はじめに
事業としてソフトウェア開発を行う企業にとって、自分たちの開発チームの生産性が十分に高いのか、あるいはそうでないのかについては大きな関心があります。
そのこと自体は、何かを計測し、改善するというのは営利企業としては健全です。一方で、ソフトウェアエンジニアリングの世界で「生産性の高さ」だと主張できる汎用性の高い指標は存在しません。こういった状況の中で、「生産性」を巡る議論は経営やビジネス部門とエンジニアチームとの間で繰り広げられ、場合によっては大きな不和や不信感につながることも珍しいことではありません。
今回は、エンジニアの開発生産性について、さまざまなステークホルダーと議論する上で把握しておきたいさまざまな論点について解説します。それによって、「我々が本当に議論すべきテーマは何か」についての共通認識をつくるための土台を構築することを目的としています。 もしかしたら改善したいことは「生産性」ですらないのかも知れません。後半にそのことも述べます。
記事についてのイベントをやります
開発生産性の議論はアイデンティティに届く刃である
開発生産性の議論をする上では、ある種の慎重さが要求されます。それはエンジニアチームにとってアイデンティティに届く刃だからです。経営者やステークホルダーにとっての何気ない開発効率に対する疑念は、それ自体がエンジニアの仕事に対しての不信感の表明につながりかねません。言い換えれば、あなたはちゃんと仕事をやっていないのではないかと攻めているように感じるということです。
人は、自身のアイデンティティに触れるようなテーマでの冷静な議論は難しくなります。そのなかで正しい認識に基づかない議論は、その後の冷静な会話を阻害してしまう可能性があります。雑で無理解な形での言葉の応酬が発生するとファクトを元にした改善をする上での関係性にひびを入れてしまいます。
もちろん、仕事における効率の数値化と可視化をやってしかるべきアクションです。先に触れたように業界を通じた生産性の一般指標がない中では、時に議論は乱暴になりかねず立場が弱い状況では、慎重にならざるを得ないことは想像に難くないかと思います。
「生産性」とはそもそもなにか
まず、最初に経営学的な用語としての「生産性」の定義を確認しましょう。日常会話的には、生産性が高いとは「効率的に仕事をしている」であるとか「テキパキと仕事をこなしているかそうでないか」というニュアンスで理解されています。
このような日常語としての感覚だけで生産性を評価してしまうと、あの人はいつもTwitterやSlackで雑談ばかりしているけど本当に仕事をしているのだろうかといった感覚的な不安感から、生産性が低いのではないかというあまり価値のない議論に発展してしまいます。
もしかしたら、その雑談は設計を決める上での重要な思考材料になっているかもしれませんし、Twitterで技術的な情報交換をしているかも知れません。
生産性という「数字」の議論にとっては、あくまで積み重ねたファクトを重んじるべきでしょう。
生産性とは何かを理解する上での基本的な式は次の通りです。
$$生産性 = アウトプット/インプット $$
この極めて単純な式は、何かインプットとなるリソースの量に対して、アウトプットされた量がどの程度なのかという比率が生産性であることを意味しています。
この、アウトプットとインプットに当てはまるものは実は数多くあります。
たとえば、
$$(物的労働生産性)=(生産量)÷(従業者数)$$
工場などで特定の製品を生産することが決まっている現場であれば、従業員の数に対してどれだけの量の製品を作ることができたかが物的労働生産性です。この場合、精算できた量が問題であるため、安い商品と高い商品などの区別はありません。単位は、[個数/人]です。テキパキと仕事をした方が多く作れるという生産性のイメージはこちらによって生まれているかも知れません。
$$ ((価値労働生産性)=(生産額)÷(従業者数)=((生産量)×(製品価格))÷(従業者数)$$
「価値労働生産性」であれば、従業員に対してどれだけの生産金額が得られたかを対象とします。この場合の単位は、(円/人)となり、生産に従事する一人あたりがどれだけの生産価値を創造したかを計ることになります。一方で、生産量だけしかみないため、販売部門などは含まれませんし、売れ残るケースなども評価されません。
別の例として、「付加価値労働生産性」というものがあります。
$$ (付加価値労働生産性)=(付加価値額)÷(従業者数) $$
この場合、実際に売れたことも含めて付加価値をどれだけ従業員が生み出しているのかを意味しています。付加価値労働生産性は、利益や減価償却などを無視したときに従業員ひとりあたりに支払える限界の人件費とも捉えることができます。
時折、ニュースなどで日本の生産性が低いなどと言われるときの生産性は、「付加価値労働生産性」のことです。
これは人の手間がかかる割に、粗利の小さいような商売だと小さくなってしまいます。一方で、従業員の数にかかわらず仕組みが一定程度売上をつくってくれるような事業で従業員が少ないのであれば労働生産性は高くなります。
