The Infrastructure Behind Twitter: Scale
の非公式訳です。2017年の記事。
Twitter船の概要
Twitterは物理的なエンタープライズベンダーのハードウェアがデータセンターを支配していた時代に生まれました。それ以来、私たちは最高の体験を提供するために、最新のオープンな標準技術で効率的にハードウェアを活用し、継続的に船の設計の見直しや更新を行っています。
現在のハードウェアの構成は以下のとおりです。
ネットワークトラフィック
2010年初頭、外部のホスティングからの移行を開始しました。これは、社内でインフラを構築し運用する方法を学ぶ必要があることを意味し、コアインフラのニーズを読み切れていなかったので、さまざまなネットワーク設計、ハードウェア、ベンダーを適宜入れ替えて採用していました。
2010年後半には、共有ホスティングで過去発生していたスケールとサービスの問題に対処するために、最初のネットワークアーキテクチャを完成させました。バッファの深いTop of Rackで突発のサービストラフィックをサポートし、キャリアグレードのコアスイッチでオーバーサブスクリプションのないレイヤーを実現しました。これにより、「天空の城ラピュタ」や「ワールドカップ2014」で達成した秒間ツイート数の記録など、注目すべきエンジニアリングの成果を通じて、Twitterの初期バージョンをサポートすることができました。
それから数年が経ち、私たちは5つの大陸にPOPを持ち、何十万ものサーバーを持つデータセンターを運営していました。2015年初頭には、サービスアーキテクチャの変更や容量ニーズの増加により、成長痛が発生し始め、最終的には、フルメッシュトポロジでは新しいラックを追加するために必要なハードウェアをサポートできなくなり、データセンターの物理的なスケーラビリティの限界に到達しました。さらに、既存のデータセンター用IGPは、ルーティングの規模が大きくなり、トポロジーが複雑になることで、予期せぬ動作をするようになりました。
このため、既存のデータセンターをClosトポロジ+BGPに変換する作業を開始しました。この変換はアクティブなネットワーク上で行う必要がありましたが、複雑であるにもかかわらず、比較的短期間でサービスへの影響を最小限に抑えて完了することができました。現在のネットワークはこのようになっています。
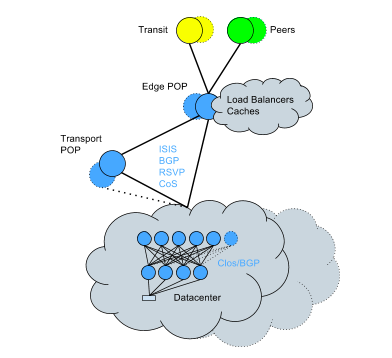
新しい手法のハイライト
- 単一デバイスの故障の影響範囲を小さくする。
- 水平方向の帯域幅拡張が可能
- ルーティングエンジンのCPUオーバーヘッドを低減し、ルート更新の処理をより効率的に
- CPUオーバーヘッドが少ないため、ルーティング能力が高い。
- デバイスやリンク単位でルーティングポリシーをより詳細に制御可能
- プロトコルの再コンバージェンス時間の増加、ルートチャーン問題、OSPF固有の複雑さによる予期せぬ問題など、過去の重大インシデントの根本原因が発生しなくなった
- 影響を与えないラックマイグレーションを可能に
以下、ネットワークインフラについて説明します。
データセンターのトラフィック
チャレンジ
私たちの最初のデータセンターは、共有サーバーの既存システムから容量とトラフィック特性をモデル化して構築されたものでした。しかし、それからわずか数年で、私たちのデータセンターは当初の設計よりも400%も大きくなってしまいました。そして今、私たちのアプリケーションスタックが進化し、Twitterがより分散化するにつれて、トラフィック特性も変化しています。初期のネットワーク設計の前提は、もはや正しいとは言えません。
