Learning Depth from Single Monocular Images(2005)
Abstract
わたしたちは単一の単眼カメラで撮影した一枚の画像から深度を推定する課題を検討する.わたしたちはこの課題に教師あり学習を採用し,(森や木,建造物を含む体系化されていない屋外環境の)単眼カメラによる画像とそれに対応する深度マップの訓練セットを集めることから始める.それから,画像を関数として,教師あり学習を深度マップの予測に適用する.深度推定は困難だがやりがいのある問題である.孤立した局所特徴では各点の深度推定に不十分であり,画像全体の状況を考慮する必要がある.わたしたちのモデルは,様々なスケールの局所および全体の画像の特徴を組み入れた識別学習したマルコフ確率場を用いている.そして各点の両方の深度と点同士の深度関係をモデル化する.わたしたちは,
わたしたちのアルゴリズムが,たとえ体系化されてないシーンであっても高精度の深度マップを高い頻度で復元することができることを示す.
We consider the task of depth estimation from a single monocular image. We take a supervised learning approach to this problem, in which we begin by collecting a training set of monocular images (of unstructured outdoor environments which include forests, trees, buildings, etc.) and their corresponding ground-truth depthmaps. Then, we apply supervised learning to predict the depthmap as a function of the image. Depth estimation is a challenging problem, since local features alone are insufficient to estimate depth at a point, and one needs to consider the global context of the image. Our model uses a discriminatively-trained Markov Random Field (MRF) that incorporates multiscale local- and global-image features, and models both depths at individual points as well as the relation between depths at different points. We show that, even on unstructured scenes, our algorithm is frequently able to recover fairly accurate depthmaps.

Depth Map Prediction from a Single Image using a Multi-Scale Deep Network(2014)
ソースコード:hjimce/Depth-Map-Prediction
Abstract
シーンの3D地形を理解する上で,深度予測は必要不可欠な要素である.ステレオ画像の局所対応は推定に十分だが,一枚の画像から深度関係を発見することは容易ではなく,様々な手がかりから,全体と局所の情報を統合する必要がある.そのうえ,この課題は本質的に不明瞭であり,不確実性の大きな原因は縮尺全般に起因している.本論文では,ふたつのディープネットワークスタックを使用してこの課題に対処する新しい方法を提示する.ひとつは画像全体を元にした全体予測を粗くし,もうひとつはこの予測を局所的なものに改善する.また,縮尺でなく深度の関係を測定するのに役立つ尺度不変誤差を適用する.
Predicting depth is an essential component in understanding the 3D geometry of a scene. While for stereo images local correspondence suffices for estimation, finding depth relations from a single image is less straightforward, requiring integration of both global and local information from various cues. Moreover, the task is inherently ambiguous, with a large source of uncertainty coming from the overall scale. In this paper, we present a new method that addresses this task by employing two deep network stacks: one that makes a coarse global prediction based on the entire image, and another that refines this prediction locally. We also apply a scale-invariant error to help measure depth relations rather than scale. By leveraging the raw datasets as large sources of training data, our method achieves state-of-the-art results on both NYU Depth and KITTI, and matches detailed depth boundaries without the need for superpixelation.

