
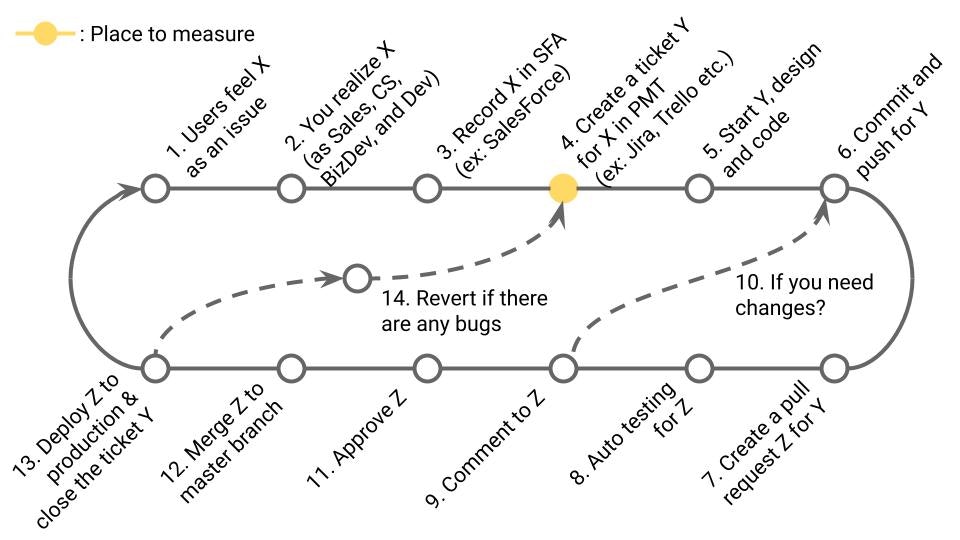
1. はじめに
システム開発にまつわるチームや組織の活動は、指標なんかで測れるわけないやろ~、という声は根強いです。ましてや、それが人の評価になろうものなら、感情的な反発さえありえます。Martin Fowlerもこちらよりです。
一方で、何らかの指標で測れるはずじゃないの?という声も根強い気がします。測れんかったら、良くなったかどうか、どうやって判断すんねん、という意見ですね。DORA Metricsを擁するGoogleはこちらよりですかね。
私はどちらなのかというと、後者で、測れるものは測りたいタイプです。もちろん、すべてが正しく測れるなどとは思っていません。そもそも定性的な指標と定量的な指標のバランスが大事であり、定量的な指標でさえも、現実世界では正確性と計測コストはトレードオフだと思ってます。
しかし、ではじゃあ、具体的にどうすればいいのか?それをまとめてみましたので、ご覧ください!
2. 何を計測したいか?
議論はここがまず一致しないまま行われることが多いように感じます。
今回計測したいものは、チームや組織のアウトプットとします。
2-1. チームのアウトプットとは何か?
内訳として個人単位も必要になるかもしれないですが、主語はあくまでシステム開発におけるチームや組織の単位とします。
ではアウトプットとは何か?アウトプットとは、行動量であり、活動量であり、生産量であり、チームへの貢献量である、と定義します。さらに具体的な指標は後述。アウトプットは、スループットやパフォーマンスと言い換えられるかもしれません。
2-2. アウトプット≠アウトカム
逆に、アウトプットは、アウトカムではありません。つまり、アウトプットは売上でもなければ、ユーザーの満足度でもない、とします。
もちろん、どのタスクが、どれだけユーザーの満足度を向上させ、ユーザーのリテンションを維持し、ユーザーのアップセルを実現し、最終的に売上に紐づいたかを計測できるならば、その方がいいわけです。ただ、ここではアウトカムは計測できない、もしくは計測コストが非常に高いので、手に入りにくいとしました。実際手に入らないからです。
アウトカムを見ることは非常に重要だと理解しつつ、その入手難易度の高さから、欠点のあるアウトプットをどう利用していくかを考えていきます。
3. なぜ計測したいか?
目的は、もちろん、課題を解決するためです。
ではチームや組織のアウトプットの数字や推移が分からないと、どういうペインを感じうるか、以下のように仮定してみました。
3-1. 課題仮説1
チームや組織の力が良いのか悪いのか、客観的に分からない
- 改善するアクションをとるべきなのかどうかも分からない
- アクションたちをとったとしても、チームや組織の力が良くなったのかどうか分からない
3-2. 課題仮説2
チームや組織内の透明性・客観性が低くなる
- 定性的なゴールだけだと、メンバーにとってふわっとなりやすい
- 個人の人事評価においても、基準があいまいだと離職率が高くなるかもしれない
3-3. 課題仮説3
社内の他のチームや組織に対する透明性・客観性が低くなる
- 開発のことを知らないメンバーに対して、今自分のチームや組織がどれだけアウトプットしているか、説明しづらいし、アピールしづらい
3-4. 課題仮説4
社外の採用候補者に対する透明性・客観性が低くなる
- どういったスピードと品質の状態にあるのか、説明しづらい
- 結果、魅力を伝えにくいので、採用候補者にとってブラックボックスリスクになる。それに気づかない人は入社してくるかもしれないが。
- また、自分たちに自分たちのアウトプットの数字や推移の目線がないので、採用候補者に対して、同じ質問をするという観点も持ちにくい
3-5. 課題仮説5
サービスのユーザー対する透明性・客観性が低くなる
- どの程度進化し続けているサービスなのか、それとも進化が止まっているサービスなのか、分からない
- GitHub Copilotのように革新的なサービスが生まれるなら分かりやすいが、必ずしも他のサービスはそうではない
のような課題が本質的にあるはずだと考える。現時点ではこの課題=ペインのヒアリングは十分ではないので、仮説である。
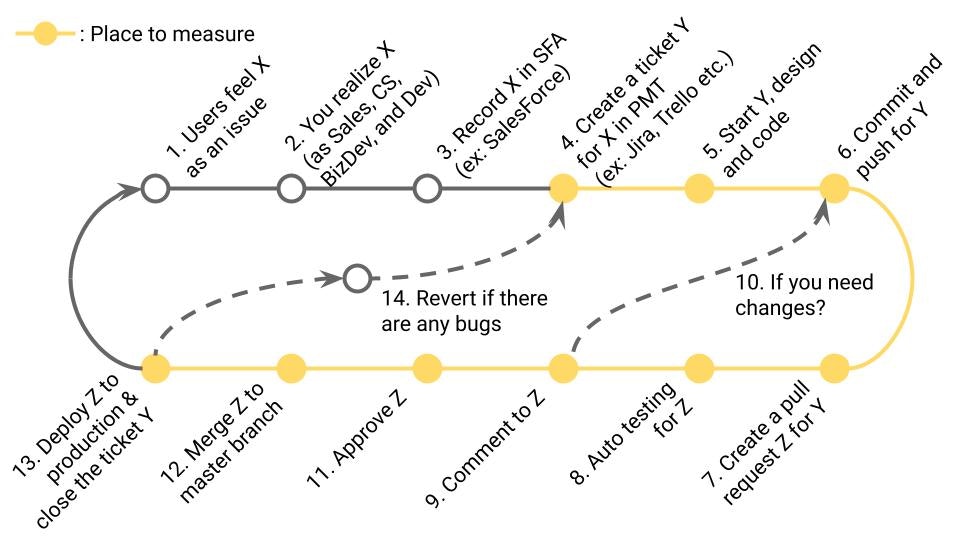
4. 具体的に何を計測できるか?