トラフィックはデータセンター全体を再設計するよりも早く成長するため、リフト&シフトマイグレーションではなく、段階的に容量を追加できるような拡張性の高いアーキテクチャを構築することが重要なのです。
高スループットのマイクロサービスには、さまざまなトラフィックを処理できる高信頼性のネットワークが必要です。私たちのトラフィックは、長時間の TCP 接続からアドホックな MapReduce ジョブ、信じられないほど短いマイクロバーストまで多岐にわたります。これらの多様なトラフィックパターンに対する私たちの最初の答えは、深いパケットバッファを特徴とするネットワークデバイスを導入することでしたが、これにはコストが高く、ハードウェアがより複雑になるという問題が付きまとうものでした。その後、より標準的なバッファサイズとカットスルースイッチング機能を採用し、サーバー側のTCPスタックをより適切にチューニングして、マイクロバーストをより適切に処理できるように設計しました。
学んだこと
長年にわたる改良を経て、私たちはいくつかの教訓を得ました。
- トラフィックが設計容量の上限を超える傾向にある場合は、当初の仕様や要件を超えた設計を行い、迅速かつ大胆に変更すること。
- 技術的な設計を正しく決定するためにデータとメトリクスを活用し、測定基準をネットワーク運用者が理解できるようにすること - これはホスティングおよびクラウド環境において特に重要です。
- 一時的な変更や回避策というものは存在しない。ほとんどの場合、回避策は技術的負債となります。
バックボーントラヒック
チャレンジ
当社のバックボーン・トラフィックは年々劇的に増加していますが、データセンター間でトラフィックを移動する際には、通常の3~4倍のバーストが発生することがあります。このため、MPLSRSVPプロトコルのように、突然のバーストではなく、何らかの形で徐々に増加することを想定して設計されていない従来のプロトコルには、特有の課題があります。可能な限り高速な応答時間を得るために、これらのプロトコルのチューニングに膨大な時間を費やさなければなりませんでした。さらに、トラフィックの急増に対応するため(特にストレージのレプリケーション)、優先順位付けを行いました。
お客様のトラフィックの配信は常に保証する必要がありますが、SLAが数日に及ぶような優先度の低いストレージレプリケーションのジョブの配信を遅らせることは可能です。こうすることで、ネットワークは利用可能な容量をすべて使用し、リソースを最大限に効率的に利用することができます。お客様のトラフィックは、常に優先度の低いバックエンドのトラフィックよりも重要なのです。さらに、RSVPの自動帯域幅につきもののビンパッキングの問題を解決するために、TE++を導入しました。トラフィックが増加するとLSPを追加作成し、トラフィックが減少するとそれを削除する仕組みになっています。これにより,大量の LSP を維持するための CPU 負荷を軽減しつつ, リンク間のトラフィックを効率的に管理することができるようにな りました.
