この記事を書いている 2024/4/18 時点ではこれらの機能はまだ beta です。今後の更新で不整合が起きる可能性があることはご留意ください。
この記事の内容は、すべて私個人の意見や見解に基づくものであり、所属組織との関わりは一切ありません。
背景
以前にこんな記事を書いていましたが
4月の更新で、置き換えられたり追加されたりした機能があるようなのでいくつか試してみました。
File Search
ツールとしての呼び出しが retrieval から file_search に変わりましたね。一通り Python SDK を使った操作も試しましたが、設定画面が結構よくできていて、
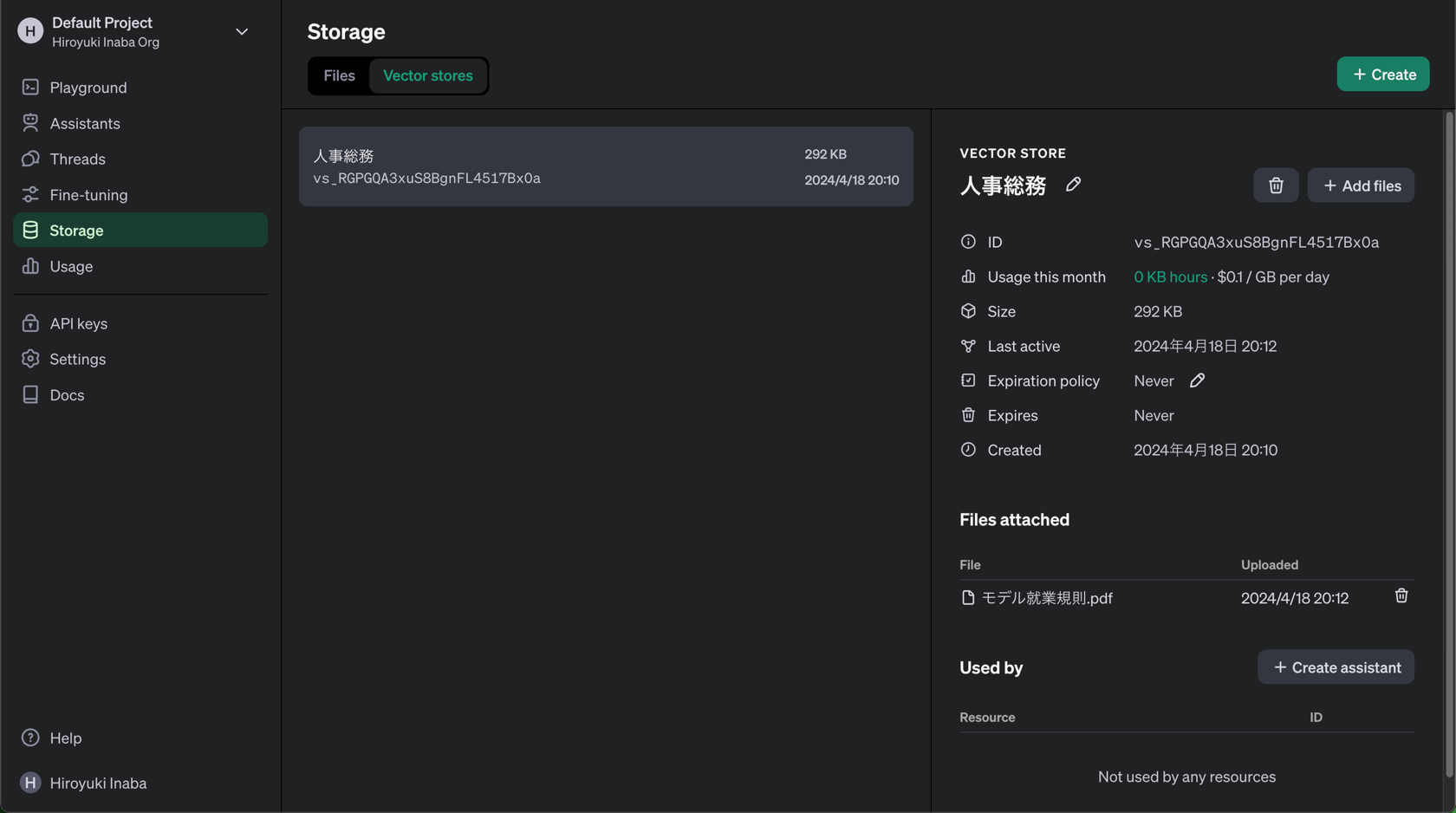
- Vector Store の作成
- ファイルのアップロード(からのチャンク作成やベクトル化)
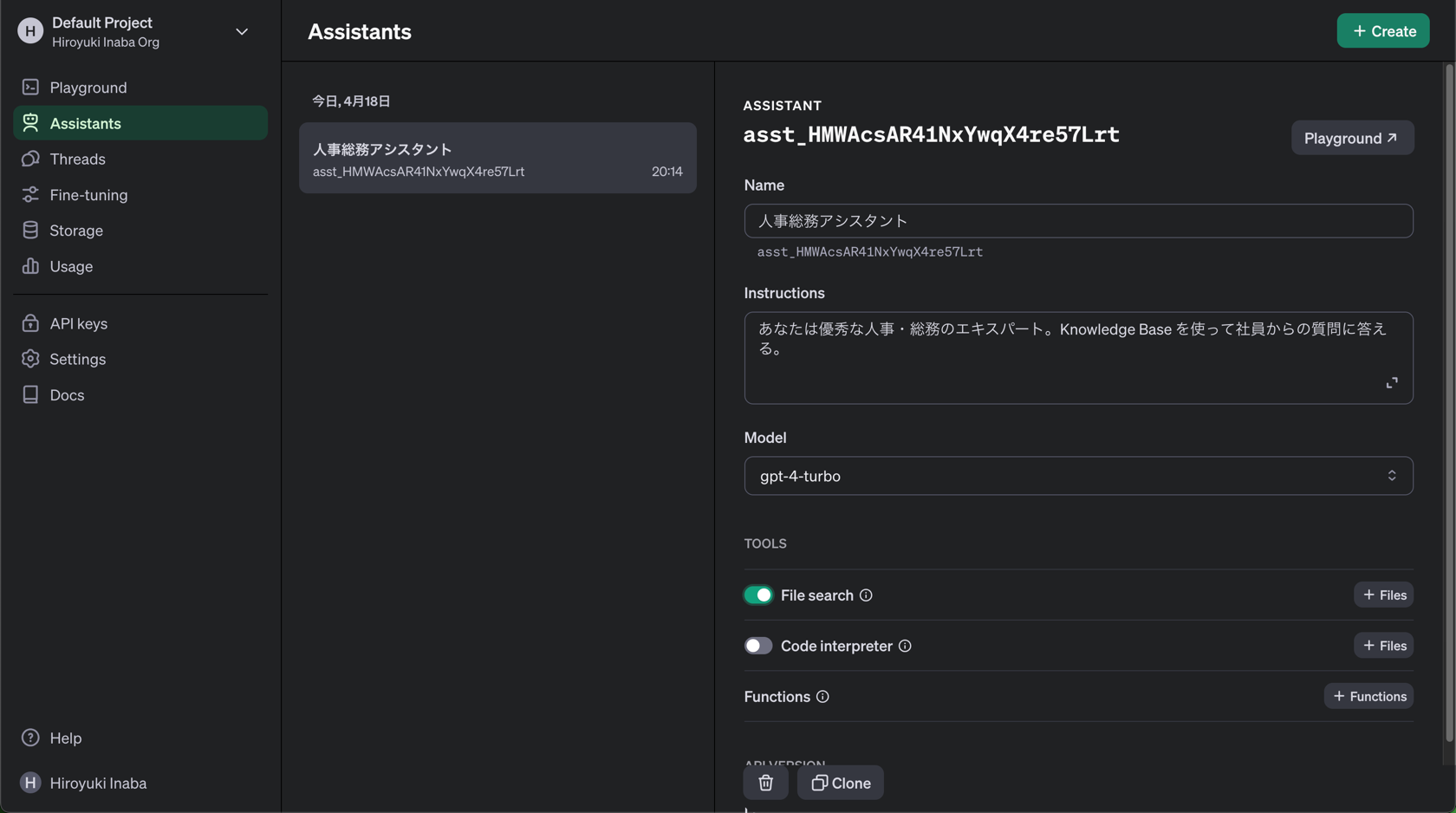
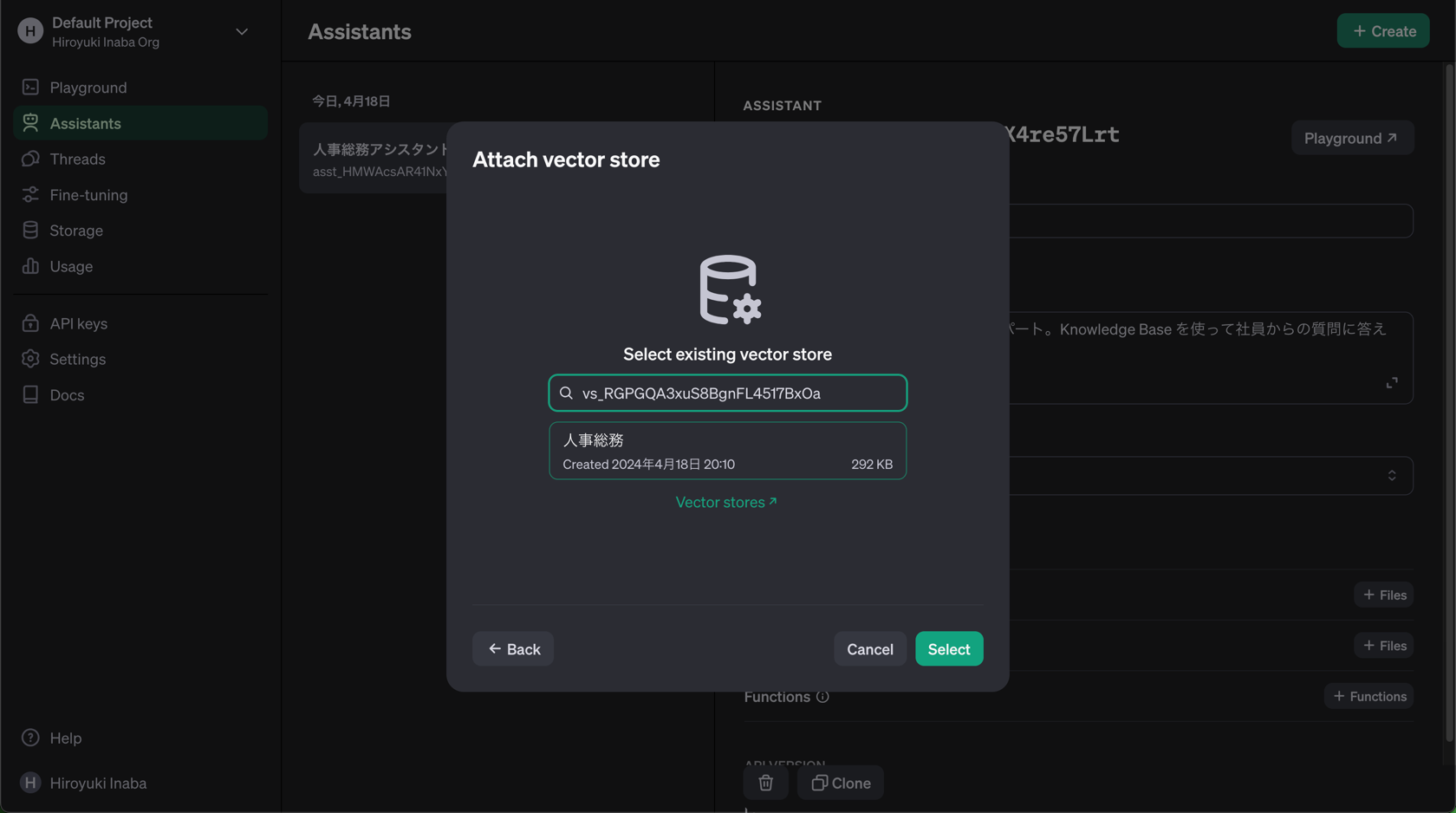
- それを使うアシスタントの作成
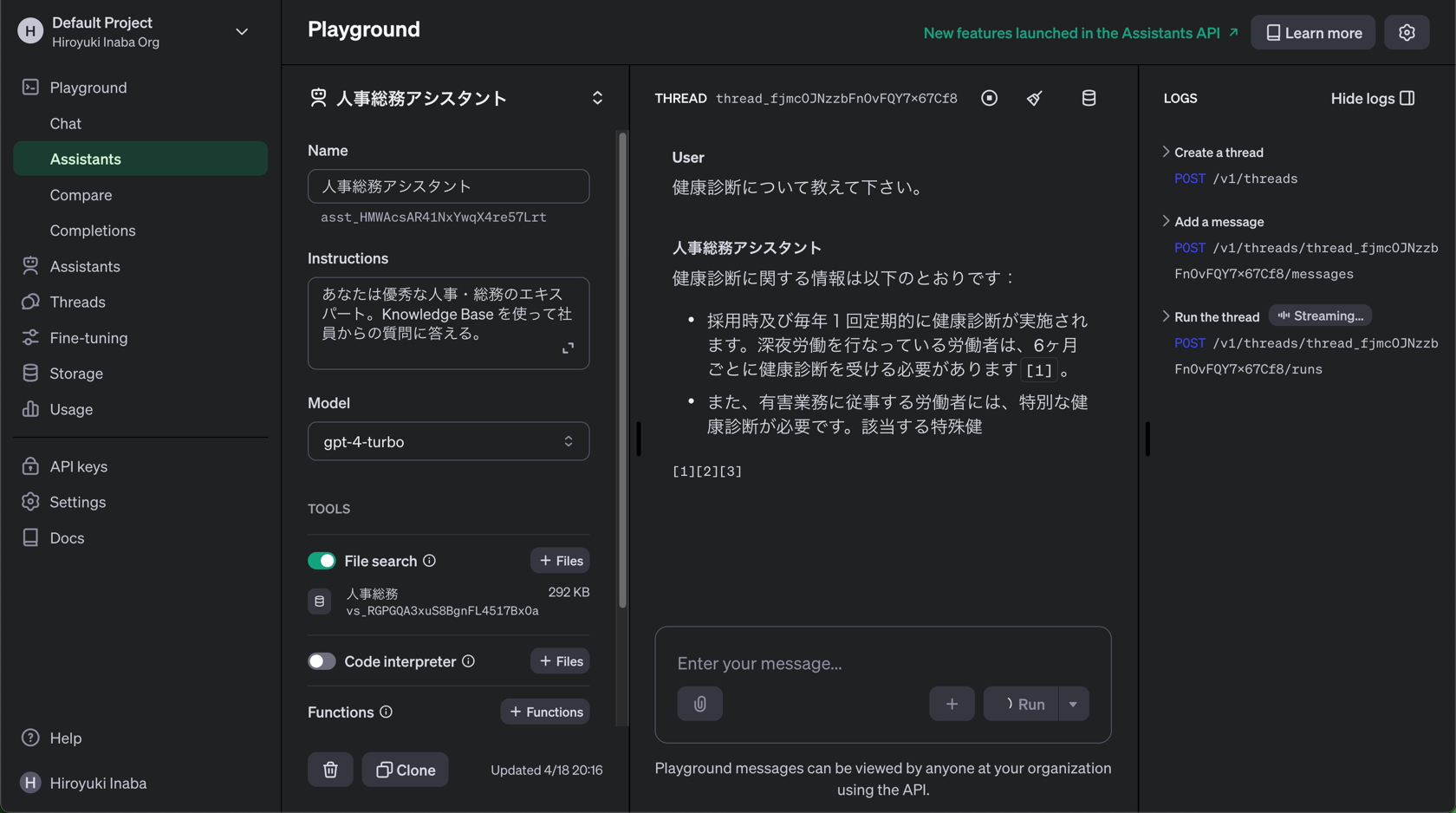
