LLM Advent Calendar 2023の記事です
概要
- multi hopな質問をLLMと知識グラフで解く試み
- 家光の墓を探します
背景
単純なRAGで問題となるのは、
- 全体を読まないと回答ができない場合
- 散逸している情報を結合しないと回答できない場合(mutli hop QA)
ですよね。
対策としては、agentで多段的に推論していく等ありますが、そもそも元データの方を情報検索や抽出しやすい形に直しておく、というアプローチがあります。
個人的に知識グラフや論理推論に興味があるのですが、LLMとの融合的なアプローチが色々ありそうで調べたりしてます。
お題
mutli hop QAのデータセットとしてはHotPotQAというのがあり、その日本語バージョンのようなデータセットが最近公開されていたので、
ぼーっとdevデータセットを眺めていましたら
{"qid": "0db707837b3611c4f3365cf869bf799f",
"type": "compositional",
"question": "徳川家宣の父方の祖父の墓所は何というお寺にありますか?",
"answer": "輪王寺",
"derivations": [["徳川家宣",
"父方の祖父",
["徳川家光"]],
["徳川家光",
"墓所",
["輪王寺"]]],
"page_ids": ["37222",
"11182"],
"time_dependent": false}
ちょうど大河ドラマ最終回でも家光君がチラッと出てきましたし、家光と立花宗茂や阿茶の小説も読んでいたので、このquestion:
「徳川家宣の父方の祖父の墓所は何というお寺にありますか?」
が目に入り、これをどう解くかをテーマにしようと決めました。
道草
zero-shot

不正解。
full-shot
両wikipediaテキストを全部gpt-4 128kに入れる。正解する。
素晴らしい!でも実務上これでできても意味がない。
タスクを設定
HopQAタスクでは難易度レベルとして、以下の2レベルがあるそうですが、
- データセット全体の中で回答に必要な情報が存在するデータ箇所が与えられる
- データセット全体から探す
今回は前者、与えられたwikipediaページを参照して回答するタスクとします。
与えられたpage_idによれば、これは家光と家宣のwikiページです。
テキストデータを準備
from langchain.document_loaders import WikipediaLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
def get_wiki_docs(query: str, lang:str = "ja"):
loader = WikipediaLoader(query, lang=lang, load_max_docs=1, doc_content_chars_max=1000000)
return loader.load()
document_mitsu = get_wiki_docs("徳川家光")
document_nobu = get_wiki_docs("徳川家宣")
ベクトルRAG
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain
from langchain.memory.buffer import ConversationBufferMemory
documents = []
documents.extend(get_wiki_docs("徳川家光"))
documents.extend(get_wiki_docs("徳川家宣"))
text_splitter = RecursiveCharacterTextSplitter(chunk_size=800, chunk_overlap=100)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
vectordb = Chroma.from_documents(texts, embeddings)
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True,
output_key='answer'
)
qa = ConversationalRetrievalChain.from_llm(
ChatOpenAI(model="gpt-4-1106-preview"),
vectordb.as_retriever(search_kwargs={"fetch_k": 5}),
memory=memory,
return_source_documents=True
)
試します。
qa({"question":"徳川家宣の父方の祖父は?"})

正解。これは・・・いけるか?
qa({"question":"徳川家宣の父方の祖父の墓所は何というお寺にありますか?"})

不正解。家光の墓所は日光東照宮の輪王寺です。
ちなみにbm25によるキーワード&ベクトルのhybrid検索も試しましたが、正解できませんでした。
ベクトルRAG × Agent
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.agents import Tool
agent = initialize_agent(
tools=[Tool(name = "searcher", func=qa, description="")],
llm=ChatOpenAI(temperature=0, model="gpt-4"),
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
agent.run("徳川家宣の父方の祖父の墓所は何というお寺にありますか?")
結果

