概要
今回就活の面接の課題で、ブラウザで画面が表示されるまでの流れを説明できるようにするというものがありました。
正直どっから説明なのかよくわかっていないのですが、ブラウザとわざわざ指定があったのでブラウザ内部の挙動を中心に説明して行きます。
具体的なブラウザの実装は読めていないので、まさかり歓迎です。
https://www.html5rocks.com/ja/tutorials/internals/howbrowserswork/
上記を元にしているので、名称などは基本的には上記のページにしたがっております。
ウェブブラウザの仕組み~内容~
目次
最後に作ります
ウェブブラウザのざっくりとした要素
要素と処理の流れの全体像
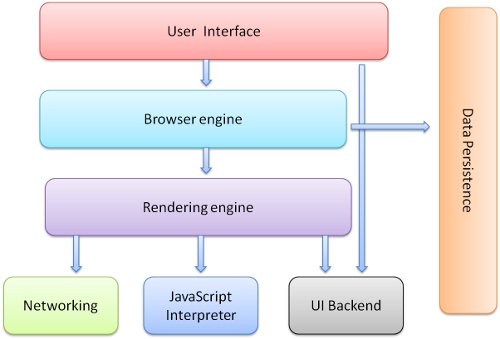
(引用 https://www.html5rocks.com/ja/tutorials/internals/howbrowserswork/)
それぞれの要素の説明
基本的には7つの要素からブラウザはなります。
-
ユーザーインターフェース - アドレスバー、戻る/進むボタン、ブックマーク メニューなど。要求したページが表示されるメインウィンドウを除くすべての部分。ユーザーの目に見える部分。
-
ブラウザエンジン : UIとレンダリングエンジンの間の処理を担う。多分内部的に、ブラウザのユーザーの操作を受けて、実際に内部的な処理を走らせるための中間層・インターフェースになっているような部分。
-
レンダリングエンジン : 要求されたコンテンツの表示を担当します。たとえば、要求されたコンテンツがHTMLの場合は、HTMLとCSSを解析する。様々なレンダリングエンジンがある。
-
ネットワーキング : HTTPリクエストなどのネットワークの呼び出しに使用されます。ここは別途詳しく書きます。
-
UIバックエンド : ウィンドウなどの基本的なウィジェットの描画に使用される。
-
JavaScriptインタープリタ : JavaScriptコードの解析と実行に使用される。
-
データストレージ : 永続的なレイヤで、ブラウザではCookieなどさまざまなデータをハードディスクに保存するのでその部分
参考
具体的な要素の説明
ユーザーインターフェース
アドレスバー、戻る/進むボタン、メニューなど。ブラウザの見た目のすべての部分(要求したページが表示されるメインウィンドウを除く)。ユーザーの目に見える部分。
これは特に調べてないです。ユーザーが使う部分であり、あくまで処理に関係なさそうだなと(勝手に)判断したので割愛します。
ブラウザエンジン
UIとレンダリングエンジンの間の処理を担う。多分内部的に、ブラウザのユーザーの操作を受けて、実際に内部的な処理を走らせるための中間層・インターフェースになっているような部分。
あくまでブラウザがどのようにユーザーインターフェースにレンダリングエンジンの結果を反映させるかを担っている部分という理解。
インターネット上に落ちてる情報が少なすぎました...
所感ですが、無視されてるかブラウザエンジンとレンダリングエンジンがごちゃごちゃになってるような記事が多いような気がします。
ここに着目した記事が見つからないので、誰か見つけたらコメントください。
レンダリングエンジン
要求されたコンテンツの表示を担当します。たとえば、要求されたコンテンツがHTMLの場合は、HTMLとCSSを解析する。様々なレンダリングエンジンがある。
一番大事。よく言われているのはgoogle ChromeやChromiumならBlink, firefoxならGeckoなどなど。ネットワーキングで取得してきた情報をゴニョゴニョしてブラウザエンジンさんに扱えるようにしてあげる部分の処理を担当します。
ウェブブラウザのエンジンと調べるとこいつが出てきます。
補足
Geckoはレンダリングエンジンの機能だけでなく、ブラウザエンジンの機能も持っています。
Gecko is the open source browser engine designed to support open Internet standards such as HTML 5, CSS 3, the W3C DOM, XML, JavaScript, and others.
