はじめに
Auto Scaling グループの各インスタンスのCPU使用率を一目で確認したい場合、CloudWatchのダッシュボードを作成して各インスタンスのCPU使用率を表示するウィジェットを追加することで実現可能です。
しかし、スケールアウト、スケールインに合わせてダッシュボードの内容を動的に変更する機能は本記事の投稿日の時点では存在しないため、スケールアウト、スケールインの度にダッシュボードの対象インスタンスを追加、削除する必要があります。これを手動で実施するのは手間なので、Lambda関数で自動化する方法を紹介します。
なお、今回紹介する方法はCPU使用率のみでなく、ディスクI/Oや、ネットワークI/O、メモリ使用率、ディスク使用率といったメトリクスを確認したい場合にも応用可能ですので参考にしていただければと思います1。
課題
下図のようなAuto Scaling グループを管理しているとします。
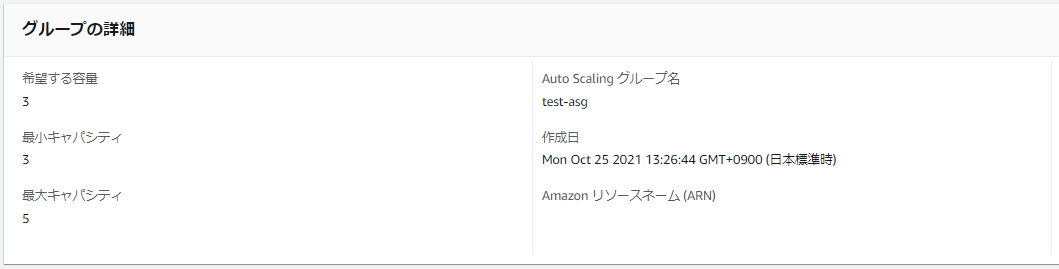
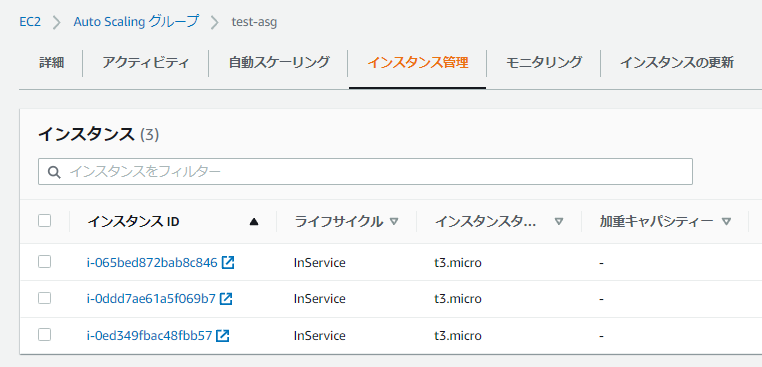
Auto Scaling グループには以下3台のEC2インスタンスが存在します。
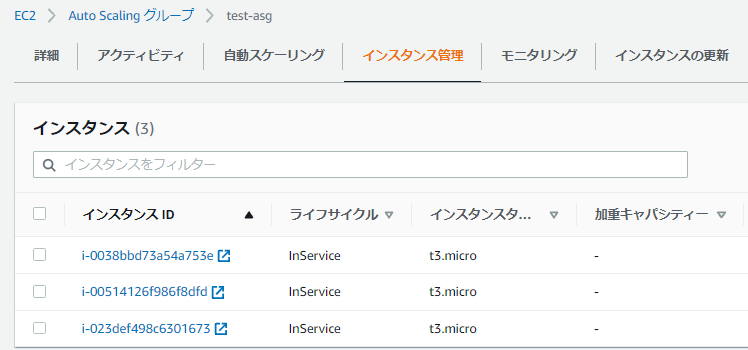
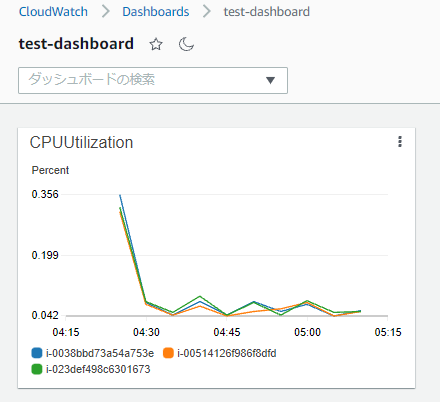
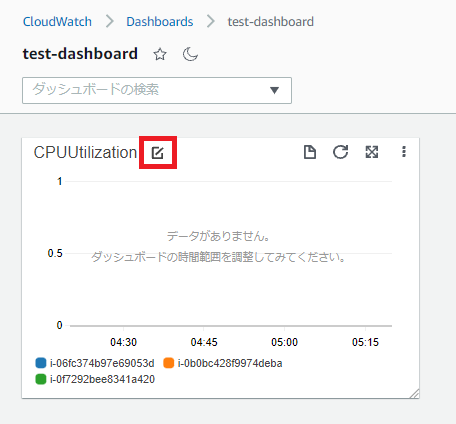
各EC2インスタンスのCPU使用率を確認したいのですが、Auto Scaling グループのCloudWatch メトリクスでは、以下のように全インスタンスの平均CPU使用率しか確認できません。
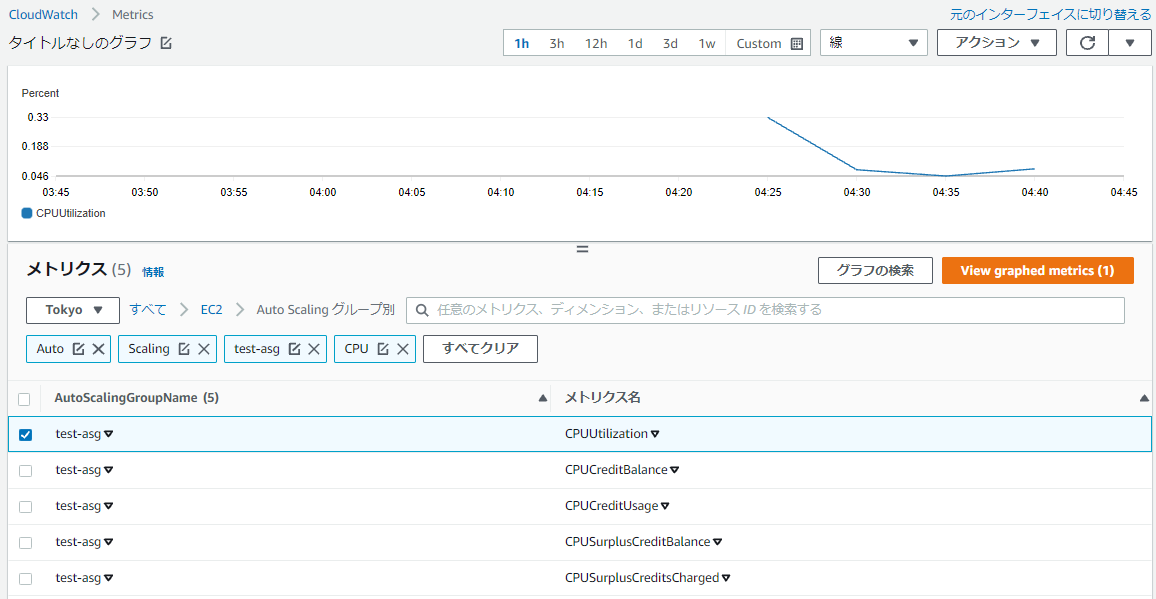
そのため、CloudWatchで各EC2インスタンスのCPU使用率を確認したい場合は以下のようにCloudWatchのダッシュボードで各インスタンスのCPUUtilizationを表示するウィジェットを作成する必要があります。
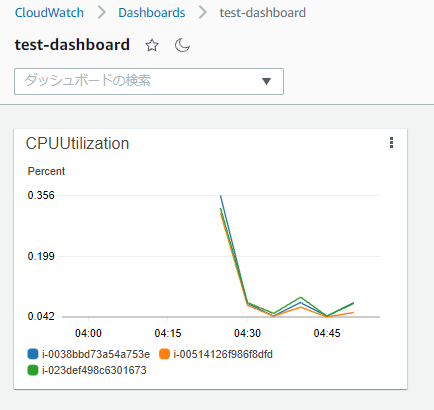
しかし、Auto Scaling グループにおいてスケールアウトが発生した場合、どうなるかを見てみましょう。
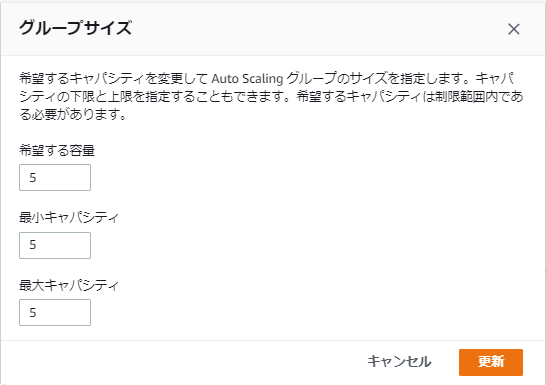
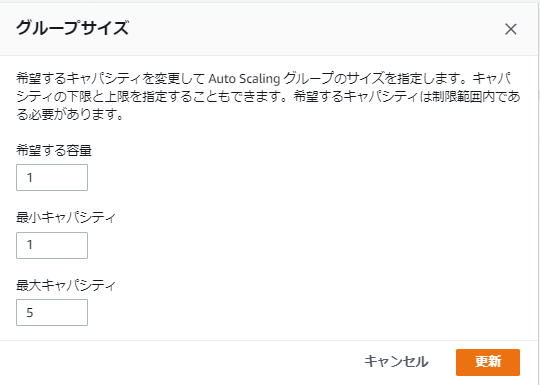
実験のためAuto Scaling グループの希望する容量および最小キャパシティを3から5に変更してみます。
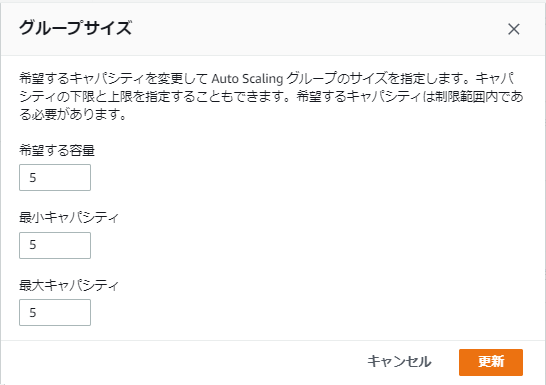
少し待つとAuto Scaling グループのインスタンスが2台増えて5台になりました。
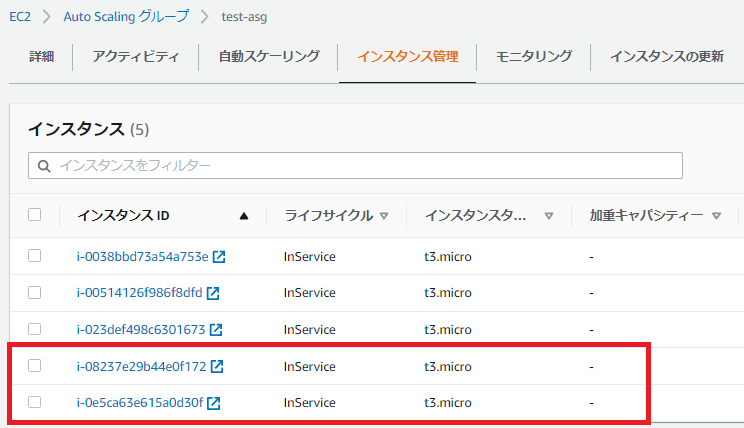
一方でダッシュボードのウィジェットに表示されるCPU使用率のグラフは、当たり前ですが、もともと存在した3台分のCPU使用率しか表示されていません。
スケールインの場合も同様で、Auto Scaling グループから削除されたインスタンスがダッシュボードから削除されない状態という問題が発生します。
対処方針
上記のダッシュボードはJSON形式で以下のように定義されています。
Auto Scaling グループのスケールアウト/スケールインをトリガーとしてLambda関数を起動し、LambdaでこのJSONのmetricsの部分にインスタンスIDを追加、または削除することでAuto Scaling グループへの追従を実現します。