ほぼ正解。もうこれで良いんじゃないかと思えてきます。
ただ実行のたびに結果が揺らぐのがちょっと不安ではありますね。

このあと知識グラフ的な手法を試していきますが、agentで関連テキストを手繰って回答にたどり着けるのであれば、単一質問であれば、これが一番低コストかも。
知識グラフの場合はまずその構築に初期コストが発生するので。
その代わりに一旦知識が整理されれば、その後の情報抽出やクエリで低コストになる。
知識グラフアプローチ1(triple/factoidとして)
テキストから、いわゆるtriple(subject-relationship-object)を抽出します。
こちらの記事などが参考になります。
gpt-4 128kで全文渡して一気にやると案外上手くいきませんでした(それに遅い!)。
分割実行するのが良さそうですが、名寄せ・共参照の解決のためには、要約処理と同様の工夫(ex. map-reduce, map-rerank, refine)が必要になりそうです。
contextを作る
def summarize(text: str):
res = client.chat.completions.create(
model="gpt-4-1106-preview",
messages=[{"role":"user","content":f"""
summarize the given text as 500 chars around.
response should be JSON having, 'title', 'theme','summary'
text:
{text}
"""}],
response_format={ "type": "json_object" }
)
return json.loads(res.choices[0].message.content)
実行例
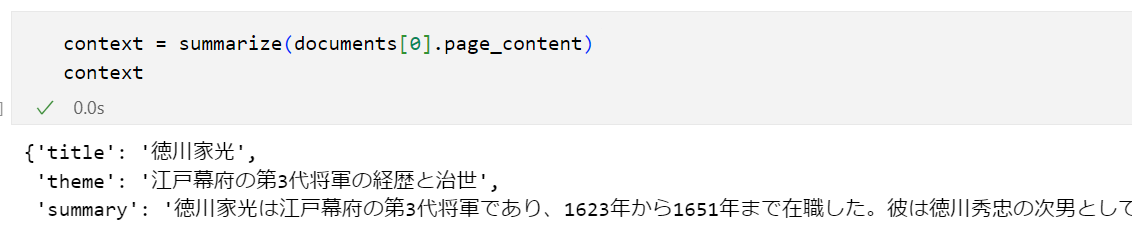
contextを付与しつつtripleを抽出
上記の記事にある、知識抽出のための下記promptを流用します。
instruction = """
# Knowledge Graph Instructions
## 1. Overview
You are a top-tier algorithm designed for extracting information in structured formats to build a knowledge graph.
- **Nodes** represent entities and concepts. They're akin to Wikipedia nodes.
- The aim is to achieve simplicity and clarity in the knowledge graph, making it accessible for a vast audience.
## 2. Labeling Nodes
- **Consistency**: Ensure you use basic or elementary types for node labels.
- For example, when you identify an entity representing a person, always label it as **"person"**. Avoid using more specific terms like "mathematician" or "scientist".
- **Node IDs**: Never utilize integers as node IDs. Node IDs should be names or human-readable identifiers found in the text.
## 3. Handling Numerical Data and Dates
- Numerical data, like age or other related information, should be incorporated as attributes or properties of the respective nodes.
- **No Separate Nodes for Dates/Numbers**: Do not create separate nodes for dates or numerical values. Always attach them as attributes or properties of nodes.
- **Property Format**: Properties must be in a key-value format.
- **Quotation Marks**: Never use escaped single or double quotes within property values.
- **Naming Convention**: Use camelCase for property keys, e.g., `birthDate`.
## 4. Coreference Resolution
- **Maintain Entity Consistency**: When extracting entities, it's vital to ensure consistency.
If an entity, such as "John Doe", is mentioned multiple times in the text but is referred to by different names or pronouns (e.g., "Joe", "he"),
always use the most complete identifier for that entity throughout the knowledge graph. In this example, use "John Doe" as the entity ID.
Remember, the knowledge graph should be coherent and easily understandable, so maintaining consistency in entity references is crucial.
## 5. Explicit Entity Identification
- Unique Entity Representation: When an entity is introduced in the text, assign it a unique identifier. Use this identifier consistently for all mentions of the entity throughout the text.
- Example Implementation: For a text mentioning "grandfather" and "old man" as the same person, assign a unique identifier like "grandfather_1" and use it for all subsequent mentions.
## 6. Strict Compliance
Adhere to the rules strictly. Non-compliance will result in termination.
think step by step.
First, list up entities as much as possible.
Second, attach relations between entities.
q: 太郎はA事業部の課長を経て、B事業部の部長になった
a: {s:A事業部, r:課長, o:太郎},{s: B事業部, r:部長, o:太郎}
"""
from openai import OpenAI
import json
client = OpenAI()
def extract(input: str, context: dict[str]=None):
messages=[{"role":"user","content":f"""
{instruction}
output list of triple(subject, predicate, object) from the given text.
response should be JSON list. Each element has properties s,o,r.
relation means is-a or has-a, so it has direction.
ex.
太郎は花子が好き
s: 太郎, r: 好き, o: 花子
太郎は花子の息子である
s: 太郎, r: 母, o: 花子
s:花子, r:子, o: 太郎
nodes already given:
{','.join(node_names)}
ex.
input: 太郎は花子が好きです。彼は、桃子の娘・花子と結婚している
output: {{"triples":[{{"s":"太郎","o":"花子","r":"好き"}},{{"s":"太郎","o":"花子","r":"夫婦"}},{{s:桃子,o:花子,r:娘}}]}}
input: 太郎は、山田家の当主・一郎の長男として生まれた。一郎の弟は二郎である。
output: {{"triples":[{{"s":"太郎","o":"一郎","r":"父"}},{{"s":"太郎","o":"二郎","r":"叔父"}},{{s:山田家,o:一郎,r:当主}}]}
input: {input}
output:
"""}]
if context:
# messagesの先頭にcontextを追加
messages.insert(0, {"role":"system", "content":f"""
user want to extract knowledge from partial text of long text.
Context of long text is below.
With this context, you should estimate and compensate unmentioned person in user's text.
ユーザテキストの中では主語や対象が省略されている可能性がある
you should combine context and user's text, to extract knowledge.
Think step by step, but don't output thinking process.
Pay attention to direction of relation.
ex.
context: 日本国憲法について
user's text: 発布は1946年(昭和21年)11月3日
knowledge: (s: 日本国憲法, r: 発布, o: 1946年11月3日)
context: ピカソとその時代
user's text: 1901年、パリに移り住む
knowledge: (s: ピカソ, r: 居住地, o: パリ)
# context
title: {context['title']}
theme: {context['theme']}
summary:
{context['summary']}
"""})
response = client.chat.completions.create(
model="gpt-4-1106-preview",
messages=messages,
response_format={ "type": "json_object" }
)
return json.loads(response.choices[0].message.content)["triples"]
triple抽出を実行
from tqdm import tqdm
text_splitter = RecursiveCharacterTextSplitter(chunk_size=800, chunk_overlap=100)
def collect_triples(document):
node_names = []
context = summarize(document.page_content)
texts = text_splitter.split_documents([document])
infos = []
for text in tqdm(texts):
info = extract(text.page_content, context)
infos.extend(info)
for ii in info:
node_names.extend([ii["s"], ii["o"]])
node_names = list(set(node_names))
return infos
実行してtripleリストを取得しjsonファイルで保存しておきます。
triples = []
triples.extend(collect_triples(document_mitsu))
triples.extend(collect_triples(document_nobu))
with open("output.json", "w") as f:
json.dump(infos, f, indent=4, ensure_ascii=False)
中身例
[
{"s": "徳川家光", "o": "江戸幕府", "r": "第3代将軍"},
{"s": "徳川家光", "o": "乳兄弟", "r": "稲葉正勝"},
{"s": "徳川家光", "o": "乳兄弟", "r": "稲葉正吉"},
...
先回りして、回答に必要な情報が含まれているのを確認。
{"s": "徳川家光", "r": "葬地", "o": "日光の輪王寺"},
{"s": "綱重", "o": "徳川家光", "r": "父"},
{"s": "徳川家宣", "o": "徳川綱重", "r": "父"},
LLMがこれらを検索参照さえできれば、問題クエリに回答可能なはず。
問題はどうやってこれらtripleに着目させられるか。
クエリに関係しそうなtripleを抽出する
- その中の情報で回答できるかもしれない
- できなくてもqueryを簡約(refine)できるかもしれない
queryに類似するtripleを検索する関数
少々乱暴だがtripleを平文にしてベクトル化する。
どこかのneo4j記事でも似たようなことはやっていた。
例:あるノードの特徴量として、そこに接続する周辺ノードやリンクの情報を平文化してベクトルにする
from langchain.embeddings import OpenAIEmbeddings
doc_result = embeddings.embed_documents([f"{i['s']}の{i['o']}に対する関係:{i['r']}" for i in triples])
def similar_triples(query: str):
query_vector = embeddings.embed_query(query)
cos_similarities = cosine_similarity([query_vector], doc_result)[0]
# 類似度とインデックスをペアにしてソート
paired_similarities = list(enumerate(cos_similarities))
paired_similarities.sort(key=lambda x: x[1], reverse=True)
# 上位20個のベクトルを取得
top_20_similar_indices = [i for i, _ in paired_similarities[:10]]
top_20_similar_indices
return list(np.array(total_info)[top_20_similar_indices])
実行例

