はじめに
ソースコードの解読には、高度な技能や時間が必要です。しかし、ChatGPT を使えば、ソースコードの解読を迅速に行うことができます。
ChatGPT は、OpenAI が開発した言語モデルの一つであり、大量の自然言語のコーパスを学習しています。そのため、一定期間内の OSS のソースコードを解析する際には、最新の知識を反映させることができません。しかし、LangChain を使用することで、最新の OSS のソースコードに対しても問い合わせを行うことができます。
この記事では、ChatGPT と LangChain を用いて、最新の OSS ソースコードのウォークスルーを行う方法について紹介します。
ChatGPT に最新の OSS ソースコードを解析させるには?
LangChain は、外部のベクターストアを使用して、ソースコードに含まれるテキストデータの意味的な関連性を ChatGPT に与え、ソースコードの内容について自然言語で回答させることができます。このため、LangChain を使用することで、ChatGPT が未学習である最新の OSS のソースコードに対しても、ChatGPT で適切な解析を行うことができるようになります。
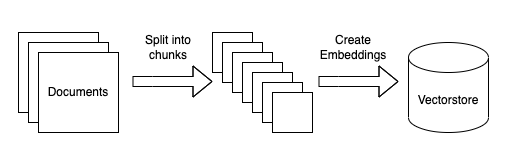
具体的には、LangChain の API を使って、最新の OSS のソースコードをベクターストアに読み込ませます。この際、LangChain はソースコード内の単語やフレーズをベクトル表現に変換し、それらのベクトル間の距離や関連性を解析したものをベクターストアに格納します。LangChain は、この外部ベクターストアを基に、ChatGPT に自然言語での解説や概要を生成させることができます。
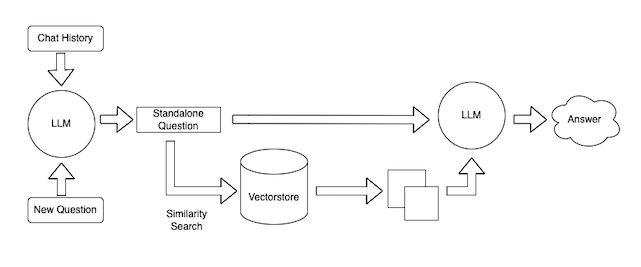
詳しく知りたい方は、下記の LangChan によるブログ記事 Tutorial: ChatGPT Over Your Data を参照してください。
LangChain を使用することで、最新の OSS のソースコードに対しても、ChatGPT を使用して正確な解析とウォークスルーを行うことができます。もちろん、業務で開発中のソースコードに対しても有効であると想定できます。
必要なもの
本記事では実行環境として Google Colab 上で Python コードを書き、ChatGPT と LangChain の Python API を呼び出すこととします。
- Google Colab アカウント
- ChatGPT API キー
- ソースコードリポジトリ
ChatGPT API キーの取得方法
ChatGPT API キーを取得するには、OpenAI の Web サイトに登録する必要があります。登録後、API キーを取得してください。API キーは、後で使用するので、大切に保管してください。
LangChain を使うには?
LangChain はライブラリですので、使用するのに特に API キーのようなものは必要ありません。詳しくは LangChain の GitHub リポジトリを参照してください。
使用するソースコード
本記事では、LangChain 自身のソースコードを使用することとします。
本記事を執筆している 2023 年 4 月時点では、LangChain はまだ非常に新しい OSS です。リポジトリを見ると、最初の公開リリースは、2023 年 に入ってから行われているようです。このため、LangChain のソースコードについては、ChatGPT 単体では答えることはできません。
Google Colab での Python コードの実行
では、Google Colab を開き、Python コードを書くためのノートブックを作成します。はじめに、以下のように必要なライブラリをインポートします。
%%writefile requirements.txt
openai
chromadb
langchain
deeplake
tiktoken
%pip install -r requirements.txt
import os
import platform
import openai
import chromadb
import langchain
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain
from langchain.document_loaders import TextLoader
from langchain.vectorstores import DeepLake
解析したいソースコードの読み込み
まず、解析したいソースコードの Git リポジトリをクローンしておきます。
!git clone https://github.com/hwchase17/langchain
前述の処理を行うために、LangChain の API を使って、入手したソースコードファイルを読み込ませておきます。
root_dir = './langchain/langchain'
docs = []
for dirpath, dirnames, filenames in os.walk(root_dir):
for file in filenames:
try:
loader = TextLoader(os.path.join(dirpath, file), encoding='utf-8')
docs.extend(loader.load_and_split())
except Exception as e:
pass
上記で読み込んだ、docs 配列の 2 番目の要素を見てみましょう。
docs[2]
ソースコードの内容が読み込まれています。
Document(page_content='async def atransform_documents(\n self, documents: List[Document], **kwargs: Any\n ) -> List[Document]:\n """Asynchronously transform a list of documents by splitting them."""\n raise NotImplementedError\n\n\nclass CharacterTextSplitter(TextSplitter):\n """Implementation of splitting text that looks at characters."""\n\n def __init__(self, separator: str = "\\n\\n", **kwargs: Any):\n """Create a new TextSplitter."""\n super().__init__(**kwargs)\n self._separator = separator\n\n def split_text(self, text: str) -> List[str]:\n """Split incoming text and return chunks."""\n # First we naively split the large input into a bunch of smaller ones.\n if self._separator:\n splits = text.split(self._separator)\n else:\n splits = list(text)\n return self._merge_splits(splits, self._separator)\n\n\nclass TokenTextSplitter(TextSplitter):\n """Implementation of splitting text that looks at tokens."""\n\n ...