{
"widgets": [
{
"type": "metric",
"x": 0,
"y": 0,
"width": 6,
"height": 6,
"properties": {
"view": "timeSeries",
"stacked": false,
"metrics": [
[ "AWS/EC2", "CPUUtilization", "InstanceId", "i-08be7c869e37389d9" ],
[ "...", "i-0a37908112466619f" ],
[ "...", "i-0e459f75258cde7db" ]
],
"region": "ap-northeast-1",
"title": "CPUUtilization"
}
}
]
}
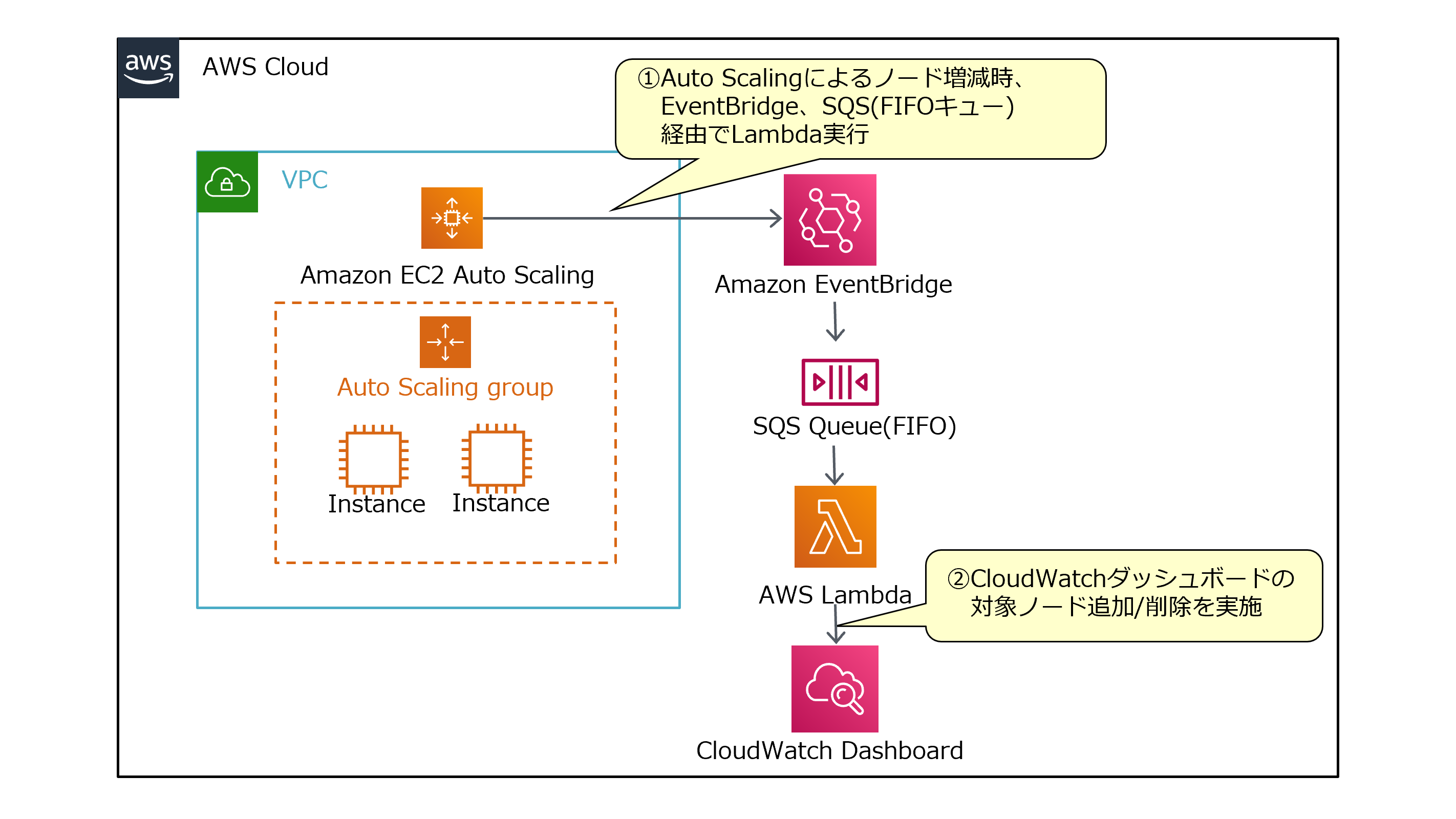
構成
Amazon EventBridgeのルールを作成し、イベントをSQSのFIFO キュー経由でLambdaを実行するよう設定します。
LambdaではAWS SDKを使用してCloudWatchのAPIを叩き、ダッシュボードへのインスタンスIDの追加、削除を実施します。
なお、以下でEventBridgeから直接Lambdaを実行せず、SQSのFIFO キューを経由しているのはLambdaの同時実行数を1に制限するためです。
Lambdaの同時実行数を1に制限する理由については後述します。
構築手順
前提
- AWS SAMを使用してリソースを作成するため、AWS SAM CLIがインストール済みであることを前提とします。
- 以下では対象のAuto Scaling グループ自体は既に存在し、ダッシュボードは未作成という状態を想定して手順を記載します。
ダッシュボードおよびウィジェットの作成
ダッシュボードの作成
マネジメントコンソールの CloudWatch > ダッシュボード で「ダッシュボードの作成」をクリックし、ダッシュボード名を入力して「ダッシュボードの作成」をクリックしてダッシュボードを作成します。
ウィジェットの作成
- マネジメントコンソールの CloudWatch > ダッシュボード で作成したダッシュボードをクリックします。
- 「ウィジェットの追加」をクリックします。
- 「ウィジェットの追加」で「線」をクリックします。
- 「これをダッシュボードに追加」で「メトリクス」をクリックします。
- 「メトリクスグラフの追加」で「EC2」をクリックします。
- 「インスタンス別メトリクス」をクリックします。
- 検索ボックスに「CPUUtilization」と入力してエンターキーを押下し、表示された検索結果のうち、対象Auto Scaling グループに含まれるインスタンスのチェックボックスをすべてチェックして「ウィジェットの作成」をクリックします。
- ダッシュボードの画面に戻るので、作成されたウィジェットの名前の横の編集ボタンをクリックして「ウィジェットの名前変更」画面でウィジェット名を入力して「適用」をクリックします。ウィジェット名を変更する必要が無い場合は、編集ボタンをクリック後、そのまま「適用」をクリックしてください。本記事の投稿日の時点で、本手順を実行しないとダッシュボードのソースで作成したウィジェットに
titleが作成されず、以下で作成するLambdaが正常に動作しません。
sam initの実行
