概要
生成AIの中で、テキストや画像・動画の生成に比べやや地味な印象のある音楽生成AIをとりあげ、次の内容をまとめてみた。
・基本構造、提供機能
・使われている技術
・活用事例
・顕在課題
・将来展望、感想
本題に入る前に、様々な生成AIの中での音楽生成AIの位置付けを俯瞰してみる。
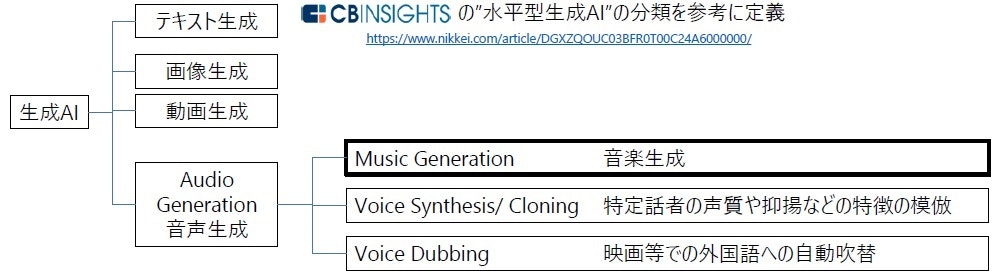
モチベーション
音楽に関し、聴く以外ももともと熱心な趣味や興味対象にしていた背景がある。
1.バンド演奏:キーボード担当(20年以上、洋楽カバー等、24年7~8月にもライブ3回予定)
2.作曲(数年、主に学生の頃)
3.音楽に関するデータ分析への興味
1)しゃれた響きの可視化に興味…そこから様々な和音、音階等の構成音を会得
2)“誰々風”の曲等、似た雰囲気の曲をそう印象づける共通要素の可視化に興味…例えば次の内容を想定
①ド・レ・ミ等の音の出現確率分布
②ある音から次の音への遷移確率分布
③CM7・Dm7・G7等のコードの出現確率
④あるコードから次のコードへの遷移確率分布
※この辺に同じ興味をお持ちの方、ぜひ情報・意見交換しましょう!
音楽生成AIの基本構造
ChatGPT、Stable Diffusion等で文章や画像を生成するのと同様、感覚的な指示のテキスト入力だけで、指示に沿った歌詞・ボーカル付、バック演奏付の2、3分程度の曲が、瞬時に再生されるような無料サービスが、優に10社以上登場している。
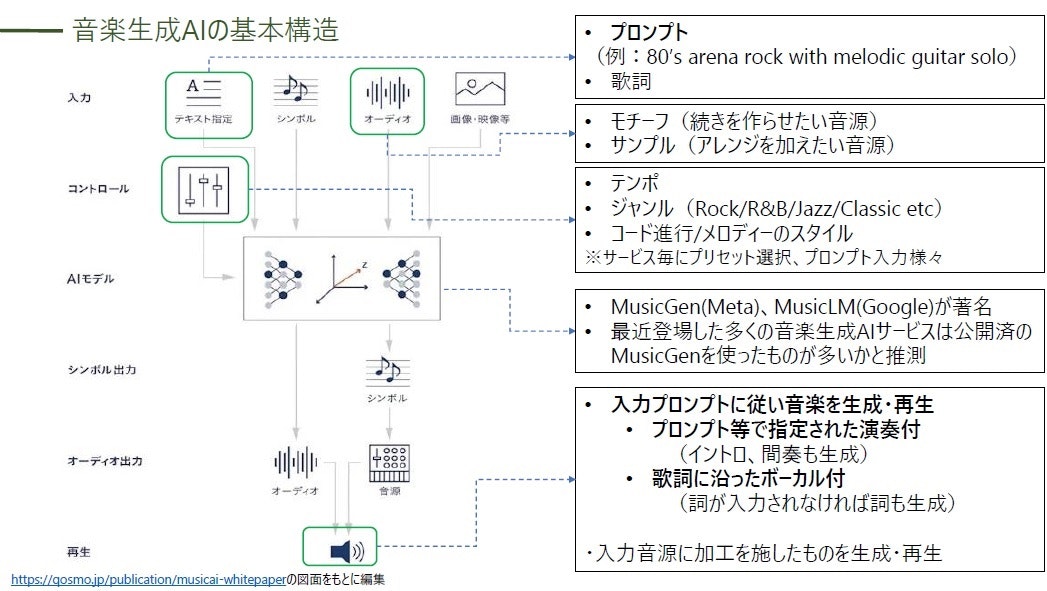
「音楽生成AI」というワードで検索するだけで「音楽生成おすすめソフト10選!」的な記事は多数見つかるので、その種の情報はここでは触れない。実際に自分が使ったサービスを1つだけ以下記載。
音楽生成AIの例:Suno (https://suno.com/)
