PyTorch1.0で転移学習を動かしてみた
他のライブラリでも転移学習をやったことがないPyTorch初心者がResNetによる転移学習(+ファインチューニング)を動かしてみました。
複数のResNetで動かして比較してみました。
実行したチュートリアル
実行したのは下記リンクのTransfer Learning Tutorialです。
https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html
ResNetの学習済みモデルを使用して、それぞれ120枚ほどの学習データからハチとアリを分類する転移学習(+ファインチューニング)を行います。

転移学習とは
本チュートリアルはTransfer Learning Tutorialとありますが、最初にFine Tuningをやって、その後Transfer Learningをやっています。言葉の定義として、下記が一般的だと思っています。学会などで定義されているのがあるのでしょうか。
- Transfer Learning(転移学習): 学習済みモデル(出力層以外)のウエイトは変更せず特徴量抽出に利用
- Fine Tuning(ファインチューニング):学習済みモデル(出力層以外)のウエイトを使って再学習
ResNet(Residual Network)とは
ディープニューラルネットワークでは層を深くすると表現力が増しますが、勾配消失問題によって学習が進みにくいという問題がありました。
学習が進みにくい問題を、CNNでショートカットの結合を作り、残差を学習するという形になることで解消し、152層という深い層でも学習を2015年に実現したのがResNetと理解しています。Residualは残差という意味ですね。
論文は下記で見られますが、こちらの説明がわかりやすいですね。
https://arxiv.org/abs/1512.03385
実行環境
実行環境は下記の通りです。構築手順は以前の記事をご参照ください。
- OS: Windows 10 Pro
- CPU: Intel Xeon E3-1240v3 3.40GHz
- メインメモリ: 8GB
- GPU: NVIDIA GeForce GTX 1050 Ti 4GB
- Disk: Samsung SSD 860 EVO 500GB
- Anaconda3(64bit)
- python=3.6.7
- pytorch=1.0.0
- torchvision=0.2.1
- cudatoolkit=9.0
- cudnn=7.1.4
チュートリアル実行
Jupyter Notebookでチュートリアルを開く
チュートリアルサイトの一番下にあるDownload Jupyter notebook: transfer_learning_tutorial.ipynbからjpynbファイルをダウンロードし、Jupyter Notebookから開きます。
Dataのダウンロードと解凍
チュートリアルに書いてある通り、Data をダウンロードして解凍して、フォルダの参照(data_dir)と合わせます。
解凍すると下記のようにフォルダが作られます。
Data
└─hymenoptera_data
├─train
│ ├─ants
│ └─bees
└─val
├─ants
└─bees
必要に応じ、data_dirを変更します。
data_dir = 'data/hymenoptera_data'
学習済みモデルの読み込み
FINETUNING THE CONVNETで下記のようにresnet18のモデルがダウンロードされます。
Fine Tuning(ファインチューニング)
It should take around 15-25 min on CPU. On GPU though, it takes less than a minute.とありますが、私の環境では学習に5分35秒かかりました。
全Epochの最高Accuracyのモデルを返す関数は勉強になりますね。
model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler,
num_epochs=25)
Out:
Epoch 0/24
----------
train Loss: 0.5373 Acc: 0.7623
val Loss: 0.2439 Acc: 0.9412