任意のディレクトリで以下のコマンドを実行してサーバーレスアプリケーションのイニシャライズを行います。
$ sam init --package-type Zip --runtime python3.9 --name AutoScalingCloudWatchLambda --app-template hello-world
SAMテンプレートの作成
AutoScalingCloudWatchLambdaディレクトリに作成されたtemplate.yamlを以下の内容に変更します。
なお、SAMテンプレート中に登場するEventBridgeのイベントパターン(AutoScalingCloudWatchEventBridgeのEventPattern)、デッドレターキュー(AutoScalingCloudWatchFIFOSQSDLQ)、SQSのアクセスポリシー(AutoScalingCloudWatchFIFOSQSPolicy)については後述の補足にて詳細を解説していますので必要に応じてご参照ください。
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: >
AutoScalingCloudWatchLambda
SAM Template for AutoScalingCloudWatchLambda
Parameters:
AutoScalingGroupName:
Type: String
DashboardName:
Type: String
WidgetName:
Type: String
Resources:
AutoScalingCloudWatchFunction:
Type: AWS::Serverless::Function
Properties:
FunctionName: auto-scaling-cloudwatch-lambda
CodeUri: hello_world/
Handler: app.lambda_handler
Runtime: python3.9
Timeout: 30
Environment:
Variables:
DASHBOARD_NAME: !Ref DashboardName
WIDGET_NAME: !Ref WidgetName
Policies:
- Statement:
- Sid: CloudWatchDashboardPolicy
Effect: Allow
Action:
- cloudwatch:PutDashboard
- cloudwatch:GetDashboard
Resource: !Sub arn:${AWS::Partition}:cloudwatch::${AWS::AccountId}:dashboard/${DashboardName}
Events:
AutoScalingCloudWatchFIFOSQSEvent:
Type: SQS
Properties:
Queue:
Fn::GetAtt:
- AutoScalingCloudWatchFIFOSQS
- Arn
BatchSize: 1
AutoScalingCloudWatchFunctionLogGroup:
Type: AWS::Logs::LogGroup
Properties:
LogGroupName:
!Sub
- /aws/lambda/${FuncName}
- {FuncName: !Ref AutoScalingCloudWatchFunction}
RetentionInDays: 365
AutoScalingCloudWatchFIFOSQS:
Type: AWS::SQS::Queue
Properties:
FifoQueue: true
ContentBasedDeduplication: true
QueueName: auto-scaling-cloudwatch-sqs.fifo
VisibilityTimeout: 30
RedrivePolicy:
deadLetterTargetArn:
Fn::GetAtt:
- AutoScalingCloudWatchFIFOSQSDLQ
- Arn
maxReceiveCount: 1
AutoScalingCloudWatchFIFOSQSPolicy:
Type: AWS::SQS::QueuePolicy
Properties:
Queues:
- !Ref AutoScalingCloudWatchFIFOSQS
PolicyDocument:
Version: "2012-10-17"
Id: AutoScalingCloudWatchFIFOSQSPolicy
Statement:
- Sid: AllowSendMessage
Action:
- sqs:SendMessage
Effect: Allow
Resource:
Fn::GetAtt:
- AutoScalingCloudWatchFIFOSQS
- Arn
Principal:
AWS: "*"
Condition:
ArnEquals:
aws:SourceArn:
Fn::GetAtt:
- AutoScalingCloudWatchEventBridge
- Arn
AutoScalingCloudWatchFIFOSQSDLQ:
Type: AWS::SQS::Queue
Properties:
FifoQueue: true
QueueName: auto-scaling-cloudwatch-sqs-dlq.fifo
MessageRetentionPeriod: 60
AutoScalingCloudWatchEventBridge:
Type: AWS::Events::Rule
Properties:
Name: auto-scaling-cloudwatch-eventbridge-rule
EventPattern:
source: [ aws.autoscaling ]
detail-type:
- EC2 Instance Launch Successful
- EC2 Instance Terminate Successful
detail:
AutoScalingGroupName: [ !Ref AutoScalingGroupName ]
Targets:
- Arn:
Fn::GetAtt:
- AutoScalingCloudWatchFIFOSQS
- Arn
Id:
Fn::GetAtt:
- AutoScalingCloudWatchFIFOSQS
- QueueName
SqsParameters:
MessageGroupId: auto-scaling-cloudwatch-message-group
RetryPolicy:
MaximumRetryAttempts: 0
Lambda関数の作成
AutoScalingCloudWatchLambda/hello_world/app.pyを以下の内容に変更します。
import boto3
import json
from os import getenv
from logging import getLogger