また、物価高などに連動して価格に転嫁をした場合は、生産性は高くなりますし、逆に物価高にもかかわらず仕事を増やして値段を据え置きにした場合は生産性は低くなります。
つまり、会社全体のビジネスモデルがどれだけ付加価値をつくりやすい仕組みであるのかが強いファクターであり、ひとりひとりテキパキと仕事をがんばってこなしている度合いはあまり大きなファクターではありません。
また、これまでの物的労働生産性や価値労働生産性とは異なり、生産部門だけの評価ではなく、企業全体の評価である点にも注意が必要です。前者2つは、「製造することができれば売れた」時代の評価基準であり、生産部門の評価にも使うことができましたが、マーケティングやブランド戦略に応じてオンデマンドでの生産に価値が移っていくと生産現場にとっても唯一の基準とは言えなくなってます。
日本の労働生産性という数字の低さを持って、仕事の頑張り方が悪いという話につなげるのは、端的に間違いです。その仕事内容やビジネスモデル自体を見直すべきときだという理解の方が適切だといえます。
「開発生産性の議論」における混乱
生産性を議論する上で、インプット(分母)がなんであるか、アウトプット(分子)がなんであるかによって見える景色ががらりと変わることがわかりました。ということは、これらの分子分母がなんであるかを正しく定義できないままの議論では意味がありません。これは、ソフトウェア開発の生産性においても同様です。
ソフトウェア開発における開発生産性を考える上で、一般的に考えられるインプットとアウトプットのパターンについてそれぞれ検討していきましょう。開発生産性を立式するに当たって考えられる主なパターンは次の通りです。
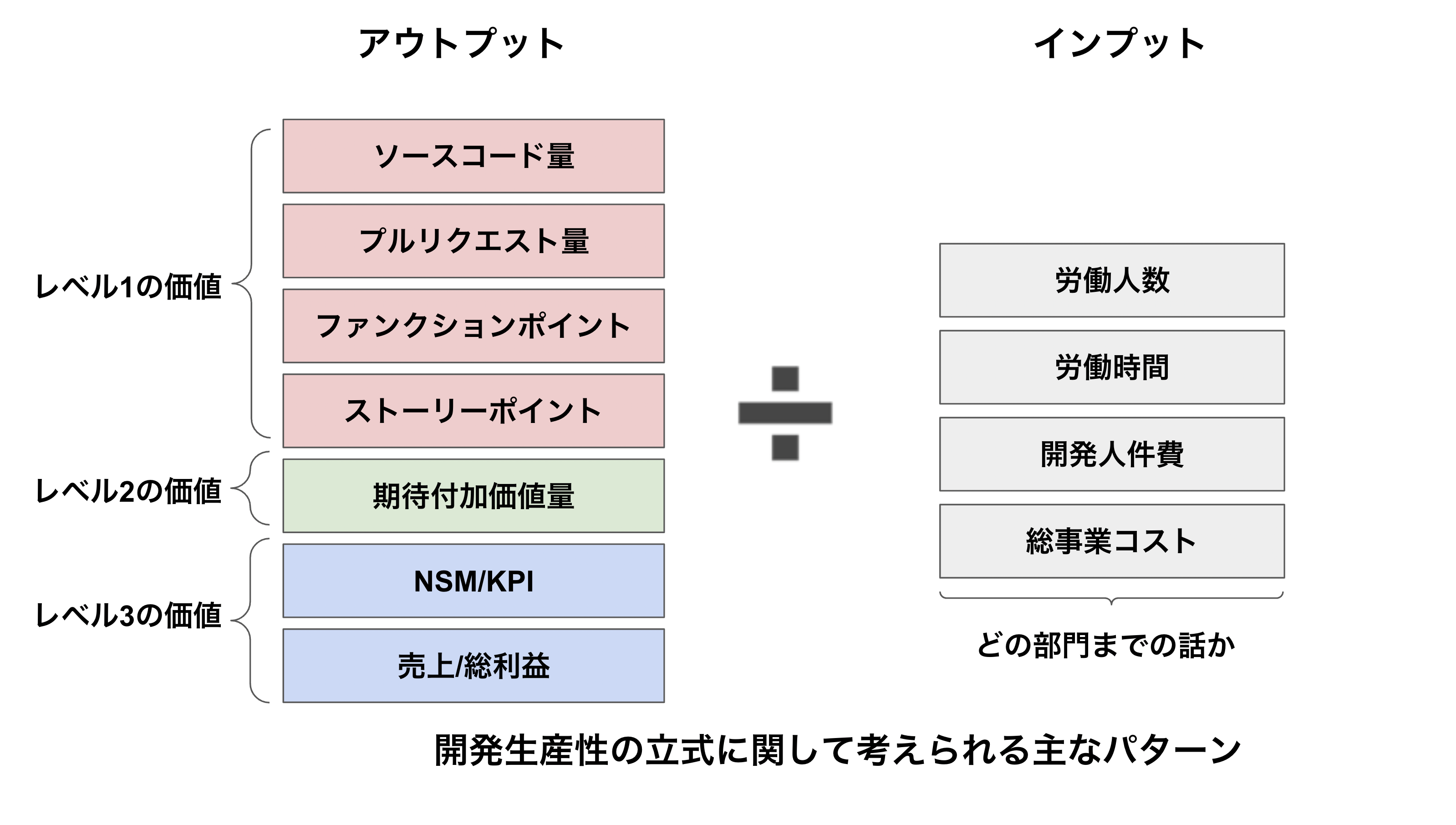
それぞれについて詳細に見えていく前に、開発生産性の持つ構造を観察していきましょう。
開発生産性の3階層
開発生産性を考える上で、3つのレイヤーで生産性を捉えるとわかりやすくなります。
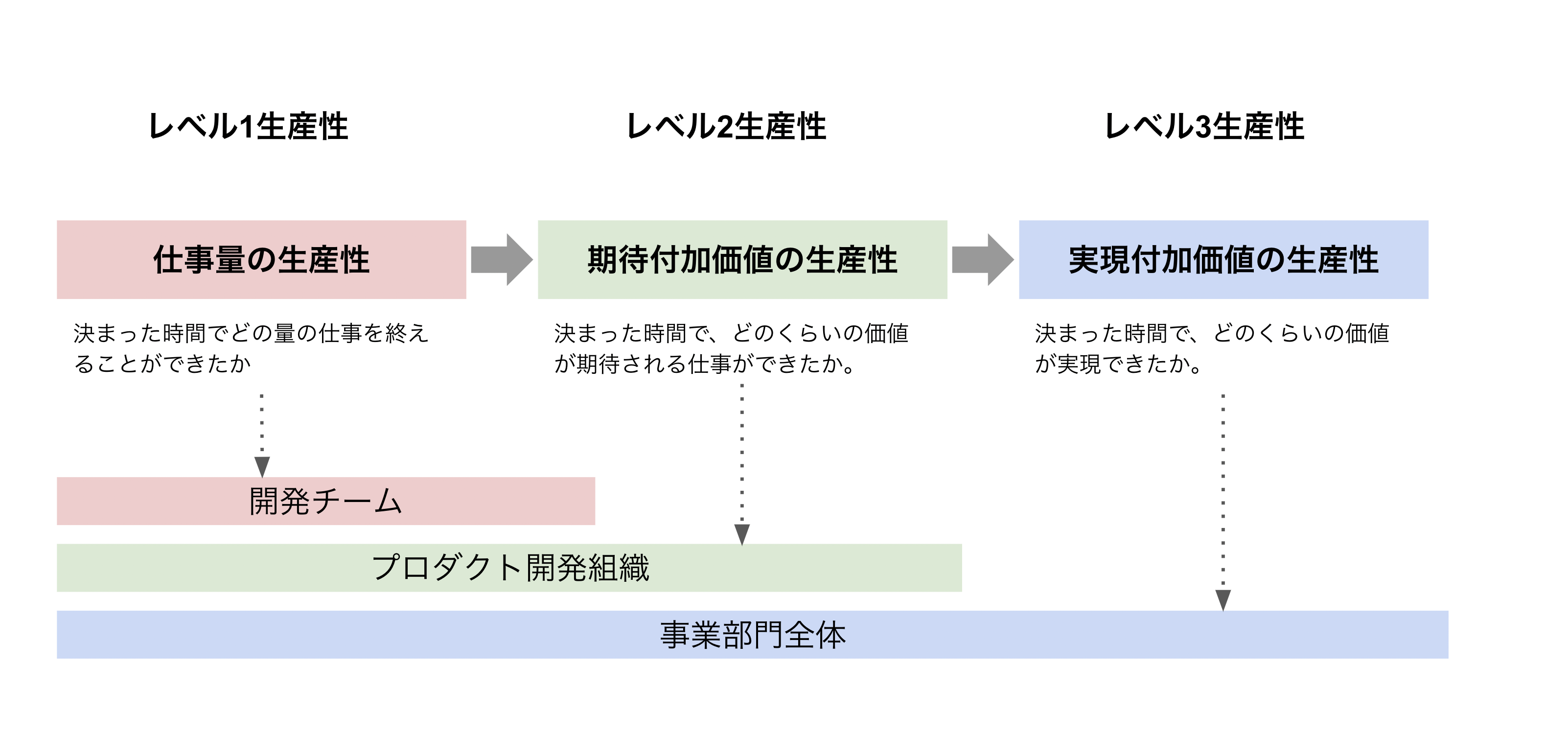
レベル1:仕事量の生産性
一段階目が、仕事量の生産性です。これは、その仕事の価値や売上貢献などはいったん置いておいて、作業量としてどの程度の仕事をこなすことができたのかを評価する生産性です。仕事量の生産性が十分高くても、レベル2以降の生産性が高いとは言えませんが、少なくとも作業の効率が悪いというわけではないことを評価するために使います。これは、一開発者やエンジニアリングチームでも改善がしやすいため、まずはこういった生産性に注目することが多いです。
レベル2:期待付加価値の生産性
二段階目が、期待付加価値の生産性です。これは、仕事量だけではなく個々の施策がどの程度プロダクトにとって価値があることなのかを踏まえて評価したい場合に使います。しかし、現実的にはリリースした施策にどの程度の価値があったのかを評価するのには時間がかかります。そのため、プロダクトチーム全体で価値があると「期待している」施策がどの程度リリースできたのかに注目することで、プロダクト開発に関する効率の良さやコストパフォーマンスの良さを評価する為に使います。この点は、施策を考え決めていくプロダクト開発組織全体のアウトプットを評価することに用いることができます。
レベル3:実現付加価値の生産性
三段階目が、実現付加価値の生産性です。これは、売上やKPIなどの実際のサービスに対しての貢献を評価するときに用います。この生産性は、開発チームやプロダクト開発組織だけでなく、カスタマーサクセスやセールス、マーケティングなど事業に関わる様々な部門の全体の貢献によって実現されます。多くの場合、遅行指標になるため、最終的な判断には使うことができますが、リアルタイムな評価には不向きです。
開発生産性とひとくちに言っても、このような三階層を意識した上で議論することが重要です。
開発生産性の3階層とビジネスコミュニケーション
「開発生産性」を議論する上では、レベル1からレベル3までの生産性を区別して理解することが重要です。
レベル1では、エンジニアが効率的な開発環境を構築できているか、必要なスキルを習得できているか、サービス自体が良い構造を持っているかなどが影響を与えるファクターになります。一段上がったレベル2では、正しいタスクを選択でき、優先順位を付けることができるかが重要です。また、そのタスクを正しく完了できるかも指標となります。そして、レベル3では、そのタスクが実際にビジネスの目標に貢献できているかが指標となります。
そのため、エンジニアの生産性を捉える上では、各レベルを把握して、それぞれについて指標を設けることが重要です。また、より高次な生産性を上げるためには、個々のエンジニアのスキルやタスクの選択に加え、チームや事業全体でのコミュニケーションやプロセスの改善も検討する必要があります。
たとえば、自動車をつくっている工場に対して、「売上が低いから生産性が低い」と考える人はいませんよね。生産量が十分にあるのに、販売戦略に問題があって売れていない場合などであれば、工場にその話をしてもどうしようもありません。