必要な情報を拾えているか?
- 家宣の父は綱重 => OK
- 家光の墓所は輪王寺 => OK
- 綱重の父は家光 => ない!
元のクエリには「綱重」も「家光」も登場しないので、これは納得。
質問文をrefineしてmulti hopをなくす
関連tripleによって質問文を部分解決し、より直接的な質問に変形することを考えます。
from textwrap import dedent
def refine_query(query: str):
triples = similar_triples(query)
triples_str = ",\n".join([json.dumps(t, ensure_ascii=False) for t in triples])
prompt = dedent(f"""
you are AI who can extract fact from knowledge graph.
graph is composed from triples.
triple difinition: {{s(subject),r(relation),o(object)}}
ex. {{s: 太郎, r:好き, o: 花子}} means 太郎は花子が好きだ
context(factoids):
{triples_str}
Based on this context, refine query to more simple one, or return input query.
Don't refer any other information except for this context.
Think step by step, but don't output thinking process.
keep in mind,
- original query and refined query has same type(5W1H, bool).
- if original query is asking who, refined one should be asking who too.
- you cannot change predicate
ex.
context: 太郎の妻は花子です
query: 太郎の妻の父は誰ですか?
correct output: 花子の父は誰ですか?(refined!)
ex.
context: 太郎の妻は花子です
query: 花子の父は誰ですか?
correct output: 花子の父は誰ですか?(no information to refine, keep original)
ex.
context: 太郎の妻は花子です
query: 花子の夫は誰ですか
wrong output: 太郎です(this is answer. not question)
wrong output: 太郎は誰ですか?(tautology)
wrong output: 太郎ですか?(you changed question type. also lack of subject)
wrong output: 夫は誰ですか?(you changed question type. also lack of subject)
wrong output: 花子の夫は太郎ですか?(changed question type from who to yes/no)
correct output: 花子の夫は誰ですか(keep original)
ex.
context:アメリカの首都はワシントンです
query: ワシントンを首都とする国はどこですか?
wrong output: アメリカはどこの国ですか?(tautology)
correct output: ワシントンはどこの国の首都ですか?
query: {query}
output:
""")
# print(prompt)
res = client.chat.completions.create(
model="gpt-4-1106-preview",
messages=[{"role":"user","content":prompt}],
)
return res.choices[0].message.content
効果を確認
refined = refine_query("徳川家宣の父方の祖父の墓所は何というお寺にありますか?")
print(refined)
refined = refine_query(refined)
print(refined)
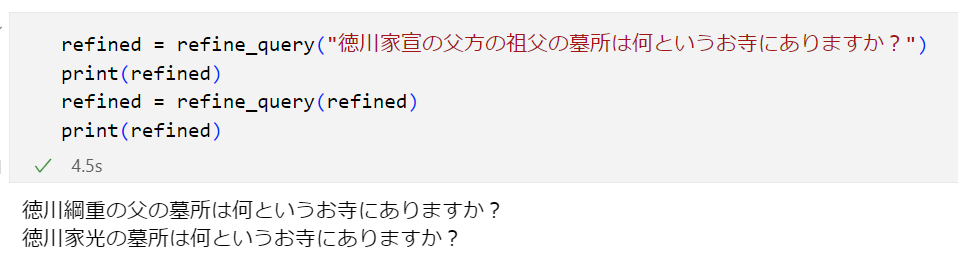
汎用化
answer or refine-query する処理を作って、呼び出し続ける!
from textwrap import dedent
def main(query: str):
triples = similar_triples(query)
# print(triples)
triples_str = ",\n".join([json.dumps(t, ensure_ascii=False) for t in triples])
prompt = dedent(f"""
you are AI who can extract fact from knowledge graph.
graph is composed from triples.
triple difinition: {{s(subject),r(relation),o(object)}}
ex. {{s: 太郎, r:好き, o: 花子}} means 太郎は花子が好きだ
context(factoids):
{triples_str}
Based on this context, refine query to more simple one, or answer.
if both are impossible, just return input query as refined one.
Don't refer any other information except for this context.
Think step by step, but don't output thinking process.
keep in mind,
- original query and refined query has same type(5W1H, bool).
- if original query is asking who, refined one should be asking who too.
- you cannot change predicate
ex.
context: 太郎の妻は花子です
query: 太郎の妻の父は誰ですか?
correct output: 花子の父は誰ですか?(refined!)
ex.
context: 太郎の妻は花子です
query: 花子の父は誰ですか?
correct output: 花子の父は誰ですか?(no information to refine, keep original)
ex.
context: 太郎の妻は花子です
query: 花子の夫は誰ですか
wrong output: 太郎は誰ですか?(tautology)
wrong output: 太郎ですか?(you changed question type. also lack of subject)
wrong output: 夫は誰ですか?(you changed question type. also lack of subject)
wrong output: 花子の夫は太郎ですか?(changed question type from who to yes/no)
correct output: 太郎です
ex.
context:アメリカの首都はワシントンです
query: ワシントンを首都とする国はどこですか?
wrong output: アメリカはどこの国ですか?(tautology)
correct output1: ワシントンはどこの国の首都ですか?
correct output2: アメリカ
answer format should be JSON, having 'answer' and 'refinedQuery'
you should set either of them.
ex.
{{answer: "太郎", refinedQuery: null}}
{{answer: null, refinedQuery: "花子の父は誰ですか?"}}
Think step by step, but don't output thinking process.
query: {query}
output:
""")
# print(prompt)
res = client.chat.completions.create(
model="gpt-4-1106-preview",
messages=[{"role":"user","content":prompt}],
response_format={ "type": "json_object" }
)
return json.loads(res.choices[0].message.content)
answerに到達するまで(refineしながら)これを呼び続けてみます
query = "徳川家宣の父方の祖父の墓所は何というお寺にありますか?"
res = {"answer": None}
while True:
res = main(query)
print(res)
if "answer" in res and res["answer"] is not None:
break
query = res["refinedQuery"]
実行例
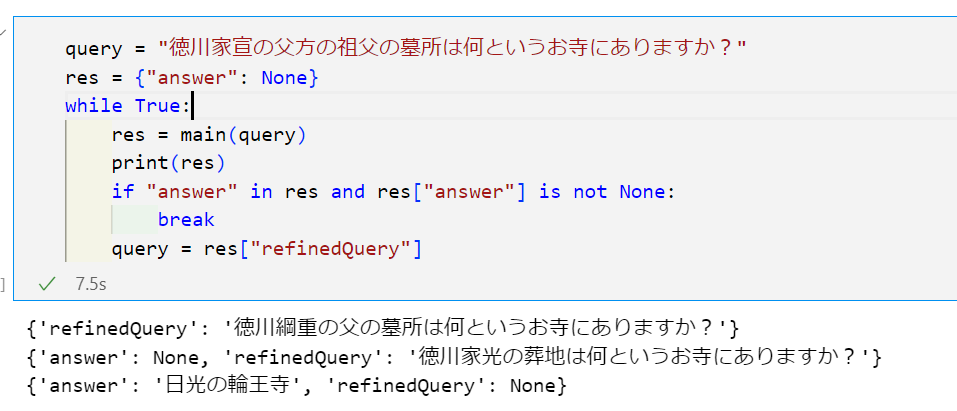
成功!
休憩:データ整形
このあとグラフによるアプローチに進むのですが、現在のtripleには問題点があります。
{"s": "綱重", "o": "徳川家光", "r": "父"},
{"s": "徳川家宣", "o": "徳川綱重", "r": "父"},
共参照が解決されていない状態です。
もしこのままグラフ化するとこんなデータができてしまいます。
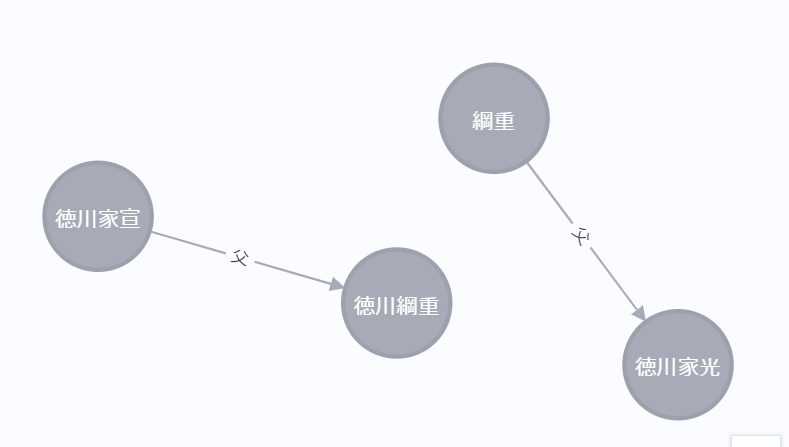
原因は、家光wikiでは徳川綱重を「綱重」としか言及していないためです。


