はじめに
FMEのPythonCallerを使って、ラスタデータ解析のパイプラインを前回までで作ってみましたが、こんかいは、もともとの話として、PythonCallerの使い方について少し深めに理解したいと思います。
PythonCallerは、FME の標準トランスフォーマーではできない柔軟なロジックや外部ライブラリの活用を可能にする超強力ツールです。以下のようなことができます。
- 複雑な条件分岐・計算ロジックの実装
- 外部ライブラリ(例:WhiteboxTools, NumPy, pandas)の利用
- 属性やジオメトリの加工・新規生成
- Web API 呼び出しやファイル出力
PythonCallerは、基本的には、PythonCallerの設定画面を開いて、そこにPythonのコードを書き込んで利用します。ただし、最初にちょっと引っかかるのが、旧形式と新形式という2つの書き方があることです。
旧形式と新形式について
2025年現在のFMEでは、新形式が推奨です。ですが、念の為FME の PythonCaller における 「新形式」 (FeatureProcessor クラス形式) と 「旧形式」 (processFeature(feature) 関数形式) の違いと、注意点を整理します。
| 項目 | 旧形式 (processFeature) |
新形式 (FeatureProcessor クラス) |
|---|---|---|
| FME バージョン | すべて対応(古いFMEでもOK) | FME 2022 以降(完全対応は 2022.1+) |
| スクリプト構造 | 関数ベース | クラスベース(状態を持てる) |
| フィーチャ出力 | return feature |
return feature または self.pyoutput(feature)
|
| 処理の状態管理 | 各フィーチャに対して都度処理 | クラスの中でフラグやカウンタ保持可能。__init__で変数保持 |
| 複数出力 | × 不可(1対1) | 〇 可能(self.pyoutput() を使う) |
| 実装の簡単さ | ◎ 初心者向き | △ Pythonnに慣れていると便利 |
ChatGPTなどに聞くと、旧形式の話も出てきますが、新形式で行きましょう! |
具体例
PythonCallerの使い方を、新形式で丁寧に解説します。
まず全体の流れから説明します。以下のワークスペースでは、座標値 (0,0) で属性名 building_height をもつテスト用のデータを作成し、PythonCallerでデータを処理しています。
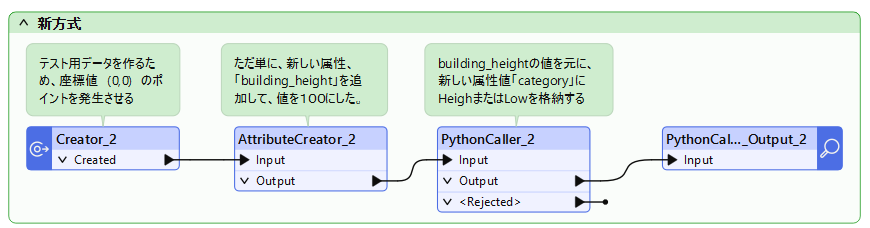