もちろん、製品が売れすぎて生産量を増やさないといけないときに、生産量がボトルネックになっていたら自動車工場の効率が売上につながるはずですので、そういうときは生産量に注目し「他の同じような工場に対して生産量が低いから生産性が低い」と言われる分には改善の余地がありそうです。
このようにビジネスモデル毎に売上や企業価値につながる様々なファクターには段階が存在して、適切な理解の元コミュニケーションをしないと「何言ってるんだこいつは」となってしまいます。
こんなことは常識だと思われるかも知れません。
ところがソフトウェアエンジニアリング機能を必要とする事業をやっているにもかかわらず、それと同じようなレベルでしかエンジニアの生産性について捉えておらず、
- 「エンジニアがたくさんいるのに売上が上がらないのはエンジニアがさぼっているからだ」
- 「すべて完成すれば必ず売れるはずなのに、完成させられないのはエンジニアのレベルが低いからだ」
というようにエンジニアの生産性というブラックボックスに問題を転嫁してしまうような事例をよく耳にします。
経営層から見ると、すべてはレベル3の結果が重要だという視点になります。そのため、何を評価するにおいても実現付加価値についてに注目してしまいます。一方で、エンジニアからみると生産性の議論はレベル1の話に聞こえます。タスクの生産性をあげることが自分たちのできる効率化の限界であると捉えてしまいがちです。
レベル3の生産性が低いからと言って、レベル1の生産性が低いわけではないのですが、そこを短絡化した議論がなされてしまい、コミュニケーションはあらぬ方向へ進んでしまいます。
開発生産性におけるインプットは何か
開発労働生産性におけるインプットとして考えられるものは、大まかには次の4つがあります。
- 労働人数
- 労働時間
- 開発人件費
- 総事業コスト
労働人数
もっともわかりやすいものは、労働人数です。5人のチームであれば5というように、ヘッドカウントを分母に据えることは、計算を単純化します。一方で、週一日だけコミットしているとか、複数のプロジェクトに兼務しているとかは考慮の対象外です。
労働時間
次にインプットとして考えられるのは、労働時間です。単位は人月や人日などです。わかりやすく計算しやすいためよく用いられます。
しかし、注意する必要があるのは、年収1500万の1人月も、年収500万の1人月も等しく扱われる点です。
飽くまでヘッドカウントに対してどれだけの効率があがっているかを捉えるためには労働時間を基準にするのが良いでしょう。
細やかな注意としては、人月や人日で扱うのか、総労働時間で扱うのかについても重要です。総労働時間で扱う場合において、同様のアウトプットを基準で考えるとき残業が多くなればなるほど生産性は下がります。一方、人月や人日で扱うのであれば残業をしてアウトプットが多くなった場合、インプットが同じ値のため生産性は上がることになってしまいます。
開発人件費
次に考えられるのが、開発人件費全体です。分母が円になるため、1円あたりのアウトプットを評価することができます。
一方で、ここには「クラウド利用費用」「ツール/サービスの利用料」は含まれません。そのため、より効率的に設備への投資をした方が生産性は上がります。また、同じ生産量であれば、できるかぎり安い人件費の人材に仕事を移した方が効率が良くなります。
総事業コスト
人件費だけでなく、関連する設備や販売費用、マーケティングコストやカスタマーサクセス、セールスなどの事業に関わる全ての費用を対象に見ることもあります。ビジネス全体として資本生産性や費用対効果などを見る上では、重要になります。
どの部門までインプットを含めるべきか
多くのほとんどすべてのソフトウェアビジネスは、ソフトウェア開発者だけでは成立しません。ある種の価値実現を行うためには、プロダクトマネージャーやエンジニアリングマネージャ、QAチームなどとの連携が必要不可欠になります。さらに価値実現のためには、CSチームやセールス部隊との戦略の一致がなければ、結果に繋がらないということもめずらしくありません。
次に述べるアウトプットと対応関係をもったインプットでなければ、意味がないどころか自分の力では影響を及ぼし難いファクターの責任を取らされているような気分になりモチベーションが下がることにつながりかねません。
開発生産性における「アウトプット」とは何か
次に開発生産性におけるアウトプットについてです。インプットに比べて、開発生産性におけるアウトプットは多様なパターンが考えられます。
たとえば、次のようなものが考えられます:
- ソースコード量(SLOC)
- ファンクションポイント量
- プルリクエスト量
- ストーリーポイント量
- 期待付加価値の量
- NSM( North Star Metrics )やKPIへの貢献
- 売上や粗利益額
それぞれについて見ていきましょう。
ソースコード量(SLoC:Source Lines of Code)
ソフトウェアの生産量を考える上で、ソースコードの行数(コメントや空行などを除いた実効行数:実効SLoC)は1つの指針です。しかし、SLoCを基準に生産量の議論をすることはエンジニアにとっては違和感があるのではないでしょうか。