これを名寄せにより解決し、綺麗なデータとしておきます。
今回はwikipediaのページ間リンクを使います。
from bs4 import BeautifulSoup
from wikipedia.wikipedia import WikipediaPage
def get_links(wiki_page: WikipediaPage):
res = {}
html = wiki_iemitsu.html()
soup = BeautifulSoup(html, "html.parser")
# linkテキストとhrefの組のリストを取得
for a in soup.find_all("a"):
title = a.get("title")
if title and a.text != title:
res[a.text] = title
return res
link_dic = {}
link_dic.update(get_links(wiki_iemitsu))
link_dic.update(get_links(wiki_ienobu))
link_dic
結果

先に保存したtriplesに対して、いま得た名寄せを適用します。
import json
with open('output.json') as f:
output = json.load(f)
for rec in output:
rec["s"] = link_dic.get(rec["s"], rec["s"])
rec["o"] = link_dic.get(rec["o"], rec["o"])
with open('output2.json', 'w') as f:
json.dump(output, f, ensure_ascii=False, indent=4)
問題のtripleはこうなりました。
{"s": "徳川綱重", "o": "徳川家光", "r": "父"},
{"s": "徳川家宣", "o": "徳川綱重", "r": "父"},
知識グラフアプローチ2(グラフDBで直接回答を得る)
ここまでtripleをただ文字列として扱ってきましたが、ちゃんとグラフとして活用する方法も試します。
各種DBと言語がありますが、ここではneo4jとcypherを使います。
neo4j環境準備
ver5系だとapocやgdsがうまくセットアップできなかったためver4を使います。
docker-compose.yml
version: '3'
services:
neo4j:
image: neo4j:4.4.29
container_name: neo4j
volumes:
- ./neo4j/data:/data
- ./neo4j/plugins:/plugins
- ./neo4j/logs:/logs
- ./neo4j/import:/import
- ./neo4j/init:/init
ports:
- "7474:7474"
- "7687:7687"
environment:
- NEO4JLABS_PLUGINS=["apoc","graph-data-science"]
- NEO4J_apoc_export_file_enabled=true
- NEO4J_apoc_import_file_enabled=true
- NEO4J_apoc_uuid_enabled=true
- NEO4J_dbms_security_procedures_unrestricted=apoc.*,gds.*
- NEO4J_dbms_security_procedures_whitelist=apoc.*,gds.*
- NEO4J_dbms.security.procedures.allowlist=apoc.*,gds.*
- NEO4J_dbms_memory_heap_initial__size=512m
- NEO4J_dbms_memory_heap_max__size=2G
- NEO4J_dbms_default__listen__address=0.0.0.0
- NEO4J_dbms_connector_bolt_listen__address=:7687
- NEO4J_dbms_connector_http_listen__address=:7474
- NEO4J_dbms_connector_bolt_advertised__address=:7687
- NEO4J_dbms_connector_http_advertised__address=:7474
- NEO4J_dbms_allow__upgrade=true
- NEO4J_dbms_default__database=neo4j
- NEO4J_AUTH=neo4j/password
便利クラスを作っておきます。
import os
from neo4j import GraphDatabase
class Neo4jConnection:
def __init__(self, uri, user, pwd):
self.__uri = uri
self.__user = user
self.__pwd = pwd
self.__driver = None
try:
self.__driver = GraphDatabase.driver(self.__uri, auth=(self.__user, self.__pwd))
except Exception as e:
print("Failed to create the driver:", e)
def close(self):
if self.__driver is not None:
self.__driver.close()
def reset(self):
with self.__driver.session() as session:
session.run("MATCH (n) DETACH DELETE n")
def query(self, query, parameters=None, db=None):
assert self.__driver is not None, "Driver not initialized!"
session = None
response = None
try:
session = self.__driver.session(database=db) if db is not None else self.__driver.session()
response = list(session.run(query, parameters))
except Exception as e:
print("Query failed:", e)
finally:
if session is not None:
session.close()
return response
環境変数からdockerで建てたローカルneo4jの接続情報を取得し、接続インスタンスを作ります。
conn = Neo4jConnection(
uri=os.environ['NEO4J_URI'], # ex. neo4j://localhost:7687
user=os.getenv('NEO4J_USERNAME'), # ex. neo4j
pwd=os.getenv('NEO4J_PASSWORD') # ex. password
)
tripleを登録する
import json
from tqdm import tqdm
with open("output2.json", "r") as f:
triples = json.load(f)
for triple in tqdm(triples):
query = """
MERGE (subject:Entity {name: $subject})
MERGE (object:Entity {name: $object})
WITH subject, object
CALL apoc.create.relationship(subject, $relationship, {}, object) YIELD rel
RETURN rel
"""
conn.query(query, parameters={'subject': triple["s"], 'relationship': triple["r"], 'object': triple["o"]})
ちなみにrelationship生成にapoc関数を使っているのは、生cypherだとnameが日本語のrelationshipをcreateできないためです(エラーになる)。
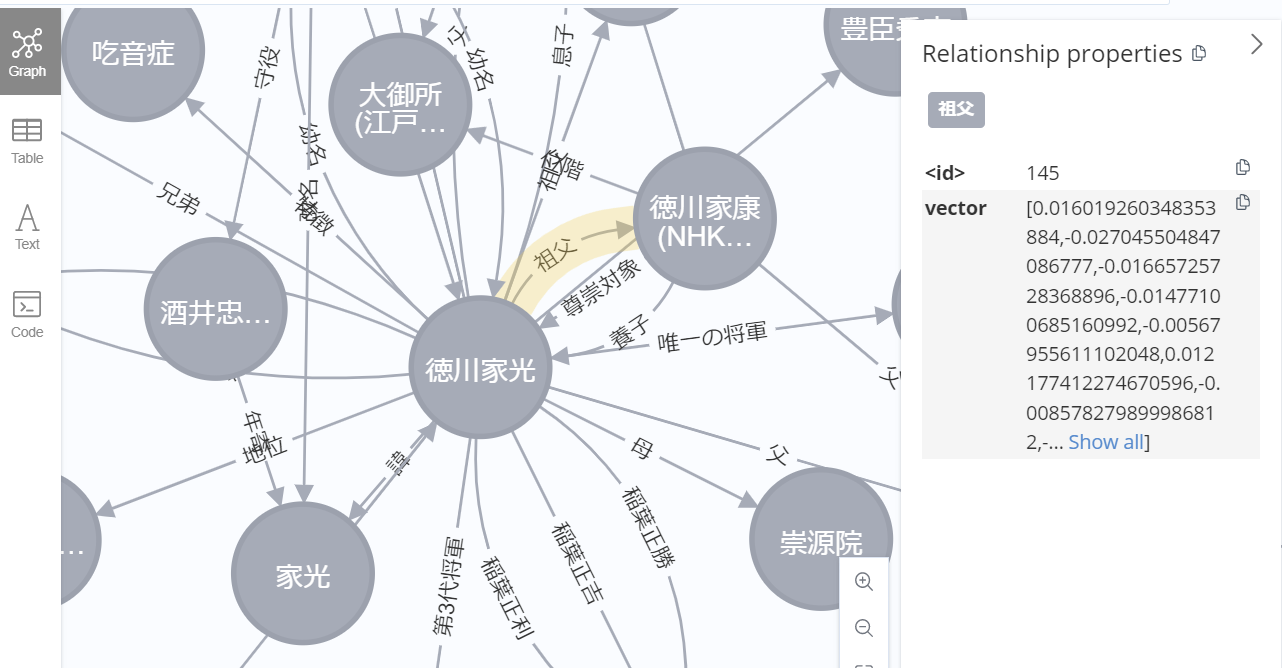
結果
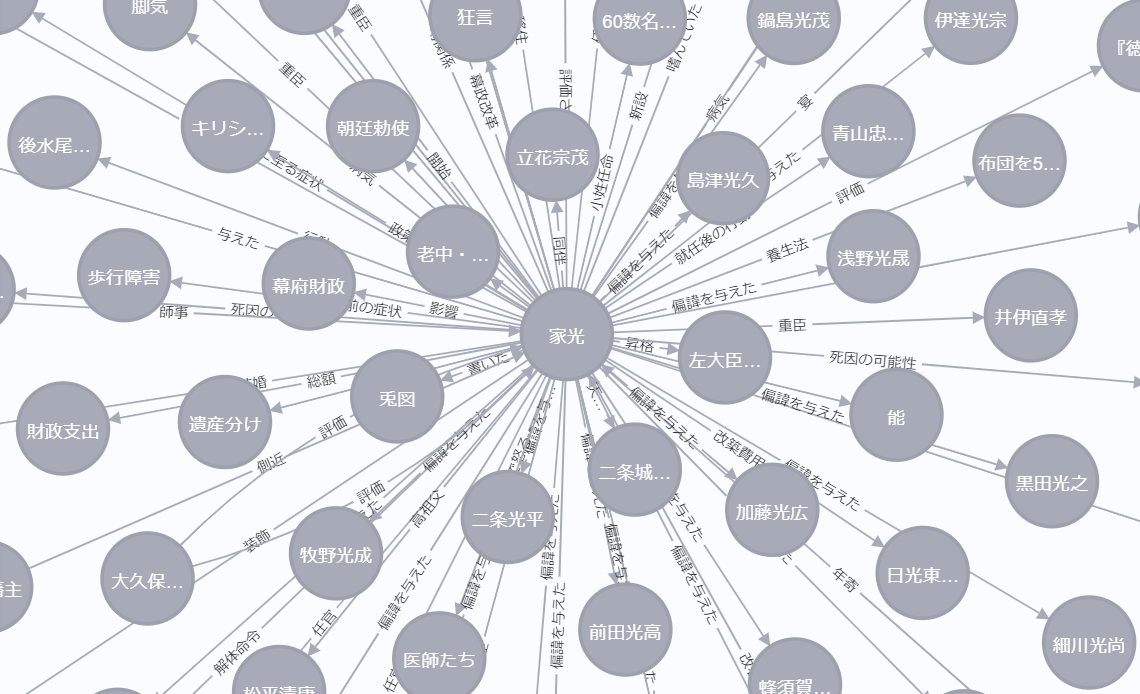
(立花宗茂が近くにいる!嬉しい!)
先回りして、回答に必要な情報が含まれることを確かめておきます。
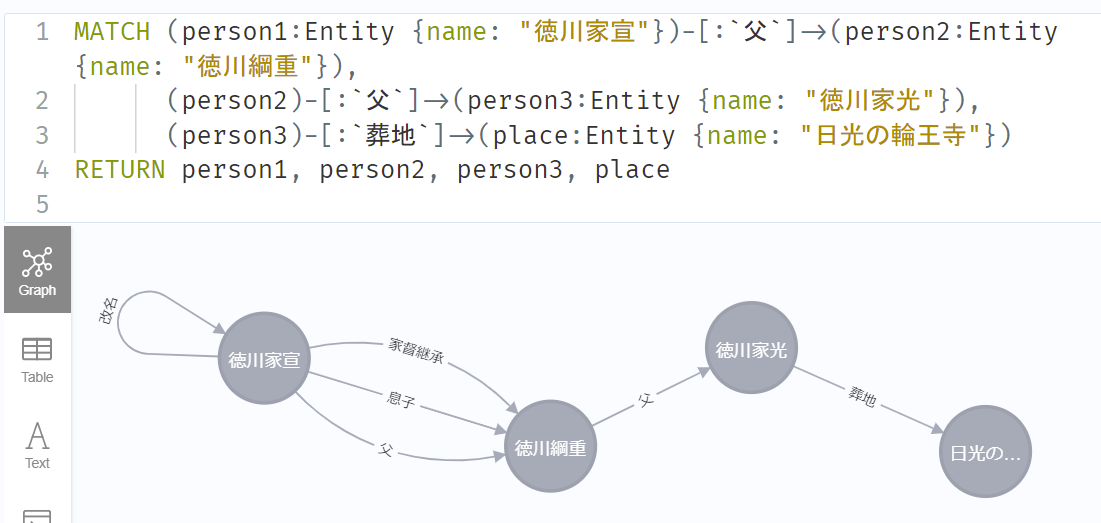
ちょっとミスもありますが、回答に至るパスは確かに存在します。
langchainのcypherChainを試す
langchainにはGraphCypherQAChainというのがあり、グラフschemaと質問文を渡すと、裏でcypherクエリを組み立てて(text2cypher)結果を取得し、回答してくれます。
from langchain.chains import GraphCypherQAChain
from langchain.graphs import Neo4jGraph
import os
graph = Neo4jGraph(
url=os.getenv('NEO4J_URI'),
username=os.getenv('NEO4J_USERNAME'),
password=os.getenv('NEO4J_PASSWORD')
)
cypher_chain = GraphCypherQAChain.from_llm(
graph=graph,
llm=ChatOpenAI(temperature=0, model="gpt-4-1106-preview"),
validate_cypher=True,
verbose=True
)
試してみます。
cypher_chain.run("徳川家宣の父は?")
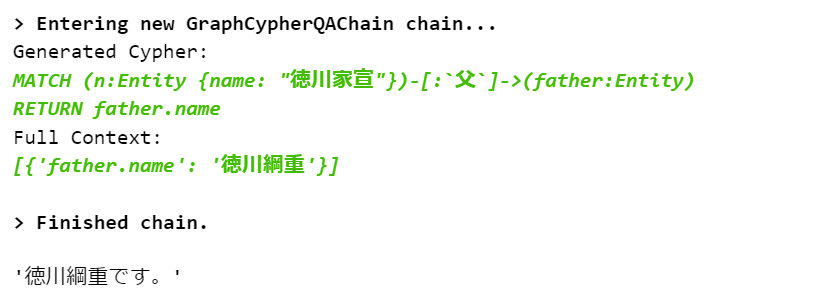
cypher_chain.run("徳川家宣の祖父は?")