本章では具体的な指標と定義、見方を紹介していきます。
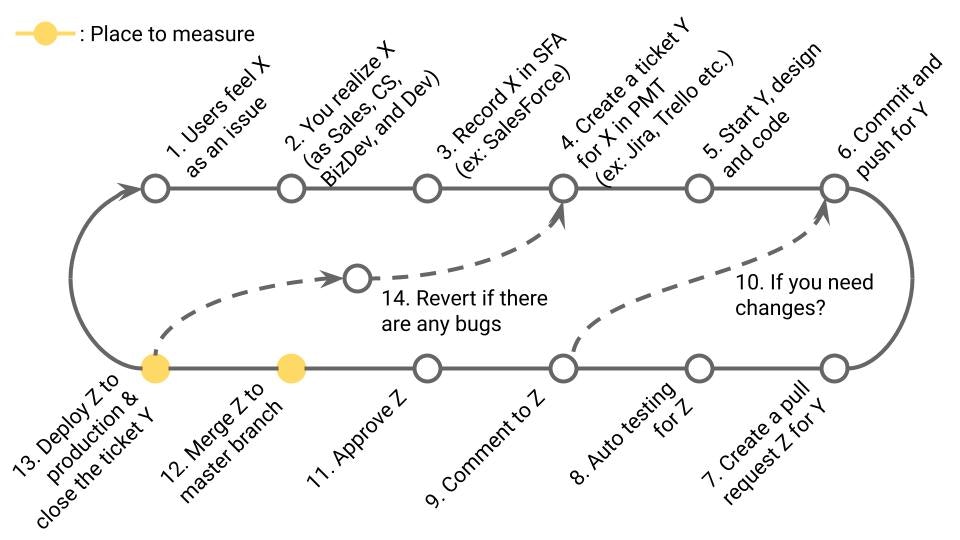
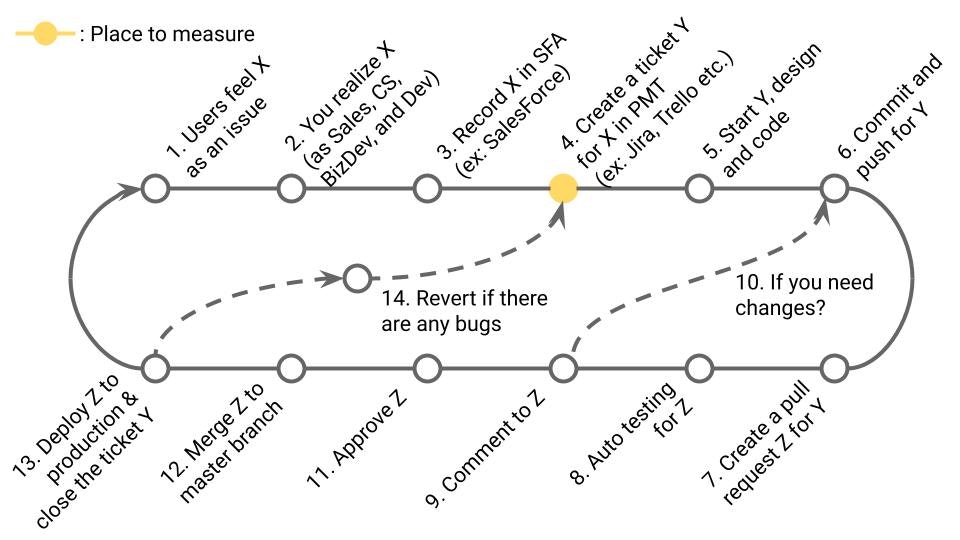
4-1. Deployment Frequency (DORA)

定義
本番環境へのデプロイ頻度。DORA Metricsの1つ。
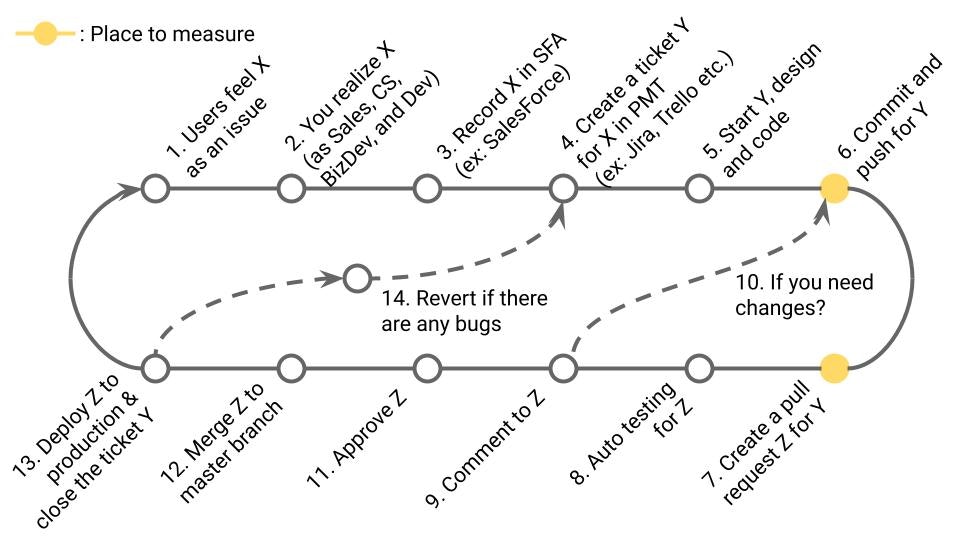
業務サイクルの該当箇所
13の頻度(≒12の頻度 ※13の頻度が計測しにくい場合)
計算式
デプロイ頻度=f(A, B)×C/D
- A=対象期間の最後の日付
- B=Max(対象期間の最初の日付、全期間の最初のプルリクエストのマージ日)
- f () =AとBの日付間の平日数
- C=1日の営業時間
- D=対象期間にマージされたプルリクエスト回数
- 例: (2022年11月14日-Max(2022年1月1日、2022年11月1日))×1日8時間/10回
=(2022年11月14日-2022年11月1日)×1日8時間/10回
=10日×1日8時間/10回
=8時間/回
ソース
GitHub、GitLab、BitBucket等
数字の見方
-
対象期間の数字を、State of DevOpsが提供する基準値と比較する(下図)

-
対象期間の数字もしくは改善幅を、同リポジトリの他チームや、他リポジトリと比較する
-
対象期間の数字を、自チーム内の前期までの推移と比較する
改善アクション
そもそも何がボトルネックなのか、チームで議論するのが大事
- 3や4で内容確認のための手戻りが多いのであれば、起票の仕方を工夫してテンプレート化する
- 4や7で、リリース単位を小さくする(決して見せかけだけの悪いことではない)
- 5~6で時間がかかっているのであれば、ドキュメントを4や7の必須事項に追加する(デプロイの度に該当箇所のドキュメントを強化していく)
- 7で、エビデンスをスクショではなく、動画にすることで、11を早める
- 8で、自動テストを導入する(短期的にはデプロイ頻度落ちるが、中長期的には必ず貢献する)
- 9で差し戻しが多いのであれば、7のテンプレートを改善する
- 13で、自動デプロイを導入する(デプロイ頻度の改善だけでなく、人的ミスも減る)
- デプロイ頻度の高いメンバーの理由を分析して、他メンバーに共有する
- 開発メンバーを増員する
参考URL
- https://cloud.google.com/blog/products/devops-sre/using-the-four-keys-to-measure-your-devops-performance
- 2022 State of DevOps Report | Google Cloud
- https://linearb.io/blog/deployment-frequency/
4-2. Lead Time for Changes (DORA)
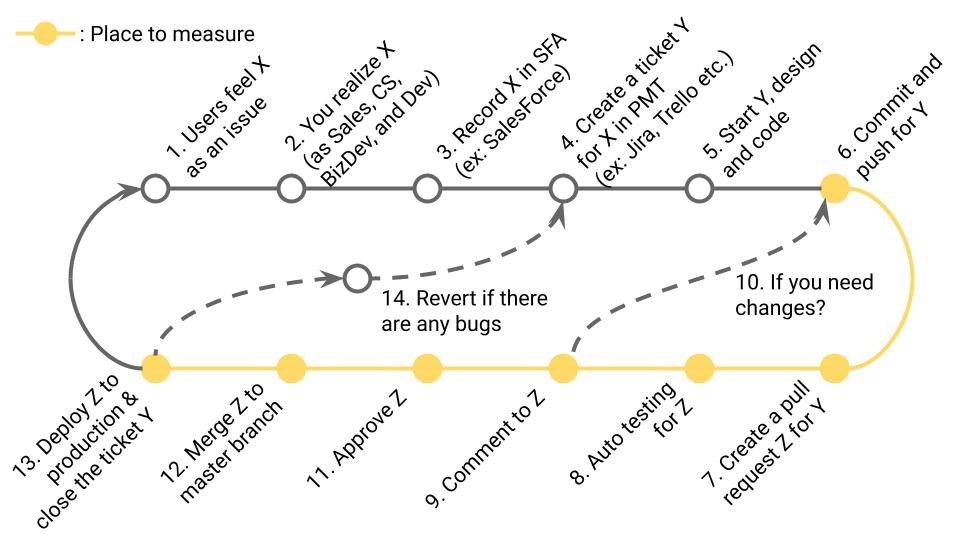
定義
1stコミットからデプロイまでのリードタイム。DORA Metricsの1つ。
業務サイクルの該当箇所
6~13までの時間(≒6~12までの時間 ※13の時刻が計測しにくい場合)
計算式
Σ(A-B)/C
- A=対象期間にマージされたプルリクエストのマージ時刻
- B=そのプルリクエストの最初のコミット時刻
- C=対象期間にマージされたプルリクエスト回数
- 例: (2時間+4時間+6時間)/3回=4時間
- 注意事項: オリジナルの定義が曖昧な影響で、計算式の解釈に幅がある。特にBの対象期間の開始の定義が曖昧で、業務サイクルの4や5と定義してる場合もある
ソース
GitHub、GitLab、BitBucket等
数字の見方
-
対象期間の数字を、State of DevOpsが提供する基準値と比較する(下図)

-
対象期間の数字もしくは改善幅を、同リポジトリの他チームや、他リポジトリと比較する
-
対象期間の数字を、自チーム内の前期までの推移と比較する
改善アクション
そもそも何がボトルネックなのか、チームで議論するのが大事
- 4や7で、リリース単位を小さくする(決して見せかけだけの悪いことではない)
- 7で、エビデンスをスクショではなく、動画にすることで、11を早める
- 8で、自動テストを導入する(短期的にはデプロイ頻度落ちるが、中長期的には必ず貢献する)
- 9で差し戻しが多いのであれば、7のテンプレートを改善する
- 9や11で、レビュアーのリアクションが遅い場合
- アラート方法を見直す(普段Slackを見ているのに、アラートはメール通知で見てなかった等)
- TODO管理の方法を見直す(Slack通知はあるが、TODO管理のJiraには登録されないので、流れてしまって忘れてしまった等)
- 13で、自動デプロイを導入する(デプロイ頻度の改善だけでなく、人的ミスも減る)
参考URL
- https://cloud.google.com/blog/products/devops-sre/using-the-four-keys-to-measure-your-devops-performance
- 2022 State of DevOps Report | Google Cloud
- https://www.blueoptima.com/blog/how-to-measure-devops-success-why-dora-metrics-are-important#:~:text=The lead time for changes,between one and six months.