Gecko provides the foundation needed to display content on the screen, including a layout engine and a complementary set of browser components.
Gecko's function is to render web content, such as HTML, CSS, XUL, JavaScript, and render it on the user's screen or print it.
引用
https://developer.mozilla.org/en-US/docs/Mozilla/Gecko
https://developer.mozilla.org/en-US/docs/Gecko/FAQ
さらに補足
どうやらWeb Kitもredering engineだけでなく、ブラウザエンジンの機能もついてるっぽいですね
参考
https://webkit.org/
http://myakura.github.io/n/webkit4devs.html
レンダリングエンジンのメインフロー
下記はレンダリングエンジンのメインフローの図です。

流れとしては、
- HTMLファイルを字句解析・構文解析してDOMに変換し"content tree"を作成
- レンダーツリーを作成
- レンダーツリーを元にレイアウト処理をしていく。
- レンダーツリーをpaintingします
ここで上記で使用された用語の説明をします。
content tree
「content tree」は DOM 要素と属性のノードのツリー。cssやstyle情報は含まれない。parseしたhtmlをDOM treeに変換したモノがコンテンツ・ツリーと呼ばれているっぽい。
引用
https://stackoverflow.com/questions/31759719/what-is-the-difference-between-browser-dom-tree-and-render-tree#:~:text=The%20DOM%20tree%20is%20essentially,actually%20rendered%20onto%20the%20page.
https://javascript.info/dom-nodes
DOM tree
HTML ドキュメントや、HTML 要素と JavaScript などの外部世界とのインターフェースをオブジェクトで表現したもの。「Document Object Model」の略。
- 字句解析によるトークンのリスト化
- 構文解析による構文木構築
- 構文木内にあるJavaScriptを実行しつつDOMツリーの構築が行われる
The rendering engine will start parsing the HTML document and convert elements to DOM nodes in a tree called the "content tree". The engine will parse the style data, both in external CSS files and in style elements. Styling information together with visual instructions in the HTML will be used to create another tree: the render tree.
Firefox では、読み込みや解析が途中のスタイル シートがある場合、すべてのスクリプトをブロックしています。Webkit では、まだ読み込まれていないスタイル シートの影響を受けそうな特定のスタイル プロパティにスクリプトがアクセスしようとした場合にのみ、スクリプトをブロックします。
どうやらCSSOMが作成されるのはhtmlのparseをDOM化が終わってからっぽい。(シングルスレッドだし)
var para = document.getElementsByTagName("p")[0];
var atts = para.attributes;
console.log(atts)
>NamedNodeMap {length: 0}
length: 0
__proto__: NamedNodeMap
getNamedItem: ƒ getNamedItem()
arguments: (...)
caller: (...)
length: 1
name: "getNamedItem"
__proto__: ƒ ()
[[Scopes]]: Scopes[0]
No properties
getNamedItemNS: ƒ getNamedItemNS()
item: ƒ item()
arguments: (...)
caller: (...)
length: 1
name: "item"
__proto__: ƒ ()
[[Scopes]]: Scopes[0]
length: (...)
removeNamedItem: ƒ removeNamedItem()
arguments: (...)
caller: (...)