これは家宣ノードと家光ノードの間に「祖父」リンクが存在しないためです。
これこそ知識グラフに付随する典型的な問題で、例えば知識グラフ補完/リンク推定という解決策があります。統計的自然言語処理によって、例えば「家宣 - 祖父 -> 家光」というrelationshipを推定作成してしまうような処理です。そちらは別の機会に試してみようと思います。
雲行きを怪しみつつ、本題クエリもやってみます。
cypher_chain.run("徳川家宣の父方の祖父の墓所は何というお寺にありますか?")

実はこれメチャメチャ惜しいです。「祖父」を使わずに「父」の「父」と分解してくれたのが素晴らしい。「墓所 => 葬地」に変えれば正解します。
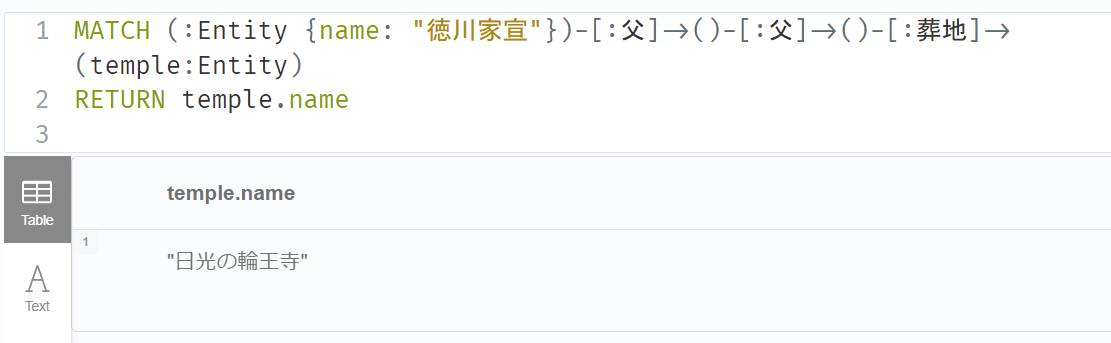
GraphCypherQAChainの実装はそれほど複雑ではないです。
graph schemaとユーザクエリを受け取って、うまくschemaに合うように、cypherクエリに変換してくれます。
graph schemaには全relationshipの情報が入ってます。
「うまくschemaに合うように」とは、schemaに含まれるrelationshipを使ってくれるという意味です。
にも拘らず、上記の失敗例では、
- 生成cypherが(「父」ではなく)「祖父」relationshipを使ってしまった
- 生成cypherが(「葬地」ではなく)「墓所」relationshipを使ってしまった
ことによりクエリが空振りしています。なぜか?
実は元データtripleに、これらのrelationshipも存在してました。
{"s": "徳川家光", "o": "浅井長政", "r": "祖父"},
{"s": "徳川家光", "o": "徳川家康", "r": "祖父"},
{"s": "徳川家宣", "o": "三縁山広度院増上寺","r": "墓所"},
つまり少々状況がややこしいのですが、
GraphCypherQAChainの機能としては、お題クエリ:
「徳川家宣の父方の祖父の墓所は何というお寺にありますか?」
をcypher化するのに際して、もしschemaに「父」「葬地」しかrelastionshipが存在しなければなるべくそれらで表現しようとするところ、
別データ由来の「祖父」「墓所」がschemaに存在するためにそれらでcypherクエリを作ってしまう、という問題が生じています。
ちなみに家光の母は浅井三姉妹の三女「お江の方」ですね。同母の姉が千姫です。
GraphCypherQAChainのpromptを改造する
本筋はグラフ側でrelationshipの統合やリンク補完を行うべきなのだと思いますが、すでに(GraphCypherQAChain内部で)LLMの力を多用してしまっているので、その路線であがいてみます。
from langchain_core.prompts.prompt import PromptTemplate
MY_CYPHER_GENERATION_TEMPLATE = """
Task:Generate Cypher statement to query a graph database.
Instructions:
Use only the provided relationship types and properties in the schema.
Do not use any other relationship types or properties that are not provided.
Schema:
{schema}
Note: Do not include any explanations or apologies in your responses.
Do not respond to any questions that might ask anything else than for you to construct a Cypher statement.
Do not include any text except the generated Cypher statement.
keep in mind, target graph is not treated by Knowledge Graph Completion or link prediction.
I mean, concepts of relationships may overlap with each other.
For example, when you search grandchild of a person, and you can see '子','孫' in relationships,
you should create compound cypher query like:
```
MATCH (n:Entity {{name: "対象の人物名"}})-[:`孫`]->(grandchild:Entity)
RETURN grandchild
UNION
MATCH (n:Entity {{name: "対象の人物名"}})-[:`子`]->()-[:`子`]->(grandchild:Entity)
RETURN grandchild
```
For example, when you search homeland of a person, and you can see '出身地','で生まれた' in relationships,
```
MATCH (n:Entity {{name: "対象の人物名"}})-[:`出身地`]->(grandchild:Entity)
RETURN homeland
UNION
MATCH (n:Entity {{name: "対象の人物名"}})-[:`で生まれた`]->(grandchild:Entity)
RETURN homeland
```
or more refined version may be:
```
MATCH (n:Entity {{name: "対象の人物名"}})-[r]->(location:Entity)
WHERE type(r) IN ['出身地', 'で生まれた']
RETURN homeland
```
The question is:
{question}"""
cypher_prompt = PromptTemplate(
input_variables=["schema", "question"], template=MY_CYPHER_GENERATION_TEMPLATE
)
from langchain.chains import GraphCypherQAChain
from langchain.chat_models import ChatOpenAI
cypher_chain = GraphCypherQAChain.from_llm(
graph=graph,
llm=ChatOpenAI(temperature=0, model="gpt-4"),
cypher_prompt=cypher_prompt,
validate_cypher=True,
verbose=True
)
先ほど失敗したものを試してみます。
cypher_chain.run("徳川家宣の祖父は?")

改善しました。しかし本題クエリはダメでした。
cypher_chain.run("徳川家宣の父方の祖父の墓所は何というお寺にありますか?")

ベクトル類似度で検索する
GraphCypherQAChainは忘れて、より汎用的に類似概念を検索することを考えます。
安直にOpenAI embeddingを使ってみます。
登録済relationshipにvector属性を付与します。
from langchain.embeddings import OpenAIEmbeddings
from tqdm import tqdm
embeddings = OpenAIEmbeddings()
rels = []
for t in triples:
rels.append(t["r"])
rels = list(set(rels))
rel_vecs = embeddings.embed_documents(rels)
for rel_name, vector_value in tqdm(zip(rels, rel_vecs)):
conn.query(f"""