- DevOps の Four keys の Lead time for changes (=変更のリードタイム)についてのまとめ
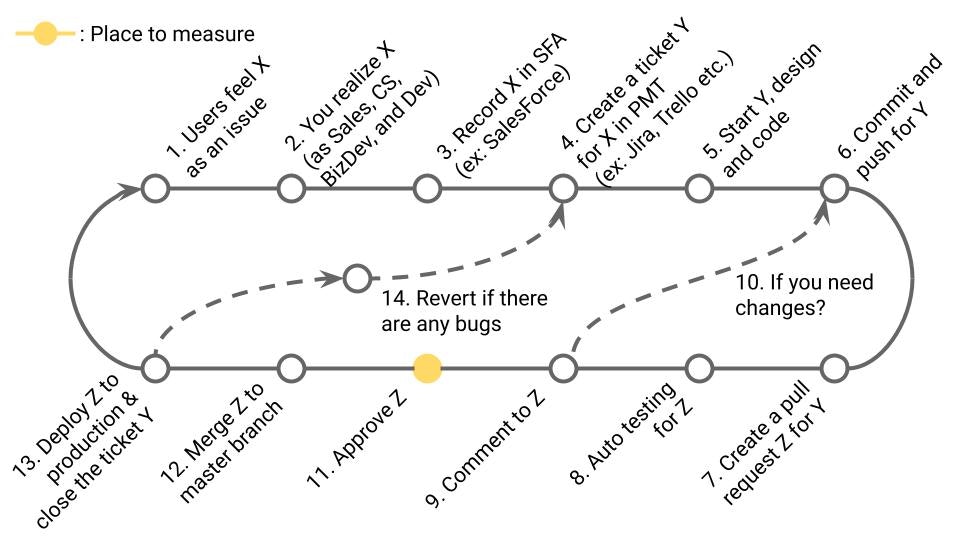
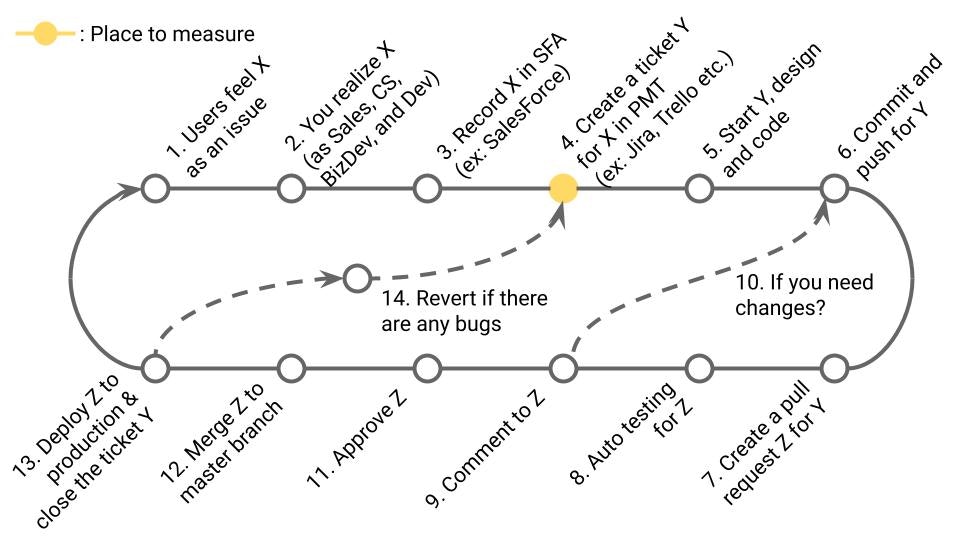
4-3. Change Failure Rate (DORA)
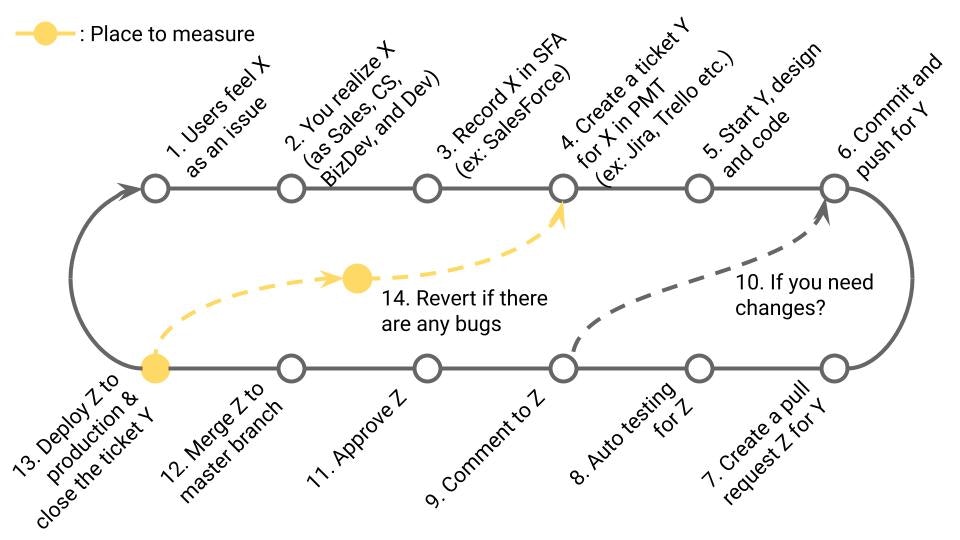
定義
本番障害につながったプルリクエストの確率%。DORA Metricsの1つ。
業務サイクルの該当箇所
13の内14に発展したもの
計算式
A/B
- A =対象期間にマージされたプルリクエストの中で、リバートされたプルリクエスト数
=MAX(C、D、E)- C=プルリクエストのタイトルに「Revert」を奇数回含むプルリクエスト数
※偶数回の場合は、修正用のプルリクエストであるとみなす - D=ラベルに「incident」を含むプルリクエスト数
※多くの場合、インシデント後の手運用となるため、精度が低い - E=ラベルに「bug」を含むプルリクエスト数
※修正用のプルリクエストのラベルなので、厳密には、本番障害につながったプルリクエストそのものではないが、タイミングが事後ではないため、Dより精度が高い場合がある
- C=プルリクエストのタイトルに「Revert」を奇数回含むプルリクエスト数
- B=対象期間にマージされたプルリクエストの中の、総プルリクエスト数
- 例: 2回/100回=2%
- 注意事項:
- デプロイメント≒マージとしている
- リバートされた理由が、単なる作業ミスの場合でも、カウントされてしまう
ソース
GitHub、GitLab、BitBucket等
数字の見方
-
対象期間の数字を、State of DevOpsが提供する基準値と比較する(下図)

-
対象期間の数字もしくは改善幅を、同リポジトリの他チームや、他リポジトリと比較する
-
対象期間の数字を、自チーム内の前期までの推移と比較する
改善アクション
そもそも何がボトルネックなのか、チームで議論するのが大事
- 4や7で、リリース単位を小さくする。リスクの観点でも有効
- 7で、エビデンスをスクショではなく、動画にすることで、不具合に気づきやすくする
- 8で、自動テストを導入する。そもそもテストしていませんでした、を防げる
- 9で、ソースに対するコメントがすべて「Resolved」にならないとマージできないようにする(リポジトリの設定で可能)
- 11で、レビューを必須にする(リポジトリの設定で可能)
- 11で、レビュー人数を2人以上にする(リポジトリの設定で可能)
- QAの部署を作り、11の承認権限を持たせる
- 3を起票したノンエンジニアのビジネス部門の人も、11の承認プロセスに加える
- 13で、自動デプロイを導入し、デプロイミスをなくす
参考URL
- https://cloud.google.com/blog/products/devops-sre/using-the-four-keys-to-measure-your-devops-performance
- 2022 State of DevOps Report | Google Cloud
- Why defining failure is the key to measuring change failure rate | Evan Klein | July 27, 2022
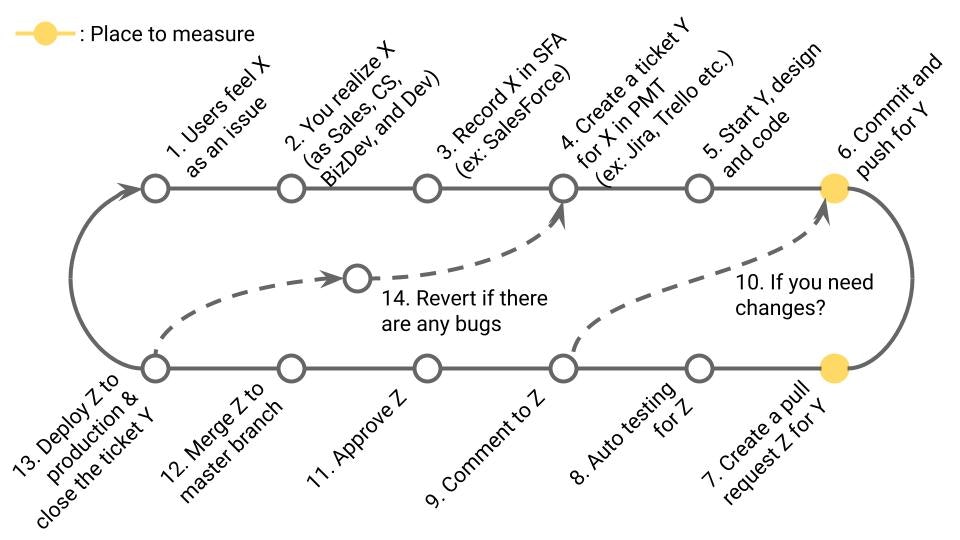
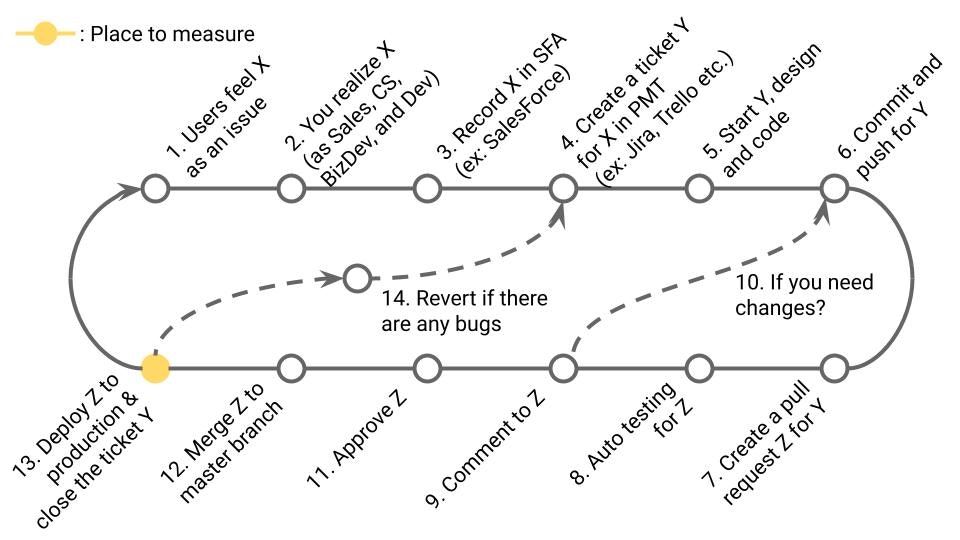
4-4. Time to Restore Service (DORA)
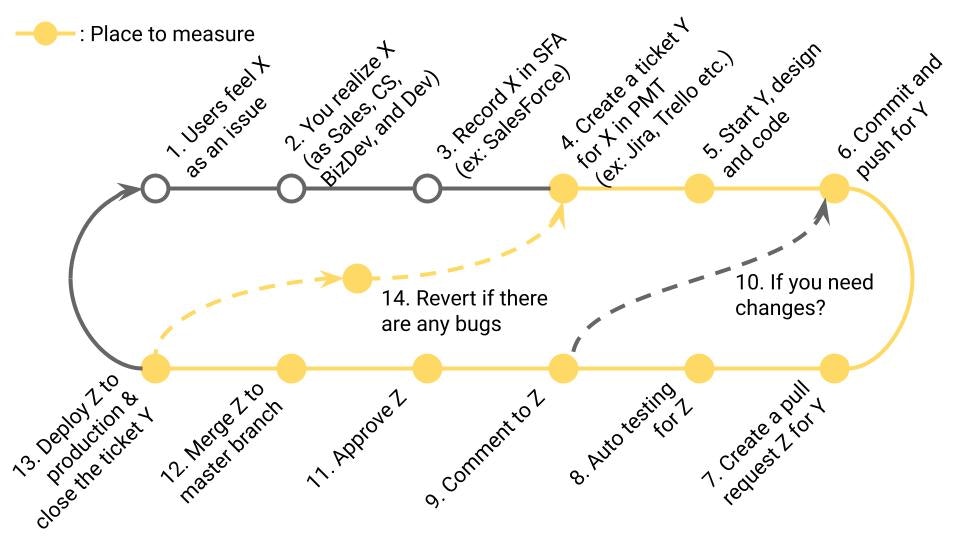
定義
本番障害発生から、復帰までの時間。DORA Metricsの1つ。
業務サイクルの該当箇所
障害の原因となった13~14~対応された13までの時間
計算式
Σ(A-B)/C
- A=障害Xの修正をしたプルリクエストがマージされた時刻
- B=障害Xの直接的な原因となったプルリクエストがマージされた時刻
≒Aの直前のプルリクエストと仮定する - C=対象期間内の障害Xの回数
- 例: (2時間+4時間+6時間)/3回=4時間
- 注意事項:
- Bの定義は正確ではないが、本指標が悪いチームや組織ほど、正確なBを特定し、Aに紐づける運用の徹底が出来ていないことが多いのではと仮定した
- 仮に上記の運用が徹底されていても、GitHub等のAPIから上記を特定することも難しい
- また、サーバーダウンや、CPU100%張り付き、等インフラ起因の障害は、本集計方法では含まれない
ソース
GitHub、GitLab、BitBucket等
数字の見方
-
対象期間の数字を、State of DevOpsが提供する基準値と比較する(下図)

-
対象期間の数字もしくは改善幅を、同リポジトリの他チームや、他リポジトリと比較する
-
対象期間の数字を、自チーム内の前期までの推移と比較する
改善アクション
そもそも何がボトルネックなのか、チームで議論するのが大事
- 障害に気づいてから、必要なチームに連絡がとれるまでの時間に問題がある場合
- Slackだけで見てませんでした、であれば、障害時は電話に変える
- 電話したけど、気づきませんでした、であれば、何度も電話する
- 何度も電話しても、つながりませんでした、であれば、連絡網を増やす=体制を増やす
- 社内の体制強化に限界があるのであれば、外注を検討する
- 障害の原因を特定するまで、もしくは解決するまでの時間に問題がある場合
- 実際に起きた障害で、模擬訓練する(再現が難しかったり、手間がかかる場合も多い)
- 本番環境とは別に、検証環境が稼働しているならば、普段から検証環境をクリーンに保つ(とはいえ、検証環境がダウンしても、チームの指針によっては、優先順位が上がらない場合も多い)
- プロダクトのドキュメント不足が原因ならば、業務サイクルの7でドキュメントのURL添付を必須にする(とはいえ、運用ルールの徹底が必要)
参考URL
- https://cloud.google.com/blog/products/devops-sre/using-the-four-keys-to-measure-your-devops-performance
- 2022 State of DevOps Report | Google Cloud
- MTTR: Mean time to recovery - Incident Management - Atlassian
4-5. Number of Pull Requests
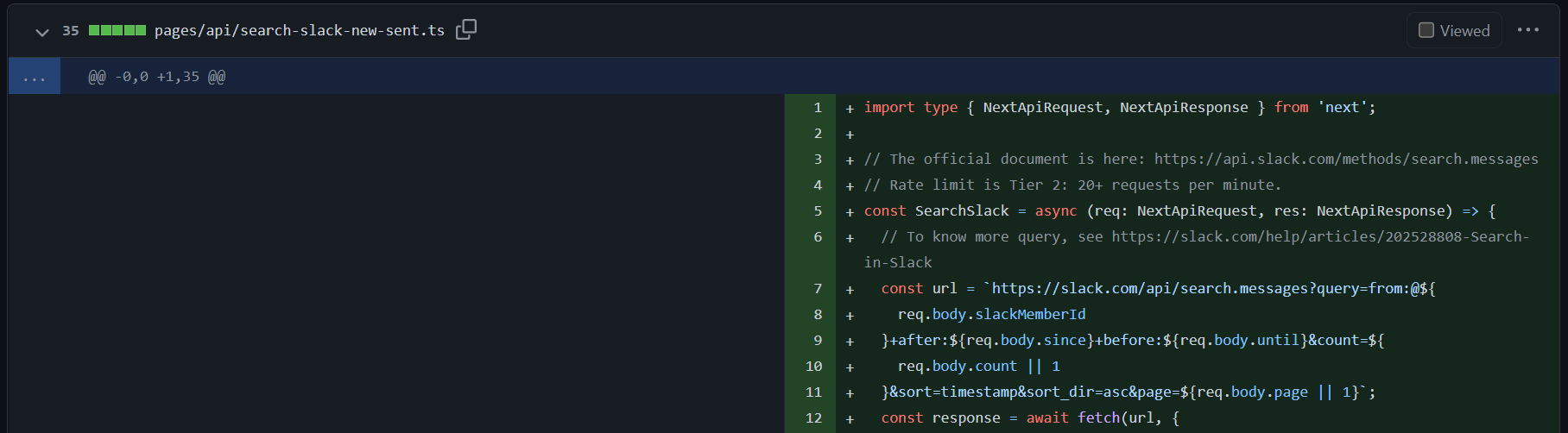
定義
プルリクエストがマージされた回数
業務サイクルの該当箇所
13の回数(≒12の回数)
計算式
対象期間にマージされたプルリクエストの回数
- APIエンドポイント例: https://api.github.com/search/issues