Epoch 1/24
----------
train Loss: 0.4252 Acc: 0.8197
val Loss: 0.1811 Acc: 0.9281
Epoch 2/24
----------
train Loss: 0.5282 Acc: 0.7869
val Loss: 0.2781 Acc: 0.8889
Epoch 3/24
----------
train Loss: 0.5797 Acc: 0.7500
val Loss: 0.4213 Acc: 0.8301
Epoch 4/24
----------
train Loss: 0.4304 Acc: 0.8115
val Loss: 0.3417 Acc: 0.8627
Epoch 5/24
----------
train Loss: 0.4440 Acc: 0.8279
val Loss: 0.3300 Acc: 0.8824
Epoch 6/24
----------
train Loss: 0.6152 Acc: 0.7992
val Loss: 0.2846 Acc: 0.8954
Epoch 7/24
----------
train Loss: 0.2882 Acc: 0.9016
val Loss: 0.2643 Acc: 0.9020
Epoch 8/24
----------
train Loss: 0.3794 Acc: 0.8361
val Loss: 0.2373 Acc: 0.9020
Epoch 9/24
----------
train Loss: 0.2986 Acc: 0.8770
val Loss: 0.2179 Acc: 0.9346
Epoch 10/24
----------
train Loss: 0.2764 Acc: 0.8852
val Loss: 0.2320 Acc: 0.9216
Epoch 11/24
----------
train Loss: 0.2345 Acc: 0.9098
val Loss: 0.2242 Acc: 0.9216
Epoch 12/24
----------
train Loss: 0.3228 Acc: 0.8443
val Loss: 0.2501 Acc: 0.9216
Epoch 13/24
----------
train Loss: 0.2862 Acc: 0.8689
val Loss: 0.2239 Acc: 0.9216
Epoch 14/24
----------
train Loss: 0.2475 Acc: 0.8770
val Loss: 0.1922 Acc: 0.9412
Epoch 15/24
----------
train Loss: 0.3028 Acc: 0.8893
val Loss: 0.2112 Acc: 0.9281
Epoch 16/24
----------
train Loss: 0.2343 Acc: 0.9016
val Loss: 0.2237 Acc: 0.9216
Epoch 17/24
----------
train Loss: 0.2799 Acc: 0.8852
val Loss: 0.2334 Acc: 0.9150
Epoch 18/24
----------
train Loss: 0.2620 Acc: 0.9057
val Loss: 0.2156 Acc: 0.9346
Epoch 19/24
----------
train Loss: 0.2529 Acc: 0.9098
val Loss: 0.2735 Acc: 0.9020
Epoch 20/24
----------
train Loss: 0.2604 Acc: 0.8811
val Loss: 0.2128 Acc: 0.9281
Epoch 21/24
----------
train Loss: 0.2869 Acc: 0.8730
val Loss: 0.2234 Acc: 0.9281
Epoch 22/24
----------
train Loss: 0.2494 Acc: 0.9016
val Loss: 0.2005 Acc: 0.9216
Epoch 23/24
----------
train Loss: 0.2599 Acc: 0.8893
val Loss: 0.1854 Acc: 0.9281