ソースコードの内容を分割する
次にソースコードファイルからテキストを抽出し、抽出したテキストを適切なサイズごとに分割しておきます。
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(docs)
ソースコードテキストは、必ずしも指定したサイズごとにきれいに区切れるとは限らないため、下記のような警告が出ることがありますが、概ね ChatGPT のモデルで扱えるサイズに収まっているため、ここでは無視することとします。
WARNING:langchain.text_splitter:Created a chunk of size 1620, which is longer than the specified 1000
WARNING:langchain.text_splitter:Created a chunk of size 1273, which is longer than the specified 1000
WARNING:langchain.text_splitter:Created a chunk of size 1213, which is longer than the specified 1000
WARNING:langchain.text_splitter:Created a chunk of size 1496, which is longer than the specified 1000
WARNING:langchain.text_splitter:Created a chunk of size 1263, which is longer than the specified 1000
...
分割されたテキストの一つを見てみると、小さいチャンクに区切られていることが確認できます。
texts[0]
Document(page_content='"""Functionality for splitting text."""\nfrom __future__ import annotations\n\nimport copy\nimport logging\nfrom abc import ABC, abstractmethod\nfrom typing import (\n AbstractSet,\n Any,\n Callable,\n Collection,\n Iterable,\n List,\n Literal,\n Optional,\n Union,\n)\n\nfrom langchain.docstore.document import Document\nfrom langchain.schema import BaseDocumentTransformer\n\nlogger = logging.getLogger(__name__)\n\n\nclass TextSplitter(BaseDocumentTransformer[Document], ABC):\n """Interface for splitting text into chunks."""', metadata={'source': './langchain/langchain/text_splitter.py'})
LangChain における LLM のセットアップ
次に、ChatGPT による自然言語でのクエリ処理を実行するためのコードを書きます。
まず、OpenAI の API Key をセットして、LangChain で使用する LLM を準備します。
os.environ["OPENAI_API_KEY"] = '(Your API Key is here)'
openai.api_key = os.getenv("OPENAI_API_KEY")
llm = ChatOpenAI(temperature=0, model_name='gpt-3.5-turbo')
上記のコードでは、ChatGPT の gpt-3.5-turbo モデルを使用してソースコードを解析します。
その他のモデル名を指定したり、最大トークン数などのパラメータも指定することもでき、生成されるテキストの質を制御するために使用されます。
分割したテキストの情報をベクターストアに格納する
次に、分割したテキストについて、テキスト間の関連性に関するベクターデータをベクターストアに格納します。
本記事では、ChatGPT に与えるベクターストアとして、DeepLake という Deep Learning 用のデータレイクサービスを使用します。
DeepLake を使用するには、下記の ActiveLoop のサイトから API キーを作成しておきます。
次に、取得した API キーを設定し、ベクターストアに分割したテキストを格納します。
os.environ['ACTIVELOOP_TOKEN'] = '(Your DeepLake API Key is here)'
embeddings = OpenAIEmbeddings()
dataset_path = "hub://(Your DeepLake Username is here)/(Your dataset name is here)"
db = DeepLake.from_documents(texts, embeddings, dataset_path=dataset_path, read_only=True)
上記を実行すると、DeepLake にデータを送信するのに少し時間がかかります。
Your Deep Lake dataset has been successfully created!
The dataset is private so make sure you are logged in!
This dataset can be visualized in Jupyter Notebook by ds.visualize() or at https://app.activeloop.ai/(Your DeepLake Username is here)/(Your dataset name is here)
hub://(Your DeepLake Username is here)/(Your dataset name is here) loaded successfully.