- クエリ例: is:pr is:merged repo:${ownerName}/${repoName} author:${userName} merged:${since}..${until}
- 例: 10回
ソース
GitHub、GitLab、BitBucket等
数字の見方
4-1と同様
- 頻度だけだと、絶対量が直感的にわからないので、セットで見ると有効
- 特にビジネス部門に対しては、絶対量の方が伝わりやすい場合がある
- 但し、絶対量だけでなく、何をリリースしたかの中身も重要であることを忘れてはいけない
改善アクション
4-1と同様
4-6. Number of Reviews
定義
プルリクエストをレビューした回数
業務サイクルの該当箇所
11の回数
計算式
対象期間内にマージされたプルリクエストの中で、ユーザーが承認した回数
- APIエンドポイント例: https://api.github.com/search/issues
- クエリ例: is:pr is:merged repo:${ownerName}/${repoName} reviewed-by:${userName} merged:${since}..${until}
ソース
GitHub、GitLab、BitBucket等
数字の見方
- 承認回数は、レビュー回数であり、この回数が多ければ多いほど、基本的には、レビュアーとしてチームに貢献していることになる
- 一方で、当然レビューの中身も重要
- 例えば、誰が見ても、何のコメントも不要なプルリクエストもある。ただ、往々にして、何のコメントもないプルリクエストを私は見たことがない。特に毎回コメントもなく、LGTMだけしていたり、不具合の原因となったプルリクエストにコメントなく承認していた場合などには、注意が必要だ
改善アクション
- DORA MetricsのChange Failure Rateが高いのであれば、不具合がレビューをすり抜けていることになるので、根本的にはレビュー回数を増やす必要がある
- GitHubの場合は、リポジトリ単位で、承認人数や回数を制限することが可能。今まで必須設定がなかったのであれば、1人設定する
- 可能であれば、意味のある2人以上に設定する
- それ以外にも、プルリクエストごとに任意のピアレビューを依頼する
4-7. Number of Lines of Code Added
定義
追加 or 編集したコード行数
業務サイクルの該当箇所
6 or 7
計算式
対象期間に追加 or 編集したコード行数
-
新規に追加したか、それとも編集したか、どっちなのかはGitHub APIの場合判定できない
-
新規に追加したコードの例
-
編集したコードの例
ソース
GitHub、GitLab、BitBucket等
数字の見方
いわゆる昔からあるLOC。これは特に反発が多い指標で、意味がないという意見も多いです。
一方で、最近だと、Elon MuskがTwitterのグローバル・レイオフを行なった際の基準にLOCが使われたという噂もあるくらい、シンプルな指標でもあります。
- 対象期間の数字もしくは改善幅を、同リポジトリの他チームや、他リポジトリと比較する
- 僅差での順位には意味がない。例えば、100行追加したチームと、1行しか追加しなかったチームとで、どちらがアウトプットしたかを単純に比べることは出来ない。1行だけの追加でもエレガントに目的を達成できてる場合もあるからだ
- とはいえ大局してみると、アウトプットそのものである、ともとらえられる。例えば、1万行追加したチームと、100行追加したチームとでは、やはり前者のチームの方がアウトプットしている可能性は高い
- 対象期間の数字を、自チーム内の前期までの推移と比較する
- チームの学習カーブがあがっていく過程では、本指標もあがっていく可能性は高い
- チームがより効率よくコードを再利用できるようになってくると、1回のプルリクエスト内の追加行数は下がっていくかもしれないが、プルリクエストの回数自体が増えていくはずなので、やはり本指標もあがっていく可能性は高い
改善アクション
4-1と同様
4-8. Number of Lines of Code Deleted
定義
削除 or 編集したコード行数
業務サイクルの該当箇所
6 or 7
計算式
対象期間に削除 or 編集したコード行数
-
削除したか、それとも編集したか、どっちなのかはGitHub APIの場合判定できない
-
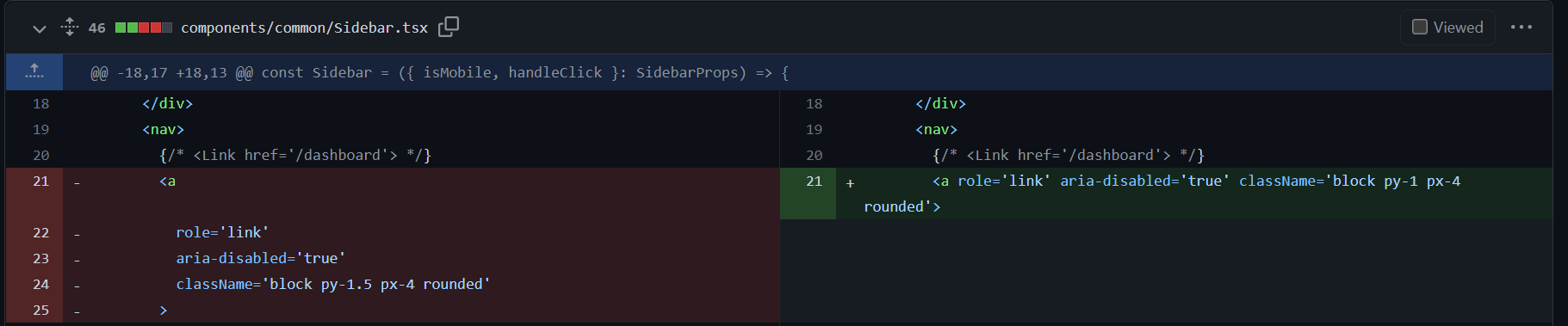
削除したコードの例: 単純に不要になったコード、もしくはリファクタリングし、不要になったコード等。後者の場合は厳密には代替コードがある
-
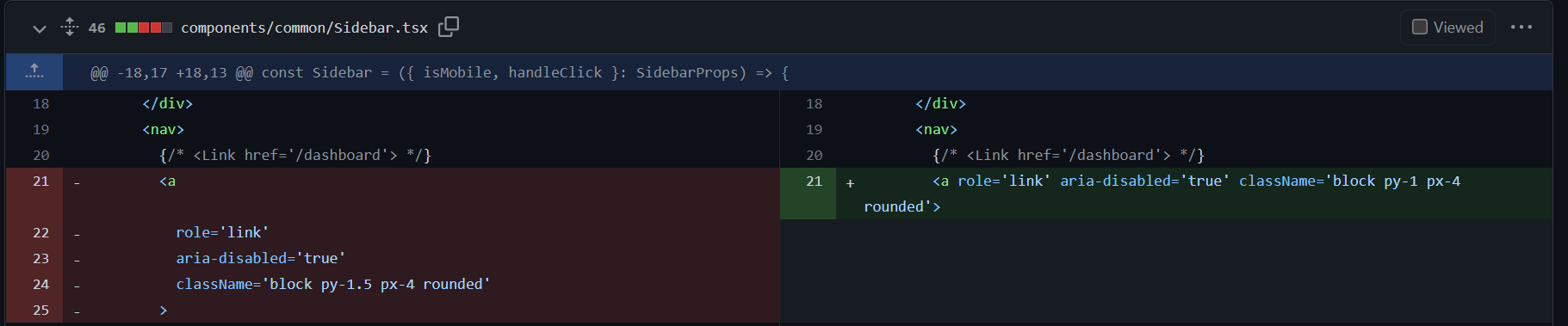
編集したコードの例: 修正したのは、パディングの値を1.5から1に変更しただけなので、実質は1行だが、Prettierなどのフォーマッターの関係で5行削除としてカウントされることがある(ノイズとして理解し、コストの安い指標として、受け入れる)
ソース
GitHub、GitLab、BitBucket等
数字の見方
- 対象期間の数字もしくは改善幅を、同リポジトリの他チームや、他リポジトリと比較する
- 対象期間の数字を、自チーム内の前期までの推移と比較する
改善アクション
4-1と同様
4-9. Number of Created Tasks
定義
チケットを作成した回数
業務サイクルの該当箇所
4の回数
計算式
対象期間内に作成されたチケットの数
- Jiraの場合:
- API例: https://api.atlassian.com/ex/jira/${*atlassianCloudId*}/rest/api/3/search
- クエリ例: creator = currentUser() AND createdDate < 2022-10-01 AND createdDate >= 2022-09-01
ソース
- GitHub Issues、GitLab Issues、BitBucket Issues
- Jira、Trello、Asana、Monday.com、ServiceNow、ClickUp、Wrike等
数字の見方
- 4で作成されるチケットは、後続で開発される機能の元ネタになる。まずは単純に未来の種がどの程度生み出されているのか、誰が特に生み出しているのか知ることが出来る。但し、大事なのは、中身と数の両方であることを常に理解しておく
- また、そもそも、Slackでの指示や口頭での指示がまだまだ多いプロジェクトもある。そういったプロジェクトにおいては、このチケット作成数をメンバー別にみることで、作業指示者がちゃんと作っているか、作業者がそもそもチケットを作成しているか、切り分けることも出来る
改善アクション
- チケットに書く内容をテンプレート化することで、起票者の起票スピードが速くなる
- このチケット起票という行為そのものが面倒なことが多い。なので、チケット作成回数自体も貢献の1つとして見てるよ、というメッセージは、チケットをちゃんと作ろうというモチベーションを沸かせる可能性がある
