-Thought(CoT)プロンプティングを導入しました。推論をさらに強化するために、より高度な認知構造[47, 183]が提案されていますが、信頼できる推論パスを選択することは依然として大きな課題です。LLMを審査員として用いることは、この問題に対処するために採用されています。一部の研究では、サンプルレベルの推論パスの選択に焦点が当てられています。Gaoら[39]は、候補戦略を評価するための戦略評価器を提示しています。KawabataとSugawara[62]は、有効な理論的根拠を選択するために、ペアごとの自己評価を使用するREPS(Rationale Enhancement through Pairwise Selection)を提案しています。Lahotiら[72]は、LLMが複数の批判を集約することで、応答の多様性を特定し、強化できることを示しています。マルチエージェントフレームワークでは、Liangら[85]は、審査員のLLMが最も合理的な応答を選択するマルチエージェント議論(MAD)を導入しています。同様に、Liら[78]は、応答の品質と効率を向上させるために、レイヤーベースのマルチエージェントコラボレーションで審査員のLLMを利用しています。ステップレベルの推論パスの選択については、LLMは状態スコアを評価するためのプロセス報酬モデル(PRM)として機能します。Creswellら[25]は、推論をSelection(選択)とInference(推論)に分解し、LLMを使用して潜在的な推論トレースを判断します。Xieら[174]は、LLMを数学的推論のための状態遷移推論器に変えるKwai-STaRフレームワークを提案しています。Lightmanら[86]は、推論時の監視とBest-of-NサンプリングのためにLLMをPRMとしてトレーニングします。Setlurら[126]は、将来の正しい応答の可能性に基づいて報酬を生成するプロセスアドバンテージ検証器(PAV)を導入しています。高度な認知構造もシミュレートされています。Haoら[47]は、LLMを、慎重なパス選択のためのモンテカルロ木探索(MCTS)を備えた世界モデルとして使用しています。Bestaら[11]は、LLMの出力をグラフとしてモデル化し、一貫性と論理的推論を評価しています。さらに、批判ベースのLLM審査員[4, 74, 185, 194]は、推論プロセスを強化するための詳細なフィードバックを提供します。Yaoら[184]は、推論トレースとタスク固有のアクションを生成するために、LLMをインターリーブ方式で使用することを先駆的に行いました。推論トレースは、アクションプランを更新する際にモデルをガイドし、アクションは外部ソースとの相互作用を促進します。これを基に、Yangら[181]は、LLMを審査員として活用して、ツールの使用精度を向上させるAuto-GPTを導入しました。さまざまな外部ツールを統合することで、LLMはより汎用性があり、賢明なツールの選択を通じて計画パフォーマンスが向上します。Shaら[127]は、人間のような常識的推論を必要とする、複雑な自動運転シナリオにおける意思決定におけるLLMの可能性を探求しました。Zhouら[217]は、LLMがクエリを判断し、その後の推論に最適な推論構造を選択する自己発見プロセスを採用しました。
検索
検索におけるLLMを審査員としての役割は、従来のドキュメントランキングと動的なRetrieval-Augmented Generation(RAG)アプローチの両方を包含します。従来の検索では、LLMは高度なプロンプティング技術を通じてランキングの精度を高め、最小限のラベル付きデータで効果的なドキュメント順序付けを可能にします。RAGフレームワークは、取得された情報に基づいてコンテンツを生成するLLMの能力を活用し、複雑または進化する知識統合を必要とするアプリケーションをサポートします。
最近の研究では、精度を高め、広範なトレーニングデータへの依存を減らすことを目的として、ドキュメントランキングの審査員としてLLMを検討しています。Zhuangら[222]は、きめ細かい関連性ラベルをLLMプロンプトに埋め込み、モデルが洗練されたドキュメント順序付けのために微妙な関連性の変化を区別できるようにしています。リストワイズランキングの革新には、タスク固有のトレーニングデータなしでドキュメント識別子を並べ替える、Maら[103]のLarge Language Model(LRL)によるリストワイズリランカーが含まれます。Zhuangら[223]は、パフォーマンスを犠牲にすることなく効率を高める、ゼロショットランキングのためのSetwiseプロンプティング戦略を導入しています。位置バイアスに対処するため、Tangら[144]は順列自己整合性を提案し、複数のリスト順序を平均化して、順序に依存しないランキングを生成します。Qinら[114]は、ポイントワイズおよびリストワイズランキングプロンプトを批判し、大規模モデルの費用対効果の高い代替手段として、中規模のオープンソースLLMを備えたペアワイズランキングプロンプティング(PRP)を提案しています。RAGの最近の進歩では、注釈付きデータセットまたはパラメータ調整なしで、自己評価と改善を行うLLMの能力が検討されています。Tangら[143]は、自然言語インデックスを使用して単一のLLM内で情報検索を統合し、検索をドキュメント生成および自己評価プロセスに変換するSelf-Retrievalを提案しています。質問応答では、LLMは評価エージェントとしてますます使用されています。Rackauckasら[116]は、ユーザーインタラクションとドメイン固有のドキュメントから合成クエリを生成するLLMベースの評価フレームワークを導入し、LLMは取得されたドキュメントを評価し、RAGEloを介してRAGエージェントのバリアントをランク付けします。Zhangら[198]は、オープンドメインQAにおける関連性と有用性を評価するLLMの能力を調査し、反事実的なパッセージを使用した効果的な区別と適応性を示しています。ドメイン固有のRAGシステムは、専門知識構造を統合することで複雑なクエリをナビゲートするLLMの可能性を明らかにしています。Wangら[156]は、階層型知識構造と自己認識型評価リトリーバーを使用してベクトルの取得を強化するBIORAGを提示しています。Liら[79]は、LLMと継続的に進化するアルツハイマー病知識グラフを組み合わせ、ノイズフィルタリングに自己認識型知識取得を使用するDALKを導入しています。Jeongら[55]は、LLMが回答生成に最適な証拠を選択するLiuら[94]による、RAGの原則を生物医学アプリケーションに適用するSelf-BioRAGを提案しています。