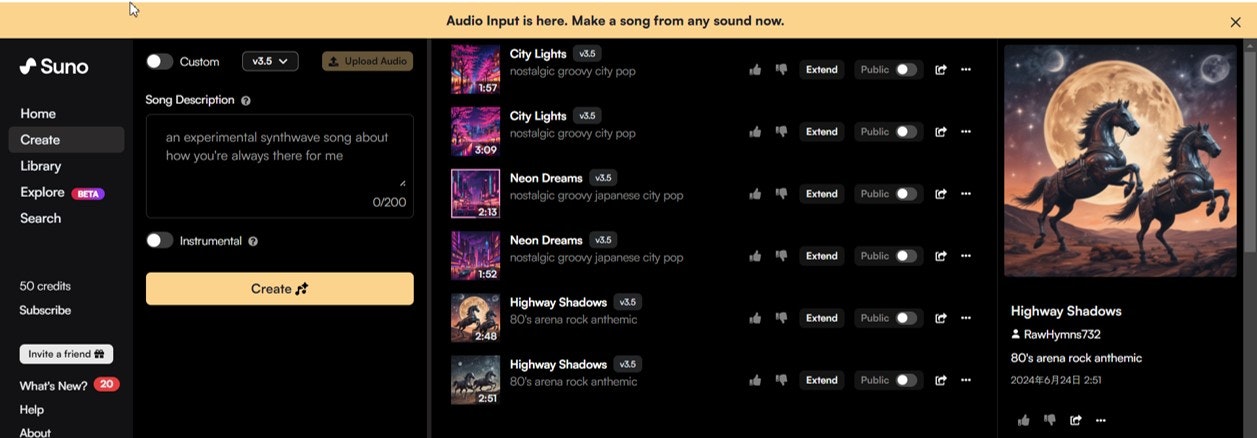
このサービスで、"80’s arena rock with melodic guitar solo"というプロンプトを入力しただけで、イメージどおり、産業ロックと当時揶揄されたジャーニー等を彷彿とさせる曲が、歌詞も含め瞬時に生成された。
同様に"Japanese City Pop in late 70's"というプロンプトに対しても、いかにもデジタル音源という感じの楽器の音色を除けば、ある程度意図が汲まれた曲が生成された。生成された歌詞は英語でしたが、歌詞に"Tokyo skies..."という一節が登場。(日本語詞の生成をプロンプト以外で明確に指定する設定も別途存在。)
※Qiita上での音声ファイル共有の術を存じませんが、もし共有する術があれば後日アップロードします。
Sunoは23年5月に登場したが、その後、Stable Audio (23/9~)、Udio (24/4~)等が登場し、相次いで次のような点でのVer Upを重ね、サービス機能強化を競っている印象。
・生成可能な曲の長さの拡張
・保存できる音源の音質向上(wav 16bit, 48KHz等)
・未完成曲拡張機能の追加
補足:音楽生成AIで扱われるデータサイズ
大抵2、3分、ないしそれ以上の長さになる音楽のデータ量は、動画ほどではないものの、静止画よりは遥かに大きく、学習にも生成にもそれ相応の負荷がかかり、そのため、データ量と直結する長さや音質については、ユーザニーズ等を見据えながら徐々に拡張しているものと思われる。
■前提:CD並の音質(fs=44.1KHz、16bit、ステレオ、非圧縮)の4分の曲
→再生1秒あたり:44,100Hz × 16bit × 2ch / 8 =176.4KB(= ビットレート1,411kbps)