length: 1
name: "removeNamedItem"
__proto__: ƒ ()
[[Scopes]]: Scopes[0]
removeNamedItemNS: ƒ removeNamedItemNS()
setNamedItem: ƒ setNamedItem()
setNamedItemNS: ƒ setNamedItemNS()
constructor: ƒ NamedNodeMap()
Symbol(Symbol.iterator): ƒ values()
Symbol(Symbol.toStringTag): "NamedNodeMap"
get length: ƒ length()
__proto__: Object
render tree
色や大きさのついたrectangles(長方形とかの意味だけど上手い訳が思いつかない...)。DOM treeの順番で正しく並んでいる。
こいつを元に実際に画面に表示されるので重要。これはあくまで表示用のtreeなので、DOM treeと一対一の関係ではないです。
例えばhead要素はrender treeに含まれません。属性noneのついているものも、表示されないです。
レイアウト処理
レンダーツリーに座標情報を与える。
レンダーツリーの構築とレイアウト処理は、htmlのparseが終わった部分から行われる。なので、全てのcontent treeの描画を待つわけではない。
painting
レイアウト処理の結果をUIコンポーネントに反映させる処理
参考
レンダリングエンジンのwebkitの具体的な処理の流れ
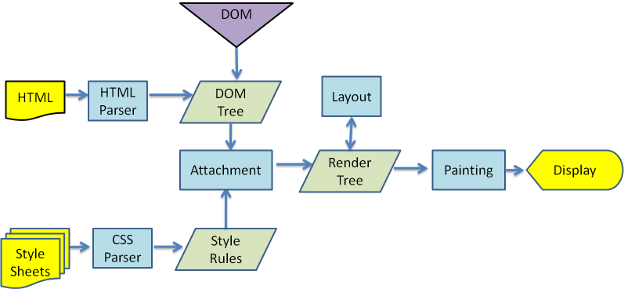
(引用 https://www.html5rocks.com/ja/tutorials/internals/howbrowserswork/)
html parserの話は少し難しいので今回は割愛します...
https://html.spec.whatwg.org/multipage/parsing.html#html-parser
ネットワーキング
HTTPリクエストなどのネットワークの呼び出しに使用されます。
第二層
AS(多分routerが管理しているネットワークを集めたもの)
BGPでは経路制御を行う組織ごとにインターネットの世界で唯一の番号が割り当てられ、個々の経路を識別します。このインターネットの世界で唯一の番号をAS(Autonomous System)番号と呼び、AS番号はIANA(Internet Assigned Numbers Authority)
https://www.nic.ad.jp/ja/newsletter/No35/0800.html
OSPF→AS内部で使われているリンク状態型(ASの繋がりやネットワークの状態などをASで共有しておき、最適な経路情報をつど共有する方法)の動的ルーティングのシステム
BGP(border gateway protocol)→最短経路情報をルーター間で保持しておくためのプロトコル。