- そもそも作業依頼は、必ずチケットで行う、というルール作りは、チケット作成数を高めるだろう。また、このルールは業務効率そのものも高めてくれる可能性がある。作業依頼が様々なルートで可能な場合、作業依頼の割り込みや、隠れた作業依頼、雑な作業依頼の温床になるからだ
参考URL
4-10. Number of Closed Tasks
定義
完了したチケットの数
業務サイクルの該当箇所
13の回数
計算式
対象期間内に完了したチケットの数
- 条件: 対象期間の最終日時点でも、そのチケットが完了状態であること
- Jiraの場合:
- API例: https://api.atlassian.com/ex/jira/${*atlassianCloudId*}/rest/api/3/search
- クエリ例: assignee = currentUser() AND status CHANGED TO 10006 DURING (${since}, ${until}) AND status was 10006 ON ${until}
ソース
- GitHub Issues、GitLab Issues、BitBucket Issues
- Jira、Trello、Asana、Monday.com、ServiceNow、ClickUp、Wrike等
数字の見方
- 対象期間の数字もしくは改善幅を、同リポジトリの他チームや、他リポジトリと比較する
- 1つ1つのチケットの粒度や難易度が異なるので、単純比較は出来ない
- そのため、僅差を論じるのはまったく無意味だが、大きな傾向の違いを読み取る分には使えるかもしれない
- また、恐らくまったく可視化していないチームや組織もあるはずで、そのこと自体も比較しようとすればわかるはずだ
- 対象期間の数字を、自チーム内の前期までの推移と比較する
- 他チームや他組織と比較するよりは、意味があるかもしれない
- この本期間も比較対象期間も同じルールでチケットを作っていれば、正確とは言えないまでも、安く手に入る指標になる
- 何より、このチケット消化実績から、今後消化されるであろうチケット数を予測することができる
改善アクション
- 完了条件を明確にする。明確でないから閉じられなくなって、ゴミになったチケットをよく見ます
- 見られている、という意識をチームメンバーに持たせることで、ちゃんと完了にするようになる
- 1つずつ、ちゃんと完了させていく癖をつける。Waitingフラグにしてもいいが、簡単にブロッカーを理由にチケットを止めない
- ブロッカーが発生した場合に、相談しやすい環境をマネージャーが整える
4-11. Number of Open Tasks
定義
未完了なチケットの数
業務サイクルの該当箇所
4
計算式
対象期間の末時点で未完了なチケットの数
- Jiraの場合:
- API例: https://api.atlassian.com/ex/jira/${*atlassianCloudId*}/rest/api/3/search
- クエリ例: assignee = currentUser() AND status != DONE AND resolution = Unresolved
ソース
- GitHub Issues、GitLab Issues、BitBucket Issues
- Jira、Trello、Asana、Monday.com、ServiceNow、ClickUp、Wrike等
数字の見方
- 対象期間の数字もしくは改善幅を、同ワークスペースの他チームや、他ワークスペースと比較する
- 1つ1つのチケットの粒度や難易度が異なるので、単純比較は出来ない
- そのため、僅差を論じるのはまったく無意味だが、大きな傾向の違いを読み取る分には使えるかもしれない
- チーム間の抱えているタスク量の違いが分かり、チーム間のリソースのバランスを考えるヒントになる
- 対象期間の数字を、自チーム内の前期までの推移と比較する
- 推移を見れば、増えているか、減っているか、わかる
- タスクが洗い出される初期や、解像度があがっていってる感覚があれば増えていても問題はない
- 但し、プロジェクトの後半だったり、納期が近づいてるのに、まだ増えていたとすると、それは赤信号である
改善アクション
4-10. Number of Closed Tasksと同様
- 完了条件を明確にする。明確でないから閉じられなくなって、ゴミになったチケットをよく見ます
- 見られている、という意識をチームメンバーに持たせることで、ちゃんと完了にするようになる
- 1つずつ、ちゃんと完了させていく癖をつける。Waitingフラグにしてもいいが、簡単にブロッカーを理由にチケットを止めない
- ブロッカーが発生した場合に、相談しやすい環境をマネージャーが整える
4-12. Closing Velocity
定義
チケットが完了するスピード
業務サイクルの該当箇所
4~13
計算式
A/B
- A=対象期間内に完了したチケットの数
- B=対象期間内の日数
- 例: 180回/90日=2回/日=14回/週
- 注意事項: 暗算しやすい数字にするために、土日や営業時間外も含めて計算している。含めたくない場合は除外してください
ソース
- GitHub Issues、GitLab Issues、BitBucket Issues
- Jira、Trello、Asana、Monday.com、ServiceNow、ClickUp、Wrike等
数字の見方
毎朝・毎夜TODOを整理することを考えると、その日にやること、明日やることを1つの塊として認識する方は多いですよね。
その考えだと、絶対値として1日1チケット以上、もしくは1週間で5チケット以上が望ましいかもしれません。1週間で1チケットだと進捗が分かりにくいためです。
- 対象期間の数字もしくは改善幅を、同リポジトリの他チームや、他リポジトリと比較する
- 対象期間の数字を、自チーム内の前期までの推移と比較する
改善アクション
4-10. Number of Closed Tasksと同様
- 完了条件を明確にする。明確でないから閉じられなくなって、ゴミになったチケットをよく見ます
- 見られている、という意識をチームメンバーに持たせることで、ちゃんと完了にするようになる
- 1つずつ、ちゃんと完了させていく癖をつける。Waitingフラグにしてもいいが、簡単にブロッカーを理由にチケットを止めない
- ブロッカーが発生した場合に、相談しやすい環境をマネージャーが整える
4-13. Estimated Completion Date
定義
未完了のチケットがすべて完了する見込み日
業務サイクルの該当箇所
4
計算式
today()+A/B
- today(): 本日の日付
- A: 本日時点の未完了のチケット数
- B: 対象期間のチケット完了スピード ※土日も含めたスピード
ソース
- GitHub Issues、GitLab Issues、BitBucket Issues
- Jira、Trello、Asana、Monday.com、ServiceNow、ClickUp、Wrike等
数字の見方
今チームや組織に溜まっているタスクがいつ完了する見込みか、が一発でわかります。これをぱっと言えない状態は多いのではないでしょうか?