→1曲あたり:176.4KB × 4分 × 60秒 = 42.3MB(下記の画像15枚分に相当)
・画像の場合 前提:HD、24bit full color
→1280pix × 720pix × 24bit / 8 =2.76MB
音楽生成モデルの概要
MusicLM
2023年5月、Google I/Oにて発表
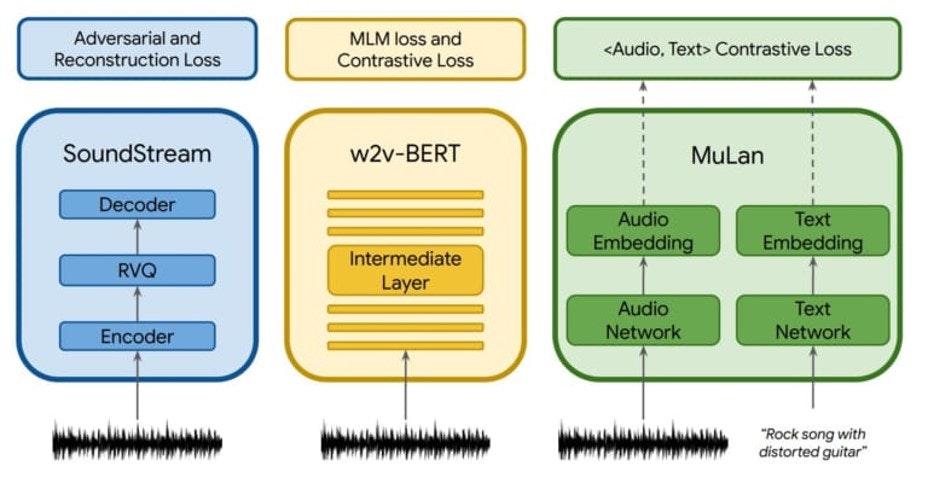
1)SoundStream:圧縮データを元に音楽を復元し、MuLanからの指示に基づいて新しい音楽を生成
・音楽データを効率的に圧縮し、大量の音楽データを学習し、音楽のパターンや構造を理解
・新しい音楽を生成する際、圧縮データをもとに音楽を復元し、新しいメロディやビートを作成
2)w2v-BERT:入力テキストを解析し、人の意図する音楽スタイルや感情を理解
・入力テキストで意図された音楽の生成を準備
- w2v:Word2Vec(単語の意味をベクトル化)
- BERT:文脈を理解するGoogleの言語モデル
3)MuLan:テキストに対応する音楽の特徴を抽出
・テキストと対応する音楽データをペアに学習
・学習で得たテキストと音楽データの関係を参照し、その特徴を元に新しい音楽を生成
MusicGen
2023年6月、オープンソースとして発表、
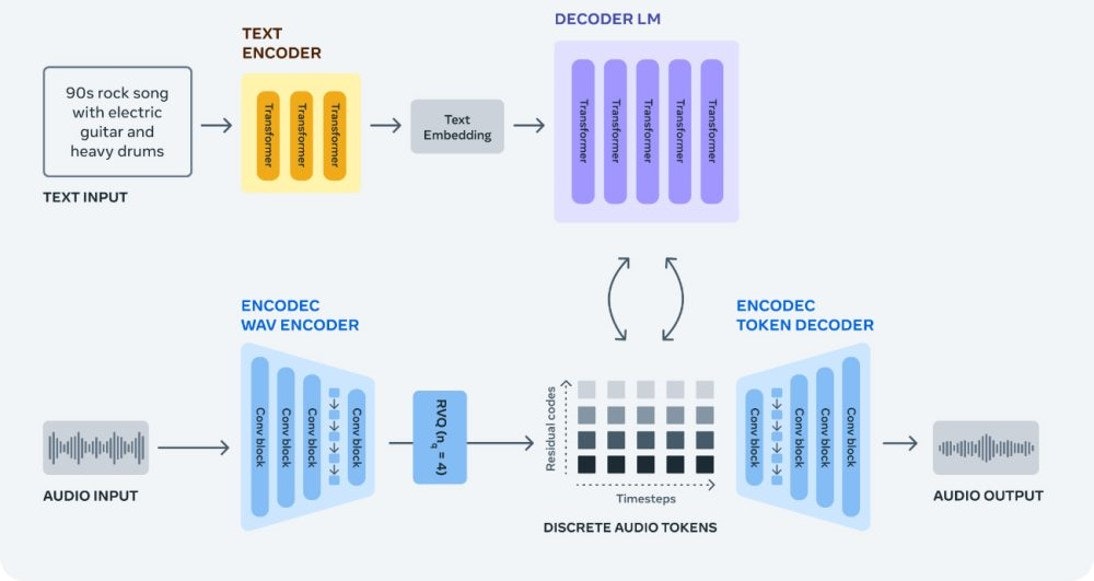
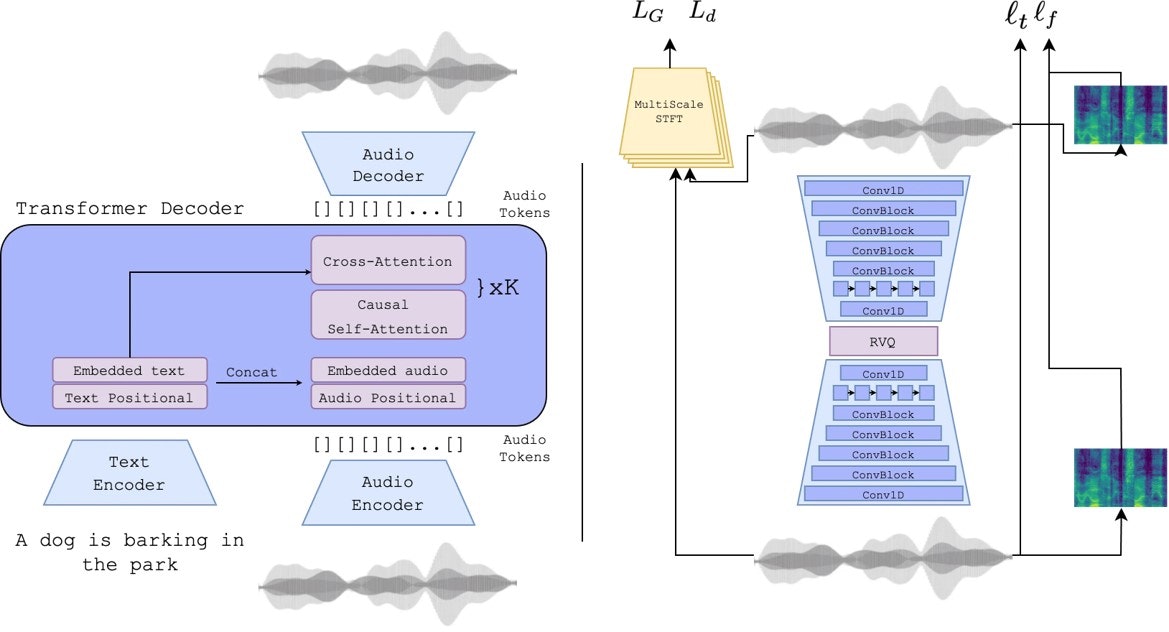
・Encodec部は、SoundStreamとほぼ同じ構造の様子。(オートエンコーダー構造、RVQ量子化、GANによる高品質化)
・それ以外の部分は、MusicLMではw2v-BERTとMuLanで分担してるのをTransformer Decoderだけでまかなっている?
