こんにちは。今回は友人からの希望を受けて、 SysOps アドミニストレーターアソシエイトのサンプル問題解説です。
AWS 環境の管理や運用を担当するシステムアドミニストレーターな方向けの認定試験です。
AWS認定とは
AWS 認定は、クラウドの専門知識を検証し、専門家が需要の高いスキルを強調し、組織が AWS を使用してクラウドイニシアチブにおける効果的で革新的なチームを構築するのに役立ちます。個人やチームが独自の目標を達成できるように、役割と専門分野ごとに設計したさまざまな認定試験から選択します。
AWS 認定は領域やレベルごとに分けられ、本校執筆時点(2020/10)では12の認定資格が存在しています。
- レベル
- 基礎
- アソシエイト(中級ととらえてください)
- プロフェッショナル(上級ととらえてください)
- 専門知識(対象分野に特化した高度な認定)
- 領域
- 全般
- ソリューション
- 開発
- 運用
- DBや機械学習といった専門分野
表にまとめると以下の通りです。
| # | レベル | 認定名 |
|---|---|---|
| 1 | 基礎 | クラウドプラクティショナー |
| 2 | アソシエイト | ソリューションアーキテクトアソシエイト |
| 3 | アソシエイト | デベロッパー アソシエイト |
| 4 | アソシエイト | SysOps アドミニストレーター アソシエイト |
| 5 | プロフェッショナル | ソシューションアーキテクト プロフェッショナル |
| 6 | プロフェッショナル | DevOps エンジニア プロフェッショナル |
| 7 | 専門知識 | 高度なネットワーク |
| 8 | 専門知識 | Alexaスキルビルダー |
| 9 | 専門知識 | セキュリティ |
| 10 | 専門知識 | 機械学習 |
| 11 | 専門知識 | データ分析 |
| 12 | 専門知識 | データベース |
AWS認定 SysOps アドミニストレーターアソシエイト
試験の概要や出題割合などは、以下の試験ガイドをご確認ください。
https://d1.awsstatic.com/ja_JP/training-and-certification/docs-sysops-associate/AWS-Certified-SysOps-Administrator-Associate_Exam-Guide.pdf
サンプル問題を解いてみよう
それでは、サンプル問題を確認していきましょう。
※以降、Markdown記載に合わせて、サンプル問題のABCDを1234と置き換えています。
第1問
問題文
企業は単一のサーバーから Application Load Balancer (ALB) の背後にある複数の Amazon EC2 インスタンスにレガシーのウェブアプリケーションを移行しています。移行後、ユーザーがセッションの頻繁な切断、また再ログインを求められることを報告しています。
ユーザーから報告された問題を解決するために次のうちどの措置を講じる必要がありますか?
- ALB がマルチ AZ 構成になっていないかの確認
- ALB を基として Amazon CloudFront ディストリビューションの設定
- ALB の前に Network Load Balancer をデプロイする
- EC2 インスタンスのターゲットグループに対してスティッキーセッションの有効化。
回答
4
解説
ALB の利用やレガシーのウェブアプリケーションの移行、頻繁な切断や再ログインが求められるとの記載から考えていきます。
レガシーのウェブアプリケーションではセッション情報をサーバー内部で持つことが一般的でした。
通常、ALB は背後にいる Amazon EC2 インスタンスへバランスよくリクエストを振り分けます。インスタンスが2台いれば、A,B,A,B...のように。ログインを行うと前述の「A」のインスタンスでログインしセッション情報は「A」のインスタンス内部に格納されることになります。その後のリクエストで「B」のインスタンスへ振り分けられてしまうと、セッション情報が存在しない状態になります。そのため、問題文にあるような事象が発生してしまいます。
この事象を回避するには、セッション情報を Amazon DynamoDB や Amazon ElastiCache などに格納し、リクエストがあるたびにそれらサービスへセッション情報を確認するつくりにすることです。
ただし、レガシーなアプリケーションを移行してきた場合は、極力、アプリケーションコードに手を入れたくない、いれられないことも考えられます。