もともとバックボーンにはトラフィックエンジニアリングがありませんでしたが、私たちの成長に合わせて拡張できるように追加されました。そのために、コアとエッジのルーティングをそれぞれ専用のルーターで行うという役割分担を完了させました。これにより、複雑なエッジ機能を持つルーターを購入する必要がなくなり、費用対効果の高い方法で拡張することが可能になりました。
エッジ側では、すべてを接続するコアがあるため、非常に水平に拡張することができます(つまり、すべてを相互接続するコア層があるため、サイトごとに数台のルーターではなく、数十台のルーターを持つことができます)。
ルーターのRIBを拡張するために、ルートリフレクションを導入してスケール需要に合うようにする必要がありましたが、これを行うことで、階層型デザインに移行し、ルートリフレクターを自分自身のルートリフレクターのクライアントにもしてしまいました
学んだこと
昨年から、デバイスの設定をテンプレートに移行し、定期的に監査しています。
エッジトラフィック
Twitterの世界的なネットワークは、世界中の多くのデータセンターにある3,000以上のユニークなネットワークと直接相互接続しています。トラフィックの直接配信は、私たちの最優先事項です。トラフィックの60%をグローバルネットワークバックボーン経由で相互接続ポイントやPOPに運び、ローカルフロントエンドサーバーでクライアントセッションを終了させるなど、できる限りお客様の近くにいることを心がけています。
チャレンジ
世界各地で起こる予測不可能な出来事は、同様に予測不可能なバーストトラフィックを発生させます。スポーツ、選挙、自然災害、その他ニュースになるような大きなイベント時のバーストは、ほとんど事前通告なしにネットワークインフラ(特に写真とビデオ)に負荷をかけます。このようなイベントのために容量を確保し、利用率の大幅な上昇(ある地域で大きなイベントが予定されているときは、通常の3~10倍のピークになることもあります)に備えて計画を立てています。トラフィックは年々大幅に増加しているため、容量を確保することは本当に大変なことです。
私たちは、すべてのお客様のネットワークと可能な限りピアリングを行っていますが、これには課題があります。意外なことに、ネットワークやプロバイダーがホーム拠点から離れた場所での相互接続を好んだり、ルーティングポリシーによって拠点から離れたPOPにトラフィックが到着してしまうことがよくあるのです。Twitterはトラフィックを観測するすべての主要ネットワークとオープンにピアリングしていますが、すべてのISPがそうしているわけではありません。私たちは、ルーティング・ポリシーを最適化し、できるだけユーザーの近くで、できるだけ直接的にトラフィックを提供できるよう、多大な時間を費やしています。
学んだこと
歴史的に、誰かが「www.twitter.com」を要求したとき、そのDNSサーバーの場所に基づいて、サーバーの特定のクラスターにマッピングするために、異なる地域のIPを渡しました。この方法論「GeoDNS」は、ユーザーが正しいDNSサーバーにマッピングすることや、DNSサーバーが世界のどこに物理的に配置されているかを信じることができないという事実のために、部分的に不正確です。また、インターネットのトポロジーは、必ずしも地理的な条件と一致しません。
これを解決するために、私たちは「BGPエニーキャスト」モデルに移行し、すべての場所から同じルートを発表し、お客様から私たちのPOPまでの最適な経路を取るようにルーティングを最適化しました。こうすることで、インターネットのトポロジーの制約の中で可能な限り最高のパフォーマンスを得ることができ、DNSサーバーの存在に関する予測不可能な仮定に依存する必要がありません。