それには、次のような理由があります。
コードの質を無視する : ソースコード行の行数を見ることで、生産性を評価する場合、コードの質を無視することになります。コードの質が悪い場合、多くの行を書くことでも、実際の作業量は少なくても、生産性が高く見えることがあります。
可読性を無視する: ソースコード行の行数を見ることで、生産性を評価する場合、可読性を無視することになります。可読性が高いコードは、少ない行数でも、実際の作業量は多くても、生産性が高く見えることがあります。
コードの冗長性を無視する: ソースコード行の行数を見ることで、生産性を評価する場合、コードの冗長性を無視することになります。冗長なコードは、多くの行を書くことでも、実際の作業量は少なくても、生産性が高く見えることがあります。
デザインパターンやライブラリを使用する場合に不公平になる: ソースコード行の行数を見ることで、生産性を評価する場合、デザインパターンやライブラリを使用する場合に不公平になります。デザインパターンやライブラリを使用することで、複雑な処理を簡単に実装することができますが、そのためには、少ない行数で実装することができることがあります。
通常、人類がつくる物理的な構造物というのは、同じようなパーツをたくさん組み合わせることで、1つの大きな構造物を作り上げます。一方でソフトウェアは、同じパーツはコピー可能であり、再利用可能でもあるため、常に新しい要素がどこかしらに入るという性質を持っています。そのため、ソースコードの量をひとつとっても作業の単位として捉えることが難しいのです。
以下の図表は、ソフトウェア開発データ白書2018-2019およびソフトウェア開発分析データ集2022から抜粋してご紹介します。
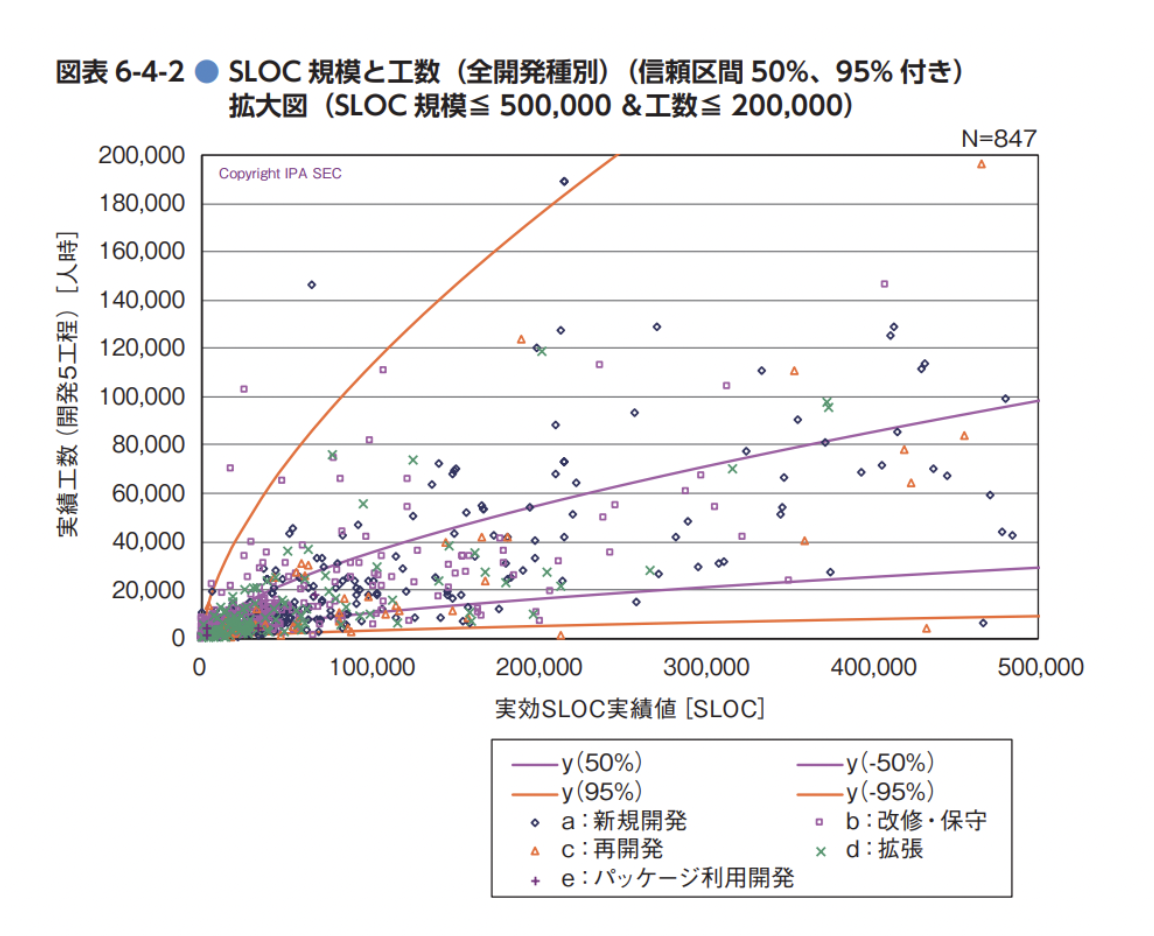
実際に数多くのプロジェクトにおけるコード行数と工数の関係を見ると、大きなばらつきがあることが確認できます。この点からもSLOCを生産性の指標に使うことが難しいことが理解できます。
一方で、ソースコード行数と工数のそれぞれついて対数をとったグラフを見てみましょう。

概ね、直線上に並んでいることが見て取れます。このことから言えることは、ソースコード行数は、生産性の指標に使うにはばらつきが多いが、システムの規模感を見る上ではSLOCの対数(つまり桁の数のレベル)においては一定の推論に使えそうだということです。
このような特性を利用して、ソースコード行数から工数を見積もるCOCOMOと言う手法があります。
$$ 開発工数 = a *実効コード行数^b $$
このようなパラメトリックな手法は、開発規模等のパラメータからおおよその工数規模を推論するためには使えますが、厳密なプロジェクト管理に使う際は、タスク分解をした上で見積もる必要があります。
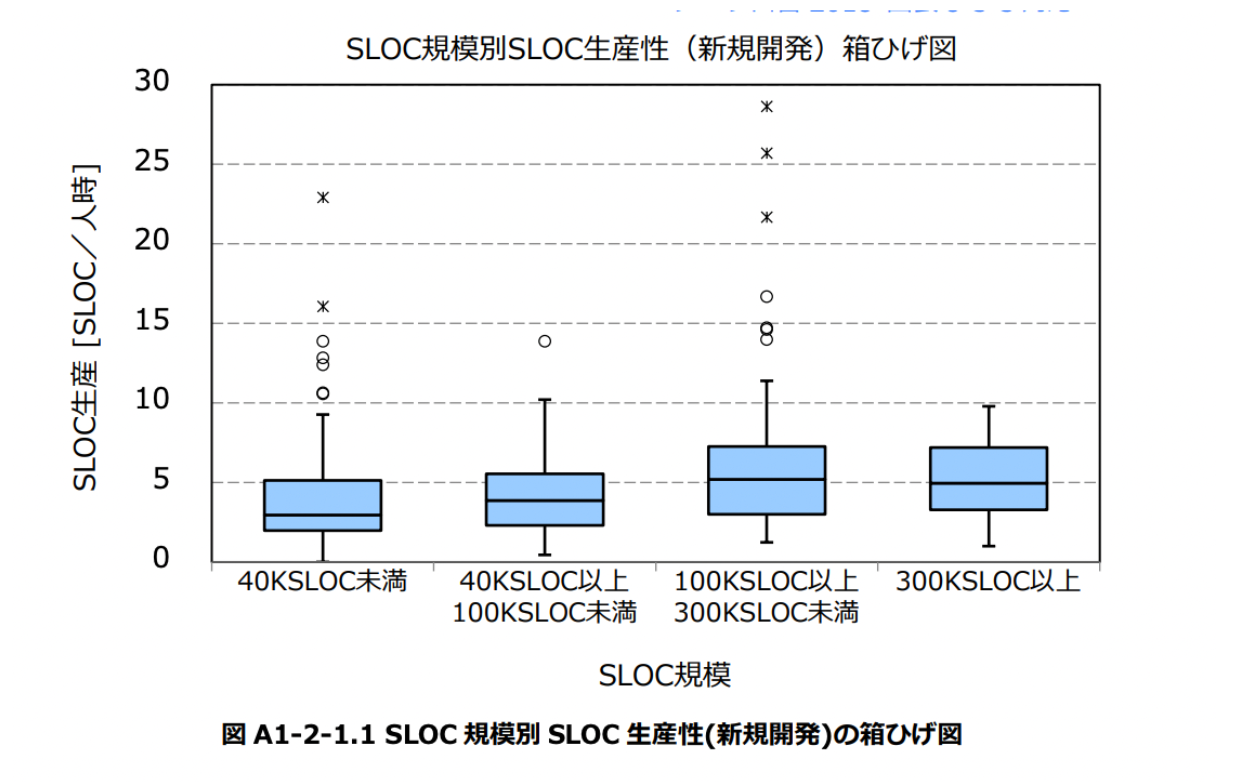
また、これも意外な数字と感じるかも知れませんので、掲載しておくとプロジェクト全体を通じて、1時間あたり一人が書いているコード行数はたかだか数行で多い場合でも数十行だということです。
これは日本のエンジニアが怠けているからでも実力が乏しいからでもなく、ソフトウェア開発におけるソースコードの記述の背後に様々な工数がかかっていることが多いからでしょう。
プルリクエスト量
プルリクエスト(PR:Pull Request)とは、GitHubやGitLabなどのソースコードマネジメントサービスで使われる機能です(GitLabではMerge Requestと呼ばれている。以下PRと呼ぶ)。プルリクエストを使用することで、他の人が作成したコードをレビューし、マージすることができます。このPRの単位を生産性の評価指標に使うことがあります。
PRの数を用いて生産性を評価するのは、GitHubなどからデータを取ることができるため、測定が簡単であるというメリットがあります。
しかし、デメリットもあります。PRの作業サイズがバラバラであるため、生産性の指標として扱いづらいです。また、PRの作業粒度を細かくすること自体が目的化しかねない点も、PRの数を用いた生産性の評価において懸念される点です。
一方で、プルリクエストのサイズはバラバラであることが多いものの、少なくとも1つのマージ可能な単位のタスクが完了したことを意味するため、ばらつきが小さいとされます。さらに、PRやブランチの命名規則などから、大きい単位の作業と小さい単位の作業を区別して記録するなどの工夫で、おおよその作業サイズをそろえて扱うこともできます。
また、PR自体を目的化してしまうデメリットについては、その扱い方によるところも大きいため、一概には言えません。しかし、一般に作業サイズを細かくした上でレビューを受けることは、開発の品質を上げる上で良いことが多いとされます。そのため、プルリクエストの数が増えること自体は望ましいとされます。様々な指標との合わせ技で評価することで、デメリットにはならないかもしれません。
そのため、EI(エンジニアリングインテリジェンス )のサービスでは、プルリクエストの数をトラックしています。これにより、開発チームのテンポを良くするだけでなく、開発生産性にも寄与すると考えられています。