基本的にOSI参照モデルとよばれるように分割されたモデルで説明される、通信の仕組みにしたがってデータのやり取りが行われます。
実際に知る必要があるのは、第三層のネットワーク層からです。第一層の物理層や第二層のデータリンク層は、電気がどう流れるとかの話なので今回は割愛します。
実際に第3層以降で、データがどのようにやり取りされているかを考える上で、まず考えるのはip addressです。
そもそもip addressとは下記に引用するように、あるネットワークないにおける住所のようなものである。
IPネットワーク上の情報機器を識別するために指定するネットワーク層における識別用の番号
引用 https://ja.wikipedia.org/wiki/IP%E3%82%A2%E3%83%89%E3%83%AC%E3%82%B9
普段我々が使用しているパソコンなどの機器は、ネットワーク(インターネット以外)に接続したとき普通このip addressを割り振られる。
その仕組みとしてDHCPがあげられる。
DHCP
動的にip addressを割り振るプロトコル。ip address(global/private問わず、addressがないと通信ができない。だって
住所がないから)それを自分で手で設定してもいいけど、動的にそのネットワークに接続した機器にip addressを割り振ってくれる仕組みである。
基本的に家庭にあるルーターに割り振られているglobal ip address自身も、それぞれのモデムのプロバイダーがDHCPで割り当てられたりしている。
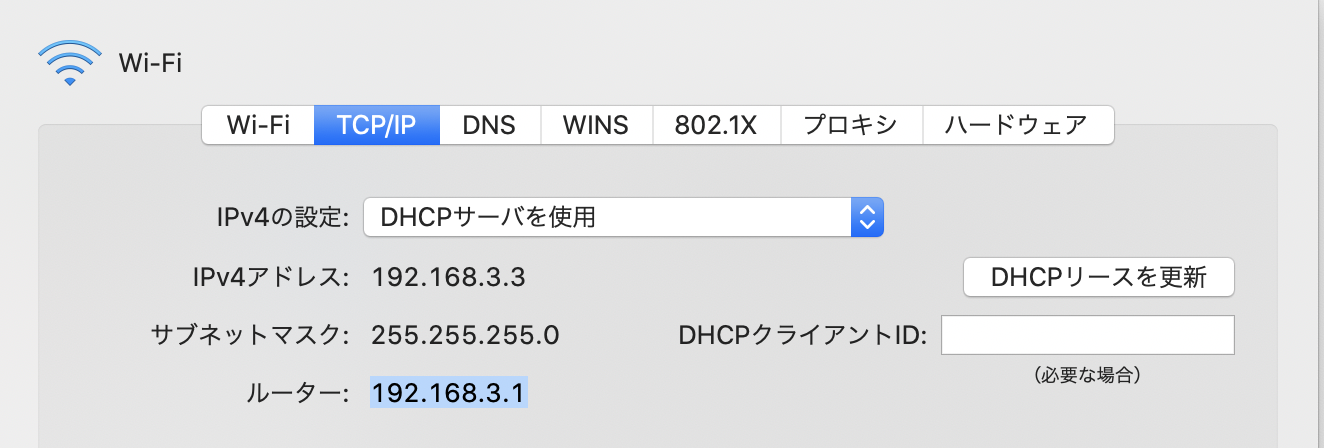
MacOSの場合は、このようにsystem preferenceで確認できます。
https://www.infraexpert.com/study/tcpip13.html
https://docs.oracle.com/cd/E19504-01/805-1756/administration16-36116/index.html
private adress(ルーターが作ってるネットワークのアドレス)とglobal address(インターネット上のip アドレス)の二つがあり、インターネット上でやり取りをするために必要なのはglobal ip addressです。これはICANNと言う団体が管理しています.
実際に行われる処理は、まずuri(Uniform Resource Locator)のホスト名から、DNSのプロトコルにのっとり通信をしたいサーバーのip addressをDNSサーバーに問い合わせます。

引用 https://ja.wikipedia.org/wiki/Uniform_Resource_Locator
上記はdebianですが、まず使用しているパソコンの内部のip addressを解決できないかどうか、/etc/private/hosts見にいくようです。
そこにない場合/etc/resolv.confを見にいきます。そこにname serverが書かれているのでそのroutingに従い、名前解決の通信が走ります。(macだとwifiのルーターになるっぽい)