・オープンソースになっていることで、前述したようなサービスいくつかで活用されていると思われる。
活用分野の例
以下を全て満たすような場面で活用事例が増えている印象
①作曲に要する時間や労力の抜本的な削減が望まれる
②作曲者の知名度やキャラは不要
③但しある程度の独創性は必要
1.BGM等の商業音楽の作成
“拘り”にマッチした曲調のオリジナル曲を安価に著作権フリーで制作
次の記事はホテルのBGMの例(他、ゲーム、映画、ChatBot、Web広告等のBGMにも広がりつつある様子)

2.教育場面での学習ツール
歌や楽器が苦手な子でも音楽の授業を楽しめる:速さ、コード進行、メロディースタイル等を選択し歌詞を入力すると、メロディを生成し歌付で再生

3.作曲支援ツール
具体例の記事等は未確認だが、プロ・アマ問わずニーズはありそう
・上記1のような案件を著名なプロのミュージシャンや作曲家が受けた場合も、クライアントの感覚的な依頼に基づく短期間での大量候補曲の準備や手直し等には相当重宝しそう
顕在課題
テキストや画像・動画の生成AIと同様、権利侵害、フェイク流通、既存従事者の存在を脅かすような課題が散見され、Universal Music Group、Sony Music Entertainment等の大手レーベルが動くような例も見られる。以下、主に米国での事例をまとめた。
| 年月 | 事例 |
|---|---|
| 23/04 | 第三者がDrakeとWeekndの声をまねてAIで生成した曲が、2人のコラボ曲としてSpotifyで25万回以上、TikTokで1,000万回以上再生。2人の所属するUMGが未許可で権利侵害だと訴え、その曲は削除された。 |