以下が、PRをベースに開発効率を可視化することができるツールの実際の事例です。
開発のテンポの良さを可視化する上では、PR数を見ることは価値があります。また、開発のテンポの良さは、開発組織の良い兆候の1つですので、ある種の健全さ指標としても用いることができるでしょう。
デプロイ数とPR数
プルリクエスト数の代わりにデプロイ数を見る場合もあります。デプロイの数は、GitHubフローを採用し、mainへのマージすなわちデプロイという状況であれば、違いがあまりないのでそこまで注目する必要がありあせん。しかし、リリース前の承認が必要だったり、定時/週次リリースなどをしている状況だったりすると数字が低くなってしまいます。これは、CI/CDパイプラインが未成熟だったり、安全な開発がしにくい環境であることを暗に示唆していることがあるため、あえてデプロイ数に注目することでDevOps的な環境の成熟度も評価することにつながります。これが Four key Metricsと呼ばれるDevOps指標の1つにデプロイ数がある理由だったりします。
コード品質の評価と健全化指標
ソースコードや、PRといった形でのアウトプット量に注目するとき、同時に課題になるのは、量が増えたけれども品質に影響を与えていないのかという疑念です。このように、ある指標に注目したときに、それが健全な形でアウトプットされているかを評価するための指標のことを「健全化指標」と言います。健全化指標は、ある一定の値で安定していることを評価するような指標のため、生産性に応じて右肩上がりになるような指標ではありません。この値が一定の基準を超えていないのであれば、十分に良いアウトプットができていると見なすための指標です。それには次のようなものが考えられます。
- デプロイ失敗率
- バグ件数
- MTTR(Time to restore service)
- 複雑度
- コードカバレッジ
各項目については、ここでは深く触れません。「アジャイルメトリクス」などの書籍を参考にしてみてください。
ファンクションポイント量
ファンクションポイント法は、1979年にIBMのアラン・J・アルブレクト(Allan J. Albrecht)が提案した作業量の見積り手法の1つです。
この手法では、あるプロジェクトを完了するために必要な作業量を、特定の要素(例えば、入力フォームやレポートなど)の数や、それらの要素がどの程度複雑であるかを基に決定します。ある程度、ソフトウェア機能の性質からタスクを類型化することで、統計的に取り扱いやすい数字になります。
ファンクションポイントは、プロジェクトの規模や複雑さを推定するためによく使われます。「ソースコードの行数」や「ファイルサイズ」はシステム要件がほぼ固まった段階や実装後でないと計算できず、また開発環境や運用環境に依存するため、客観的な指標として扱いづらいという欠点がありました。しかし、ファンクションポイントであれば、それらに左右されずに決定することができます。
そのため、プロジェクトを完了するために必要なリソースや期間をより正確に推定することができるため、プロジェクトマネージャーがプロジェクトを適切にプランニングし、スケジュールを立てることができるとされています。一方、ソースコード量を評価することに比べて、都度人による見積もりが必要になるため、常に評価できるとは限りません。
1986年に米国IFPUG(International Function Point Users Group)が設立され、国際的な普及・定着を図っています。日本では1994年に日本ファンクションポイントユーザ会(JFPUG)が設立されています。また、ISO/IECでは、ファンクションポイント法をベースに「機能的規模見積り技法」の標準化作業が進められているなど各方面で採用されています。
ファンクションポイントの規模と工数のグラフを以下に示します。
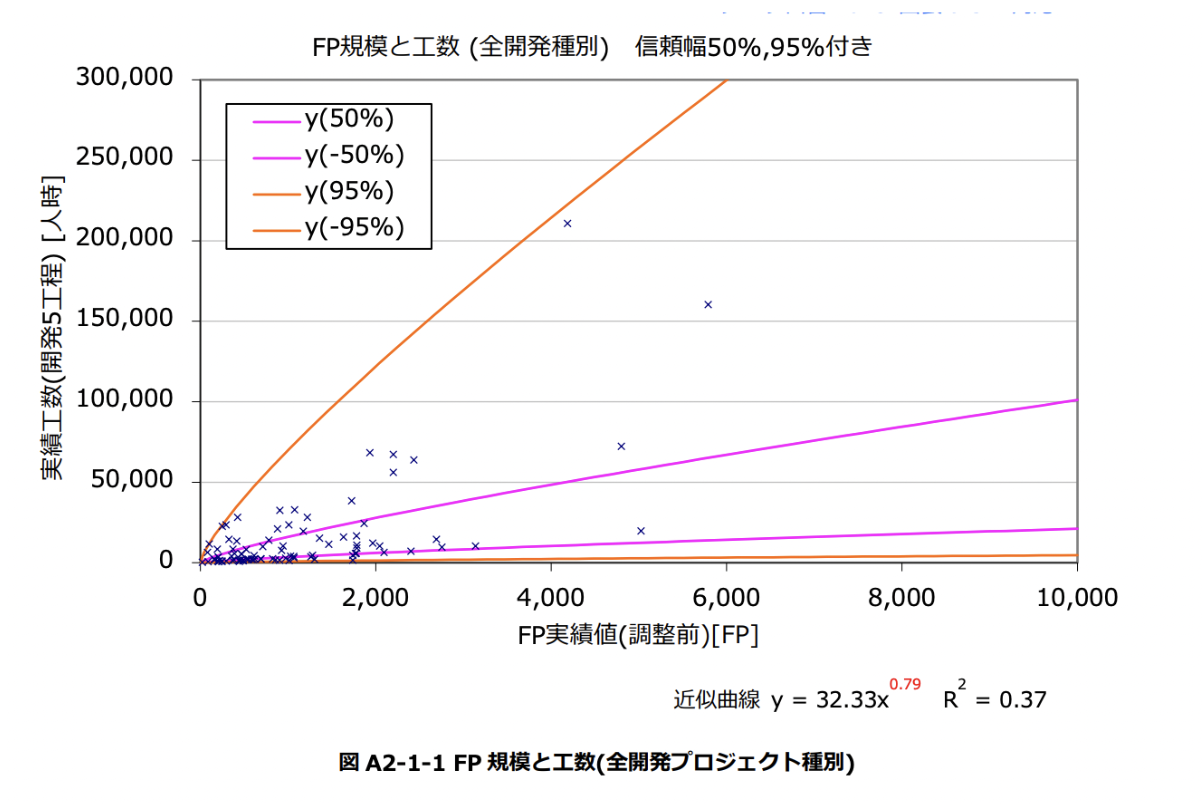
このようにすると、SLOCよりは若干良さそうにも見えますが、大差ないようにも見えます。両対数で見てみましょう。
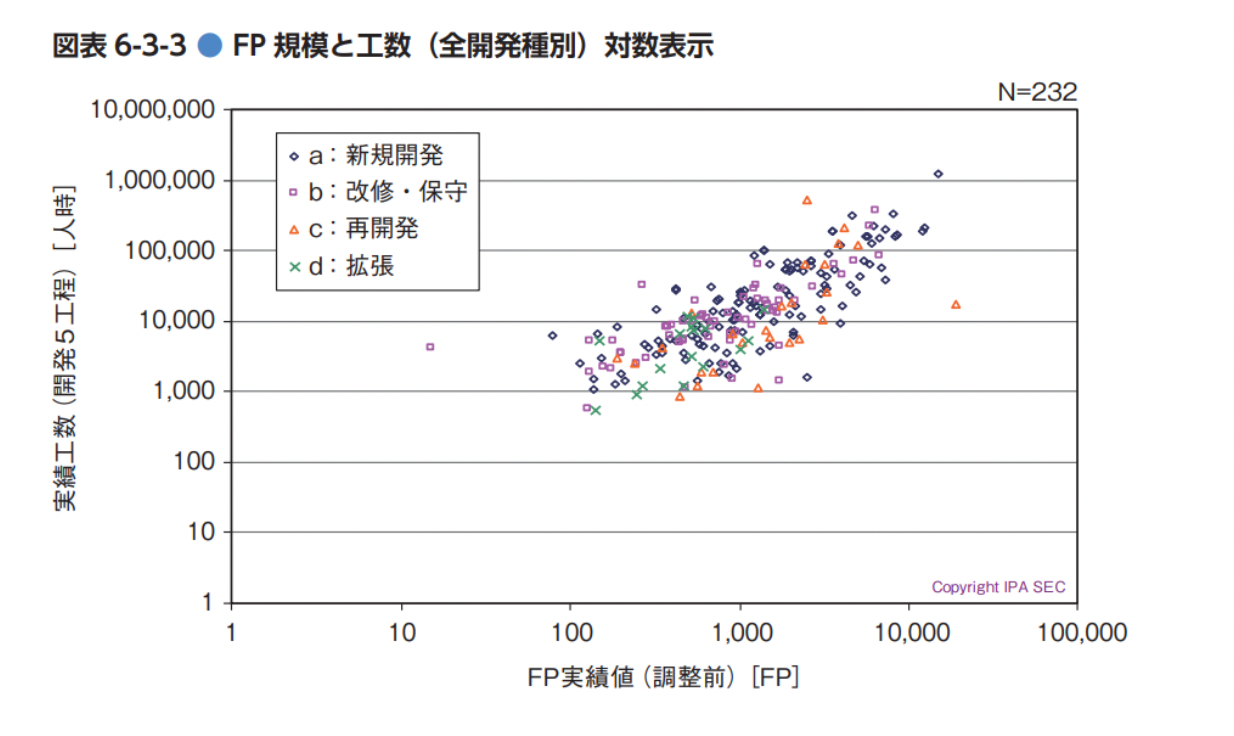
ストーリーポイント量(ベロシティ)
アジャイル開発において、ストーリーポイントは、プロダクトを開発する際に、そのプロダクトの要件を表す単位です。ストーリーポイントは、そのプロダクトに対して、どの程度の難易度であるか、どの程度の重要度であるかを表すことができます。
ストーリーポイントは、アジャイル開発において、プロダクトバックログと呼ばれる、プロダクトの開発に必要な機能を記述したドキュメントに記載されます。プロダクトバックログは、プロダクト開発のスプリントプランニングで使用され、各スプリントで実装する機能を決定するために使われます。
ストーリーポイントは、プロダクトの開発に必要な作業量を推定するために使われることもあります。これにより、プロダクトを実装するために必要なリソースや期間をより正確に推定することができます。