7.1.2 ソーシャルインテリジェンス
LLMの能力が進歩するにつれて、機械は、特にコンテキスト固有のドメインにおいて、かつては人間だけが実行できると考えられていたタスクを引き受けることが増えています。注目すべき分野はソーシャルインテリジェンスです。ここでは、モデルは文化的価値観、倫理原則、社会的影響を含む複雑な社会的シナリオをナビゲートする必要があります。たとえば、Xuら[176]はLLMのソーシャルインテリジェンスを評価し、大きな進歩にもかかわらず、これらのモデルは学術的な問題解決能力と比較してまだ不十分であると指摘しています。同様に、Zhouら[218]は、LLMエージェント間の複雑な社会的相互作用をシミュレートし、そのソーシャルインテリジェンスを評価するために、SOTOPIAとSOTOPIA-EVALを導入しています。彼らの研究では、GPT-4は人間の判断の代わりとして機能し、これらのシミュレートされた相互作用における目標達成、財務管理、および関係維持を評価します。
7.1.3 マルチモーダル
マルチモーダルAIの分野では、テキストと視覚モダリティにわたって機能するLLMベースのシステムを評価するためのベンチマークが作成されました。これらのベンチマークにより、画像のキャプション作成や数学的推論などのタスクの評価が可能になりました。これらのタスクでは、LLMはペアワイズ比較で人間の好みに合致していましたが、スコアリングとバッチランキングではパフォーマンスが低かった[18]。中国のマルチモーダルアライメントでは、ベンチマークは一貫性と推論における課題を特定し、既存のシステムよりも一貫性の高い調整された評価モデルの提案につながりました[172]。さらに、マルチモーダルおよびマルチエージェントシステムの進歩がレビューされ、合理性を向上させ、バイアスを最小限に抑えるためのコラボレーションメカニズムが強調されました[56]。Xiongら[175]は、透明性と一貫性を高めるために、最終的なスコアと評価の背後にある理論的根拠の両方を提供することにより、マルチモーダルモデルのパフォーマンスを評価するためのLLMを審査員として使用することを調査しています。Chenら[21]は、自動運転のコーナーケースに焦点を当てた、LVLMの自動評価のための最初のベンチマークを導入しています。彼らの調査結果は、LLMを審査員として実施された評価が、LVLMを審査員として実施された評価と比較して、人間の好みに近いことを示しています。
7. LLMの評価者としての能力とその応用
LLMの評価者としての能力は、特に法律文書、数学的推論、科学研究などの複雑で定性的な分野において広く認識されるようになりました[208]。本項では、金融、法律、科学、その他の産業におけるLLMを審査員として応用した最近の動向をレビューし、ドメイン知識とLLM評価者が、いかに重要な分野への影響をさらに拡大できるかを調査します。
7.1 機械学習

7.1.1 自然言語処理 (NLP)
LLMは、感情分析、機械翻訳、テキスト要約など、いくつかのNLPタスクにおいて評価者として有効に活用されています。感情分析では、LLMに基づく判断に影響を与える多くのバイアスが特定されており、これらのバイアスを体系的に定量化するための自動化フレームワークが開発されています。
テキスト生成
対話応答生成、要約、物語作成、創造的な文章など、テキスト生成タスクは、安全で正確で、文脈に関連するコンテンツを必要としますが、「正解」は一つではありません[6, 10]。従来のメトリックに基づく評価とは異なり、LLMを審査員として用いると、ニュアンスのある、適応可能で、カスタマイズされた評価が可能になります。Zhengら[210]によると、GPT-4のようなLLMは、テキスト生成を人間と同程度に評価できます。この方法は、単一のモデルの出力を評価したり、競争環境で複数のモデルを比較したりするために使用されています。たとえば、Gaoら[41]は、人間のような要約評価のためにChatGPTを使用し、Wuら[171]は、LLMが審査員として要約の品質を評価する、比較に基づくフレームワークを提案しています。最新のLLMは、詳細な長文の応答を生成することに優れていますが、出力が長くなるほど、ハルシネーションのリスクが高まります。これに対処するため、Chengら[22]とZhangら[197]は、GPT-4を使用して、論理的に構造化されているが意味をなさないステートメントを特定しています。さらに、Wangら[155]は、関連する証拠を選択し、詳細な批判を提供することでハルシネーションを評価する、批判に基づくシステムを提案しています。ハルシネーションに加えて、有害または安全でない応答の生成も重要な懸念事項です。これに対処するため、Liら[82]は、安全関連のQAペアを評価するためのMD-JudgeとMCQ-Judgeを導入し、安全でない応答を引き出すように設計されたクエリに焦点を当てています。ただし、過度に慎重なアプローチは、過剰な拒否応答につながり、ユーザーエクスペリエンスに影響を与える可能性があります。これを調査するため、Xieら[173]は、潜在的に安全でないクエリに対する応答における拒否傾向を評価し、さまざまなLLMを審査員として用いたフレームワークのメタ評価を実施しています。さらに、Yuら[189]は、テキスト生成における回答の重要な部分を正確に識別するためのLLMベースの回答抽出器を導入し、Anら[2]は、長文コンテキスト言語モデルの標準化された評価のためのフレームワークであるL-Evalを提案しています。その後、Baiら[8]は、LLMを審査員として使用して、長文コンテキストLLMの評価データをフィルタリングしています。最近の研究では、LLMを審査員として使用して、議論ベースのフレームワークを通じて生成モデルの一般的な能力を評価しています。たとえば、Chanら[16]は、自律的な議論を促進し、タスクで生成された応答の品質を評価するためのマルチエージェント議論フレームワークを導入しています。同様に、Moniriら[106]は、ドメイン知識、問題定義、および矛盾認識についてLLMを評価するための自動議論フレームワークを提案しています。