- 単純に遠いと感じた場合(例:1年後など)
- Aの量が多い可能性
- Bのスピードが遅い可能性
- Aの量は適切ならば、Bのスピードを早める工夫が必要。Bの改善策を参照
- 根本的なBの消化スピードを早めるために、メンバーを増やすべきタイミングかもしれない
- 推移でみて、だんだん遠くなっている場合
- タスクの溜まるスピードAと、タスクを消化するスピードBが釣り合ってない
改善アクション
4-10. Number of Closed Tasksと同様
- 大分前に作成されたがもう不要な未完了チケット等、を整理して再度確認
- そもそも、未完了チケットを「Won't Do」に自動的にするルールを策定
- Aを優先度で仕訳し、優先度=高のみで集計し、再度確認
- そもそも完了条件を明確にする。明確でないから閉じられなくなって、ゴミになったチケットをよく見る
- そして、「見られている」という意識をチームメンバーに持たせることで、ちゃんと完了にするようになる
- また、1つずつ、ちゃんと完了させていく癖をつける。Waitingフラグにしてもいいが、簡単にブロッカーを理由にチケットを止めない
- ブロッカーが発生した場合に、相談しやすい環境をマネージャーが整える
- メンバーが戦力になるのに時間がかかっているならば、オンボーディングプロセスを再考する時期かもしれない
- やれることをやりつつ、そもそもメンバーを増やす
4-14. Number of Times You Have Been Mentioned
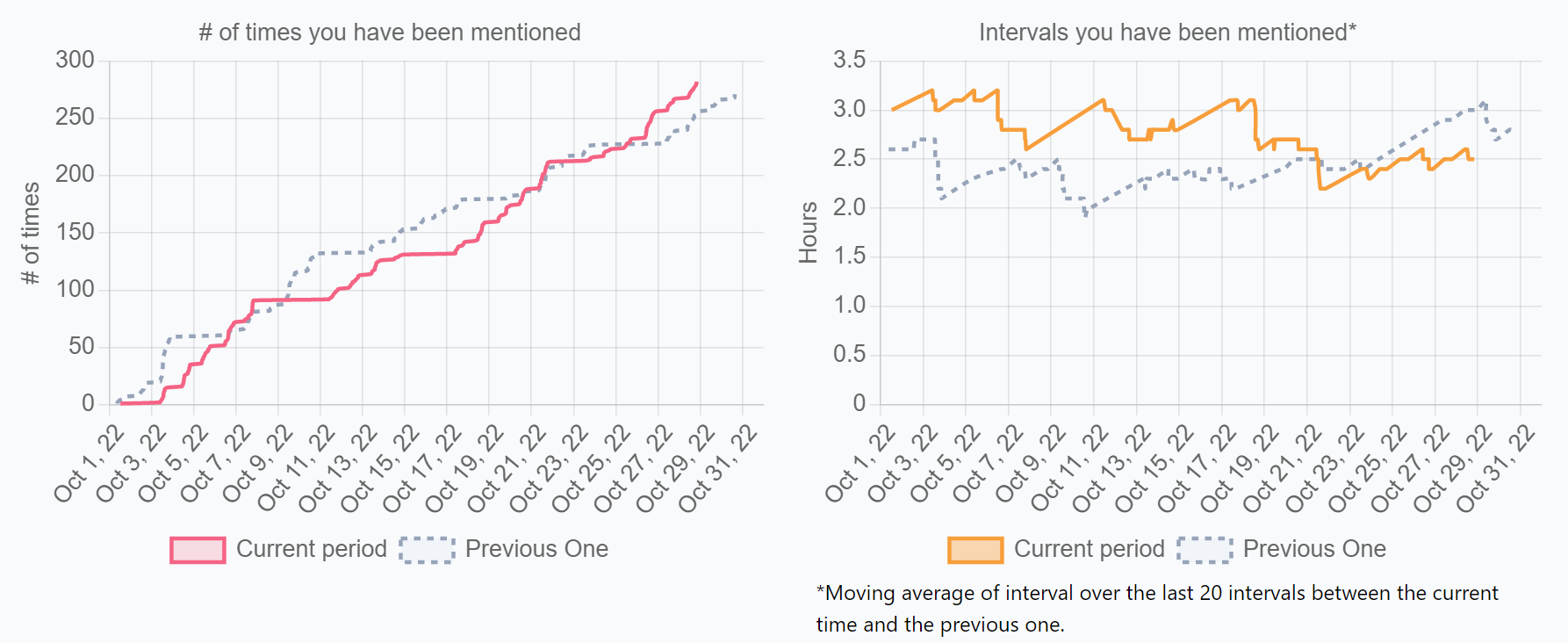
定義
自分がメンションされた回数
計算式
対象期間内に、自分がメンションされた回数
- API例: https://slack.com/api/search.messages
- クエリ例:
- ${memberId}+after:${since}+before:${until}
- U02DK80DN9H+after:2022-01-01+before:2022-10-24
ソース
Slack、Microsoft Teams、Discord、Chatwork等
数字の見方
次項に記載
改善アクション
次項に記載
4-15. Intervals You Have Been Mentioned
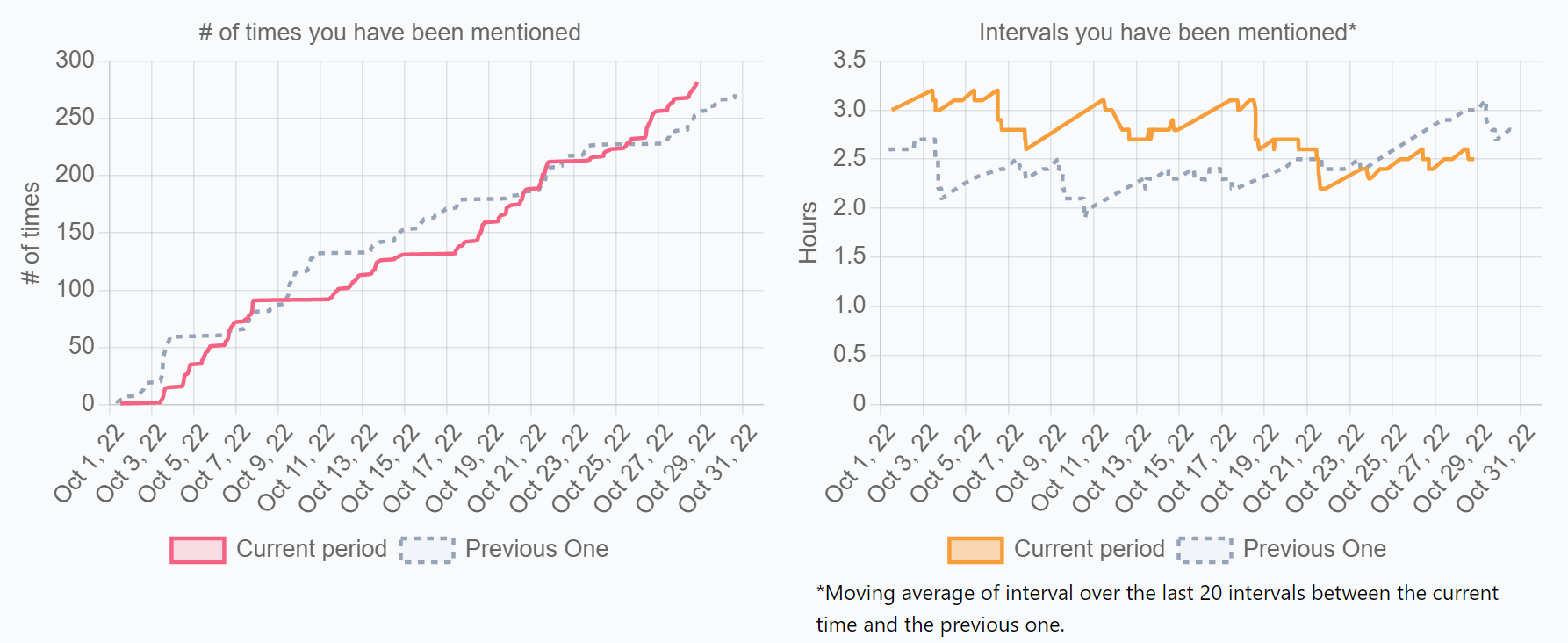
定義
自分がメンションされた間隔
計算式
Σ(A-B)/C
- A=対象期間内に、自分がメンションされた時刻
- B=Aの前に自分がメンションされた時刻
- C=対象期間内に、自分がメンションされた回数
ソース
Slack、Microsoft Teams、Discord、Chatwork等
数字の見方
チーム内メンバーや他チームから用がある、求められている、頼られているかの参考指標。また、その人へのコミュニケーション上の負荷としても捉えられます。
- 対象期間の数字を、他メンバーと比較する
- マネージャー以上の場合
- マネージャー間で比較し、チームの大きさを考慮して、数字が相対的に大きい場合
- マネージャーに対する心理的安全性が高く、メンバーの業務に対する好奇心も高いかもしれない
- 一方で、高いから良いとは言えない。質問や報告が集中し、負荷が高い状態かもしれず、間に更にマネージャーを立てるべき時期かもしれない
- マネージャー間で比較し、チームの大きさを考慮して、数字が相対的に小さい場合
- マネージャーに対する心理的安全性が低く、メンバーの業務に対する好奇心も低いかもしれない
- 一方で、低いから悪いとは言えない。過度な報告がなく、メンバーが伸び伸びと業務出来ている可能性もある。他のマネージャーの負荷が大きすぎるだけで、このマネージャーの負荷は適切かもしれない
- マネージャー間で比較し、チームの大きさを考慮して、数字が相対的に大きい場合
- プレイヤーの場合
- プレイヤー間で比較し、数字が相対的に大きい場合
- 露出が高いのは悪いことではないが、作業に支障が出ている場合、負荷を下げる必要があるかもしれない
- プレイヤー間で比較し、数字が相対的に小さい場合
- 露出が低いのは必ずしも良いことではないが、作業に集中できている状態かもしれない
- プレイヤー間で比較し、数字が相対的に大きい場合
- マネージャー以上の場合
- 対象期間の数字を、自チーム内の前期までの推移と比較する
改善アクション
- 増やしたい場合
- 他のメンバーに自分がどういう人か分かってもらうために、自ら発信を増やす
- 他の人の発信にコメントやリアクションをする
- 減らしたい場合
- 参加してるチャンネルから離脱する
- チームメンバーに権限移譲する
- チームメンバーとの間にマネージャーを挟む(必ずしも悪いことではない)
4-16. Number of Times You Have Replied
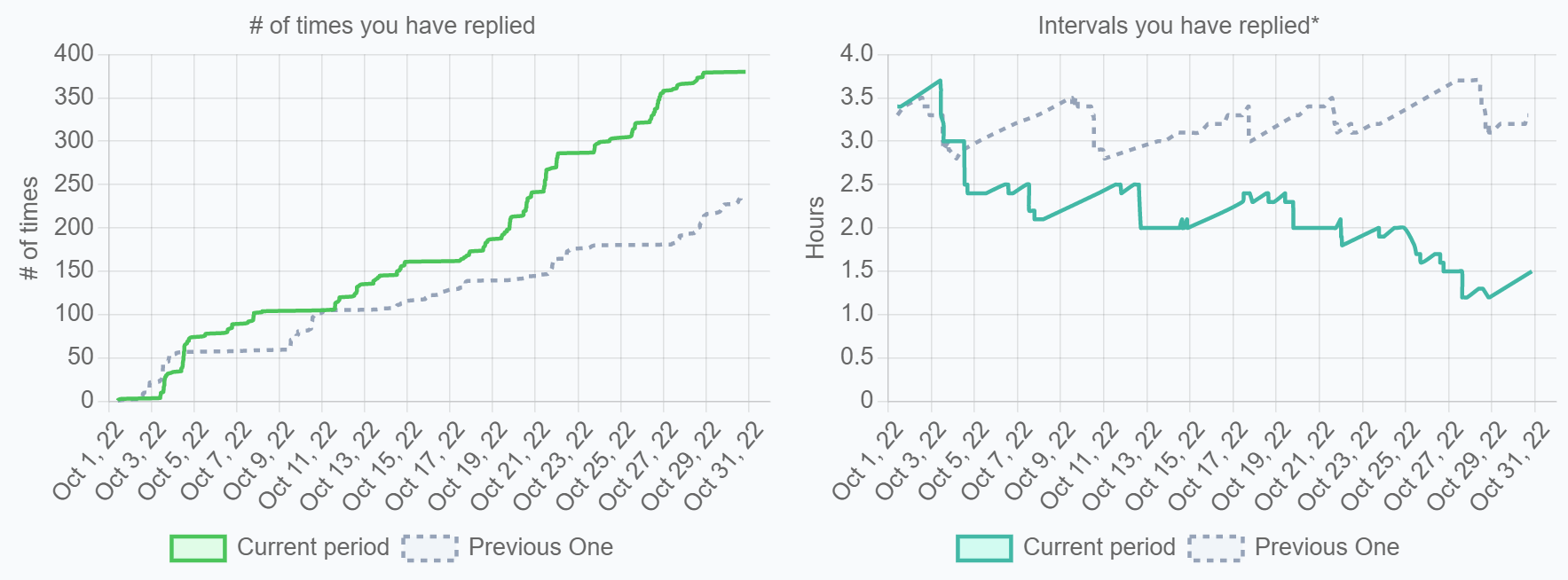
定義
スレッドに返信した回数
計算式
対象期間内に、スレッドに返信した回数
- Slack: from:@${memberId}+after:${since}+before:${until}+is:thread
- API例: https://slack.com/api/search.messages