その場合は、選択肢の「4」にあるスティッキーセッションを有効化します。
スティッキーセッションを使うことで、セッション情報が生成されたインスタンスに対してリクエストが転送されるので、「A」のインスタンスでログインを行った場合に継続的に「A」への通信が行われることになります。よって、正答であると考えます。
- マルチ AZ 構成になっていることと ALB を使っていることで、セッションの切断や再ログインが求められることは要因の一つではありますが、「確認する」ことが解決のための手段ではないので回答としては不適当です。
- Amazon CloudFront ディストリビューションの設定をしても、セッション周りの動きはかわらないので、回答としては不適当です。
- ALB の前に Network Load Balancer (NLB)をデプロイしても、セッション周りの動きはかわらないので、回答としては不適当です。
- 前述の通り、スティッキーセッションを有効化する必要があるため、適当であると考えます。
第2問
問題文
運用チームは、毎週 AWS Personal Health ダッシュボードで、次の AWS ハードウェアメンテナンスイベントをチェックしています。最近、一人のスタッフが休暇中であったためチームはメンテナンスの予定を見落とし、その結果サービスが停止しました。ームはダッシュボードの確認を一人のスタッフに頼るのではなく、全員が次
のメンテナンスを周知できるような簡単な方法を求めています。
これに対処する方法は次のうちどれですか?
- Personal Health ダッシュボードを監視する ウェブスクレーパーを構築する。新しいイベントが検出されたときに、チームで監視する Amazon SNS トピックに通知を送信する。
- AWS Health サービスに基づいて Amazon CloudWatch Events イベントを作成し、チームで監視する Amazon SNS トピックに通知を送信する。
- Personal Health ダッシュボードでメンテナンスの予定を表示するようチームにリマインドするために、チームで監視する Amazon SNS トピックに通知を送信し、Amazon CloudWatch Events を作成する。
- すべての EC2 インスタンスに対し継続的に ネットワーク接続確認を実行して正常性を確認するために AWS Lambda 関数を作成する。これに失敗した場合は、チームにアラートを送信する。
回答
2
解説
所謂、属人化が原因となった事象ですね。これを回避するには属人化を回避し、全員が即座に確認や対応といった初動に移れるように通知する仕組みが必要です。そして、できるだけ、機械化や自動化を取り入れて確認作業の漏れや抜けも防げるようにするとよいでしょう。
AWS Personal Health ダッシュボードの情報は、 AWS Health サービスで管理されています。イベントの発生や予告がされたことを契機に、Amazon CloudWatch Events のイベントが実行できます。そこから Amazon SQS や Amazon SNS などを通じて処理が行えます。
本件でいえば、次のメンテナンスの周知なので、運用担当者のメーリングリストや、MS Teams, Slackなどへ通知ができればよさそうなので、 Amazon SNS を使うのがよいでしょう。
- 前述の通り仕組みが用意されているのに、わざわざ ウェブスクレーパーを構築するのは、工数がもったいないです。画面構成や文字列が変わったら使えなくなってしまい、延々とメンテナンスを続けないとなりません。そのため、この回答は不適当であると考えます。
- 前述の通り、この選択肢が適当であると考えます。
- 良い線までいっているように見えますが、ダッシュボードを見に行く(表示する)をリマインドするために、Amazon SNS で通知するとあるので不適当であると考えます。
- 「ネットワーク接続確認」のみであればこの手法も悪くはなさそうですが、発生しうるインシデントはネットワーク問題だけではありません。また、要件としては、 AWS ハードウェアメンテナンスイベントが対象と記載があるため、要件を満たしていないため不適当です。
第3問
問題文
VPC で稼働されているアプリケーションは異なるアカウントによって所有され、かつ別のリージョンの VPC で稼働されているインスタンスにアクセスする必要があります。コンプライアンスの観点から、トラフィックはパブリックインターネットを通過してはなりません。
これらの要件を満たすために、管理者はネットワークルーティングをどのように構成すべきでしょうか?
