1 Introduction
2 The Single Shot Detector (SSD)
本章ではイヌとネコの検出を例に,SSDのフレームワークについてより具体的な説明がされます.
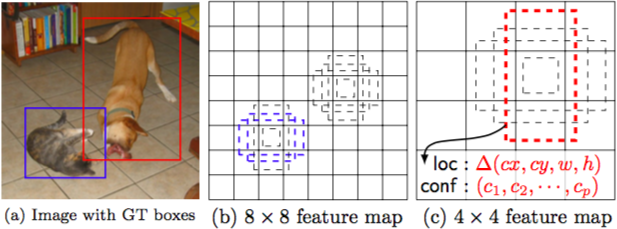
図1:SSDフレームワーク
-
SSDは,画像とその正解ボックス(ボックスの教師データ)についての情報を与えれば訓練がおこなえる.
-
畳み込みでは,縮尺の異なる特徴マップそれぞれのさまざまな箇所でデフォルトボックスの集合を評価する.図1では8×8および4×4の特徴マップを想定し,それぞれの特徴マップ上の各箇所で4組のデフォルトボックスの集合を評価している.
-
それぞれのデフォルトボックスについて,『カテゴリスコア』と『形状オフセット』を予測する.
-
訓練では,はじめに正解ボックスに対するデフォルトボックスの対応付けをおこなう.つまり図1のようにネコとイヌにそれぞれ別のデフォルトボックスを合わせた場合,(イヌまたはネコの正解ボックスに対して)一方のデフォルトボックスをポジティブとして扱うなら,もう一方はネガティブとして扱われる.
-
モデルの目的関数はデフォルトボックスの位置および形状についての誤差関数(localization loss)と物体カテゴリについての誤差関数(confidence loss)の重み項α付きの和で与えられる.
(model\,loss)=(localization\,loss)+α(confidence\,loss)
2.1 Model
SSDは畳み込みネットワークによって『バウンディングボックスの集合』と『カテゴリスコア』を算出し,最後にnon-maximum suppression stepを実行して検出結果を得る.SSDのネットワーク先端は,終端の全結合層を排除したVGG16を用いる(以降これをベースネットワークと呼称する).このベースネットワークに以下のような構造を加えることでSSDを構築する.
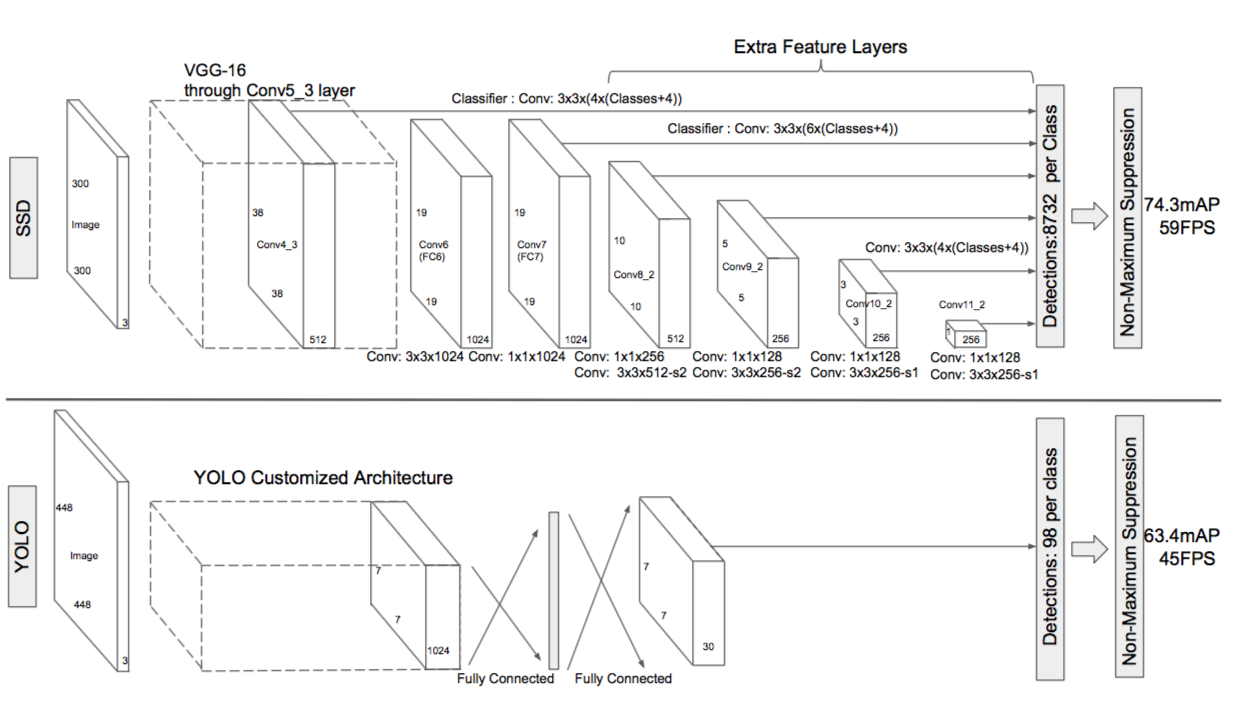
図2:SSDとYOLOの比較
- 複数の特徴マップ
