TL;DR
Pandasでデータの前処理をする場合はapply()を使っていこうという話をまとめます。
Pandasとは
http://pandas.pydata.org/pandas-docs/stable/
pandasは、Pythonにおいて、データ解析に必要なメソッドを用意したライブラリです。時系列データから、テーブルのようなデータ系列まで幅広く対応でき、かつ高速に集計できるようになっています。今のご時世では「Pythonでデータ分析する」という事例はよく耳にするかと思います。
会社でのデータ分析業務
Moff社内ではデータ分析業務をする際、事前データを抽出して後、スポットで分析する場合はデータを加工することをよくやります。最終的に作りたいデータテーブルを描いた上で、それまでに前処理をいくつか走らせることになります。
初学者でなされたこと。
例えば下記のようなデータセットがあったとします。
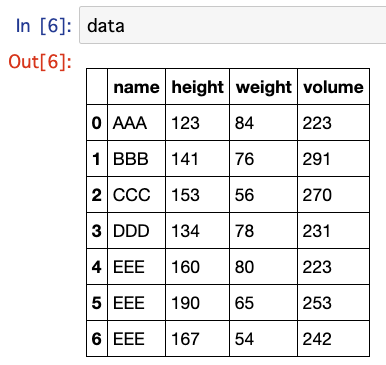
その上で、「nameの文字数を新しくcolumnに追加したい」という前処理をするとしましょう。
その時に、プログラミングを初めたばかりのインターン生に特に散見されましたが、前処理上でよく見かけるのが下記の前処理コードでした。
data['len'] = 0
for k, d in data['name'].iteritems():
data['len'][k] = len(d)
確かに出力結果はこれで事足りますし、数行程度のデータでは確かにそこまで時間を消費するものにはならないかと思います。
apply()で対処してみる。
では今度は、apply()で対処してみようと思います。
apply()とはDataFrame, Series型に備わっているメソッドの一つでDataFrame, Seriesも式はgroupbyされたDataFrameにおける各々のvalueを引数として、apply()の引数に与えられた関数のreturn値のSeries、DataFrame、もしくはスカラー値を返すことができます。
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.apply.html
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.apply.html
先ほどの例だと、lenを返す関数を作ればこういう形になります。
def return_len(x)
return len(x)
data['len'] = data['name'].apply(return_len)
lambda式(無名関数)を知っていれば、下記ようなこともできます。
data['len'] = data['name'].apply(lambda x: len(x))
と記述的には比較的シンプルにはなると思います。
気づいた方もいるかもしれませんが、今回はlen()の結果を返す関数をわざわざ関数を実装して紹介しました。よくよく考えればlen()自体も関数なので、こういう風にもできます。
data['len'] = data['name'].apply(len)
単純な処理であればforループでも解決はできるかもしれませんが、より複雑な前処理を検討する場合は、前述よりかは関数化してapply()で適用させる方が、間違い等には気づき安くなるんではないかと思います。
処理速度はどうなのか
上記の例ではデータが少量なので対して、処理速度においては差分はないかと思うので、ランダムな文字列データに対しての長さを出力する処理を適用してみた結果を示してみます。
検証環境は下記になります。
- MacBook Pro (13-inch, 2016, Four Thunderbolt 3 Ports)
- macOS Mojave 10.14.5
- プロセッサ 2.9GHz Intel Core i5
- メモリ 8GB 2133 MHz LPDR3
- 文字列データに対して新しく文字列の長さを値にいれた行を追加する処理(つまり上記のような処理)を実行完了するまでの時間を計測
| # of data | for loop | pandas.DataFrame.apply() |
|---|---|---|
| 100 | 3.907sec | 0.079sec |
| 10000 | 415.032sec | 0.231sec |
| 100000 | 3100.906sec | 1.283sec |
ご覧の通り、100件くらいでもおよそ3.8秒差、1万件、10万件単位になってくると如実に結果出力までにかかる時間の差が膨大になることがわかります。どのようなデータセット規模にせよ、どのような前処理にしても、素早く結果を知るにはapply()を使う方が得策なのは明白なのではないでしょうか。
apply()が何をしているのか。実体は?
例えばDataFrameのapplyの本体はこちら
https://github.com/pandas-dev/pandas/blob/5a7b5c958c6f004c395136f9438a1ed6c04861dd/pandas/core/frame.py#L6440
frame_apply()を追跡してみると
FrameApplyというクラスにどうも何かしら書いてる模様。
frame_apply()上にてget_result()をコールしているのでその処理を追跡します。
パラメータによっては分岐もありますが、特にOptionalな引数を与えなければ、下記が呼ばれている模様です。
apply_standard()内でlibreduction.compute_reduction()が計算本体をやっているようです。そのあとに、apply_series_generator()、wrap_results()で結果をしているようですね。
libreductionが/_lib/reduction.pyxにあるみたいです。
どうも、Reducer内にてデータをnumpy.ndarray.shapeで行列データを分割して扱うような挙動をしているようです、for i in range(self.nresults):から諸々やっている模様。
ここからNumpy上での話になりそうです。上記のコードを閲覧してみてもどうもPandas
上では計算で工夫されているポイントはなさそうに見えるのでNumpy上で処理の工夫をしているように思えます。というのも、最終的に上記のReducer上でres = self.f(chunk)とあり、Numpyのndarrayに対して関数を適用する処理以降で特に特徴的に計算処理で工夫している点が見当たらなかったからです。一応Chunk分けして処理しているような記述がありましたが、関数適用のres = self.f(chunk)の時点で実処理の詳細がこの時点では不明瞭で、以降Numpy側の処理で完結されているようにみえます。巷で言われている程度では、Numpyにおける計算処理が純Pythonのみでの計算処理に比べて速いと言われているを加味すると、多少納得いきます。
もう少し知りたいところですが、これ以上書くとボリューミーなので、Numpyにおける処理特定は別の機会にします。ともあれ、少なくてもPandas上ではないことは確定しました。(言語性能に依存しているのか計算処理で工夫しているかはいまだに不明ですが)
map, apply, applymapなどに関してその他
apply()の派生という形で、Series, DataFrameにはそれぞれmap()、applymap()が存在します。
一見何が違うんだろうと気になったので端的に調べてみたところ、下記のStackOverFlowの回答に、その違いがまとまっておりました。
https://stackoverflow.com/a/56300992/7649377
要点だけ抑えると、
- DataFrame, Series共にapply()が使用可能、applymapはDataFrame、mapはSeriesにのみ使える。
- Seriresのmapではdict, Seriresを引数として渡すとその引数のキーに応じて適用する関数を設定することができる
- apply()に関してはgroupby等の集計系処理にできたDaraFrame, Seriesでも使える
というのがポイントでしょうか。
まとめ
- apply()の使い方に慣れるだけで、前処理作業は格段に早い処理にすることができます。
- apply()が何をやっているかはそれこそPandasの中身を追ってみる。追ってみた結果Numpyにおける配列処理に帰結しているため、Numpy上のコードリーディングが必要。
次このネタで記事をかくときはNumpyを読み漁ろうと思います。
ありがとうございました。