- 各アカウント内に他のアカウントの仮想プライベートゲートウェイを示すルートを格納するカスタムルーティングテーブルを作成する。
- 各アカウント内にそれぞれの VPC のパブリックサブネットに NAT ゲートウェイを設定する。次に、NAT ゲートウェイからのパブリック IP アドレスを使用し、2 つの VPC 間のルーティングを有効にする。
- 1 つのアカウントで VPCs の間に VPN のサイト間の 接続を構成する。各アカウント内にリモート VPC のCIDR ブロックを示す VPC ルートテーブルにルートを追加する。
- 1 つのアカウントから VPC ピアリング要求を作成する。他のアカウントの管理者が要求を受け入れた後、ピアリングされた VPC の CIDR ブロックを示す各 VPC のルートテーブルにルートを追加する。
回答
4
解説
アプリケーションやインスタンスは VPC で稼働している、トラフィックはパブリックインターネットを通過してはならないという要件から、各 VPC を接続して トラフィックを AWS ネットワーク外に出さない VPC ピアリング接続や Transit Gateway で解決できそうです。
- 仮想プライベートゲートウェイ(VGW)はオンプレミスとの専用線接続(Direct Connect)や VPN との接続に使うものです。また、Direct Connect Gateway を利用していたとしても互いの VGW を介しての通信はできません。よって、不適当であると考えます。
- NAT ゲートウェイではパブリックインターネットに出てしまうため、不適当です。
- VPN とはいえ、パブリックインターネットを通過するので不適当です。
- VPC ピアリング接続の設定とルートテーブルの設定をしているため、この選択肢が適当であると考えます。
第4問
問題文
Amazon EC2 インスタンスで稼働されているアプリケーションは、Amazon DynamoDB テーブルに格納されているデータにアクセスする必要があります。
最も安全な方法でアプリケーションにテーブルへのアクセスを許可するソリューションは、次のうちどれですか?
- アプリケーションの IAM グループを作成し、必要な権限を持つアクセス許可ポリシーを添付する。EC2 インスタンスを IAM グループに追加する。
- Amazon EC2 に必要なアクセス許可を付与する DynamoDB テーブルの IAM リソースポリシーを作成する。
- DynamoDB テーブルへのアクセスに必要な権限を持つ IAM ロールを作成する。ロールを EC2 インスタンスにアサインする。
- アプリケーション用の IAM ユーザーを作成し、必要な権限を持つアクセス許可ポリシーを添付する。アクセスキーを生成し、そのキーをアプリケーションコードに埋め込む。
回答
3
解説
Amazon DynamoDB へ安全にアクセスするのが要件です。選択肢も併せて確認すると、IAM の設定の話のようです。
Amazon EC2 に設定ができる IAM の機能がわかり、アプリケーションから AWS サービスを利用する際のベストプラクティス、つまり安全なアクセス方法を知っていれば答えが導かれます。
- IAM グループに追加できるのは、IAM ユーザーのみです。Amazon EC2 インスタンスを追加することはできないので、不適当です。
- IAM リソースポリシーは Amazon EC2 でサポートされていません。そのため不適当です。
- IAM ロールを利用することで、Security Token Service(STS) の力により、一時的に利用可能なアクセスキーとシークレットアクセスキー、トークンが払い出されます。アプリケーションはこれらの情報を使うことで安全に AWS サービスへアクセスが行えます。よって、適当であると考えます。
- アクセスキー、シークレットアクセスキーをアプリケーションコードに埋め込むのはバッドノウハウです。何かのはずみでキーが漏れたり、キーを埋め込んだアプリケーションコードを Github などで公開してしまうと、権限を奪取されかねません。よって、安全に接続するという要件が満たせないため、不適当です。
第5問
問題文
サードパーティのサービスは毎晩 Amazon S3 にオブジェクトがアップロードしています。場合によってはサービスにより、誤ってフォーマットされたバージョンのオブジェクトがアップロードされることもあります。このような場合、SysOps Administrator は旧バージョンのオブジェクトを回復する必要があります。
リモートサービスからオブジェクトを取得せずにオブジェクトを回復する、最も効率的な方法は次のうちどれですか?