cw = boto3.client('cloudwatch')
logger = getLogger(__name__)
dashboard_name = getenv('DASHBOARD_NAME')
widget_name = getenv('WIDGET_NAME')
def lambda_handler(event, context):
instance_id = ''
event_type = ''
try:
auto_scaling_event = json.loads(event['Records'][0]['body'])
instance_id = auto_scaling_event['detail']['EC2InstanceId']
event_type = auto_scaling_event['detail-type']
except Exception as e:
logger.error('Failed to get Information. [event] ' + json.dumps(event))
raise(e)
if event_type == 'EC2 Instance Launch Successful':
add_instance_to_dashboard(instance_id, logger)
elif event_type == 'EC2 Instance Terminate Successful':
delete_instance_from_dashboard(instance_id, logger)
return
def add_instance_to_dashboard(instance_id, logger):
try:
#ダッシュボード情報取得
dashboard_body_dic = get_dashboard(dashboard_name)
#対象インスタンスをダッシュボードのウィジェットに追加
for widget in dashboard_body_dic['widgets']:
widget_prop = widget['properties']
if widget_prop['title'] == widget_name:
#冪等性確保のため、当該インスタンスIDが無かったらappend
i = -1
for i, metric in enumerate(widget_prop['metrics']):
target_instance_id = metric[-1]
if(target_instance_id == instance_id):
break
if i == -1:
#metricsリストが空
widget_prop['metrics'].append([ "AWS/EC2", "CPUUtilization", "InstanceId", instance_id])
elif i == len(widget_prop['metrics']) - 1:
#該当インスタンスIDなし
widget_prop['metrics'].append(["...", instance_id])
put_dashboard(dashboard_name, json.dumps(dashboard_body_dic))
except Exception as e:
logger.error('Failed to add the instance to the dashboard. '
+ '[DashboardName] ' + dashboard_name