MATCH ()-[r:`{rel_name}`]-()
SET r.vector = $vectorValue
RETURN count(r) as updatedRelations
""", parameters={'vectorValue': vector_value})
結果
これを使えば、ベクトル類似度によりfuzzyな検索ができるはずです。
多分に誘導的ですが、本題クエリに対してこれが有効なことを確かめておきます。
vector_value = embeddings.embed_query("墓所")
res = conn.query("""
MATCH (child:Entity {name: "徳川家宣"})-[:`父`]->(father:Entity)-[:`父`]->(grandfather:Entity)
MATCH (grandfather: Entity)-[r]->(graveyard:Entity)
WITH grandfather, r, graveyard, gds.similarity.cosine(r.vector, $vectorValue) AS similarity
WHERE similarity >= 0.9
RETURN graveyard.name
""", parameters={'vectorValue': vector_value})
res[0].values()[0] # 日光の輪王寺
apocにもcosine類似度関数はありますが、今回はgdsの方を使いました。
0.9以上で類似relationshipとみなすことで「墓所≒葬地」を解決できました。
fuzzy text2cypherとして汎用化
折角グラフを使っているので、汎用的な方法で、一発で回答に辿りつきたい。
ということで先ほどのベクトル類似度による方法を汎用化してみます。
from openai import OpenAI
from textwrap import dedent
def text2cypher(query: str):
client = OpenAI()
prompt = dedent(
f"""
create cypher statement corresponding to the given query.
We have a knowledge graph consisting of node(type: Entity, having name property in Japanese) and relation(having name property in Japanese)
each relationship(not node) has 'vector' property, expressing meaning of the relationship,
so that you can execute 'semantic search' about relationship.
you can use graph-data-science library to calculate vector similarity, like:
gds.similarity.cosine(vector1, vector2)
you can calculate a concept vector using:
CALL apoc.ml.openai.embedding([context], $apiKey) YIELD embedding
ex. if you calculate vector of '犬',
CALL apoc.ml.openai.embedding(['犬'], $apiKey) YIELD embedding
here, 'embedding' is a vector itself, not object.
you can calculate vector similarity only for relationship/predicate.
steps:
- first, simply construct your original cypher query
- next, rewrite original query with breaking each relationship into a series of simple, primitive concepts.
ex. "node1-[nephew]->node2" => "node1-[sibling]->node3-[son]->node2"
ex. "node1-[grandchild]->node2" => "node1-[child]->node3-[child]->node2"
keep in mind that:
- assume our knowledge graph consists of primitive relationships
- you don't know the actual relationship name, so you CANNOT set relationship name directly in cypher query.
ex. if you use '子', actual predicate may be '子供' in the graph. No assurance.
- these rules are only applied to relationship, not node.
- rewrite the query with fuzzy match relationships(for all relationship!):
- fuzzy match can be done by calculating vector similarity between relationship
- regard 2 relationships as same if their similarity >= 0.9
- for every predicate/relationship in original query:
1. execute apoc.ml.openai.embedding to get vector
2. search similar relationship in graph by calculating similarities
rules:
- you must not query relationship name directly in query, without exception.
You must parameterize them instead.
Because target nodes to be searched, are not always linked by input relationship name, but linked by similar name.
you can detect such similar relationship by calculating similarities.
- please let $apiKey as it is so that user can set outside.
- think step by step, but do not output any text except the generated Cypher statement
query: {query}
response format: JSON like {{output: "XXX"}}
"""
)
response = client.chat.completions.create(
model="gpt-4-1106-preview",
temperature=0,
response_format={ "type": "json_object"},
messages=[{"role":"user","content": prompt}],
)
return json.loads(response.choices[0].message.content)["output"]
本題クエリで試します。
cypher = text2cypher("徳川家宣の父方の祖父の墓所は何というお寺にありますか?")
print(cypher)
res = conn.query(cypher, parameters={'apiKey': os.environ['OPENAI_API_KEY']})
res