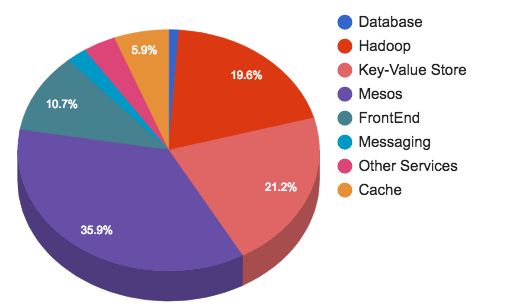
ストレージ
毎日、何億ものツイートが送信されます。それらは処理され、保存され、キャッシュされ、提供され、分析されます。このような膨大なコンテンツには、それに見合ったインフラが必要です。ストレージとメッセージングがTwitterのインフラストラクチャーの45%を占めています
。
ストレージとメッセージングのチームは、以下のサービスを提供しています。
- コンピューティングとHDFSの両方を実行するHadoopクラスタ
- 低遅延のキーバリューストア用のManhattanクラスタ
- シャード化されたMySQLクラスタによるグラフストア
- Blobstoreクラスタ:すべてのラージオブジェクト(ビデオ、画像、バイナリファイルなど)用
- キャッシュクラスタ
- メッセージングクラスタ
- リレーショナルストア(MySQL、PostgreSQL、Vertica)
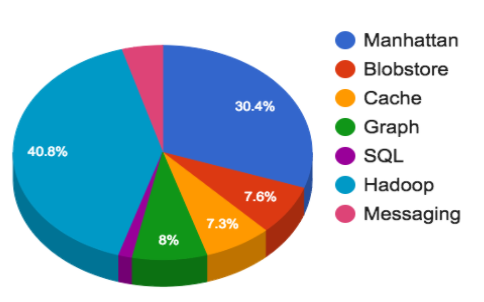
チャレンジ
この規模ではさまざまな課題がありますが、マルチテナントは特に克服しなければならない課題の一つです。多くの場合、お客様は既存のテナントに影響を与えるようなコーナーケースを持ち、私たちは専用のクラスタを構築することを余儀なくされます。専用クラスタが増えれば、それを維持するための運用負荷も増えます。
私たちのインフラには驚くようなものはありませんが、興味深いものをいくつか紹介します。
- Hadoop: 500PB以上のデータを格納する複数のクラスターを、4つのグループ(リアルタイム、プロセッシング、データウェアハウス、コールドストレージ)に分けています。最大のクラスターは1万ノード以上です。150kのアプリケーションを実行し、1日あたり130Mのコンテナを起動しています。
- Manhattan(ツイート、ダイレクトメッセージ、Twitterアカウントなどのバックエンド): 大規模なマルチテナント用、非共有用の小規模なもの、読み取り専用、書き込み/読み取りが多いトラフィックパターン用の読み取り/書き込み用など、さまざまなユースケースに合わせて複数のクラスターを運営しています。読み込み専用のクラスタは数千万QPSを処理し、読み込み/書き込みのクラスタは数百万QPSを処理します。最高性能のクラスタは、すべてのデータセンターでインジェストする観測可能なクラスタで、数千万以上の書き込みを処理することができます。
- グラフ: レガシーなGizzard/MySQLベースのシャードクラスターで、グラフを保存しています。ソーシャルグラフのFlockはピーク時で数千万QPS、MySQLサーバーは平均して30k~45kQPSを処理します。
- ブロブストア: 画像、動画、大容量ファイルなど、数千億のオブジェクトを保存することができます。
- キャッシュ: RedisとMemcacheのクラスタ:ユーザー、タイムライン、ツイートなどをキャッシュしています。
- SQL: MySQL、PostgreSQL、Verticaが含まれます。MySQLやPostgreSQLは、広告キャンペーンや広告取引所、社内ツールなど、強い一貫性が必要な場所で使用されます。Verticaは、営業やユーザー組織をサポートするTableauのバックエンドとしてよく使われるカラムストアです。