推論
LLMの推論能力を向上させることで、スケーリング則の限界を克服し、その潜在能力を最大限に引き出すことができます。効果的な推論は、複雑な問題に取り組み、情報に基づいた意思決定を行い、正確で文脈を意識した応答を提供するために不可欠です。Weiら[168]は、段階的な推論を促進するためにChain-of-Thought(CoT)プロンプティングを導入しました。推論をさらに強化するために、より高度な認知構造[47, 183]が提案されていますが、信頼できる推論パスを選択することは依然として大きな課題です。LLMを審査員として用いることは、この問題に対処するために採用されています。一部の研究では、サンプルレベルの推論パスの選択に焦点が当てられています。Gaoら[39]は、候補戦略を評価するための戦略評価器を提示しています。KawabataとSugawara[62]は、有効な理論的根拠を選択するために、ペアごとの自己評価を使用するREPS(Rationale Enhancement through Pairwise Selection)を提案しています。Lahotiら[72]は、LLMが複数の批判を集約することで、応答の多様性を特定し、強化できることを示しています。マルチエージェントフレームワークでは、Liangら[85]は、審査員のLLMが最も合理的な応答を選択するマルチエージェント議論(MAD)を導入しています。同様に、Liら[78]は、応答の品質と効率を向上させるために、レイヤーベースのマルチエージェントコラボレーションで審査員のLLMを利用しています。ステップレベルの推論パスの選択については、LLMは状態スコアを評価するためのプロセス報酬モデル(PRM)として機能します。Creswellら[25]は、推論をSelection(選択)とInference(推論)に分解し、LLMを使用して潜在的な推論トレースを判断します。Xieら[174]は、LLMを数学的推論のための状態遷移推論器に変えるKwai-STaRフレームワークを提案しています。Lightmanら[86]は、推論時の監視とBest-of-NサンプリングのためにLLMをPRMとしてトレーニングします。Setlurら[126]は、将来の正しい応答の可能性に基づいて報酬を生成するプロセスアドバンテージ検証器(PAV)を導入しています。高度な認知構造もシミュレートされています。Haoら[47]は、LLMを、慎重なパス選択のためのモンテカルロ木探索(MCTS)を備えた世界モデルとして使用しています。Bestaら[11]は、LLMの出力をグラフとしてモデル化し、一貫性と論理的推論を評価しています。さらに、批判ベースのLLM審査員[4, 74, 185, 194]は、推論プロセスを強化するための詳細なフィードバックを提供します。Yaoら[184]は、推論トレースとタスク固有のアクションを生成するために、LLMをインターリーブ方式で使用することを先駆的に行いました。推論トレースは、アクションプランを更新する際にモデルをガイドし、アクションは外部ソースとの相互作用を促進します。これを基に、Yangら[181]は、LLMを審査員として活用して、ツールの使用精度を向上させるAuto-GPTを導入しました。さまざまな外部ツールを統合することで、LLMはより汎用性があり、賢明なツールの選択を通じて計画パフォーマンスが向上します。Shaら[127]は、人間のような常識的推論を必要とする、複雑な自動運転シナリオにおける意思決定におけるLLMの可能性を探求しました。Zhouら[217]は、LLMがクエリを判断し、その後の推論に最適な推論構造を選択する自己発見プロセスを採用しました。
検索
検索におけるLLMを審査員としての役割は、従来のドキュメントランキングと動的なRetrieval-Augmented Generation(RAG)アプローチの両方を包含します。従来の検索では、LLMは高度なプロンプティング技術を通じてランキングの精度を高め、最小限のラベル付きデータで効果的なドキュメント順序付けを可能にします。RAGフレームワークは、取得された情報に基づいてコンテンツを生成するLLMの能力を活用し、複雑または進化する知識統合を必要とするアプリケーションをサポートします。
最近の研究では、精度を高め、広範なトレーニングデータへの依存を減らすことを目的として、ドキュメントランキングの審査員としてLLMを検討しています。Zhuangら[222]は、きめ細かい関連性ラベルをLLMプロンプトに埋め込み、モデルが洗練されたドキュメント順序付けのために微妙な関連性の変化を区別できるようにしています。リストワイズランキングの革新には、タスク固有のトレーニングデータなしでドキュメント識別子を並べ替える、Maら[103]のLarge Language Model(LRL)によるリストワイズリランカーが含まれます。Zhuangら[223]は、パフォーマンスを犠牲にすることなく効率を高める、ゼロショットランキングのためのSetwiseプロンプティング戦略を導入しています。位置バイアスに対処するため、Tangら[144]は順列自己整合性を提案し、複数のリスト順序を平均化して、順序に依存しないランキングを生成します。Qinら[114]は、ポイントワイズおよびリストワイズランキングプロンプトを批判し、大規模モデルの費用対効果の高い代替手段として、中規模のオープンソースLLMを備えたペアワイズランキングプロンプティング(PRP)を提案しています。RAGの最近の進歩では、注釈付きデータセットまたはパラメータ調整なしで、自己評価と改善を行うLLMの能力が検討されています。Tangら[143]は、自然言語インデックスを使用して単一のLLM内で情報検索を統合し、検索をドキュメント生成および自己評価プロセスに変換するSelf-Retrievalを提案しています。質問応答では、LLMは評価エージェントとしてますます使用されています。