Evaluating ingest: 100%|██████████| 3/3 [00:21<00:00
-Dataset(path='hub://(Your DeepLake Username is here)/(Your dataset name is here)', tensors=['embedding', 'ids', 'metadata', 'text'])
tensor htype shape dtype compression
------- ------- ------- ------- -------
embedding generic (2280, 1536) float32 None
ids text (2280, 1) str None
metadata json (2280, 1) str None
text text (2280, 1) str None
このベクターストアを下記のように LLM に対して与えることで、テキスト間の関連性について表現したベクトルデータを LLM に使用させることができます。
retriever = db.as_retriever()
retriever.search_kwargs['distance_metric'] = 'cos'
retriever.search_kwargs['fetch_k'] = 100
retriever.search_kwargs['maximal_marginal_relevance'] = True
retriever.search_kwargs['k'] = 20
qa = ConversationalRetrievalChain.from_llm(llm, retriever=retriever)
以上で ChatGPT に読み込ませたソースコードの内容を自然言語で問い合わせる準備ができました。
ソースコードの内容を自然言語で問い合わせる
それでは、ChatGPT に 読み込ませたソースコードの内容について聞いてみましょう。
今回は、下記の関連記事で使用した、LangChain の SQLDatabaseChain の内部的な挙動が気になったため、これについて調べたいと思います。
そこで、下記のような内容を ChatGPT に質問します。
- SQLDatabaseChain は何をしているか?
- chain/sql_database/base.py ファイルでは何をしているか?
- SQLDatabaseChain は SQL クエリを ChatGPT を使って作成しているか?
- SQLDatabaseChain で ChatGPT に SQL クエリを作成させる時のプロンプト文は何か?
- SQLDatabaseChain はどのように SQL クエリを実行しているか?
たくさん聞きたいことが出てきましたので、LangChain で複数の質問をまとめて ChatGPT に問い合わせてみます。
import time
questions = [
"What does SQLDatabaseChain do? Explain it within 1000 words.",
"Explain what the chain/sql_database/base.py do within 1000 words.",
"Does the SQLDatabaseChain make SQL queries by ChatGPT?",
"What are the ChatGPT prompts to make SQL queries in SQLDatabaseChain?",
"How does the SQLDatabaseChain execute SQL queries?",
]
chat_history = []
for question in questions:
result = qa({"question": question, "chat_history": chat_history})
chat_history.append((question, result['answer']))
print(f"-> **Question**: {question} \n")
print(f"**Answer**: {result['answer']} \n")
time.sleep(25)
この場合の注意点として、無料お試し版の ChatGPT の API キーでは、一定時間あたりに実行可能な API コールの数に制限があるため、質問ごとにウェイトを入れることにします。ChatGPT Plus を契約している場合は、上記のコード中にあるスリープ文は不要です。
下記が各質問に対する ChatGPT による回答です。
What does SQLDatabaseChain do? Explain it within 1000 words.
Answer:
SQLDatabaseChain is a Python package that provides a chain for interacting with SQL databases. It is designed to make it easy to query SQL databases using natural language queries. The package is built on top of the Pydantic library, which provides a way to define data models and validate input data.
The SQLDatabaseChain package provides a Chain class that can be used to define a chain of operations that can be executed in sequence. The Chain class is designed to be extensible, so that new operations can be added easily. The package also provides a number of pre-defined operations that can be used to interact with SQL databases.
The SQLDatabaseChain package is built on top of the LangChain library, which provides a way to define natural language models and generate text using those models. The LangChain library is built on top of the PyTorch library, which provides a way to define and train neural networks.
The SQLDatabaseChain package provides a number of pre-defined operations that can be used to interact with SQL databases. These operations include:
- Query: This operation allows you to execute a SQL query on a database and return the results.
- Insert: This operation allows you to insert data into a database.
- Update: This operation allows you to update data in a database.
- Delete: This operation allows you to delete data from a database.
The SQLDatabaseChain package also provides a number of pre-defined prompts that can be used to generate natural language queries. These prompts include:
- Select: This prompt generates a natural language query that selects data from a database.
- Insert: This prompt generates a natural language query that inserts data into a database.
- Update: This prompt generates a natural language query that updates data in a database.
- Delete: This prompt generates a natural language query that deletes data from a database.
The SQLDatabaseChain package is designed to be extensible, so that new operations and prompts can be added easily. This makes it easy to customize the package to meet your specific needs.