- クエリ例: from:@U02DK80DN9H+after:2022-01-01+before:2022-10-24+is:thread
ソース
Slack、Microsoft Teams、Discord、Chatwork等
数字の見方
次項に記載
改善アクション
次項に記載
4-16. Intervals You Have Replied
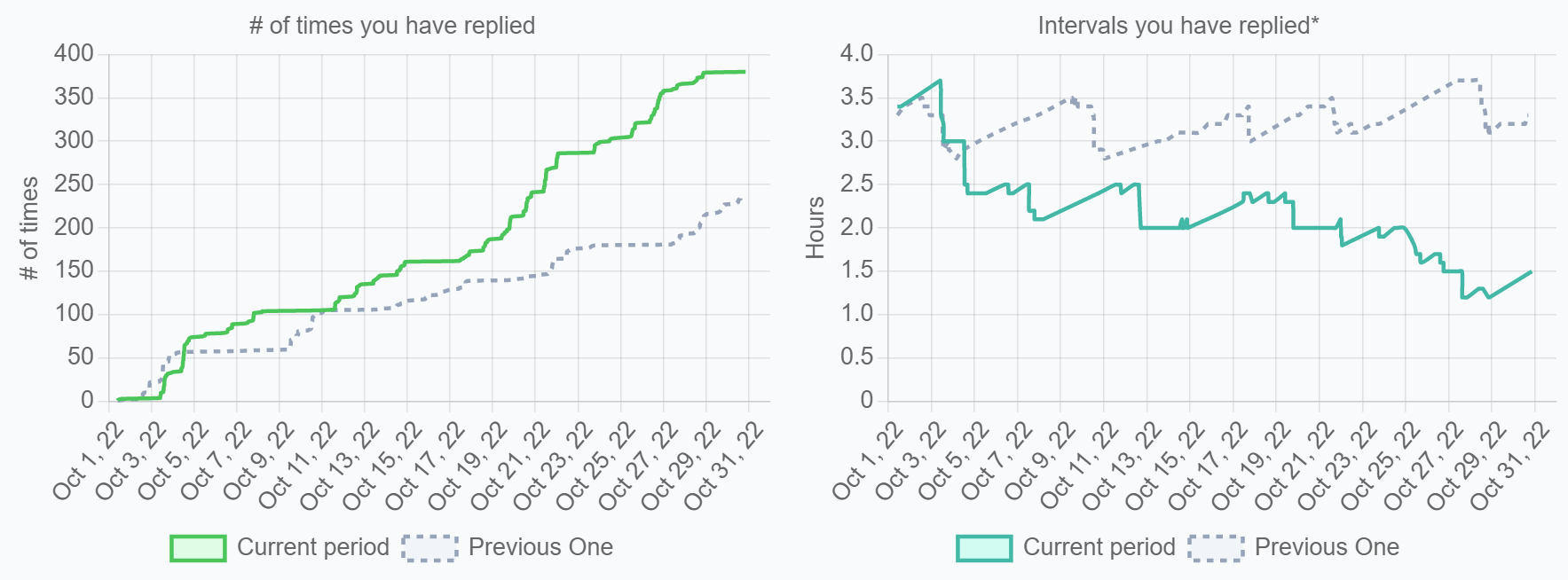
定義
自分がスレッドに返信した間隔
計算式
Σ(A-B)/C
- A=対象期間内に、自分がスレッドに返信した時刻
- B=Aの前に自分がスレッドに返信した時刻
- C=対象期間内に、自分がスレッドに返信した回数
ソース
Slack、Microsoft Teams、Discord、Chatwork等
数字の見方
あなたがどれだけチーム内メンバーやチーム外に情報をギブしたか、フィードバックしたか、協力したか、の参考指標です。また、その人のコミュニケーション上の負荷としても捉えられます。
4-17. Number of Times You Have Sent New Posts
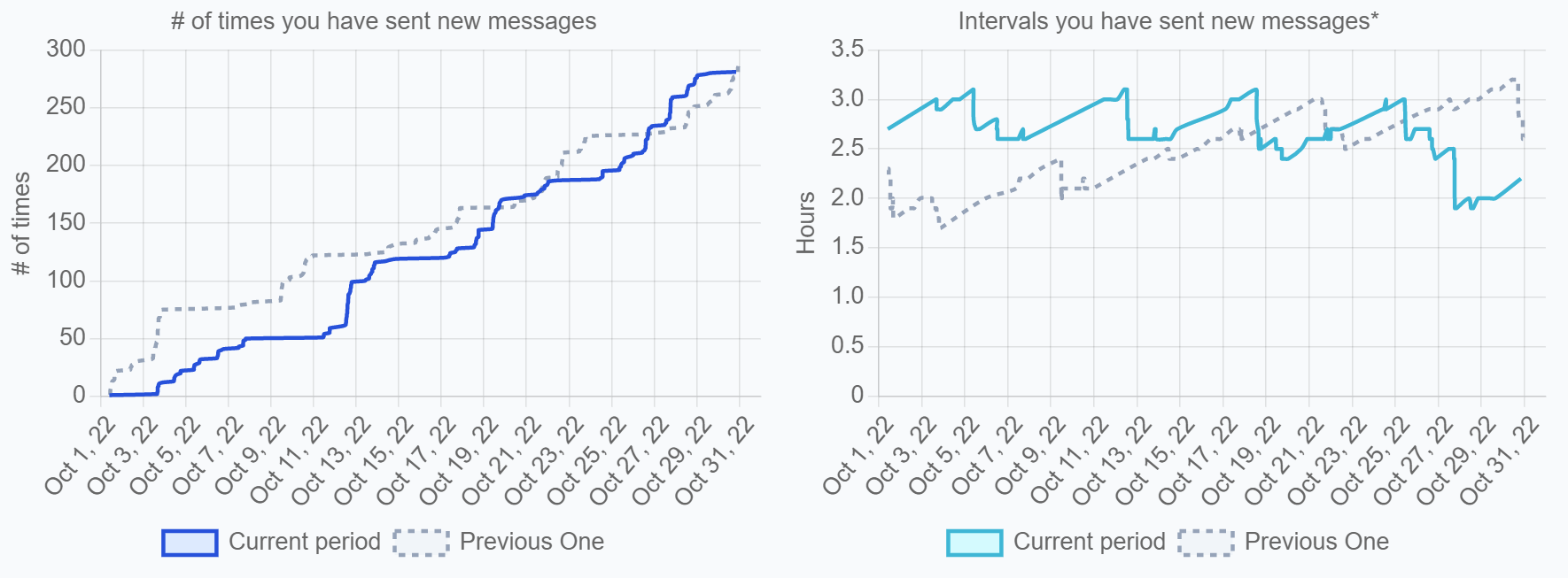
定義
新規にメッセージを投稿した回数
計算式
対象期間内に、新規にメッセージを投稿した回数
- Slack API例: https://slack.com/api/search.messages
- クエリ例
- from:@${memberId}+after:${since}+before:${until}+**-**is:thread
※4-15との違いは、is:threadの前に「-」が入っている点です - from:@U02DK80DN9H+after:2022-01-01+before:2022-10-24+**-**is:thread
- from:@${memberId}+after:${since}+before:${until}+**-**is:thread
ソース
Slack、Microsoft Teams、Discord、Chatwork等
数字の見方
次項に記載
改善アクション
次項に記載
4-18. Intervals You Have Sent New Posts

定義
自分が新規にメッセージを投稿した間隔
計算式
Σ(A-B)/C
- A=対象期間内に、自分が新規にメッセージを投稿した時刻
- B=Aの前に自分が新規にメッセージを投稿した時刻
- C=対象期間内に、自分が新規にメッセージを投稿した回数
ソース
Slack、Microsoft Teams、Discord、Chatwork等
数字の見方
どれだけ自発的にメッセージを投稿したか、情報をギブしたか、または誰かに質問したか、などを表す参考指標
- 対象期間の数字を、他メンバーと比較する
- 自分の発信量は、まず自分的には足りていると思うのか考える
- その上で、自分より発信していると思う人と比べる
- 具体的にどのくらいの差があるのか知る
- 発信する上で、どういうことを意識しているのか聞く
- 対象期間の数字を、自分の前期までの推移と比較する
改善アクション
- 自分が意味がないと思ってる情報は、相手にとって意味があるかもしれない、ということを話し合ってみる
- 今、何か調べ物をして、何か学んだとしたら、それをまだ知らない、知る必要を感じながらも調べていない人というのはいるはず。それを共有する
- 1つ作業したら1つ発信する。何をしているのか、ということも周りにとっては情報になる
- Twitterのような感覚で、まさにつぶやくような感覚で、投稿してみる
- 単にニュースを見たら、それに特にコメントつけずに、気楽に共有する
- 投稿しやすいチャンネルを作る
4-19. Number of Meetings
定義
会議の数
計算式
対象期間の会議の数
- 条件: 参加者が2人以上
ソース
Google Calendar、Microsoft Outlook
数字の見方
次項に記載
改善アクション
次項に記載
4-20. Meeting Occupancy Ratio
定義
営業時間内における会議比率
計算式
A/B
- A=対象期間内におけるトータル会議時間(h)
- 条件: 参加者が2人以上
- B=対象期間内におけるトータル営業時間(h)
- 注意事項: 会議が伸びたり早く終わった場合、実態に合わせてカレンダーを変更した方がよりリアルに集計できる
ソース
Google Calendar、Microsoft Outlook
数字の見方
比率に正解はありません。
ただ、会議に時間をとられて作業に集中できなかった、というのはよく聞く話です。
特に自分に役割のない会議、聞くだけの会議、そもそも内職をしていて聞いてもない会議等、無駄が生まれやすいのも聞き覚えがあると思います。それを見直すための、継続的な参考指標として使うイメージです。
- 対象期間の数字を、他メンバーと比較する
- チーム: 比率なので、マネージャーとプレイヤーの比率に影響されるが、チーム間でもある程度比較可能。
- 個人: 成果を出してると言われてる人の使い方と比較する
- 対象期間の数字を、自分の前期までの推移と比較する
- 気づかぬうちに、じわじわと、上がっていくもの