Epoch 24/24
----------
train Loss: 0.2261 Acc: 0.8893
val Loss: 0.1964 Acc: 0.9412
Training complete in 5m 35s
Best val Acc: 0.941176
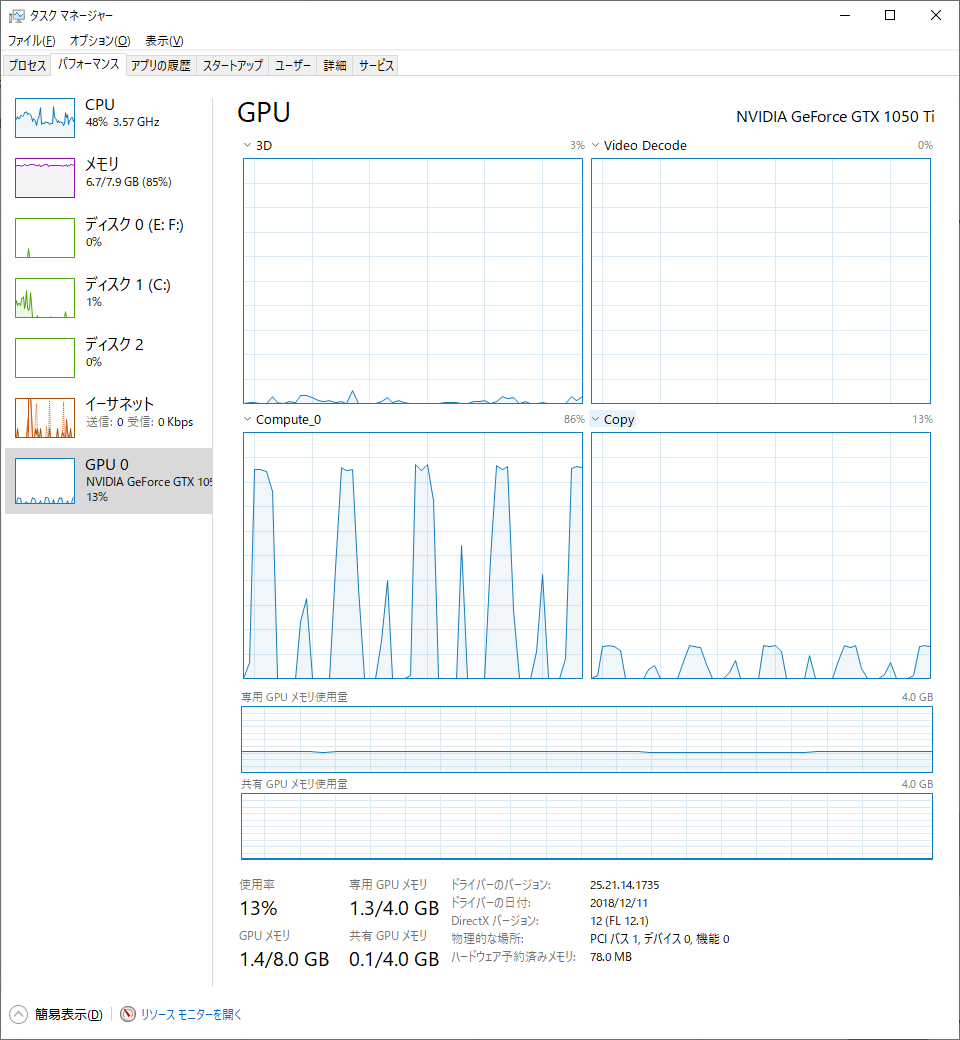
Training中、タスクマネージャーのパフォーマンスを見ると下記のような状態です。GPUを使い切っていない感がありますね。
Transfer Learning(転移学習)
On CPU this will take about half the time compared to previous scenario. This is expected as gradients don't need to be computed for most of the network. However, forward does need to be computed.とありますが、私の環境では学習に4分19秒かかりました。
model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler,
num_epochs=25)
Out:
Epoch 0/24
----------
train Loss: 0.7296 Acc: 0.6434
val Loss: 0.1994 Acc: 0.9346
Epoch 1/24
----------
train Loss: 0.4441 Acc: 0.8115
val Loss: 0.1860 Acc: 0.9346
Epoch 2/24
----------
train Loss: 0.4742 Acc: 0.7910
val Loss: 0.2729 Acc: 0.9216
Epoch 3/24
----------
train Loss: 0.3916 Acc: 0.8115
val Loss: 0.2997 Acc: 0.8889
Epoch 4/24
----------
train Loss: 0.3901 Acc: 0.8320
val Loss: 0.3009 Acc: 0.8758
Epoch 5/24
----------
train Loss: 0.5111 Acc: 0.7787
val Loss: 0.2289 Acc: 0.9412
Epoch 6/24
----------
train Loss: 0.4529 Acc: 0.8320
val Loss: 0.2287 Acc: 0.9542
Epoch 7/24
----------
train Loss: 0.3774 Acc: 0.8320
val Loss: 0.2287 Acc: 0.9412
Epoch 8/24
----------
train Loss: 0.3578 Acc: 0.8279
val Loss: 0.2529 Acc: 0.9477
Epoch 9/24
----------
train Loss: 0.3365 Acc: 0.8607
val Loss: 0.2207 Acc: 0.9412
Epoch 10/24
----------
train Loss: 0.3646 Acc: 0.8484
val Loss: 0.2284 Acc: 0.9412
Epoch 11/24
----------
train Loss: 0.2713 Acc: 0.8852
val Loss: 0.2245 Acc: 0.9477
Epoch 12/24
----------
train Loss: 0.3849 Acc: 0.8402
val Loss: 0.2102 Acc: 0.9412
Epoch 13/24
----------
train Loss: 0.4059 Acc: 0.8156
val Loss: 0.2141 Acc: 0.9477
Epoch 14/24
----------
train Loss: 0.3821 Acc: 0.8156
val Loss: 0.1993 Acc: 0.9477
Epoch 15/24
----------
train Loss: 0.3498 Acc: 0.8238
val Loss: 0.2322 Acc: 0.9412
Epoch 16/24
----------