Rackauckasら[116]は、ユーザーインタラクションとドメイン固有のドキュメントから合成クエリを生成するLLMベースの評価フレームワークを導入し、LLMは取得されたドキュメントを評価し、RAGEloを介してRAGエージェントのバリアントをランク付けします。Zhangら[198]は、オープンドメインQAにおける関連性と有用性を評価するLLMの能力を調査し、反事実的なパッセージを使用した効果的な区別と適応性を示しています。ドメイン固有のRAGシステムは、専門知識構造を統合することで複雑なクエリをナビゲートするLLMの可能性を明らかにしています。Wangら[156]は、階層型知識構造と自己認識型評価リトリーバーを使用してベクトルの取得を強化するBIORAGを提示しています。Liら[79]は、LLMと継続的に進化するアルツハイマー病知識グラフを組み合わせ、ノイズフィルタリングに自己認識型知識取得を使用するDALKを導入しています。Jeongら[55]は、LLMが回答生成に最適な証拠を選択するLiuら[94]による、RAGの原則を生物医学アプリケーションに適用するSelf-BioRAGを提案しています。
7.1.2 ソーシャルインテリジェンス
LLMの能力が進歩するにつれて、機械は、特にコンテキスト固有のドメインにおいて、かつては人間だけが実行できると考えられていたタスクを引き受けることが増えています。注目すべき分野はソーシャルインテリジェンスです。ここでは、モデルは文化的価値観、倫理原則、社会的影響を含む複雑な社会的シナリオをナビゲートする必要があります。たとえば、Xuら[176]はLLMのソーシャルインテリジェンスを評価し、大きな進歩にもかかわらず、これらのモデルは学術的な問題解決能力と比較してまだ不十分であると指摘しています。同様に、Zhouら[218]は、LLMエージェント間の複雑な社会的相互作用をシミュレートし、そのソーシャルインテリジェンスを評価するために、SOTOPIAとSOTOPIA-EVALを導入しています。彼らの研究では、GPT-4は人間の判断の代わりとして機能し、これらのシミュレートされた相互作用における目標達成、財務管理、および関係維持を評価します。
7.1.3 マルチモーダル
マルチモーダルAIの分野では、テキストと視覚モダリティにわたって機能するLLMベースのシステムを評価するためのベンチマークが作成されました。これらのベンチマークにより、画像のキャプション作成や数学的推論などのタスクの評価が可能になりました。これらのタスクでは、LLMはペアワイズ比較で人間の好みに合致していましたが、スコアリングとバッチランキングではパフォーマンスが低かった[18]。中国のマルチモーダルアライメントでは、ベンチマークは一貫性と推論における課題を特定し、既存のシステムよりも一貫性の高い調整された評価モデルの提案につながりました[172]。さらに、マルチモーダルおよびマルチエージェントシステムの進歩がレビューされ、合理性を向上させ、バイアスを最小限に抑えるためのコラボレーションメカニズムが強調されました[56]。Xiongら[175]は、透明性と一貫性を高めるために、最終的なスコアと評価の背後にある理論的根拠の両方を提供することにより、マルチモーダルモデルのパフォーマンスを評価するためのLLMを審査員として使用することを調査しています。Chenら[21]は、自動運転のコーナーケースに焦点を当てた、LVLMの自動評価のための最初のベンチマークを導入しています。彼らの調査結果は、LLMを審査員として実施された評価が、LVLMを審査員として実施された評価と比較して、人間の好みに近いことを示しています。
7.2 その他の特定領域
7.2.1 金融
LLMは、特に予測、異常検知、パーソナライズされたテキスト生成などのタスクにおいて、金融分野で大きな可能性を示しており[207]、LLM評価者の需要が高まっています。金融分野におけるLLM-as-a-judgeアプリケーションにおいては、専門知識がドメイン固有の評価において非常に重要です。現在の研究は、主に2つの分野に分けることができます。1つは、特定のタスクに対して専門知識を活用するLLMベースの評価者を設計することに焦点を当てています。例えば、Briefら(2024)は、LLMのパフォーマンスを向上させるために、金融におけるマルチタスクのファインチューニングに関するケーススタディを実施しました[14]。Yuら(2024)は、金融意思決定を改善するために、概念的な口頭強化を使用するマルチエージェントシステムであるFinConを導入しました[190]。研究の2番目の分野は、LLMによるドメイン固有の知識の評価と理解を向上させるためのベンチマークを提供することを目的としています。これらのベンチマークには、ユーザーフィードバックに基づくUCFE[182]、専門的な試験問題のデータセットであるIndoCareer[68]、AIによって生成されたドメイン固有の評価セット[119]が含まれます。定量的な投資においては、LLM-as-a-judgeのアプローチが、LLMによって生成された取引シグナルの洗練と強化において価値を示しています。[159] (図17)は、自己改善型取引シグナルを生成するための2層アーキテクチャを提案しています。彼らのシステムは、内側のループにデュアルLLMセットアップを採用しており、一方のLLMが取引アイデアを生成し、もう一方のLLMが評価と洗練を行うjudgeとして機能します。外側のループには、情報係数やシャープ比などの定量的な指標に基づいて包括的なレビューを提供する追加のLLM judgeが組み込まれており、取引シグナルが厳格なパフォーマンス基準を満たすようにしています。さらに、LLM-as-a-judgeのコンセプトは、クレジットスコアリング[5, 188]や環境、社会、ガバナンス(ESG)スコアリング[207]において有望なアプリケーションを示しています。この研究はまだ初期段階にあり、評価方法を改良し、金融分野での応用を拡大するために、さらなる探求が必要です。

7.2.2 法律