| 23/05 | Spotifyが同社サービスから数万曲のAI生成曲を削除したことを公表。削除された楽曲は、ボット再生による再生数捏造が疑われたためだが、それ以外にもAI生成曲は1,400万曲以上存在。 |
| 24/01 | UMGとTikTok運営会社の間の楽曲利用のライセンス契約交渉が決裂。UMGは「TikTokはAI作成音源の蔓延を容認し、AI音楽制作ツールも開発し、アーティストの収入減を助長」と批判。→その後、5月に和解(未承認のAI生成曲のTikTokからの削除等を合意) |
| 24/04 | ミュージシャンの権利擁護団体「Artist Rights Alliance」が、人の芸術性の置換や公正な報酬の拒否に繋がる音楽生成AI技術の開発・導入の中止をテック企業などに要求。Jon Bon Jovi, Billie Eilishら200人以上が署名。 |
| 24/05 | SMEは、同社の楽曲などを許可なくAI学習に使わないよう、開発者に700通以上の警告を送ったことや、この1年間で2万件以上のAI楽曲の削除を要請したことを公表。 |
| 23/05 | 米国の一部のTikTokerが、好きなアーティストの架空のカバー曲をAI生成し公開しているとの報道。Ariana GrandeによるKill Bill/ SZAのカバー、 Justin BieberによるFlowers/ Miley Cyrusのカバー等。ファンには総じて好評で、@ai_coversという特集ページあり。Harry Stylesのあるカバー動画は150万回以上再生。(※現状、問題視はされていなさそう。) |
その他、次の方法で、既成の著名曲の雰囲気に限りなく似せた曲を容易に創作することも想定可能
■テキスト生成AIに、目的とする具体的なアーティスト名や曲名を示した上、そのような優れた曲を作るため、その音楽スタイルや歌詞のエッセンスをまとめるよう命令し、その出力結果をプロンプトとして音楽生成AIに入力(音楽の心得のある方なら、目標とする原曲のエッセンスの言語化は、生成AIに頼らずともある程度可能)