- ベースネットワークに複数のレイヤを加える.これらの特徴レイヤにそれぞれ別の畳み込みモデルを適用することで,入力画像のサイズを徐々に縮小し,特徴の大小に関わらないマルチスケールな検出予測を可能にする.
- →OverfeatやYOLOの特徴マップはシングルスケール対応
- 複数の畳み込みフィルタ
- 図2で示されるように,サイズ3×3の畳み込みフィルタで各特徴レイヤを畳み込み,『カテゴリスコア』と『形状オフセット』を算出する.
- →YOLOではここで畳み込み層の代わりに全結合層を使用
- 複数のデフォルトボックス
- 各特徴マップの"ます目"にデフォルトボックスの集合を対応づける.
アスペクト比の異なるデフォルトボックスをk個設定したと仮定する.物体のカテゴリ数をcとすれば,デフォルトボックス中の物体が各カテゴリに属する信頼度を示す『カテゴリスコア』はc次元のパラメータを持ち,『形状オフセット』はボックスの位置座標,高さ,幅に関するオフセットで計4次元のパラメータを持つ.よって特徴マップの畳み込みには,k個あるデフォルトボックスの『カテゴリスコア』と『形状オフセット』のパラメータを算出するために,(c+4)k個の畳み込みフィルタが用いられる.そして畳み込みの結果,特徴マップの大きさをm×nとすれば,合計で(c+4)kmn個の出力値を得ることになる. - →デフォルトボックスそれ自体はFaster R-CNNで用いられるアンカーボックスに類似しているが,SSDではこれを解像度の異なる複数の特徴マップに適用している点で異なる.各特徴マップで形状の異なるデフォルトボックスの適用を許容することは,バウンディングボックスを効率的に離散化できることを意味している.
用語
- VGG16
- 13層の畳み込み層と3層の全結合層からなる標準的なCNN.
- 参考:Very Deep Convolutional Networks for Large-Scale Image Recognition
- non-maximum suppression step
- 物体の存在を示す領域候補が複数存在し,なおかつ重複している場合,ひとつの物体に複数の領域候補が与えられている可能性がある.ひとつの物体に対応する領域候補は少ないほうが良いので,領域候補を抑制(suppression)する以下のようなアルゴリズムが必要になる.