Hadoop/HDFSは、Scribeベースのログパイプラインのバックエンドでもありますが、アグリゲーターへの選択的なクライアントのレート制限/スロットルの欠如、カテゴリーの配信保証の欠如、メモリ破壊の問題の解決などの制限に対処するために、Apache Flumeへの置き換えを最終テスト段階で行っています。私たちは1日あたり1兆通以上のメッセージを扱い、これらはすべて500以上のカテゴリに処理され、統合された後、すべてのクラスタに選択的にコピーされます。
時系列での進化
TwitterはMySQLで構築され、当初はすべてのデータがMySQLに保存されていました。小さなデータベース・インスタンスから大きなデータベース・インスタンスへ、そして最終的には多くの大きなデータベース・クラスタへと移行していきました。MySQLインスタンス間でデータを手動で移動させるには、多くの時間を消費する手作業が必要でした。そこで2010年4月に、分散データストアを作成するためのフレームワークであるGizzardを導入しました。
当時のエコシステムは
- レプリケートされたMySQLクラスタ
- Gizzardベースのシャード化されたMySQLクラスタ
です。
2010年5月にGizzardをリリースした後、GizzardとMySQLをベースにしたグラフストレージソリューションのFlockDBを発表し、2010年6月にはユニークIDサービスのSnowflakeを発表しました。2010年は、Hadoopに投資した年でもあります。元々はMySQLのバックアップを保存するためのものでしたが、現在は分析に多用されています。
2010年頃、ストレージソリューションとしてCassandraも追加しました。オートインクリメント機能がないため、MySQLの完全な代替にはなりませんでしたが、メトリクスストアとして採用されました。トラフィックが飛躍的に増加したため、クラスタの増強が必要となり、2014年4月にリアルタイム・マルチテナント分散データベースであるManhattanを立ち上げました。それ以来、Manhattanは私たちの最も一般的なストレージレイヤーの1つとなり、Cassandraは非推奨となりました。
2012年12月、Twitterは写真のネイティブアップロードを可能にする機能をリリースしました。その裏には、新しいストレージ・ソリューションであるBlobstoreがありました。
学んだこと
長年にわたり、より良い可用性、より低いレイテンシ、より簡単な開発を利用するために、MySQLからManhattanにデータを移行してきました。また、トラフィックパターンに対応するために、追加のストレージエンジン(LSM、b+treeなど)を採用してきました。さらに、インシデントから学び、バックプレッシャーシグナルを送信し、クエリフィルタリングを有効にすることで、ストレージ層を不正使用から保護するようになりました。
私たちは、仕事に適したツールを提供することに引き続き注力していますが、これは、あらゆる可能性のあるユースケースを正当に理解することを意味します。「一つのやり方がすべてにフィットする」解決法が機能することはほぼありません。一時的な解決策ほど永続的なものはないので、コーナーケース用のショートカットを作ることを避けています。最後に、解決策を過剰に売り込んではいけません。すべてのものには長所と短所があり、現実的な感覚を持って採用する必要があります。