Unsupervised CNN for Single View Depth Estimation: Geometry to the Rescue(2016)
ソースコード:Ravi-Garg/Unsupervised_Depth_Estimatio
Abstract
現在のほとんどの深層畳み込みニューラルネットワークが抱える重大な欠点は,大量の人の手によってラベル付けされたデータを用いて訓練する必要があることである.本論文では,単一視点の深度推定のための深層畳み込みニューラルネットワークを学習するための教師なしフレームワークを提示する.わたしたちはオートエンコーダに類似した方法によるネットワークの訓練によってこれを得る.訓練時,ステレオ画像のように二枚の間の小さなカメラモーションが既知である一組の画像,ソースとターゲットについて考慮する.ソース画像の深度マップを推定するために畳み込みエンコーダを訓練する.そのために,予測された深度と既知の視点間変位を用いて,ターゲット画像の逆ワーピングを生成し,そしてソース画像を再構築する.再構築における測光誤差はエンコーダの再構築誤差である.この訓練データの取得は等価のシステムと比べてかなり簡単であり,手作業のアノテーションや,深度センサのカメラに対するキャリブレーションを必要としない.KITTIデータセットのうち半分以下で訓練したわたしたちのネットワークが,単一視点の深度推定のための最先端の教師あり学習手法に匹敵するパフォーマンスを発揮することを示す.
A significant weakness of most current deep Convolutional Neural Networks is the need to train them using vast amounts of manually labelled data. In this work we propose a unsupervised framework to learn a deep convolutional neural network for single view depth prediction, without requiring a pre-training stage or annotated ground-truth depths. We achieve this by training the network in a manner analogous to an autoencoder. At training time we consider a pair of images, source and target, with small, known camera motion between the two such as a stereo pair. We train the convolutional encoder for the task of predicting the depth map for the source image. To do so, we explicitly generate an inverse warp of the target image using the predicted depth and known inter-view displacement, to reconstruct the source image; the photometric error in the reconstruction is the reconstruction loss for the encoder. The acquisition of this training data is considerably simpler than for equivalent systems, requiring no manual annotation, nor calibration of depth sensor to camera. We show that our network trained on less than half of the KITTI dataset gives comparable performance to that of the state-of-the-art supervised methods for single view depth estimation.

Deeper Depth Prediction with Fully Convolutional Residual Networks(2016)
ソースコード:iro-cp/FCRN-DepthPrediction
Abstract
本論文は,一枚のRGB画像で与えられたシーンの深度マップ推定の問題に対処する.わたしたちは,一枚の画像と深度マップ間のあいまいなマッピングをモデルするための,残差学習(residual learning)を包括する全層畳み込みアーキテクチャ(fully convolutional architecture)を提案する.出力の解像度を改善するために,わたしたちはネットワーク内の特徴マップのアップサンプリングを効率的に学習する斬新な方法を提示する.最適化のために,わたしたちは課題にふさわしく,また深度マップに共通して存在する値分布によって駆動する反転Huber損失を導入する.わたしたちのモデルはエンドツーエンドで訓練され,条件付き確率場や追加の改善工程のような後処理の手法に依存しない単一アーキテクチャで構成される.その結果,モデルは画像やビデオでリアルタイムに実行する.評価段階においては,わたしたちはモデルが,深度推定のあらゆるアプローチよりも優れたパフォーマンスであるにも関わらず,現在最先端のものよりも少ないパラメータを含み,少ない訓練データを要求することを示す.コードとモデルは公的に利用可能である.
This paper addresses the problem of estimating the depth map of a scene given a single RGB image. We propose a fully convolutional architecture, encompassing residual learning, to model the ambiguous mapping between monocular images and depth maps. In order to improve the output resolution, we present a novel way to efficiently learn feature map up-sampling within the network. For optimization, we introduce the reverse Huber loss that is particularly suited for the task at hand and driven by the value distributions commonly present in depth maps. Our model is composed of a single architecture that is trained end-to-end and does not rely on post-processing techniques, such as CRFs or other additional refinement steps. As a result, it runs in real-time on images or videos. In the evaluation, we show that the proposed model contains fewer parameters and requires fewer training data than the current state of the art, while outperforming all approaches on depth estimation. Code and models are publicly available.