それぞれのルーターでdns routing tableが定義されているらしく、リゾルバ・サーバーまでたらい回しにされていきます。
https://www.atmarkit.co.jp/ait/articles/1601/29/news014.html
⋊> ~ cat /etc/resolv.conf 18:58:24
#
# macOS Notice
#
# This file is not consulted for DNS hostname resolution, address
# resolution, or the DNS query routing mechanism used by most
# processes on this system.
#
# To view the DNS configuration used by this system, use:
# scutil --dns
#
# SEE ALSO
# dns-sd(1), scutil(8)
#
# This file is automatically generated.
#
nameserver 2400:2410:ac02:5800:1111:1111:1111:1111
nameserver 192.168.3.1
まずは最寄りのname server(resolver sercer)までたどり着くと、そこから一旦そのname serverが、権威DNSサーバー(どのサーバーに、あるドメインの一覧が保存されているかを記録しているサーバー)のうち、まずルートドメインを司ってる、ルートサーバーに聞きにいきます。
そうすると、トップレベルドメインのipを返してくれる。
→トップレベルドメインにセカンドレベルドメインを聞きに行く(最終的にipに解決できるまで、同じことを繰り返す。)
→最寄りのname srverが、その結果をパソコンに返してくれ、名前解決ができます。
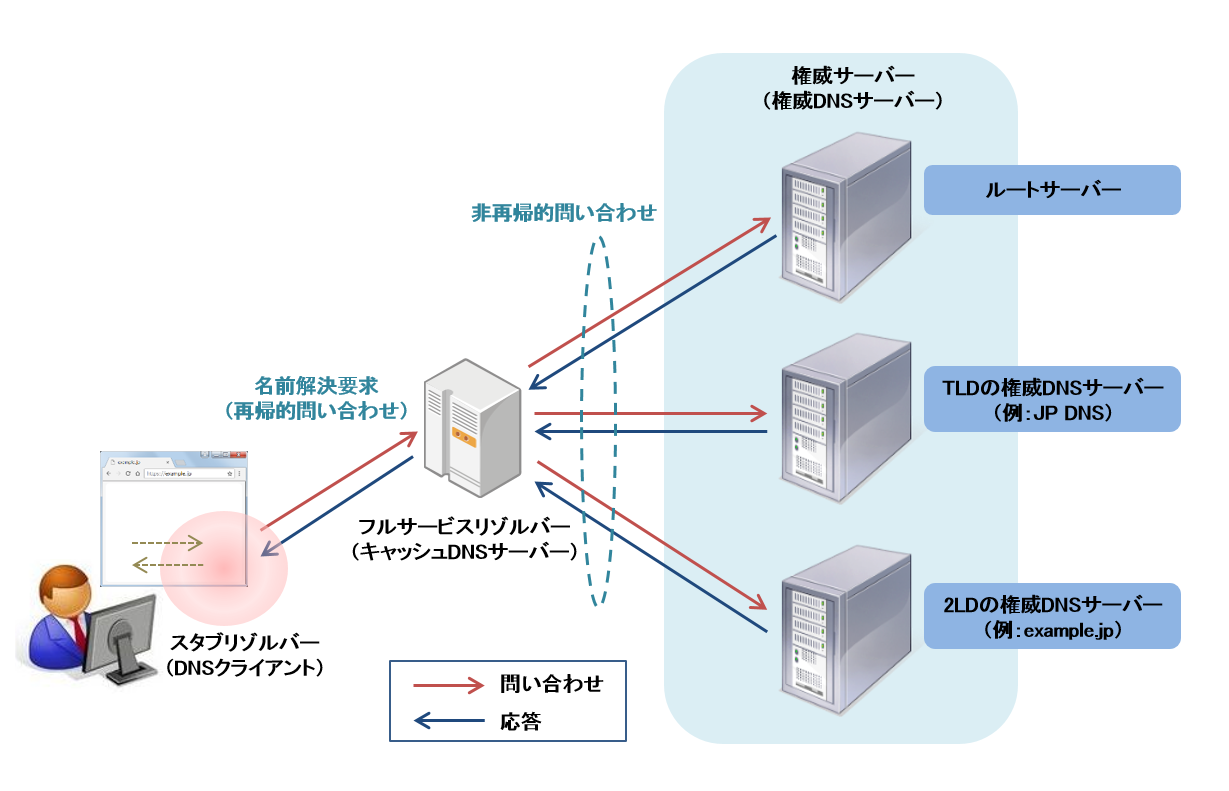
引用 https://jprs.jp/glossary/index.php?ID=0197
参考
https://ja.wikipedia.org/wiki/%E3%83%9B%E3%83%83%E3%83%97_(%E3%83%8D%E3%83%83%E3%83%88%E3%83%AF%E3%83%BC%E3%82%AF)
https://www.jstage.jst.go.jp/article/ieiej/30/8/30_615/_pdf/-char/en
https://ja.wikipedia.org/wiki/Domain_Name_System
ここで、インターネット上でやり取りする上で、global ip addressがないとできないのですが、それはルーターの機能でNAPTと言うprivate ip+portと一時的なglobal ipアドレスの対応表を作成する機能があり、さもglobal ipからの通信のように見せかけているからです。
またipを使用したプロトコルではMAC addressも必要ですが、arpと呼ばれるプロトコルを用いてmac addressとip addressを紐づけて保存しています。これはおそらくルーターが自動でやってくれています。正直よくわかってないです....