次に各個のトランスフォーマについて説明します。
Creator
Creatorトランスフォーマは、一見よくわからないトランスフォーマなのですが、色んなところに現れます。要は、処理パイプラインの頭につけるもので、Readerを使ってファイルを指定したワークスペースを作る以外のときによく使います。何かを置いておかないと、パイプラインが完成しないとき、また、手動でジオメトリを定義してからスタートしたいときに使います。
まず、Creator_2と書かれている、Creatorで、座標値 (0,0) のダミーデータを作成します
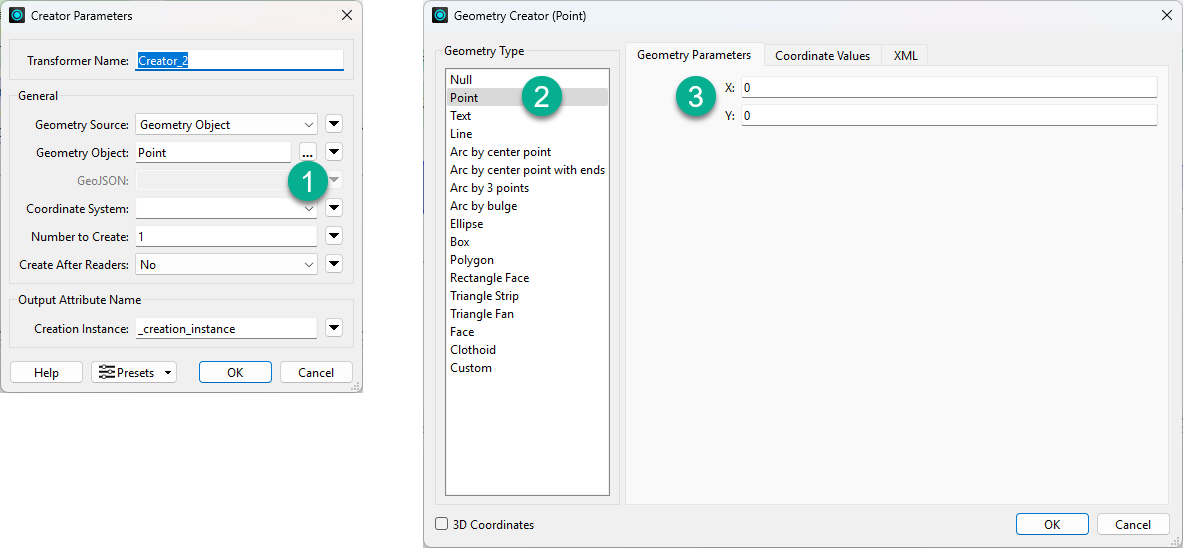
- オプションメニューをクリック
- Pointを選択
- 適当な座標値を入力
AttributeCreator
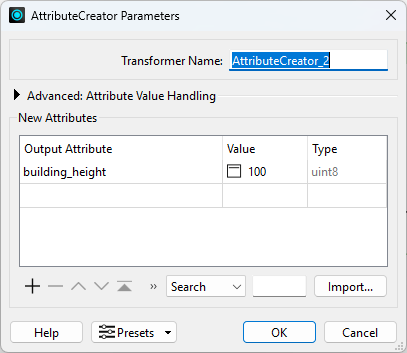
次に、Creatorででっち上げたデータに、building_heightという属性列を追加し、100をデフォルト値として設定します。
ここまでのワークスペースを実行すると、以下のようなデータが出来上がっています。
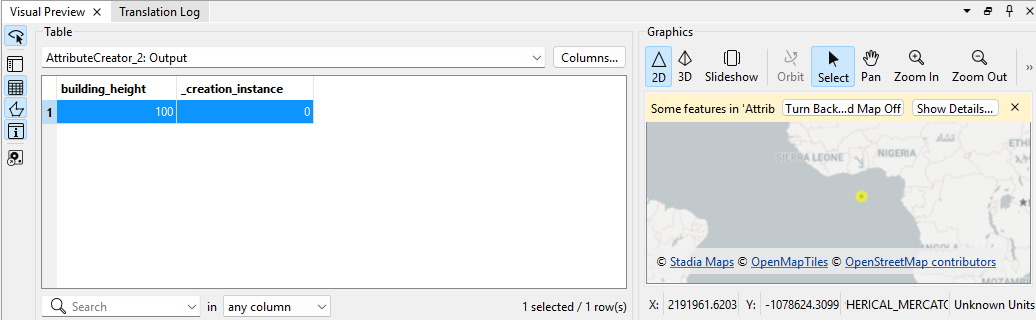
左側では、building_height列に100という値が格納されているのがわかります。右の地図を見ると、緯度経度が0の場所に点があるのがわかります。
PythonCallerで設定するPythonスクリプト
上で作成したデータを、PythonCallerに渡します。ここでの処理は、高さが50より大きければ High、低ければ Lowを、新しい属性値「category」に格納するというものです
動くコードは以下です。
class FeatureProcessor(object):
def __init__(self):
pass # 初期化処理が不要な場合は pass でOK
def input(self, feature):
height = feature.getAttribute("building_height")
print(height)
if height > 50:
feature.setAttribute("category", "High")
print('heigh')
else:
feature.setAttribute("category", "Low")
print('low')
self.pyoutput(feature)
いくつかポイントがあります。
まず、処理の内容は、Pythonのクラスとして定義する必要があります。それが、
class FeatureProcessor(): の部分です。