- 常に不要な会議の見直しのきっかけにする
改善アクション
- 不要な会議を減らす
- 聞くだけで発言しない会議は出席をやめるか、積極的に発言するか、どちらかにする
- 自分が内職してる場合は、基本的に不参加にする
- 定例化しているが、特にアジェンダのなくなってきた会議は廃止を提案する
- 参加者が増えれば増えるほど、基本的にはあまり参加しない人が増える。むやみにそういう会議を増やさない
- 1on1やコミュニケーションをとるための時間は、大事なので、出来るだけ削らない
- 必要な会議でも、1回の会議時間を短くする
- 何をする会議か、アジェンダを決めて、カレンダーに貼っておく
- 資料があるならば、事前に資料をリンクで配る。ぎりぎりまで作業したいという気持ちは捨てて、最低でも前日時点で途中でも一度配る
- 事前に配られた資料を読む、コメントしておく
5. 共通して気を付けること
5-1. 数字を過度に追いかけすぎない(Goodhart’s Law)
“When a measure becomes a target, it ceases to be a good measure.”
指標の話をすると、よく引き合いに出されるフレーズ。元は、イギリスの経済学者Charles Goodhartによって、1975年のイギリスの金融政策の中で使われたフレーズ。その後、1996年に、Keith Hoskinsによって出版された本で、更に一般化されて使用されました
Open AIも言っていますが、本当に追うべき指標はアウトカムであり、それはお客様がどれだけ喜んだかであり、もっと複雑で測定が困難なものです。ゆえに、その代替指標として上記の様々な簡易でコストの低い指標を用いています。したがって、あまり最適化し過ぎないように注意する必要があります
- 出所1: Goodhart's law | Wikipedia
- 出所2: Measuring Goodhart’s Law (5 mins to read) | April 13, 2022 | Open AI
5-2. 数字を鵜呑みにしてはいけない
数字には往々にしてノイズが含まれるものです。だから数字を鵜呑みにしてはいけません。
例えば、先月のDORA Metricsのデプロイ頻度が高かったとしても、喜ぶのは早いわけです。それは例えば
- 単に細かいリリースが続いただけかもしれない(悪いことではない)
- バックログの中から簡単なものばかり選んだかもしれない(これは中身次第だが、恐らく良い傾向とは言えない)
- 自動テストを書いてね、と指示しているにも関わらず、自動テストをちゃんと書かずに、マニュアルテストで済ませたからかもしれない
- 更に悪いことに、テストシナリオを十分に考えずに、適当に済ませたからかもしれない。なんなら、そもそもテストしなかったかもしれない(信じられないかもしれませんが、過度に急がせると普通に起きうります)
などが思いつくからです。
逆に先月のデプロイ頻度が低かったとしても、落ち込むのも早いわけです。それは例えば
- チームが、少し大きめのリリースを控えているからかもしれない
- 今まで自動テストをしてなかったが、先月から自動テストをし始めたので、一時的にスピードが落ちてるのかもしれない
- 新メンバーの加入で、エースのリソースをオンボーディングに意図的に割いたので、スピードが落ちたのかもしれない
- コードが負債にならないように、チェック項目を増やしたことで、慣れないメンバーの手戻りが増えてるだけかもしれない
などがありえるからです。
これらに騙されたり、惑わされたりしないためには、数字の読み方について、オープンにして、ちゃんと議論することでしょう。より正確に見るためには、単月だけではなく推移で傾向も見るべきですし、当然、その中身も知る必要があります。
5-3. 全ての数字を一度に追いかけない(特定の数字にフォーカスする)
指標の種類は多岐にわたります。それはチームや組織の様々なフェーズや課題に応じて、見るべき指標が異なるからです。
しかし、ある期間において、追いかける指標は少なくてシンプルである方がいいかもしれません。暗記して数字を言えるくらい絞っておく方が、チームや組織の意識の浸透もしやすいでしょう。
その種類の数はチーム内でよく議論した方がいいですが、例えば月ごとに2~3個、出来れば目標は1つに絞れるとよいかもしれません。二兎を追う者は一兎をも得ず、と言いますからね。
- 出所1: ”Key Business Metrics”, Fred Wilson, Partner at Union Square Venture in New York City
- 出所2: ビジネス指標は少ないほど効果が高く、強い企業文化をつくる
6. 最後に
ここまで読んで頂き、ありがとうございました。
もし、ご意見やご感想がありましたら、ぜひコメント欄や、TwitterのDM(Twitter)やメールアドレス(hnishio0105@gmail.com)までお気軽にフィードバック下さい。
また、こうした具体的な指標を簡単に計測できるツール「WorkStats」を開発・運営しています。よければ実際に試してみて下さい。きっと新しい発見があるはずです。
これが機に、数字を知り、課題を特定し、改善するアクションをし、また数字を見る、そういったPDCAを考えるきっけけになればと思います。