キャッシュ
キャッシュは私たちのインフラの3%程度ですが、Twitterにとって重要なものです。キャッシュは、重い読み取りトラフィックからバックストアを保護し、ハイドレーションコストの高いオブジェクトの保存を可能にします。私たちは、RedisやTwemcacheなど、いくつかのキャッシュ技術を大規模に使用しています。具体的には、専用クラスタとマルチテナントのTwitter memcached(twemcache)クラスタ、そしてNighthawk(シャード化されたRedis)クラスタが混在している状態です。運用コストを下げるために、主要なキャッシュのほぼすべてをベアメタルからMesosに移行しています。
チャレンジ
Cacheにとって、スケールとパフォーマンスは主要な課題です。私たちは、320Mパケット/秒のパケットレートを持つ数百のクラスタを運用し、120GB/秒を超えるパケットをお客様に提供しています。イベントスパイクが発生した場合でも、99.9%および99.99%の遅延制約で各レスポンスを配信することを目指しています。
高スループットと低レイテンシーのサービスレベル目標(SLO)を達成するためには、システムのパフォーマンスを継続的に測定し、効率的な最適化を検討する必要があります。これを実現するために、私たちはrpc-perfを作成し、キャッシュシステムのパフォーマンスをより深く理解できるようにしました。これは、専用機から現在のMesosインフラに移行する際のキャパシティプランニングに欠かせないものでした。これらの最適化努力の結果、レイテンシーを変えずに、マシンあたりのスループットを2倍以上にすることができました。私たちは、まだ大きな最適化効果が得られると信じています。
学んだこと
Mesosへの移行は、運用面で大きな成果をもたらしました。構成を体系化し、ヒットレートを維持するためにゆっくりとデプロイし、永続ストアに負担をかけないようにし、この層をより確実に成長、拡張できるようになりました。
twemcacheインスタンスあたり何千もの接続があるため、プロセスの再起動やネットワークの急変化、その他の問題があれば、キャッシュ層に対してDDoSのような接続攻撃が発生する可能性がありました。規模を拡大するにつれ、これはより大きな問題となりました。ベンチマークを通じて、高い再接続率によってSLOに違反することになる場合、各キャッシュへの接続を個別にスロットルするアップテイクルールを実装しました。
キャッシュはユーザー、ツイート、タイムラインなどで論理的に分割され、一般的にすべてのキャッシュクラスタは特定のニーズに応じてチューニングされています。クラスタのタイプに応じて、10Mから50M QPSを処理し、数百から数千のインスタンスを実行します。
Haplo
Haploについても紹介しましょう。これはTweet Timelineの主要なキャッシュで、Redisのカスタマイズバージョン(HybridListの実装)によってバックアップされています。HaploはTimeline Serviceから読み取り専用で、Timeline ServiceとFanout Serviceから書き込まれます。また、これはまだMesosに移行していない数少ないキャッシュサービスの1つです。
- 40Mから100M/秒のコマンドを集約しています。
- ネットワークIO 100Mbps/ホスト
- サービスリクエストの集約 800K/秒
追加の読み物