LLMは、法的相談などの専門分野において専門的なアドバイスを提供する能力が向上しており、特にテキストの要約や法的推論などのタスクに優れています。しかし、他の分野と比較して、法律分野はLLMにおける潜在的な偏りや事実の不正確さについてより懸念しています。金融分野と同様に、法律における既存の研究は主に2つのカテゴリに分類できます。最初のカテゴリは、専門的な制約に対処したり、評価者自体を設計したりすることにより、法律アプリケーションに特化したLLM評価者を開発することに焦点を当てています。例えば、[102]は、少数の専門家プロンプトを持つ一般的なLLMを使用して、法的事実の関連性を効果的にシミュレートし、自動化された司法評価者としてのLLMの可能性を示しています。Cheongら(2024)は、法的アドバイスのための責任あるLLMを構築するための4次元フレームワークを提案し、(a)ユーザー属性と行動、(b)クエリの性質、(c)AIの能力、(d)社会的影響を強調しています[23]。Ryuら(2023)は、LLMによって生成された法的テキストの妥当性を評価する、検索拡張生成器(RAG)ベースの評価者であるEval-RAGを開発しました。韓国の法律に関する質疑応答タスクでテストしたところ、Eval-RAGを従来のLLM評価方法と組み合わせることで、人間の専門家の評価により近い結果が得られることがわかりました[121]。研究の2番目のカテゴリは、法律シナリオにおけるLLMの適用性を評価するためのベンチマークを作成することです。例としては、インドネシアの専門的な試験用のIndoCareerデータセット[68]や、複数のドメインと言語にわたるLLMの法的推論能力を評価するために共同で構築されたベンチマークであるLegalBench[44]などのマルチドメイン評価セットがあります。これらのベンチマークは、独自の法的構造と用語のために、言語固有であることがよくあります。例えば、中国語の法的テキスト用のLexEval[80]や韓国語用のEval-RAG[121]などがあります。その他のベンチマークは、倫理[202]や有害性[3]などの特定の属性を対象としています。
7.2.3 科学のためのAI
LLMは、Tangら[145]、Zhaoら[208]、Zhouら[216]などの科学分野、特に医療に関する質疑応答や数学的推論などの分野で顕著な可能性を示しており、精度と一貫性を向上させるための評価者として機能します。医療分野では、Brakeら(2024)とKrolikら(2024)による研究により、LLaMA2などのモデルが、人間の専門家に匹敵するレベルの精度で臨床ノートやQ&Aの応答を評価できることが示されました[13, 69]。このアプローチは、プロンプトエンジニアリングを活用して専門知識を埋め込み、LLMが複雑でニュアンスのある情報を処理できるようにすることで、人間の専門家の負担を軽減する信頼性の高い一次評価を提供します。
数学的推論においては、強化学習(RL)と協調的推論法により、LLMの評価者としての能力がさらに向上します。特に定理証明タスクにおいて効果を発揮します[99]。例えば、WizardMathは、数学タスクにおける推論を洗練するために、ステップバイステップのフィードバックを通じてRLを採用することにより導入されました[100]。Zhuら(2023)は、人間の二重過程推論を模倣するために生成と検証を組み合わせた協調的推論(CoRe)フレームワークを提案し、モデルの問題解決精度を向上させました[221]。さらに、Luら(2023)は、視覚的な文脈における数学的推論を評価するためのベンチマークであるMathVistaを開発し、GPT-4VなどのLLMが視覚的な要素を伴う数学的推論を伴うタスクを評価します[99]。これらの方法は、数学的推論全体でLLMの評価および推論スキルを向上させる上で、RL、協調的推論、およびプロンプトエンジニアリングを組み合わせることの価値を強調しています。
7.2.4 その他
LLMはまた、さまざまな分野で効率と一貫性を高めるための評価者としても採用されています。ソフトウェアエンジニアリングでは、バグレポートの要約を評価するためにLLMを使用する方法が提案されており、疲労を経験した人間の評価者よりも正確性と完全性の評価において高い精度を示しています[70]。このアプローチは、評価のためのスケーラブルなソリューションを提供します。教育においては、オープンソースLLMを使用した自動エッセイ採点と修正が検討されており、従来型のディープラーニングモデルに匹敵するパフォーマンスを達成しています。少数の学習やプロンプトの調整などの手法により、採点精度が向上し、修正によりエッセイの質が効果的に向上しましたが、元の意味を損なうことはありません[135]。コンテンツモデレーションでは、Redditのようなプラットフォームでのルール違反を特定するためにLLMベースのアプローチが開発され、高い真陰性率を達成しましたが、複雑なルールの解釈に課題があり、ニュアンスのあるケースでは人間の監視が必要であることが強調されました[66]。行動科学では、ペルソナに基づいてユーザーの好みを評価するためのLLM-as-a-Judgeフレームワークが評価され、単純化されたペルソナのために信頼性と一貫性に限界があることが明らかになりましたが、口頭による不確実性の推定を通じて大幅に改善され、高確実性ケースの人間の評価との高い一致を達成しました[33]。LLMの評価者としてのこれらのアプリケーションは、多様なセクターにおけるLLMの成長の可能性を強調し、ドメイン固有の知識を統合し、方法論を洗練する必要性を強調しています。さらに、LLMは評価者として、サービスの質を評価したり、ユーザーエクスペリエンスのフィードバックを分析したり、芸術作品や文学評論などの創造的なコンテンツを評価したりするなど、定量化が難しい定性的な評価において大きな利点を示しています。ニュアンスのある言語を理解し、生成するLLMの能力は、従来は人間の判断を必要としていた主観的な評価タスクに適しています。今後の研究は、これらの分野にさらに焦点を当て、LLMをjudgeとして活用することで、従来の定量的な方法では不十分な評価の精度と一貫性をどのように高めることができるかを検討していきます。
8. 課題