- 毎晩行われるオブジェクトのアップロードの前に S3 バケットをバックアップするための AWS Lambda 関数をトリガーする、Amazon CloudWatch Events スケジュールイベントを設定する。その際不良オブジェクトが検出された場合は、バックアップバージョンを復元する。
- オブジェクト作成時に、オブジェクトを Amazon Elasticsearch Service (Amazon ES) クラスターにコピーする S3 イベントを作成する。その際不良オブジェクトが検出された場合は、Amazon ES から以前のバージョンを取得する。
- 別のアカウントが所有する S3 バケットにオブジェクトをコピーする AWS Lambda 関数を作成します。S3 で新しいオブジェクトが作成されたときに関数をトリガーします。不良オブジェクトが検出された場合は、他のアカウントから以前のバージョンを取得します。
- S3 バケットのバージョン管理を有効にする。その際不良オブジェクトが検出された場合は、CLI または AWS 管理コンソールを使用して以前のバージョンにアクセスする。
回答
4
解説
Amazon S3 にアップロードされているオブジェクトをサードパーティのサービス(リモートのサービス)から取得せずに復旧するのが要件です。
Amazon S3 にはこういった際に使える機能として、バージョニングとレプリケーションが用意されています。
- バージョニング
- 格納したオブジェクトに対して更新(上書き)や削除を行うと、一意のバージョンIDを付与して、同じオブジェクト名だが、異なるバージョンIDをもつオブジェクトをその都度保持する機能
- 誤った削除や上書きをした際に、以前のバージョンを指定して復元が可能
- レプリケーション
- 異なるバケット間でオブジェクトを自動的に非同期コピーする機能
このことから、本問題の要件から、バージョニング機能を利用することが回答として正しそうです。
- Amazon S3 にはオブジェクトを格納したり削除したりといったアクションが実行された際、それをトリガに AWS Lambda の関数を実行する機能があります。また、前述の通りバージョニング機能があるため、わざわざ Amazon Cloudwatch Events のスケジュールイベントをトリガにバックアップするのは非効率であるため、不適当です。
- 執筆時点(2020年10月)では、 S3 イベントの送信先に指定できるのは、 Amazon SQS、Amazon SNS、AWS Lambda であるため不適当です。
- 別のバージョンへコピーする AWS Lambda 関数を作ったり、不良発生時のリカバリの際、専用の関数を使うのか、手作業でいったんダウンロードして再アップロードするのかはわかりませんが、効率が良い作業とは言えないため、不適当です。
- 前述の通り、バージョニング機能有効化し、選択肢にある通り、 AWS CLI や AWS 管理コンソール(マネージメントコンソール)から、戻したいバージョンを指定することで簡単に復元することができます。よって、適当であると考えます。
第6問
問題文
AWS 共有責任モデルによると、次の Amazon EC2 アクティビティのうち、AWS が責任を負うのはどれですか? (2つ選択)
- ネットワーク ACL の設定
- ネットワークインフラストラクチャのメンテナンス
- メモリ使用率の監視
- オペレーティングシステムへのパッチ適用
- ハイパーバイザーへのパッチ適用
回答
2、5
解説
責任共有モデルとは AWS と利用者で役割や責任の範囲を分けて対応し、全体的なセキュリティを確保しようという考え方です。ざっくりと役割や範囲をまとめると以下のような図になります。
これを踏まえて、正答だと考えられるものを選びます。