ストーリーポイントを決める方法として、主に相対見積もりと絶対見積もりの2つがあります。これらは誰か有識者が見積もると言うよりもチームの単位で決めます。
相対見積もり: 相対見積もりは、以前に開発したプロダクトの機能と比較して、新しいプロダクトの機能の難易度を推定する方法です。例えば、以前に開発したプロダクトの機能が、ストーリーポイントで2であったとします。そのとき、新しいプロダクトの機能が、以前のプロダクトの機能よりも2.5倍も複雑であるとすると、新しいプロダクトの機能を表すストーリーポイントは、5となります。このとき、大きさの粒度としてフィボナッチ数列(1、2、3、5、8、13、21)を用いることがあります。
絶対見積もり: 絶対見積もりは、新しいプロダクトの機能を、それ自体で評価して、その作業量を推定する方法です。例えば、新しいプロダクトの機能が、以前のプロダクトの機能よりも複雑であるとすると、その作業量を推定することで、新しいプロダクトの機能を表すストーリーポイントを決めることができます。理想日や理想時間(ミーティングなどを含まない理想的な作業時間でどの程度か)で見積もります。
ストーリーポイントをあるスプリントでどの程度、開発完了することができたのかを「ベロシティ」と呼びます。ベロシティは、それを用いて残りのスケジュールを予測するのに使われます。
しかし、一般的にストーリーポイントの付け方はチームによってまちまちです。そのため、 チームを横断してベロシティを用いて開発のアウトプット量だと見なすことはできません。 あくまで、チームのアクティビティの安定性を見極めるかの指標として用いられます。数字が大きいほど良いと言うよりも、安定しているほどよいと考えます。そのため、一般的にはストーリーポイントを生産性のアウトプット指標に使うことは難しいあるいは良くないことだと考えられています。
期待付加価値のスコアリング
実際の作業量や機能だけに注目してアウトプットを設計すると、実際に意思決定者やプロダクト部門との関連性が見出しづらくなります。プロダクト機能の観点からは、価値につながりづらいが、見積もりされたタスクが多いと、開発チームの価値貢献が見えづらくなってしまいます。
そのため、作業量ではなく、実際の価値貢献を元にアウトプットを設計したくなります。しかし、それには問題があります。実際にリリースされてみるまでは価値検証ができないのです。そうなると、生産性を測るという目的では遅行指標になりすぎてしまうリスクがあります。
こういったリスクを避けるために価値実現そのものの成果をみるのではなく、事前にどの程度の価値がある機能なのかという「期待」の段階で評価を行い、その期待の価値ポイントがどの程度の量リリースすることができたのかを測定するという手法が考えられます。
これらの「期待付加価値」のスコアリングは、プロダクトマネジメントにおける優先順位評価の手法をほぼそのまま用いることができますので、いかに2つのシンプルな期待付加価値のスコアリング手法をご紹介します。
RICE スコア
RICEは、プロダクトマネジメントで優先順位付けを行うために行われる一般的なスコアリングモデルです。RICEは、4つの要素を考慮して、特定のプロジェクトや作業の重要度を評価することができます。これらの要素は次のようになります。
Reach(0~5): この機能追加がどの程度多くの人に影響を与えるかを示す指標です。
Impact(0-5): この機能追加がどの程度大きな影響を与えるかを示す指標です。
Confidence(1-5): この機能追加が成功する可能性を示す指標です。
Effort(1-5): この機能追加を実行するのに必要な工数を示す指標です。
各要素の評価値として、0から5までの数字がどの程度の影響であるのかを別途決めておきます。細かく数字にするよりも、ざっくりと考えられる幅で設計することで迷いづらくなります。
RICEスコアリングモデルでは、各要素に対してスコアを付け、それらを加算して最終的なスコアを算出します。最終的なスコアが高ければ、そのプロジェクトや作業は優先順位が高くなります。
例えば、新しい機能を開発するプロジェクトを考えます。このプロジェクトに対して、次のようにスコアを付けることができます。
Reach: 4 (新しい機能は多くのユーザーに利用されると予想される)
Impact: 5 (新しい機能は、ユーザーの作業効率を大幅に向上させると予想される)
Confidence: 3 (新しい機能は、過去に似たような機能を開発した経験があるため、成功する可能性は高いと思われる)
Effort: 2 (新しい機能は、比較的単純なものであるため、実装するのに必要な労力は比較的少
上記の例では、各要素に対してスコアを付けました。次に、これらのスコアを加算して最終的なスコアを算出します。最終的なスコアは、次のようになります。
$$(Reach * Impact * Confidence) /Effort =( 4 * 5 * 3) /2 = 30$$
このようにRICEスコアリングモデルは簡易的なコストパフォーマンス評価ができます。優先順位を設計する際には、この値を用いて数値の高い順に取り組むことで、開発リソースを無駄にせず価値あるものの実現に時間を使うことができます。