+ ' [InstanceId] ' + instance_id
+ ' [Exception] ' + str(e))
raise(e)
return
def delete_instance_from_dashboard(instance_id, logger):
try:
#ダッシュボード情報取得
dashboard_body_dic = get_dashboard(dashboard_name)
#対象インスタンスをダッシュボードのウィジェットから削除
for widget in dashboard_body_dic['widgets']:
widget_prop = widget['properties']
if widget_prop['title'] == widget_name:
i = -1
for i, metric in enumerate(widget_prop['metrics']):
target_instance_id = metric[-1]
if(target_instance_id == instance_id):
break
if i >= 0:
#対象インスタンスがmetricsリストに存在
if(i == 0 and len(widget_prop['metrics']) > 1):
#metricsリストの要素が2つ以上かつ対象インスタンスがmetricsリストの先頭
widget_prop['metrics'][i][-1] = widget_prop['metrics'][i+1][-1]
widget_prop['metrics'].pop(i+1)
else:
widget_prop['metrics'].pop(i)
put_dashboard(dashboard_name, json.dumps(dashboard_body_dic))
except Exception as e:
logger.error('Failed to delete the instance from the dashboard. '
+ '[DashboardName] ' + dashboard_name
+ ' [InstanceId] ' + instance_id
+ ' [Exception] ' + str(e))
raise(e)
return
def get_dashboard(DashboardName):
try:
response = cw.get_dashboard(
DashboardName = DashboardName
)
dashboard_body_json = response['DashboardBody']
return json.loads(dashboard_body_json)
except Exception as e:
msg = 'Failed to get the dashboard information. Detail: ' + str(e)
raise(e)
def put_dashboard(DashboardName, DashboardBody):
response = cw.put_dashboard(
DashboardName=DashboardName,
DashboardBody=DashboardBody
)
if len(response['DashboardValidationMessages']) != 0:
msg = 'Failed to update the dashboard.'