Semi-Supervised Deep Learning for Monocular Depth Map Prediction(2017)
ソースコード:Yevkuzn/semodepth
Abstract
教師ありディープラーニングはしばしば訓練データが不十分でないことに悩まされる.とりわけ単眼カメラの画像深度マップ予測においては,現実の動的な屋外環境において高密度の深度画像を決定することはほとんど不可能である.ライダー(LiDARs)センサを用いた場合,例えば,距離測定ではノイズが存在し,センサ間のキャリブレーションは完璧にできず,そして測定は一般的にカメラ画像よりも低密度である.本論文では,半教師あり方法での単眼カメラの画像深度マップに対する新しいアプローチを提示する.わたしたちは教師あり学習に低密度な深度を用いるが,わたしたちのディープネットワークは画素値の一致する(photoconsistent)高密度深度マップを生成する.教師あり学習において低密度な深度を使用するが,ダイレクトイメージアライメント損失を使用してステレオセットアップでフォトコンシステントな高密度深度マップを生成する.
実験により,最先端の理論と比較して単一画像による深度マップ予測において優れた性能を発揮することを検証する.
Supervised deep learning often suffers from the lack of sufficient training data. Specifically in the context of monocular depth map prediction, it is barely possible to determine dense ground truth depth images in realistic dynamic outdoor environments. When using LiDAR sensors, for instance, noise is present in the distance measurements, the calibration between sensors cannot be perfect, and the measurements are typically much sparser than the camera images. In this paper, we propose a novel approach to depth map prediction from monocular images that learns in a semi-supervised way. While we use sparse ground-truth depth for supervised learning, we also enforce our deep network to produce photoconsistent dense depth maps in a stereo setup using a direct image alignment loss. In experiments we demonstrate superior performance in depth map prediction from single images compared to the state-of-theart methods.

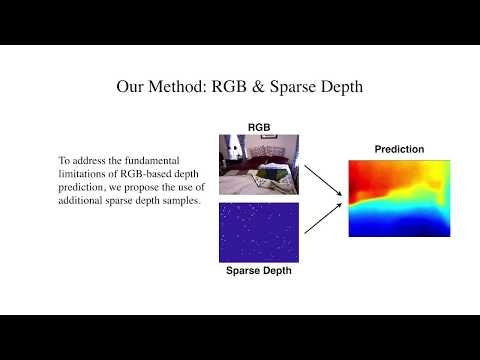
Sparse-to-Dense: Depth Prediction from Sparse Depth Samples and a Single Image(2018)
ソースコード:fangchangma/sparse-to-dense
Abstract
深度測定と単一RGB画像の低密度セットによる高密度深度予測の問題を検討する.単眼カメラ画像からの深度推定は本質的に不明瞭で不確実なものであり,高レベルのロバスト性と精度を得る為には,追加の低密度深度サンプルを導入する必要があり,それは低解像度の深度センサあるいはSLAMアルゴリズムによって得る.わたしたちはRGB-D生データから直接学習する単一のディープ回帰ネットワークの使用を提示し,予測精度における深度サンプル数の影響を探る.一枚のRGB画像のみを用いる場合と比較して,100個の空間的にランダムな深度サンプルを追加すると,NYU-Depth-v2屋内データセットで二乗平均平方根誤差が50%減少することを,わたしたちの実験は示す.さらにKITTIデータセットでは信頼度予測は59%から92%に上昇する.ふたつの提示されたアルゴリズム(低密度マップを高密度マップに変換するSLAMのプラグインモジュール,ライダー(LiDARs)のための超解像度)の応用を実証する.ソフトウェアとビデオデモンストレーションは公的に利用可能である.
We consider the problem of dense depth prediction from a sparse set of depth measurements and a single RGB image. Since depth estimation from monocular images alone is inherently ambiguous and unreliable, to attain a higher level of robustness and accuracy, we introduce additional sparse depth samples, which are either acquired with a low-resolution depth sensor or computed via visual Simultaneous Localization and Mapping (SLAM) algorithms. We propose the use of a single deep regression network to learn directly from the RGB-D raw data, and explore the impact of number of depth samples on prediction accuracy. Our experiments show that, compared to using only RGB images, the addition of 100 spatially random depth samples reduces the prediction root-mean-square error by 50% on the NYU-Depth-v2 indoor dataset. It also boosts the percentage of reliable prediction from 59% to 92% on the KITTI dataset. We demonstrate two applications of the proposed algorithm: a plug-in module in SLAM to convert sparse maps to dense maps, and super-resolution for LiDARs. Software and video demonstration are publicly available.