- Playgroud でアシスタントを試す
この一連の流れは特に迷うことなくスムーズに進みました。
参考画面
Vector Store の定義
Assistant の定義
Assistant への Vector Store の追加
Playground での試行
Streaming
Asistant の出力も Streaming に対応したとのことなので試してみます。こちらは最初 API リファレンスを見ていたのですが、Python SDK でヘルパーが作られていたりしたので、そちらを参考にしました。
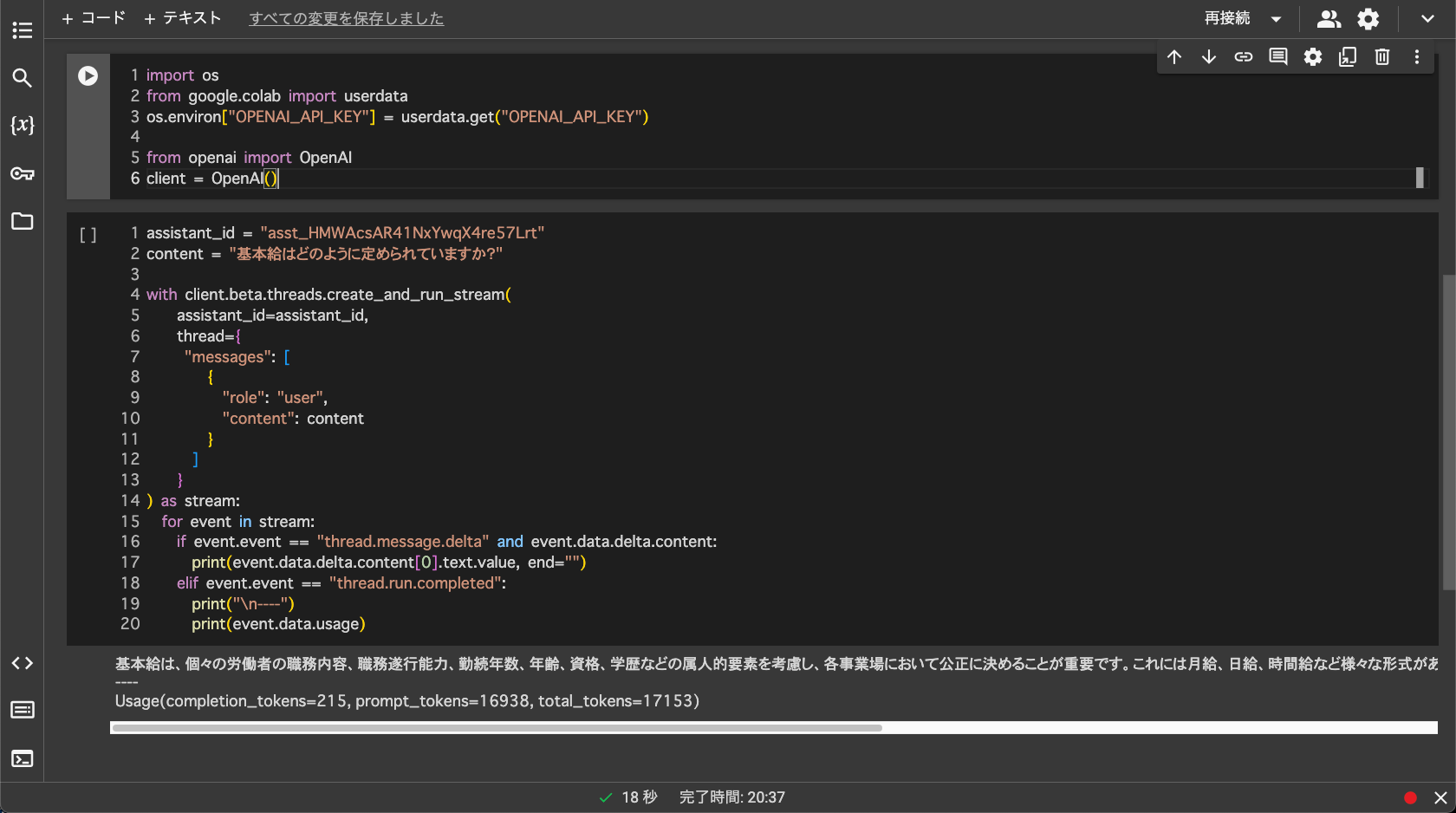
先ほどのアシスタントを呼び出して、結果をストリーミングで表示するようにしてみたコードです。Google Colaboratory で動かすことを想定しています。
!pip install openai
import os
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get("OPENAI_API_KEY")
from openai import OpenAI