また、今回評価したいのは、費用対効果ではなく「効果」の方なので、Effortで除算せずに:
$$(Reach * Impact * Confidence) =( 4 * 5 * 3) = 60 $$
という値をそのままアウトプットの値として使うのがよいでしょう。
加重スコアリング
加重スコアリングは、RICEのスコアリングモデルをもう少し柔軟に複数の要素を同時に考慮した上で、それらをスコア化し、ランキングや重要度を決めるために使われます。
加重スコアリングでは、まずカテゴリーに対して重要度を決めます。この重要度は、その要素がビジネスの目標達成にどの程度寄与するかを示すものです。そして、各要素に対してスコアを付けます。このスコアは、その要素がどの程度の条件を満たしているかを示すものです。最後に、重要度とスコアを掛け合わせることで、各要素の最終スコアを求めます。
加重スコアリングを使うことで、プロダクトマネジメントにおいて、複数の要素を同時に考慮した上で、優先順位や重要度を決めることができます。また、加重スコアリングを使うことで、各要素の条件や達成度を比較することができるため、プロダクト開発やビジネス戦略の策定などで役立つことがあります。
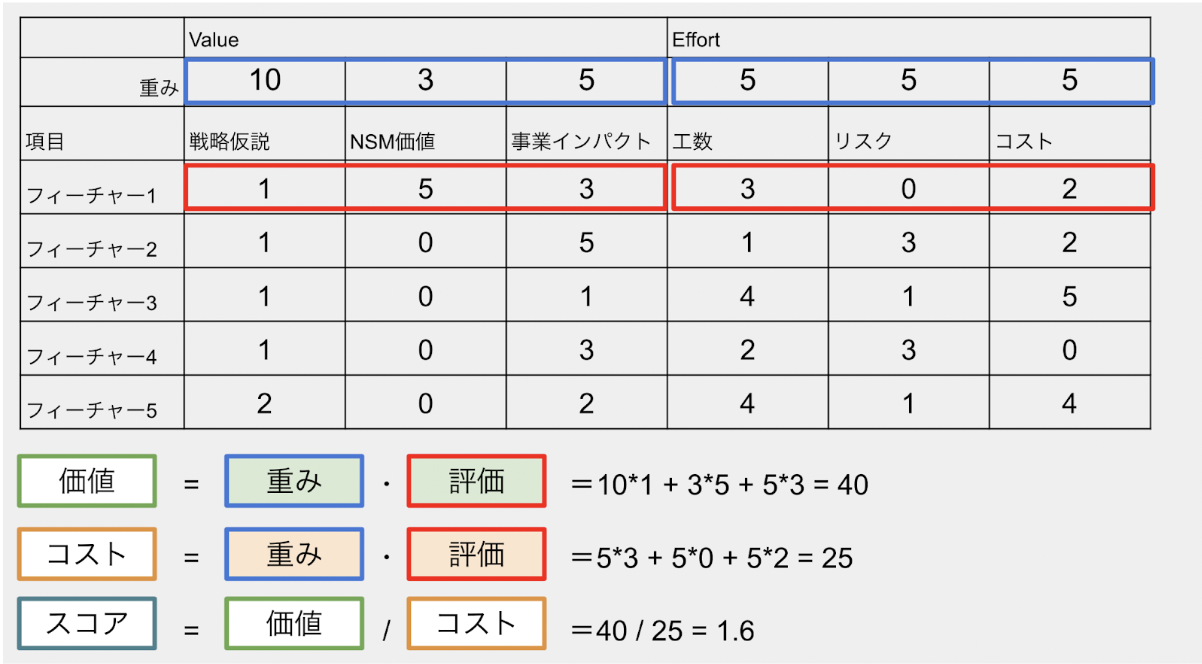
North Star Metrics
NSM(North Star Metrics)は、直訳すると北極星指標です。航海における北極星が常に北を指し示すように、プロダクトマネジメントにおいてそのプロダクトが成長していることを示す重要な指標のことを指します。NSMは、プロダクトが目指すビジネスを体現するような顧客のニーズを満たすことを表す指標です。
NSMは、プロダクトマネージャーがプロダクトを成功に導くために、常にフォーカスするべき指標です。NSMを設定することで、プロダクトマネージャーは、プロダクト開発やマーケティング活動を行う際に、どのような方向性をとるべきかを明確にすることができます。プロダクトマネージャーがプロダクトを成功に導くために持続的に追跡することができるように、シンプルで明瞭であることが大切です。
例えば、動画視聴サービスなどを提供する場合、「総動画視聴時間」などが挙げられます。
この値は、期待付加価値量とは異なり、実際に運用しているサービスの実現値です。実現付加価値と呼んで良いでしょう。そのため、結果ができるまでは時間がかかることが多く、開発チームだけではなく、サービス全体の総合的なアウトプットの評価や価値評価に使うことが望ましいです。
売上(や粗利益額)
実現付加価値として、より全体的なビジネスをとらえたものには、「売上」や「営業利益」などのP/L的な指標が考えられます。アウトプットに全体的な指標を取った際は、それに応じてインプットも全体的な者にする必要があります。
サービス開発をしているチームに売上貢献の話ばかりをしてしまうと、正しい評価にはならないでしょう。
開発生産性が高くても”開発が早い”訳ではない
ここまで「開発生産性」の議論をしてきました。生産性というのはあくまで、あるインプットのうちにどれだけのアウトプットができたのかという指標でした。この指標が意味するところは何なのでしょうか。これは「開発が早い」ということを意味しているのでしょうか。
開発がはやいと言ったときに2つの解釈がありえます。スループットとレスポンスタイム(リードタイム)です。
スループット的な速い :決まった時間にどれだけの施策の個数をこなせたか?などのように時間を固定して、アウトプットの数を数えるもの。これまで議論してきた生産性的な意味でのはやい。同じ工数などでどれだけの機能を実現したか。
リードタイム的な早い :ある施策に注目したときに、それをリリースするまでに何日かかったかなどを数えるもの。これまで議論してきたはやいとは違い、数ではなく期間に注目するもの。
たとえば、1年の間に12個の機能を開発した2つの組織があったとします。タスク量も期待価値も同程度だったとするとレベル1とレベル2の生産性では、同じ値になります。しかし、片方のチームAは、1年後に12個の機能をリリースしており、もう片方のチームBは一ヶ月毎に1つの機能をリリースしているとします。
このとき、どちらのチームが開発が早いと感じるでしょうか。それはその人が注目している観点によって異なります。ある機能にフォーカスを定めて、それを心待ちにしている人にとっては、スループット的な速さを意味する生産性の話をされても、本来したい話とはずれてしまいます。
問題は、この2つのはやさについて、日常語ではあまり区別しないで理解しているため、「ある施策のリードタイムを早くしたい」という話を「生産性を上げたい」という言葉にしてしまうというケースが往々にしておきやすいという点です。
このようなリードタイムを短くするということに価値の源泉をおいた効率性のことをフロー効率性と言います。フロー効率性とその対になるリソース効率性に関する話は以下を参照してください。