知識グラフアプローチ3(グラフRAG × agent)
アプローチ2では少々強引なcypherクエリ化で「一発で回答を得る」方法を試しました。ただこれは知識グラフや概念類似度の正確さに依存しており、たまたまうまくいったという不穏な感じもします。
そこでcypher chainをagent化し、nodeを少しずつ辿って回答nodeに近づいていけないかを試してみます。すなわち、
家宣 =(父)=> 綱重 =(父)=> 家光 =(墓所)=> 輪王寺
という探索経路です。
agent = initialize_agent(
tools=[Tool(name = "searcher", func=cypher_chain, description="")],
llm=ChatOpenAI(temperature=0, model="gpt-4"),
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
agent.run("徳川家宣の父方の祖父の墓所は何というお寺にありますか?")

「祖父=家光」までは辿り着きますが、やはり「墓所≒葬地」がcypher化で反映されないため回答が得られません。
先程と同様に、fuzzy検索を行うためのcypher chainを作ります。
from langchain.chains import GraphCypherQAChain
from langchain.chat_models import ChatOpenAI
apiKey = os.environ['OPENAI_API_KEY']
MY_CYPHER_GENERATION_TEMPLATE2 = dedent(f"""
create cypher statement corresponding to the given query.
We have a knowledge graph consisting of node(type: Entity, having name property in Japanese) and relation(having name property in Japanese)
each relationship(not node) has 'vector' property, expressing meaning of the relationship,
so that you can execute 'semantic search' about relationship.
you can use graph-data-science library to calculate vector similarity, like:
`gds.similarity.cosine(vector1, vector2)`
you can calculate a concept vector using:
CALL apoc.ml.openai.embedding([context], '{apiKey}') YIELD embedding
ex. if you calculate vector of '犬',
CALL apoc.ml.openai.embedding(['犬'], '{apiKey}') YIELD embedding
here, 'embedding' is a vector itself, not object.
you can calculate vector similarity only for relationship/predicate.
steps:
- first, simply construct your original cypher query
- next, rewrite original query with breaking each relationship into a series of simple, primitive concepts.
ex. "node1-[nephew]->node2" => "node1-[sibling]->node3-[son]->node2"
ex. "node1-[:孫]->node2" => "node1-[:子]->node3-[:子]->node2"
keep in mind that:
- assume our knowledge graph consists of primitive relationships
- you don't know the actual relationship name, so you CANNOT set relationship name directly in cypher query.
ex. if you use '子', actual predicate may be '子供' in the graph. No assurance.
- these rules are only applied to relationship, not node.
- rewrite the query with fuzzy match relationships(for all relationship!):
- fuzzy match can be done by calculating vector similarity between relationship
- regard 2 relationships as same if their similarity >= 0.9
- for every predicate/relationship in original query:
1. execute CALL apoc.ml.openai.embedding to get vector
2. search similar relationship in graph by calculating similarities
rules:
- you must not query relationship by name directly in query.
You must parameterize them instead.
Because target nodes to be searched, are not always linked by in[ut] relationship name, but linked by similar name.
you can detect such similar relationship by calculating similarities.
- think step by step, but do not output any text except the generated Cypher statement
for example, when you search O in S-R->O, the query would be like:
MATCH (n:Entity <name: 'S'>)-[r]->(m:Entity)
CALL apoc.ml.openai.embedding(['R'], '<api key>') YIELD embedding
WITH m, r, gds.similarity.cosine(r.vector, embedding) AS similarity
WHERE similarity >= 0.9
RETURN m.name as answer
question: {{question}}
output:
"""
)
cypher_prompt2 = PromptTemplate(
input_variables=["schema", "question"], template=MY_CYPHER_GENERATION_TEMPLATE2
)
cypher_chain2 = GraphCypherQAChain.from_llm(
graph=graph,
llm=ChatOpenAI(temperature=0, model="gpt-4"),
cypher_prompt=cypher_prompt2,
validate_cypher=True, # Validate relationship directions
verbose=True
)
langchainのdefaultのcypher promptでは、知識グラフのschemaを渡していますが、今回fuzzy検索をするので(少なくともrelationshipの)schema情報は不要です。
これでagentを作り、実行します。
agent = initialize_agent(
tools=[Tool(name = "searcher", func=cypher_chain2, description="")],
llm=ChatOpenAI(temperature=0, model="gpt-4"),
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
agent.run("徳川家宣の父方の祖父の墓所は何というお寺にありますか?")

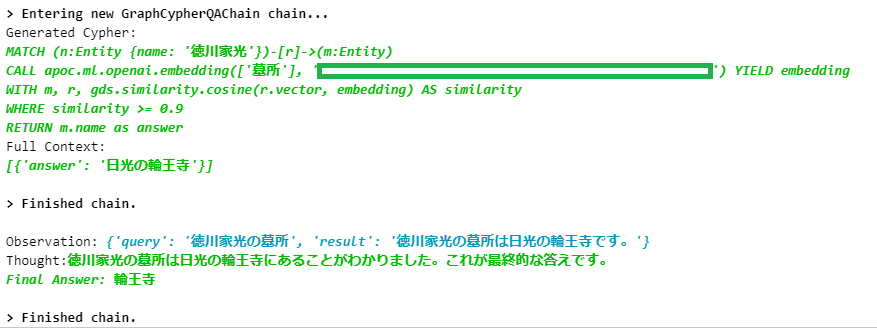
※ 四角にはOpenAI API Keyが入ってます
おまけ
ようやく家光の墓に辿り着きました。