- ネットワーク ACL の設定は、上記参考リンクの図でいうところの「ネットワークトラフィック保護」に該当します。よって AWS の責任範囲ではないため不適当です。
- ネットワークインフラストラクチャは、上記参考リンクの図でいうところの「ネットワーキング」や「ハードウェア/AWSグローバルインフラストラクチャー」などに該当します。よって、AWSの責任範囲であるため、正解であると考えます。
- メモリ使用率の監視は、一般的には上記参考リンクの図でいうところの「オペレーティングシステム」に該当します。よって AWS の責任範囲ではないため不適当です。
- オペレーティングシステムへのパッチ適用は、一般的には上記参考リンクの図でいうところの「オペレーティングシステム」に該当します。よって AWS の責任範囲ではないため不適当です。
- ハイパーバイザーへのパッチ適用は、上記参考リンクの図でいうところの「ハードウェア/AWSグローバルインフラストラクチャー」に該当します。よって、AWSの責任範囲であるため、正解であると考えます。
第7問
問題文
セキュリティおよびコンプライアンスチームは、すべての Amazon EC2 ワークロードで承認済みの Amazon Machine Images (AMI) を使用する必要があります。SysOps Administrator は未承認の AMI から起動された EC2 インスタンスを検知するプロセスを実装しなければなりません。
これらの要件を満たすソリューションは次のうちどれですか?
- AWS Systems Manager インベントリを使用してカスタムレポートを作成し、未承認の AMI を識別する。
- 各 EC2 インスタンスで Amazon Inspector を実行し、未承認の AMI を使用している場合はインスタンスにフラグを立てる。
- AWS Config ルールを使用し、未承認の AMI を識別する。
- AWS Trusted Advisor を使用し、未承認の AMI を使用する EC2 ワークロードを識別する。
回答
3
解説
承認された AMI のみを使うように強制するには、 AWS Config の「approved-amis-by-id」や「approved-amis-by-tag」など AWS Config Managed Rule を利用することで効率よく検知することができます。検知後は、例えば、Amazon SNS を経由して自動的にメール通知などを行うといった運用が可能です。
これを踏まえて、正答だと考えられるものを選びます。
- AWS Systems Manager インベントリは、未承認の AMI を検知するサービスではないため、不適当です。さ
- Amazon Inspector はネットワークアクセシビリティや Amazon EC2 インスタンス上で動作するアプリケーションのセキュリティ状態をテストするサービスです。未承認の AMI を利用していることを検知するサービスではないため、不適当です。
- 上述の通り、 AWS Config のルールを使用し、設定することで、自動的に未承認の AMI を検知、識別することが可能です。よって正解と考えます。
- AWS Trusted Advisor はパフォーマンスやセキュリティ、コストといった観点でアドバイスをしてくれるサービスです。未承認の AMI を利用していることを検知するサービスではないため、不適当です。
第8問
問題文
SysOps Administrator は Application Load Balancer で大量の不正な HTTP リクエストを監視しています。そのリクエストはさまざまな IP アドレスから発信されています。それによりサーバーの負荷とコストが増加しています。
SysOps Administrator はこの不正なリクエストをブロックするために何を行う必要がありますか?