Yao Yue (@thinkingfish) は、私たちの Redis の使用や、より新しい Pelikan コードベースなど、キャッシュに関する素晴らしい講演や論文を何年もかけて作成しています。ビデオや最近のブログ記事もご覧ください。
Puppetを大規模に運用する
私たちは、Kerberos、Puppet、Postfix、Bastions、Repositories、Egress Proxiesなど、さまざまなコアインフラストラクチャサービスを稼働させています。私たちは、これらのサービスの拡張、ツールの構築、管理、およびデータセンターとPOP(Point of Presence)の拡張のサポートに注力しています。ちょうどこの1年、私たちはPOPインフラを多くの新しい地域拠点に大幅に拡張し、新しい拠点の計画、起動、立ち上げの方法を完全に再設計する必要がありました。
私たちは、すべての構成管理とシステムのポストキックスタートパッケージのインストールにPuppetを使用しています。このセクションでは、私たちが克服した課題の一部と、構成管理インフラストラクチャの方向性について詳しく説明します。
チャレンジ
ユーザーのニーズを満たすために成長する中で、私たちはすぐに標準的なツールやプラクティスを追い越していきました。私たちは月間100を超えるコミッター、500のモジュール、1000を超えるロールを抱えています。最終的には、コードベースの品質を向上させながら、ロール数、モジュール数、コード行数を削減することができました。
ブランチ
私たちは、Puppetが環境として参照する3つのブランチを持っています。これらによって、適切にテスト、カナリア、そして最終的には本番環境に変更をプッシュすることができます。より分離されたテストのために、カスタムブランチも許可しています。
現在、テストから本番環境に変更を移すには、手作業で少し手助けする必要がありますが、私たちは、自動統合/バックアウトプロセスを備えた、より自動化されたCIシステムへと移行しています。
コードベース
私たちのPuppetリポジトリには100万行以上のコードが含まれており、Puppetのコードだけでも1ブランチあたり10万行以上あります。最近、私たちは、死んだコードや重複するコードを減らすために、コードベースのクリーンアップに大規模な努力をしました。
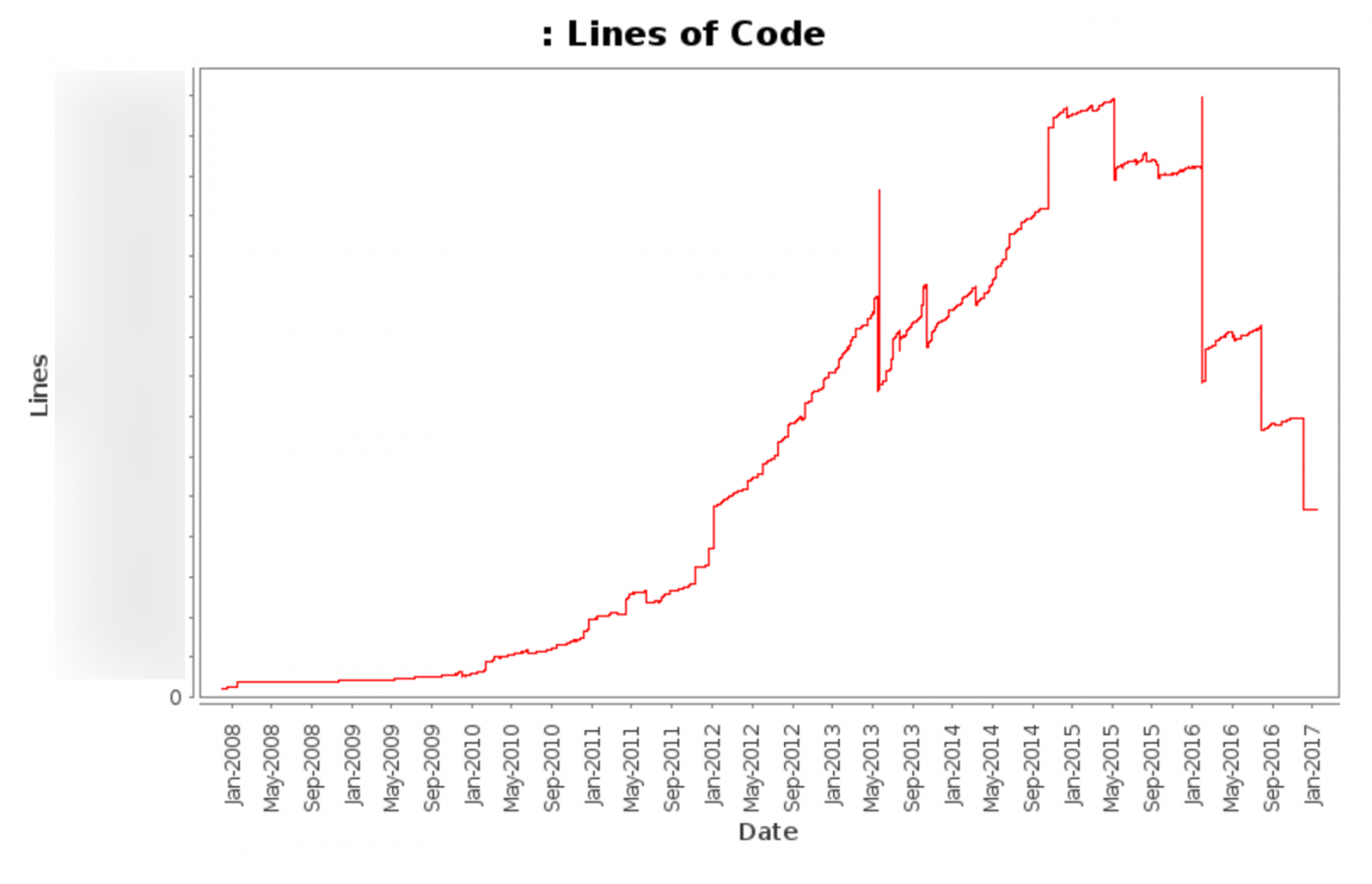
このグラフは、2008年から今日までの当社の総コード行数(自動更新される各種ファイルを含まない)を示しています。
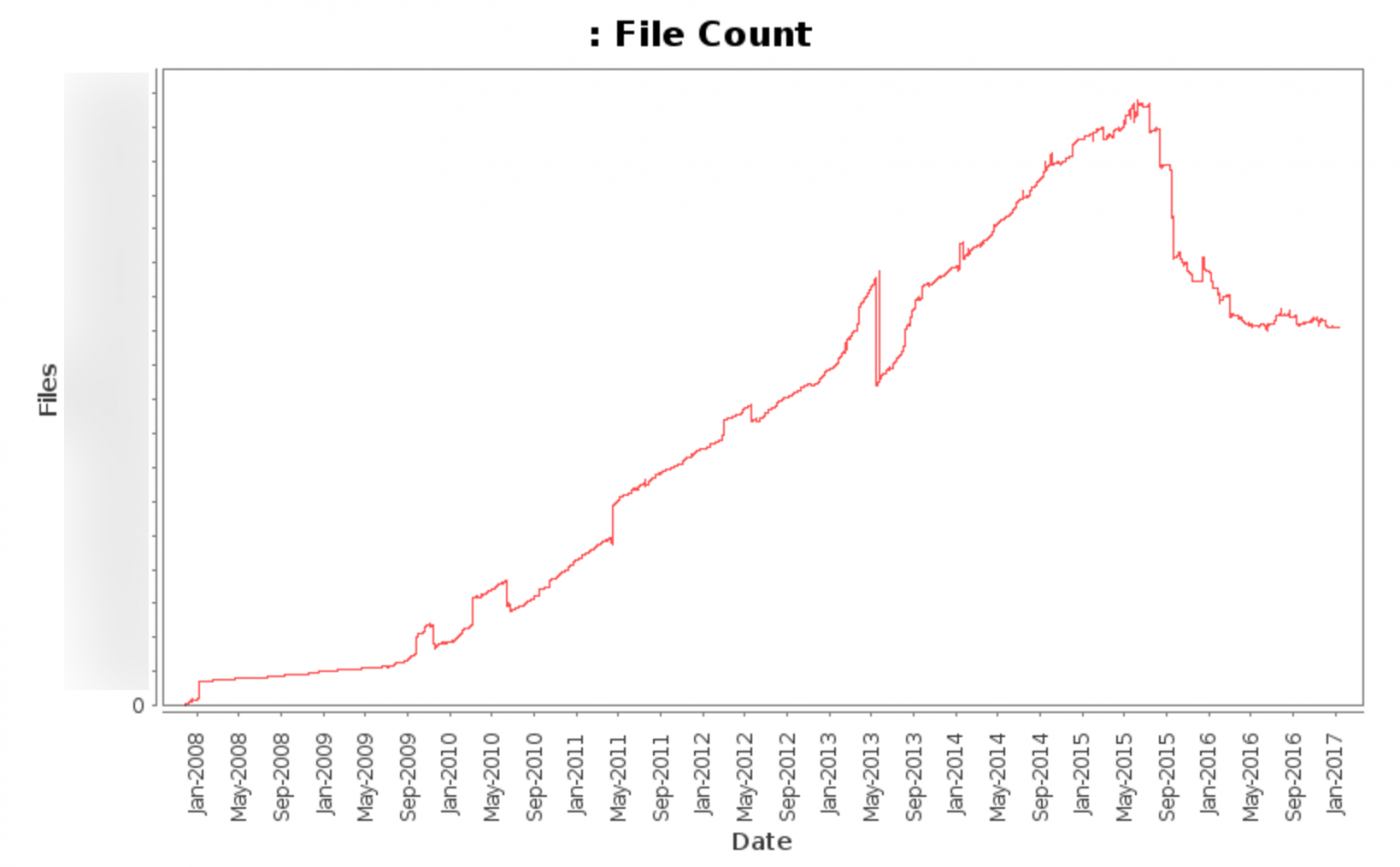
このグラフは、2008年から今日までの総ファイル数(自動更新された各種ファイルを含まない)を示しています。
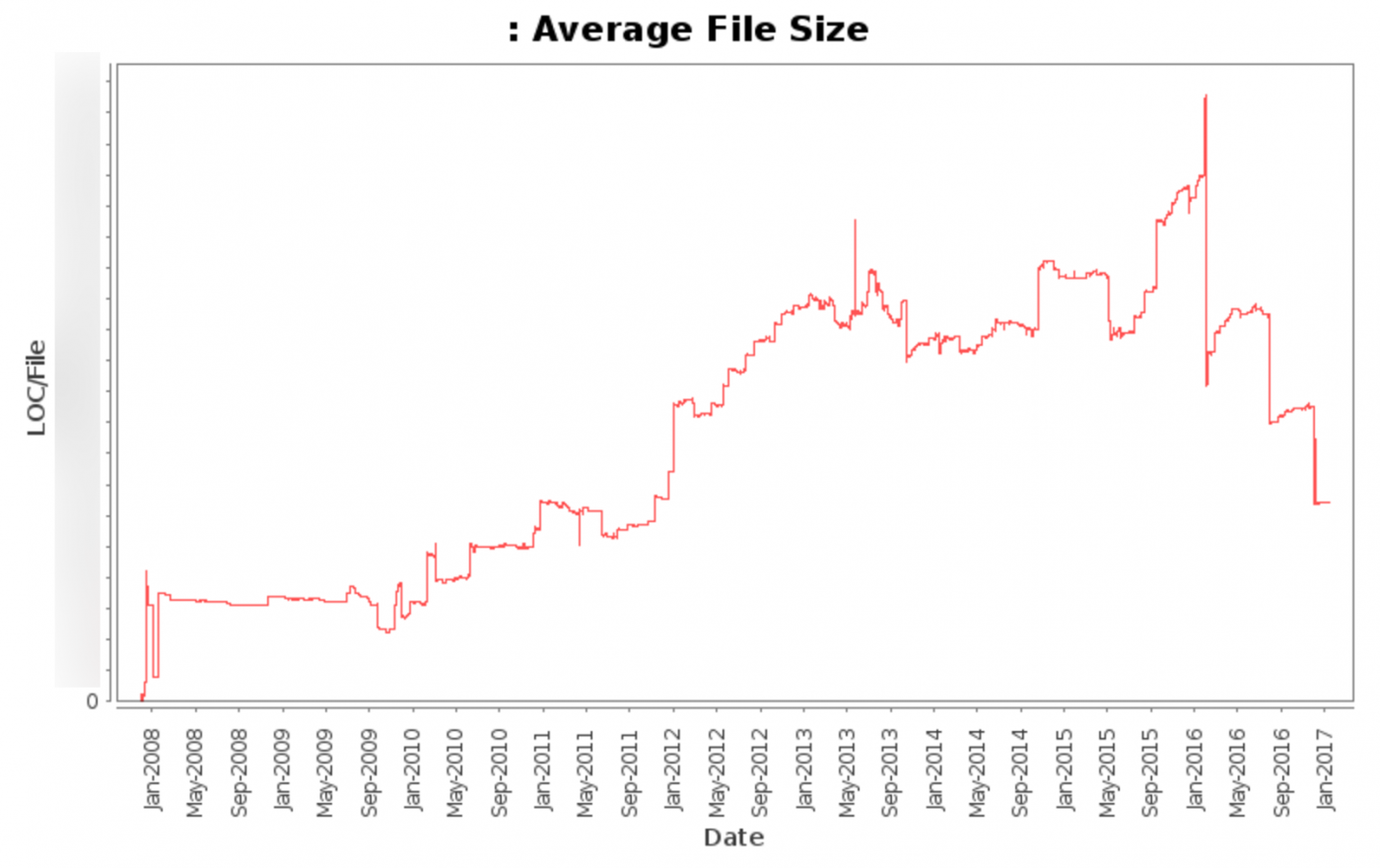
このグラフは、2008年から今日までの平均ファイルサイズ(自動更新された各種ファイルを除く)のグラフです。
大きな成果
私たちのコードベースにとって最大の成果は、コードリンティング、スタイルチェックフック、ベストプラクティスのドキュメント化、そして定期的なオフィスアワーの開催です。
linting ツール (puppet-lint) を使って、コミュニティの一般的な linting 標準に準拠することができました。コードベースにおけるlintingのエラーや警告を何万行も減らし、コードベースの20%以上に手を入れました。