参考
https://ja.wikipedia.org/wiki/Address_Resolution_Protocol
その次に、getしたip addressを元にサーバーがどこにあるかrouterを経由して疎通を取ろうとします。
⋊> ~ traceroute google.jp 18:40:53
traceroute to google.jp (172.217.24.131), 64 hops max, 52 byte packets
1 192.168.3.1 (192.168.3.1) 2.807 ms 4.677 ms 1.543 ms
2 * * *
3 softbank221111179173.bbtec.net (221.111.179.173) 5.915 ms 5.717 ms 5.089 ms
4 * * *
5 209.85.149.253 (209.85.149.253) 6.230 ms 6.774 ms 7.489 ms
6 * * *
7 72.14.233.220 (72.14.233.220) 13.596 ms
172.253.66.202 (172.253.66.202) 8.361 ms
108.170.242.129 (108.170.242.129) 6.867 ms
8 108.170.236.25 (108.170.236.25) 5.519 ms
72.14.234.229 (72.14.234.229) 5.764 ms
108.170.242.144 (108.170.242.144) 6.765 ms
9 64.233.175.137 (64.233.175.137) 6.244 ms
nrt20s01-in-f3.1e100.net (172.217.24.131) 5.541 ms
216.239.43.157 (216.239.43.157) 63.412 ms
macのルーティングの設定を見てルーティングテーブルにのっとり、ホップしていく(どんどん聞いていく)
指定されたipアドレスのdestinationを見て一致したら、そのgatewayに向かって、通信を投げる(送り出す)
もしサーバーにたどり着いたらそこから通信が始まる。
なければ基本的にdefaultのrouteに飛ばされる。
MAXOSのルーティングテーブル↓ wifiをつなげると自動でdefaultのdestinationが書き換わる。不思議。
⋊> ~ netstat -rn 19:22:24
Routing tables
Internet:
Destination Gateway Flags Netif Expire
default 192.168.3.1 UGSc en0
127 127.0.0.1 UCS lo0
127.0.0.1 127.0.0.1 UH lo0
169.254 link#6 UCS en0 !
192.168.3 link#6 UCS en0 !
192.168.3.1/32 link#6 UCS en0 !
192.168.3.1 d8:f:99:c7:ae:35 UHLWIir en0 1195
192.168.3.3/32 link#6 UCS en0 !
224.0.0/4 link#6 UmCS en0 !
224.0.0.251 1:0:5e:0:0:fb UHmLWI en0
239.255.255.250 1:0:5e:7f:ff:fa UHmLWI en0
255.255.255.255/32 link#6 UCS en0 !
⋊> ~ man netstat
-r Show the routing tables. Use with -a to show protocol-cloned routes. When -s is also present, show routing statistics instead. When -l is also present, netstat assumes more columns are there and the
maximum transmission unit. More detailed information about the route metrics are displayed with -ll for TCP round trip times -lll for all metrics. Use the -z flags to display only entries with non-zero
RTT values. (``mtu'') are also displayed.