client = OpenAI()
- API キーは Colaboratory のシークレット機能を使っています
assistant_id = "[Assistant Id に置き換え]"
content = "基本給はどのように定められていますか?"
with client.beta.threads.create_and_run_stream(
assistant_id=assistant_id,
thread={
"messages": [
{
"role": "user",
"content": content
}
]
}
) as stream:
for event in stream:
if event.event == "thread.message.delta" and event.data.delta.content:
print(event.data.delta.content[0].text.value, end="")
elif event.event == "thread.run.completed":
print("\n----")
print(event.data.usage)
- Stream モード(?) にするにはいくつかやり方があるようなのですが、なるべくシンプルなものにしてみました
- event はいくつかの型が返ってくるので、文字が返ってきた場合と、run が終了した時の情報だけ取り出すようにしています
- 提供されているサンプルだと、event.type で判別したりしているのですが、実際の返ってきている内容を見ると event.event だったので現物合わせしてます
Colaboratory での実行例
ちなみに Python SDK には、ポーリングの仕組みも組み込んでくれた呼び出しメソッドも用意されていました。(以前は自前実装が必要だったのでこれも便利に)
Polling Helpers
https://github.com/openai/openai-python/tree/main?tab=readme-ov-file#polling-helpers
その他
デフォルト設定だとこうなるということで、これは本当に単なる初期設定なのか、いろいろ試した結果これが良さそうとなったのかは少し気になるところです。
By default, the file_search tool uses the following settings:
- Chunk size: 800 tokens
- Chunk overlap: 400 tokens
- Embedding model: text-embedding-3-large at 256 dimensions
- Maximum number of chunks added to context: 20 (could be fewer)
まだ制約がいろいろあるようで、このあたりは今後の更新待ちです。
Known Limitations
We have a few known limitations we're working on adding support for in the coming months:
- Support for modifying chunking, embedding, and other retrieval configurations.
- Support for deterministic pre-search filtering using custom metadata.
- Support for parsing images within documents (including images of charts, graphs, tables etc.)
- Support for retrievals over structured file formats (like csv or jsonl).
- Better support for summarization — the tool today is optimized for search queries.
引用元:
https://platform.openai.com/docs/assistants/tools/file-search/how-it-works
(2024/4/18 時点)
あと、画像の結果を見て気づかれた方もいらっしゃるかもしれませんが、特に制御をかけていない状態だと結構な量をプロンプトにグランディングしてくれるようで、1回あたりのトークン数が 16,000 とか 17,000 近くになってます。
gpt-4-turbo の価格体系がこの時点では 100 万トークンで $10 なわけですが、60回くらい試したら到達してしまうと言うわけで。![]()