はじめに
AWS Lambdaでテンポラリファイルを作成し、それをS3にアップロード。さらに、S3にアップロードしたファイルを元の場所にダウンロード、というグルグルをやってみます。
システム構成
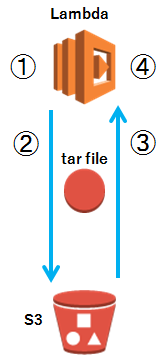
-
/tmp/log/sess/にファイルを作成し、ディレクトリを/tmp/sess-info.tarにアーカイブします。 - S3<bucket>に
sess-info.tarをアップロードします。 -
/tmp/sess-info.tarを削除し、S3<bucket>のsess-info.tarを/tmp/sess-info.tarにダウンロードします。 -
/tmp/log/sess/が存在すれば削除し、sess-info.tarを/tmp/log/sess/に展開します。
Lambda Code
import boto3
import os
import os.path
import tarfile
import shutil
def lambda_handler(event, context):
bucket_name = 'bucket_name'
tmp_dir = '/tmp/'
log_dir = '/tmp/log/sess/'
file_name = 'sess-info.tar'
key = file_name
file_path = tmp_dir + file_name
# === Step 1
# create log dir
if os.path.exists(log_dir) == False:
os.makedirs(log_dir)
# write log
with open(log_dir + 'log1.txt', 'w') as file:
file.write('hoge\n')
with open(log_dir + 'log2.txt', 'w') as file:
file.write('fuga\n')
# create log archive
with tarfile.open(file_path, mode='w:gz') as archive:
archive.add(log_dir)
# === Step 2
# create s3 resource
s3 = boto3.resource('s3')
bucket = s3.Bucket(bucket_name)
# upload log archive
bucket.upload_file(file_path, key)
# === Step 3
# delete log archive
if os.path.exists(file_path):
os.remove(file_path)
# download log archive
bucket.download_file(key, file_path)
# === Step 4
# delete log dir
if os.path.exists(log_dir):
shutil.rmtree(log_dir)
# extract log archive
with tarfile.open(file_path, mode='r:gz') as archive:
archive.extractall('/')
※ bucket_name は適宜、設定してください。
Lambda Configuration
- Runtime: Python 2.7
- Handler: lambda_function.lambda_handler
- Role: Choose an existing role
- Existing role: AmazonS3FullAccess
- Memory(MB): 128
- Timeout: 0 min 10 sec
※ LambdaとS3を連携させる場合、Lambdaにroleを設定するだけで連携可能でした。SessionにAccess Key Id,Secret Access Keyを指定したり、S3のアクセス許可を設定したりする必要はありませんでした。
S3 Bucket
Lambda Codeのbucket_nameと同じ名前のBucketを作成します。
おわりに
Lambdaは、ステートレスに設計するのが基本ですが、ステートフルなデータにアクセスしたくなるケースもあります。
そんな場合は、下記をうまく利用して対応します。
- Lambdaの/tmp ディレクトリに 500 MBまでのテンポラリファイルを作成可能
- Amazon S3と連携
- Amazon DynamoDBと連携
今回は、Lambdaの/tmpディレクトリとS3を利用する例でした。