if('DataPath' in response['DashboardValidationMessages']):
msg += ' DataPath: ' + response['DashboardValidationMessages']['DataPath']
if('Message' in response['DashboardValidationMessages']):
msg += ' Message: ' + response['DashboardValidationMessages']['Message']
raise Exception(msg)
return
sam deployの実行
以下のようにsam deploy --guidedを実行してサーバレスアプリケーションのデプロイを実行します。
$ sam deploy --guided
Configuring SAM deploy
======================
Looking for config file [samconfig.toml] : Not found
Setting default arguments for 'sam deploy'
=========================================
Stack Name [sam-app]: auto-scaling-cw-lambda
AWS Region [ap-northeast-1]:
Parameter AutoScalingGroupName []: test-asg
Parameter DashboardName []: test-dashboard
Parameter WidgetName []: CPUUtilization
#Shows you resources changes to be deployed and require a 'Y' to initiate deploy
Confirm changes before deploy [y/N]:
#SAM needs permission to be able to create roles to connect to the resources in your template
Allow SAM CLI IAM role creation [Y/n]:
Save arguments to configuration file [Y/n]:
SAM configuration file [samconfig.toml]:
SAM configuration environment [default]:
なお、パラメータAutoScalingGroupName、DashboardName、WidgetNameはそれぞれ対象のAuto Scaling グループ名、対象のCloudWatch ダッシュボード名、対象のウィジェット名を指定してください。
動作確認
Auto Scaling グループには以下3台のEC2インスタンスが存在します。
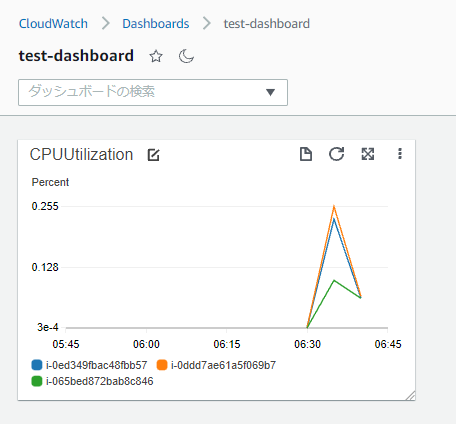
CloudWatchのダッシュボードには3台のインスタンスのCPU使用率が表示されています。
Auto Scaling グループの希望する容量および最小キャパシティを3から5に変更してみます。
少し待って、インスタンスが5台になってからダッシュボードを確認すると、追加されたインスタンスのCPU使用率も表示されています。
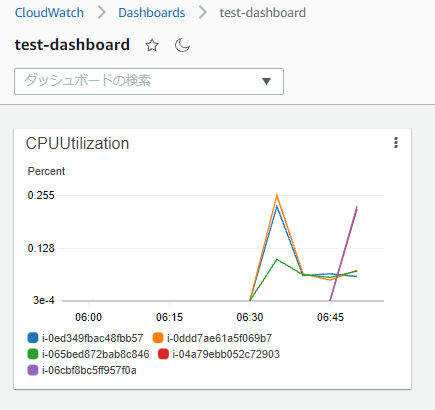
続けてAuto Scaling グループの希望する容量および最小キャパシティを5から1に変更してみます。
少し待って、インスタンスが1台になってからダッシュボードを確認すると、残った1台のインスタンスのCPU使用率のみ表示されています。
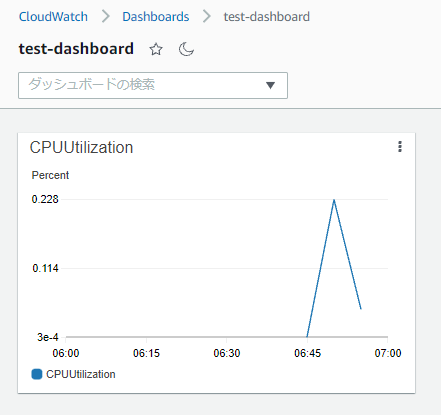
これで、CloudWatchのダッシュボードをAuto Scalingに追従して自動で設定するという目的を達成できました。
補足
EventBridgeのイベントパターンについて
以下を指定することで、対象オートスケーリンググループのスケールアウトによるインスタンス追加時およびスケールインによるインスタンス削除時にSQSにイベントを送信することができます。SAMテンプレートではこれをAWS::Events::RuleのEventPatternにYAML形式で指定しています。
{
"detail-type": ["EC2 Instance Launch Successful", "EC2 Instance Terminate Successful"],
"source": ["aws.autoscaling"],
"detail": {
"AutoScalingGroupName": ["<対象オートスケーリンググループ名>"]
}
}
SQSについて
SQSのFIFO キューを使用する理由
EventBridgeでは直接イベントをLambdaに送信することもできるので、なぜSQSのFIFO キューを経由するのか疑問に思う方がいるかもしれません。そのため、ここで理由を説明します。