このような2つのスループット的な速さと、リードタイム的な早さの両方について開発生産性の議論では、同時にしかも区別無く扱われることがあります。この点を理解しないと開発生産性と言う言葉を巡って議論されるいくつかのキーワードの理解が難しくなってしまいます。
リードタイムの種類
ひとくちに開発のリードタイムと言っても、先ほどの開発生産性の3階層と同じようにレベルの異なる複数の指標があります。
この点も注意が必要です。
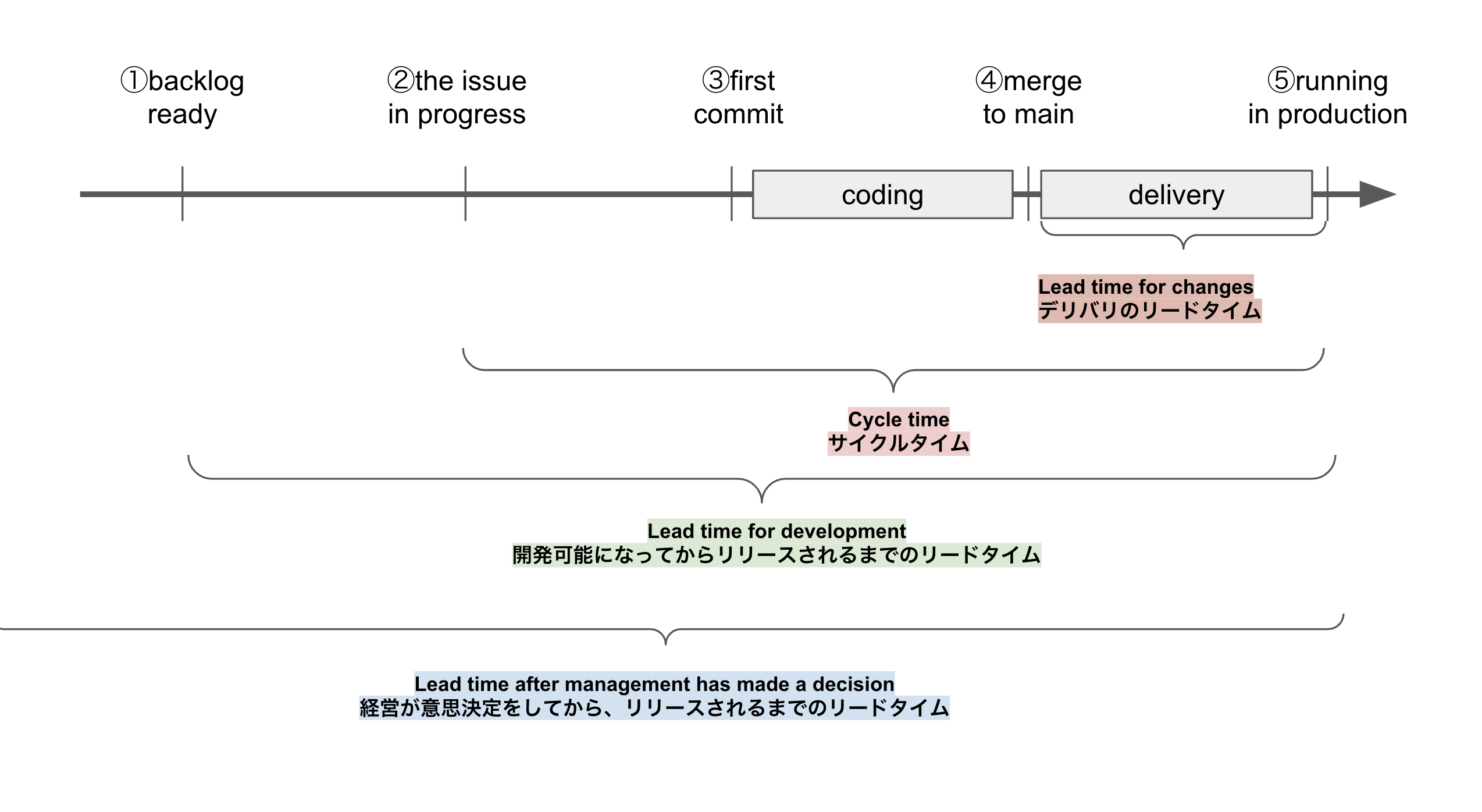
デリバリのリードタイム
main/masterのリポジトリにマージされたコードが、実際に本番稼働するまでの時間(の中央値)
いろいろ言及される場所によって混乱があるが、 DevOpsの変更リードタイムとはこれのこと/あるいはFirst Commitからの中央値とされることもある。CI/CDのパイプラインが健全で、効率的なデプロイが実現できていると短くなる。リリース承認や定期リリースなどをおこなっていると長くなってしまう。生産性そのものと言うよりもチームの健全性や、ソースコード修正に対する心理的安全性の高さと関係している。
(注) 変更のリードタイムについての論点
変更のリードタイムについては、計測ツールや表記によってまちまちで、評価が難しいが
- デプロイのリードタイム
- ファーストコミットからのリードタイム
のどれかを意味している
サイクルタイム
チケットに着手してから、実際に稼働するまでの時間。開発、レビュー、QAなどの待ち時間がなくスムースにいくと短くなる。多くのEIツールで計測されている。そのため、4 keys のデリバリのリードタイムと同一視されたりする。計測はじめにFirst Commitやリモートブランチを切った時刻を採用することで、コーディング着手をSCMで管理しやすく扱っている。レベル1の生産性であるタスクの生産性と関連している。
開発のリードタイム
プロダクトバックログアイテムがReadyな状態になってから、実際に稼働するまでの時間。タスクが積み重なっていると、着手が遅れるため長くなってしまう。レベル2の生産性である期待付加価値の生産性と関連している。
意思決定からのリードタイム
経営や事業責任者が意思決定してから、要件が固まり実際にリリースされるまでの時間。あまり開発現場が見えていない経営者の場合、「開発が遅い」となるのは、この意思決定からのリードタイムであることが多い。しかしこれは、レベル3の生産性である組織全体で解決すべき事柄であることが多い。というのも、多くのソフトウェア開発プロジェクトにおいてリードタイムにおける比重で、
「頻度が質に転化される」という考え方
これまで見てきたように、開発生産性の議論には、2つの速さと早さが混ざり合うことがあります。リードタイム的な早さとスループット的な速さを同時に評価する上で、近年注目されているのは、「開発テンポの良さ」です。
小さなタスクであっても実際にどのぐらいの数のリリースができているのか、そしてそれは障害無くリリースできているのかということを検証することで、開発チームやそのプロダクトの「成熟度」を評価するというものです。ある機能に必要なすべてのコード量が同じだったとしても、できるかぎり小分けに価値ある単位でテンポ良く提供していけば、それだけ、テストやリリースの回数は増えます。
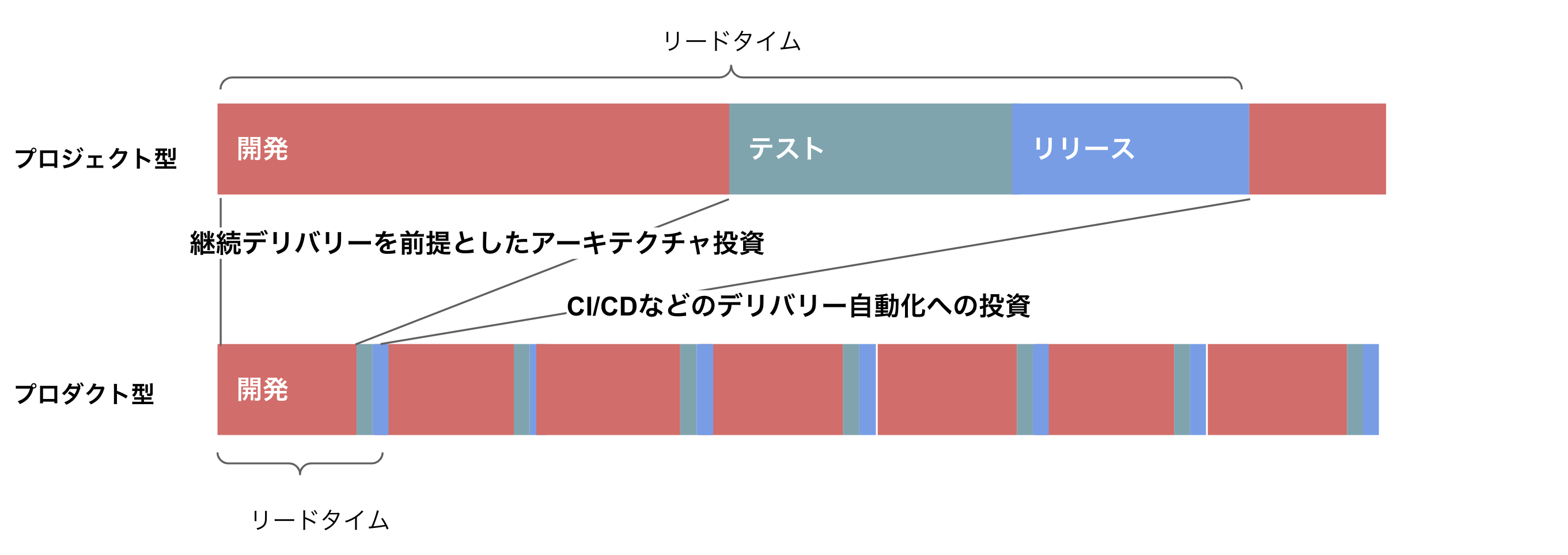
開発時のリリース工程の頻度を高めることで、品質検査とリリースフローを通さないといけない回数が増えます。この頻度が、自動的なテストの価値を高めていき、結果的に品質につながるという考え方です。小さな差分であっても全体的な自動テストが必ず通るという状態であれば、複雑性が小さい状態で検査ができます。大きな差分になってしまうと、複雑性はその分爆発してしまいます。
こうしたことから、Google CloudのDevOps Research and Assessment(DORA)チームも、開発チームの健全な開発環境を評価するのに
- デプロイ頻度(回数指標)
- 変更のリードタイム(リードタイム指標)
- サービス回復時間(健全化指標)
- 変更失敗率(健全化指標)
という構造をもつメトリクスを採用しているという背景があります。

これらはあくまで、開発チームがつくる環境が、「いつ障害が起こるか怖くて仕方ない」という状態ではなく、「率先してチャレンジできる環境」であることを示すものです。レベル2以上の生産性には、統計的な相関関係はありそうだというぐらいでしかありません。
ですが、多くの企業ではまずはここから取りかかっても悪いことはないでしょう。
開発生産性を超えて
ここまでの議論を経て、開発生産性について一筋縄には評価できないものなのだという理解が得られたら、1つの役割は果たせたかなと思います。
ですが、冒頭にも触れたとおり、営利企業であるのだから効率性を数値化、可視化して評価することは重要であるということは間違いありません。
エンジニアチームとそうでないチームで生産性について議論するとき、まずこの記事を読み合わせてみることからはじめてみるとよいのではないでしょうか。