本章では、特に LLM-as-a-Judge(LLMを評価者として使用する)という文脈において、LLMを評価タスクに利用する際に生じる主な課題を探ります。その能力が向上しているにもかかわらず、LLMは依然として信頼性、ロバスト性、および基盤となるバックボーンモデルの限界に関連する重大な問題に直面しています。これらの課題を理解することは、LLMを公正、一貫性、かつ信頼性の高い方法で使用するために不可欠です。ここでは、信頼性、ロバスト性、そしてより強力なバックボーンモデルの必要性という3つの主要なテーマに沿って、これらの懸念事項に対処します。
8.1 信頼性
評価者として使用されるLLMの信頼性を評価すると、いくつかの喫緊の課題が明らかになります。人間とLLMの評価者の両方が偏向を示し、評価の一貫性と公平性に関する懸念が高まります。具体的には、人間の評価者も固有の偏見を持っていることが判明しており [170, 210]、信頼できる回答を提供できない場合さえあります [24, 46]。人間に代わるものとして、LLMの評価にも特定の偏りがあることが判明しており、注釈の結果にはより多くの評価が必要です [109]。これは§4で議論したとおりです。 LLM-as-a-Judgeの偏りは、§4で定義したように、LLMが確率的モデルであるという事実によるものが大きいです。さらに、人間のフィードバックを用いた強化学習(RLHF)は、LLMを人間の好みに合わせることでLLMのパフォーマンスを向上させます。ただし、RLHFでトレーニングされたモデル[73]が堅牢で一貫した出力を生成することを保証することは、依然として進行中の課題です。このセクションでは、信頼性をより良く理解するために、偏り、過信、および一般化における課題から生じる信頼性の問題について説明します。
過信。
Instruction-tuningされたLLMは、過信の問題を抱えていることが示されています。つまり、自身の応答を評価する際に、過度に好意的なスコアを提供する傾向があります[148]。 LLM-as-a-Judgeのシナリオでも、過信が非常に高く存在し、LLMによって生成された応答を評価することにも関与しています。その結果、通常はInstruction-tuningされている最新のLLMでLLM-as-a-Judgeを利用する場合は、過信の存在と影響を細心の注意を払って検討する必要があります。
公平性と一般化。
信頼性のもう1つの重要な側面は、公平性と一般化です。 LLM-as-a-Judgeによる評価は、状況によってかなりの不一致を示す可能性があります。これが、プロンプトベースの手法がLLM-as-a-Judgeのパフォーマンスを向上させるためによく使用される理由です。ただし、プロンプトエンジニアリングの敏感さにより、公平性と一般化に関する課題が発生する可能性があります。たとえば、コンテキスト内の例の順序はモデルの出力に大きな影響を与え、例の配置が不適切である場合、不公平な評価につながる可能性があります。さらに、LLMは長いコンテキストウィンドウを効果的に処理するのに苦労し、パフォーマンスが低下したり、シーケンスの後の例を優先したりすることがよくあります。これらの問題は、LLMベースの評価における公平性と一般化に関する懸念を引き起こします。
8.2 ロバスト性
LLMの優れた能力にもかかわらず、敵対的攻撃を受けやすいことが判明しています[57, 128, 226]。敵対的攻撃下では、LLMは有害なコンテンツを生成するように誘導される可能性があります。 LLM攻撃に関する既存の研究は主にNLGタスクに焦点を当てていますが、LLM-as-a-Judgeに対する攻撃は比較的十分に調査されていません[20]。これは、LLM-as-a-Judgeを使用する際に、ロバスト性に関するいくつかの課題に直面することを意味し、これらのリスクは不明です。これらのロバスト性の課題に対処するには、LLM-as-a-Judgeタスクに関連する特定の脆弱性についてより深く理解する必要があります。従来の自然言語生成(NLG)に対する敵対的攻撃とは異なり、モデルを誤って有害または不正確な出力を生成させることを目的とする場合が多いのに対し、LLM-as-a-Judgeに対する攻撃は、モデルの意思決定プロセスにおける偏り、矛盾、または抜け穴を悪用することを目的としています。たとえば、入力の言い回しやコンテキストフレーミングを微妙に操作すると、判断に大きな逸脱が生じる可能性があり、高リスクアプリケーションでの信頼性に関する懸念が高まります。現在、ロバスト性を維持するために、このような攻撃から防御するためのいくつかの方法があります。これらのアプローチには、主に応答フィルタリングや一貫性チェックなどの後処理手法が含まれており、評価の品質を向上させるために不可欠です。ただし、これらの手法は依然として大きな課題に直面しています。主な問題の1つは、自己整合性です。LLMは、同じ入力を複数回評価する場合、一貫性のない出力を生成することがよくあります。もう1つの課題は、ランダムスコアリングです。モデルが、生成された出力の真の品質を正確に反映しない、任意または過度に肯定的なスコアを割り当てる場合です。このような制限は、これらの防御メカニズムの信頼性とロバスト性を損ないます。
8.3 強力なバックボーンモデル
LLMはテキストベースの評価で優れたパフォーマンスを発揮しますが、マルチモーダルコンテンツの信頼できる評価者として効果的に機能するための堅牢なマルチモーダルモデルが、この分野には不足しています。 GPT-4 Visionなどの現在のマルチモーダルLLMは、さまざまなモダリティにわたる複雑な推論に苦労しています。この制限により、マルチモーダル評価タスクで信頼性の高い評価を達成することが難しくなります。多くの場合、テキストコンテンツを評価するための十分な強力なInstruction-following能力と推論能力がないため、LLMは質の高い評価コンテンツを完了できません。
9. 今後の展望