- 不正なリクエストをブロックするために、Amazon EC2 インスタンスに Amazon Inspector をインストールする。
- Amazon GuardDuty を使用し、ウェブサーバーをボットやスクレーパーから保護する。
- AWS Lambda を使用し、ウェブサーバーのログの分析及びボットトラフィックの検出を行い、セキュリティグループの IP アドレスをブロックする。
- AWS WAF レートベースのブラックリストを使用し、しきい値を超えたときにトラフィックをブロックする。
回答
4
解説
Application Load Balancer(ALB) を使っており、大量に発生している不正な HTTP リクエストをブロックするのが要件です。
これを達成するには、 AWS WAF を使うのが最適です。
AWS WAF では IP アドレスベースでアクセスを遮断したり、アクセス元の国や地域を基にした遮断をしたり、選択肢にある通りレートベースでの遮断といったことが可能です。そして、CloudFront や ALB と連携して、不正なリクエストをブロックすることができます。
- Amazon Inspector は、インターネットからリモートログインできるようになっていないか、セキュリティ脆弱性が無いかなどを自動的に判定するサービスであるため、回答としては不適当です。
- Amazon GuardDuty は AWS アカウント上のAWS CloudTrail イベントログ、Amazon VPC フローログ、および DNS ログなどの複数のイベントを解析し、脅威のあるイベントを検知するサービスのため、不適当です。
- リクエストは様々な IP アドレスから発信されているとあることから、すぐにセキュリティグループの上限値に抵触してしまうのが予想されること、 大量のアクセスとあることから AWS Lambda が大量に実行され、スロットリングになったり、処理時間が頭打ちになったりなど、結果的にコスト増大を引き起こします。よって、不適当です。
- 前述の通り、 AWS WAF のレートベースのブラックリストを使うことで、大量に発生している不正なリクエストを遮断することができるので、正解と考えます。
第9問
問題文
SysOps Administrator は AWS 上で運用されているウェブアプリケーションのセキュリティグループポリシーを設定しています。Elastic Load Balancer は Amazon EC2 インスタンスのフリートに接続します。各 Amazon EC2 インスタンスはポート 1521 を通じて Amazon RDS データベースに接続します。セキュリティグループの名称はそれぞれ elbSG、ec2SG、 rdsSG です。
これらのセキュリティグループをどのように設定すべきでしょうか?
- elbSG: 0.0.0.0/0 からポート 80 および 443 を許可する。
ec2SG: elbSG からポート 443 を許可する。
rdsSG: ec2SG からポート 1521 を許可する。 - elbSG: 0.0.0.0/0 からポート 80 および 443 を許可する。
ec2SG: elbSG と rdsSG からポート 80 および 443 を許可する。
rdsSG: ec2SG からポート 1521 を許可する。 - elbSG: ec2SG からポート 80 および 443 を許可する。
ec2SG: elbSG と rdsSG からポート 80 および 443 を許可する。
rdsSG: ec2SG からポート 1521 を許可する。 - elbSG: ec2SG からポート 80 および 443 を許可する。
ec2SG: elbSG からポート 443 を許可する。
rdsSG: elbSG からポート 1521 を許可する。
回答
1
解説
まず、問題文から類推される、使用するポートをまとめます。
- Elastic Load Balancer の 一般的な待ち受けポート: 80 や 443
- EC2(ウェブアプリケーションサーバ)の一般的な待ち受けポート: 80 や 443
- RDSの待ち受けポート(問題文中から): 1521
次に問題文から起こした想定される構成図は以下の通りです。
構成図内の (A) ~ (E) は各セキュリティグループのインバウンドとアウトバウンドを示します。
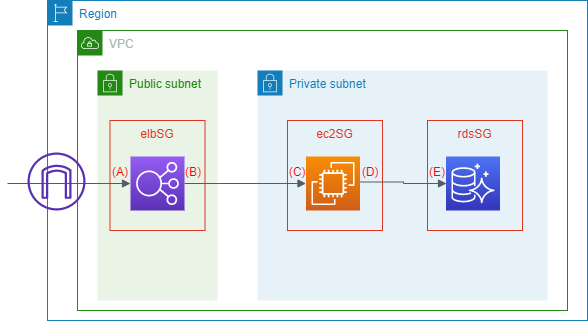
構成図と前述のポートをマッピングすると以下のようになります。
| 位置 | 送信元/送信先 | ポート | 補足 |
|---|---|---|---|