ルーティングの設定は、destination/gatewayの設定をするのが基本。
ここは動的に自動で設定さレルプロトコルがあるが、手動で設定もできる。
セッション層。
ここでは接続が途切れていないか、無事に繋がって通信できる状態かの確認をするレイヤーです。
ICMP→通信経路でえらってるか確認するプロトコル。
こんかいはあまり触れません。
トランスポート層
tcp/ip→これはあくまでプロトコル。実際にやり取りしたいデータをどうやってパケットに分割するとか、port番号を乗っけて通信を走らせるとかが定義されていここのプロトコルにしたがって通信が行われます。基本的にウェブブラウザの通信はtcpで行われます。
tcpの特徴として、正確なデータの送信が行われることが重視されています。
3ウェイハンドシェイクと呼ばれる方法で疎通を確認した後、シーケンス番号と確認応答番号を用いてデータの漏れがないようにデータのやり取りを行います。
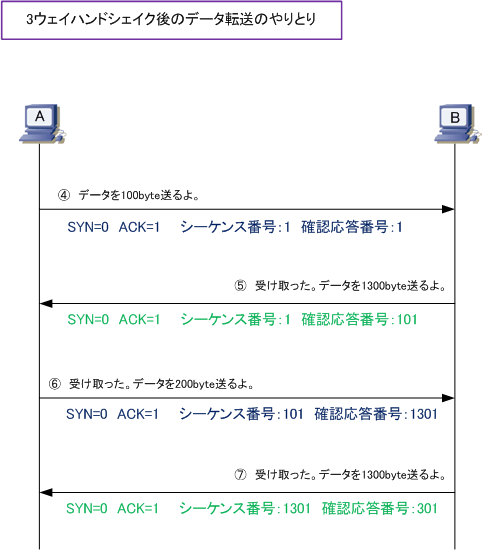
引用 https://www.infraexpert.com/study/tcpip9.html
ここでズレがあった場合、ズレがあった部分から再度リクエストをしたり、切断したりして正しいデータが確実に受け取れるようにします。
⋊> ~ arp -a 19:22:24
? (192.168.3.1) at d8:f:99:c7:ae:35 on en0 ifscope [ethernet]
? (224.0.0.251) at 1:0:5e:0:0:fb on en0 ifscope permanent [ethernet]
? (239.255.255.250) at 1:0:5e:7f:ff:fa on en0 ifscope permanent [ethernet]
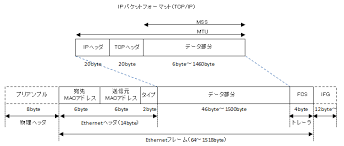
MAC adressやglobal ipはethernet frameに格納されている。
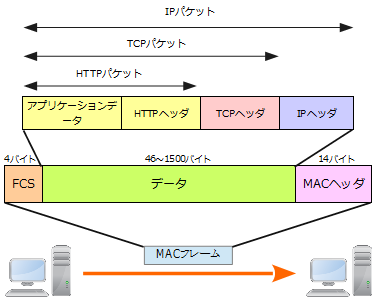
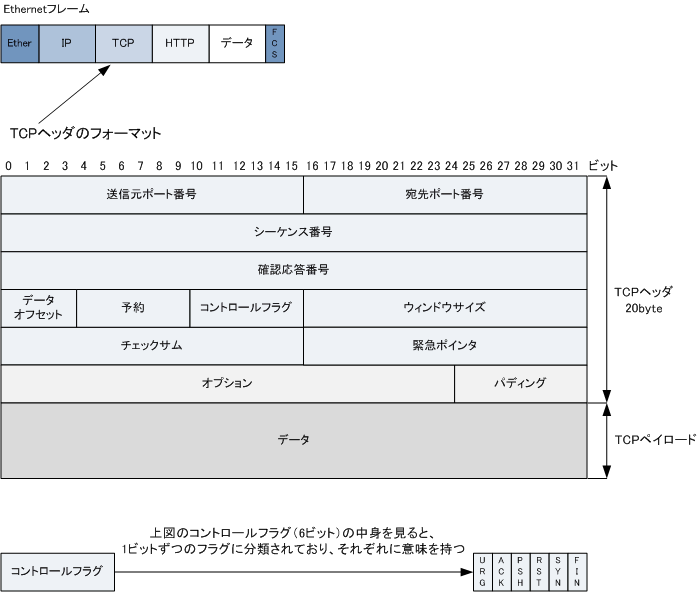
引用(google)
tcpヘッダ内部で、portの情報が格納されているから、ブラウザのプロセスに割り当てられたportに情報が届く。
アプリケーション層
tcpパケットのデータの中身に、HTTP headerとかbodyとかの情報が含まれている。なのでサーバーはそれを受け取ったら、それをサーバー側のプログラムで読み解き、それに対応したレスポンスを返します。
HTTPについて
やり取りされるデータは、HTTPメッセージと呼ばれる。 リクエストメッセージはリクエスト行・ヘッダーフィールド・ボディで構成され、レスポンスメッセージは、ステータス行・ヘッダーフィールド・ボディで構成される。
これの詳しい仕様はwikiがまとまってるので読んでください。
このような形式でリクエストを送る。
GET / HTTP/1.1
Host: google.com
Connection: close
[other headers]
大事なのは、xml/htmlなどのやり取りにおける、プロトコルであると言うことである。
headerに何をつけるとか、どうつけるかと言うのは正直細かすぎる話題な気がするので割愛する。
UIバックエンド
ウィンドウなどの基本的なウィジェットの描画に使用される。
下記に引用するように、select boxだとかのウィジェットを表示するために使用される。ブラウザのUIを変更する部分
The interface layer communicates with the data layer to retrieve data. The interface layer also communicates with the UI Backend to draw widgets as per requests by the HTTP Response body (our HTML source code). The browser engine communicates between the UI and the rendering/layout engine.