AI時代[179]において、LLM-as-a-Judge(裁判官としてのLLM)システムは、幅広い専門領域で人間の判断を支援、あるいは代替する可能性をますます示しています。多くの役割は本質的に、複雑なシナリオを評価、査定、または裁定する能力を必要とし、高度なデータ処理とパターン認識能力を備えたLLMは、これらのタスクをサポートまたは強化するのに適しています。図16に示すように、LLMは多様な分野で汎用性の高い評価者として機能します[167]。たとえば、作家は物語の構造や市場の動向を分析することで、LLMを活用して創造的なアイデアの実現可能性と独創性を評価できます。医師は医療記録と画像データを処理することで、LLMを使用して病状を診断し、結果を予測できます[145, 204, 214]。定量アナリストは金融データのパターンを特定することで、LLMを使用して市場の動向を予測し、リスクを評価できます。また、裁判官は法律と判例を解釈するためにLLMを利用し、訴訟の裁定を支援できます。LLMはスケーラブルで柔軟な評価に優れていますが、限界もあります。今後の研究は、これらの限界に対処しながら、新たな応用を探求し、LLM-as-a-Judgeシステムの信頼性、公平性、適応性を向上させ、社会的価値観と専門的な基準への整合性を確保することに焦点を当てるべきです。図18に示すように、GPT-4の登場により評価方法論の開発は大きく進化し、LLM-as-a-Judgeシステムに対するよりスケーラブルで柔軟なアプローチが可能になりました。これらの評価パラダイムは通常、環境との相互作用に依存してフィードバックを取得し、それが自己進化のシグナルの基礎を形成します。今後、信頼できるLLM-as-a-Judgeを確立し、さらにAIの知的性能をワールドモデルとして強化できれば、ワールドモデルを裁判官として使用することで、現実世界のシミュレーションをより現実的で広く信頼できるものにすることができます。AIはこのアプローチを使用して自己進化を達成し、LLM-as-a-Judgeを重要なツールおよび能力として使用することにより、汎用人工知能(AGI)のスケーリングを強化する可能性があります。
9.1 より信頼性の高いLLM-as-a-Judge
私たちの定式化(§2)と戦略(§3)で強調されているように、LLMは確率的モデルであり、裁判官としての信頼性を高めるためには広範な研究と最適化が必要です。現在の手法はLLM-as-a-Judgeの信頼性を向上させていますが、適応性や頑健性など、多くの課題が未解決のままです。確率的モデルが現実世界のシナリオと密接に整合した評価を提供できるようにするために、今後の研究では、評価パイプライン全体にわたるLLM-as-a-Judgeの改良と実装を優先する必要があります。コンテキスト学習、モデル選択、後処理技術、およびLLM-as-a-Judgeの全体的な評価フレームワークなど、さまざまな側面で信頼性を向上させる可能性は大いにあります。これらの取り組みは、評価の信頼性を高めるだけでなく、これらの評価の頑健性を体系的に評価および検証するための方法論の開発を優先する必要があります。さらに、包括的な評価ベンチマークと解釈可能な分析ツールの確立は、LLM評価者の信頼性を評価および改善するために非常に重要になります。最後に、頑健性リスクの不確実で進化する性質は、積極的な軽減戦略の必要性を強調しています。これらの戦略には、判断タスクに合わせて調整された敵対的トレーニング手法の開発、堅牢な不確実性定量化手法の統合、および重要な決定を監督する人間参加型システムの導入が含まれます。これらの課題に対処することで、敵対的な状況下でも高いレベルの信頼性を維持できる、より弾力的で信頼できるシステムを構築できます。
9.2 データアノテーションのためのLLM-as-a-Judge
対照的に、LLM-as-a-Judgeは、LLMを使用して人間のラベリングを近似する一般的な手法です。LLMに「ソースへの忠実さ」、「正確性」、「役立ち度」などの質を評価するように依頼する場合、評価プロンプトでこれらの用語の意味を定義し、LLMがトレーニングデータから学習したセマンティックな関係に依存します。その幅広い応用にもかかわらず、データアノテーションは、データの複雑さ、主観性、多様性により、現在の機械学習モデルにとって大きな課題となっています。このプロセスは、ドメインの専門知識を必要とし、特に大規模なデータセットを手動でラベル付けする場合は、リソース集約的です。GPT-4[107]、Gemini[43]、LLaMA-2[153]などの高度なLLMは、データアノテーションに革命を起こす可能性を秘めています。LLMは単なるツール以上の役割を果たし、データアノテーションの有効性と精度を向上させる上で重要な役割を果たします。アノテーションタスクの自動化[206]、大量のデータ全体の整合性の確保、および特定のドメイン向けに微調整またはプロンプトを通じて適応できる能力[102, 134]により、従来のアノテーション手法で遭遇する課題が大幅に軽減され、NLPの分野で達成可能なものの新しい基準が設定されます。科学研究の分野であろうと産業界であろうと、私たちは皆、依然として不十分なターゲットデータとドメイン固有のデータ、またはデータ品質が十分に高くない状況に苦しんでいます。LLM-as-a-Judgeが安定したパフォーマンスを達成し、公平かつ信頼できると仮定すると、LLMを使用して、データが不十分なシナリオでデータをアノテーションしてデータを拡張できます。データ品質が低いシナリオでは、LLMを通じてデータ品質を評価し、品質タグをラベル付けして、高品質のデータを選択するという目標を達成できます。現在、さまざまなシナリオのデータを確実に評価するために、LLMのみに実験的に依存することはできていません。ほとんどの場合、プロフェッショナリズムと信頼性を確保するために、依然として人間のアノテーションに依存しています。LLM-as-a-Judgeは、特定のラベリングタスクを実行するために、人間のアノテーションから学習する必要があることがよくあります。
9.3 MLLM-as-a-Judge
