はじめに
本記事では、ChatGPT と LangChain の API を使用して、PDF ドキュメントの内容を自然言語で問い合わせる方法を紹介します。
具体的には、PDF ドキュメントに対して自然言語で問い合わせをすると、自然言語で結果が返ってくる、というものです。
ChatGPT と LangChain を使用することで、下記のような複数ステップの仕事を非常に簡単に実行させることができます。
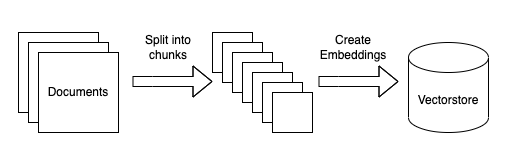
- PDF ドキュメントからテキストを抽出して複数に分割する
- 分割したテキストからテキスト間の関連を表すベクターデータを作成する
- 作成したベクターデータをベクターストアに格納しておく
- ChatGPT に外部から与えたベクターストアを使って問い合わせに答えるようにさせる
これにより、大量の PDF ファイルを自動的に解析し、必要な情報を素早く抽出できるようになります。
本記事では、ChatGPT と LangChain の API を使用し、実際にサンプルの PDF ファイルを解析する方法を説明します。
必要なもの
本記事では実行環境として Google Colab 上で Python コードを書き、ChatGPT と LangChain の Python API を呼び出すこととします。
- Google Colab アカウント
- ChatGPT API キー
- PDF ドキュメント
ChatGPT API キーの取得方法
ChatGPT API キーを取得するには、OpenAI の Web サイトに登録する必要があります。登録後、API キーを取得してください。API キーは、後で使用するので、大切に保管してください。
LangChain を使うには?
LangChain はライブラリですので、使用するのに特に API キーのようなものは必要ありません。詳しくは LangChain の GitHub リポジトリを参照してください。
使用する PDF ドキュメント
本記事では、具体的な PDF ドキュメントとして、アメリカの CLOUD 法のホワイトペーパー資料を使用することとします。
CLOUD 法のホワイトペーパー資料は、アメリカ合衆国司法省のホームページから入手できます。
下記がホワイトペーパーの PDF ドキュメントになります。18 ページに渡って難しそうな文章が並んでいます。初めて見た時のことを想像した場合、少なくとも自分には内容を理解するために多くの時間がかかりそうな資料です。
ここで、アメリカの CLOUD 法とは?については気になるかと思いますが、あえて説明しません。後述するように、ChatGPT と LangChain を使って、上記 PDF ドキュメントの内容について聞いてみたいと思います。
PDF ドキュメントの内容を ChatGPT で扱うには?
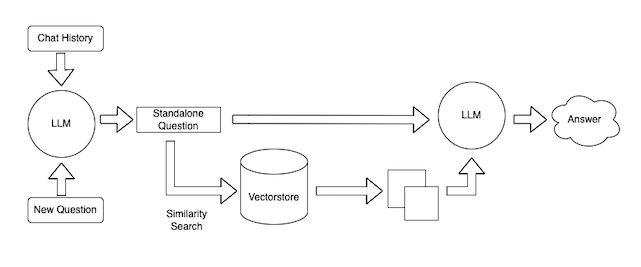
ChatGPT には一度に扱えるテキストの量に限界があります。このため、はじめに大きなドキュメントからテキストを抽出して、それを分割しておきます。次に、テキスト間の関連性についてのベクトルデータをベクターストアに格納しておく必要があります。こうすることで、前述の制限に対応することができます。
具体的には、下図のように、ベクターストアから問い合わせ文に関連する部分を探し、それらを LLM に与えることで、LLM が回答を作成することができるようになります。
詳しく知りたい方は、下記の LangChan によるブログ記事 Tutorial: ChatGPT Over Your Data を参照してください。
Google Colab での Python コードの実行
では、Google Colab を開き、Python コードを書くためのノートブックを作成します。はじめに、以下のように必要なライブラリをインポートします。
%%writefile requirements.txt
openai
chromadb
langchain
pypdf
tiktoken
%pip install -r requirements.txt
import os
import platform
import openai
import chromadb
import langchain
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain
from langchain.document_loaders import PyPDFLoader
PDF ドキュメントのマウント
PDF ドキュメントは、Google ドライブに格納して Google Colab から Python コードでアクセスすることができます。この場合、Google Colab の環境を使って、Python のライブラリをインストールし、Google ドライブとの接続を設定する必要があります。
from google.colab import drive
drive.mount('/content/drive')
その後、LangChain の API で、Google ドライブ内の PDF ドキュメントを読み込んでおきます。これで、PDF ドキュメントに対して自然言語で問い合わせするためのコードを記述することができます。
loader = PyPDFLoader("/content/drive/My Drive/Colab Notebooks/dataset/doj_cloud_act_white_paper_2019_04_10.pdf")
PDF ドキュメントの内容を分割する
前述の処理を行うために、LangChain の API を使って、PDF ドキュメントからテキストを抽出し、抽出したテキストをページごとに分割します。
pages = loader.load_and_split()
では、11 ページ目の内容を見てみましょう。
pages[10].page_content
下記が出力結果になります。
Promoting Public Safety, Privacy, and the Rule of Law Around the World - 11 \n The CLOUD Act also clarified the U.S. Stored Communications Act to enable the framework \nenvisioned by the CLOUD Act, that each nation would use its own law to access data. The CLOUD Act clarified that U.S. law requires that providers subject to U.S. juris diction disclose data that is \nresponsive to valid U.S. legal process, regardless of where the company stores the data. This \nensured consistency with U.S. obligations under Article 18(1) of the Budapest Cybercrime \nConvention, aligning the United States with the more than 60 other parties to the Convention. \nB. CLOUD Act Agreements \n2. Who can enter into a CLOUD Act agreement with the United States? \nThe CLOUD Act provides that the United States may enter into CLOUD Act agreements only with \nrights -respecting coun tries that abide by the rule of law. In particular, before the United States \ncan enter into an executive agreement anticipa...