今回作成するLambda関数では、以下の処理を行います。
-
get_dashboard()によるダッシュボードのJSON取得、JSON編集 -
put_dashboard()によるダッシュボード更新
上記を踏まえた上で、Auto Scalingによるスケールアウトで2台のインスタンスが追加され、Lambda関数が同時に実行されるケースを考えると時系列で以下の処理順となった場合にダッシュボードの状態が不正となります。以下では追加インスタンス1の延長で起動したLambdaをLambda①、追加インスタンス2の延長で起動したLambdaをLambda②とします。
- [Lambda①]
get_dashboard()によるダッシュボードのJSON取得、JSON編集 - [Lambda②]
get_dashboard()によるダッシュボードのJSON取得、JSON編集(※) - [Lambda①]
put_dashboard()によるダッシュボード更新 - [Lambda②]
put_dashboard()によるダッシュボード更新(※)
※ダッシュボードのJSONを取得した後に当該ダッシュボードが更新され、その後に古いJSONをもとに編集したJSONでダッシュボード更新するので追加インスタンス1の情報が消えてしまう。
スケールイン時も同様です。
そのため、Lambda関数の同時実行数を1に制限する必要があります。
Lambdaの同時実行数を1に制限するという要件は、SQS の FIFO キューを Lambda 関数のトリガーとすることで達成できます。2
デッドレターキュー
SQSによってトリガーされたLambda関数がエラーになった場合、
今回はエラー時にリトライせずにイベントを破棄したいので、AutoScalingCloudWatchFIFOSQSのRedrivePolicyでmaxReceiveCountを1にして、エラー発生時にメッセージを即デッドレターキューに移動するように設定し、移動先のデッドレターキューAutoScalingCloudWatchFIFOSQSDLQのMessageRetentionPeriodを最小値の60とすることで、最短で破棄する挙動としています。実際に使用する場合は保持期間を長くする、デッドレターキューにメッセージが移動されたら通知するよう設定する等、要件に合わせて修正してください。
アクセスポリシー
EventBridgeからSQSのキューにイベントを送信するためには、対象キューのアクセスポリシーで以下のようにEventBridgeのルールに対してsqs:SendMessageを許可する必要があります。SQSキューのアクセスポリシーはSAMテンプレートではAWS::SQS::QueuePolicyというリソースで定義します。
{
"Version": "2012-10-17",
"Id": "AutoScalingCloudWatchFIFOSQSPolicy",
"Statement": [
{
"Sid": "AllowSendMessage",
"Effect": "Allow",
"Principal": {
"AWS": "*"
},
"Action": "sqs:SendMessage",
"Resource": "<SQSキューのARN>",
"Condition": {
"ArnEquals": {
"aws:SourceArn": "<EventBridgeのルールのARN>"
}
}
}
]
}
まとめ
Lambda関数を使用してCloudWatchのダッシュボードをAuto Scalingに追従して自動で設定する方法を紹介しました。
Auto Scaling グループの各インスタンスのCPU使用率やその他のメトリクスをダッシュボードで確認したいというケースがありましたらご活用いただければ幸いです。
-
EC2インスタンスのメトリクスについて、CPU使用率、ディスクI/O、ネットワークI/Oは特別な設定なしにCloudWatchで取得可能ですが、メモリ使用率、ディスク使用率を取得するためにはCloudWatch エージェントのインストールが必要です。詳細はCloudWatch エージェントの公式ドキュメントをご参照ください。 ↩
-
当初はSAMテンプレートで
AWS::Serverless::FunctionのReservedConcurrentExecutionsを1にすることで同時実行数を1に制限できるのでは無いかと思ったのですが、ReservedConcurrentExecutionsはあくまでも同時実行数を予約するための設定(User Guide参照)であり、指定した実行枠が確保されるというものです。ReservedConcurrentExecutionsが1のときに同時実行数が1となることが保証される(2以上とならない)というドキュメント記載は見当たらず、AWSサポートに問い合わせてみたところ、ReservedConcurrentExecutionsを1にしても同時実行数が1であることを保証するようなドキュメントは無く、代わりにSQSのFIFOキューを使用し、単一のメッセージグループIDを使用することで条件を満たすことができるという回答をいただきました(詳細はAWS Compute Blogの該当記事参照)。 ↩