この記事は何?
前の記事の続きとなります。
netatmoのデータ取得ができたので、このデータを使ってAWS Elasticsearch Serverでデータ取得から描画まで行います。
AWS Elasticsearch Serviceとは?
概要だけつまむと、データレイクのElasticsearchと可視化BIツールのkibanaが合体したサービス。各サービスの結合と必要な設定を担当してくれます。
AWS Elasticsearch Serviceの環境構築
AWS Elasticsearch Serviceの新規環境構築していきます。

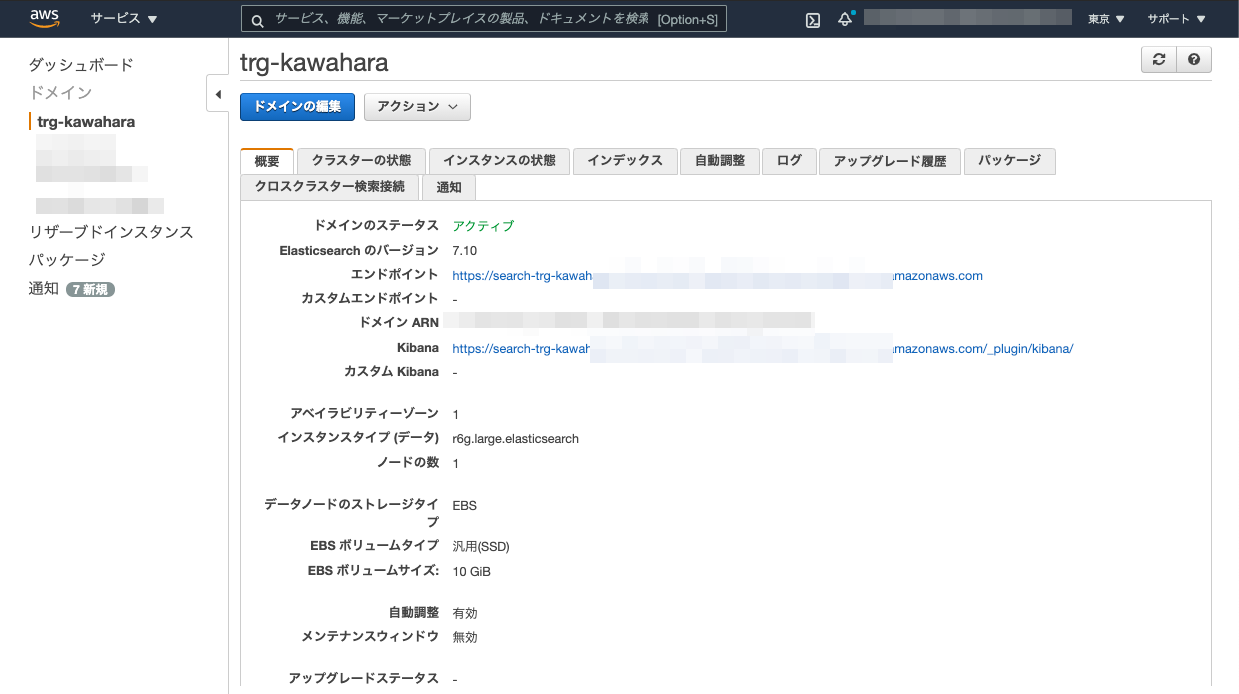
AWSコンソールを開きElasticsearch Serviceから新しいドメイン作成から環境構築します。

途中の設定のうち今回は動くことを目標とするため、デフォルトから2つ設定を変更します。
1つがネットワーク構築です。これをパブリックアクセスとすることでどこからでもアクセスが可能と変更します。
このままだとどこからでもアクセスし放題のため、次でアクセス制限をかけます。