| (A)elbSG インバウンド | 0.0.0.0/0 | 80 および 443 | 443のみということも |
| (B)elbSG アウトバウンド | ec2SG | 80 および 443 | 443 のみということも |
| (C)ec2SG インバウンド | elbSG | 80 および 443 | 443 のみということも |
| (D)ec2SG アウトバウンド | rdsSG | 1521 | 接続先の RDS の DB エンジンによる |
| (E)rdsSG インバウンド | ec2SG | 1521 | 使用している RDS の DB エンジンによる |
上の表で送信元や送信先に ec2SG などのようにセキュリティグループの名称が記載されていることにお気づきかと思います。
クラウドの場合、オンプレミスと異なり送信元や送信先の IP アドレスが常に変わる可能性があります。(AutoScaling でインスタンスが起動したり削除されたりするような環境など)
そのため、指定されたセキュリティグループが設定されている場合は通信が許可されるように設定が可能です。
- 構成図とポートのマッピングの表の通りの内容のため正解と考えます。
- ec2SGにある、RDS からは EC2 へ 80 や 443 での接続はしないため、不適当です。
- elbSGがインターネットからのアクセスが認めていない、elbSG にある ec2SG からの接続や ec2SG にある rdsSG からの接続はしないため、不適当です。
- elbSGがインターネットからのアクセスが認めていない、elbSG にある ec2SG からの接続や rdsSG にある elbSG からの接続はしないため、不適当です
第10問
問題文
E コマース関連企業は 1 日の売上を集計し、その結果を Amazon S3 に保存する夜間処理のコストを削減したいと考えています。その処理は複数のオンデマンドインスタンスで実行され、処理が完了するまでに 2 時間弱かかります。処理は夜間にいつでも実行できます。何らかの理由により処理が失敗した場合は、最初から処理を開始する必要があります。
この要件に基づいて、最もコスト効率の良いソリューションは次のうちどれですか?
- 予約インスタンスを購入する。
- スポットブロックのリクエストを作成する。
- すべてのスポットインスタンスのリクエストを作成する。
- オンデマンドインスタンスとスポットインスタンスを併用する。
回答
2
解説
処理時間は2時間弱で、複数のオンデマンドインスタンスで実行されている。いつ実行してもよい。処理失敗時は最初からやりなおす、つまり途中経過を管理したりリカバリするためのロールバックといったことは不要だが、何らかの要因でインスタンスが停止することが続くと、一向に処理が終わらないといったことも考えられる。こういった観点で、コスト効率が良いものを選ぶのが要件です。
- 2時間弱で終わる処理に対して ReservedInstance(予約インスタンス) を購入するのはやりすぎ(コスト高)なため、不適当です。
- スポットブロックは、スポットインスタンスの価格変動があっても一定の時間(60~360分)は起動し続けられるオプションです。よって要件を満たせるため、正解と考えます。
- スポットインスタンスですべてをまかなってしまうと、価格変動が頻繁に発生した場合、夜間に処理が完了しない恐れがあります。そのため、不適当です。
- たしかに、スポットインスタンスを併用するとオンデマンドインスタンスのみで実行している現在よりはコスト効率は上がりますが、選択肢の3のような事象に遭遇したりすると問題です。また、選択肢2と比較するとコスト効率の面でもよいとは言えなくなります。よって、不適当です。
サンプル問題以外の学習リソース
様々な学習リソースが用意されています。
以下はその一例です。
- AWS公式の模擬問題
- AWS 認定サイトから受験可能です。
- 認定準備ワークショップに参加
- AWS が定期的に開催しているワークショップに参加して学ぶことが可能です
- 試験対策テキスト
- AWS認定アソシエイト3資格対策~ソリューションアーキテクト、デベロッパー、SysOpsアドミニストレーター~
まとめ
SysOps アドミニストレーターアソシエイト試験は、既に AWS 上で稼働しているシステムに対して運用面での改善やインシデント対策に関する問題が多い傾向にあります。そのため、システム構築するには...という観点よりは、よりよくするにはどうしたらよいかで問題内容を把握し、最良の答えを選んでいっていただけたらと思います。
記載されている会社名、製品名、サービス名、ロゴ等は各社の商標または登録商標です。