train Loss: 0.3119 Acc: 0.8730
val Loss: 0.2210 Acc: 0.9477
Epoch 17/24
----------
train Loss: 0.2813 Acc: 0.8811
val Loss: 0.2164 Acc: 0.9412
Epoch 18/24
----------
train Loss: 0.3408 Acc: 0.8648
val Loss: 0.2438 Acc: 0.9412
Epoch 19/24
----------
train Loss: 0.3522 Acc: 0.8320
val Loss: 0.2120 Acc: 0.9477
Epoch 20/24
----------
train Loss: 0.3202 Acc: 0.8648
val Loss: 0.2249 Acc: 0.9477
Epoch 21/24
----------
train Loss: 0.2755 Acc: 0.8975
val Loss: 0.2448 Acc: 0.9412
Epoch 22/24
----------
train Loss: 0.3320 Acc: 0.8607
val Loss: 0.2094 Acc: 0.9477
Epoch 23/24
----------
train Loss: 0.3511 Acc: 0.8566
val Loss: 0.2324 Acc: 0.9412
Epoch 24/24
----------
train Loss: 0.2879 Acc: 0.8770
val Loss: 0.2336 Acc: 0.9477
Training complete in 4m 19s
Best val Acc: 0.954248
Training中、タスクマネージャーのパフォーマンスはほぼ同じ状況でしたので省略します。
ResNet比較
チュートリアルはResNet18ですが、他にResNet34、ResNet50、ResNet101、ResNet152でも実行してみました。
下表に結果を整理してみます。
| ResNet | Learning | Best Val Acc | Training Time | GPU Memory |
|---|---|---|---|---|
| ResNet18 | FineTuning | 0.941176 | 5m 35s | 1.3GB |
| ResNet18 | Transfer | 0.954248 | 4m 19s | 1.3GB |
| ResNet34 | FineTuning | 0.973856 | 6m 56s | 1.5GB |
| ResNet34 | Transfer | 0.954248 | 4m 47s | 1.6GB |
| ResNet50 | FineTuning | 0.934641 | 8m 25s | 1.8GB |
| ResNet50 | Transfer | 0.960784 | 5m 19s | 1.8GB |
| ResNet101 | FineTuning | 0.921569 | 12m 2s | 2.3GB |
| ResNet101 | Transfer | 0.941176 | 6m 26s | 2.3GB |
| ResNet152 | FineTuning | 0.954248 | 15m 37s | 2.8GB |
| ResNet152 | Transfer | 0.973856 | 7m 45s | 2.8GB |
単純に層が深いほど良い結果になるわけではないところが面白いですね。
DeepLearningのウエイトの初期値はランダム性があるので、本来このような比較は、何度かやった結果でするべきですが、その場合も平均よりは最大値で比較するのが良いでしょう。Oputunaを使うとそういうこともできるのでしょうか。
FineTuningが転移学習より時間がかかるのに、結果が悪いことが多いのは、なかなか使い道が難しいですね。
所感と今後の抱負
現実問題では画像データ数が十分ではないことが想定されるので、転移学習で学習済みモデルを利用できることは非常に有効だと思う。
学習時間はそんなに長くなく、十分実用的だと分かったことは非常に良かった。
最適な学習モデルを自動で選択するようなコードを書いていきたいが、その前にPyTorchの基礎を固めたい。