最初のクリーンアップの後、コードベースの小さな変更が容易になり、バージョン管理フックとして自動スタイルチェックを組み込むことで、コードベース内のスタイルエラーを劇的に減らすことができました。
組織全体で100人以上のPuppetコミッターがいるため、内部およびコミュニティのベストプラクティスをドキュメント化することで、力を発揮することができました。参照できる単一の文書があることで、コードを出荷する際の品質と速度が向上しました。
チケットやチャットチャンネルが十分な情報量を提供しない場合や、達成しようとしていることの全体像を伝えられない場合、支援のための定期的なオフィスアワーを開催し(時には招待制)、1対1のヘルプを可能にしました。その結果、ほとんどのコミッターはコミュニティやベストプラクティス、最適な変更の適用方法を理解することで、コードの品質と速度を向上させることができました。
モニタリング
システムメトリクスは一般的に有用ではありませんが(Caitlin McCaffreyのMonitoramaの2016年の講演はこちら)、私たちが有用と判断したメトリクスに追加のコンテキストを提供します。
私たちが警告を発し、グラフ化する最も有用なメトリクスには、次のようなものがあります。
- 実行の失敗数。成功しなかったPuppetの実行の数。
- 実行時間。Puppetクライアントの実行が完了するまでにかかった時間です。
- 未実行。期待する間隔で起こっていないPuppet実行の数。
- カタログサイズ。カタログのサイズ(MB)。
- カタログコンパイル時間:カタログがコンパイルするのにかかる時間(秒)。
- カタログ・コンパイル数。各マスターがコンパイルしているカタログの数。
- ファイルリソース数。フェッチされているファイルの数。
これらの各メトリクスは、ホストごとに収集され、役割ごとに集計されます。これにより、特定の役割、役割のセット、またはより広範な影響を及ぼすイベントにわたって問題が発生した場合、即座に警告と特定を行うことができます。
インパクト
Puppet 2からPuppet 3への移行とPassengerのアップグレード(いずれもこんど別記事で)により、Mesosクラスタ上での平均Puppet実行時間を30分以上から5分未満に短縮することができました。
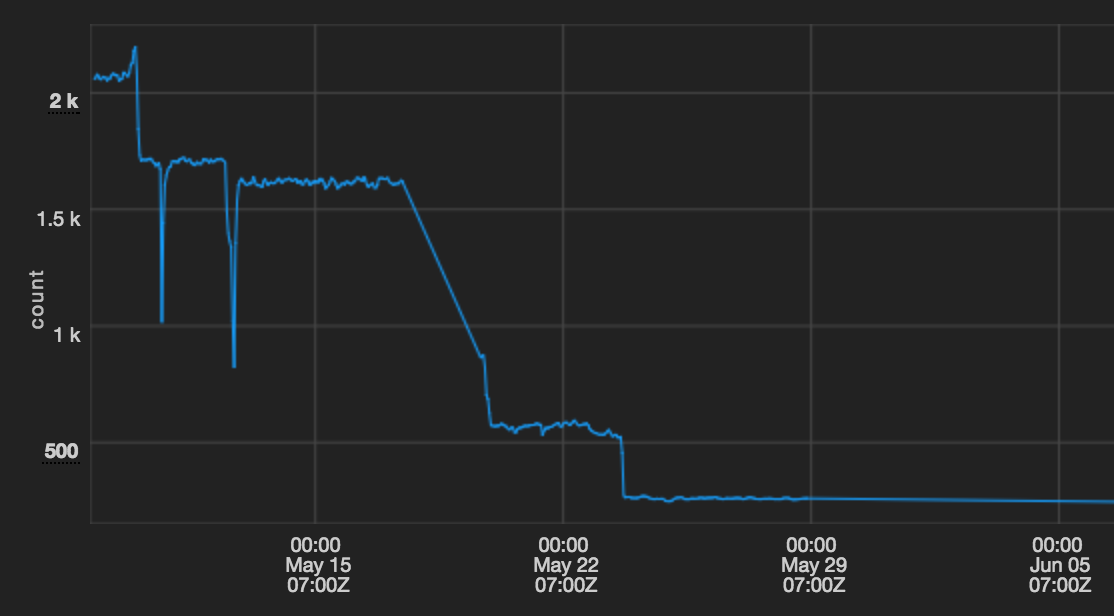
このグラフは、Mesosクラスタ上でのPuppetの平均実行時間を秒単位で示したものです。
Puppetインフラストラクチャの支援に興味がある方、募集中です。
より一般的なシステムのプロビジョニングプロセス、メタデータデータベース(Audubon)、ライフサイクル管理(Wilson)に興味があれば、プロビジョニングエンジニアリングチームは最近我々の#Computeイベントで発表し、その模様はここに収録されています。
これは、Twitterエンジニアリングの皆さんの努力と献身があったからこそ実現できたことです。Twitterの信頼性を築き、貢献した現・元エンジニアに賞賛を送ります。
このブログ記事に貢献してくれたBrian Martin、Chris Woodfield、David Barr、Drew Rothstein、Matt Getty、Pascal Borghino、Rafal Waligora、Scott Engstrom、Tim Hoffman、Yogi Sharmaに特別感謝します。