AIシステムは、汎用性が高く多機能なエンティティへと進化しています[29]。従来、感情分析、構文解析、対話モデリングなど、異なる言語処理タスクには特殊なモデルが必要でした。しかし、大規模言語モデル(LLM)は、単一の重みセットを使用してこれらのタスク全体で能力を発揮しています[137]。同様に、複数のデータモダリティを処理できる統合システムに向けて進歩が見られています。テキスト、音声、画像を処理するために異なるアーキテクチャを採用する代わりに、最近のGPT-4o[107]、Gemini[43]、LLaVA[92]などのモデルは、これらの機能を単一のフレームワーク内に統合しています。これらの開発は、AIシステムの構造と機能の統一に向けた成長傾向を強調しており、これはLLM-as-a-Judgeという新たなパラダイムにも拡張されています。現在、MLLM-as-a-Judgeフレームワーク[18]がモデルの評価のために登場しています。ただし、MLLM-as-a-Judgeがデータやエージェントの評価にどのように適用できるかを探求する研究は限られています。モデル評価を超えて、MLLM-as-a-Judgeは、LLM-as-a-Judgeと同様に、データを評価またはアノテーションし、報酬モデルとして機能し、または中間推論プロセス内で検証者として機能する能力を持つと想定されています。これらの拡張された役割により、MLLM-as-a-JudgeはAIパイプラインに広く貢献できます。評価の将来は、テキスト、音声、画像、ビデオにまたがる複雑なコンテンツを推論および評価できる、堅牢なマルチモーダル評価者を開発することにあります。現在のマルチモーダルLLMは有望な能力を示していますが、テキストベースの対応するものと比較して、推論の深さと信頼性がしばしば欠けています。今後の研究では、これらの制限に対処し、推論能力の強化、信頼性の向上、およびモダリティ間のシームレスな統合を可能にすることに焦点を当てる必要があります。実用的なマルチモーダル評価者は、AI研究を前進させるだけでなく、マルチモーダルコンテンツのモデレーションや自動知識抽出などの分野で新しいアプリケーションを可能にする可能性を秘めています。
9.4 より多くのLLM-as-a-Judgeベンチマーク
より包括的で多様なベンチマークの開発も、LLM-as-a-Judgeシステムの信頼性と適用性を高めるために非常に重要です。今後の取り組みは、ドメイン固有のアプリケーション、マルチモーダルコンテンツ、および現実世界の複雑さを含む、幅広いシナリオを網羅する高品質で大規模なデータセットの作成に焦点を当てる可能性があります。さらに、ベンチマークは、より詳細で詳細な評価指標を統合する必要があります。これらの改善は、LLMのパフォーマンスをより包括的に理解するだけでなく、その能力を強化するための方法論の開発を導きます。ImageNet[30]と同等の規模と影響力を持つ厳格な基準とデータセットを確立することにより、LLM-as-a-Judgeの分野は、より深い洞察を得て、より大きなイノベーションを促進できます。
9.5 LLM最適化のためのLLM-as-a-Judge
LLM-as-a-Judgeは、LLMの最適化を進める上で大きな可能性を示しています。最近の研究[225]では、LLM-as-a-Judgeをマルチエージェントフレームワークに組み込み、エージェント間の相互作用を導き、それによって全体的な意思決定効率と品質を向上させています。さらに、LLM-as-a-Judgeは、モデルの推論プロセスを評価するための重要なスコアリングモジュールとして機能する、強化学習による微調整(ReFT)パイプライン[154]で使用されています。LLM-as-a-Judgeは、多様なコンテンツ形式とドメインに柔軟に適応することで、幅広い最適化タスクに対する堅牢かつ効率的な評価メカニズムを提供します。これらの心強い展開にもかかわらず、現在の研究活動はまだ始まったばかりです。今後の研究は、特に複雑なマルチモーダルシナリオにおいて、LLM-as-a-Judgeの実装のためのアプリケーションドメインと戦略を拡大することに焦点を当てる必要があります。さらに、モデルのパフォーマンスと頑健性を高める上で、LLM-as-a-Judgeの潜在能力を最大限に発揮するためには、その信頼性と一般化能力の体系的な評価が不可欠になります。
10. 結論
LLM-as-a-Judge(裁判官としてのLLM)は、自動評価のための有望なパラダイムとして登場し、従来の専門家主導またはメトリクスに基づく手法を凌駕する拡張性と適応性を提供します。 大規模言語モデルの推論能力を活用することで、このフレームワークは、テキスト品質評価、モデル評価、自動データアノテーションなどのタスクで優れています。 これは、大規模で効率的、かつ適応性のある評価にとって特に価値があります。 多様なコンテンツ形式を処理し、ドメイン固有の知識を統合する能力により、教育、ピアレビュー、意思決定システムでのアプリケーションに特に適しています。 これらの強みにもかかわらず、その可能性を最大限に実現するには、いくつかの課題に対処する必要があります。 信頼性の確保は依然として重要な問題です。確率的な出力は、一貫性の欠如、過信、トレーニングデータから継承されたバイアスを引き起こす可能性があるためです。 RLHFなどの手法により、人間の判断との整合性が向上しましたが、すべての主観的な要因を排除するわけではありません。 さらに、ロバスト性の確保も重要な課題です。 LLM-as-a-Judgeは、敵対的なプロンプト操作や文脈的なフレーミングバイアスを受けやすく、意図しない、または信頼性の低い評価を引き起こす可能性があります。 最後に、ドメインやモダリティを跨いだ汎化は依然として大きなハードルです。現在のモデルは、マルチモーダル入力の評価、構造化されたデータに関する推論、ドメイン固有の評価基準への適応に苦労するためです。 これらの課題に対処するために、今後の研究は3つの主要な分野に焦点を当てる必要があります。 第一に、信頼性の向上には、自己整合性メカニズム、不確実性キャリブレーション、バイアス軽減技術の進歩が必要です。これにより、モデルが安定した、適切に調整された判断を提供することが保証されます。 第二に、ロバスト性の強化には、敵対的な攻撃に強い評価フレームワークの開発と、文脈の変動に対する感受性を低減するプロンプトエンジニアリング手法の改良が必要です。 第三に、汎化能力の拡大には、マルチモーダル推論の推進、構造化された知識表現の統合、ドメイン適応学習戦略の洗練が必要です。これにより、モデルは多様な評価シナリオをより効果的に処理できるようになります。 最終的に、LLM-as-a-Judgeは次世代評価システムの不可欠な要素となり、人間の専門知識を置き換えるのではなく、強化するでしょう。 信頼性、ロバスト性、汎化の課題に対処することで、より信頼性が高く、適応性があり、包括的な評価者を構築できます。