前回の記事 ではシンプルなロードバランサーを Go で一から作成しました。
しかし、バックエンドの一部がダウンしている状況では、そのバックエンドへロードバランシングした際にクライアントへ HTTP502 をレスポンスしてしまいます。
このような状況では、応答しないサーバーへのロードバランシングを行わないように、バックエンドへのヘルスチェック機能を追加したいと思います。
ヘルスチェック
まずどのようにバックエンドの生死状態を管理するかですが、今回は Backend struct に IsAlive フィールドを追加して行うことにします。
type Backend struct {
Url *url.URL // Backend's URL
ReverseProxy *httputil.ReverseProxy // reverse proxy instance
+ IsAlive bool // false if health check failed
}
そして Go 標準ライブラリにある net.DialTImeout を使用して簡単な TPC のヘルスチェックを行うことにします。
package healthCheck
const HEALTH_CHECK_TIMEOUT = 2 * time.Second
func isBackendAlive(u *url.URL) bool {
port := u.Port()
if port == "" {
port = "80"
}
address := u.Host + ":" + port
con, err := net.DialTimeout("tcp", address, HEALTH_CHECK_TIMEOUT)
if err != nil {
return false
}
con.Close()
return true
}
競合状態
さて Node.js のような基本的にシングル スレッドで動作するランタイム上では前述のヘルスチェックの処理を愚直に書いていけば OK ですが、Go は基本的にマルチスレッド プログラムであるため、競合状態を考慮した上で並行処理を進めなければいけません。
どういうことかというと、まず Go の HTTP サーバーは各リクエストごとに goroutine を生成します (つまり各リクエストはそれぞれ別々のスレッド上で処理されます)。
そのため、ある時点である変数の読み取りと書き込みが、具体的には以下の様な処理が同時に発生する可能性があります。
- クライアントからのリクエストを処理するスレッド:
Backend.IsAliveの読み取り - バックエンドをヘルスチェックするスレッド:
Backend.IsAliveの更新

チャネルによる並行処理
Go には並行処理を記述するための基本的な要素として、Mutex とチャネルというものがあります。
今回のようなケースではシンプルに Mutex を使っても良さそうですが、筆者の勉強も兼ねてチャネルによる並行処理の管理を行ってみます (Share Memory By Communicating
)。
具体的には、変数にアクセスできるスレッドを一つに制限し、他のスレッドからその変数へのアクセスはチャネル (キュー) 経由でリクエストを行うようにします。
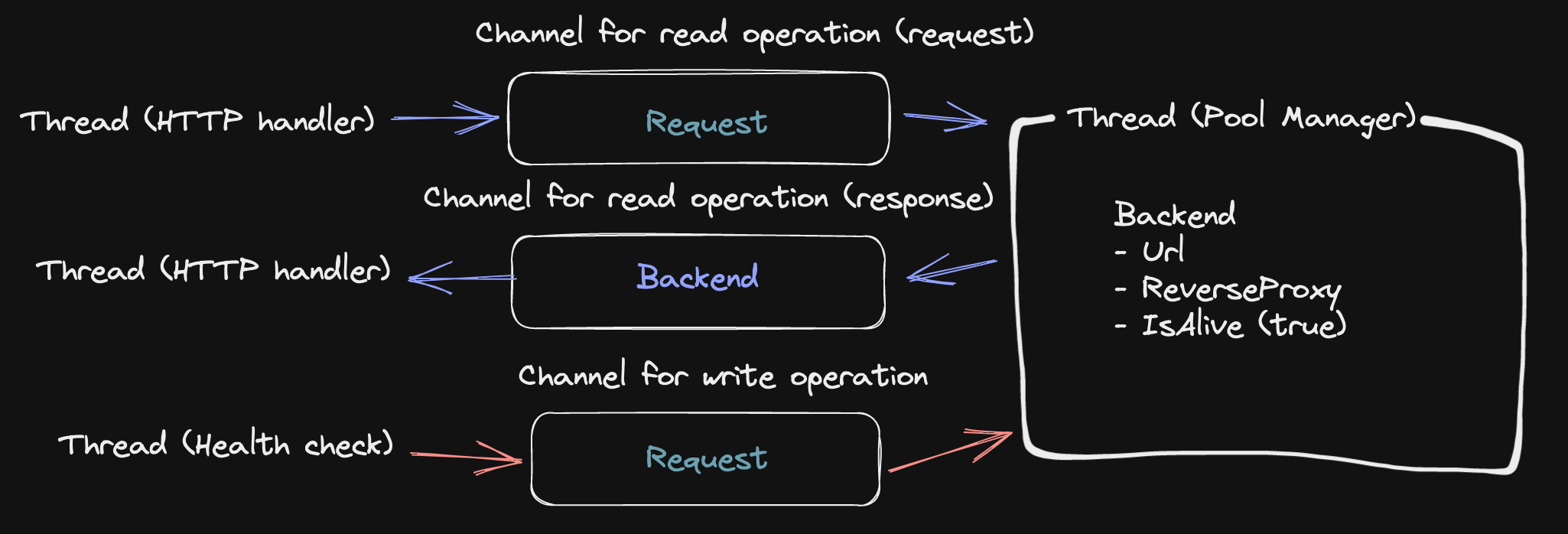
いざ実装
チャネルに流すデータ構造を定義します。
+type HealthCheck struct {
+ index int
+ isAlive bool
+}
+type AvailableBackend struct {
+ backend *models.Backend
+ err error
+}
pool の変数へのアクセスは pool のポインター レシーバー poolManager で管理します。
// poolManager responsible for managing backends and other resources in Pool
func (p *Pool) poolManager() {
for {
select {
// Health check
case hc := <-p.hcStream:
p.backends[hc.index].IsAlive = hc.isAlive
// Available backend
case <-p.reqStream:
backend, err := p.nextBackend()
p.resStream <- AvailableBackend{backend: backend, err: err}
// Clone backends
case <-p.cloneRequestStream:
cloned := make([]models.Backend, len(p.backends))
for i, b := range p.backends {
cloned[i] = *b
}
p.cloneResponseStream <- cloned
}
}
}
そして pool 生成時に poolManager を別スレッドで起動するようにします。
(ヘルスチェックの際に各バックエンドの情報が必要となるため、バックエンド情報をクローンした clone も合わせて作成します。)
type Pool struct {
backends []*models.Backend // array of backends
currentIndex int // current index of serving backend
+ reqStream chan interface{} // used to request next available backend
+ resStream chan AvailableBackend // used to share next available backend
+ hcStream chan HealthCheck // health check stream
+ cloneRequestStream chan interface{} // use to request an array of cloned backends
+ cloneResponseStream chan []models.Backend // used to send an array of cloned backends
}
// ...