「ある領域候補の,それよりも得点の高い領域候補との重なり度合(IoU値)が,訓練によって設定されたしきい値を超えるなら,その領域候補を削除する.」(下記参考論文2.2. Test-time detectionより意訳) - 参考:Rich feature hierarchies for accurate object detection and semantic segmentation
2.2 Training
2.2ではSSDの訓練過程について説明があります.著者らはハイパーパラメータに具体的な数値を次々と設定していくのですが,それについて(2.2節においては)特に説明がないことが気になりました.
- デフォルトボックスと正解ボックスの対応付け
- 訓練過程では,どのデフォルトボックスが正解ボックスに対応するか決定し,適切にネットワークを訓練していく必要がある.SSDでは,しきい値(0.5とする)を超えるjaccard指数のデフォルトボックスと正解ボックスを対応付けることにする.しきい値を超えるものを対応付けすることで,正解ボックスに重複する複数のデフォルトボックスを対応付けすることができる.
- 目的関数
- SSDの目的関数は位置誤差関数(loc)とカテゴリ誤差関数(conf)の重み付き和であらわされる.
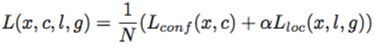
ただし$N$は正解ボックスに対応したデフォルトボックスの数であり,$N=0$のとき目的関数は0とする.位置誤差関数には正解ボックスと予測ボックスのパラメータの差分を変数にとるSmooth L1関数を,カテゴリ誤差関数にはsoftmax関数を用いる.なお重み項$α$は交差検証によるハイパーパラメータ探索で1に設定されている.
- デフォルトボックスの大きさ・アスペクト比の決定
- 画像中の大きさの異なる物体を探知するために,SSDでは大小の特徴マップを用いる.図1では,8×8および4×4の特徴マップをフレームワークで用いたことを示した.実際には小さな計算負荷でもっと多くの特徴マップを用いることができる.予測のためにm個の特徴マップを使用すると仮定する.それぞれの特徴マップに対応するデフォルトボックスの大きさは次のように計算される.
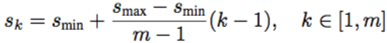
なお$s$$min$は0.2,$s$$max$は0.9であり,最小値0.2と最大値0.9の間ですべてのレイヤの大きさは規則的に離間している.デフォルトボックスには異なるアスペクト比$a_r=1,2,3,1/2,1/3$が適用される.これでそれぞれのボックスの幅($w_k^a=s_k\sqrt{a_r}$)および高さ($h_k^a=s_k/\sqrt{a_r}$)を計算でき,結果的に特徴マップの位置につき6種類のデフォルトボックスを設定することができる.
複数の特徴マップ上の複数のデフォルトボックスの予測を組み合わせることによって,さまざまな物体の大きさおよび形状を網羅する多様な予測が可能になる.例えば図1について,イヌの大きさは4×4の特徴マップに適合しているが,8×8の特徴マップ上のデフォルトボックスには適合せず,訓練中はネガティブと見なされている. - Hard negative mining
- デフォルトボックスを正解ボックスに対応付けしたあと,ネガティブなデフォルトボックスが多く発生する.カテゴリ誤差関数(conf)の高い順に並べて,ネガティブとポジティブの個数が3:1となるように上位のものを選択する.こうすることで安定した訓練をおこなうことができる.
- Data augmentation
- 縮尺および形状に対してよりロバストなモデルにするために,訓練画像をランダムに以下のオプションを選び,サンプリングする.
- サンプリングしない
- jacquard指数の最小値が0.1,0.3,0.5,0.7,0.9になるよう画像中の領域をサンプリング
- 画像中の領域をランダムにサンプリング
- サンプリングする領域の大きさは画像の0.1から1倍,アスペクト比は1/2から2倍とし,サンプリング領域内に正解ボックスの中心がある場合,正解ボックスが重複した部分はそのままにする.
用語
- jaccard係数
- 領域どうしの共通部分の面積を,ふたつの領域で囲む面積で割ったもので定義され,領域どうしの相関をあらわす.
- 引用:Wikipedia
- 参考:Jaccard index