2つ目のアクセス制限です。アクセスポリシーからCIDR表記でアクセス制限をかけます。

これから最後まで設定して、最終的に新しくドメインを取得することができ、elasticsearchとkibanaの環境が得られました。
Elasticsearchにデータを挿入する
前章で取得したnetatmoのアクセストークンを使ってデータをkibanaに流し込みます。
この時ポイントは2つあり、netatmoのデータを加工しElasticsearchが時系列として扱えるよう日付データを追加し、kibanaのエンドポイントを都度変更しデータの上書きをしないようにしています。
時系列データを扱うため、このプログラムをlambdaで定期実行にしたり、cronで定期実行にしたりして時系列として扱えるようにします。
import datetime
import json
import requests
from requests.auth import HTTPBasicAuth
def get_date_suffix():
now = datetime.datetime.now()
return now.strftime('%Y%m%d%H%M%S')
def get_station_data():
netatmo_headers = {'Content-Type': 'application/x-www-form-urlencoded', 'charset': 'UTF-8'}
netatmo_url = 'https://api.netatmo.com/api/getstationsdata'
netatmo_data = {
'access_token': 'アクセストークン'
}
resp = requests.post(url=netatmo_url, headers=netatmo_headers, data=netatmo_data)
json_data = json.loads(resp.text)
# netatmoのデータがタイムスタンプ形式から、Elasticsearchで扱える形である「yyyy/mm/dd hh:mm:ss」へと変換し、カラムを追加する。
unix_time = datetime.datetime.fromtimestamp(json_data['body']['devices'][0]['dashboard_data']['time_utc'])
json_data['body']['devices'][0]['dashboard_data']['@timestamp'] = unix_time.strftime("%Y/%m/%d %H:%M:%S")
resp_data = json.dumps(json_data)
return resp_data
# エンドポイントを上書きしないように、リクエストのたびにURIの末尾を変更している
url = 'AWS Elasticsearch Service記載のエンドポイント' + '/trg/_doc/trg-kawahara' + get_date_suffix()
headers = {
'Content-Type': 'application/json'
}
data = get_station_data()
auth = HTTPBasicAuth('kibanaのユーザーID', 'kibanaのパスワード')
basic_auth_req = requests.post(url=url, headers=headers, data=data, auth=auth)
print(basic_auth_req.text)
レスポンスは下のようにsuccessfulが帰ってきます。
{
"_index": "trg",
"_type": "_doc",
"_id": "trg-kawahara20210816192617",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
kibanaでのデータ操作:データにindexをはる
kibanaの画面からはStack Managementでデータ操作をします。
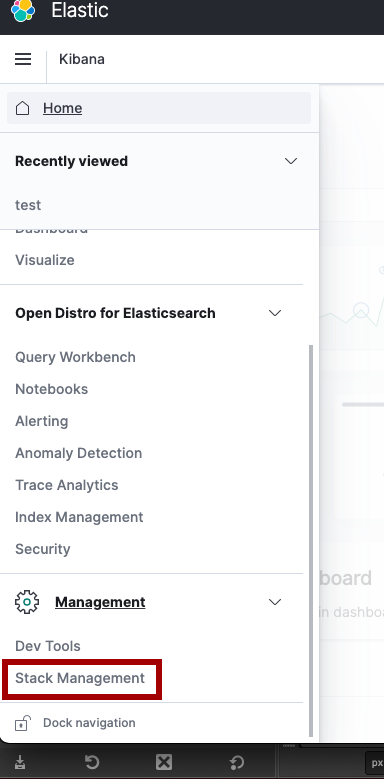
Stack ManagmentからCreateincex patternから投入データのindexを貼り、このindexを貼ったデータを使ってplotしてくことになります。
そのためまずindexを作ります。

注目点はConfigure settingsで先ほどpythonで書いた日付データが時系列データとして出てくることです。

これでデータにindexがはれたので、次は描画する部分を作ります。
kibanaでのデータ操作:描画する
データの準備ができたため、あとはデータから描画するところを作ります。
kibanaでは描画する機能をDashboardといい、Dashboardを操作して描画するものを作ります。

Create newから新しい図を作成します。

今回は折れ線グラフを描画したいため、Lineを選択します。

選択するデータのメトリクスは下図のように、Y軸にCO2濃度を、X軸に時系列をとります。
設定するだけでは何も出ないため、設定を反映します。
図の設定が終わったら、Updateをクリックして設定を反映することで、描画することができます。

あとは保存をすることで、Dashboardに描画する図が完成します。

これでデータ挿入からデータ操作、描画まで一連の動作が完了です。
あとはこれを自分の欲しい図に沿って設定値を変更していくことが必要になっていきます。