→模倣の疑いをかけられるような原曲に酷似したメロディーを含めることなく、大ヒット曲のエッセンスを凝縮した曲が生成され、オリジナルとして世に出せる可能性(これが、果たして間違った行為なのかは何ともいえないが...)
音楽生成AIの市場規模
Market Research Bizという調査会社が発表した数字によると、市場規模は下記のとおり($1=¥150で換算)
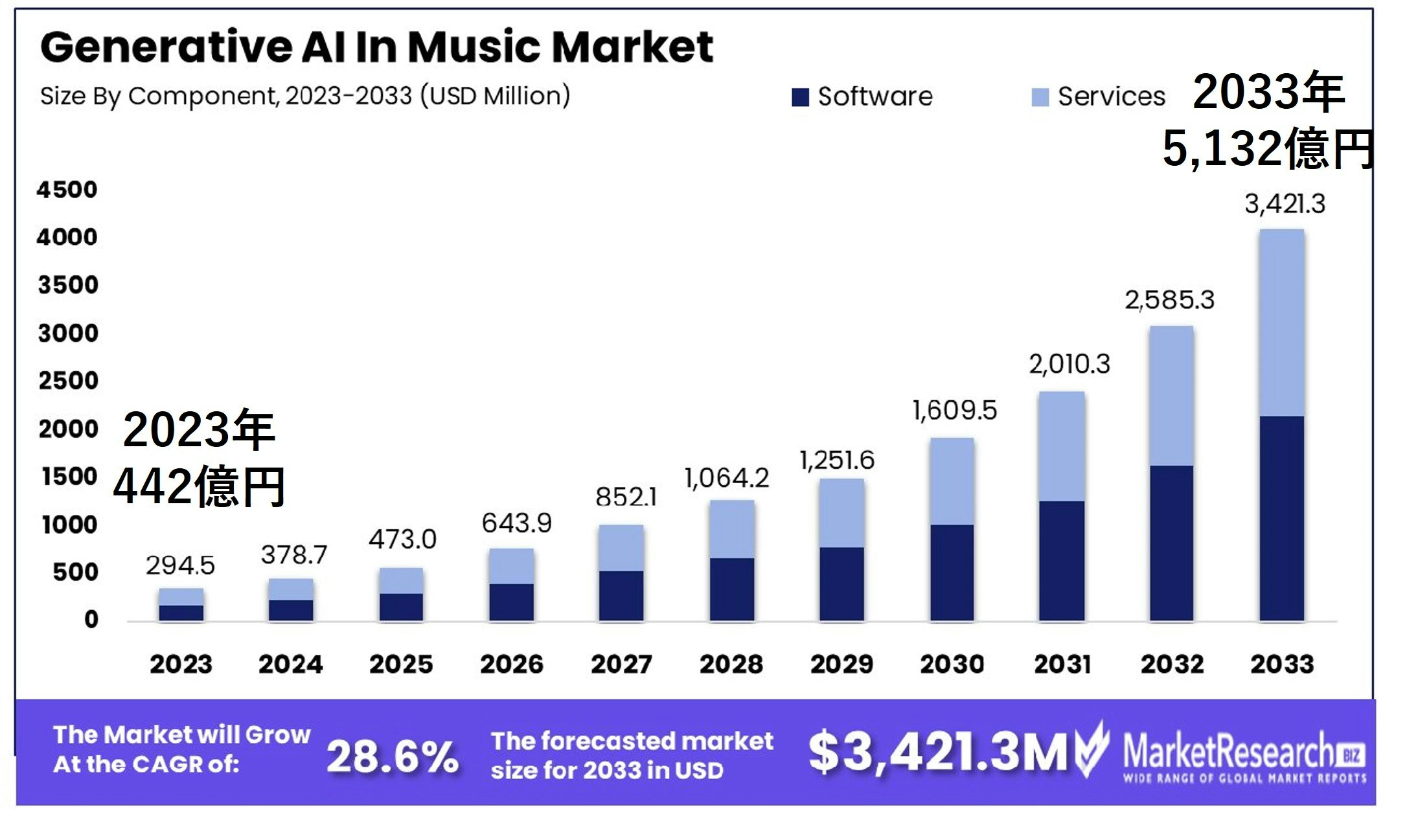
https://marketresearch.biz/report/generative-ai-in-music-market/
一方、ある音楽業界団体のレポートによると、音楽全体のグローバル市場規模は昨年時点で4兆円で、音楽生成AIの市場はまだその1%程度。10年で音楽生成AIの市場が10倍になると予想される中、音楽全体が10倍にまで伸びるとは考えにくく(ストリーミング隆盛により、かつての縮小傾向から反転拡大基調とはいえ)、音楽市場全体への影響は今より遥かに大きくなると予想される。
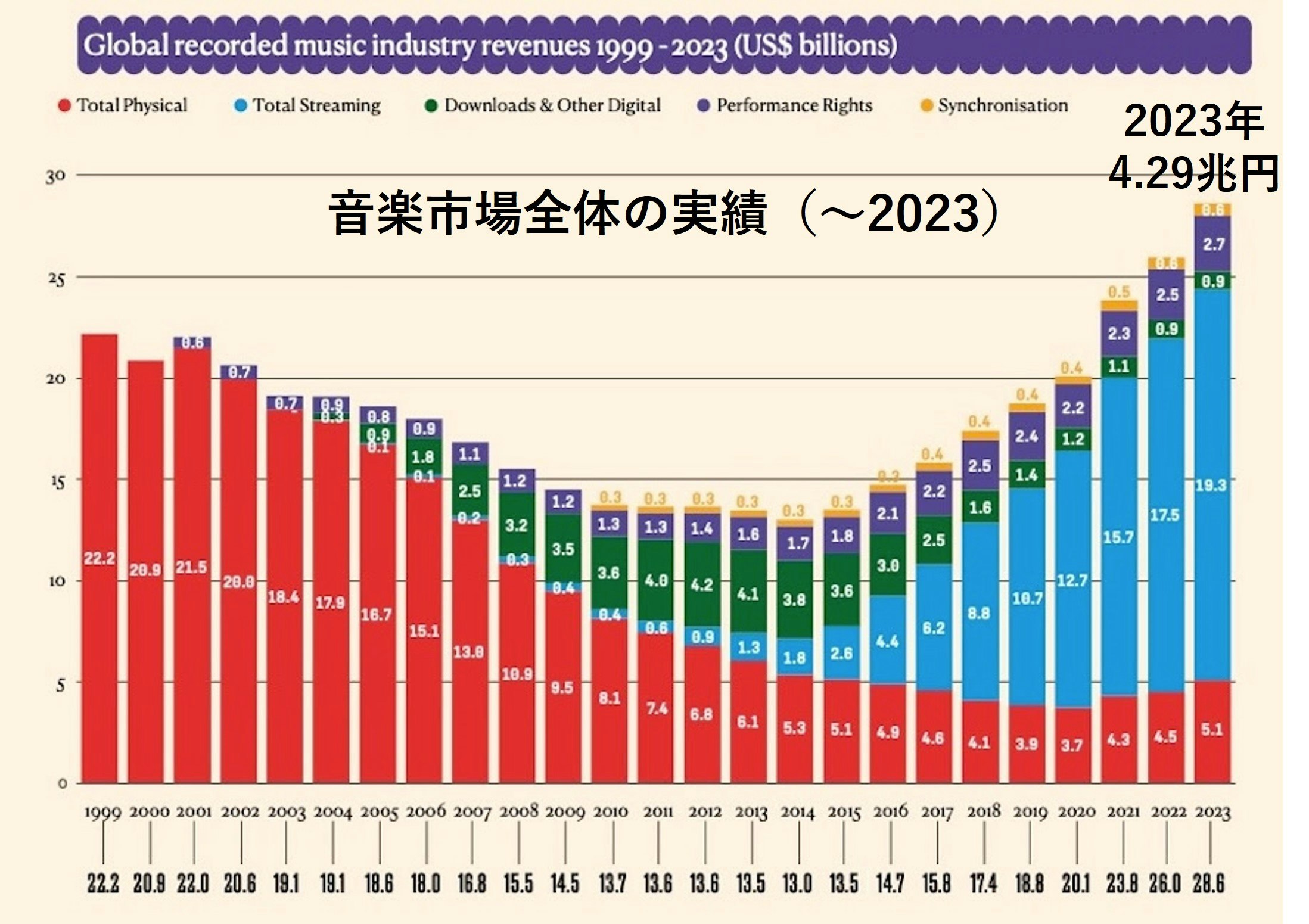
https://globalmusicreport.ifpi.org/
将来展望・個人的な感想 etc
ここまでの情報をふまえ、以下、思いつくまま妄想も含め書いてみた。
展望1.当該技術は、特定用途では極めて有効であり、さらなる普及が継続
「①時短・コスト圧縮の要求大、②知名度・キャラは不要、③独創性は必要」な商業音楽全般で重宝され続ける
展望2.著名アーティストの作品の模倣等の共存は、アーティスト側がある程度の妥協を余儀なくされる