実際の PDF ドキュメントと見比べてみましたが、確かに 11 ページ目の内容になっています。
LangChain における LLM のセットアップ
次に、ChatGPT による自然言語でのクエリ処理を実行するためのコードを書きます。
まず、OpenAI の API Key をセットして、LangChain で使用する LLM を準備します。
os.environ["OPENAI_API_KEY"] = '(Your API Key is here)'
openai.api_key = os.getenv("OPENAI_API_KEY")
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
上記のコードでは、ChatGPT の gpt-3.5-turbo モデルを使用して、クエリを生成します。
その他のモデル名を指定したり、最大トークン数などのパラメータも指定することもでき、生成されるテキストの質を制御するために使用されます。
上記ではモデル名とサンプリング温度以外、デフォルトとしています。サンプリング温度は、生成されるテキストにおける単語の選択に関係しています。ここでは、0 という一番低いサンプリング温度を指定しているため、最も出現頻度が高い単語が選択されるようになります。
分割したテキストの情報をベクターストアに格納する
次に、分割したテキストについて、テキスト間の関連性に関するベクターデータをベクターストアに格納しておきます。
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(pages, embedding=embeddings, persist_directory=".")
vectorstore.persist()
ベクターストアには Chroma という AI 用のオープンソースのベクターデータベースを使用します。

このベクターストアを LLM に対して与えることで、テキスト間の関連性について表現したベクトルデータを外部から与え、そのデータを LLM に使用させることができます。
PDF ドキュメントへ自然言語で問い合わせる
それでは、ChatGPT に PDF ドキュメントの内容について聞いてみましょう。
ここでは、回答文の作成に関連した元テキスト群についても示すように指定します。
pdf_qa = ConversationalRetrievalChain.from_llm(llm, vectorstore.as_retriever(), return_source_documents=True)
はじめに英語で US クラウド法とは何か?について聞いてみます。回答は日本語で返してもらうこととします。
query = "What is US Cloud Act? Answer within 50 words in Japanese."
chat_history = []
result = pdf_qa({"question": query, "chat_history": chat_history})
result["answer"]
下記が ChatGPT による回答です。
"CLOUD法案は、アメリカ合衆国が制定した法律であり、海外にあるアメリカのグローバルプロバイダーが保持する電子情報へのアクセスを加速することを目的としています。この法律は、テロや暴力犯罪、児童性的搾取、サイバー犯罪などの重大犯罪の捜査に必要な電子証拠を、アメリカ以外の国の法執行機関がアクセスできるようにすることを目的としています。"
上記の回答に関連した元のテキスト群について確認します。
result['source_documents']
下記が出力結果になります。実際にはもっと多くの元テキストから出力を作成しているようですが、ここでは割愛します。
[Document(page_content='Promoting Public Safety, Privacy, and the Rule of Law Around the World - 2 \n
Introduction \n
\n
The United States enacted the CLOUD Act to speed access to electronic information held by U.S. -\n
based global providers that is critical to our foreign partners’ investigations of serious crime, \n
ranging from terrorism and violent crime to sexual exploitation of children and cybercrime. Our \n
foreign partners have long expressed concerns that the mutual legal assistance process is too \n
cumbersome to handle their growing needs for this type of electronic evidence in a timely \n
manner. The assist ance requests the United States receives often seek electronic information \n
related to individuals or entities located in other countries, and the only connection of the \n
investigation to the United States is that the evidence happens to be held by a U.S. -based global \n
provider . The CLOUD Act is designed to permit our foreign partners that have robust protections \n
for privacy and civil liberties to enter into executive agreements with the United States to obtain \n
access to this electronic evidence, wherever it happens to be located, in order to fight serious \ncrime and terrorism.