func New(serverUrls []string) *Pool {
+ reqStream := make(chan interface{})
+ resStream := make(chan AvailableBackend)
+ hcStream := make(chan HealthCheck)
+ cloneRequestStream := make(chan interface{})
+ cloneResponseStream := make(chan []models.Backend)
backends := make([]*models.Backend, len(serverUrls))
for i, serverUrl := range serverUrls {
backends[i] = models.NewBackend(serverUrl)
log.Printf("server #%d: %s registered.\n", i, backends[i].Url)
}
pool := &Pool{
backends: backends,
currentIndex: len(backends) - 1,
+ reqStream: reqStream,
+ resStream: resStream,
+ hcStream: hcStream,
+ cloneRequestStream: cloneRequestStream,
+ cloneResponseStream: cloneResponseStream,
}
+ go pool.poolManager()
return pool
}
nextBackend() で使用しているラウンドロビンもヘルスチェックを考慮する形に直します。
func (p *Pool) nextBackend() *models.Backend {
// Round Robin
- p.currentIndex = (p.currentIndex + 1) % uint64(len(p.backends))
- return p.backends[p.currentIndex]
+ for i := 0; i < len(p.backends); i++ {
+ p.currentIndex = (p.currentIndex + 1) % len(p.backends)
+ if p.backends[p.currentIndex].IsAlive {
+ return p.backends[p.currentIndex], nil
+ }
+ }
+ log.Println("All backend servers are down!")
+ return &models.Backend{}, errors.New("all backend servers are down")
}
前回作成した CreateHandler 関数上で reqStream/resStreamチャネルを使うように更新します。
// Returns an HTTP handler for load balancing
func (p *Pool) CreateHandler() HttpHandler {
return func(w http.ResponseWriter, r *http.Request) {
- b := p.nextBackend()
- b.ReverseProxy.ServeHTTP(w, r)
+ // Send a request
+ p.reqStream <- struct{}{}
+ // Receive a response
+ available := <-p.resStream
+ if available.err != nil {
+ http.Error(w, "BadGateway!!", http.StatusBadGateway)
+ return
+ }
+ available.backend.ReverseProxy.ServeHTTP(w, r)
}
}
チャネルを直接露出するよりも、パブリックなポインター レシーバーで抽象化したほうが読みやすいため、定義します。
+// Updates status of backends[i]
+func (p *Pool) UpdateBackendHealth(i int, isAlive bool) {
+ p.hcStream <- HealthCheck{index: i, isAlive: isAlive}
+}
このレシーバーを使用してヘルスチェックを行う関数を別のパッケージに定義します。
package healthCheck
const DURATION = 3 * time.Second
type pool interface {
GetClonedBackends() []models.Backend
UpdateBackendHealth(idx int, isAlive bool)
}
func TcpHealthCheck(p pool) {
ticker := time.NewTicker(DURATION)
log.Println("Health check started")
for range ticker.C {
clonedBackends := p.GetClonedBackends()
for i, b := range clonedBackends {
isAlive := isBackendAlive(b.Url)
if isAlive != b.IsAlive {
p.UpdateBackendHealth(i, isBackendAlive(b.Url))
}
}
}
}
最後に main.go を更新して完了です。
func main() {
c, err := config.LoadConfigFile(CONFIG_FILE_NAME)
if err != nil {
panic(err)
}
p := pool.New(c.ServerUrls)
+ go healthCheck.TcpHealthCheck(p)
mux := http.NewServeMux()
mux.HandleFunc("/", p.CreateHandler())
server := http.Server{Addr: ":3000", Handler: mux}
fmt.Println("Load balancer is up and running - http://localhost:3000")
if err := server.ListenAndServe(); err != nil {
log.Fatal(err)
}
}
これで LB を起動し、別ターミナル上で docker stop web2 などで任意のバックエンドを停止させると、ヘルスチェックが検知してロードバランシングの対象からそのバックエンドを外してくれるようになります!
次回はこの LB に別のロードバランシング アルゴリズムを追加したいと思います。