はじめに
本記事は2019/03/03に執筆しました。
これ系の技術は常にアップデートされているため、将来的に古くなる可能性があります。
Translator TextとCustom Translator
Translator Textとは
Microsoftが展開している「Cognitive Services」の1つで、いわゆる機械翻訳です。
https://azure.microsoft.com/ja-jp/services/cognitive-services/
Cognitive Servicesの他には、音声解析や画像解析機能が提供されています。
Bing翻訳の内部も、どうやら同様のエンジンを使用していそうです。(推測)
基本的にTranslator Textは、Rest APIから実行します。
なので時折、「Translator Text API」と呼んでいたりもします。
https://azure.microsoft.com/ja-jp/services/cognitive-services/translator-text-api/
Translator Text APIは、Azureから設定を行います。
設定方法などは、公式のリファレンスを参照ください。
https://docs.microsoft.com/ja-jp/azure/cognitive-services/translator/translator-info-overview
Custom Translatorとは
上記のTranslator Text APIでは、一般的な翻訳の結果しか適用されません。
つまり、自社独自であったり、業界独特の文章や単語は、翻訳結果に反映されないわけです。
そこで登場するのが、この「Custom Translator」です。
https://www.microsoft.com/ja-jp/translator/business/customization/
Custom Translatorは「ニューラル機械翻訳(NMT:Neural Machine Translation)」という仕組みを採用しており、機械翻訳結果をより自然に、人の翻訳のように反映させるものです。(詳しくは後述)
Custom Translatorでは、人の手で行われた翻訳結果の対照テキスト一覧(例:日本語⇔英語)を、事前に管理者がシステムにアップロードし、学習させます。
これは各環境(プロジェクト)ごとに学習させるため、自社独自の辞書であったり、独自の業界の言葉や言い回しを、オンリーミーとして学習させる事ができるわけです。
システム連携をすることで、Translator Textには、Custom Translatorで学習させた内容が反映されます。
これで、Translator Text APIを、ほとんど変えることなく今まで通り(ちょこっと変わるけど)呼び出すだけで、独自の辞書結果を反映してくれます。
本投稿は、このCustom Translatorについて、さわりを超ざっくり解説していきます。
Custom Translatorの概要
ニューラル機械翻訳(NMT:Neural Machine Translation)
上記の通り、Custom Translatorは「ニューラル機械翻訳(NMT:Neural Machine Translation)」という仕組みを採用しております。
ニューラル機械翻訳(NMT:Neural Machine Translation)については、この記事が非常に分かりやすかったです。
超ざっくりいうと、
- これまで(ルールベース機械翻訳):文法ルールと辞書情報を基に訳文を生成するので、翻訳結果が機械的になることが多かった
- NMT:実際に人間が翻訳した文章で学習するので、結果も自然になる
- ただし:学習させていない単語の翻訳にはとことん弱い
こんな特徴を持ちます。
Custom Translatorの使用まで
実際にCustom Translatorを使用するまでは、以下の内容を参考にしました。
実際に触ってみて、少しだけ補足したいことがあったので、こちらに記載します。
学習のためのsentenceは10,000文以上必要
まず、機械学習のための学習データを作成時に、翻訳前⇔翻訳後の文章をアップロードします。
その後、学習データのモデルを作成するのですが、文章が足りないと、
「Please select one or more parallel documents with a minimum of 10,000 sentences to start your training.」
と表示されます。
これは、「トレーニングを開始するには、少なくとも1万の文章を含む1つ以上の並列ドキュメントを選択してください。」ということです。要するにCustom Translatorの使用には、翻訳前⇔翻訳後の文章がそれぞれ1万文章以上必要ってことです。
「うちには少し、専門用語のAAAとBBBとCCCがあるから、それらを翻訳結果に反映させたいな!」ぐらいのニーズだと、とても実現ができなそうです。
まあ機械学習はデータ量が肝だから仕方ないね。このサービスは大企業向けの内容でしょう。
ちなみに自分は、検証用として、青空文庫の「吾輩は猫である」を、日本語と、機械翻訳した英語の本文をそれぞれ作成し、アップロードして試しています。機械翻訳した内容を再度NMTに学習させるという笑
Custom TranslatorのAPI
Custom TranslatorのAPIは用意されています。(ただし2019/03/03現在Preview版)
こちらがリファレンス・・・なのですが、どうもこのリファレンスは不足がけっこうありそうです。
色々探りまくったら、GitHubにサンプルソースがあったので、こちらをご参照ください。→CustomTranslatorApiSamples
Microsoft Graph APIでの認証方法とほとんど同じなのですが、注意するのが「resourceUri」が "https://graph.microsoft.com" ではなく "api://6981666b-e0e0-47d6-a039-35318677bf79/access_as_user" という文字列なことです。なんじゃそりゃ。
将来的にGAされたときに変わるんですかね?とりあえずこの文字列を使用すれば大丈夫そうですね。
APIがあれば、例えば各部署の担当者が、学習のための翻訳前⇔翻訳後ファイルアップロードを、Custom Translatorのサービスページにアクセスさせなくても実行できるようになるはずです。(Custom Translatorのサービスページにみんなをアクセスさせちゃうと、非常に危険ですよね)
また、翻訳機能を埋め込んだアプリを実行時に、ワークスペース一覧、カテゴリ一覧を表示し、
翻訳サービスの利用者に、ワークスペースやカテゴリなどを選んでもらって、翻訳させる・・・なんてことも出来るかもしれません。
(権限的に、管理者でないユーザーがワークスペース一覧、カテゴリ一覧を取得出来るか、未検証ですが・・・)
Translator Text APIにCustom Translatorの結果を反映
2020/01/22修正しました
Translator Text APIに、Custom Translatorの結果を反映させるためには、APIのTranslateのクエリ文字列に、「category=(カテゴリID)」を追加してあげます。
なおカテゴリIDは、Custom TranslatorのProjectに記載しております。
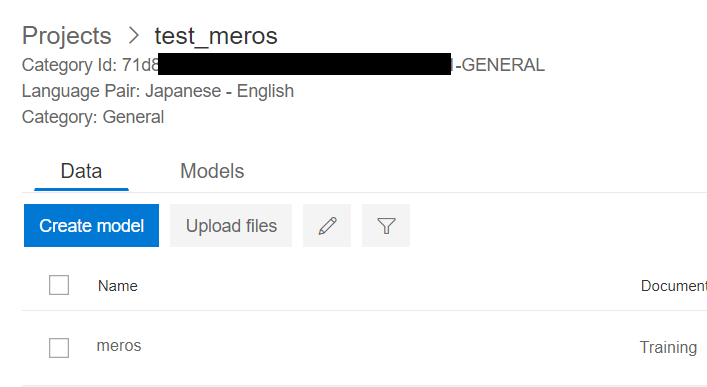
プロジェクトなのにカテゴリIDなんですね。分かりづらry
まとめ
- Custom Translatorは、機械翻訳に独自の翻訳結果を追加できる機能
- 方式はニューラル機械翻訳で、自然な翻訳結果には長けているが、学習していない言葉には弱い
- 使用には10,000文以上必要。「この何個かの単語を結果に反映させてほしいな」ぐらいの用途には向かない
- Custom Translator APIをうまく絡めれば、管理もしやすそう。ただし、現在プレビュー版