...
それでは、US クラウド法によってどういう主体が影響を受けるか聞いてみます。
chat_history = [(query, result["answer"])]
query2 = "What actors are affected by the US Cloud Act? Answer it within 50 words in Japanese."
result2 = pdf_qa({"question": query2, "chat_history": chat_history})
result2["answer"]
下記が ChatGPT による回答です。
"米国のCLOUD法は、米国管轄下にある電子通信サービスまたはリモートコンピューティングサービスを提供する企業に影響を与えます。これには、電子メールプロバイダー、携帯電話会社、ソーシャルメディアプラットフォーム、クラウドストレージサービスなどが含まれます。ただし、インターネットとのある程度の関係がある企業、例えば特定のeコマースサイトなどは含まれません。"
今度は日本語で聞いてみます。もちろん、先ほどと同様の内容が得られることが確認できます。
chat_history = [(query, result["answer"]), (query2, result2["answer"])]
query3 = "CLOUD法によって影響を受ける主体にはどういったものがありますか?日本語で回答してください。"
result3 = pdf_qa({"question": query3, "chat_history": chat_history})
result3["answer"]
下記が ChatGPT による回答です。
"米国のCLOUD法は、米国の「遠隔コンピューティングサービス」(RCS)および「電子通信サービス」(ECS)プロバイダーに適用されます。これらの定義には、電子メールプロバイダー、携帯電話会社、ソーシャルメディアプラットフォーム、クラウドストレージサービスなどが含まれます。ただし、特定の電子商取引サイトなど、インターネットとのやり取りがあるだけの企業は含まれません。CLOUD法は、米国の管轄権を拡大するものではなく、プロバイダーに対する新しい義務を課すものでもありません。"
以上が、ChatGPT と LangChain を使用して自然言語で PDF ドキュメントの内容について問い合わせる方法の具体的な例となります。
注意点として、ChatGPT による回答の正確性については保証されていませんので、関連する元テキスト情報などに基づいて、ご自身で判断いただく必要があります。
それでも、はじめて難解な資料に向き合う必要ができた時のことを想像すると、非常に大きな助けになることが分かります。
まとめ
今回のブログでは、ChatGPT と LangChain を使用して、簡単には読破や理解が難しい PDF ドキュメントに対して自然言語で問い合わせをし、爆速で内容を把握する方法を紹介しました。
これにより、ユーザーは簡単に特定のトピックに関する情報を検索することが容易になります。ChatGPT は、豊富な情報源をもとにトレーニングされており、高度な自然言語処理技術を使用して、PDF ドキュメントに含まれる情報を正確に抽出できます。そのため、ユーザーは煩雑なキーワード検索やページめくりの手間を省くことができます。
さらに、ChatGPT は翻訳機能を備えており、複数の言語での問い合わせにも対応しています。これにより、グローバルなビジネス環境においても、異なる言語のドキュメントにアクセスし、情報を共有することができます。ChatGPT を使用することで、PDF ドキュメントの読み込みや検索の時間を短縮し、業務効率を向上させることができます。
ChatGPT を使って PDF ドキュメントの内容について問い合わせることのできるサービスも出てきているようですが、今回紹介した方法では、ChatGPT の API のみを使用し、他には外部のサービスを利用せずに PDF ドキュメントの内容について問い合わせることができます。
実は、ChatGPT は US クラウド法について学習済みであるため、わざわざ LangChain を使用せずとも ChatGPT はその内容について回答することができます。
そこで、ぜひ読者の方には ChatGPT がまだ直接答えることができないであろう PDF ドキュメントに対して ChatGPT と LangChain を用いて自然言語で問い合わせてみて頂きたいと思います。本ブログが参考になれば幸いです。
関連記事