はじめに
先日、pix2pixという画像から画像への変換問題に包括的に使用できるアルゴリズムが発表されました。サンプルを見ると、白黒写真のカラー化から、航空写真からの地図の生成、さらには、地図からそれっぽい航空写真を生成するということもできたと書かれています。さらに、素晴らしいことに、実装もすべてGitHubに公開されており、データさえ用意すればすぐに使える状況となっています。
そこで、ロイ・リキテンスタインのポップアートを写真風に変換するというモデルを作ってみました。写真をポップアート風にするシステムはいろいろありますが、ポップアートを写真風にするシステムはあまりないと思うので、その分pix2pixの強さが見えてくるんじゃないかと思います。
pix2pixについて
pix2pixは、GAN (Generative Adversarial Network)という仕組みを基にしています。GANの詳細は、こちらの記事などを参照していただくとして、pix2pixで使用されているConditional GANとの違いを少し紹介したいと思います。
最も大きな違いは、GANではGeneratorに乱数zしか与えていなかったのが、Conditional GANではGeneratorに変換元となる画像も与えるようになっているという点です。そして、Discriminatorについても、GANでは1つの画像が与えられ、学習データに含まれている画像かGeneratorが生成した画像かという判断を下すだけだったのですが、Conditional GANでは2つの画像が与えられ、学習データに含まれている (変換元画像, 変換先画像) というペアなのか、 (変換元画像, 変換元画像からGeneratorが生成した画像) のペアなのかという判断を下すようになっています。
航空写真から地図を生成する例を考えてみると、以下のようになります。
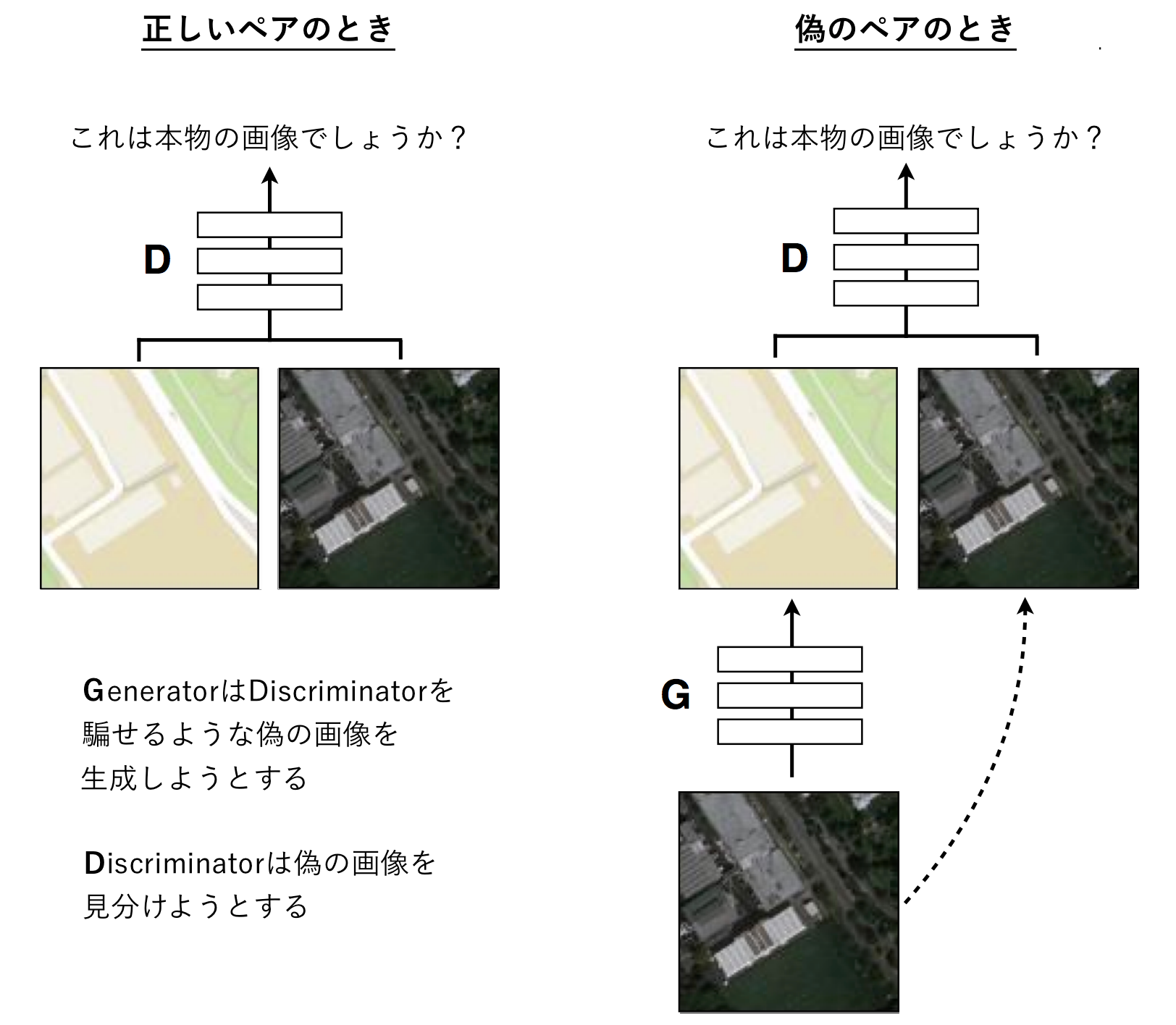
さらに、pix2pixではよりリアルな画像を生成するために、目的関数へのL1正則化項の追加と、PatchGANと呼ばれる仕組みの導入を行っています。L1正則化項は、変換先画像とGeneratorが生成した画像がピクセル単位でどれくらい違っているかということを表しており、これを最小化するということは、ピクセル単位で正解画像に近いような画像を生成するようになるということです。これにより、Discriminatorによって大域的な正しさを判定しつつ、L1正則化でピクセル単位での正しさも勘案する、ということが可能になります。