今でも溢れかえる"歌ってみた/踊ってみた"コンテンツに加え、"作ってみた/カバーさせた/REMIXした/マッシュアップした"コンテンツ等も広がる
・楽曲は、そのような”使われてなんぼ”の商品や、販促ツールとしての側面が増し、アーティストの稼ぎの中心はライブやグッズに更にシフト
展望3.下記のような新サービスが登場する可能性も
①AI生成曲だけをかけ続けるFM局、有線チャンネル、ストリーミングプレイリスト
同じ曲は二度とかけず、それを聞きたい客には、かかった日時等で曲が特定されれば、オプション料金で提供
②パーソラナイゼーションを究めた音楽療法
特定個人への治癒効果の最大化を狙い、曲を生成AIで作り込み提供
感想1.音楽生成AIは、極めて"力技"的なアプローチでできていることを認識
・予想:コンパクトな譜面情報を処理し、メロディーやコードの出現/遷移確率を制御して作曲。バックの演奏にはルールベースも活用。
・実際:大量の楽曲の音声データを学習し、GANや拡散モデル等を駆使して生成
感想2.音楽生成AIの入力音源をモチーフとして続きを作らせる機能は、ぜひ試したい
・昔、途中まで作って挫折した曲の素材がいくつもあるため。但しその機能でいい曲が作れたとして、ほんとうに嬉しいかはなんとも言えないが...
感想3.音楽生成AIが作り手、聴き手各々にどこまで支持されるかは、用途や意味付け次第
・展望1で記載したような用途なら、作り手には大いに重宝。聴き手は誰が作ろうが気にしないので、その場にあった曲調でさえあれば、有効となりうる。
・一方、作り手が自己表現として作曲を行う際は、ほんとうに煮詰まった時の一助的な使い方を除き使われない気がする。
・聴き手も、アーティストに拘らず機能的な理由で聴く曲(例:単に心地よい、ジョギングのお供に適する)と、アーティストとセットで聴く曲は明確に分かれていくのでは。
以上