In summary, SQLDatabaseChain is a Python package that provides a chain for interacting with SQL databases. It is built on top of the LangChain library, which provides a way to define natural language models and generate text using those models. The package provides a number of pre-defined operations and prompts that can be used to interact with SQL databases, and is designed to be extensible so that new operations and prompts can be added easily.
残念ながら、こちらの回答は誤った内容が多いように思います。
使用したプロンプトが単純すぎたり、指定した単語数が多すぎたせいかもしれません。
プロンプトテンプレートや質問文について改善の余地ありです。
Explain what the chain/sql_database/base.py do within 1000 words.
Answer:
The
chain/sql_database/base.pyfile contains the base class for theSQLDatabaseChain, which is a chain for interacting with a SQL database. It also contains theQuerySQLDataBaseTool, which is a tool for querying a SQL database. The file defines the input and output formats for the chain and tool, as well as the methods for executing the chain and tool. Additionally, the file contains some utility functions for loading theSQLDatabaseChainfrom a configuration file.
base.py にはSQLDataBaseChainが含まれ、それはSQLデータベースとやり取りするChainである、という内容のところなどは合っています。
ですが、こちらの回答も一部誤りが含まれているようです。回答文にあったQuerySQLDataBaseToolというものはソースコードリポジトリからは見つかりませんでした。こちらもプロンプトテンプレートや質問文について改善の余地ありです。
Does the SQLDatabaseChain make SQL queries by ChatGPT?
Answer:
SQLDatabaseChain uses the
_callmethod to make SQL queries. This method takes in a dictionary of inputs, with the SQL query being passed in under the key specified by theinput_keyattribute (which defaults to "query"). The method then determines which tables to use based on the query, calls theget_usable_table_namesmethod of the SQLDatabase object to get a list of usable table names, and passes the query and the list of table names to the decider chain to determine which tables to use. Finally, the method calls the_callmethod of the SQLDatabase object with the query and the list of table names to execute the query and return the results.
こちらは _call メソッドを使ってSQL文を作成している、という内容や、SQLDatabase オブジェクトのget_usable_table_namesメソッドからの返却値を使って使用可能なテーブル名の一覧を得ている点など、ソースコードの内容をきちんと反映した、かなり正確な回答になっているようです。
What are the ChatGPT prompts to make SQL queries in SQLDatabaseChain?
Answer:
SQLDatabaseChain uses different prompts for different SQL dialects. Here are the prompts used for each dialect:
- GoogleSQL:
GOOGLESQL_PROMPT- MSSQL:
MSSQL_PROMPT- MySQL:
MYSQL_PROMPT- MariaDB:
MARIADB_PROMPT- Oracle:
ORACLE_PROMPT- PostgreSQL:
POSTGRES_PROMPT- SQLite:
SQLITE_PROMPTAll of these prompts are defined in the
prompts.pyfile in the SQLDatabaseChain repository.
こちらはかなり正確な回答が返ってきているようです。
How does the SQLDatabaseChain execute SQL queries?
Answer:
The SQLDatabaseChain executes SQL queries by first determining which tables to use based on the query, and then calling the normal SQL database chain based on those tables. It uses a language model to parse the query and determine which tables to use, and then passes the query and the selected tables to the SQL database chain for execution.
こちらもかなり正確な回答が返ってきているようです。
以上が、ChatGPT と LangChain を使用して自然言語でソースコードの内容について問い合わせる方法の具体的な例となります。
ソースコードの内容を問い合わせてみての感想
いかがでしょうか?実際のソースコードと上記の回答を見比べてみると、最初からソースコードを読もうとするよりも、はるかに理解しやすくなり、学習曲線がスムーズになることを体感できました。
注意点として、ChatGPT による回答の正確性については保証されていませんので、上記のように関連する元ソースコードの情報と照らし合わせて、正確性についてはご自身で判断いただく必要があります。
それでも、はじめて見る難解なソースコードに向き合う必要ができた時のことを想像すると、非常に大きな助けになることが分かります。
まとめ
今回の記事では、ChatGPT と LangChain を使用して、最新かつ大量の OSS ソースコードに対して自然言語で問い合わせをし、爆速で内容を把握する方法を紹介しました。
ChatGPT と LangChain を使用することで、最新の OSS ソースコードの解説やウォークスルーを迅速かつ正確に行うことができます。
これにより、開発者はより迅速にソースコードを解読し、コードの品質を向上させることができます。また、ChatGPT は機械学習による自己学習を行っているため、開発者が新しい用語やフレーズを使っても、適切に解釈することができます。
ChatGPT を使ったソースコードのウォークスルーは、プログラマーにとって有用なツールの 1 つであると言えるでしょう。
関連記事