PatchGANは、Discriminatorに画像を与える際に、画像すべてではなく、16x16や70x70といった小領域(=Patch)を切り出してから与えるようにするという仕組みです。これにより、ある程度大域的な判定を残しながらも学習パラメータ数を削減することができ、より効率的に学習することができるそうです。
つまり、ここまでの話を総合して考えると、ピクセル単位で対応が取れるような変換にはとても向いているアルゴリズムということになります。実際に、サンプルとして挙げられている白黒写真のカラー化や地図の生成はすべてピクセル単位で揃うような問題となっています。一方で、画像の回転や反転を含むような変換はあまり得意ではなさそうです。実際に、風景写真を拡大したものをデータセットとした学習では、あまりうまく生成できていないようです。
実験結果
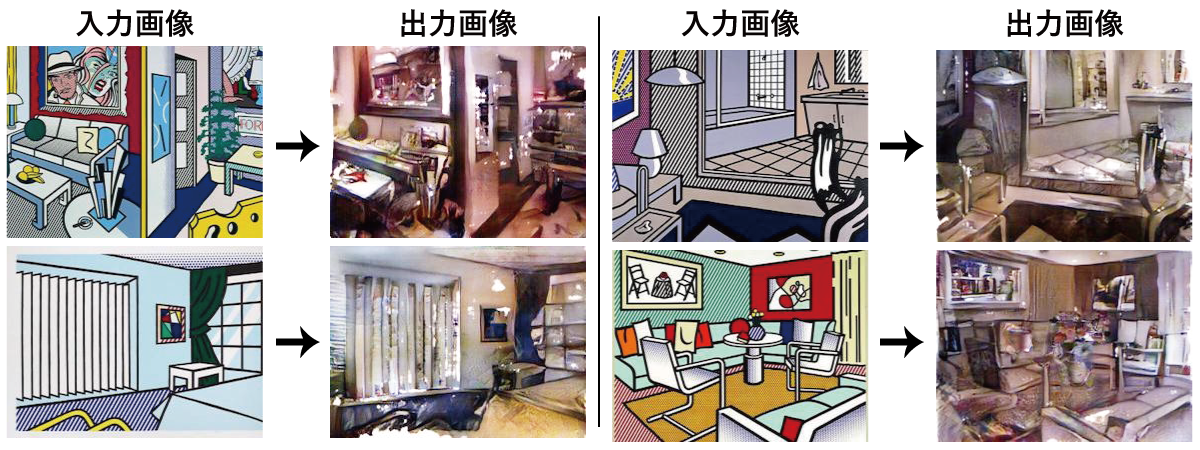
学習データ1159枚で、1200 epochまで回したときの結果が上のものです。データ数が少なくてもそれなりに学習してくれるのでGTX 970でもメモリサイズは余裕でしたが、1200 epochまで回すと70時間弱ほど掛かりました。
入力画像と出力画像を見比べてみると、物体の場所はある程度維持したまま、写真っぽい雰囲気に変換できていることが分かるかと思います。一方で、局所的に白く飛んでしまっているところもあり、劣化した古い写真のような感じになってしまっているという点もあります。
宣伝
ポップアートと写真のパラレルデータセットなんて無い中で学習データをどうやって生成したのかなど、具体的な手法が気になる方もいらっしゃるかもしれませんが、詳細はコミックマーケット91 木曜日 西み-29bで頒布される「SunPro会誌」に書く予定ですので、よろしければお立ち寄りください。
(ここに全部書いちゃうとコミケのネタが無くなるので許してください ![]() )
)
追記 (2016/12/31)
コミックマーケット91にて印刷版の「SunPro会誌」は完売してしまいましたが、電子版をBOOTHで公開しました。サンプル紙面も掲載しておりますので、ぜひご覧ください!