The final step is to paint the screen, wherein the render tree is traversed, and the renderer’s paint() method is invoked, which paints each node on the screen using the UI backend layer.
引用
https://dzone.com/articles/behind-browser-basicspart-1
https://www.browserstack.com/guide/browser-rendering-engine
JavaScriptインタープリタ
JavaScriptコードの解析と実行に使用される。
下記がブラウザに使われている。javascriptcoreについてはjsのinterpreterとしても使えるっぽい。
https://v8.dev/
https://developer.apple.com/documentation/javascriptcore
処理タイミングについて
制作者はパーサーが
<script>タグに達するとすぐにスクリプトが解析、実行されると想定しています。ドキュメントの解析はスクリプトが実行されるまで中断されます。スクリプトが外部にある場合は、最初にネットワークからリソースを取得する必要があります。この処理も同期的に行われるため、リソースを取得するまで解析は中断されます。
基本的にブラウザはシングルスレッドなので<script>がきたら逐一その部分をjavascript engineに投げてるっぽい。しかし実際はマルチスレッドでparseも行われているよう。
Webkit と Firefox のいずれもこの最適化を行っています。スクリプトの実行中に別のスレッドでドキュメントの残りを解析し、ネットワークから読み込む必要のある他のリソースを探して、読み込みます。このようにリソースの読み込みを並列接続上で行うため、全体的な速度が向上します。なお、投機的なパーサーでは DOM ツリーは変更せず、メインのパーサーに委ねています。外部にあるスクリプト、スタイル シート、画像などの外部リソースへの参照のみを解析します。
The model of the web is synchronous. Authors expect scripts to be parsed and executed immediately when the parser reaches a
<script>tag. The parsing of the document halts until the script has been executed. If the script is external then the resource must first be fetched from the network–this is also done synchronously, and parsing halts until the resource is fetched. This was the model for many years and is also specified in HTML4 and 5 specifications. Authors can add the "defer" attribute to a script, in which case it will not halt document parsing and will execute after the document is parsed. HTML5 adds an option to mark the script as asynchronous so it will be parsed and executed by a different thread.
qiitaの仕様のため<script>のように本文に`を足しています。qiita....
データストレージ
永続的なレイヤで、ブラウザではCookieなどさまざまなデータをハードディスクに保存する必要があります。
ブラウザのdeveloper toolsのapplicationsで見れるように、ブラウザはそのOSにcookiesなどの情報を格納しています。javascriptなら簡単にアクセスなどができます。
参考文献
https://www.html5rocks.com/ja/tutorials/internals/howbrowserswork/
http://cidermitaina.hatenablog.com/entry/2020/03/14/191419