その後、最低2つの関数を定義します。1つ目は、初期状態を定義する部分で、
def __init__(self):
pass # 初期化処理が不要な場合は pass でOK
何にもなければ、passと書いておきます。これは必須です。
次に、実際の処理を定義する部分で、
def input(self, feature):
xxxxx
xxxxx
self.pyoutput(feature)
となっています。この部分も必須で、実際処理コードを書いたうえで、self.pyoutput() でデータを出力します。
ここまでを最低限のコードとしてまとめると、
class FeatureProcessor(object):
def __init__(self):
pass # 初期化処理が不要な場合は pass でOK
def input(self, feature):
pass
というテンプレートになります。
ちなみに、FeatureProcessor というのは適当につけた名前なので自分で好きに名前をつけてください。
PythonCallerの設定
実際に、動くコードをPythonCallerに貼り付けると以下のようになります。
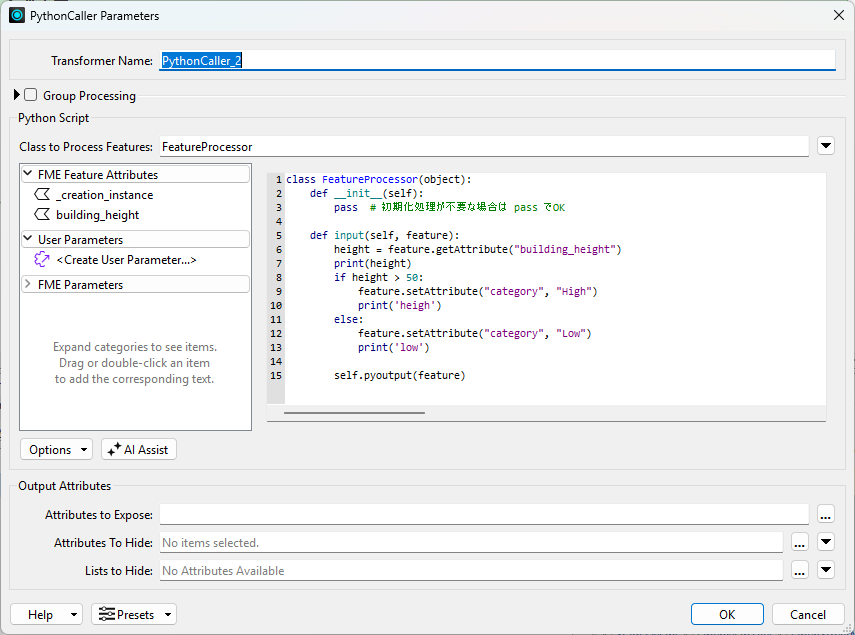
このまま実行してみると一つ問題がわかります。
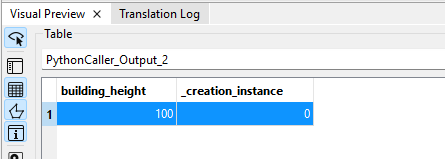
予定していた、新しい属性列、category が現れません。頑張って色々探すと、Feagure Informationの中のUnexposed Attributeの中に、現れていました。
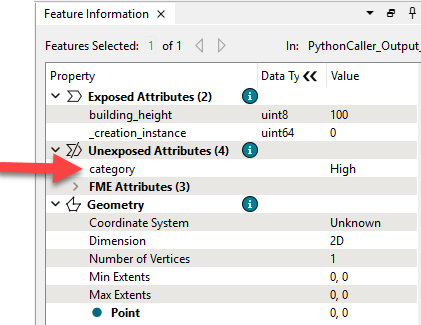
PythonCallerを実行した時点でAttributeをさらけ出したいときは、Attributes to Expose であらかじめ今回新たに作成したcategory 属性をさらけ出すことを明示しておく必要があります。
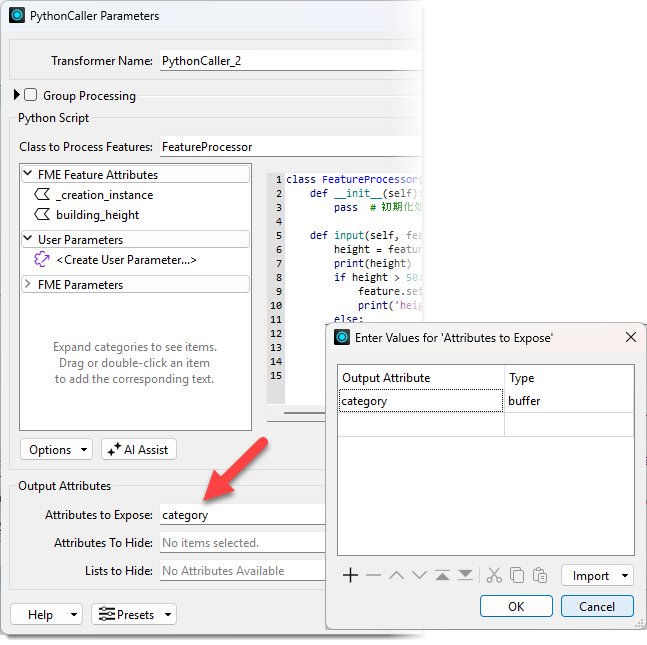
Typeの指定には、とりあえずbufferを指定しておけば間違いないです。
これですべての設定が終わったので、全体を実行してみます。すると以下のような結果が得られます。これでイメージ通りですね。
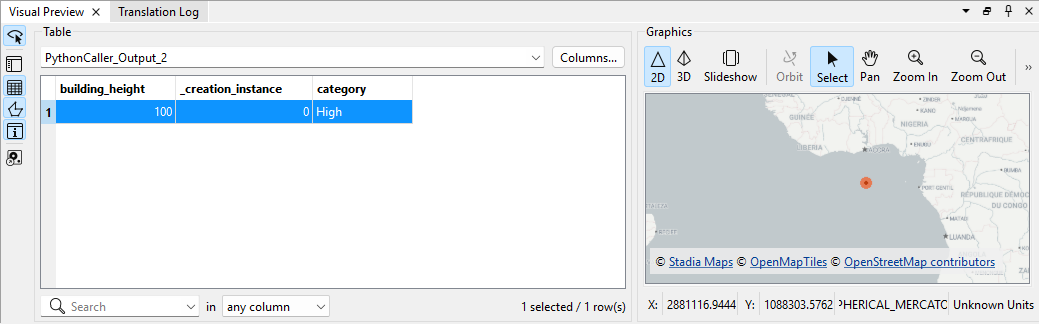
今回は、FMEでPythonを使うためのPythonCallerの基本的な使い方について丁寧に説明してみました。FMEでPythonが使えればかなり複雑な処理やデータ解析のフローが作れるので、徐々に難しいことに挑戦したいと思います。